
작성자
- 양철종 (멀티모달 AI Lab)
- 딥러닝을 이용한 비디오생성 기술을 연구하고 있습니다.
이런 분이 읽으면 좋습니다!
- Diffusion 모델을 이용한 이미지/비디오생성 연구에 관심이 있는 분
- AI를 활용한 비디오생성 서비스가 궁금한 분
이 글로 알 수 있는 내용
- Diffusion Model을 활용한 비디오생성 모델의 동작 원리
- 비디오생성 기술 현 수준과 앞으로의 연구 흐름
비디오생성 AI 기술 개요
Stable Diffusion, DALL-E, Midjourney 등으로 대표되는 이미지생성 기술은 텍스트 프롬프트나 스케치 등을 입력으로 받아 실제와 같은 이미지를 생성할 수 있는 AI 기술입니다. 비디오생성 AI는 이러한 이미지생성 기술을 한 차원 더 발전시킨 형태로, 텍스트 프롬프트나 이미지를 입력으로 받아 동영상을 출력하는 기술을 의미합니다. 두 기술 모두 생성형 AI 모델을 기반으로 하지만, 비디오생성 AI는 시간적 연속성과 움직임을 함께 모델링해야 한다는 점에서 조금 더 복잡한 기술이라고 할 수 있습니다.
영상 1. Stable Video Diffusion [1]
비디오생성 모델 동작 원리
그렇다면 AI 모델은 어떻게 비디오를 생성할 수 있을까요? 비디오생성 AI는 이미지생성 모델을 시간 차원으로 확장한 모델로 두 모델은 많은 기술을 공유합니다. 이번글에서는 비디오생성 AI 기술의 시공간적 특성의 모델링 방법을 이미지생성 AI 기술과 비교하며 살펴보고자 합니다.
이미지생성과 Diffusion Model
이미지생성 기술의 역사는 꽤나 길지만 실생활에 사용할 만큼의 성능을 확보한 시기는 Diffusion Model의 접근법이 성숙한 시점부터 입니다. Diffusion Model의 기본 아이디어는 데이터에 랜덤 노이즈를 반복적으로 주어 데이터를 손상시키며 (‘그림 1’의 ‘Fixed forward diffusion process’), 다시 원본 데이터를 복원시키는 네트워크를 거꾸로 학습하는 것 입니다 (‘그림 1’의 ‘Generative reverse diffusion process’).
이때 Reverse process에서 노이즈를 추정하기 위한 네트워크는 U-Net을 주로 사용합니다. 실제 이미지생성 과정에서는 노이즈 스텝에 따라 U-Net으로 노이즈를 제거하는 과정을 반복적으로 거치며 깨끗한 이미지를 얻게 됩니다.

그림 1. Diffusion Process 예시 [2]
Latent Diffusion Model (LDM)
이미지와 같은 높은 차원의 데이터를 Diffusion Process로 연산하는 데에는 방대한 리소스를 필요로하고 학습 난이도도 꽤나 높습니다. Latent Diffusion Model (LDM)은 Diffusion Model에 수반되는 이러한 문제를 해결하기 위하여 낮은 차원의 잠재 공간 (Latent space)에서 Diffusion Process를 수행하기 위해 제안된 모델입니다. LDM은 다음과 같은 순서로 이미지 생성 추론 과정에 적용할 수 있습니다.
- 인코더를 이용하여 이미지를 잠재 공간으로 투영 (‘그림 2’의 ‘Pixel Space’ 블럭)
- 잠재 공간의 벡터에 Diffusion Process를 반복적으로 수행 (‘그림 2’의 ‘Latent Space’ 블럭)
- 생성된 벡터를 이미지 공간으로 디코딩 (‘그림 2’의 ‘Pixel Space’ 블럭)
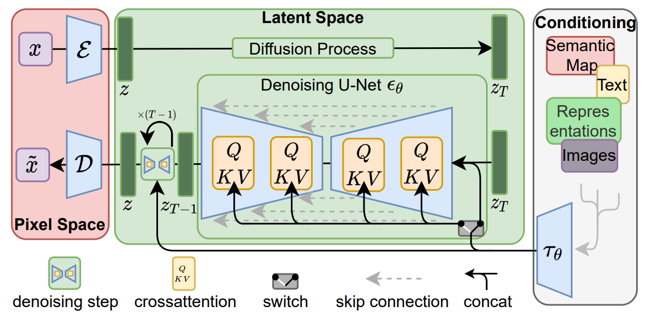
그림 2. Latent Diffusion Model 구조 [3]
이때 이미지공간과 잠재공간 사이를 투영하는 인코더 / 디코더 모델은 생성 이미지의 인지적인 퀄리티를 높이는 방향으로 모델링되고, 잠재 공간에서의 Diffusion Model은 생성 이미지가 포함하는 의미론적인 컨텐츠를 학습하게 됩니다. LDM은 이와같은 학습전략을 이용하여 조화로운 구성의 고품질 이미지를 생성할 수 있음을 증명하였습니다. 이후 더욱 많은 데이터와 다양한 컨디셔닝 기법을 (‘그림 2’의 ‘Conditioning’ 블럭) 통해 성능을 끌어올린 LDM 기술은 대부분의 이미지생성 상용 서비스에 적용되고 있습니다.
비디오생성과 Latent Diffusion Model
최근의 비디오생성 기술은 앞서 설명한 LDM 모델을 적극적으로 차용하고 있습니다. (이번 글에서는 LDM 기반의 비디오생성 기술을 ‘비디오 LDM’이라 부르겠습니다.) 그렇다면 비디오 LDM 모델을 구성하는데 있어 가장 중요한 요소는 무엇일까요? 비디오생성이 이미지생성과 가장 큰 차이는 인접 프레임 간 일관성을 고려해야한다는 점 입니다. 즉, 시간 차원에서 다른 프레임의 정보를 바라볼 수 있는 장치가 필요한 것이죠.
시간적 일관성 측면에서 비디오 LDM이 갖는 구조적 차이점은 U-Net 구조를 시간축으로 확장한 3D U-Net을 사용하는 점입니다. 이미지생성을 위한 Diffusion model의 U-Net 구조가 1개 프레임의 Noise 이미지를 입력으로 받는것과는 다르게, 비디오 LDM의 3D U-Net은 연속 프레임을 입력으로 받아 다른 프레임 정보를 참조할 수 있는 구조를 사용하는 것이죠.
이때 다른 프레임 정보를 참조하는 방법은 대표적으로 그림 3과 같이 U-Net의 세부 모듈 마지막에 Temporal Transformer Layer를 두는 것 입니다. 이는 시간축에 대하여 어텐션 메커니즘을 적용하여 다른 프레임의 쿼리를 참조하게 함으로써 시간적 일관성을 유지하면서 비디오를 생성하도록 돕습니다.
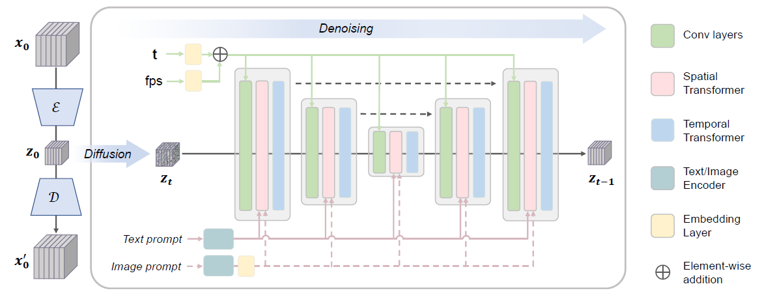
그림 3. 비디오 LDM 구조 [4]
그렇다면 비디오 LDM으로 만든 비디오의 품질은 어떨까요? 앞서 비디오 LDM의 3D U-Net은 연속된 프레임을 참조한다고 설명드렸습니다. 때문에 비디오 LDM 모델 학습을 위해서는 연속된 프레임 입력이 필요하고, 이는 이미지생성 모델 대비 고용량의 학습 데이터와 리소스를 사용함을 의미합니다. 추론 과정에서도 한번에 출력되는 프레임의 길이도 제한적일 수 밖에 없고요.
이러한 한계로 인하여 비디오 LDM으로 생성된 비디오는 ‘영상 1’과 같이 3-4초 내외의 HD급 화질을 보여주고 있습니만 (여러 테크닉을 이용하여 공간적-시간적 업스케일링을 할 수 있습니다), 아직은 긴 문장의 텍스트 프롬프트를 모두 담기에는 그 길이와 해상도가 조금 부족하다는 생각이 들 수 있습니다.
비디오생성 AI 기술의 발전 방향
최근 OpenAI에서는 비디오 LDM 방식들의 한계를 뛰어 넘는 Sora라는 모델을 공개하며 또 한번 세상을 놀라게 했습니다. OpenAI가 ChatGPT에서 보여주었던 Scaling Law를 비디오생성 AI 모델까지 확장할 수 있도록, 3D U-Net을 Diffusion Transformer 구조로[5] 변경하고 엄청난 데이터와 컴퓨팅 파워를 쏟아부어 만든 모델인데요.
긴 문장의 텍스트 프롬프트에 대하여 FHD 화질의 1분에 가까운 비디오를 생성함으로써, 앞으로 비디오생성 AI 분야도 언어모델과 같이 데이터 규모와 컴퓨팅 파워의 싸움으로 흘러갈 수 있음을 보여주고 있습니다.
영상 2. OpenAI Sora 소개영상 [6]
비디오생성 기술 활용 분야
비디오생성 기술은 텍스트 프롬프트나 정지된 이미지로부터 다이나믹한 비디오를 만들어낼 수 있기 때문에 다양한 컨텐츠 창작 분야의 패러다임을 바꿀것으로 기대받고 있습니다. 그렇다면 비디오 LDM을 기반으로하는 비디오생성 기술들이 어떤 분야에 활용될 수 있을지 살펴보겠습니다.
카메라 구도 편집
비디오 LDM도 다양한 컨디션을 입력으로 주어 생성 결과를 조절할 수 있는 연구가 활발히 진행되고 있습니다. 그 중 한 가지로, 사용자가 입력한 카메라의 구도와 등장인물의 움직임에 따라 비디오를 생성하는 기능도 있는데요. 이는 영상 제작 과정에서 스토리보드나 컨셉 아트로부터 다양한 비디오 시안을 작성할 수 있어, 시네마틱 영상이나 애니메이션 제작에 시간을 획기적으로 줄일 수 있을 것으로 예상됩니다.
영상 3. 카메라 구도 변경 비디오 생성
아트 에셋 생성
또한 아트 에셋이나 특수 효과 제작에도 도움을 줄 수 있는데요. 원하는 영상의 스틸 이미지와 함께 필요한 특수 효과를 텍스트로 입력하면 꽤나 괜찮은 배경 에셋을 만들 수도 있습니다. 특히 반복적인 재생에도 이질감이 없도록 Loop 형태의 비디오를 생성하는 기술도 많은 연구가 이루어지고 있습니다.
영상 4. 배경 특수효과 생성
마치며
이번 글에서는 비디오생성 AI 모델의 배경 기술 및 원리와 함께 그 활용 방안을 살펴보았습니다.
생성 결과물을 보면 아직 개선이 필요한 부분도 있지만, 비디오 LDM은 2023년 부터 본격적으로 연구된 분야임을 감안한다면 앞으로의 성장이 더욱 기대되는 기술임에는 논란의 여지가 없을 것 입니다.
이미지생성 분야와 같이 많은 사람들이 사용하기 위해서는 비디오생성 결과물의 재편집 과정의 어려움과 텍스트 프롬프트에 집중되어 있는 가이드 방식의 제약은 꼭 해결되어야할 문제입니다. 당연히 비디오모델 학습과 추론에 수반되는 컴퓨팅 파워도 개선이 되어야 할 것이고요. 적어두고보니 비디오생성 분야는 아직도 갈길이 멀어보이기도 합니다. 이런 문제들을 헤쳐 나가는 우리팀의 연구 노하우를 다시 나눌 기회가 있기를 희망하며 글을 마칩니다.
[1] Introducing Stable Video Diffusion, Stability AI
[2] Denoising Diffusion-based Generative Modeling: Foundations and Applications, CVPR Tutorial (2022)
[3] High-resolution image synthesis with latent diffusion models, Rombach (2022)
[4] Videocrafter2, Chen (2024)
[5] Scalable Diffusion Models with Transformers, Peebles (2023)
[6] Video Generation Models as World Simulators, OpenAI
[7] CameraCtrl, He (2024)
[8] Gen-2, Runway Research
