
작성자
- 정윤재 (오디오AI Lab)
- 오디오 생성AI를 위한 여러가지 제반 기술을 연구하고 있습니다.
이런 분이 읽으면 좋습니다!
- 오디오 생성AI에서의 최근 접근 방법이 궁금하신 분
- 오디오 생성AI에서의 언어 모델 접근 방법이 궁금하신 분
이 글로 알 수 있는 내용
- 뉴럴 오디오 코덱을 통해 오디오 신호를 이산 표현으로 토큰화하는 이유와 방법
- 뉴럴 오디오 코덱 기반 오디오 언어 모델의 작동 원리
- SoundStream, UniAudio 방법론의 세부 작동 방식
시작하며
현재의 오디오 생성모델은 주로 멜-스펙트로그램(Mel-Spectrogram) 기반의 음향모델과 보코더(Vocoder)로 이뤄져 있습니다. 음향모델은 주어진 텍스트 스크립트 등의 조건에 따라 멜-스펙트로그램 형태의 오디오를 생성하며, 보코더는 이를 오디오 신호로 변환합니다. 이 방법은 고품질 녹음 데이터를 학습에 필요로 하며, 대량의 학습 데이터를 구축하기 어려워 일반화된 모델을 만드는 데 제한이 있습니다. 예를 들어, 제로샷 TTS(Zero-shot TTS)와 같은 경우에는 사용자가 원하는 목소리와 유사한 음성을 만들기 어렵습니다.
언어모델링은 자연어 처리 분야에서 매우 효과적으로 검증된 방법입니다. 최근에는 텍스트뿐만 아니라 이미지, 영상 등 다른 영역에서도 많은 가능성을 보여주고 있습니다. 오디오 생성 분야에서는 뉴럴 오디오 코덱(Neural Audio Codec)을 활용하여 연속적인 오디오를 이산 코드로 변환하고, 자기 지도 학습(Self-supervised Learning, SSL)과 언어모델링 접근 방법을 통해 앞서 언급한 문제 등을 해결하고자 하는 시도들이 계속 진행되고 있습니다.
Meta의 AudioBox1와 같은 연구에서는 오디오 입력과 텍스트 형태의 지시문을 결합하여 목소리와 효과음 등 다양한 소리를 생성할 수 있게 되었습니다. 사용자는 텍스트 거대언어모델(Large Language Models, LLMs)을 사용하는 것과 유사하게, 다양한 사용자의 지시와 문맥 정보를 활용하여 사용자 정의 오디오를 손쉽게 만들 수 있게 되었습니다.
영상 1. Meta의 AudioBox 소개 (https://audiobox.metademolab.com/)
오디오 신호를 직접 언어모델에 적용하는 것은 사실상 불가능합니다. 오디오 신호는 1차원의 연속적인 샘플로 이루어져 있고, 각 샘플은 스칼라 값으로 표현됩니다. 또한 오디오 신호는 텍스트보다 훨씬 긴 시퀀스로 이루어져 있습니다. 예를 들어 CD 품질의 오디오는 1초당 44.1k 개의 샘플로 이루어져 있으며, 각 샘플은 16비트로 표현되는 연속된 값을 가지고 있습니다.
오디오 코덱은 오디오 신호를 압축(인코딩)하고 해제(디코딩)하는 기술을 의미합니다. “코덱”은 “코더(coder)”와 “디코더(decoder)”의 합성어로, 오디오 데이터를 압축하여 저장하거나 전송할 때 사용됩니다. 뉴럴 오디오 코덱은 딥러닝 접근 방식을 활용하여 전통적인 알고리즘 기반의 오디오 코덱을 대체하며, 높은 압축율과 재현 품질을 실현했습니다. 예를 들어, Opus와 같은 알고리즘 기반 코덱이 12kbps로 압축한 오디오에 비해 뉴럴 오디오 코덱은 3kbps의 압축으로 더 뛰어난 음질을 제공합니다2.
뉴럴 오디오 코덱은 오디오 신호를 효율적이고 이산적인 코드(오디오 토큰)로 압축하여 연속적인 오디오에 대한 언어모델링을 가능하게 합니다. 이를 위해 오디오 코덱 기반 언어모델은 다음과 같은 과정을 거칩니다. (1) 다양한 문맥 정보와 오디오 신호를 토큰 형태로 인코딩합니다. 이 과정에서는 각각 Context Encoder와 Codec Tokenizer가 사용됩니다. (2) 뉴럴 코덱 기반 언어모델(Neural Codec LM)을 통해 원하는 대상 오디오 코덱 토큰 시퀀스를 생성합니다. (3) 생성된 토큰 시퀀스는 코덱 디코더(Codec Decoder)를 통해 오디오 신호로 변환됩니다.
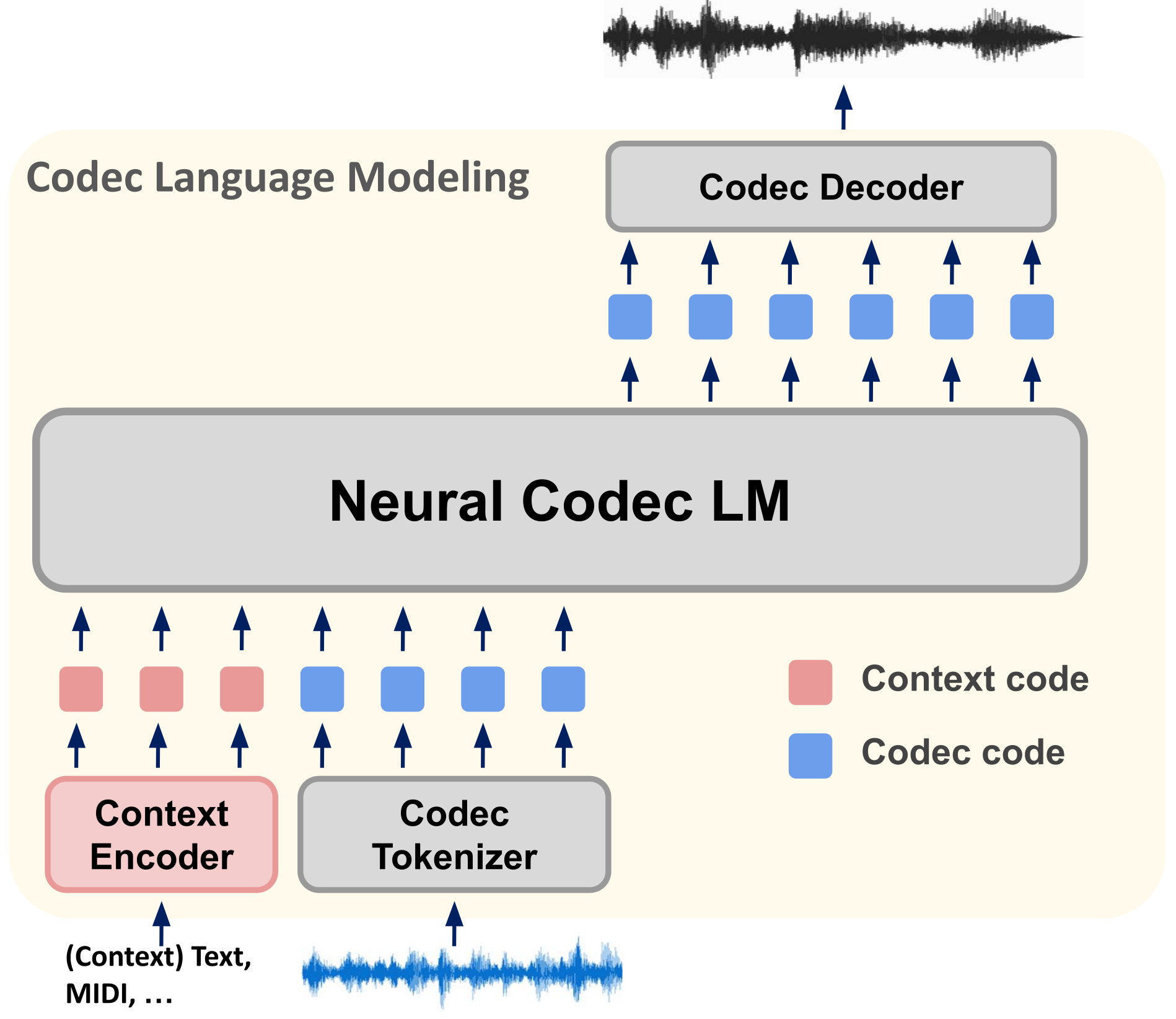
그림 1. 뉴럴 오디오 코덱 기반 언어모델링 3
이 블로그에서는 두 가지 중요한 연구인 SoundStream2과 UniAudio4를 소개합니다. SoundStream은 Google AI에서 개발한 뉴럴 오디오 코덱으로, 이후의 연구에 기반이 되어 현재까지 광범위하게 활용되고 있습니다. UniAudio는 뉴럴 오디오 코덱을 활용하여 음성 합성, 음성 변환, 음성 개선, 대상 음성 추출 등 다양한 오디오 작업을 수행할 수 있는 언어모델링 접근 방식입니다. 이는 오디오 생성 분야에서 GPT와 유사한 역할을 합니다. UniAudio는 오디오 처리와 생성 분야에서 새로운 혁신적인 방법을 제안하고 있습니다.
SoundStream
SoundStream2은 최신 뉴럴 오디오 합성 기술과 양자화 모듈을 활용하여 음성, 음악, 효과음 등의 오디오 신호를 고품질이고 고효율로 압축합니다. 이는 오토인코더(Auto Encoder)와 양자화(Quantization) 기법을 결합한 형태입니다. SoundStream은 인코더(Encoder), 잔여 벡터 양자화기(Residual Vector Quantizer, RVQ), 디코더(Decoder)로 구성되어 있으며, 적대적 학습과 재구성 손실을 통해 모델을 학습합니다. 필요에 따라 잡음 제거 기능을 선택적으로 추가할 수 있습니다.
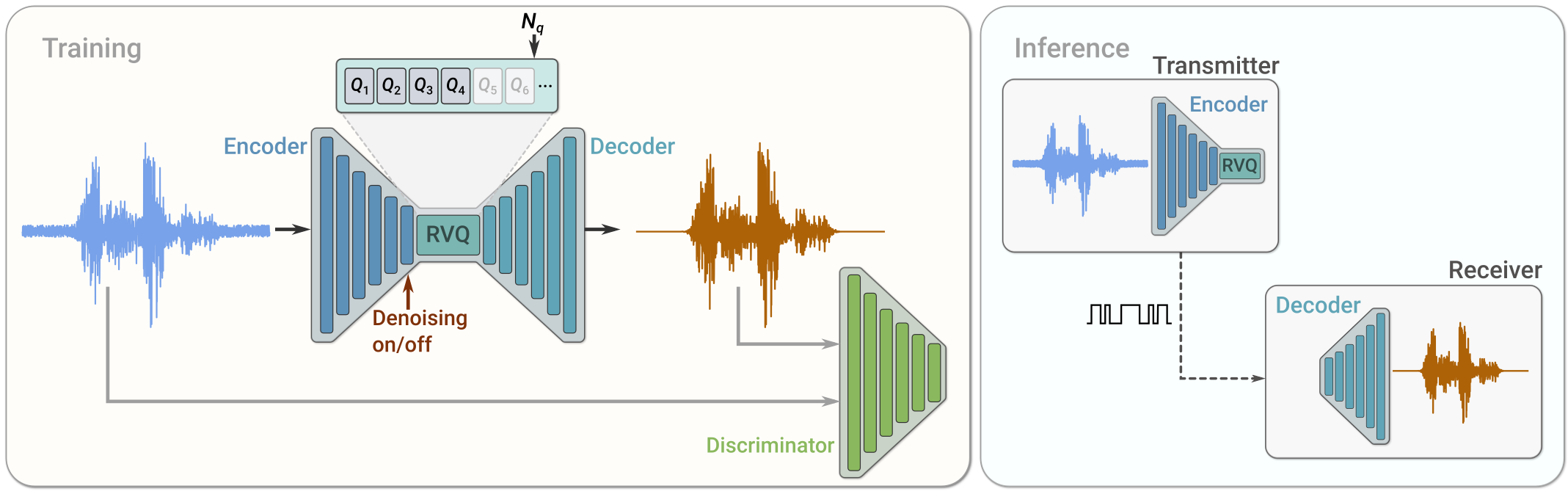
그림 2. Sound Stream 아키텍처 2
인코더는 원본 오디오 신호의 정보를 더 적은 샘플 레이트(sample rate)로 압축하는 역할을 합니다. 샘플 레이트는 1초 동안 샘플링되는 데이터 포인트의 수를 나타냅니다. RVQ는 인코더의 출력 임베딩 값을 이산 표현으로 변환하여 더 작은 크기로 압축합니다. 이는 한 샘플을 표현하는 데 필요한 비트레이트(bitrate)를 줄이는 것입니다. 비트레이트는 1초 동안의 오디오 신호를 표현하는 데 필요한 비트 수를 말합니다. 디코더는 RVQ를 통해 이산 표현으로 압축된 오디오 토큰을 다시 오디오 신호로 변환합니다.
학습 과정에서 두 가지 구분자(Discriminator)가 사용됩니다. 첫 번째는 파형 기반 구분자로 원본 오디오 신호와 디코더를 통해 복원된 신호의 파형을 최대한 유사하게 만드는 역할을 합니다. 두 번째는 STFT(Short-Time Fourier Transform)에 기반한 구분자로 원본 오디오 신호의 주파수 분석 결과와 복원된 오디오 신호의 주파수 분포가 유사하게 학습되도록 합니다.
인코더 아키텍처
인코더 아키텍처는 아래 그림 3과 같습니다. 입력 오디오 신호의 채널 수는 \(C_{enc}\)로 표시되며, 1D 합성곱 레이어와 이어지는 \(B_{enc}\)개의 합성곱 블록으로 구성됩니다. 각 블록은 3개의 잔여 유닛(Residual Unit)으로 이루어져 있으며, 다운샘플링 과정에서 채널 수가 2배씩 증가합니다. 마지막 1D 합성곱 레이어는 임베딩 차원(\(D\))을 설정합니다.
입력 파형과 임베딩 사이의 시간적 리-샘플링(re-sampling) 비율은 \(B_{enc}\)와 각 합성곱 블록의 스트라이드(Stride)에 따라 결정됩니다. 예를 들어, \(B_{enc} = 4\)이고 스트라이드가 \(S = \left( 2, 4, 5, 8 \right)\)로 구성된 경우, \(M = 2 \cdot 4 \cdot 5 \cdot 8 = 320\)개마다 하나의 임베딩이 계산됩니다. 즉, 입력 샘플 \(x\)가 \(T\)개의 샘플로 구성되어 있다면, 인코더는 \(enc \left( x \right) = R^{S \times D}\)의 임베딩 값을 출력합니다. 여기서 \(S\)는 \({T \over M}\)입니다..
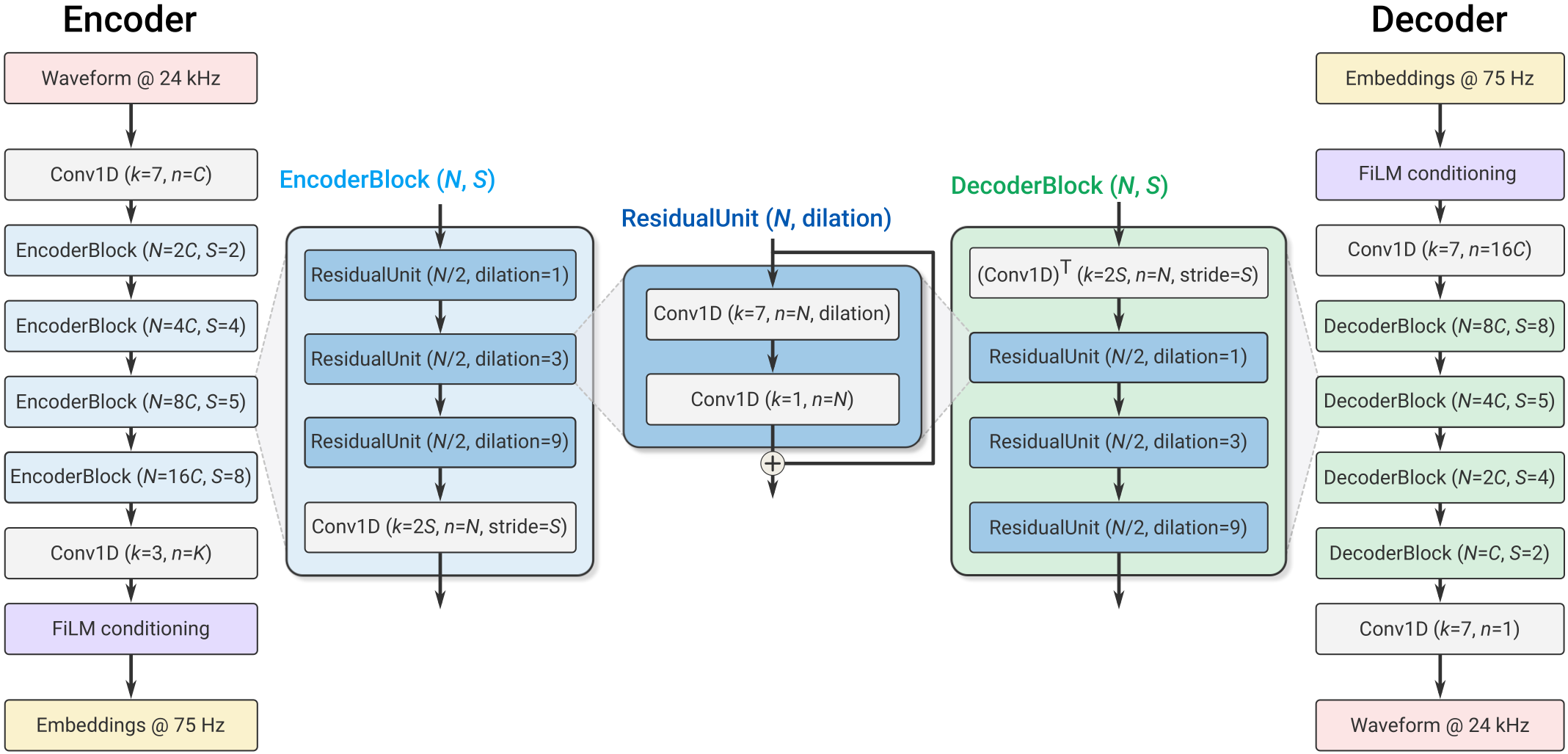
그림 3. Sound Stream의 인코더와 디코더 모델 2
디코더 아키텍처
디코더 아키텍처는 인코더와 유사한 구조를 갖고 있습니다. 먼저 1D 합성곱 레이어를 거친 후 일련의 디코더 블록이 이어집니다. 각 블록은 인코더 블록과 유사하며, 업샘플링을 위해 전치 합성곱(Transposed Convolution)이 사용됩니다. 업샘플링할 때마다 채널 수가 절반으로 줄어들며, 마지막 1D 합성곱 레이어는 임베딩을 다시 파형 도메인으로 투영하여 원래 파형을 재구성합니다. 인코더와 디코더의 채널 수는 동일한 파라미터로 제어됩니다.
잔여 벡터 양자화(Residual Vector Quantization, RVQ)
RVQ는 인코더 출력을 압축하는 중요한 역할을 합니다. 이는 일반적인 벡터 양자화(Vector Quantization, VQ)의 한계를 극복하고 비트레이트 확장성을 제공하는 강력한 압축 기법입니다. RVQ는 종단간 방식으로 학습되며, 역전파를 통해 양자화기, 인코더, 디코더를 공동으로 최적화합니다.
VQ는 \(D\)차원의 인코더 출력 \(\text{enc} \left( x \right)\)를 대상 비트레이트 \(R\)로 압축하기 위해, \(N\)개의 크기를 갖는 코드북으로 매핑하는 것을 목표로 합니다. 코드북의 코드는 \(\text{log}_2{N}\)개의 비트로 이루어진 원핫(one-hot) 벡터입니다. 그러나 VQ는 많은 정보를 압축할 때 코드북의 크기가 실현 불가능할 정도로 커지는 문제점을 가지고 있습니다. 예를 들어 비트레이트 \(R = 6,000 \text{bps}\)를 대상으로 하는 코덱을 고려해 봅시다. 샘플링 레이트 \(f_s = 24 \text{kHz}\)의 원본 오디오 신호를 \(M = 320\)을 사용하여 인코딩할 경우, 인코더의 출력은 1초 당 \(S = f_s/M = 24,000/320 = 75\)개의 \(D\)차원 벡터의 시퀀스가 됩니다. 이것에 대상 비트 레이트가 \(R = 6,000\)를 대입할 때, 각 벡터에 할당된 비트 수는 \(r = R/75 = 6,000/75 =80\)이 되며, 총 \(N = 2^r = 2^{80}\)의 코드북 크기가 필요합니다.
RVQ는 이를 해결하기 위해 \(N_q\)개의 VQ 레이어를 캐스케이드(Cascade) 방식으로 연결하여 코드북 크기를 제어합니다. 그림 4에서 보여주는 것과 같이, RVQ는 양자화되지 않은 입력 벡터를 첫 번째 VQ를 통과시키고 양자화 잔차(Quantization Residual)을 계산합니다. 그런 다음 잔차(Residual) 값은 일련의 추가 VQ에 의해 반복적으로 양자화됩니다. 총 비트는 각 VQ에 균등하게 할당됩니다. 즉 \(i\)번째 VQ에 할당된 비트수는 \(r_i = r/N_q = \text{log}_{2}{N}\)가 됩니다. 예를 들어 VQ 레이어 수를 \(N_q=8\)로 설정할 때, 각 VQ는 총 크기가 \(N = 2^{r/N_q} = 2^{80/8} = 1024\)인 코드북을 사용하게 됩니다.

그림 4. 잔여 벡터 양자화 알고리즘 2
구분자(Discriminator) 아키텍처
적대적 손실을 계산하기 위해 두 가지 다른 구분자를 사용합니다. 첫 번째는 파형 기반 구분자로, 단일 파형을 입력으로 받습니다. 두 번째는 STFT(Short Time Fourier Transform) 기반 구분자로, 입력 파형의 복소값 STFT를 실수부와 허수부로 표현한 것을 입력으로 받습니다.
파형 기반 구분자
파형 기반 구분자는 MelGAN5에서 사용된 것같이 다중 해상도 합성곱 구조를 사용합니다. 입력 오디오를 세 가지 해상도(원본, 2배 다운샘플링, 4배 다운샘플링)로 처리하며, 각 해상도의 구분자는 일반 합성곱 레이어와 그룹화된 컨볼루션 레이어로 구성되어 있습니다. 마지막으로 최종 출력, 즉 로짓(logit)을 생성하기 위해 두 개의 추가 일반 컨볼루션 레이어를 거칩니다.
STFT 기반 구분자
STFT 기반의 구분자는 입력 오디오 파형의 STFT를 기반으로 작동합니다. 윈도우 길이는 1024이고, 홉(hop) 길이는 256으로 설정됩니다. 이후에는 \(7 \times 7\) 크기의 커널과 32개의 채널을 가진 2D 합성곱을 적용합니다. 총 6개의 잔차 블록(residual block)이 사용되며, 각 블록은 다양한 크기의 합성곱과 스트라이드를 가집니다. 출력은 다운샘플링을 거친 후 주파수 빈(bin)에서 로짓을 집계합니다.
UniAudio
UniAudio4는 대규모 언어모델(LLM) 기술을 활용하여 특정한 입력 조건에 따라 다양한 종류의 오디오를 생성합니다. 이 과정은 다음과 같습니다: (1) 대상 오디오와 다른 조건을 토큰화하고, (2) 소스-대상 쌍을 하나의 시퀀스로 결합하며, (3) LLM을 사용하여 다음 토큰을 예측합니다. 또한, 매우 긴 시퀀스를 처리하기 위해 잔차 벡터 양자화 기반 신경 코덱과 다중 스케일 트랜스포머 모델을 도입하였습니다. UniAudio의 학습은 다양한 오디오 생성 작업을 기반으로 하여, 오디오의 본질적 특성과 다른 모달리티와의 상호 관계에 대한 충분한 사전 지식을 확보하는 것을 목표로합니다. 학습된 UniAudio 모델은 모든 훈련된 작업에서 강력한 성능을 보이며, 간단한 파인튜닝 후 새로운 오디오 생성 작업을 원활하게 지원할 수 있는 잠재력을 지니고 있습니다.
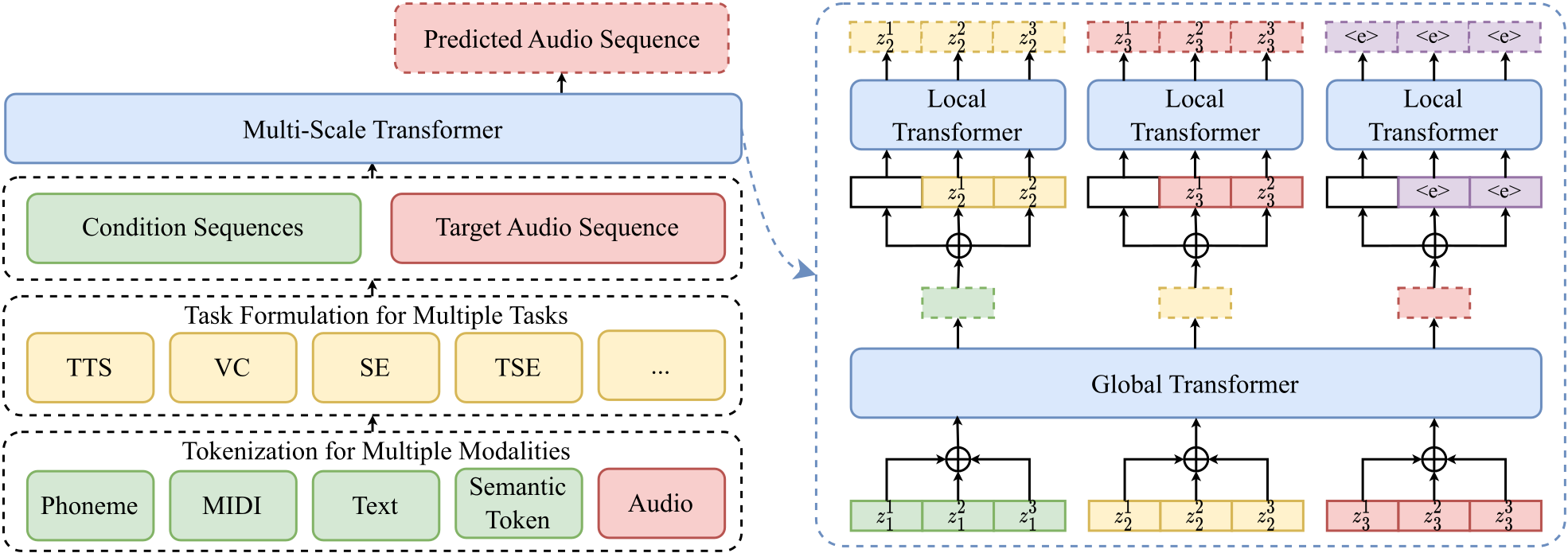
그림 5. UniAudio의 개요(왼쪽) 및 다중 스케일 트랜스포머 아키텍쳐(오른쪽)4: \(z_t^k\)는 $t$번째 프레임의 \(k\)번째 오디오 토큰을 나타내며 <e>는 시퀀스의 끝입니다.
토큰화
오디오 토큰화
언어모델은 대개 입력 토큰에 대한 순차적 모델링 방식을 사용합니다. 오디오도 다른 입력 모달리티와 유사한 토큰화 과정을 거칩니다. UniAudio는 음성, 소리, 음악, 노래 등 모든 유형의 오디오를 예측합니다. 이를 위해 UniAudio는 모든 유형의 오디오를 단일 모달리티로 통합하여 토큰화합니다. 이러한 방법은 고유한 패턴이 존재하더라도 모든 유형의 오디오를 공유된 잠재 공간으로 매핑하기에 적합한 모델을 필요로 합니다. UniAudio는 뉴럴 오디오 코덱을 이용하여 이를 실현합니다.
기타 입력 모달리티 처리
UniAudio에서는 오디오 이외의 입력 모달리티도 시퀀스로 표현하고 토큰화하여 이산형 데이터로 변환합니다. 각 입력 모달리티의 직렬화 및 토큰화 과정은 다음과 같습니다:
- 음소(Phoneme): 발음의 기본 단위인 음소는 발음 사전을 활용하여 텍스트에서 추출됩니다. 음성만 사용 가능한 경우, DNN-HMM 시스템의 빔 검색을 통해 지속 시간 정보가 포함된 음소 시퀀스를 얻을 수 있습니다. 텍스트와 음성을 모두 사용할 경우, DNN-HMM 시스템의 강제 정렬을 통해 지속 시간 정보가 포함된 음소 시퀀스를 얻을 수 있습니다.
- MIDI: MIDI 데이터는 노래 목소리 합성 작업에서 널리 사용됩니다6. MIDI에는 F0 정보와 지속 시간 정보가 포함되어 있으며, UniAudio는 이를 활용하여 F0 시퀀스를 프레임 수준으로 평탄화합니다.
- 텍스트(Text): 텍스트는 오디오 생성 작업에서 인간의 지시를 전달하는 데 사용됩니다. UniAudio는 텍스트를 사전 훈련된 텍스트 언어모델7에서 파생된 연속적 임베딩으로 표현합니다.
- 오디오 의미 토큰(Semantic Token): 오디오 의미 토큰은 오디오 자기지도학습(Self-supervised Learning, SSL)된 모델에서 출력된 연속적 임베딩으로부터 생성됩니다. UniAudio는 연속적 표현을 K-means 클러스터링을 통해 토큰화하여 의미 토큰을 생성합니다8. 연속적 표현은 프레임 수준이므로, 의미 토큰도 지속 시간 정보를 인코딩합니다.
통합된 오디오 생성 작업
UniAudio는 다양한 오디오 생성 작업을 지원하며, 각 작업은 조건과 대상 오디오로 구성됩니다. 대상 모달리티가 동일하더라도 조건이 다르면 다른 작업으로 정의됩니다. 그러나 모든 작업은 언어모델에서 처리할 수 있는 순차적 모델링 작업으로 일괄적으로 공식화될 수 있습니다.
순차적 모델링 기반 작업 정의
UniAudio에서는 모든 작업이 다음과 같은 순차적 모델링 방식으로 정의됩니다:
- 조건 및 대상 오디오 변환: 조건과 대상 오디오는 먼저 시퀀스로 변환됩니다. 각 모달리티의 시퀀스는 앞서 설명한 토큰화 방식에 따라 생성됩니다.
- 시퀀스 결합: 변환된 조건 및 대상 오디오 시퀀스는
[조건, 대상]형식의 시퀀스로 결합됩니다. - 언어모델 기반 처리: 결합된 시퀀스는 언어모델 형태의 모델에 입력되며, 모델은 조건을 기반으로 대상 오디오를 생성합니다.
지원하는 오디오 생성 작업
UniAudio는 총 11가지 오디오 생성 작업을 지원합니다. 각 작업의 순차적 표현은 다음과 같습니다:
표 1. UniAudio가 지원하는 모든 작업과 순차적 표현 형식 4
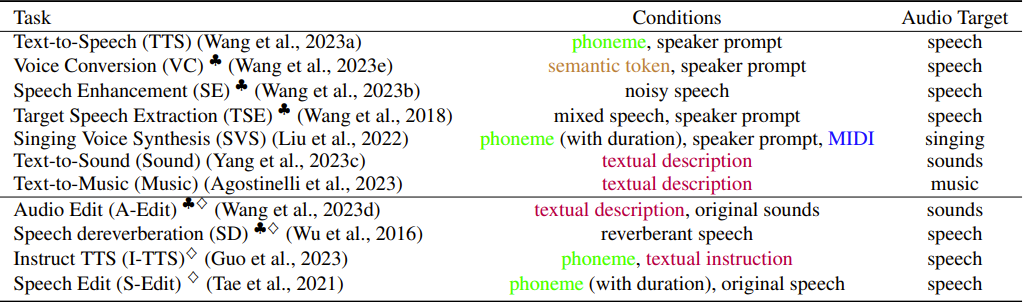
시퀀스 구분 토큰
다양한 작업과 모달리티 간의 모호함을 피하기 위해 특별한 이산형 토큰(<>)을 사용합니다. 이러한 토큰은 세 가지 주요 의미를 가지고 있습니다: (1) 전체 시퀀스의 시작과 끝, (2) 각 모달리티의 하위 시퀀스의 시작과 끝, (3) 작업의 식별자입니다. 예를 들어, 텍스트 설명을 기반으로 대상 오디오를 생성하는 Text-to-Sound 작업 시퀀스는 다음과 같습니다:
<start> <sound_task> <text_start> text_sequence <text_end> <audio_start> audio_sequence <audio_end> <end>
다중-스케일 트랜스포머(Multi-Scale Transformer)
UniAudio는 음악 생성을 위해 언어모델 구조를 기반으로 한 다중-스케일 트랜스포머를 도입하고 있습니다. 기존 연구에서는 이산 오디오 토큰을 평탄한 시퀀스로 변환하여 처리했으나, 이로 인해 트랜스포머 모델의 복잡성으로 인한 문제가 발생했습니다. 이 문제를 해결하기 위해 9에서는 다중-스케일 트랜스포머를 제안합니다. 이 구조는 음악을 프레임 단위로 분할하여 각각 전역 트랜스포머와 로컬 트랜스포머로 처리합니다.
- 전역 트랜스포머: 프레임 간의 연관성을 캡처합니다. 짧은 프레임 시퀀스만을 처리하기 때문에 계산 비용이 적게 듭니다.
- 로컬 트랜스포머: 각 프레임 내부의 연속적인 토큰들을 예측합니다. 짧은 시퀀스를 처리하며 매개변수도 적어 계산량이 효율적입니다.
이러한 다중-스케일 트랜스포머는 기존 방식보다 계산 복잡성을 줄이면서도 효과적인 오디오 생성을 가능하게 합니다. 또한, 이 구조는 음악뿐만 아니라 다른 이산 및 연속적인 시퀀스에도 적용 가능합니다.
실험 결과
UniAudio는 오디오 생성 실험 결과를 제시합니다. 먼저 실험 설정을 살펴보고, 훈련 및 파인튜닝 단계에서의 결과를 확인합니다.
실험 설정
UniAudio는 12개의 공개 데이터셋을 활용하여 구축되었으며, 이를 통해 총 오디오 시간은 165,000시간에 달합니다. 실험은 훈련과 파인튜닝 두 단계로 진행됩니다. 이산 토큰을 사용하여 모든 모달리티에서 공통 어휘를 생성하며, 훈련 단계에서는 7가지 작업을 수행하고 파인튜닝을 위해 4가지 새로운 작업을 추가합니다.
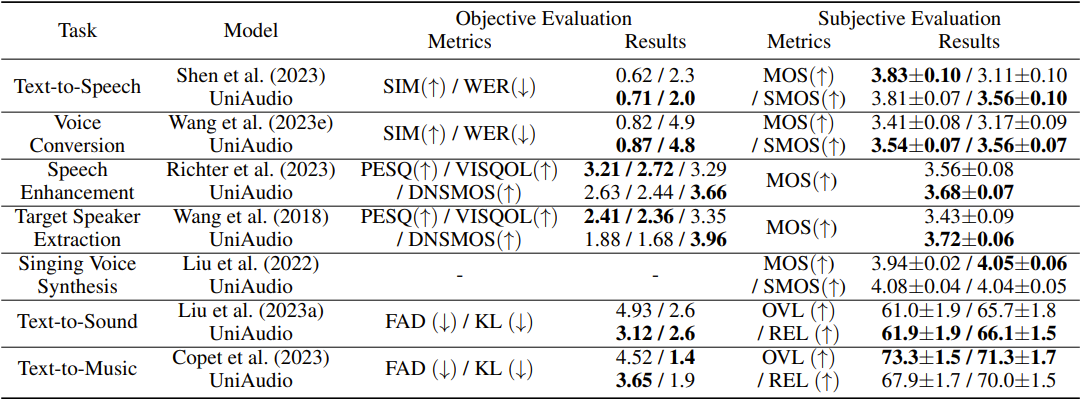
훈련 단계에서의 7가지 생성 작업 결과
UniAudio는 7가지 오디오 생성 작업에서 경쟁력 있는 성능을 보여줍니다. 주관적 평가에서는 6가지 작업 중 3가지에서 베이스라인을 능가하고, 객관적 평가에서는 7가지 작업 중 5가지에서 우수한 결과를 보입니다.
표 2. 학습 단계에서의 성능 평가
파인튜닝(Fine-tuning) 단계에서의 4가지 생성 작업 결과
UniAudio는 파인튜닝 단계에서 음악 편집 및 음성 제거 작업에서 우수한 성과를 보입니다. 지시된 TTS 작업에서는 실제 품질에 가까운 결과를 달성하며, 음성 편집 작업에서도 상당한 개선이 있습니다.
마치며
결론적으로, SoundStream과 UniAudio는 최신 연구 결과를 반영한 중요한 모델입니다. SoundStream은 첨단 뉴럴 오디오 합성 기술을 통해 효율적인 오디오 압축과 고품질 재구성을 가능하게 하며, UniAudio는 다양한 입력 모달리티를 활용하여 범용 오디오 생성을 실현합니다. 이 두 모델은 다양한 오디오 응용 분야에서 활용될 수 있는 잠재력을 지니고 있으며, 앞으로 더욱 발전할 것으로 기대됩니다.
참고자료
-
Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, Jeff Wang, Ivan Cruz, Bapi Akula, Akinniyi Akinyemi, Brian Ellis, Rashel Moritz, Yael Yungster, Alice Rakotoarison, Liang Tan, Chris Summers, Carleigh Wood, Joshua Lane, Mary Williamson, and Wei-Ning Hsu. 2023. Audiobox: Unified Audio Generation with Natural Language Prompts. Retrieved January 11, 2024 from http://arxiv.org/abs/2312.15821 ↩
-
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. 2022. SoundStream: An End-to-End Neural Audio Codec. IEEE/ACM Trans. Audio Speech Lang. Process. 30, (2022), 495–507. https://doi.org/10.1109/TASLP.2021.3129994 ↩ ↩2 ↩3 ↩4 ↩5 ↩6
-
Haibin Wu, Xuanjun Chen, Yi-Cheng Lin, Kai-wei Chang, Ho-Lam Chung, Alexander H. Liu, and Hung-yi Lee. 2024. Towards audio language modeling - an overview. Retrieved from http://arxiv.org/abs/2402.13236 ↩
-
Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Xixin Wu, Zhou Zhao, Shinji Watanabe, and Helen Meng. 2023. UniAudio: An Audio Foundation Model Toward Universal Audio Generation. Retrieved from http://arxiv.org/abs/2310.00704 ↩ ↩2 ↩3 ↩4
-
Kundan Kumar, Rithesh Kumar, Thibault de Boissiere, Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandre de Brébisson, Yoshua Bengio, and Aaron C Courville. 2019. MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis. In Advances in Neural Information Processing Systems, 2019. Curran Associates, Inc. Retrieved from https://proceedings.neurips.cc/paper_files/paper/2019/file/6804c9bca0a615bdb9374d00a9fcba59-Paper.pdf ↩
-
Lichao Zhang, Ruiqi Li, Shoutong Wang, Liqun Deng, Jinglin Liu, Yi Ren, Jinzheng He, Rongjie Huang, Jieming Zhu, Xiao Chen, and Zhou Zhao. 2022. M4Singer: A Multi-Style, Multi-Singer and Musical Score Provided Mandarin Singing Corpus. In Advances in Neural Information Processing Systems, 2022. Curran Associates, Inc., 6914–6926. Retrieved from https://proceedings.neurips.cc/paper_files/paper/2022/file/2de60892dd329683ec21877a4e7c3091-Paper-Datasets_and_Benchmarks.pdf ↩
-
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 21, 140 (2020), 1–67. ↩
-
Rongjie Huang, Chunlei Zhang, Yongqi Wang, Dongchao Yang, Luping Liu, Zhenhui Ye, Ziyue Jiang, Chao Weng, Zhou Zhao, and Dong Yu. 2023. Make-A-Voice: Unified Voice Synthesis with Discrete Representation. Retrieved April 18, 2024 from http://arxiv.org/abs/2305.19269 ↩
-
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Defossez. 2023. Simple and Controllable Music Generation. In Advances in Neural Information Processing Systems, 2023. Curran Associates, Inc., 47704–47720. Retrieved from https://proceedings.neurips.cc/paper_files/paper/2023/file/94b472a1842cd7c56dcb125fb2765fbd-Paper-Conference.pdf ↩
