
작성자
- 김홍태(VARCO 서비스실)
- AI/ML 기술을 활용해서 도움이 되는 서비스를 만드는데 관심이 많습니다.
이런 분이 읽으면 좋습니다!
- LLM을 활용하여 다양한 분야에 필요한 모델을 생성하는 과정이 궁금하신 분
이 글로 알 수 있는 내용
- VARCO LLM을 활용하여 다양한 데이터에 추가 학습없이 적용가능한 추천 모델을 생성한 과정
들어가며
안녕하세요, 저는 VARCO서비스실 김홍태 라고 합니다. 오늘은 NC Research가 개발한 거대언어모델(LLM)인 VARCO LLM을 활용하여 연구하였던 생성형 추천 시스템에 대한 소개를 드리고자 합니다. 저는 글 제목에서 사용한 각각의 용어의 의미를 하나씩 풀어가며 설명드리겠습니다.
생성형 모델을 활용한 추천 시스템
해당 주제에 대해 생소하신 분들도 계실텐데요, 최근 텍스트와 이미지 등 다양한 정보에 대해 방대한 지식을 활용하여 원하는 정보를 다양한 모달리티로 생성할 수 있는 거대 모델이 대두됨에 따라, 추천 도메인에서도 거대 모델을 활용하여 기존 추천 모델 방식의 한계를 뛰어넘기 위한 시도들이 이루어지고 있습니다.
생성형 추천 시스템이란 글자 그대로 LLM과 같은 생성형 모델을 활용하여 입력으로 기존 유저가 구매 또는 소비하였던 아이템의 정보(ex. 아이템 제목, 아이템 설명, 아이템 이미지 등)를 모델에 넣었을 때 해당 유저가 구매/소비할 것으로 예상되는 아이템 정보를 출력으로 생성하는 추천 시스템입니다. 아래 [그림 1]의 P5와 M6-Rec이 대표적인 생성형 추천 시스템입니다.
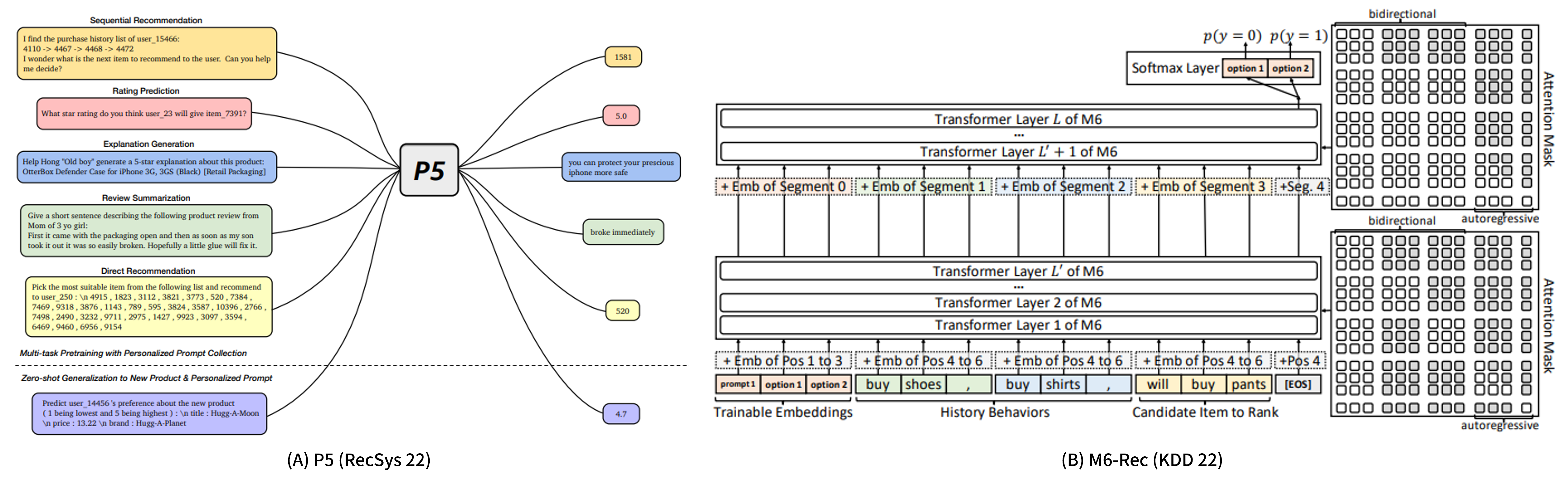 [그림 1. (A) P5 모델, (B) M6-Rec 모델]
[그림 1. (A) P5 모델, (B) M6-Rec 모델]
그런데 문득 한 가지 의문이 듭니다.
왜 기존 추천 모델보다 무겁고 안정된 생성 결과가 보장되지 않는 생성형 모델을 활용해서 아이템을 추천을 할까요?
현재 LLM을 활용한 추천 모델은 환각 문제, 높은 리소스 사용량, 느린 추론 속도 등으로 인하여 아직까지 실제 서비스에 활용되는 사례는 손에 꼽습니다. 대표적인 실 서비스 사례로 Alibaba가 자사 전자 상거래 플랫폼의 추천 모델로 사용하고 있다는 M6-Rec 이 있습니다. (해당 모델에 대한 소개는 해당 논문을 참조해주세요.) 이렇게 실 사례가 적은 이유는 생성형 모델로 추천을 수행하는 경우에 기존 추천 모델보다 무겁고 안정된 추천 결과가 생성되지 않기 때문입니다.
하지만, Google Research에서 RecSys ‘23에서 발표한 연구에서도 소개하고 있듯이, near cold-start 환경에서 LLM을 활용한 추천 시스템은 기존 아이템 기반, CF(Collaborative Filtering) 기반, 그리고 Neural 모델 기반 추천 시스템과 비교해도 성능이 뒤쳐지지 않는다고 합니다. 여기서 near cold-start 환경이란 신규 도메인 또는 서비스에서 기존 유저에 대한 학습 데이터를 쉽게 확보하기 힘든 환경을 의미합니다. 즉, LLM을 활용한 추천 모델은 비록 무겁고 안정된 추천 결과가 생성되지 않지만, 학습 데이터 확보, 개인정보 활용 이슈 등으로 추천에서 많이 문제가 되는 cold-start problem 을 해결하기 위한 좋은 후보가 될 수 있을 것 같습니다! 이런 관점에서 저희 NC에서도 생성형 추천 시스템 연구를 시작하게 되었습니다.
LLM을 활용한 추천 모델 연구는 아래 그림과 같이 (A) 분류 vs 생성, (B) 모델링 방식, (C) 학습 방법 세 가지 관점에 따라 구분될 수 있습니다. 먼저, LLM을 활용한 추천 모델이라고 해서 모두 생성형 모델은 아닙니다.
그 예시로 [그림 2]의 왼쪽 트리의 Discriminative LLM4Rec은 쉽게 설명하면, 입력 프롬프트에 유저 히스토리와 후보 아이템을 넣은 후에 “이러한 구매 히스토리를 가진 유저가 후보 아이템을 구매할까?”에 대한 확률을 생성하는 모델입니다. 상식적으로 생각해봐도 이러한 모델은 추천 아이템을 의미하는 의미있는 텍스트 토큰을 생성하는 것보다 쉽습니다. 다만 이러한 모델의 문제는 100개의 후보 아이템이 존재한다면, 추론도 100번을 수행해야 한다는 점입니다. 이는 listwise하게 후보 아이템을 넣더라도 크게 다르지 않습니다. 하나의 프롬프트에 100개의 아이템을 모두 넣는다는 것은 비효율적이기 때문입니다.
그렇기 때문에 Retriever를 활용하여 유저 히스토리와 관련성이 높은 후보 아이템을 추리고, 좁힌 후보 아이템을 프롬프트에 넣어서 이 중 가장 적합한 아이템을 추천하는 방식도 존재하긴 합니다. 하지만 이러한 모델은 추천 사유나 추천이 어떤 요소를 중점적으로 보고 추천해줬는지에 대한 정보를 주지 못합니다.
[그림 2]의 가운데 그림을 보시면, 크게 LLM Embedding + RS, LLM tokens + RS, LLM as RS로 나눠진 것을 보실 수 있을텐데요. 첫 번째 케이스는 LLM을 Embedding 모델로써 활용하고 임베딩 벡터를 기존 추천 모델의 입력으로 활용하는 방식입니다. 이는 굳이 LLM이 아니더라도 기존 추천 모델 설계시 많이 활용하던 방식입니다. 두 번째는 유저 정보와 아이템 정보를 LLM의 입력으로 넣었을 때 나온 답변 텍스트를 또 다른 RS의 입력으로 주는 방식입니다. 위와 마찬가지로 이 또한 새로운 도메인에서는 새로운 RS를 학습해야 하는 형태가 되겠군요.
마지막으로 LLM as RS의 경우에는 LLM에 유저와 아이템 정보를 입력으로 줬을 때 우리가 원하는 추천 상품 또는 추천 상품에 대한 설명을 출력으로 내놓는, 말그대로 LLM 자체를 추천 모델처럼 활용하겠다는 것이고 우리가 하고자 하는 것과 부합합니다. LLM 자체가 지닌 다양한 도메인에 대한 지식을 추천 명령문을 잘따라서 추천 사유에 대한 추론, 추천 상품에 대한 제안을 출력하도록 학습하면 될테니까요.
그렇다면 마지막은 자연스럽습니다. 기존 LLM을 추천 도메인에 특화되게 추천 관련 지시문이나 질문을 기존 지식을 활용하여 연역적/귀납적 추론을 수행하여 아이템을 추천하도록 Instruction Following 능력을 향상시켜 주면 됩니다.
결과적으로 저희가 이 글에서 소개드리는 연구는 위의 (A) 관점에서 생성, (B) 관점은 LLM as RS, 그리고 마지막으로 (C) 관점으로는 Instruction tuning 방식으로 분류된다는 것을 염두에 두고 읽으시면 좋을 것 같습니다.
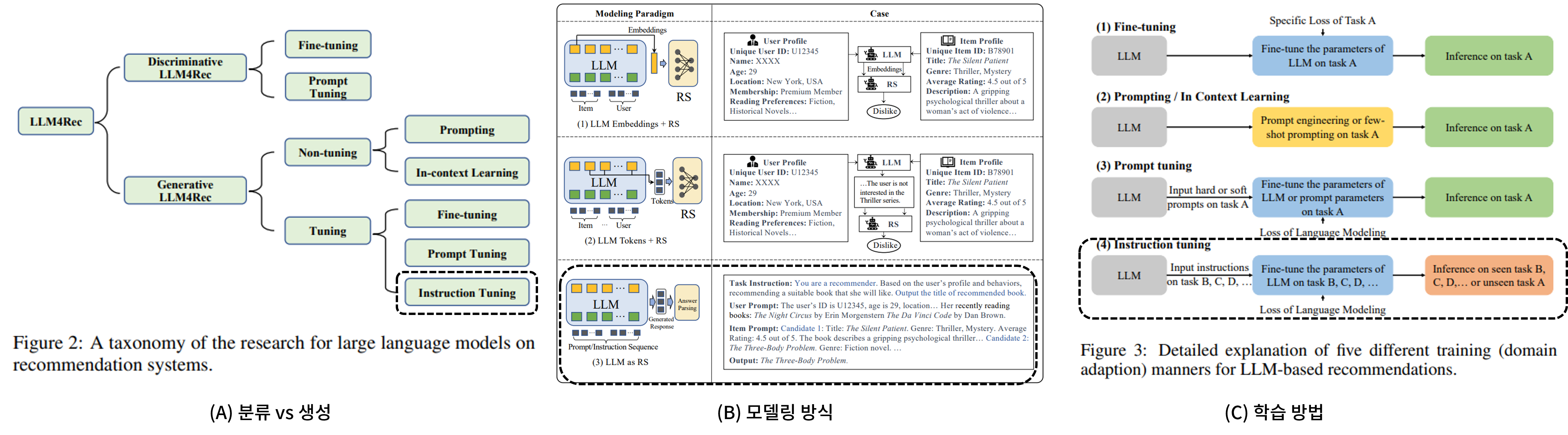 [그림 2. LLM을 활용한 추천 모델의 분류 체계]
[그림 2. LLM을 활용한 추천 모델의 분류 체계]
Cross-domain Zero-shot 추천 시스템
이번 단락에서는 제목에서 등장하는 주요한 용어인 Cross-domain Zero-shot에 대해서 설명드리겠습니다. 이해를 돕기 위해서 아래 [그림 3]을 참고하시어 글을 읽으시면 좋을 것 같습니다. 일반적인 추천 시스템은 인하우스 속성을 지닙니다. 이는 도메인, 서비스 종속성, 유저 데이터 보안 이슈 등 다양한 이유로 인해 추천 모델이 다른 도메인으로 확장되기 어렵다는 것을 의미합니다. 아래 그림의 왼쪽에서 볼 수 있듯이 현재 추천 시스템은 웹소설, 전자상거래, 뉴스 등의 각 도메인마다 고유한 유저-아이템 상호작용을 가지고 있고, 해당 정보는 회사의 소중한 데이터 자산으로써 공유하지 않기 때문에 분야를 넘나들며 추천할 수 있는 global 모델 구축이 매우 어렵습니다. 예를 들어, 웹툰의 굿즈 판매를 촉진하기 위해 전자상거래 업체에서는 웹툰 업체로부터 정보를 공유받거나, 언론사에서는 웹툰 작가에 관한 소식 등을 맞춤으로 제공하기 위한 방법 등을 고민할 수 있는데, 이러한 데이터는 각 회사에서 공유받을 수 없어 global 모델을 구축하는 것이 어렵습니다. 즉, 각 회사는 하나의 도메인 정보만을 활용하여 추천 시스템을 개발해야 하며, 합니다. 이런 경우 새로운 도메인으로 진입이 어렵다는 단점이 있습니다. 이런 단점을 극복하고자 최근에는 도메인을 넘나들며 추천할 수 있는 Cross-domain 추천 시스템이 많이 연구되고 있습니다.
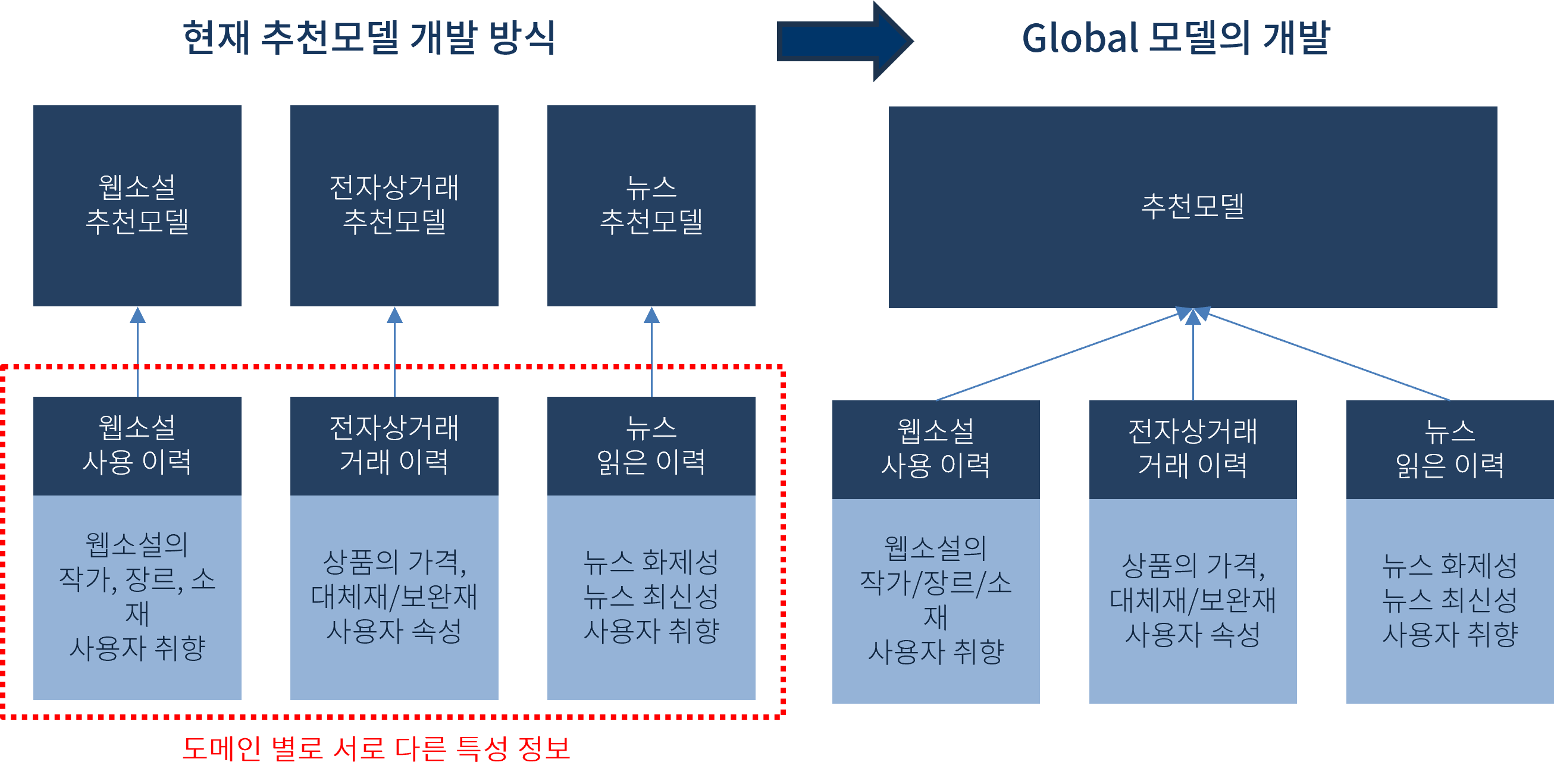 [그림 3. 기존 추천모델 개발 방식과 LLM을 활용한 글로벌 모델 개발 방식]
[그림 3. 기존 추천모델 개발 방식과 LLM을 활용한 글로벌 모델 개발 방식]
그림 4는 LLM이 Cross-domain 추천에서의 어려움을 극복할 수 있다는 가능성을 보여주고 있습니다. 해당 그림에서 사용자는 게임과 영화라는 두 개의 서로 다른 도메인이 섞인 질문을 하고 있습니다. 구체적으로, 사용자는 레드데드리뎀션 2 게임에 등장하는 아서 모건이라는 캐릭터의 특성과 유사한 캐릭터가 등장하는 영화를 추천하고 있는데, Llama 2는 해당 캐릭터의 특성과 서사를 정확하게 파악하여 비슷한 플롯이나 주제를 다루는 영화를 설득력 있게 추천해주고 있습니다. 이 때 주목할만한 점은 저희가 아이템 간의 관계를 추가로 학습하거나 벡터화하지 않고 자연어 지시문만으로 좋은 추천 결과를 얻었다는 점입니다. 이는 LLM이 다양한 도메인에 대한 정보를 배경 지식으로 학습하고 있기 때문으로 여겨지며, 이러한 LLM의 특성으로 인해 신규 도메인과 서비스에 추천을 적용해야 하는 cold-start 환경에서 추가적인 학습 없이 설득력 있는 추천이 가능할 것으로 생각되었습니다.
 [그림 4. Llama2 13B 모델을 활용한 게임+영화 도메인 추천]
[그림 4. Llama2 13B 모델을 활용한 게임+영화 도메인 추천]
본격적으로 생성형 추천 시스템을 개발해보자
생성형 추천 시스템을 개발 과정기를 설명드리기 위해서 크게 다음과 같은 섹션으로 나눠서 설명드릴 예정입니다.
먼저 추천 분야는 안타깝게도 기존에 존재하는 다양한 Instruction dataset으로는 제대로 학습하기 어렵습니다. 따라서 직접 데이터를 생성하는 작업부터 진행을 했는데요. 첫 번째로 Instruction tuning을 위한 학습 데이터 준비에서는 추천 모델 학습을 위한 [system message, instruction, response]를 어떻게 구성하고 생성하였는지 설명드릴 예정입니다.
두 번째로 모델 파인튜닝: Instruction tuning에서는 생성된 프롬프트, 답변 데이터를 활용하여 어떤 방법론,프레임워크를 활용하여 학습하였는지, 그리고 학습된 모델의 결과를 공유드릴 예정입니다.
세 번째로 모델 개선 시도 1, 모델 개선 시도 2에서는 학습된 모델이 더 인간이 선호할 수 있는 답변을 생성하기 위해 인간이 태깅한 선호 답변 데이터를 Direct Preference Optimization을 활용한 추가 개선 시도와 Unseen 도메인 데이터에서도 실제 존재하는 연관 추천 상품을 잘 추천하기 위한 Retriever를 활용한 아이템 텍스트 chunk와 생성형 추천 모델의 답변의 연관성을 계산하여 만든 추천 결과를 공유드리고자 합니다.
Instruction tuning을 위한 학습 데이터 준비
본 연구에서는 VARCO LLM을 활용한 추천 모델이 능동적/수동적 상황의 추천 시나리오에 모두 동작하도록 학습 데이터를 구성했습니다. 저희는 능동적 상황의 경우 유저가 찾고자 하는 아이템의 의도가 있으며, 의도에 부합하는 상품을 추천받기 위해 능동적으로 검색하는 상황으로 정의하였으며(=Search), 수동적 상황의 경우 유저의 추천 희망 여부와 무관하게, 유저의 과거 히스토리를 통해 취향을 추론하고 추천을 제공하는 상황으로 정의하였습니다(=Recommendation).
저희는 생성형 추천 시스템이 앞서 설명드린 두 가지 상황에서 모두 활용될 수 있도록 하고 싶었습니다. 즉, LLM 기반의 생성형 추천 모델을 Instruction tuning 기법으로 파인튜닝 하기 위한 데이터를 생성해야 했습니다. 저희는 학습용 데이터를 생성하기 위해 1) 입력 프롬프트 템플릿을 결정했고, 2) 해당 템플릿에 적용할 데이터를 생성하고, 3) 완성된 입력 프롬프트로부터 답변 데이터를 생성하고, 4) 마지막으로 저품질 데이터를 필터링하는 총 네 단계를 통해 데이터를 생성하였습니다.
프롬프트 템플릿
먼저, 프롬프트 템플릿을 결정하는 방법입니다. 능동적/수동적 상황의 추천 시나리오에 대응되는 프롬프트 템플릿을 생성하는 방법은 다양하겠지만, 여기서는 Tencent의 연구1와 Microsoft 연구진의 Orca2 연구를 참조하여, [system message, instruction, response]로 구성하였으며, 아래 그림은 수동적 상황에서 Direct/Listwise Recommendation 예시와, 능동적 상황에서의 Direct/Listwise Search Instruction 예시입니다.
 [그림 5. 능동적/수동적 상황 추천 프롬프트 템플릿 예시]
[그림 5. 능동적/수동적 상황 추천 프롬프트 템플릿 예시]
프롬프트 템플릿에 적용할 데이터 생성
두 번째로, 프롬프트 템플릿을 채워줄 데이터를 생성하는 과정에 대해서 설명드리겠습니다. 앞서 살펴본 것처럼 추천 시스템은 도메인에 따라 서로 다른 요소가 추천에 영향을 미칩니다. 예를 들면 우리가 웹툰이나 영화를 볼 때는 스토리 플롯, 장르, 작가/감독, 출연 배우 등을 주요하게 보지만, 전자 상거래에서는 기존 구매 아이템과의 관계,기능,가격 등이 중요한 역할을 합니다. Cross-domain 추천 모델을 학습하기 위해서 저희는 각기 다른 도메인에 대해서 어떤 요소를 중요하게 보고 추천을 제공하는지 학습하기 위한 데이터가 필요합니다. 본 연구에서는 이를 확보하기 위해 여덟 개의 도메인에 대한 공개된 데이터 셋을 활용했습니다.
| 도메인 | 데이터 셋 | 비율(%) |
|---|---|---|
| 뉴스 | MIND | 17.97 |
| 음악 | Amazon Music | 11.85 |
| POI | Yelp | 11.95 |
| 애니메이션 | Anime recommendation | 9.93 |
| 도서 | Book recommendation | 5.78 |
| 영화 | MovieLens | 4.64 |
| 게임 | Steam video games | 0.72 |
| 전자상거래 | Amazon E-commerce | 37.17 |
위 표와 같이 다양한 분야의 공개 데이터의 아이템을 활용하여 실제 유저-아이템 상호작용에 기반한 약 60만개의 추천 데이터셋을 확보할 수 있었습니다.
수동적 상황의 데이터 생성: 저희는 [그림 5]에서 (A)와 (B) 프롬프트의 과거 구매내역, 소비 아이템, 후보 상품 목록 등에 위 데이터 셋을 활용하여 채워넣어 수동적 상황의 데이터를 생성할 수 있었습니다.
능동적 상황의 데이터 생성: 하지만 능동적 상황의 데이터는 어떻게 만들 수 있을까요? 저희는 Llama2 및 Mistral-7B와 같은 공개된 LLM을 활용하여 사용자의 검색 쿼리를 생성하였습니다. (여기서 살짝 비밀을 공개드리면 저희는 llama.cpp3를 활용하여 quantized model과 pure C/C++로 추론을 함으로써 빠르게 LLM을 추론하였습니다.) 아래는 저희가 LLM에 검색 쿼리를 생성하기 위해 입력한 프롬프트입니다. 저희는 일곱 개의 아이템과 쿼리 예시를 만들고, 여덟 번째에 저희가 알고 싶은 아이템에 대한 설명을 입력하고 쿼리를 생성하도록 했습니다.
당신은 사용자가 상품을 구매했을 때 입력한 쿼리를 추론할 수 잇습니다. 한 문구로 쿼리를 추론합니다. 모호한 의도 쿼리를 생성하는 것이 좋습니다.
예시:
아이템:갤럭시 S23 Ultra 5G, 쿼리:삼성 플래그쉽 스마트폰
아이템:라라랜드, 쿼리:오스카 노미네이트 영화
아이템:IPad Pro 12.9inch LTE, 쿼리:애플 태블릿
아이템:나이키 조거팬츠(사이즈:XL), 쿼리:남자 조거팬츠
아이템:젤다의 전설:야생의 숨결, 쿼리:오픈월드 RPG 게임
아이템:오징어 게임, 쿼리:넷플릭스 오리지널
아이템:간사이 쓰루패스 2-day 티켓(QR 교환 티켓/이메일 발송/환불 불가), 쿼리:오사카 트래블 패스
아이템:"Deus Ex Human Revolution", 쿼리:
프롬프트 답변 데이터 생성
저희는 답변 데이터도 LLM을 활용하여 생성하였습니다. 저희는 이미 유저 히스토리/검색 쿼리 정보와 실제 다음 시점에 구매한 아이템 정보를 알고 있습니다. 이제 주어진 히스토리/검색 쿼리와 실제 구매한 타겟 아이템 정보를 프롬프트에 넣어주고 유저 히스토리에 기반하여 타겟 아이템을 구매/소비한 사유를 추론하게 하였습니다. 이는 단순하게 아이템만을 결과로 제시하는 것보다 사유를 함께 추론하도록 할 때, 추론이 더 잘 되기 때문입니다.
수동적 상황에서의 답변 예시
능동적 상황에서의 답변 예시
위의 두 가지 예시에서 볼 수 있듯이 LLM은 사람과 비슷하게 입력 아이템과 출력 아이템을 연결해주는 추론 과정을 생성하는 역할을 하는 것을 알 수 있습니다. 즉, LLM을 이용해서 새로운 아이템이 입력될 때 이와 연관있는 출력 아이템을 생성하기 위한 데이터를 생성할 수 있었습니다.
저품질 답변 데이터 필터링
위와 같이 만들어진 학습 프롬프트를 그대로 활용하여 학습할 수 있다면 얼마나 좋을까요? 안타깝게도 생성된 프롬프트 답변의 일부는 매우 품질이 안좋은 경우가 존재합니다. 아래 예시는 실제 생성된 답변 중 품질이 안좋은 예시입니다.
부적절한 답변 예시 1
부적절한 답변 예시 2
저희는 생성된 프롬프트의 시맨틱 품질을 평가하고 필터링하기 위해서 문장의 토큰 구성과 길이의 분포 점수를 활용하였습니다.
\[\mathrm{response\ score} = ln(L)\frac{L}{C} \\ L: \mathrm{token\ length}, \,C: \mathrm{unique\ token\ length}\]답변의 형태에 따라 위 식이 어떻게 변화하게 될지 차근차근 생각해봅시다. 일반적으로 문장은 길이(L)가 길어질수록 다양한 토큰(C)으로 구성되어 있습니다. 만약, 답변에서 같은 내용을 반복하고 있는 경우는 C가 작기 때문에 일반적인 문장의 경우보다 response score가 커지게 될 것입니다. 또한 답변이 길수록 장황한 논리의 답변을 제공할 확률이 높아지기 때문에 ln(L)항을 가중치로 활용하게 됩니다. 즉, 좋은 품질의 답변은 상대적으로 낮은 값(적당한 길이 + 적당한 어휘의 풍부함)을 가질 것이고 그렇지 못한 답변은 높은 값(매우 긴 길이 + 어휘의 부족함)을 갖게 될 것입니다. 따라서 위의 response score를 통해 생성된 데이터의 품질을 평가할 수 있게 됩니다.
아래 그림은 저희가 LLM을 통해 생성한 프롬프트 답변의 response score 분포를 보여주고 있습니다. 본 연구에서는 response score가 15 이상인 데이터는 저품질이라 판단하고 제거하였습니다.
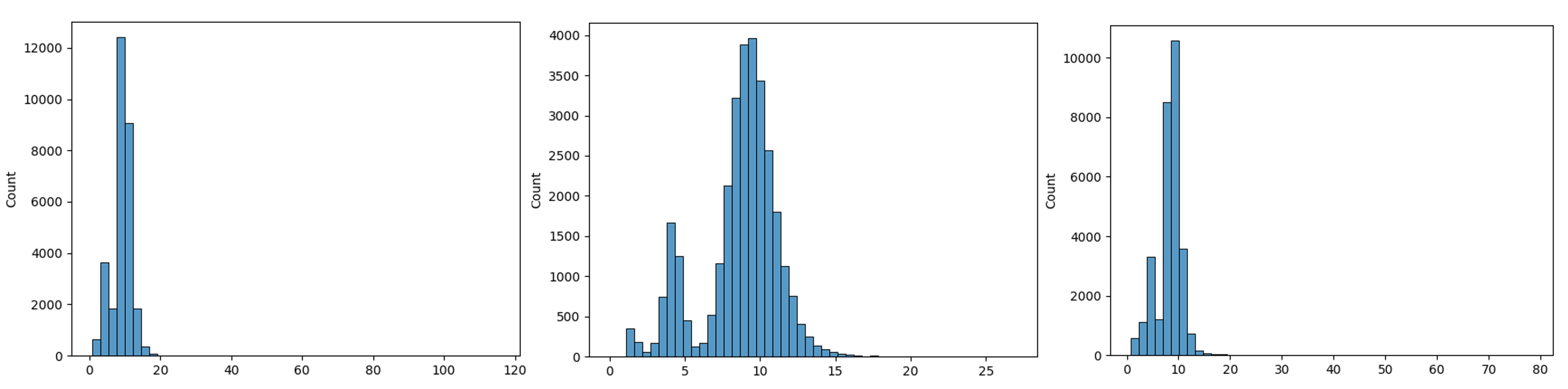 [그림 6. 왼쪽부터 전자제품, 영화, 패션 데이터셋의 답변 스코어 분포]
[그림 6. 왼쪽부터 전자제품, 영화, 패션 데이터셋의 답변 스코어 분포]
모델 파인튜닝: Instruction tuning
지금까지 저희가 만든 데이터는 [system message, instruction, response]로 구성되는데, system message와 instruction은 입력으로, response 토큰을 출력으로 생성하도록 VARCO LLM을 파인튜닝 하였습니다. 파인튜닝은 Instruction tuning으로 진행했는데요, 이는 Google에서 발표한 FLAN 논문4에서 처음 등장한 개념으로 우리가 입력한 Instruction 프롬프트를 사람의 의도에 맞는 답변을 생성하도록 학습하는 일종의 alignment의 개념입니다.
시범적인 연구로서 학습 자원을 최소화하기 위해 QLoRA5를 활용하여 학습에 사용되는 GPU 메모리의 사용량을 줄였으며, Deepspeed ZeRO6를 활용하여 학습을 진행하였습니다.
1차 결과: Instruction tuning 결과
저희가 파인튜닝한 모델이 새로운 데이터셋에 대해서도 잘 동작하는지 확인해볼까요? 아래는 뉴스와 전자 상거래 도메인에서 임의로 구성한 데이터에 대한 결과입니다.
뉴스 도메인에서의 추천 결과
전자 상거래 도메인에서의 추천 결과
얼핏 보면 나쁘지 않다고 생각할 수 있지만, 세세하게 보면 오류도 보이며, 환각 증상도 보입니다. 이러한 불완전한 답변 생성을 줄이고 사람의 선호와 일치하는 답변이 생성되게 개선할 순 없을까요?
모델 개선 시도 1: DPO를 활용한 Human Feedback 학습
저희는 사람의 선호와 일치하는 답변을 생성하기 위해 DPO7 방법을 첫 번째로 시도해 보았습니다. 이는 OpenAI가 InstructGPT 학습에 활용한 근사 정책 최적화(PPO)8 등 RLHF(Reinforcement Learning From Human Feedback) 방법의 한 방법입니다. 상세한 내용은 다른 NC Research 글이나 논문을 참조해주세요. 앞에서도 계속 언급했듯이, 저희는 최소한의 자원으로 학습하는 것이 목표이기 때문에 DPO 방법을 활용하였습니다.
DPO 목적함수
DPO는 2개의 답변 중에서 선호/비선호를 태깅한 데이터를 학습에 활용합니다. 이러한 선호 데이터를 기존 PPO 등의 강화학습 방법과 다르게 명시적인 Reward 모델링 과정을 없애고 Bradley-Terry 선호 모델을 그래디언트 업데이트만으로 직접 학습할 수 있게 되었습니다.
위와 같은 DPO 목적 함수는 모델(\(\pi_\theta\))이 reference 모델(\(\pi_{\mathrm{ref}}\))과 비교했을 때 선호 답변의 생성 확률을 증가시키고, 비선호 답변의 경우 감소시키도록 하는 형태를 띄고 있습니다. 위 식의 상세한 유도 과정과 RL 방법론에서 Reward 모델링을 생략할 수 있었던 이유는 해당 논문을 참조해주세요 :)
DPO 학습을 위한 Human Feedback 데이터 태깅
1차 실험 모델(Instruction tuning 모델)의 학습에 사용하지 않은 새로운 데이터 1,000개를 추가로 생성하고, 해당 데이터를 1차 실험 모델을 활용하여 5개의 답변을 생성하였습니다. 이 중에서 가장 선호되는 답변과 가장 비선호되는 답변을 저희가 직접 태깅하여 2차 모델 학습에 활용하였습니다.
2차 결과: DPO 학습 결과
이제 실험 결과를 비교해볼까요? 아래 그림에서 오른쪽은 Instruction tuning 모델로만 학습한 1차 실험 결과이고, 왼쪽은 1차 실험 모델 결과에 DPO로 추가로 학습한 결과를 나타냅니다. 2차 실험 모델의 결과에서 볼 수 있듯 DPO를 사용하여 추가로 학습한 경우 연관성 없는 문장이 튀어나오는 빈도가 줄어든 것을 확인할 수 있습니다. 하지만, 여전히 환각 증상이나 학습 데이터에서 등장했던 구체적인 상품명 같은 것이 튀어나오는 부분은 개선점으로 남아있습니다.
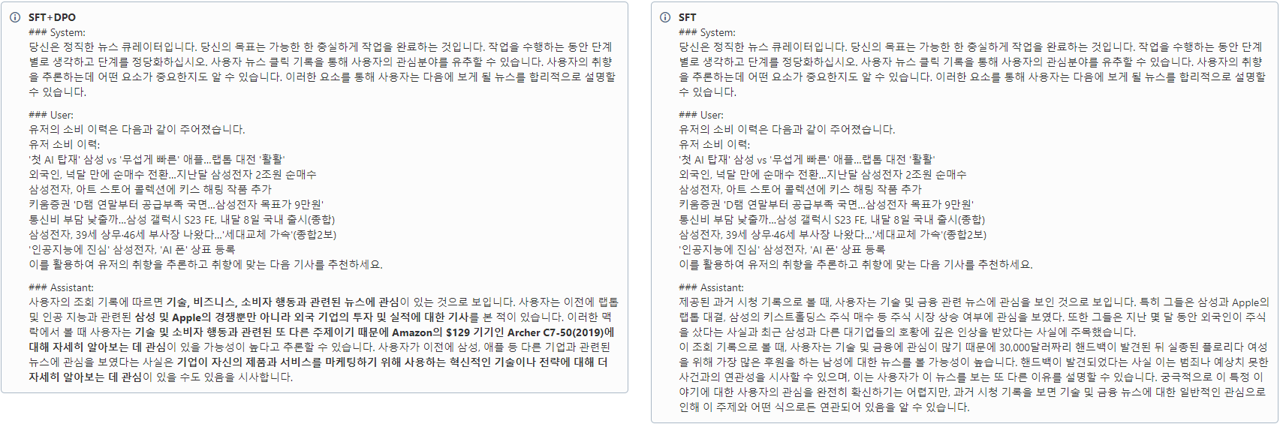 [그림 10. DPO+Instruction tuning 모델과 Instruction tuning only 모델의 결과 비교 예시]
[그림 10. DPO+Instruction tuning 모델과 Instruction tuning only 모델의 결과 비교 예시]
모델 개선 시도 2: 신뢰성 있는 zero-shot RS를 위한 검색 증강 방법 적용
위의 Instruction tuning과 DPO 방법 등은 다양한 도메인의 추천을 잘 이해하고 유의미한 추론과 연관성 있는 답변을 내놓는데까지는 성공하였습니다. 하지만, 추론 과정이 어색하고 환각 증상이 나타나거나, 학습 과정에서 등장했던 유사 상품에 대한 추천을 수행하는 등 실제 서비스로 추천에 활용하기엔 문제가 여전히 남아있습니다.
저희는 이와 같은 문제를 극복하고자 Unseen 도메인 데이터를 chunk 단위로 적재하고 이를 LLM의 답변과의 연관성을 찾는 시도를 수행하였습니다.
Unseen 도메인 데이터 vector DB 적재 및 Retriever를 활용한 연관 아이템 추천
‘모델이 생성한 답변은 실제 필요한 추천 상품에 대한 정보를 담고 있다’는 가정 하에 모델이 생성한 답변과 실제 추천을 적용하고자 하는 도메인 데이터를 chunking하고 vector DB에 저장한 각 chunk와의 유사도를 retriever를 활용하여 계산하고 가장 연관성이 높은 아이템을 반환하는 방법입니다.
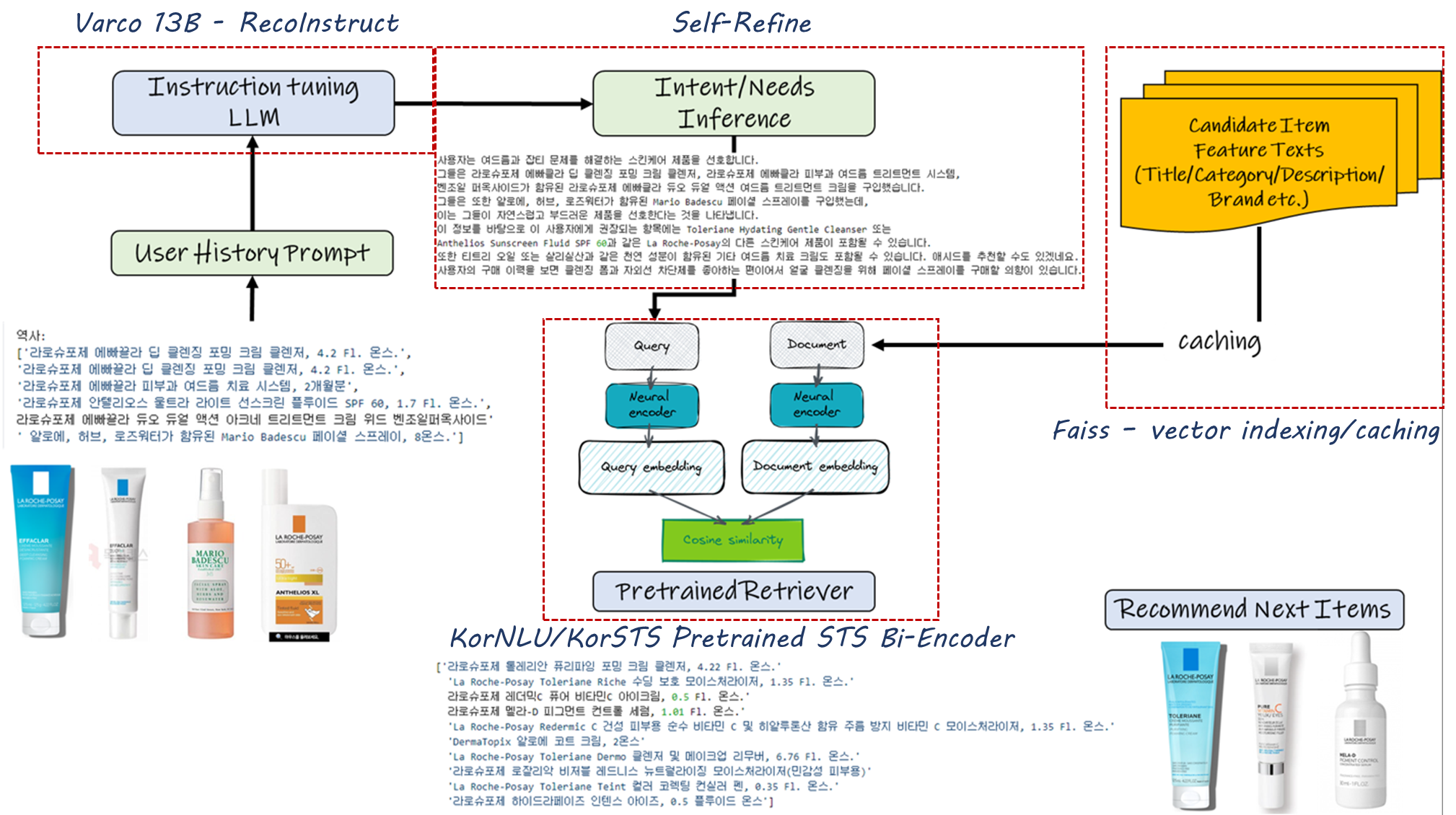 [그림 11. cross-domain zero-shot RS를 위한 파이프라인]
[그림 11. cross-domain zero-shot RS를 위한 파이프라인]
이는 ACL ‘23에서 발표된 HyDE9라는 모델의 아이디어와 유사합니다.
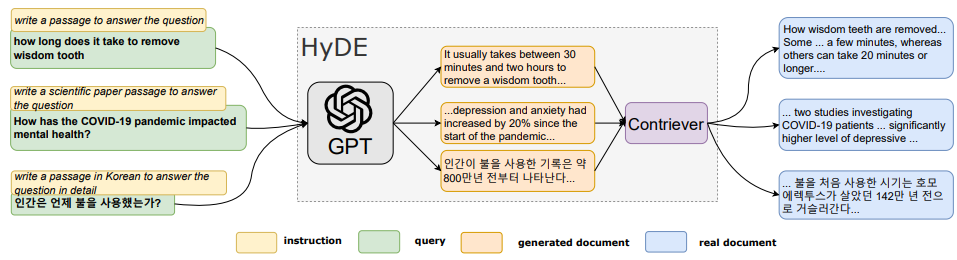 [그림 12. 생성 답변(문서)가 꼭 정확한 정보를 전달할 필요는 없다. 유사한 정보만을 담고 있으면 정확한 정보는 retriever가…]
[그림 12. 생성 답변(문서)가 꼭 정확한 정보를 전달할 필요는 없다. 유사한 정보만을 담고 있으면 정확한 정보는 retriever가…]
이러한 가정하에 vector DB를 활용하여 실제 unseen 도메인 데이터로써 연합뉴스 데이터셋을 chunking하여 저장하고, 연합뉴스 유저가 읽은 뉴스 리스트를 입력으로 하여 출력된 결과와의 사전 학습된 한국어 Retriever를 활용해 연관성 높은 뉴스를 추천해보았습니다. 아래는 유저 히스토리를 입력 프롬프트로 넣었을 때 모델이 내놓은 답변과 추천 대상이 되는 아이템 텍스트 chunk와의 유사도를 계산하여 답변과 관련성이 높은 chunk를 추출한 예시입니다.
LLM + Retriever 기반 추천 텍스트 chunk 추출
위와 같이 뉴스 중에서 투자 관련 책 내용을 다루는 기사, 정치+재정을 다루는 기사 또는 국민연금 등 재정적 안정 및 복지와 관련된 chunk를 선택한 것을 확인할 수 있습니다! 그렇다면 해당 chunk를 포함하는 기사를 추천해주면 되겠군요. 완벽하진 않지만 우리는 추가적인 학습 없이도 unseen 데이터에 대해 그럴듯한 추천을 제공할 수 있었습니다.
글 마무리
지금까지 zero-shot 추천 모델을 LLM을 활용하여 생성하기 위한 데이터 생성/학습/개선의 과정을 공유드렸는데요. 실제 서비스에 넣기에는 넘어야 할 산이 많지만, 적은 리소스로 학습한 것 대비 동작에 대한 가능성을 봤다고 볼 수 있을 것 같습니다.
실제 추천 모델로서 동작하기 위해서 환각 증상의 감소, 추론 속도 및 리소스 사용 개선 및 성능의 개선 등이 필요할 것으로 보입니다.
기존 추천 모델이 분명 효율적이고 우수한 부분이 많지만, LLM과 같은 거대 모델이 가지는 다양한 도메인 적용의 유연성, 우수한 zero-shot 성능 등은 분명 매력적인 요소입니다.
지금까지 긴 글 읽어주셔서 감사합니다!
References
-
Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach ↩
-
Orca: Progressive Learning from Complex Explanation Traces of GPT-4 ↩
-
Direct Preference Optimization: Your Language Model is Secretly a Reward Model ↩
-
Precise Zero-shot Dense Retrieval without Relevance Labels ↩
