CaPa: Carve-n-Paint Synthesis
for Efficient 4K Textured Mesh Generation
Online Demo is Open! & Stay tuned for more powerful model releases!
Graphics AI Lab, NCSOFT Research
TL;DR: We propose CaPa, a novel method for generating high-quality 4K textured mesh under only 30 seconds, providing 3D assets ready for commercial applications such as games, movies, and VR/AR.
Teaser Video
Pipeline Overview
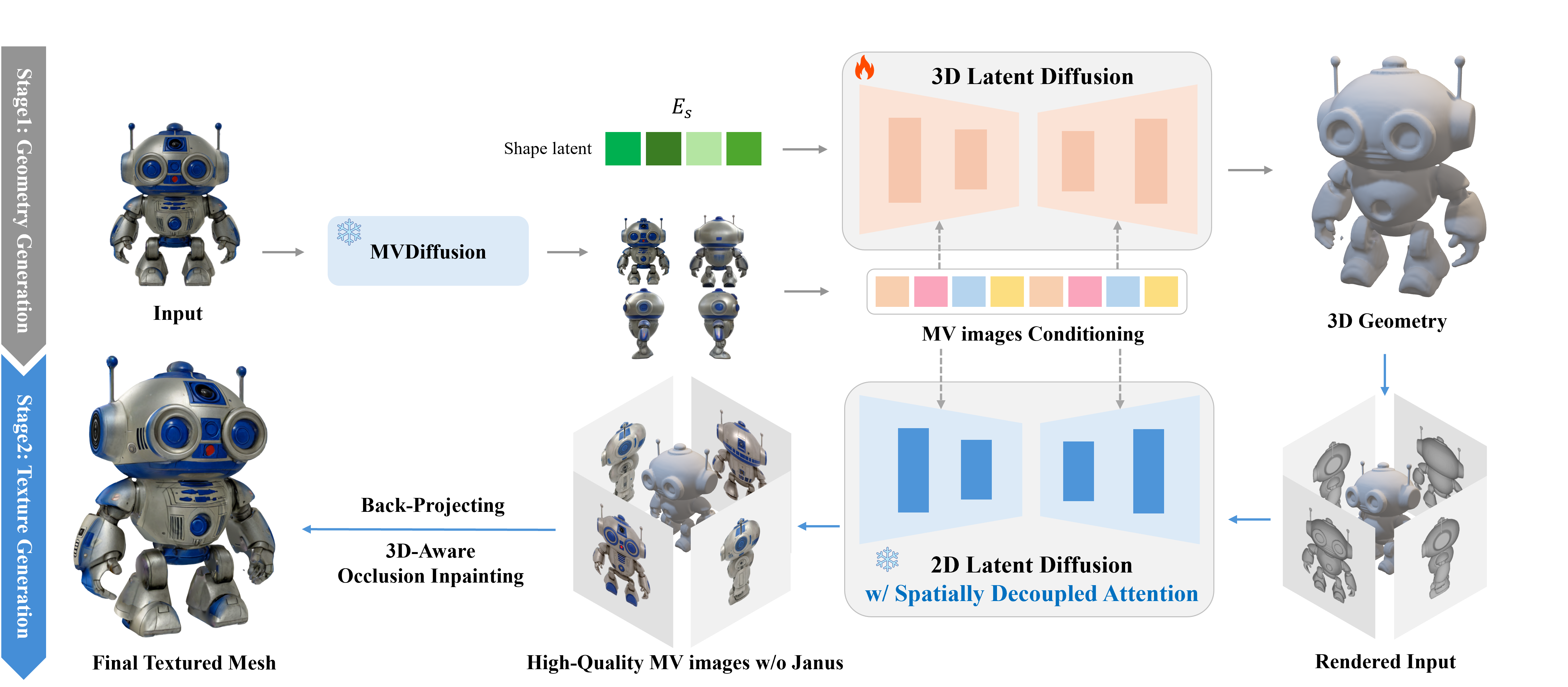
Abstract
The synthesis of high-quality 3D assets from textual or visual inputs has become a central
objective in modern generative modeling.
Despite the proliferation of 3D generation algorithms, they frequently grapple with challenges such as multi-view inconsistency, slow generation times, low fidelity, and surface reconstruction problems.
While some studies have addressed some of these issues, a comprehensive solution remains elusive.
In this paper, we introduce CaPa, a carve-and-paint framework that generates high-fidelity 3D assets efficiently.
CaPa employs a two-stage process, decoupling geometry generation from texture synthesis.
Initially, a 3D latent diffusion model generates geometry guided by multi-view inputs, ensuring structural consistency across perspectives.
Subsequently, leveraging a novel, model-agnostic Spatially Decoupled Attention, the framework synthesizes high-resolution textures (up to 4K) for a given geometry.
Furthermore, we propose a 3D-aware occlusion inpainting algorithm that fills untextured regions, resulting in cohesive results across the entire model.
This pipeline generates high-quality 3D assets in less than 30 seconds, providing ready-to-use outputs for commercial applications.
Experimental results demonstrate that CaPa excels in both texture fidelity and geometric stability, establishing a new standard for practical, scalable 3D asset generation.
Examples






We compare CaPa with state-of-the-art Image-to-3D methods. Here, all the assets are converted to polygonal mesh, using its official code. CaPa significantly outperforms both geometry stability and visual fidelity, especially for the back and side view.
Scalability & Adaptability
PBR-aware 3D asset Generation
Texture Editing
| Original | Edited w/ text prompt ("orange sofa, orange pulp") |
|---|
Citation
BibTeX
@article{heo2025capa,
title = {CaPa: Carve-n-Paint Synthesis for Efficient 4K Textured Mesh Generation},
author = {Hwan Heo and Jangyeong Kim and Seongyeong Lee and Jeong A Wi and Junyoung Choi and Sangjun Ahn},
journal = {arXiv preprint arXiv:2501.09433},
year = {2025},
}
title = {CaPa: Carve-n-Paint Synthesis for Efficient 4K Textured Mesh Generation},
author = {Hwan Heo and Jangyeong Kim and Seongyeong Lee and Jeong A Wi and Junyoung Choi and Sangjun Ahn},
journal = {arXiv preprint arXiv:2501.09433},
year = {2025},
}