
작성자
- 이상학 (챗봇서비스실)
- 검색 기술과 Query Reformulation을 연구하고 있습니다.
이런 분이 읽으면 좋습니다!
- 검색 패러다임의 등장 배경과 장단점이 궁금하신 분
- 검색 패러다임별로 대표적인 기술이 궁금하신 분
이 글로 알 수 있는 내용
- 새로운 검색 패러다임이 왜 등장했고, 어떻게 기존의 문제를 해결했는지
- BM25, DPR, SPLADE 방법론의 작동 방식
시작하며
안녕하세요. 저는 엔씨소프트에서 검색을 연구하는 이상학입니다. 회사에서 검색을 연구하면서 보니 시간이 흘러가며 검색 패러다임이 변화하는 모습이 흥미로웠습니다. 그래서 이번 블로그 글을 통해 검색 패러다임의 흥미로운 변천사를 소개하고자 합니다.
전통적인 검색은 단어 매칭을 통해 이루어졌습니다. 직관적으로 검색어와 단어가 많이 겹치는 문서를 검색 결과로 제공했습니다. 단어 매칭 기반 검색은 수십 년 동안 많은 검색 엔진에서 사용되었습니다. 단어 매칭 기반 검색 이후로 많은 시간이 흘러 언어모델의 시대가 밝았습니다. 다양한 자연어처리 태스크에 언어모델이 적용되기 시작하면서 언어모델을 활용한 검색 패러다임도 등장했습니다. 언어모델이 만드는 의미 벡터가 의미 기반 검색을 가능케 했습니다. 의미 기반 검색 이후에는 그 약점을 보완하는 새로운 검색 방법도 등장했습니다.
앞서 설명한 세 가지는 보통 Sparse Retrieval과 Dense Retrieval과 Learned Sparse Retrieval라는 검색 패러다임입니다. 본 글에서는 Sparse Retrieval부터 Learned Sparse Retrieval까지 어떻게 흘러갔는지 등장 배경과 작동 방식 그리고 예시를 통해 소개합니다.
본 글은 SIGIR 2023 Tutorial1의 흐름을 참고하여 작성했습니다.
검색 파이프라인
패러다임을 알아보기 전에 기본적인 검색 파이프라인을 살펴보겠습니다.
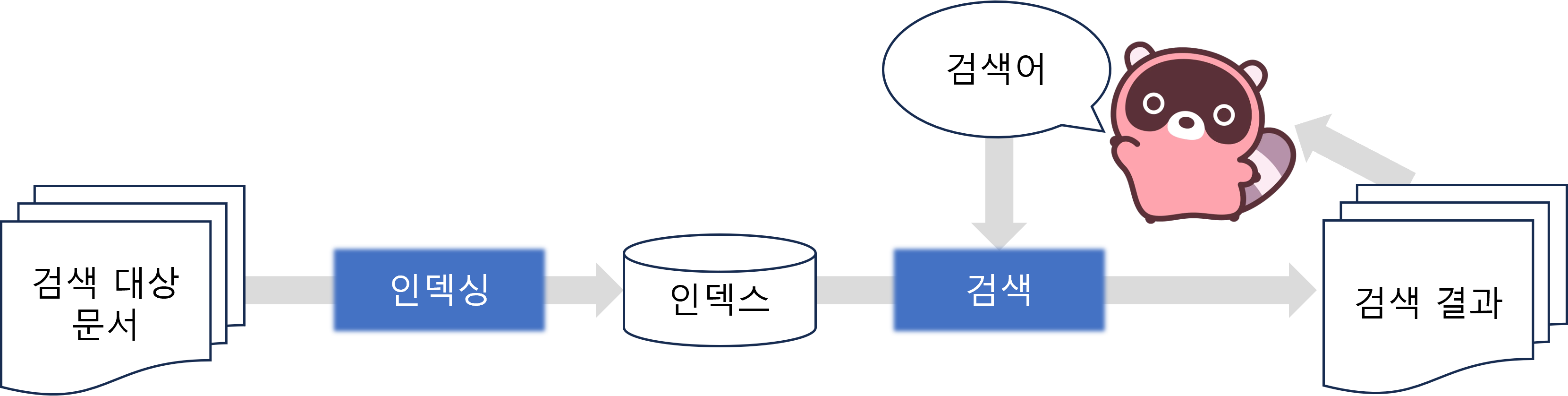 <그림 1> 검색 파이프라인
(인덱싱 단계) 검색 대상이 되는 문서들을 인덱스로 구조화한다. (검색 단계) 사용자의 검색어에 맞는 문서를 인덱스에서 찾아 검색 결과로 제공한다.
<그림 1> 검색 파이프라인
(인덱싱 단계) 검색 대상이 되는 문서들을 인덱스로 구조화한다. (검색 단계) 사용자의 검색어에 맞는 문서를 인덱스에서 찾아 검색 결과로 제공한다.
검색은 <그림 1>에 표현된 바와 같이 인덱싱 단계와 검색 단계로 이루어집니다.
- <그림 1> 왼쪽은 인덱싱(Indexing, 색인작업)에 해당합니다. 인덱싱이란 검색 대상이 되는 모든 문서를 검색할 수 있게 구조화해서 인덱스(Index, 색인)를 만드는 과정입니다. 사용자의 검색이 있기 전에 미리 진행해야 합니다.
- <그림 1> 오른쪽은 검색(Retrieval)에 해당합니다. 사용자의 검색어에 적합한 문서를 인덱스에서 찾는 작업입니다. 찾은 문서들은 사용자에게 최종 검색 결과로 제공됩니다.
검색 패러다임의 변화는 인덱싱과 검색 단계를 개선하면서 이루어졌습니다. 이제 어떤 점에서 개선이 있었는지 확인해 보겠습니다.
검색 패러다임
Sparse Retrieval
Sparse Retrieval은 Lexical Match 기반 검색 패러다임입니다. 검색어에 있는 단어가 많이 나오는 문서를 사용자에게 검색 결과로 제공합니다. 직관적인 검색 방법으로 좋은 성능을 보였기에 오랜 시간이 지난 지금에도 사용되는 전통적인 검색 방식입니다.
인덱싱과 검색 단계
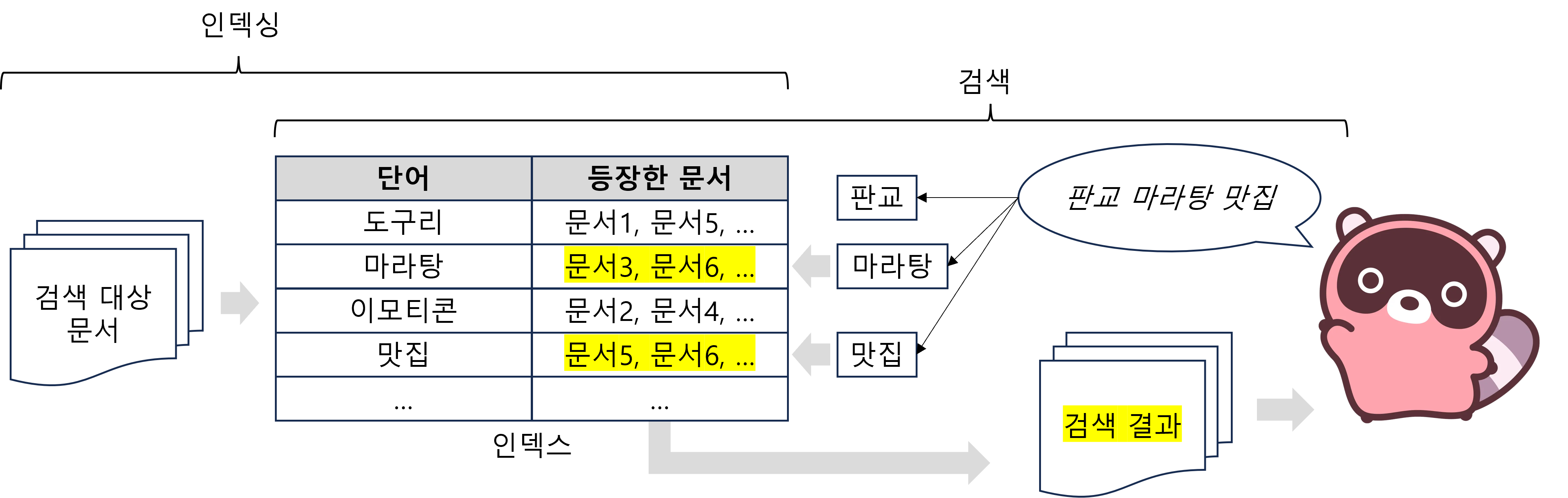 <그림 2> Sparse Retrieval의 예시
(인덱싱 단계) 어떤 단어가 어떤 문서에 들어있는지 인덱스로 구조화한다. (검색 단계) 검색어에서 단어를 뽑고 인덱스에서 해당 단어가 들어있는 문서를 찾아서 검색 결과로 제공한다.
<그림 2> Sparse Retrieval의 예시
(인덱싱 단계) 어떤 단어가 어떤 문서에 들어있는지 인덱스로 구조화한다. (검색 단계) 검색어에서 단어를 뽑고 인덱스에서 해당 단어가 들어있는 문서를 찾아서 검색 결과로 제공한다.
Sparse Retrieval의 인덱싱과 검색 단계는 <그림 2>와 같습니다.
- <그림 2> 왼쪽의 인덱싱 단계에서는 모든 문서에서 단어를 뽑습니다. 각 단어가 어떤 문서에 들어 있는지 확인하고 구조화합니다. 구조화된 문서들을 인덱스라고 합니다.
- <그림 2> 오른쪽의 검색 단계에서는 사용자의 검색어에서 단어를 뽑습니다. 인덱스를 조회해서 일치하는 단어가 많은 문서를 사용자에게 검색 결과로 제공합니다.
검색에 사용될 수 있는 단어의 개수는 매우 많습니다. Sparse Retrieval은 수많은 단어 중에서도 대상 문서와 검색어에 있는 일부 단어만 고려해서 Lexical Match 점수를 계산합니다. 일부 단어만 고려하기 때문에 Sparse Retrieval이라는 이름이 붙었습니다.
BM25 알고리즘
BM25(Best Match)2 알고리즘은 Sparse Retrieval에 속하는 대표적인 방법론입니다. BM25는 검색어와 문서 사이의 Lexical Match 점수를 계산합니다. 검색어와 문서에 있는 단어가 겹치는 정도를 기준으로 검색 결과를 만듭니다. 아래 수식은 BM25 알고리즘을 표현한 것입니다.
\[\text{BM25}(D,Q) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})}\]위 수식의 \(f(q_i, D)\)와 \(\text{IDF}(q_i)\)는 각각 TF-IDF의 구성요소인 TF(Term Frequency)와 IDF(Inverse Document Frequency)입니다. \((k_1 + 1)\)과 \(k_1 \cdot (1 - b + b \cdot \frac{\\|D\\|}{\text{avgdl}})\) 부분은 Smoothing을 위한 항으로 결과 조정을 위해 추가된 부분입니다. 따라서 BM25는 TF-IDF를 기반으로 문서-검색어 간 관련도를 계산하는 알고리즘입니다.
Sparse Retrieval의 한계
다시 <그림 2>을 살펴봅시다. <그림 2>의 인덱스를 통해 문서6에 단어 “마라탕“과 “맛집“이 있는 것을 알 수 있습니다. 검색어 “판교 마라탕 맛집“과 문서6이 두 개의 단어에서 Lexical Match 됐습니다. <그림 2>와 같이 검색어를 문서에 등장할 법한 단어로 잘 정리해서 Lexical Match가 되면 원하는 검색 결과를 쉽게 얻을 수 있습니다.
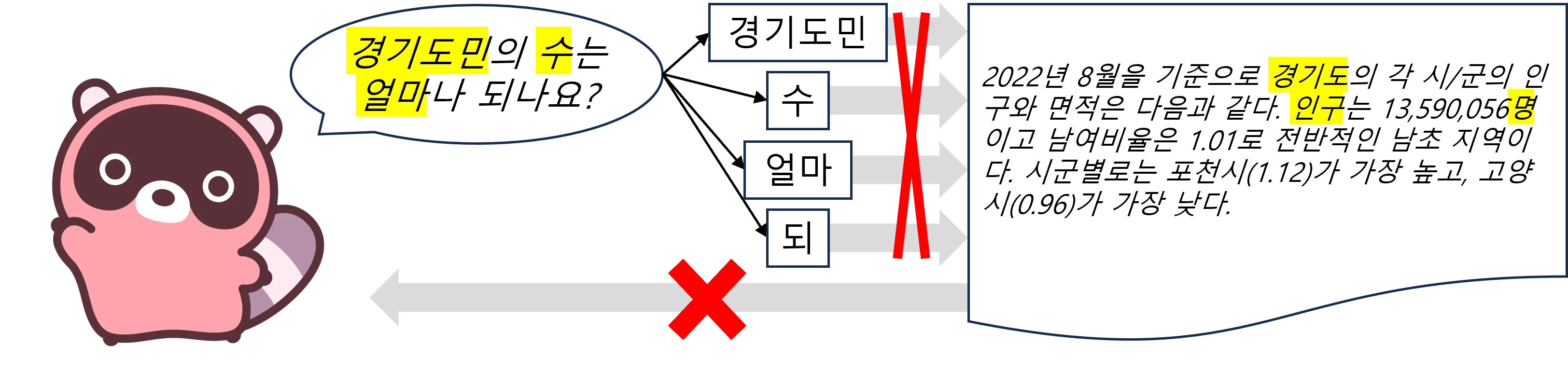 <그림 3> Lexical Mismatch 문제의 예시
검색어의 단어 “경기도민”, “수”, “얼마”, “되”가 문서의 단어 “경기도”, “인구”, “명”과 일치하지 않는다. 검색어와 문서의 의미가 비슷하나 Lexical Match에 실패해 문서가 검색 결과로 나오지 않는다.
<그림 3> Lexical Mismatch 문제의 예시
검색어의 단어 “경기도민”, “수”, “얼마”, “되”가 문서의 단어 “경기도”, “인구”, “명”과 일치하지 않는다. 검색어와 문서의 의미가 비슷하나 Lexical Match에 실패해 문서가 검색 결과로 나오지 않는다.
반면에 <그림 3>의 경우는 다릅니다. 검색어 “경기도민의 수는 얼마나 되나요?“와 문서 모두 경기도의 인구에 대한 내용입니다. 하지만 검색어와 문서에 든 단어가 일치하지 않아 문서가 검색 결과로 나오지 않습니다. 의미가 비슷하지만 Lexical Match 실패로 인해 검색되지 않는 문제를 Lexical Mismatch라고 합니다. Sparse Retrieval만 사용해서는 Lexical Mismatch 문제를 해결할 수 없습니다. Lexical Mismatch 문제는 Sparse Retrieval의 한계를 보여줍니다.
Dense Retrieval
Sparse Retrieval의 Lexical Mismatch 문제를 해결하기 위해 여러 방법이 연구되었습니다. 주로 문서와 검색어를 다른 방식으로 표현해서 Lexical Match를 유도하는 방법들입니다. 특히 문서에 등장할 법한 단어를 검색어에 추가하는 Query Term Expansion(RM33 등) 연구가 대표적입니다. Dense Retrieval도 문서와 검색어를 다르게 표현하려는 흐름에서 나타났습니다. Dense Retrieval은 의미를 담은 벡터 기반 검색으로 Lexical Mismatch 문제를 해결합니다. Lexical Mismatch 문제에서 자유로운 Dense Retrieval에 대해 알아보겠습니다.
Dense Retrieval은 문서/검색어의 의미를 고려하는 벡터 검색 패러다임입니다. 예전과 달리 언어 모델이 발전해서 문서/검색어를 의미 벡터로 표현할 수 있게 되며 Dense Retrieval이 등장할 수 있었습니다.
새로운 검색 파이프라인
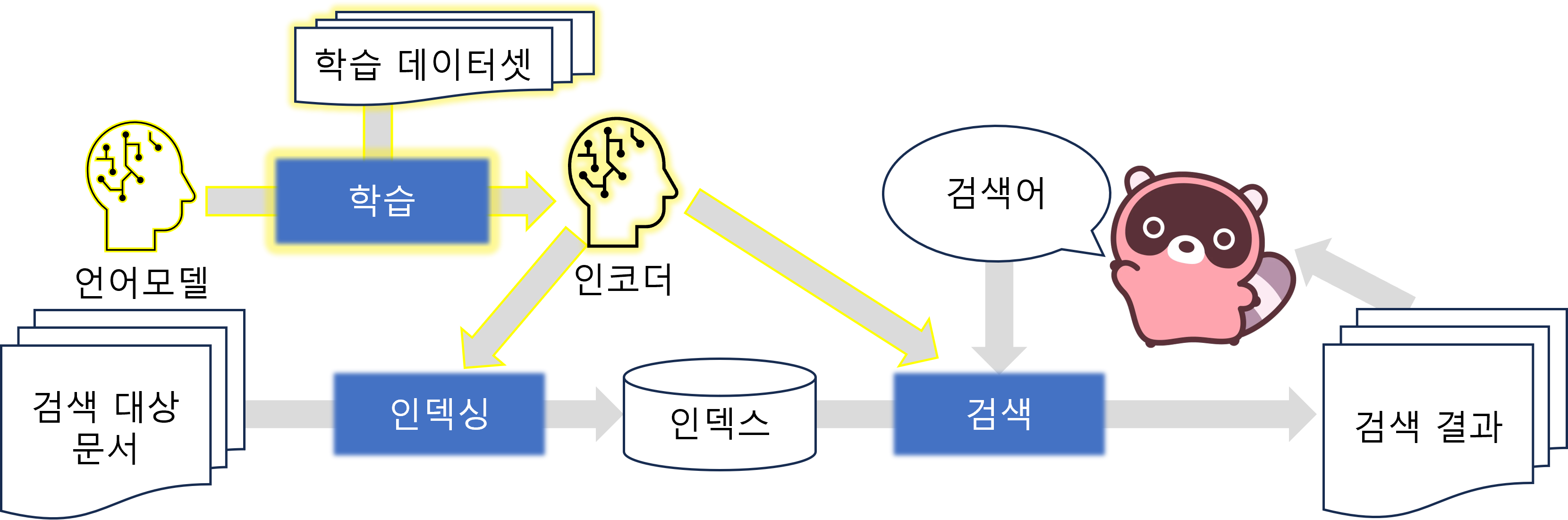 <그림 4> 학습 단계가 포함된 파이프라인
왼쪽 상단의 노란색으로 강조된 부분은 학습 단계를 나타낸다. 인덱싱을 하기 전에 언어모델을 데이터셋으로 학습해서 인코더를 만든다. 인덱싱 단계에서 문서 인코더는 문서를 벡터화한다. 검색 단계에서 검색어 인코더는 검색어를 벡터화한다.
<그림 4> 학습 단계가 포함된 파이프라인
왼쪽 상단의 노란색으로 강조된 부분은 학습 단계를 나타낸다. 인덱싱을 하기 전에 언어모델을 데이터셋으로 학습해서 인코더를 만든다. 인덱싱 단계에서 문서 인코더는 문서를 벡터화한다. 검색 단계에서 검색어 인코더는 검색어를 벡터화한다.
Dense Retrieval부터는 인코더(Encoders)의 개념이 나타납니다. 문서와 검색어를 의미 벡터로 표현하기 위한 문서 인코더와 검색어 인코더를 말합니다. 문서/검색어 인코더는 먼저 언어모델을 데이터셋으로 학습(Training)해서 만들 수 있습니다. 따라서 학습 단계가 파이프라인에 추가됩니다. <그림 4>의 좌측 상단에 노란색으로 강조한 부분이 추가된 학습 단계에 해당합니다. 인코더 학습 단계는 인덱싱과 검색 단계 이전에 진행되어야 합니다. 학습된 문서/검색어 인코더를 인덱싱과 검색 단계에서 사용하기 때문입니다.
인덱싱과 검색 단계
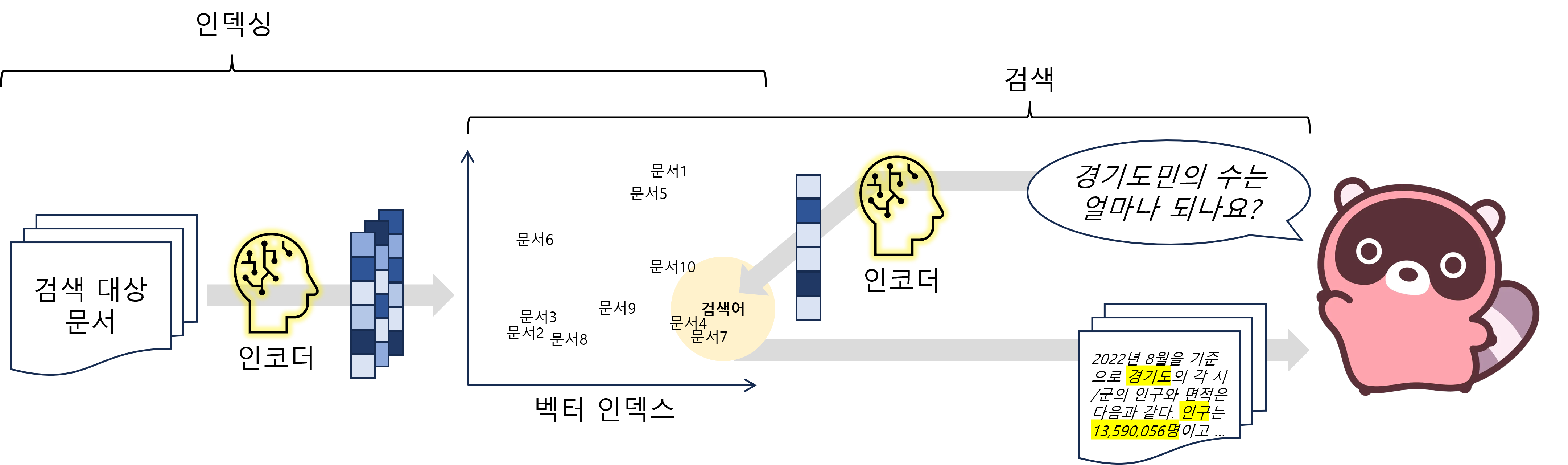 <그림 5> Dense Retrieval의 인덱싱과 검색 단계
(인덱싱 단계) 문서 인코더로 각 문서를 벡터로 만들고 벡터 인덱스로 구조화한다. (검색 단계) 검색어 인코더로 사용자의 검색어를 벡터로 만든다. 벡터 인덱스에서 검색어 벡터와 가까운 문서 벡터를 찾아서 검색 결과로 제공한다. 의미가 비슷한 문서를 검색 결과로 얻을 수 있다.
<그림 5> Dense Retrieval의 인덱싱과 검색 단계
(인덱싱 단계) 문서 인코더로 각 문서를 벡터로 만들고 벡터 인덱스로 구조화한다. (검색 단계) 검색어 인코더로 사용자의 검색어를 벡터로 만든다. 벡터 인덱스에서 검색어 벡터와 가까운 문서 벡터를 찾아서 검색 결과로 제공한다. 의미가 비슷한 문서를 검색 결과로 얻을 수 있다.
Dense Retrieval에서의 인덱싱과 검색 단계는 <그림 5>와 같습니다.
- <그림 5> 왼쪽의 인덱싱 단계에서는 문서 인코더로 모든 문서를 의미 벡터로 만듭니다. 그리고 각 벡터를 벡터 공간상에 놓습니다. 비슷한 벡터값을 가진 벡터끼리는 벡터 공간상에 가깝게 위치하게 됩니다. 문서 벡터가 놓인 벡터 공간을 벡터 인덱스라고 합니다.
- <그림 5> 오른쪽의 검색 단계에서는 검색어 인코더로 검색어를 의미 벡터로 만듭니다. 그리고 벡터 인덱스에서 검색어 벡터와 가까운 문서를 검색 결과로 제공합니다.
<그림 5>의 검색 결과로 나온 문서에 강조된 단어 “인구”, “13,590,056명“은 검색어 “경기도민의 수는 얼마나 되나요?” 에 없는 단어입니다. Dense Retrieval을 사용하면 <그림 5>처럼 문서와 검색어에 같은 단어가 없어도 의미가 비슷하면 문서가 검색 결과로 나올 수 있습니다. 앞서 Sparse Retrieval에서 보았던 Lexical Mismatch 문제가 해결됩니다.
<그림 5>의 인코더는 문서와 문장을 빽빽한 벡터(Dense Vector)로 인코딩합니다. 벡터의 각 차원은 다양한 의미를 나타내고 대부분 0이 아닌 값을 갖습니다. <그림 5>의 벡터가 각 차원에 다양한 색을 갖는 것이 Dense Vector의 특성을 보여줍니다. Dense Vector로 문서/검색어를 표현하고 검색에 사용하기에 Dense Retrieval이라고 하는 것입니다.
DPR
Dense Retrieval에서는 인코더의 구조와 학습 단계에 따라 다양한 방법론이 나타났습니다. 특히 DPR(Dense Passage Retrieval)4은 Dense Retrieval에 속하는 대표적인 방법론입니다. DPR 인코더는 BERT 기반이며 문서와 검색어 각각 전용 인코더를 두는 점이 특징입니다. 또한 In-Batch Negative Sampling과 Contrastive Learning을 통해 인코더를 학습하는 점도 특징입니다. DPR을 자세히 살펴보겠습니다.
DPR 인코더 학습 단계
DPR의 인코더 학습 단계를 간단히 살펴보겠습니다.
- 검색어와 관련 문서가 연결된 학습 데이터셋을 준비합니다.
- 문서/검색어 인코더(BERT)로 문서/검색어를 Dense Vector로 만듭니다.
- Contrastive Loss(Rank-IBN)를 최소화합니다.
- 검색어 벡터와 관련된 문서 벡터는 유사도가 커지도록 인코더의 가중치 값을 조정합니다.
- 검색어 벡터와 관련 없는 문서 벡터는 유사도가 작아지도록 인코더의 가중치 값을 조정합니다.
DPR 인코더 학습에는 Contrastive Loss의 한 종류인 Rank-IBN(In-Batch Negatives)을 사용합니다. Rank-IBN은 학습 Batch 안에서 Negative Sampling을 해서 Contrastive Learning을 합니다. Rank-IBN을 살펴보겠습니다.
\[L(q_i, p_{i}^+, p_{i,1:n}^-)= -\log{\frac { e^{\text{sim}(q_i,p_{i}^+)} } { e^{\text{sim}(q_i,p_{i}^+)} +\sum_{j=1}^n e^{\text{sim}(q_i,p_{i,j}^-)} } }\]위 수식은 검색어 \(q_i\)와 관련된 문서 \(p_{i}^+\)(Positive Sample)와 관련 없는 문서들 \(p_{i,1:n}^-\)(In-Batch Negative Samples) 간의 Contrastive Loss(Rank-IBN)를 나타냅니다. Contrastive Loss를 최소화하면 관련된 문서와의 유사도 \(\text{sim}(q_i,p_{i}^+)\)는 커지고 관련 없는 문서와의 유사도 \(\text{sim}(q_i,p_{i,j}^-)\)는 작아지도록 인코더의 가중치값이 조정됩니다.
Dense Retrieval의 한계
검색할 때는 핵심 단어에 집중할 필요가 있습니다. 하지만 Dense Retrieval에서는 핵심 단어보다는 문서/검색어의 전체적인 의미를 바탕으로 검색합니다. 검색어의 핵심 단어가 없어도 비슷한 의미의 문서가 검색 결과로 나올 수 있습니다.
예를 들어 “축구선수 리오넬 메시는 어떤 상 받았어?“를 검색하면 검색어의 핵심 단어는 단연코 “리오넬 메시“입니다. 하지만 핵심 단어가 나오는 “메시의 국가대표 경력” 문서뿐만 아니라 전체적인 의미가 비슷한 “네이마르가 바르사에서 이달의 선수상 첫 수상”, “축구선수 음바페 역대 수상 목록” 등의 문서도 검색 결과로 나오게 됩니다. 사용자의 의도에 맞지 않는 검색 결과입니다.
이렇게 핵심 단어에 집중해서 검색할 때는 오히려 Sparse Retrieval과 같이 직접적인 Lexical Match가 필요합니다.
Learned Sparse Retrieval
Sparse와 Dense Retrieval의 장단점을 다시 살펴보겠습니다.
- Sparse Retrieval은 Lexical Match에 유용하지만 Lexical Mismatch 문제가 있습니다.
- Dense Retrieval은 Lexical Mismatch 문제를 해결하지만 핵심 단어에 대한 Lexical Match를 하지 못합니다.
인코더가 Lexical Match를 학습하면 어떨까요? 문서/검색어의 의미를 반영하면서도 핵심 단어에 집중해서 검색할 수 있을 것입니다. 위 예시에서 본 “축구선수 리오넬 메시는 어떤 상 받았어?” 검색어에 대해서 “네이마르가 바르사에서 이달의 선수상 첫 수상”, “축구선수 음바페 역대 수상 목록” 문서를 찾는 문제를 막을 것입니다. 지금부터 다룰 Learned Sparse Retrieval은 학습할 수 있는 인코더로 의미 기반 Lexical Match를 하는 검색 패러다임입니다. Learned Sparse Retrieval에서 어떻게 인코더로 Lexical Match를 하는지 살펴보겠습니다.
인덱싱과 검색 단계
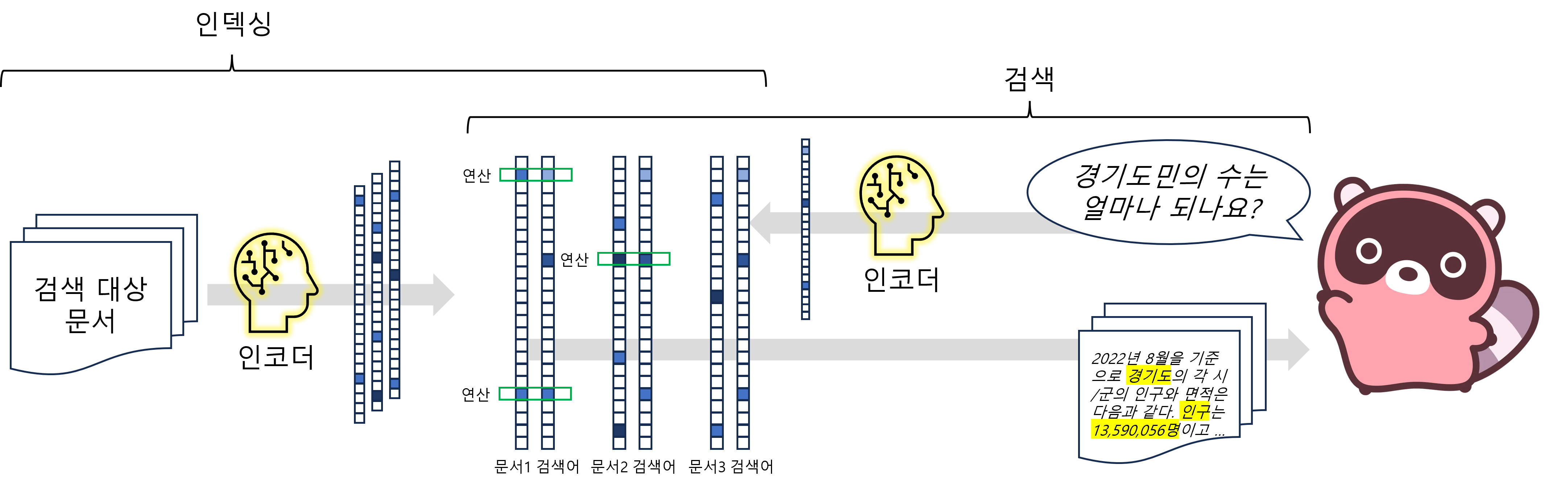 <그림 6> Learned Sparse Retrieval의 인덱싱과 검색 단계
문서 인코더와 검색어 인코더는 Sparse Vector를 만든다. Sparse Vector는 대부분이 0이고 일부분만 0이 아닌 값을 가진다. 벡터의 0인 부분은 흰색으로 표현했고 0이 아닌 부분은 푸른색으로 표현했다. 벡터 간 유사도 계산을 해서 검색어와 가까운 문서를 검색 결과로 제공한다. 녹색 사각형은 두 벡터가 모두 0이 아닌 부분을 표현하고 있다. 유사도 계산시 녹색 사각형 부분만 연산하면 된다는 특징이 있다.
<그림 6> Learned Sparse Retrieval의 인덱싱과 검색 단계
문서 인코더와 검색어 인코더는 Sparse Vector를 만든다. Sparse Vector는 대부분이 0이고 일부분만 0이 아닌 값을 가진다. 벡터의 0인 부분은 흰색으로 표현했고 0이 아닌 부분은 푸른색으로 표현했다. 벡터 간 유사도 계산을 해서 검색어와 가까운 문서를 검색 결과로 제공한다. 녹색 사각형은 두 벡터가 모두 0이 아닌 부분을 표현하고 있다. 유사도 계산시 녹색 사각형 부분만 연산하면 된다는 특징이 있다.
Learned Sparse Retrieval을 표현한 <그림 6>과 Dense Retrieval을 표현한 <그림 5>를 비교해 보면 인코더로 벡터를 만들고 유사도 계산을 하는 점이 비슷합니다. 반면에 가장 두드러지는 차이는 벡터의 형태에 있습니다. <그림 5>의 인코더는 Dense Vector를 만들지만 <그림 6>의 인코더는 희소한 벡터(Sparse Vector)를 만듭니다. <그림 6>의 벡터의 값이 0인 대부분은 흰색이고 0이 아닌 일부만 푸른색인 것이 Sparse Vector의 특성을 보여줍니다. 벡터가 Sparse하므로 유사도 계산 시 0이 아닌 부분에 대해서만 연산하면 됩니다. Sparse Vector에서 각 차원이 단어라고 생각하면 검색어와 단어가 많이 겹치는 문서에 높은 점수를 주게 되는 것입니다. Sparse Retrieval의 Lexical Match 방식과 비슷합니다. 학습을 통한 Sparse Retrieval이라 Learned Sparse Retrieval 패러다임입니다.
SPLADE
Learned Sparse Retrieval에서도 인코더의 구조와 학습 단계에 따라 다양한 방법론이 나타났습니다. 특히 Sparse Vector를 만드는 방식과 벡터의 각 차원이 의미하는 바가 무엇인지가 중요합니다. SPLADE(SParse Lexical AnD Expansion model)5는 Learned Sparse Retrieval에 속하는 대표적인 방법론입니다. SPLADE는 Log Saturation과 FLOPS Regularization을 통해 Sparse Vector를 만든다는 점과 벡터의 각 차원이 Vocabulary 단어를 의미한다는 점이 주요 특징입니다. SPLADE를 자세히 살펴보겠습니다.
SPLADE 인코더 구조
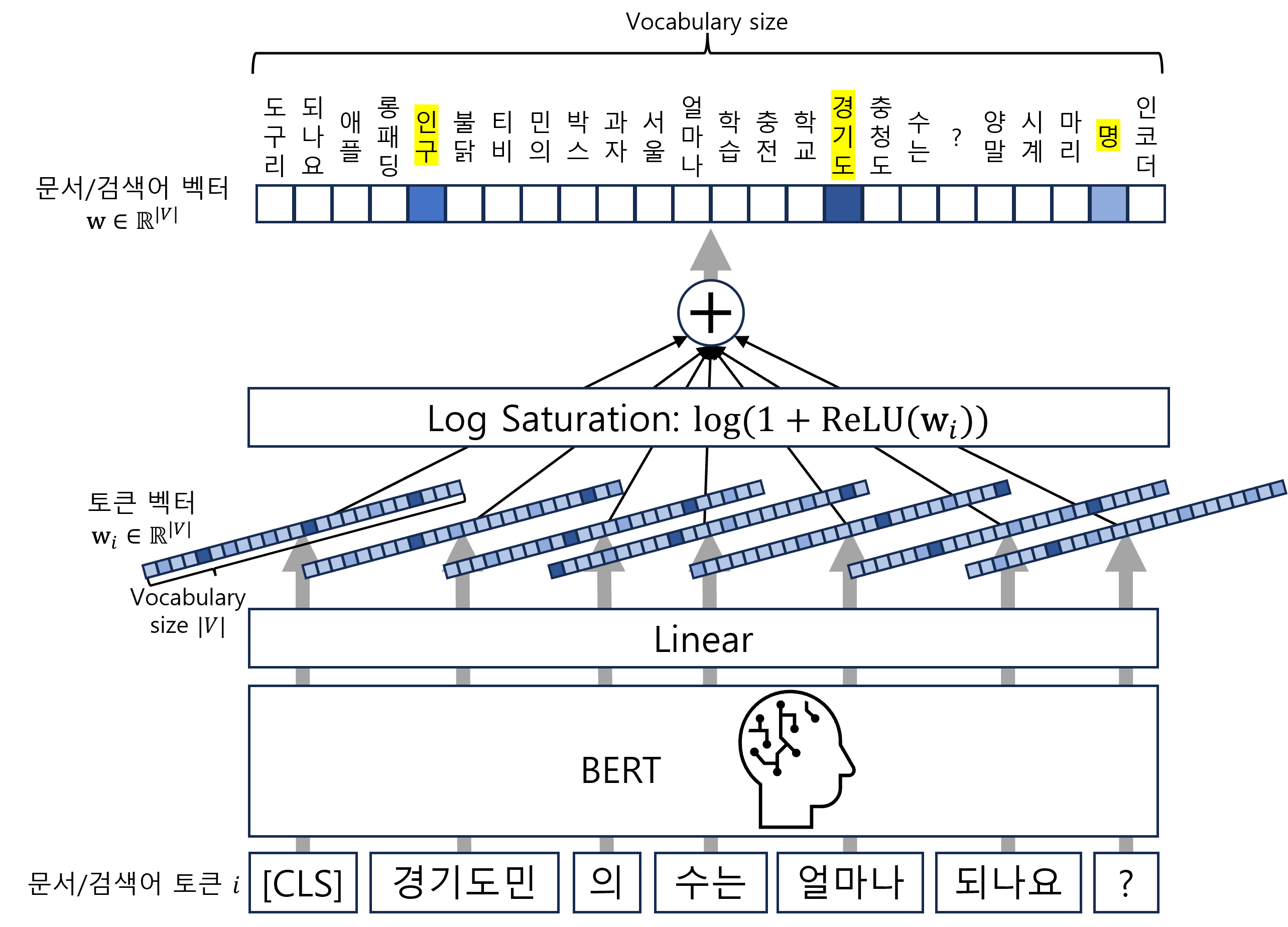 <그림 7> SPLADE 인코더 예시
BERT와 Linear는 문서/검색어 토큰의 Vocabulary Size 차원 벡터를 만든다. Log Saturation은 각 토큰 벡터를 Sparse 하게 바꾼다. 모든 토큰에 대해 Log Saturated 벡터를 더한 문서/검색어 벡터는 Sparse Vector가 된다. 벡터의 각 차원은 Vocabulary 단어의 중요도를 나타낸다.
<그림 7> SPLADE 인코더 예시
BERT와 Linear는 문서/검색어 토큰의 Vocabulary Size 차원 벡터를 만든다. Log Saturation은 각 토큰 벡터를 Sparse 하게 바꾼다. 모든 토큰에 대해 Log Saturated 벡터를 더한 문서/검색어 벡터는 Sparse Vector가 된다. 벡터의 각 차원은 Vocabulary 단어의 중요도를 나타낸다.
<그림 7>를 통해 SPLADE 인코더의 구조를 알아보겠습니다. 순서는 그림의 아래에서 위 방향으로 진행합니다. 편의상 문서와 검색어를 통칭해서 “문서”로, 문서의 단어는 “토큰”으로, Vocabulary의 단어는 “단어”로 표현하겠습니다. 또한 \(|V|\)는 Vocabulary Size를 의미합니다.
- 문서를 언어 모델(BERT)로 인코딩해서 각 토큰의 Hidden State(\(h_i\))를 만듭니다.
- Linear 레이어가 각 토큰의 Hidden State를 토큰 벡터(\(\textbf{w}_i\in\mathbb{R}^{\\|V\\|}\))로 만듭니다.
- 아래 수식은 토큰의 Hidden State \(h_i\)에 Linear 레이어를 적용해서 토큰-단어(토큰 \(i\)-단어 \(j\)) 중요도 \(w_{ij}\)를 정의합니다. Linear 레이어는 \(\text{transform}\)과 BERT Input Embedding \(E_j\)로 표현된 두 번의 Linear 연산으로 구성됩니다. 그리고 토큰 벡터 \(\textbf{w}_i\)를 모든 단어에 대한 토큰-단어 중요도 \(w_{ij}\)를 쌓은 것으로 정의합니다.
- 각 토큰 벡터에 Log Saturation을 하고 모두 더해서 문서 벡터(\(\textbf{w}\in\mathbb{R}^{\\|V\\|}\))를 만듭니다.
- 아래 수식은 Log-saturated 토큰 벡터 \(\textbf{w}_i\)의 합으로 문서 벡터 \(\textbf{w}\)를 정의합니다. Log Saturation은 수식의 \(\log(1+\text{ReLU}())\)를 말합니다.
SPLADE 인코더에서 중요한 역할을 하는 Log Saturation이 어떤 의미를 갖는지 살펴보겠습니다.
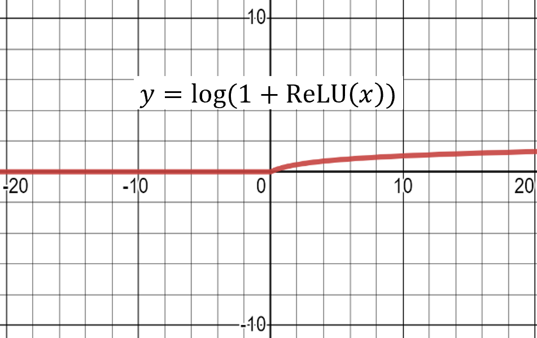 <그림 8> Log Saturation
Log Saturation은 0보다 작은 입력값을 0으로 만들고(Sparsifying) 0보다 큰 입력에는 로그를 취해 영향력을 줄인다(Smoothing).
<그림 8> Log Saturation
Log Saturation은 0보다 작은 입력값을 0으로 만들고(Sparsifying) 0보다 큰 입력에는 로그를 취해 영향력을 줄인다(Smoothing).
<그림 8>을 보면 Log Saturation은 0보다 작은 입력값은 0으로 만들고 0보다 큰 입력값에는 로그를 취하는 것을 알 수 있습니다. 음의 중요도를 모두 0으로 만들어 Sparsity를 높이며 큰 중요도의 Linear 한 영향력을 로그로 줄입니다(Logarithmic Smoothing).
Log-saturated 토큰 벡터의 합으로 정의되는 문서 벡터는 Sparse 하며 Vocabulary Size의 차원을 가지게 됩니다. 문서와 검색어는 적은 수의 단어에 대한 중요도로 표현되며 덕분에 핵심 단어에 집중할 수 있습니다. <그림 7>에서 검색어 “경기도민의 수는 얼마나 되나요?“의 벡터가 핵심 단어 “인구”, “경기도”, “명“에 집중된 것을 확인할 수 있습니다.
SPLADE 인코더 학습 단계
SPLADE의 인코더 학습 단계를 살펴보겠습니다.
- 검색어와 관련 문서가 연결된 학습 데이터셋을 준비합니다.
- 문서/검색어 인코더로 문서/검색어를 Sparse Vector로 만듭니다.
- Contrastive Loss(Rank-IBN)를 최소화합니다.
- 동시에 벡터의 FLOPS Regularizer를 최소화합니다.
아래 수식은 FLOPS(FLoating-point-OPerationS) Regularizer6를 표현하고 있습니다.
\[\ell_{\text{FLOPS}}= \sum_{j\in V} \bar{a}_j^2= \sum_{j\in V} \left( \frac{1}{N} \sum_{i=1}^N w_j^{(d_i)} \right)^2= \frac{1}{N^2}\sum_{x=1}^N\sum_{y=1}^N{\langle|\textbf{w}^{(d_x)}|,|\textbf{w}^{(d_y)}|\rangle}\]\(\ell_{\text{FLOPS}}\)를 최소화 하는 것은 모든 문서 쌍/검색어 쌍 \((d_x, d_y)\) 벡터 절댓값의 Dot Product 값인 \(\langle\vert\textbf{w}^{(d_x)}\vert,\vert\textbf{w}^{(d_y)}\vert\rangle\)를 0에 가깝게 하는 것입니다. Dot Product를 0에 가깝게 하는 것은 벡터 간에 Orthogonal 하게 하고 벡터가 Sparse 하게 만듭니다. 따라서 FLOPS Regularizer는 벡터 간의 직교성(Orthogonality)과 벡터의 희소성(Sparsity)을 높입니다. Orthogonality가 높은 것은 두 벡터가 공통으로 0이 아닌 차원의 수가 적다는 의미입니다. 따라서 유사도 연산에 필요한 Floating-point Operations의 수를 규제합니다. Floating-point Operations의 수를 규제하기에 이름이 FLOPS Regularizer입니다.
Sparsity & Orthogonality
SPLADE는 인코더 구조에 Log Saturation과 학습 단계에 FLOPS Regularizer를 사용해서 Sparse & Orthogonal 문서/검색어 벡터를 만듭니다. Sparsity 덕에 각 문서/검색어는 적은 수의 단어에 대한 중요도 벡터로 표현되며 Orthogonality 덕에 각 문서/검색어를 표현하는 단어가 덜 겹칩니다. SPLADE는 Sparsity와 Orthogonality 덕에 유사도 계산 시 연산량이 적고 핵심 단어에 집중합니다. 따라서 논문5의 실험 결과를 보면 SPLADE가 기존 모델들보다 효율과 검색 성능 면에서 뛰어납니다.
앞선 Dense Retrieval의 한계점으로 제시된 메시 예시를 다시 생각해 봅시다. SPLADE 인코더를 사용하면 “축구선수 리오넬 메시는 어떤 상 받았어?” 벡터는 “메시”, “아르헨티나”, “발롱도르” 등 핵심 단어에 집중될 것입니다. 따라서 “네이마르“나 “음바페“에 관련된 문서 대신 “메시의 국가대표 경력” 문서를 검색 결과로 찾을 것입니다.
SPLADE 결과
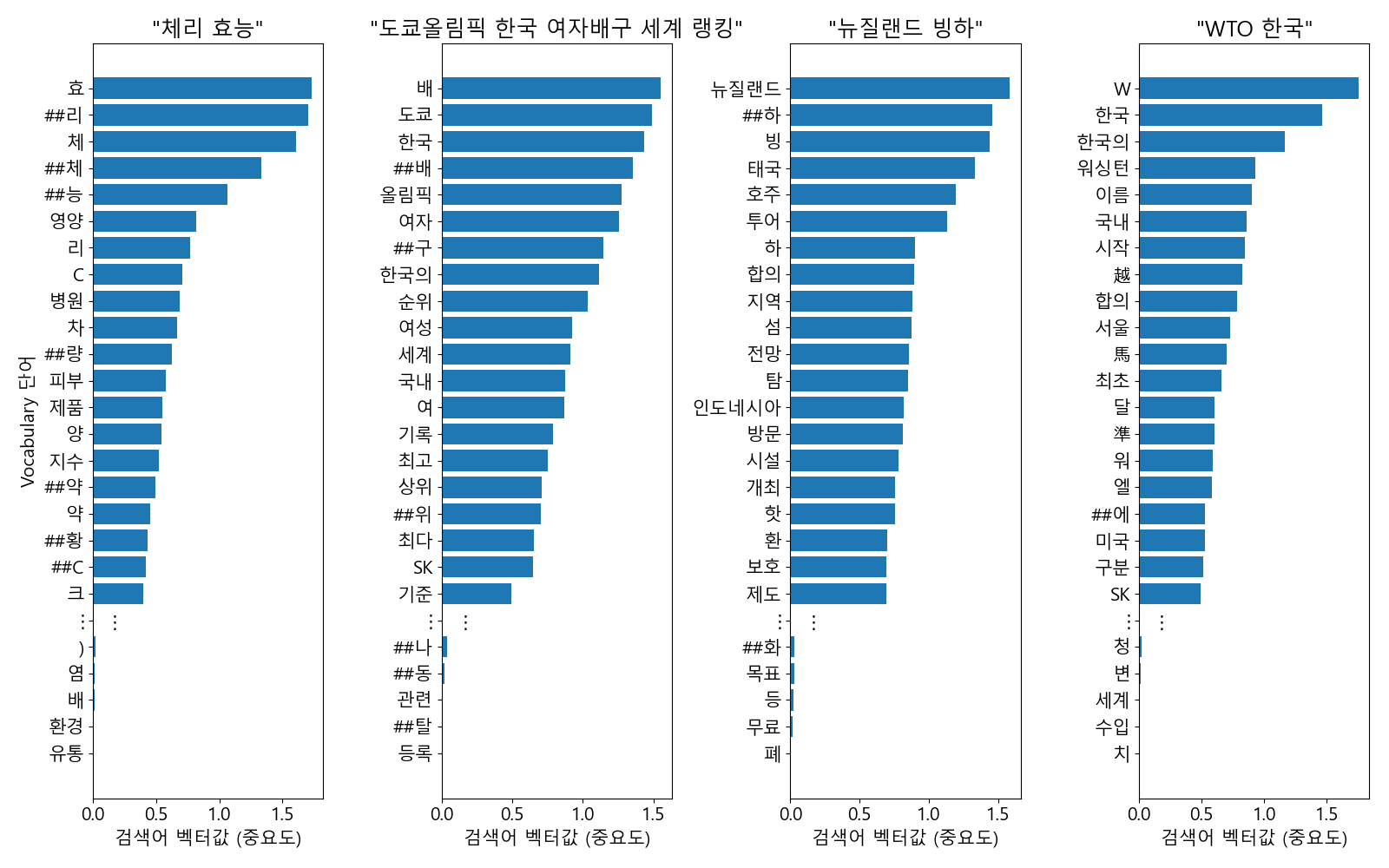 <그림 9> SPLADE 벡터 예시
SPLADE로 생성한 네 개의 검색어에 대한 벡터 예시이다. x축(Vocabulary 단어)을 y축(벡터값)의 내림차순으로 정렬했다. 검색어 벡터에서 0이 아닌 부분은 수만 개의 단어 중 100개도 되지 않을 정도로 Sparse 하다. 검색어 “체리 효능” 벡터의 단어 “영양”의 경우처럼 검색어에 없는 단어에도 높은 중요도가 나타난다. 검색어 “도쿄올림픽 한국 여자배구 세계 랭킹” 벡터의 단어 “랭킹”의 경우처럼 검색어에 있는 단어인데도 벡터값이 0인 경우가 있다.
<그림 9> SPLADE 벡터 예시
SPLADE로 생성한 네 개의 검색어에 대한 벡터 예시이다. x축(Vocabulary 단어)을 y축(벡터값)의 내림차순으로 정렬했다. 검색어 벡터에서 0이 아닌 부분은 수만 개의 단어 중 100개도 되지 않을 정도로 Sparse 하다. 검색어 “체리 효능” 벡터의 단어 “영양”의 경우처럼 검색어에 없는 단어에도 높은 중요도가 나타난다. 검색어 “도쿄올림픽 한국 여자배구 세계 랭킹” 벡터의 단어 “랭킹”의 경우처럼 검색어에 있는 단어인데도 벡터값이 0인 경우가 있다.
실제 예시를 통해서도 SPLADE의 특징을 확인할 수 있습니다. <그림 9>는 한국어 데이터로 SPLADE 인코더를 학습한 후 네 개의 검색어에 대해 벡터를 만들어 본 결과입니다. 수만 차원의 벡터에서 100개도 되지 않는 적은 차원에서만 0이 아닌 값이 나왔습니다. Sparse Vector가 만들어졌습니다. 검색어 “체리 효능“에 없는 단어 “영양“이 상위권에 생성되었고 검색어 “도쿄올림픽 한국 여자배구 세계 랭킹“에 있는 단어 “랭킹“이 사라지고 “순위“가 생겨난 것을 확인할 수 있습니다. 핵심 단어를 찾는 것이 Query Term Expansion과 Selection의 효과도 갖고 있음을 보여줍니다. 각 문서/검색어가 어떤 단어들의 벡터로 표현됐는지 알 수 있다 보니 각 단어가 검색 결과에 미치는 영향을 쉽게 확인할 수도 있습니다. 또한 중요도 0.5 이상의 단어만 쓰는 등 Thresholding을 하면 사용하는 단어의 수를 조절할 수 있습니다.
SPLADE vs. BM25, DPR
SPLADE는 앞서 보았던 방법론들과 비교하여 다음과 같은 장점이 있습니다.
- BM25와 달리 SPLADE는 학습을 통해 개선할 수 있으며 문서/검색어의 의미를 고려합니다.
- DPR와 달리 SPLADE는 핵심 단어에 대한 Lexical Match를 할 수 있으며 각 단어가 검색 결과에 미치는 영향을 쉽게 확인할 수 있습니다.
- Expansion을 통해 기존 문서/검색어에는 없는 새로운 관련 단어를 찾아내고 Selection을 통해 중요한 단어만 골라서 검색을 더 효과적으로 만듭니다.
마치며
Sparse Retrieval부터 Learned Sparse Retrieval까지 검색 패러다임의 흐름을 살펴보았습니다. 지금까지 살펴본 내용을 요약해 보겠습니다.
- Sparse Retrieval은 Lexical Match 기반 검색 패러다임입니다. Lexical Mismatch 문제라는 한계점이 있습니다.
- Dense Retrieval은 문서/검색어의 의미를 고려하는 벡터 검색 패러다임입니다. 의미를 반영하기에 Lexical Mismatch 문제를 해결하지만 핵심 단어에 집중하지 못한다는 한계점이 있습니다.
- Learned Sparse Retrieval은 학습할 수 있는 인코더로 의미 기반 Lexical Match를 하는 검색 패러다임입니다. Sparsity 덕에 연산량이 적고 핵심 단어에 집중합니다.
최신의 SPLADE에 대해서 살펴보고 싶다면 SPLADE Github과 아래 표를 참고하기를 바랍니다. SPLADE는 모델의 세팅을 바꾸어가며 연구가 계속 진행되고 있는 것으로 보입니다. 다음 표는 SPLADE의 변화를 간략하게 정리한 것입니다.
| 방법론 | 학습 | Regularizer | 문서/검색어 인코더 | Ranking Loss | Negative Sample Mining |
|---|---|---|---|---|---|
| SPLADE5 | Ranking | FLOPS | Siamese | Rank-IBN | BM25, In-batch |
| SPLADE v27 | Ranking, Distillation | FLOPS | Siamese | Rank-IBN | BM25, In-batch |
| SPLADE++8 | Ranking, Distillation | FLOPS | Siamese | InfoNCE, MarginMSE | BM25, Self-mining, Ensemble-mining |
| Efficient SPLADE9 | Middle-training, Ranking, Distillation | FLOPS, L1 | Separate | MarginMSE | BM25, Self-mining, Ensemble-mining |
앞으로 어떤 패러다임이 나타나서 검색의 새로운 흐름을 만들지 기대됩니다.
References
-
Denoising Dense Representations with Symbols (Nogueira, 2023) ↩
-
OKapi BM25 (Wikipedia) ↩
-
UMass at TREC 2004: Novelty and HARD (Abdul-Jaleel, et al., 2004) ↩
-
Dense Passage Retrieval for Open-Domain Question Answering (Karpukhin and Oğuz, et al., 2020) ↩
-
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking (Formal, et al., 2021) ↩ ↩2 ↩3
-
Minimizing FLOPs to Learn Efficient Sparse Representations (Paria, et al., 2020) ↩
-
SPLADE v2: Sparse lexical and expansion model for information retrieval (Formal, et al., 2021) ↩
-
From distillation to hard negative sampling: Making sparse neural ir models more effective (Formal, et al., 2022) ↩
-
An efficiency study for splade models (Lassance, et al., 2022) ↩
