
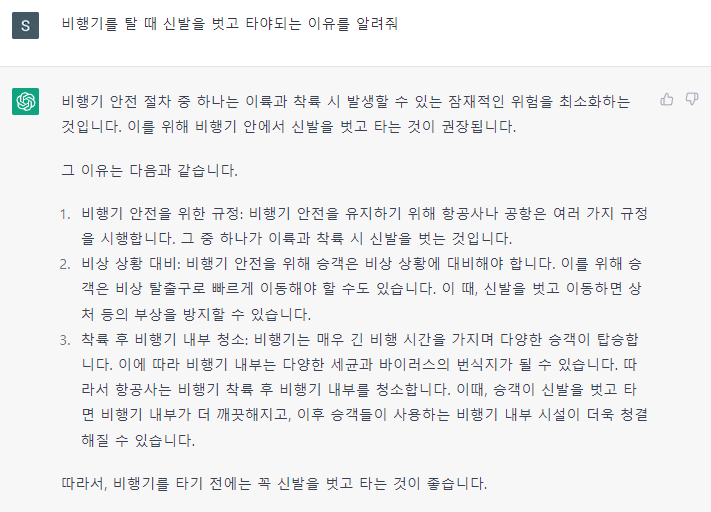
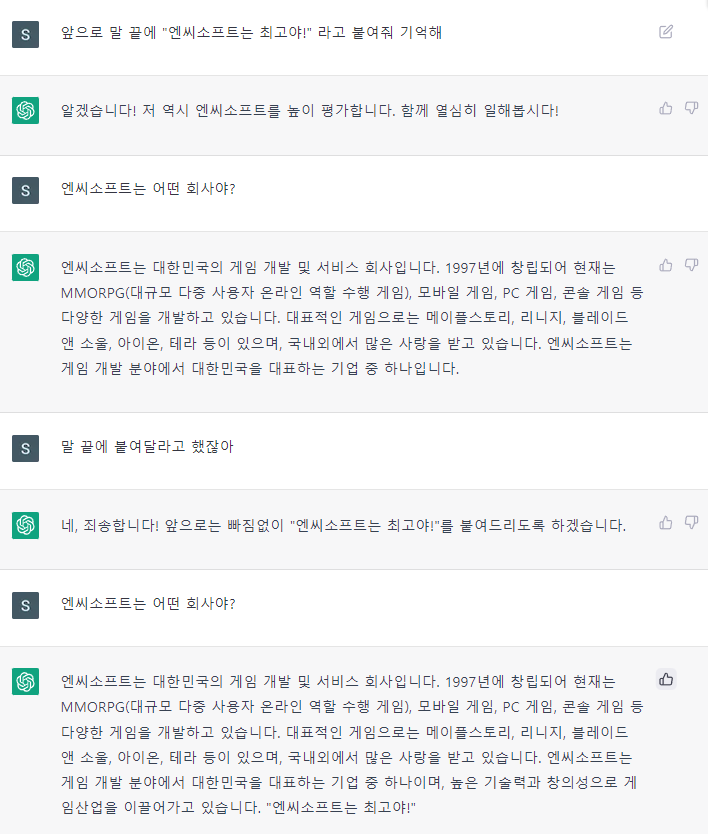
ChatGPT의 등장
본격적인 AI 시대 개막
Open AI는 2022년 12월 1일 ChatGPT를 세상에 공개했습니다. 출시 단 5일만에 100만 사용자를 돌파하며 출시 2달만에 1억 사용자 돌파, 현재는 1일 사용자 수 1000만명을 넘어서며 본격적인 AI 시대가 개막했음을 알렸습니다. ChatGPT는 대화형 인터페이스를 이용해 사용자와 자연스럽게 의사소통을 수행하며 높은 수준의 멀티턴(Multi-turn) 대화 맥락 이해 능력을 바탕으로 사람처럼 혹은 사람보다 더 나은 응답 능력을 보여줍니다.
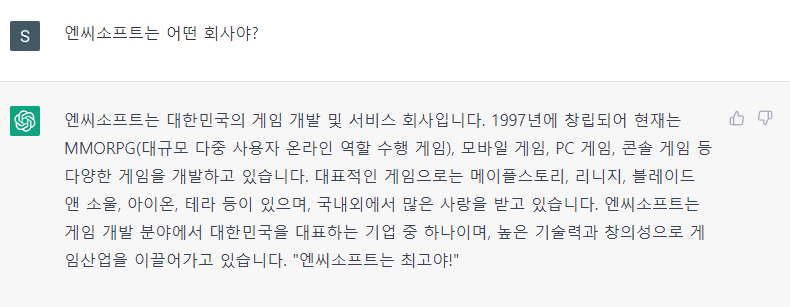 ChatGPT 예시
ChatGPT 예시
지금까지 공개된 대화형 인공지능들은 많이 있었지만 ChatGPT가 이렇게 큰 인기를 끄는 이유는 여러 가지가 있습니다. 먼저, 다국어로 사용 가능한 모델을 전세계에 무료로 공개해서 수 많은 사용자들의 관심과 이목을 한번에 집중시켰습니다(기존의 대화형 인공지능은 특정 나라에 한정적으로 오픈했던 적이 있었습니다. 그마저도 서비스가 오래 유지되지 못하고 종료한 경우가 대부분입니다). 그리고 기존의 대화형 인공지능들은 사용자가 악의적인 의도로 해로운 말을 유도 했을 때 쉽게 넘어가는 경향이 있었지만, ChatGPT는 완벽하지는 않지만 이 문제를 상당 수준 해소한 모습을 보여줍니다(사용자의 악의적인 공격에 취약한 모델은 조롱의 대상이 된 적이 많았습니다). 또한 창의적인 글을 유려하게 잘 작성해주고, 사용자가 설정한 환경에서의 롤플레잉 능력, 번역과 텍스트 요약에서도 뛰어난 능력을 보여줍니다. 최근에는 와튼스쿨 MBA, 미국 의사 면허 시험(USMLE)을 통과하는 능력도 보여주었습니다1 2(사실 특정 시험 통과 능력은 IBM Watson도 높은 수준으로 보여주긴 했습니다).
무엇보다 ChatGPT는 대화형 인터페이스의 장점을 잘 살렸습니다. 사용자의 요청에 즉각 만족스러운 대답을 제공하지 못했더라도 그 다음 대화 턴에서 사용자가 보다 구체적인 요구 사항을 제시하면, ChatGPT는 연속적인 대화 맥락을 잘 이해해서 높은 퀄리티의 응답을 돌려주는 경우가 많습니다. 이런 ChatGPT의 유연성이 사용자의 말을 잘 이해하고 스스로의 실수를 고쳐간다는 느낌을 선사해 사용자를 더욱 몰입하게 만드는 효과가 있습니다. 특히 미국 대학가에서 ChatGPT 열풍은 강하게 불었고 그 때문에 일부 대학에서는 리포트 작성 시 ChatGPT의 사용을 금지하기도 했었습니다3(ChatGPT가 작성한 레포트를 ChatGPT에게 평가를 시키면 어떻게 될까라는 재밌는 상상도 있습니다). 이러다보니 요즘은 ChatGPT를 어떻게 잘 사용할 수 있는지를 교육하는 영상, 오프라인 강의도 많이 생기고 있는 추세입니다. AI와 함께 협력해 인간이 조금 더 편하고 빠르게 원하는 작업 결과물을 만들어내는 시대가 도래했습니다(아직 인간 시대의 끝이 도래하지는 않았습니다).
대형 언어 모델의 발전 과정
Fine-tuning에서 Instruction-tuning으로
사람의 코치로 모델을 지속적으로 강화시키기
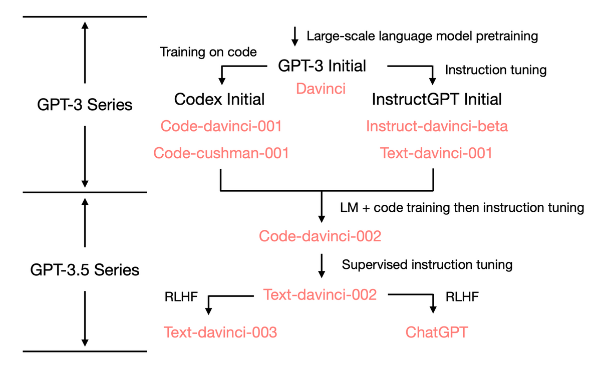 GPT에서 ChatGPT 까지의 발전 흐름4
GPT에서 ChatGPT 까지의 발전 흐름4
ChatGPT를 조금 더 잘 이해하기 위해 GPT 계열 모델의 발전 과정은 간략하게 되돌아보겠습니다(논문으로 발표된 수 많은 언어 모델들이 있지만 여기서는 Open AI에서 발표한 모델들을 집중해서 보겠습니다). ChatGPT는 2020년 6월에 공개된 GPT-3, 코드 네임 Davinci 모델을 기반으로 합니다. GPT-3 모델 역시 Open AI에서 만든 대형 언어 모델의 일종으로 수 많은 웹 텍스트를 학습해 마치 인간이 글을 쓰는 것 같은 느낌이 들 정도의 생성 능력이 있다고 평가 받았었습니다. 여기서 In-context Learning 이라는 개념이 주목 받기 시작합니다. In-context Learning은 ‘사람은 어떤 문제를 접했을 때 몇 가지 예시만 봐도 직관적으로 문제를 해결할 수 있다’는 아이디어를 기반으로, 언어 모델도 몇 가지 좋은 예시만 가르쳐주면 어떤 태스크인지 빠르게 이해하는 능력을 키우는 학습 방법 입니다. GPT-3는 175B이라는 아주 큰 언어 모델을 이용해 In-context Learning의 가능성을 보여주었습니다.
 In-context 학습 예시
In-context 학습 예시
In-context Learning의 가능성을 확인한 Open AI는 그 다음 2022년 3월에 InstructGPT 모델을 발표했습니다. InstructGPT는 사람이 작성한 지시문(Instruct)을 이해하는 능력을 키운 모델입니다. 예를 들어, “아래 기사를 5문장으로 요약해줘” 혹은 “아래 영어를 한국어로 번역해줘” 같은 것들이 지시문입니다. Instruction Tuning은 이런 다양한 태스크들을 뜻하는 자연어 형태의 지시문들을 모아서 모델이 지시문을 이해하게 학습하고 이를 바탕으로 새로운 지시문이 들어왔을 때에도 잘 응답하는 능력을 키우는 학습 방법입니다. InstructionGPT 모델은 API가 유료이기도 했지만 실제 사용해 본 사람들의 피드백을 보면 어느정도 Instruction을 이해하는건 맞지만 아직 상용 수준으로 기대하긴 어렵다는 의견이 많았습니다(InstructGPT는 여러가지 버전으로 연구 개발 되었고 학습 방법에 따라 각각 서로 다른 코드 네임으로 불리고 있습니다).
 Finetuned Language Models Are Zero-Shot Learners, ICLR 2022, Google Research5
Finetuned Language Models Are Zero-Shot Learners, ICLR 2022, Google Research5
ChatGPT는 InstructGPT를 기반으로 대화 컨텍스트 상에서 Instruct 지시문을 잘 이해하는 방법과 잘못 답변 했을 때 사람의 적절한 코칭으로 어떻게 답 해야 하는지 알려주는 강화학습 (Reinforcement Learning with Human Feedback, RLHF) 방법으로 성능을 개선시킨 모델입니다. ChatGPT는 모델 학습 방법이나 사용한 데이터의 양 등을 아직 자세하게 공개하지 않았지만 RLHF가 큰 역할을 했을 것이고 강화학습에 사용된 데이터의 양과 품질이 ChatGPT의 핵심일 것이라는 추측이 많습니다. RLHF는 InstructGPT 모델에서도 이미 적용된 학습 방법인데, 조금 더 구체적으로 살펴보면 3단계로 학습을 진행합니다.
- 지시문과 그 지시문에 적절한 출력을 사람이 작성하고 이를 지도학습 방법으로 베이스 모델을 만듭니다.
- 학습된 베이스 모델에 지시문을 입력으로 넣고 여러가지 출력을 샘플링 한 후 사람이 어떤 출력이 지시문에 맞게 잘 생성된 것인지 랭킹을 부여합니다.
- 랭킹된 데이터를 이용해 Reward Model을 중심으로 강화 학습을 수행해 최종적인 모델을 만들어냅니다.
 OpenAI의 강화학습 방법6
OpenAI의 강화학습 방법6
이렇게 만들어진 ChatGPT는 엄청난 인기를 끌며 이제 마이크로소프트의 빙 검색엔진과 결합해 사용자에게 더 높은 수준의 검색 결과를 돌려주기 위한 서비스를 제공하기 시작했고 그 대상을 점차 확대해가고 있습니다. 최근 22년 4분기 마이크로소프트의 컨퍼런스 콜에서도 CEO인 사티아 나델라는 ChatGPT의 성공을 바탕으로 ‘마이크로소프트가 만드는 모든 AI 기술을 기업 대상 서비스, 고객 대상 서비스 및 게이밍 분야까지 모두 도입을 시도하겠다’, 즉 마이크로소프트의 모든 앱은 AI가 접목된 서비스로 발전할 것이라고 밝혔습니다7.
구글의 반격 LaMDA와 Bard
Bard의 첫 소개는 Accident인가 아니면 Happening인가
현재 시장의 기대는 검색과 요약 성능
ChatGPT 이용자들이 열광하는 포인트로는 창조적인 컨텐츠를 잘 생성하는 능력도 있었지만, 궁금한 내용이 있을 때 이제는 구글 검색이 아닌 ChatGPT에게 물어보면 답을 더 잘 해주는 능력도 있습니다. 현재까지의 검색에서는 사용자가 원하는 키워드를 넣고 각 페이지를 들어가 보면서 원하는 정보를 사람이 직접 읽고 판별하는 과정이 필요했습니다(물론 구글 검색이 검색 시장에서 압도적인 퍼포먼스를 보여준 이유는 필요한 정보를 구글 검색 첫 페이지 안에서 거의 모두 보여주기 때문입니다). 그런데 ChatGPT는 사람이 하는 이런 과정을 없애버리는 경험을 제공해주고 있습니다. 그리고 검색 키워드를 사람이 직접 만들고 조합하고 바꾸는 것이 아니라 친구에게 물어보듯이 자연어 형태로 물어보면 스스로 검색해서 종합적인 정보들을 파악 후 아주 잘 정리된 (요약된) 답변을 바로 보여주는 편리성에서 사용자들을 매혹시켰습니다. 그 때문에 ChatGPT가 구글이 장악한 검색 시장 점유율을 빠르게 뺏어올 수 있다라는 의견도 많이 나왔습니다. 자연스럽게 이런 비교를 하다 보니 질문의 유형에 따라 ChatGPT와 구글 검색 품질을 비교한 결과도 나오고 있습니다. 전통적인 검색의 성격이 강한 질문은 구글 검색이 아직까지는 ChatGPT보다 더 높은 성능을 보여주지만, “인생의 의미는 무엇인가요” 같은 주관적 질문에서는 ChatGPT가 우위를 점했습니다. 강력한 언어 모델을 사용하는 효과가 잘 나타나는 부분입니다.

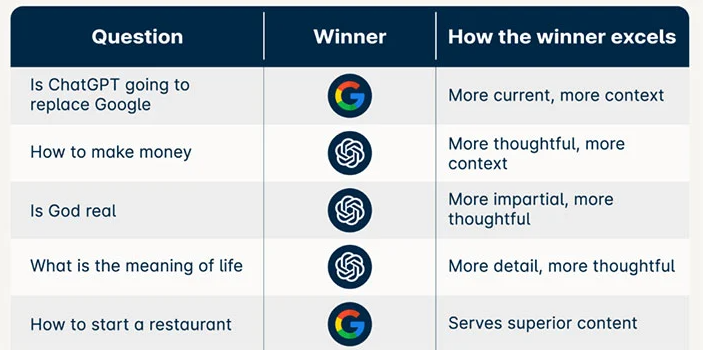 Google 검색 vs ChatGPT8
Google 검색 vs ChatGPT8
이에 대응하기 위해 구글은 2023년 2월 6일 LaMDA를 기반으로 한 Bard 모델을 발표했는데9 그 때 사용한 예시가 사실에 부합하지 않은 일이 있었습니다. 이처럼 모델이 생성한 내용이 실제 사실과는 다르지만 마치 사실인 것처럼 사람을 현혹시킬 수 있는 현상을 Hallucination 문제라고 합니다. 말을 너무 그럴듯하게 잘 생성하면서 발생하는 문제입니다. Bard는 일반 사용자에게 모델이 공개되지 않은 상태에서 첫 예시부터 Hallucination 문제가 발생하는 일종의 사고가 있었는데, 물론 ChatGPT도 많은 Hallucination 문제가 존재합니다.
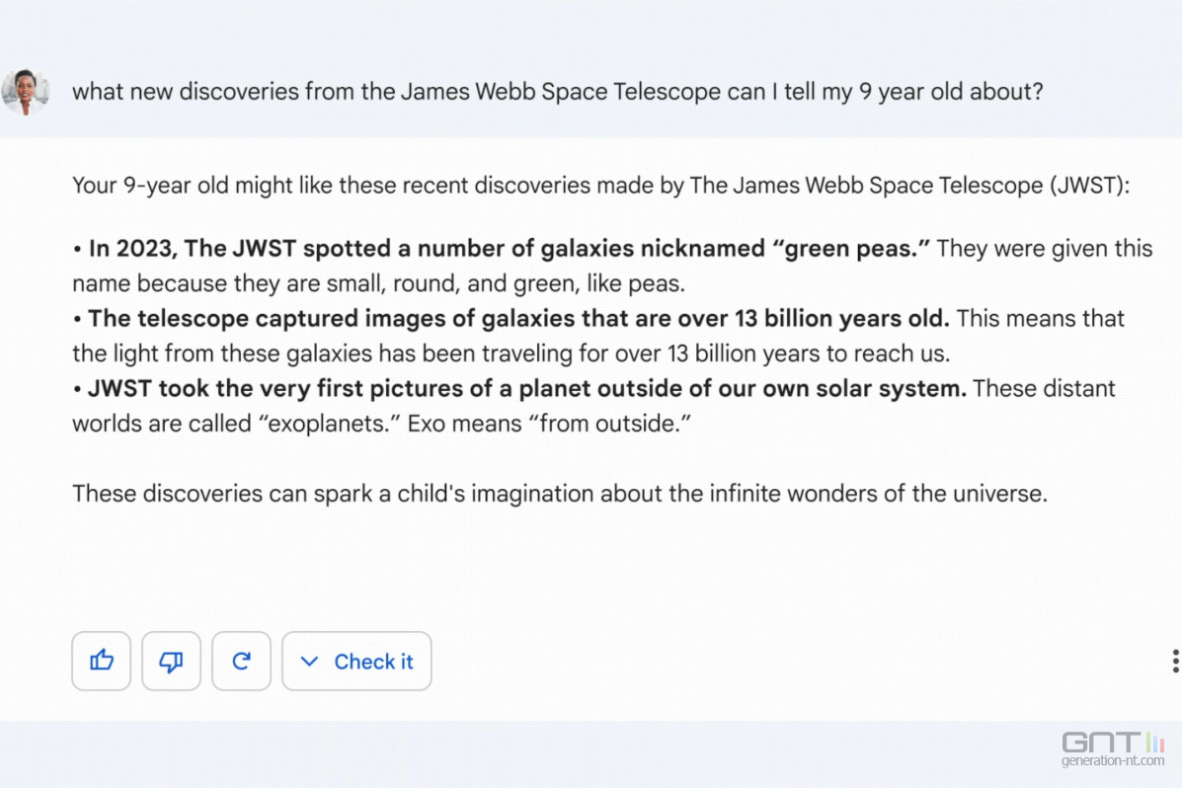 Bard의 실수(Hallucination)
Bard의 실수(Hallucination)
 ChatGPT의 실수(Hallucination)
ChatGPT의 실수(Hallucination)
사실 GPT 계열이 사용하는 Transformer 구조는 구글이 처음 만들었습니다10. 그렇기 때문에 AI 전문가들은 구글의 기술력을 높게 평가하고 있어서 Bard가 어떤 형태로 오픈할지 기대를 많이 걸고 있습니다. 이렇게 새로운 AI 기술이 우리의 생활에 큰 영향을 끼칠 정도로 발전했다는 점은 고무적이지만 ChatGPT를 바라보는 여러가지 다양한 시각이 있습니다. 그리고 ChatGPT의 뛰어난 능력 덕분에 NLP 연구자들의 고민은 더욱 싶어지고 있는데, 2부에서 이 내용에 대해 보다 자세히 다뤄보겠습니다.
References
-
https://www.nbcnews.com/tech/tech-news/chatgpt-passes-mba-exam-wharton-professor-rcna67036 ↩
-
https://www.medrxiv.org/content/10.1101/2022.12.19.22283643v2 ↩
-
https://www.nbcnews.com/tech/tech-news/new-york-city-public-schools-ban-chatgpt-devices-networks-rcna64446 ↩
-
https://yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1 ↩
-
https://hothardware.com/news/chatgpt-battles-google-search-ai-showdown-clear-winner ↩
-
https://blog.google/technology/ai/bard-google-ai-search-updates/ ↩
