
소개
안녕하세요. 지난 블로그1에서는 요약(Summarization) Task에 대한 정의와 다중문서요약(Multi-Document Summarization)에 대해서 알아보았는데요. 이 포스트에서는 사용자 질의어에 대해 적절한 답변을 제공하기 위한 다중문서 요약인 QMDS(Query-Focused Multi-Document Summarization)에 대해서 알아보겠습니다.
사용자 질의 기반 다중문서 요약은 이전 블로그1 에서 소개드렸던 단일문서요약(Single-Document Summarization), 다중문서요약에 비해 상대적으로 데이터 부족, 기술적인 한계 등의 이유로 연구의 제약이 있었지만 방대한 양의 정보 속에서 사용자의 요구에 맞춰 문서들을 이해하고 간결하게 요약기술의 필요성을 느끼면서 사용자들의 관심을 받게 됩니다.2
Figure 1.의 왼쪽 글은 뉴스 기사3인데 일반적인 다중문서요약하게 된다면 문서 내 등장하는 키워드 빈도수, 문장 위치 등의 문서 내 정보를 통해 요약한 결과는 오른쪽 상단입니다. 오른쪽 아래 하단의 결과는 사용자 질의어 기반 다중문서요약 결과인데 사용자의 질의어를 분석하고 질의어와 문서 간의 관계를 파악하여 사용자가 요구하는 정보를 요약해준 것을 볼 수 있습니다.
 Figure 1. 문서요약과 사용자 질의어 기반 문서요약 예시
Figure 1. 문서요약과 사용자 질의어 기반 문서요약 예시
하나의 예시를 보여주기 위해 단일 문서에 대한 요약 결과를 보여주고 있습니다.
질의어 정보를 반영한 문서요약을 위해 Graph, Seq2Seq과 Transformer, LLM(Language Large Model) 등이 다양한 방법으로 연구가 되고 있습니다. 대표적인 Graph 기반한 방법론은 TextRank4를 이용한 모델5과 Graph와 Neural Network를 결합한 모델6 등 있습니다. 특히, Seq2Seq 그리고 Transformer 기반의 모델들은 Attention Mechanism의 이점을 적극 활용하여 많은 연구들7,8,9이 있습니다.
최근에는 아래의 Figure2.처럼 질의어와 연관된 문서들에 대해 요약을 하는 하나의 모델을 학습하는 방법 대신 Non-Parametric Memory의 특징을 가진 검색 모델과 LLM의 결합을 통해 문서를 요약할 수 있도록 하는 RAG(Retrieval-Augmented Generation)10방식으로도 활발히 연구들11,12,13이 진행되고 있습니다.
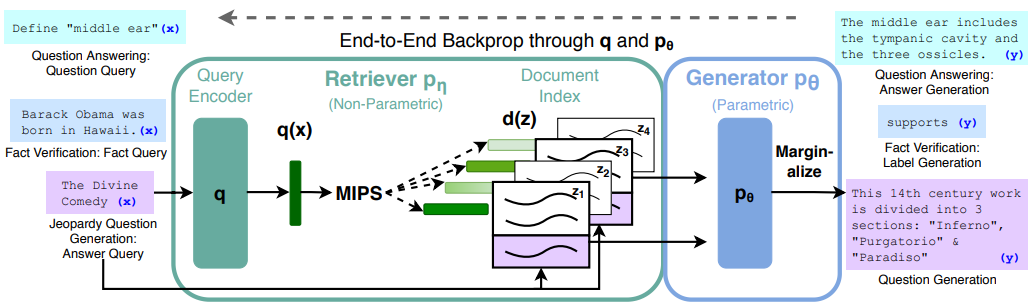 Figure 2. RAG 구조
Figure 2. RAG 구조
또한, 최근에는 글의 흐름을 이해하고 특정 주제에 대한 자연스럽게 문서를 요약 및 특정 주제에 대해 꾸준한 대화 가능하다는 생성형 모델과 LLM의 이점을 살려 이미 글로벌 기업들은 Microsoft의 Bing AI14, 구글의 Bard15 등에서는 이미 챗봇, 생성형 AI모델과 검색을 결합하는 형태의 서비스를 아래의 그림 Figure3. 과 같이 제공하고 있습니다.
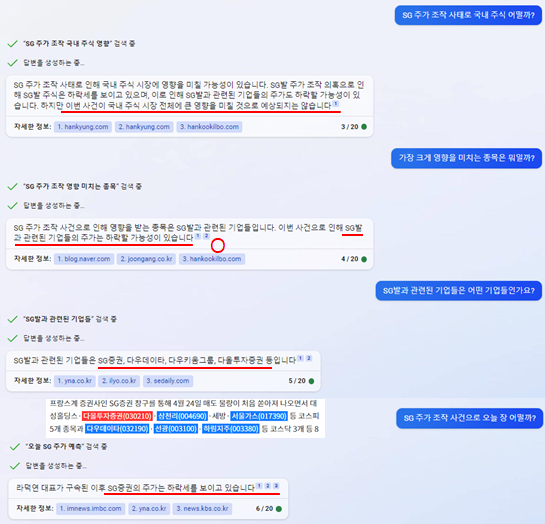 Figure 3. Microsoft에서 제공하는 Bing AI 사용 예시
Figure 3. Microsoft에서 제공하는 Bing AI 사용 예시
이번 포스트에서는 사용자 질의어 기반 다중문서요약의 대표적인 방법인 추출요약(Extractive Summarization)과 추상요약(Abstractive Summarization)에 대해 각각 1편의 논문을 소개드리며 어떤 특징을 나타내고 있는지 설명드리도록 하겠습니다.
QMDS(Query-Focused Multi-Document Summarization)
1편1에서 소개한 다중문서요약은 여러 문서들로부터 정보를 추출하고 요약한다는 단순한 목적이 있다면 사용자 질의어 기반 다중문서요약의 목표는 사용자 질의어 또는 질문에 대답을 하기 위한 정보를 여러 문서로부터 요약을 하는 것입니다.
일반 다중문서요약 방식처럼 Extractive(추출), Abstractive(추상)이 있는데요. 각각의 요약 방식에 따라 사용자 질의어에 대해 적절한 답변을 제공하기 위해 문서들은 어떻게 선별하고 어떤 방식으로 질의어 정보를 반영하여 요약시킬까요?
Extractive Method
우선 추출요약 방식에서 소개시켜드릴 논문은 2020년 ACL에서 Xu and Lapata16가 발표한 Coase-to-Fine Query Focused Multi-Document Summarzation 입니다. 제목에 있는 coarse-to-fine 이라는 단어가 생소할 수 있을텐데요… 우리와 친숙한 소프트웨어공학 관점에서 용어를 설명드리자면 프로세스나 자료를 쪼개는(나누는) 크기에 따라 coarse(크게), fine(작게)로 나뉜다고 합니다.
논문에서는 Coarse-to-Fine의 용어처럼 사용자의 질의어와 문서들 간의 연관성을 파악하고 답이 포함할 가능성을 평가하여 점차 점차 줄여나가면서 요약을 제공하는 방식으로 다중문서(coarse)를 N개의 문장들(fine)으로 요약하는 하나의 Framework를 제안합니다.
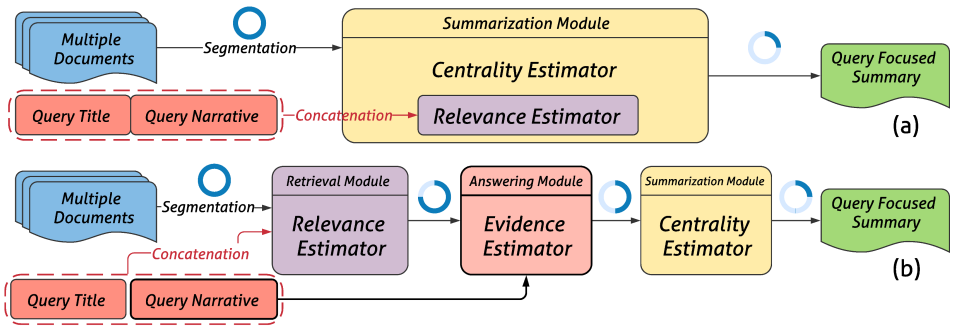 Figure 4. Coarse-to-Fine Query Focused Multi-Document Summarization Framework 구조
Figure 4. Coarse-to-Fine Query Focused Multi-Document Summarization Framework 구조
위의 그림 Figure 4.에서 (a)는 일반적인 QMDS의 프로세스고, 아래 (b)가 이 논문에서 제안하는 Framework 구조입니다. 그림의 파란색 원은 각 모듈마다 처리해야 하는 문서들에 대해서 coarse-to-fine로 나타내고 있는데 (a)와는 다르게 제안하는 방법 (b)에서는 세분화된 모듈에서 점차 줄어드는 것을 볼 수 있습니다.
모듈은 크게 3가지로 구성되어 있으며 아래는 모듈별 역할에 대해 서술하였으며 왜 점차 줄어는지 자세히 알아보도록 하겠습니다.
- Retrieval Module: 질의어(Query)와 가장 연관성(Relevance) 높은 passage를 검색
- Answering Module: 검색된 passage들을 재순위화(Re-ranking)을 통해 요약할 후보 passage들을 선정
- Summarization Module: 상위에 있는 passage들을 이용하여 요약문 구성
모듈에 대해서 설명하기 전에 입력으로는 질의어와 여러 개의 Multi-Document들이 입력되는데 하나의 Multi-Document는 연관성이 높은 문서들의 집합이라고 보기 때문에 하나의 Cluster라고 표현하였습니다. 이러한 Cluster 단위로 문서들을 segment 단위로 분리하는데 논문에서는 동일한 문서 내 sliding window 방식을 이용하여 Passage 단위로 분리시킨다고 합니다.
Retrieval Module에서는 질의어(Query)를 통해 검색된 passage들을 아래의 수식 Figure 5.와 같이 TF(Term Frequency) 기반의 Relevance Score 수식을 통해 계산하여 순위를 정합니다. \(k_{i}^{IR}\)은 \({i}\)th cluster 내 segment \({j}\)의 Score를 나타내며 대표적인 BM25, TF-IDF와 같은 다른 검색 모델도 사용해봤지만 짧은 segment에서는 유리하였지만 passage 단위에서는 오히려 성능 저하를 일으켜 TF를 사용했다고 합니다.
 Figure 5. Relevance Score 수식
Figure 5. Relevance Score 수식
Answering Module에서는 passage들의 Reranking을 통해 최종적으로 요약할 passage들을 선정하는 모듈입니다. Sentence Selection은 BERT기반의 Encoder를 활용하여 이진 분류(Binary Classification)를 통해 질의어와 passage 간의 연관성을 판별하며 Span Selection은 MRC(Machine Reading Compresion)에서 사용한 방식처럼 passage 내 답변이 될만한 문구의 바운더리(Boundary)를 찾는 모듈입니다. 또한, 기존의 데이터를 이용하여 학습하는 방식이 아니라 공개된 MRC 데이터를 활용하여 모델을 학습했다고 합니다.
마지막으로 각 모듈의 확률값과 score들을 통해 아래 Figure 7.과 같이 각 문장 \(e\)의 Evidence Score를 구하게 됩니다. \(q_{e}^S\)와\(\varepsilon^S\)는 Sentence Selection의 score, \(q_{e}^P\)와\(\varepsilon^P\)는 Span Selection의 score를 나타내고 coefficient \(\mu\)=0.9로 두어 선형 결합을 통하여 최종 Score를 계산하여 최종적으로 score를 통해 passage를 Reranking합니다.
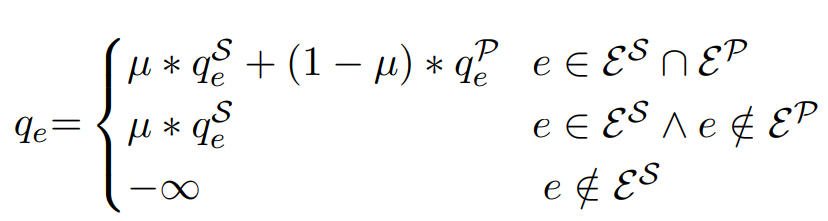 Figure 6. Sentence Selection과 Span Selection를 이용한 선형 결합 수식
Figure 6. Sentence Selection과 Span Selection를 이용한 선형 결합 수식
마지막으로 Summarization Module인데 2단계를 걸쳐 최종적으로 요약문으로 사용할 문장들을 선정합니다. 첫번째 단계는 LexRank17을 이용하여 그래프 구성(Graph Construction)을 하기 위해 문서들의 집합을 cluster로 두고 passage단위로 segment 하기 때문에 TF-ISF(Inverse Sentence Frequency)를 사용합니다. Figure 7.와 같이 그래프의 전이행렬 \(E\)와 Answering Module에서 구한 Evidence Score \(q\)를 정규화를 거쳐 특정 크기의 벡터로 나타내는 \(\tilde{q}\)를 이용하여 하나로 통합하는 작업을 수행하여 사용자의 질의어와 연관된 문장들의 가중치를 줄 수 있도록 ∅를 컨트롤하여 조정합니다.
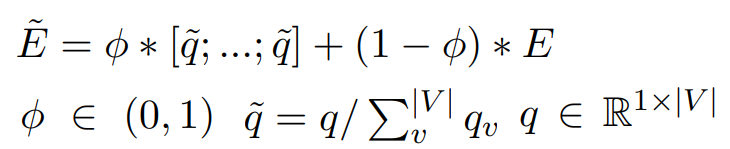 Figure 7. 그래프의 전이행렬과 Evidence Score 통합 수식
Figure 7. 그래프의 전이행렬과 Evidence Score 통합 수식
두번째 단계에서는 그래프 랭킹 알고리즘17을 수행하여 요약문으로 사용할 문장들을 선정하기 위해 이전 그래프의 전이행렬 \(\tilde{E}\)가 정상 분포 \(e^∗\)로 수렴할 때까지 Markov Chain을 실행합니다. 이렇게 최종적으로 랭킹된 문장들 중에서 250단어가 넘지 않도록 상위 문장을 선정하여 요약문으로 구성합니다. 또한, 중복되는 문장들을 제거하기 위해 상위 랭킹된 문장과 overlap되는 문장 계산시 패널티를 부과하며 코사인 유사도(>0.6) 이상인 경우에는 제거합니다.
실험 데이터로는 DUC(Document Understanding Conference) 2005-2007 benchmark와 TD-QFS(Topically Diverse QFS)18를 사용하였으며 실험결과는 아래 Figure 8.과 같으며 DUC는 Query Narrtive가 길지만 문서의 양이 많지 않고 TD-QFS는 Query Narrative가 짧지만 문서의 양이 많다는 특징을 가지고 있습니다.
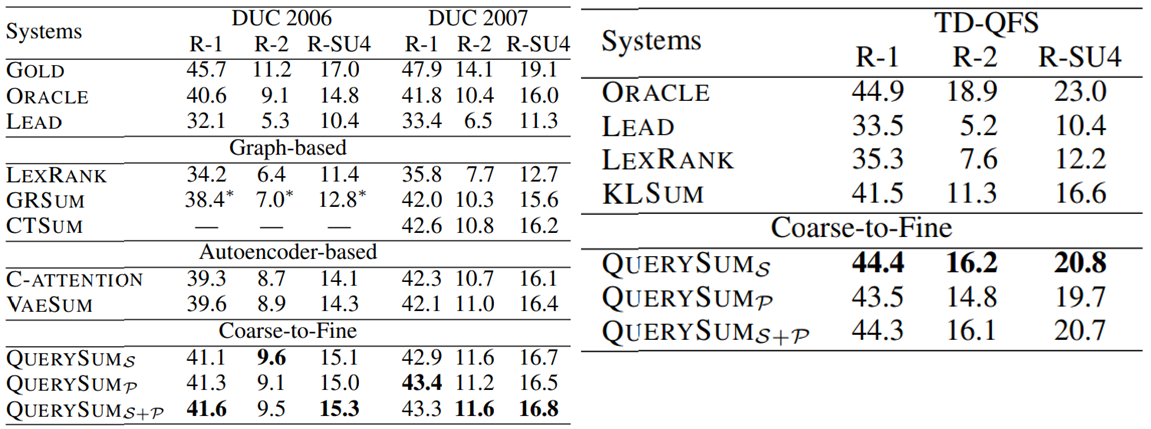 Figure 8. DUC와 TD-QFS 실험 결과
Figure 8. DUC와 TD-QFS 실험 결과
(Answering Module에서 사용한 모듈에 따라 Sentence Selection S, Span Selection P, Ensemble은 S+P로 나타내고 있습니다.)
Rouge19를 이용하여 성능 평가를 진행했는데 QUERYSUM은 논문에서 제안하는 방법이며 DUC dataset에서 다른 Graph, Autoencoder-based 모델보다 높은 성능을 보여주고 있습니다. DUC는 사람이 직접 만든 Gold보다 낮은 성능이 아쉽지만 ORACLE보다는 높은 성능을 보이고 있습니다. 또한, TD-QFS에서도 R-1의 성능은 ORACLE과 거의 유사한 성능을 보이며 제안하는 방법에 우수성을 입증하였습니다. (ORACLE은 각 문장들과 Reference Summary(정답 요약문)에 대해 ROUGE-2를 계산하여 가장 높은 값을 사용한다.)
여기서, 재밌는 점은 DUC에서는 잘 드러나지는 않지만 TD-QFS의 사용자 질의(Query)가 짧아서 그런지 Passage단위 보다는 Sentence 단위에서 높은 성능을 보이고 있어 사용자의 질의어 길이와 문장 단위(Sentence Selection)의 연관성이 있는 것이 같습니다.
Abstractive Method
다음으로 소개시켜 드릴 추상요약 논문은 2021년 AAAI에서 R. Pasunuru et al.20 발표한 Data Augmentation for Abstractive Query-Focused Multi-Document Summarization 입니다. 이 논문에서는 QMDS Task에 대한 양질의 데이터가 부족한 상황에서 기존의 데이터들을 이용하여 data augmentation 적용하여 새로운 QMDS Task의 데이터를 새롭게 구성했다고 하는데 이번 포스트에서는 모델을 중점적으로 설명드리니 궁금하신 분은 논문을 확인하세요!
본 논문은 2019년 ACL에서 Liu and Lapata21가 발표한 논문과 유사하게 Transformer9 기반의 Hierarchical Transformers 모델 구조를 가지고 있습니다. 아래 Figure 9.에 나타난 것처럼 (a)는 Liu and Lapata21가 제안한 모델 구조이며 (b)는 논문에서 제안한 모델입니다. 이전 모델과 마찬가지로 다중 문서를 계층적으로 Encoding하여 문서들 간의 관계 및 구조 정보를 추가로 활용할 수 있는 Hierarchical Transformers구조는 그대로 사용하고 사용자의 질의어 정보 반영 및 요약문 생성의 품질을 향상시키기 위해 3가지 컴포넌트를 추가했지만 Decoder 구조는 똑같다고 합니다
- Transformer Encoder Query Layer: 사용자의 질의어 정보를 반영하기 위해 독립된 모델 Layer 구성
- Hierarchical Encodings: 단일 정보가 아닌 개별 문서 정보와 전체 문서 정보를 상호보완하여 생성하기 위해 Decoder의 입력으로 Local and Global Layer의 output을 Concatenation하여 구성
- Ordering Component: 입력되는 Document들의 Rank 정보를 반영하기 위해 새롭게 구성
 Figure 9. 모델 구조 비교. (a)는 Liu and Lapata의 모델 구조, (b)는 논문에서 제안한 모델 구조
Figure 9. 모델 구조 비교. (a)는 Liu and Lapata의 모델 구조, (b)는 논문에서 제안한 모델 구조
기존의 여러 논문들22,23 에서는 사용자의 질의어인 Query 정보를 반영하기 위해서는 단순한 방법으로 입력 Document(s)에 결합하는 방식을 취했다면 제안하는 모델에서는 Transformer Encoder 기반의 독립된 Query Layer로 구성하여 Local - Query - Global Layer 이러한 관계를 통해 query뿐만 아니라 query와 document들 간의 관계 정보까지도 효과적으로 추출할 수 있다고 합니다.
Local Layer는 일반적인 Transformer Encoder 구조와 같지만 Global Layer는 차이가 있어 간략하게 소개시켜 드립니다. Global Layer에서는 Transformer의 Multi-Head Attention처럼 각 문단을 다양한 방식으로 인코딩하며 각 문서에 대해서 유연하게 표현하고 다양한 정보를 캡처할 수 있도록 Multi-Head Pooling과 Self-Attention처럼 문서 간의 상호 의존성을 알기 위해 Inter-paragraph Attention를 사용했다고 합니다.
Figure 10.은 Global Layer의 구조도이며 여기서 각 head를 통해 다른 문서 간의 정보를 수집하고 하나의 Context로 Concat하여 각각의 토큰에 추가합니다.
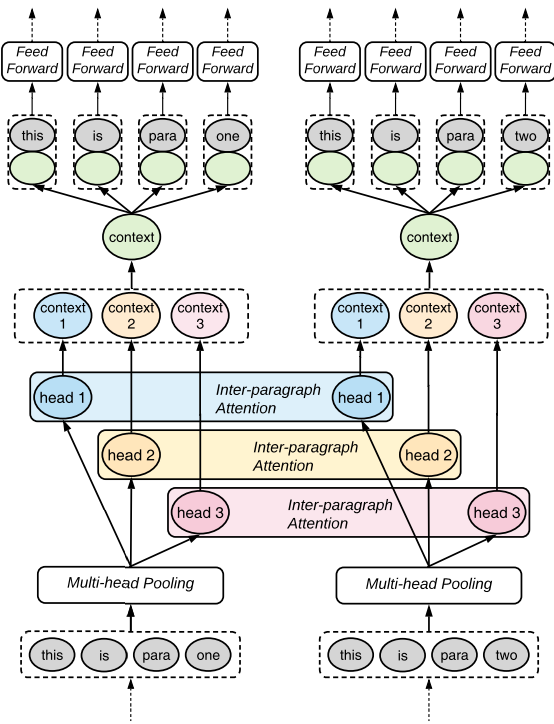 Figure 10. Global Layer 구조도
Figure 10. Global Layer 구조도
Hierarchical Encodings의 아이디어는 간단합니다. 기존 모델에서는 Local Layer의 output이 Global Layer을 거치기 때문에 Local Layer의 정보를 반영시킨 것으로 가정하여 최종적으로 Global Layer의 output만을 Decoder의 입력으로 사용하였는데 제안하는 모델에서는 각각의 output을 결합하여 Decoder의 입력으로 사용하는 것입니다.
Ordering Component은 질의어 기반의 요약 생성시 모든 문서에 대해 동일한 정보를 반영하면 변별력이 없기 때문에 질의어와 관련있는 문서들로 순위를 매긴 Ranking 정보는 매우 중요합니다. Liu and Lapata15에서는 Two-Stage Pipeline방식으로 문서들의 Ranking 정보를 반영했습니다. 첫번째는 문서와 질의어와 연관성을 판별하는 단계로써 LSTM기반의 Logistic Regression 모델을 학습하여 사용하였고 두번째는 첫번째 모델의 Score를 이용하여 Rankning을 정하는 방식인데 최종적으로 요약에 미치는 영향은 미비하다고 합니다.
이 논문에서는 Single-Stage방식으로Transfomer Encoder의 마지막 레이어에서 문서의 Positional Encoding을 아래의 Figure 10.과 같이 사용했다고 하며 다중문서 중에서 어떤 문서가 중요한지 판별하기 위해 self-attention 모듈도 함께 사용했습니다.
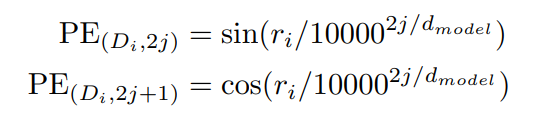 Figure 11. Ordering Component 내 Positional Encoding
Figure 11. Ordering Component 내 Positional Encoding
PE(\(D_{i}, 2j\))는 문서 \(D_{i}\)의 \(2j^{th}\)번째의 Positioinal Encoding이며 \(r_{i}\)는 self-attention을 통해 할당된 문서 \(D_{i}\)의 중요도 점수를 나타냅니다. 다시 말해, 각 문서에 대해 중요도 점수 \(r\)를 통해 핵심정보를 생성할 수 있도록 하며 PE(\(D_{i}, 2j\))를 통해 문서의 Ranking 정보를 반영하도록 모델을 학습합니다.
실험 데이터로는 WikiSum24 데이터는 질의어 정보가 위키피디아의 문서 제목이고 QMDSCNN과 QMDSIR은 논문에서 기존의 데이터를 사용하여 새롭게 구성한 QMDS Task 데이터입니다. QMDSCNN은 CNN/Daily Mail25 기사제목을 질의어로 사용하였으며 QMDS IR은 Bing14의 검색 로그에서 실제 사용자의 질의어를 이용했습니다.
제안한 모델의 실험결과는 아래 Figure 12.처럼 3개의 dataset과 Liu and Lapata15의 성능비교를 나타내고 있습니다.
| WikiSum | QMDSCNN | QMDSIR | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-1 | R-2 | R-L | R-1 | R-2 | R-L | |
| Liu and Lapata | 38.03 | 24.68 | 36.20 | 36.31 | 15.40 | 33.38 | 43.60 | 21.88 | 39.40 |
| HS w/ Hierarchical Encodings | 38.14 | 24.88 | 36.33 | 37.88 | 16.36 | 35.23 | 43.37 | 21.64 | 39.21 |
| HS w/ Ordering Component | 38.57 | 25.13 | 36.71 | 36.95 | 14.95 | 34.34 | 39.37 | 18.79 | 35.61 |
| HS w/ Query Encoding | 35.70 | 21.86 | 33.70 | 36.96 | 16.05 | 34.37 | 44.11 | 22.62 | 39.93 |
| HS-Joint Model | 38.37 | 24.90 | 36.52 | 37.09 | 16.33 | 34.45 | 45.53 | 23.44 | 41.15 |
각각의 Dataset의 특징에 따라 추가된 Component에 대해 성능향상을 나타내고 있습니다. 위키피디아 문서의 첫번째 Section을 생성하도록 하기 때문에 Ordering Component에 대해서 두각을 드러내고 QMDSCNN 경우에는 하나의 기사를 segment 단위로 나누었기 때문에 Hierarchical Encodings에서 성능 향상을 보였습니다.
마지막으로는 QMDSIR는 실제 사용자의 질의어를 사용한다는 특징이 있기 때문에 위키피디아, 뉴스 등의 제목을 임의로 질의어로 사용한 것보다 성능 향상이 눈에 띕니다. 또한 QMDSIR은 Open-Domain과 유사한 환경이라고 보이며 Query Component에서 성능 향상을 통해 3가지의 Component를 합친 Joint Model에서 가장 높은 성능을 보이고 있어 실제 서비스에서도 효과적일수도 있다는 방증입니다.
Extractive, Abstractive 비교
사용자 질의어 기반 다중문서요약의 대표적인 방법인 추출요약(Extractive Summarization)과 추상요약(Abstractive Summarization)에 대해 각각 1편의 논문을 소개시켜드렸습니다. 사용자의 질의어 정보와의 연관성을 위해 어떤 정보가 필요한지 어떤 내용을 강조해야 될지에 대해서는 파악한다는 공통점이 있지만 어떤 문장들이 중요한지 결정하고 추출하는 방식인 추출요약 방식과 새로운 문장으로 생성하거나 원문의 내용을 재구성한다는 가장 큰 차이점이 있습니다.
또한, Figure 13.에서 나타난 것처럼 질문에 대한 연관성이 있지만 추출요약 결과를 보면 중요한 문장을 선택했기 때문에 추출요약된 문장들 간의 일관성이 부족해 보일수 있지만 추상요약에서는 새로운 문장으로 생성하거나 원문의 내용을 재구성하기 때문에 생성되는 문장에 대해서도 일관성을 유지가 가능하지만 잘못 생성되는 경우도 발생합니다.
결과적으로는 추출요약은 요약 문장들 간의 일관성은 부족하지만 명확하게 문장들을 요약할 수 있지만 추상요약은 일관성은 있지만 요약 문장들이 잘못 생성 될 수 있습니다.
 Figure 13. 사용자의 질의어 기반 추출요약과 추상요약의 예시
Figure 13. 사용자의 질의어 기반 추출요약과 추상요약의 예시
마치며
이번 포스트에서는 사용자 질의어 기반 다중문서요약(Query Focused Multi-Document Summarization)에 대한 관련 연구, 연구 동향와 대표적인 방법론에 대한 논문을 각 1편씩 소개드렸으며 글로벌 기업들도 실제로 서비스에도 접목시키면서 연구의 필요성에 대해서도 말씀드렸습니다. 추출요약(Extractive)와 추상요약(Abstractive)에 대해서도 말씀드렸는데 이 방법들에 대해서는 각각의 장/단점들이 뚜렷하게 나타나기 때문에 결국에는 목적에 따라 사용할 수 밖에는 없을 것 같습니다.
2편의 포스트를 통해 다중문서요약, 사용자 질의어 기반 다중문서요약을 소개드렸습니다. 부족했지만, 포스트들을 통해서 조금이나마 이 부분에 대해서 도움이 되었으면 좋겠습니다. 감사합니다!
Reference
-
Neural Approaches to Conversational Information Retrieval (Jianfeng Gao et al., 2022) ↩
-
사우디 찾은 엔씨 윤송이 “AI, 게임 개발 효율성 높여” (2023년 10월 24일 연합뉴스 기사) ↩
-
TextRank: Bringing Order into Texts (Rada Mihalcea and Paul Tarau, 2004) ↩
-
A Query Specific Graph Based Approach to Multi-document Text Summarization: Simultaneous Cluster and Sentence Ranking (Sandip R. P. and M. A. Potey., 2013) ↩
-
Heterogeneous Graph Neural Networks for Query-focused Summarization (Jing Ya et al., 2021) ↩
-
AttSum: Joint Learning of Focusing and Summarization with Neural Attention (Ziqiang Cao et al., 2016) ↩
-
Get To The Point: Summarization with Pointer-Generator Networks (Abigail See et al., 2017) ↩
-
Attention Is All You Need (Ashish Vaswani et al., 2017) ↩ ↩2
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (Patrick Lewis et al., 2020) ↩
-
REALM: Retrieval-Augmented Language Model Pre-Training (Kelvin Guu et al., 2020) ↩
-
Re^2G: Retrieve, Rerank, Generate (Michael Glass et al., 2022) ↩
-
REPLUG: Retrieval-Augmented Black-Box Language Models (Weijia Shi et al., 2023) ↩
-
Coarse-to-Fine Query Focused Multi-Document Summarization (Yumo Xu and Mirella Lapata, 2020) ↩
-
LexRank: Graph-based Lexical Centrality as Salience in Text Summarization (Gunes Erkan and Dragomir R. Radev, 2004) ↩ ↩2
-
Topic concentration in query focused summarization datasets (Tal Baumel et al., 2016) ↩
-
Automatic Evaluation of Summaries Using N-gram Co-occurrence Statistics (Chin-Yew Lin and Eduard Hovy, 2003) ↩
-
Data Augmentation for Abstractive Query-Focused Multi-Document Summarization (Ramakanth Pasunuru et al., 2021) ↩
-
Hierarchical Transformers for Multi-Document Summarization (Yang Liu and Mirella Lapata, 2019) ↩ ↩2
-
Question-Driven Summarization of Answers to Consumer Health Questions (Max Savery et al., 2020) ↩
-
CAiRE-COVID: A Question Answering and Query-focused Multi-Document Summarization System for COVID-19 Scholarly Information Management (Dan Su et al., 2020) ↩
-
GENERATING WIKIPEDIA BY SUMMARIZING LONG SEQUENCES (Liu et al., 2018) ↩
-
Teaching Machines to Read and Comprehend (Karl Moritz Hermann et al., 2015) ↩
