
시작하며
얼마 전까지만 해도 인공 지능이 특정 분야에서 사람을 능가하는 경우는 많았지만, 다양한 상황을 일반화해 해결하는 능력에는 한계가 있었습니다. 2020년, 거대 언어 모델 GPT-31가 등장했고 방대한 규모의 데이터와 모델 크기 덕분에 처음 보는 작업도 수행할 수 있는 능력을 갖추게 되었고, 기존 언어 모델은 해결하기 어려웠던 여러 복잡한 문제를 풀어내는데 성공합니다. 이러한 일반화 능력은 특정 작업을 위한 데이터 구축의 필요성을 줄여주었고, 이는 다양한 작업에 하나의 거대 언어 모델을 사용하는 새로운 패러다임으로 이어졌습니다.
하지만 이러한 거대 언어 모델조차도 여전히 추론(Reasoning) 능력은 부족한 것으로 알려져 있었습니다. 추론 문제는 일반적으로 깊은 사고를 요구하기에 사람에게조차도 어려운 부분이 있고 일정 수준에 도달하려면 어느 정도 훈련이 필요합니다. 2022년 발표된 Chain of thought(이하 CoT)2 연구는 거대 언어 모델도 사람과 유사한 사고 과정을 거쳐 추론 문제를 해결할 수 있음을 보여주었습니다. 이번 포스팅에서는 CoT의 저자들이 어떻게 거대 언어 모델의 깊은 사고를 가능하게 했는지, 그리고 이 연구가 어떤 방향으로 발전하고 있는지 알아보겠습니다.
생각의 사슬: 인공 지능의 단계적 추론 활성화
거대 언어 모델이 프롬프팅(Prompting)1을 통해 다양한 작업을 수행할 수 있다는 것은 알려진 사실입니다. CoT의 저자들은 간단한 프롬프팅을 통해 언어 모델이 사람의 사고 과정을 모방하도록 유도하면, 추론 능력이 발현될 수 있음을 보여줍니다. 우선 예제를 통해 CoT 프롬프팅이 어떻게 구성되는지 알아보겠습니다.
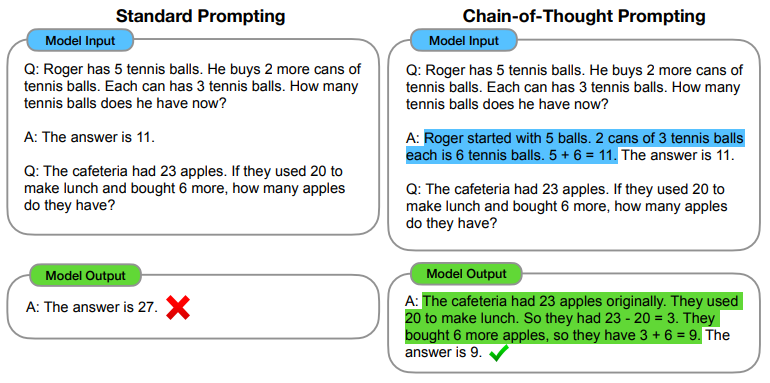 Figure 1. CoT 추론 과정 예시
Figure 1. CoT 추론 과정 예시
Figure 1의 첫 번째 질문의 답이 11개인 것은 사람에게 전혀 직관적이지 않습니다. 사람이라면 이 문제를 다음과 같이 step-by-step으로 해결할 것입니다:
- Roger는 테니스공 5개를 가지고 있었다.
- 테니스공이 3개 들어있는 캔을 2개 구매했으므로, Roger는 테니스공 6개를 산 것이다.
- 따라서 Roger가 현재 가지고 있는 테니스공은 5 + 6 = 11개이다.
CoT 프롬프팅은 이런 단계적인 추론 과정을 거쳐 답을 도출하는 예제들을 모델에게 제시해, 모델이 (즉시 답변을 생성하지 않고) 추론 과정을 거쳐 답변을 생성하도록 유도합니다.
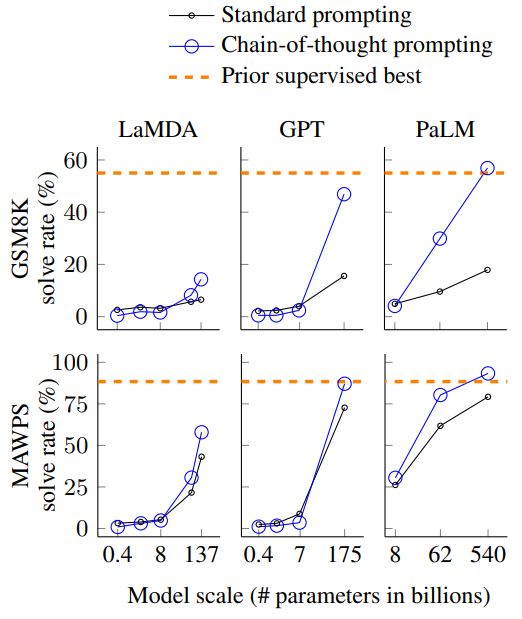 Figure 2. 모델 크기와 CoT 추론 능력의 관계
Figure 2. 모델 크기와 CoT 추론 능력의 관계
실험 결과, 이런 프롬프팅 방식은 거대 언어 모델의 추론 능력에 실질적인 도움이 되는 것으로 나타났습니다. 위 그래프에서 볼 수 있듯, PaLM3 540B 모델에 CoT 프롬프팅을 적용했을 때 대부분의 벤치마크에서 미세 조정(Fine-tuning)된 SOTA 모델과 비슷하거나 더 높은 성능을 보였습니다. 또한 GSM8K4처럼 복잡한 문제일수록 더 큰 성능 향상이 있었고, 이는 CoT가 복잡한 추론 문제에 특히 유용함을 시사합니다.
저자들은 거대 언어 모델이 올바른 답에 도달한 것이 적절한 추론을 통한 것인지, 우연인지 확인하기 위해 모델이 답을 맞힌 50건의 사례를 분석했습니다. 그 결과 2건만이 우연히 정답에 도달했고 나머지는 논리적인 추론을 거쳐 정답에 도달했다고 합니다. 또한 다양한 모델 크기에서의 실험을 통해 CoT 프롬프팅이 (실험에 사용한 사전 학습 모델 기준) 100B 이상의 큰 모델에서 추론 능력을 발현시키는 것을 확인했습니다.
CoT 프롬프팅이 어떻게 거대 모델의 추론 능력을 발현시키는지 명확히 설명하기는 어렵지만 다음과 같이 추측해 볼 수 있습니다:
- 거대 언어 모델의 학습 데이터에는 StackExchange와 같은 웹사이트의 데이터가 다수 포함되어 있을 것입니다. 이러한 웹사이트의 사용자들은 자신의 의견을 분명히 전달하기 위해 단계적인 설명을 덧붙이는 경우가 많고, 이러한 데이터는 언어 모델이 사람의 추론 형식을 이해하고 따라하는 데 도움이 되었을 것입니다.
- CoT의 각 단계를 보면 주어진 큰 문제를 비교적 쉬운 문제로 쪼개서 푸는 것과 유사해 보입니다. 거대 언어 모델에게 충분히 쉬운 문제를 반복적으로 풀도록 유도해 큰 문제의 추론을 완성하도록 하는 것으로 볼 수 있습니다.
요약하면 CoT는 Inference 단계에서의 처리를 통해 거대 언어 모델의 추론 능력을 발현시켰다고 볼 수 있습니다. 후속 연구들은 거대 언어 모델의 사고 과정을 강화, 확장하는 방향으로 진행되고 있으며, 일부는 Training 단계에서 CoT를 바라보는 방향을 모색하고 있습니다.
생각의 진화: 사람처럼 생각하는 인공지능
앞서 살펴본 CoT는 단 한 번의 사고 과정으로 결론을 내립니다. 그러나 사람은 여러 가능성을 고민하고 시행착오를 겪으며 최종 결론에 도달합니다. 이러한 인간의 복잡한 사고 과정을 모방해 CoT의 개념을 더욱 발전시킨 새로운 연구들이 등장했습니다.
 Figure 3. CoT와 후속 연구들
Figure 3. CoT와 후속 연구들
Self-Consistency with CoT5에서는 여러 사고 흐름을 샘플링한 뒤에 다수결로 정답을 선택해 더 높은 추론 성능을 얻습니다. 이 방법은 사람이 다양한 옵션을 고려하고 최선의 해결책을 찾는 과정을 반영하려는 시도로 해석될 수 있습니다. 하지만 이 방법은 출력 결과를 명백히 비교하기 어려운 생성 문제에는 적용이 어렵다는 단점이 있습니다.
Tree of thought(이하 ToT)6에서는 언어 모델의 사고 과정을 사람과 더 유사하게 시뮬레이션하려고 노력합니다. ToT는 문제를 작은 생각 단계로 분해하고 각 단계에서 생각을 계속 진행할 것인지 아니면 이전 단계로 돌아가 다른 사고 경로를 탐색할 것인지 결정하는 메커니즘을 도입합니다. 이 과정은 일종의 Tree search와 유사해 각 분기점에서 여러 방향으로의 사고를 가능하게 합니다. 분해된 각 생각 단계는 다양한 방향으로 분기할 수 있도록 충분히 작지만, 문제 해결에 충분한 문맥을 포함해야 합니다. ToT는 GPT-4조차도 어려움을 겪는 Game of 24 등 매우 깊은 추론이 필요한 문제에서도 뛰어난 성능을 보인다고 합니다.
생각의 전이: 소형 인공 지능으로의 사고력 이식
지금까지의 논의는 추론(Inference) 과정에서 언어 모델의 사고를 증진시키는 방법에 대한 것이었습니다. Orca7의 저자들은 거대 언어 모델의 사고 과정을 상대적으로 작은 모델에 학습(Training)하는 방향으로 관점을 전환합니다.
이렇게 큰 모델(선생님)로부터 작은 모델(학생)이 학습하는 것을 Distillation8이라고 합니다. 일반적인 Distillation의 접근법에서는 선생님 모델의 중간 표현(Intermediate representation)을 활용해 학생 모델을 학습하지만 ChatGPT나 GPT-4 등의 모델은 공개되어 있지 않아 이러한 방식을 적용하는 것이 불가능합니다. Orca는 중간 표현을 직접 학습하는 대신 선생님 모델의 중간 사고 과정을 통해 간접적으로 중간 표현을 학습하려고 합니다.
 Figure 4. GPT-4를 활용한 CoT augmentation 예시
Figure 4. GPT-4를 활용한 CoT augmentation 예시
Orca를 학습하는 방법은 다음과 같습니다:
- 먼저 Figure 4의 Original data 같은 입출력 쌍으로 구성된 데이터를 준비합니다.
- 선생님 모델(여기서는 GPT-4)의 추론 능력을 활성화하기 위해 “Think step-by-step” 같은 System instruction CoT에서 예제로 사고 과정을 유도한 것에 반해 Orca에서는 Instruction9으로 유도 을 입력에 추가합니다.
- 단계 2의 입력을 사용해 선생님 모델이 추론 과정을 포함하는 답변을 생성하도록 합니다.
- 단계 3에서 생성한 데이터로 학생 모델을 학습시킵니다.
실험 결과, Orca는 스포츠 이해 등 지식이 요구되는 문제에서는 ChatGPT보다 낮은 성능을 보였지만 시간, 공간 추론 등 특정 영역에서 ChatGPT보다 월등한 성능을 보였습니다. 이러한 결과로 미루어 볼 때, Orca의 방법론을 통해 거대 언어 모델의 추론 능력을 상대적으로 작은 모델에 전파할 수 있는 것으로 보이며, 이는 자원이 제한된 환경에서도 언어 모델의 추론 능력을 활용할 수 있다는 점에서 중요한 의미를 가집니다.
마치며
지금까지 거대 언어 모델의 사고 능력을 확장하고 이를 활용하는 방법에 대해 살펴보았습니다. CoT, ToT 등의 방법론은 언어 모델이 추론 과정에서 사람과 유사한 경로를 따르게 만들어 성능을 향상시킵니다. Orca는 거대 언어 모델의 추론 과정을 작은 언어 모델로 이식해 이런 과정을 더 효율적으로 만듭니다.
아직 언어 모델이 완전히 사람처럼 생각하는 단계에는 이르지 못했지만, 이러한 발전은 인공 지능이 우리의 일상생활과 전문 분야에서 중요한 도구가 되는 길을 열고 있습니다. 인공 지능이 사람처럼 생각하도록 발전한다면, 우리는 인공 지능을 더욱 신뢰할 수 있을 것이며, 함께 협력해 우리가 상상조차 못 한 방식으로 문제를 해결할 수 있을 것입니다. 이 기술의 성장은 인간의 경험을 풍부하게 하고, 우리 사회에 의미 있는 변화를 가져다줄 것입니다. 사람과 기계가 함께 이러한 가능성을 모색한다면, 우리는 조금씩이나마 더 나은 내일을 구축해 나갈 수 있을 것입니다.
(결론은 ChatGPT의 도움을 받아 작성되었습니다.)
Reference
-
Language Models are Few-Shot Learners (Brown, Tom, et al., 2020) ↩ ↩2
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei, Jason, et al. 2022) ↩
-
Palm: Scaling language modeling with pathways (Chowdhery, Aakanksha, et al. 2022) ↩
-
Training Verifiers to Solve Math Word Problems (Cobbe, Karl, et al. 2022) ↩
-
Self-consistency improves chain of thought reasoning in language models (Wang, Xuezhi, et al. 2022) ↩
-
Tree of thoughts: Deliberate problem solving with large language models (Yao, Shunyu, et al. 2023) ↩
-
Orca: Progressive learning from complex explanation traces of gpt-4 (Mukherjee, Subhabrata, et al. 2023) ↩
-
Distilling the knowledge in a neural network (Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. 2015) ↩
