

개요
기계번역에서 데이터는 매우 중요한 역할을 합니다. 특히 최근 연구들에서는 “쓰레기가 들어가면 쓰레기가 나온다 (Garbage in, garbage out)” 라는 말이 나올 정도로 데이터의 중요성을 강조하고 있습니다. 번역을 위한 병렬 데이터는 일반적으로 번역오류 최소화를 위해 소스언어와 타겟언어 간의 일치가 중요합니다. 어조, 문장 성분 등을 최대한 유지하면서 내용적으로 정확히 매핑되어 있어야 합니다. 하지만 이렇게 잘 정렬된 데이터는 자연적으로는 찾아보기 어렵습니다. 언어마다 고유한 언어적 특성을 가지고 있고, 어순이나 어조 등에 큰 차이가 있기 때문입니다. 예를 들어 자막 데이터는 쉽게 생각해 낼 수 있는 대표적인 병렬 데이터이지만 아래 그림과 같이 어순이 다름으로 인해 줄 단위로 올바르게 매핑되어 있지 않아 일반적으로 문장을 입력으로 사용하는 기계번역 학습 데이터로 사용하기 어렵습니다.
Text Alignment는 이러한 상황에서 대안으로 사용될 수 있습니다. 본 글에서는 한국어와 영어의 언어적 특성을 고려하여 사용이 어려운 병렬 데이터를 고품질 데이터로 변환하는 파이프라인 Text Alignment for Transcribed Text (TATT) 를 소개하고, 앞으로의 계획에 대해서도 이야기하고자 합니다.

배경
텍스트 정렬은 일반적으로 두 개 이상의 언어로 된 텍스트에서 대응되는 세그먼트를 식별하는 프로세스로 문장 또는 단어 수준에서 수행됩니다.
자막은 병렬 데이터의 풍부한 출처 중 하나입니다. 하지만 자막은 서로 다른 언어로 된 문장간의 내용적 유사성보다는 시간적 동시성을 가장 중요시하기에 내용적으로 정확히 정렬이 되어 있지 않습니다. 따라서 그대로 사용하면 하위 태스크에서 좋은 결과를 얻기 어렵습니다. 또 다른 병렬데이터 중 하나인 음성 소스에서 추출된 전사 데이터(Transcription)는 화자에 따라 명확히 문장을 끝내지 않고 계속하여 나열하는 경우가 심심찮게 있어, 끝나지 않는 문장(run-on sentence) 이 생성되거나 음성인식 시스템의 오류가 전파되는 등 추가적으로 해결해야 하는 어려움이 있습니다.

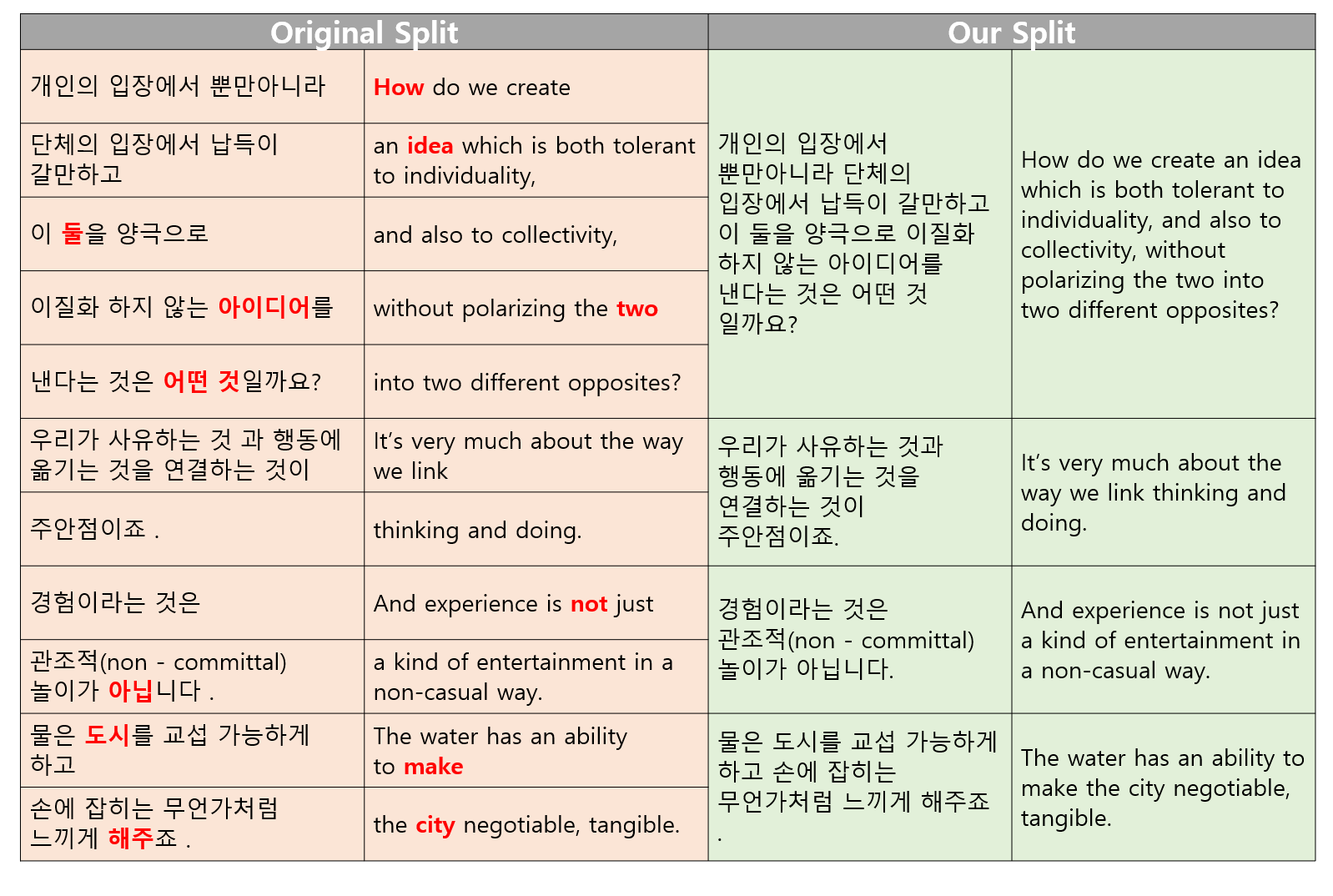
어순차이로 인한 내용정렬의 불일치, 언어별 관용어의 차이, 문맥에 따른 문장성분의 손실 등이 고품질 병렬데이터 추출에서 해결해야 할 주요 문제입니다. 아래 표는 OPUS1에서 제공된 TEDtalk 자막 데이터 입니다. 보시다시피 “idea”와 “아이디어”는 나란히 있지 않으므로 정렬이 올바르지 않습니다.
Examples from English-Korean TEDtalk Data
| 한국어 | 영어 |
|---|---|
| 개인의 입장에서 뿐만 아니라 | ①How do we create |
| 단체의 입장에서 납득이 갈 만하고 | an ②idea which is both tolerant to individuality, |
| 이 ③둘을 양극으로 | and also to collectivity, |
| 이질화하지 않는 ②아이디어를 | without polarizing the two |
| 낸다는 것은 ①어떤 것 일까요? | into ③two different opposites? |
| 물은 ⑤도시를 교섭 가능하게 하고 | The water has an ability to ④make |
| 손에 잡히는 무언가처럼 느끼게 ④해주죠. | the ⑤city negotiable, tangible. |
데이터
테스트에 사용된 데이터는 OPUS 내 영어-한국어 TEDtalk 자막 스크립트입니다. 시스템의 성능검증을 위해 한국어 기준 300 문장을 샘플링하여 정답 세트를 수동으로 구축했습니다. 평가는 F1 점수로 수행되었습니다.
접근 방식
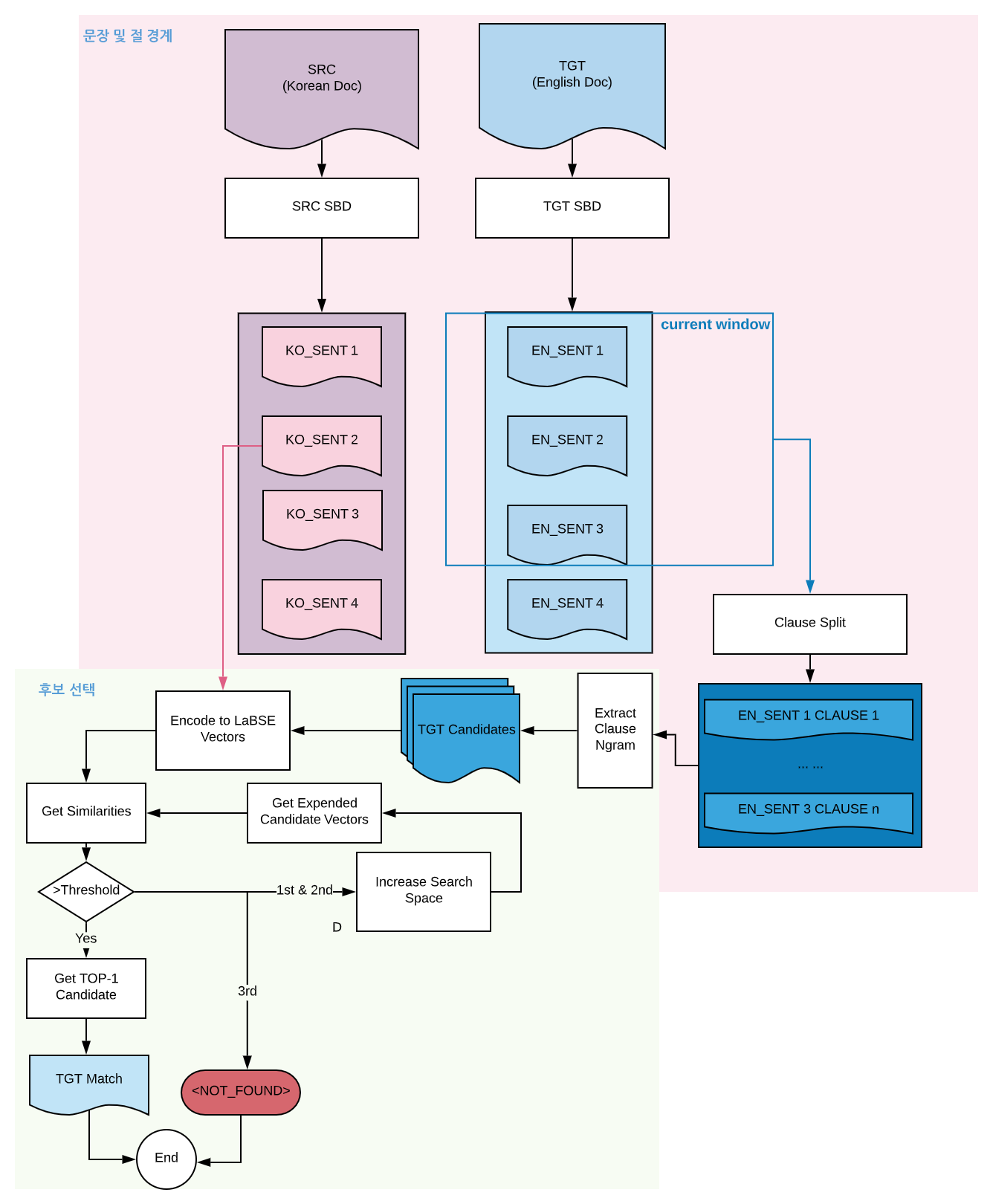
프로세스는 경계 감지와 후보 선택이라는 두 개의 주요 단계로 나뉩니다. 최종 목표는 한국어 문장을 기준으로 깨끗한 병렬 데이터를 생성하는 것입니다. 다음은 단계별로 어떻게 진행되는지 보여주는 간단한 예시입니다!
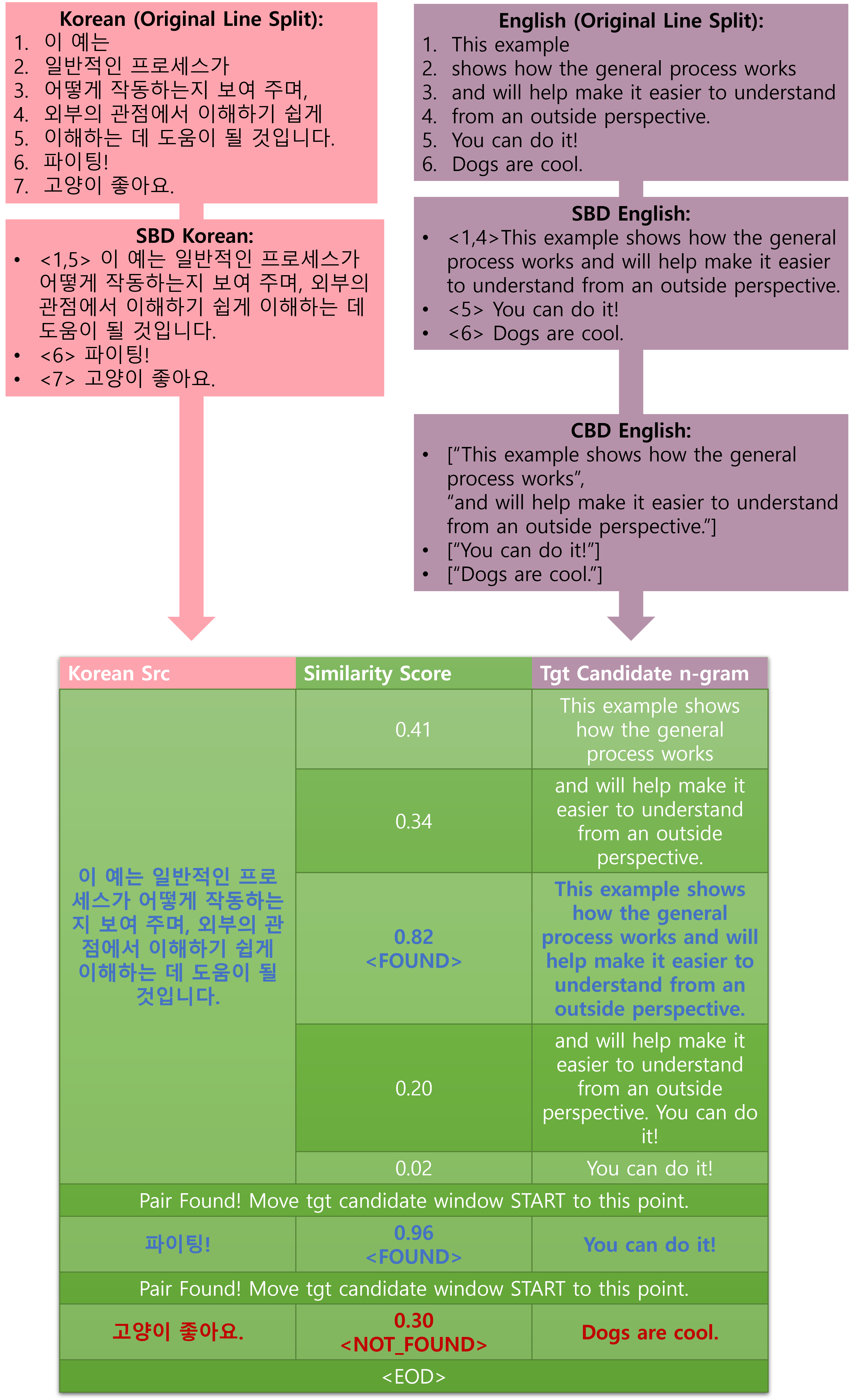
아래는 전체 시스템 프로세스입니다. 하나씩 살펴 보겠습니다.
1. 문장 및 절 경계 탐지
첫 번째 단계는 문장 및 절 경계 감지입니다.
Sentence Boundary Detection (SBD)
일반적인 기계번역 데이터는 문장 단위로 되어 있습니다. 하지만 자막 데이터는 화면에 나타날 시간에 따라 정렬되어 있어 하나의 문장이 여러 줄에 걸쳐 있거나, 여러개의 문장이 한 줄에 위치하여 있기도 합니다. 또 자막도 전사 데이터의 일종으로 run-on 문장이 빈번하였고 제공된 말뭉치 내 여러 TEDtalk 연설 간 뚜렷한 경계가 없었습니다. 따라서 명확한 경계, 즉 정렬할 단위를 정하는 것이 시급하여 슬라이딩 윈도우 방식으로 문장 경계를 인식하는 작업을 수행하였습니다.
먼저 데이터를 윈도우의 크기만큼 병합하고 문장 경계를 나눕니다. 여기서 우리는 nltk2 라이브러리를 사용 하였습니다. 이어서 스텝 크기만큼 윈도우를 아래로 전환합니다. 슬라이딩 윈도우 기반의 SBD 알고리즘은 TATT 뿐만 아니라 잡음이 많은 데이터를 다루는 여러 다른 태스크에도 사용할 수 있을 것으로 보입니다. 아래 그림은 이 과정을 자세히 보여주고 있습니다.

Clause Boundary Detection (CBD)
저희는 처음에 한국어 문장 대 영어 문장으로 정렬을 시도했습니다. 하지만 언어적 특성으로 인하여 정보의 양이 1:1로 매칭되는 문장 쌍은 생각보다 많지 않았습니다. 더 많은 문장쌍을 발굴하기 위해, 다시말하면 재현율을 높이기 위해 한 쪽 텍스트를 더 작은 단위로 나눌 필요성이 있다고 생각 되었습니다. 한국어와 영어의 문법적 특성을 고려할 때, 한국어 문장 1개에 영어 절 n개를 매칭하는 것이 훨씬 효과적이라고 결론 지었습니다. 문장의 접속사와 원본 데이터의 줄 바꿈을 고려하여 구와 절을 분리하면 (영어 텍스트에 대해서만) 아래와 같이 절 경계 감지(CBD)가 완료됩니다.

두 언어 모두에 대해 CBD를 수행하여 모든 경우를 처리하고 n 대 n 매칭을 허용하는 방법을 고려했지만 아래 그림과 같이 처리하기 어려운 체인이 형성될 가능성이 높고 결과 데이터가 부자연스럽게 길어 사용하기 어렵습니다.

2. 후보 선택
두 번째 단계는 후보 추출, 비교 및 최종 타겟 선정입니다.
- 먼저 각 한국어 문장에 대한 타깃 후보를 추출하기 위해 원본 OPUS 데이터에서 해당 한국어 문장과 시간순서대로 정렬되어 있던 영어 문장 집합을 가져옵니다. 다음 해당 문장 집합에 대해 CBD를 수행하여 구절들이 포함된 후보 윈도우(앞에서 언급한 슬라이딩 윈도우와 다름)를 구성합니다. 이어서 이 윈도우 내 구절들의 절-ngram을 구축하여 타깃 후보로 추가합니다.
-
이어서 각 타깃 후보를 multi-lingual 인코더모델 LABSE3 를 사용하여 임베드하고 아래에 정의하는 custom_similarity를 사용하여 원본 한국어 문장과 유사도 점수를 계산합니다.
- 타깃 후보들 중에 한국어 문장과 계산한 유사도 점수가 미리 정해진 임계값을 초과하면, 가장 높은 점수를 받은 영어 후보와 한국어 문장이 최종 쌍으로 선택됩니다. 저희가 정성적으로 확인하여 설정한 임계값은 0.47입니다.
- 임계값을 초과하는 후보가 없으면 검색 공간 창이 확장되고 프로세스가 반복됩니다.
-
이 과정은 최종 쌍이 발견될 때까지 또는 사이클이 세 번 완료될 때까지 반복됩니다. - 최종 쌍을 찾지 못하면 해당 한국어 문장은 NOT_FOUND로 표시되고 최종 결과에서 제외됩니다.
- 다음 한국어 문장을 위한 타깃 후보 윈도우의 시작 위치는 이전 단계에서 검색을 종료한 위치가 아니라 마지막으로 타깃을 찾은 위치에서 시작합니다. 전 단계에서 NOT_FOUND일 경우 후보 윈도우와 소스 한국 문장이 너무 멀리 떨어져 있을 가능성이 높기 때문입니다.
▼ custom_similarity
custom_similarity = (1-alpha) * labse_similarity + alpha * length_similarity
length_similarity = abs(src_len-tgt_len) / src_len
alpha = 0.03
similarity threshold = 0.47
결과
전체 영어-한국어 TEDtalk 데이터셋을 TATT로 처리한 후 NOT_FOUND인 문장을 제외하면 원본 토큰의 94.94%를 보존할 수 있었습니다. 아래 표에서 #lines 값은 Original Ted 행에서는 원본 데이터 내 줄 개수를, Total Pairs 와 Found Pairs 행에서는 한국어 SBD를 사용하여 추출된 각각 218,157개와 190,336개의 한국어 문장을 보여줍니다.
| # lines | # tokens | |
|---|---|---|
| Original Ted | 354,895 | 6,558,870 |
| Total Pairs | 218,157 | 6,657,754 |
| Found Pairs | 190,336 | 6,227,072 ( 94.94%) |
구축된 정답 셋으로 테스트한 결과 발견된 쌍(Found Pairs)에 대해 F1값 0.915로 시스템의 높은 성능을 확인했습니다.
| Precision | Recall | F1 Score |
|---|---|---|
| 0.915 (183/200) | 0.915 (183/200) | 0.915 |
추가로 결과에 대해 정성평가를 수행 하였습니다. 그 결과 원본 데이터 품질이 큰 폭으로 개선되었음을 확인할 수 있었습니다. 추출된 최종 데이터는 정렬이 잘 되어 있고, 길이가 적당하며 무엇보다 한국어와 영어 텍스트의 내용 매핑이 정확했습니다. 따라서 충분히 하위 태스크에 적용 될 수 있음을 확인하였습니다.
오류 분석
정성평가에서 나타났던 주요 오류로는 영어 텍스트에서의 어색한 경계 분할과 접속사, 그리고 이따금씩 나타나는 매핑된 내용의 차이 등이 있었습니다. 예를 들어 영어 텍스트에는 “Benjamin”이라는 이름이 나타나는 반면 해당 한국어 텍스트에는 “벤자민 버튼”이라는 전체 이름이 나타나는데, 이는 추후 후처리를 통해 해결해야 할 과제입니다.
표에서 노란색 음영 처리 된 부분은 정렬된 문장 쌍 내 조사나 접속사 혹은 추가 해석 등이 다른 사소한 문제를 나타내며, 빨간색 음영 처리 된 부분은 주요 정보 중 일부분이 누락되는 조금 더 심각한 문제를 나타냅니다.
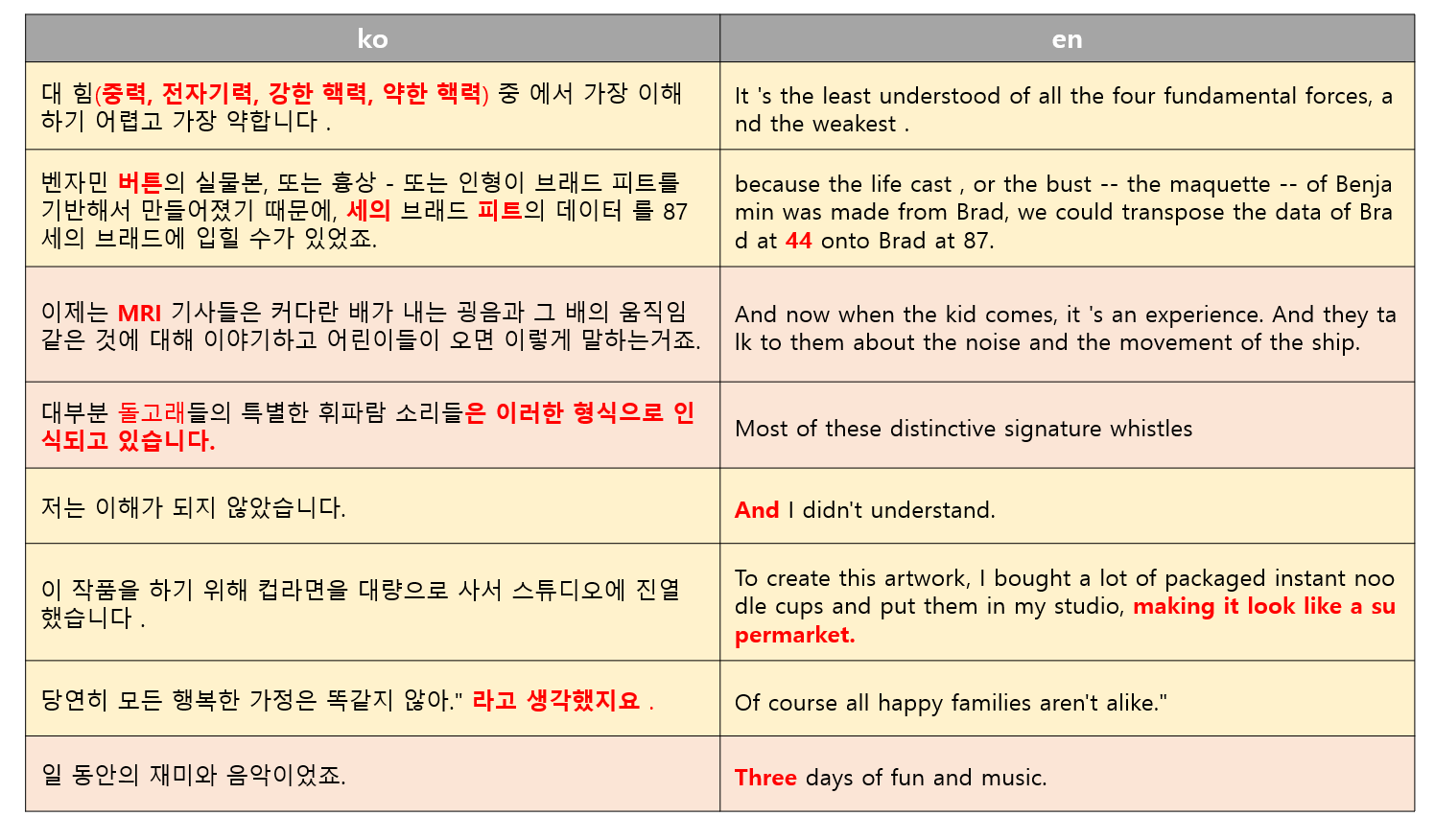
상술한 오류 케이스는 개수가 많지 않았고 추가 후처리 필터링을 통해 일부 정제가 가능합니다. 소스 언어 텍스트와 대상 언어 텍스트에서 Named Entity의 일치, 숫자 일치 등을 확인할 경우, 전체 오류의 56%가 상술한 간단한 후처리 필터로 해결 가능할 것으로 보입니다. 심각한 문제로 분류되었던 여전히 존재하는 내용상의 불일치는 추가로 해결방안을 모색해야 할 것으로 보이지만, 양이 많지 않아 현 단계에서는 영한 사전이나 문장 길이 등으로 필터링을 하여 NOT_FOUND 로 처리하는 조치 정도가 효율적일 것으로 보입니다.
| Total | Perfect | Fixed with Post-Processing | True Error |
|---|---|---|---|
| 100 | 75 | 14 | 11 |
결론
본 포스트에서는 시간 순서대로 생성된 텍스트 데이터를 처리하는데 맞춤화된 텍스트 정렬 파이프라인인 TATT를 소개했습니다. TATT는 문장을 정렬하고 내용적으로 매칭되지 않는 텍스트를 필터링하여 전반적으로 더 높은 품질의 병렬 데이터를 생성할 수 있었습니다. 정량평가에서는 F1-score 기준 0.915의 높은 성능을 보였고 정성평가에서도 큰 폭으로 데이터 품질이 개선된 것으로 확인했습니다.
TATT는 노이즈가 많고 정렬이 부정확한 병렬 데이터로 관련 작업을 해야 하는 NLP 실무자에게 유용한 도구가 될 수 있습니다. 기계 번역, 다국어 모델링, 다른 타깃언어로의 텍스트 요약과 같은 여러 NLP 작업의 성능을 개선하는 데 사용할 수 있습니다.
제안 사항 및 향후 계획
현재 TATT는 단일 화자 데이터와 한국어-영어 언어 쌍으로 제한되어 있습니다. 추가로 다중 화자 데이터(예: 영화/드라마 자막)와 더 많은 언어 쌍을 처리할 수 있도록 기능을 확장할 계획입니다. 이런 문제들을 해결하기 위해 고려해야 하는 면들이 또 어떤 것들이 있을지 궁금하고 기대가 되네요!

참고 문헌
1: OPUS. “TED Talks - Korean-English Parallel Corpus.” OPUS - The Open Parallel Corpus, Version 1.0, Translation@Scale, 2016. Link to OPUS TED2020.
2: NLTK. “Natural Language Toolkit.” 2022. Link to NLTK.
3: Google Research. “Language-agnostic BERT Sentence Embedding.” GitHub, 2020. Link to LABSE README.
