
개요
1부 포스트에서는 전반적으로 프롬프트 데이터가 거대언어모델에게 어떠한 개선점을 주는지에 대해서 함께 알아보는 시간을 가졌습니다. 특히, Figure 1과 같이 GPT-3의 직접(explicit) 프롬프트에서 보여지는 거대언어모델이 겪는 문제점을 살펴 보았으며, 데이터에 지시문(instruction)을 넣어 학습한 거대언어모델은 GPT-3의 혼란스러운 결과를 개선해주는 모습을 볼 수 있었습니다.
 Figure 1. 입력에 대한 GPT-3와 InstructGPT의 결과물 차이
Figure 1. 입력에 대한 GPT-3와 InstructGPT의 결과물 차이
여기서 이야기하는 지시문이란, 언어모델이 주어진 태스크를 잘 해결할 수 있게 도와주는 선생님의 설명과 같은 개념이라고 이해할 수 있습니다. 예를 들어 덧셈을 처음 배우는 1학년 학생들의 교실에 있다고 생각해 봅시다. 이 학생들에게 바로 덧셈 시험을 보았을 때 좋지 않은 결과를 가지고 올 것 입니다. 덧셈이라는 개념을 모르기 때문입니다.
 덧셈에 대한 문제 해결 접근법을 모르는 경우
덧셈에 대한 문제 해결 접근법을 모르는 경우
그래서 선생님은 학생들에게 처음 더하기 하는 방법 알려줍니다. 그 선생님은 “더하고자 하는 두개의 수를 더할 때 “+” 기호를 사용하며 두 수를 합하면 된다“라고 설명을 할 것이며 “3과 5를 더하는 경우, 3을 먼저 쓰고 “+” 기호를 적은 다음에 “5”를 써서 “3”과 “5”를 합하면 “8”이라는 숫자가 나오게 되지요“라고 예시를 들어 줄 것입니다. 이 설명을 들은 학생들은 덧셈을 하는 방법을 배웠으며 앞으로 주어진 숫자를 사용하여 덧셈을 하면 올바른 답변을 줄 수 있는 기술 및 지식을 터득하게 됩니다. 즉, 덧셈 이라는 태스크에 대한 문제를 해결 할 수 있게 가르침을 받은 것이라고 표현할 수 있습니다.
 덧셈에 대한 문제 해결 접근법을 배운 경우
덧셈에 대한 문제 해결 접근법을 배운 경우
그렇다면 이 초등학교 수학 시간의 예제를 저희 프롬프트 데이터 관점으로 다시 살펴봅시다. Figure1 에 따른 주어진 입력문에 따라 언어모델은 답변을 출력하기 위해 모델은 “주어진 문제에 따른 답변을 생성하세요. 단, 답변은 짧아야 합니다 (Given a question, generate the answer. Yet, the answer should be short.)“와 같은 설명을 이해하는 단계가 필요합니다. 덧셈을 배우는 학생들처럼 실행하고자 하는 접근법에 대해 이해를 하였으면 입력문이 들어왔을 때 답변을 수월하게 출력할 수 있습니다. 그 결과로, GPT-3에서는 보기 힘들었던 “달과 별에 대한 짧은 이야기를 써주세요 (Write a short story about the moon and the stars)” 입력문에 대한 자연스러운 답변 출력이 InstructGPT 에서는 “옛날 옛날에 달과 별이 (Once upon a time, the moon and the stars…)“와 같이 사람이 직접 작성한 듯한 출력물을 볼 수 있습니다. 따라서 본 포스트에서는 지시문을 가지는 프롬프트 데이터 셋을 분석해 보면서 자연어 텍스트 데이터와는 어떠한 차별점을 가지고 있는지 알아보고자 합니다.
아래에서 소개 드릴 데이터 셋은 Google, OpenAI 그리고 Wang et al. 에서 배포한 대표적인 프롬프트 데이터입니다. Google 에서는 FLAN을 선보였으며, OpenAI에서는 InstructGPT 데이터 셋을 구축하였습니다. 뿐만 아니라, Wang et al. 에서는 높은 태스크 coverage를 자랑하는 Super-NaturalInstructions 데이터 셋을 보여주었습니다. 이 세가지 데이터 셋은 아래의 Figure 2에서 보여지는 것 처럼 배포된 순서대로 설명이 진행될 것이며, 각 데이터 셋에 대한 태스크 종류, 데이터 수량, 데이터 구축 접근법을 차근 차근 살펴보면서 어떤 정보들이 학습 데이터에 포함이 되어 있는지 알아보는 시간을 가지도록 하겠습니다.
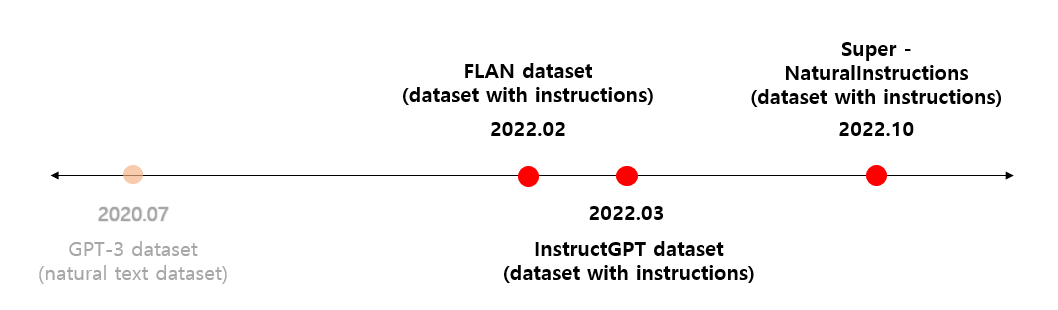 Figure 2. 거대언어모델의 데이터셋 출시 연대순
Figure 2. 거대언어모델의 데이터셋 출시 연대순
프롬프트 데이터 셋
a) FLAN (Google) 데이터 셋
FLAN은 책, SNS, 인터넷과 같은 자연어 텍스트 데이터 셋을 학습한 GPT-3의 문제점들을 개선하기 위해 나타났습니다. 즉, 지시문 데이터를 학습하여 다양한 태스크를 fine-tuning 하는 instruction-tuned된 언어 모델입니다. 언어 모델을 학습 시키기 위해 필요한 데이터를 직접 구축하는 작업을 진행하지는 않았습니다. instruction-tuning을 위한 대용량 데이터 셋을 처음부터 구축하기에는 힘들다고 판단되었기 때문이죠. 하지만, 기존에 벤치마크(benchmark)로 사용되었던 NLP 데이터 셋들을 지시문 포맷으로 변경하는 작업을 진행 하였습니다.
변경 작업의 데이터 템플릿 포맷으로는 다음과 같이 4가지로 구성되었습니다.
- 태스크 설명
- 입력 문장
- 출력 문장
- 옵션
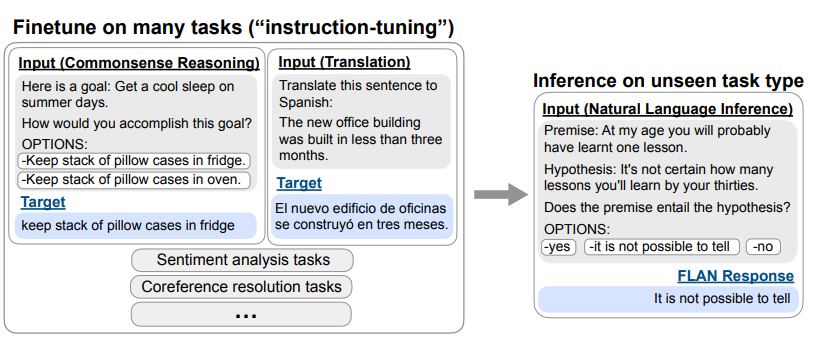 Figure 3. 태스크 별 FLAN 데이터 템플릿 예시
Figure 3. 태스크 별 FLAN 데이터 템플릿 예시
Figure 3 에 나타난 번역(Translate) 태스크를 보면서 이야기 해보겠습니다.
- 태스크 설명: “이 문장을 스페인어로 번역해라 (Translate this sentence to Spanish)”
- 입력 문장: “새 사옥은 3개월도 채 안되어 지어졌습니다 (The new office building was built in less than three months)”
- 출력 문장: 입력 데이터의 스페인어 번역 버전이 들어가게 됩니다.
- 옵션:
- 몇몇 태스크에 추가로 옵션이 포함
- 이는 다른 답안이 출력 되는 문제를 방지하고자 언어모델에게 애초부터 선택지를 부여하기 위함
- 번역 태스크와 같은 생성 분야에는 필요로 하지 않았음
이처럼 태스크 설명, 입력 문장, 출력 문장, 옵션으로 구축된 데이터는 Figure 4에 보여지는 것처럼 62개의 텍스트 데이터 셋을 아래와 같이 12개의 작업 유형으로 분류 되었습니다. 각 데이터 셋은 개별 태스크에 대한 10개의 템플릿을 기본적으로 구축하였는데, 그 10개 중 최대 3개 정도는 데이터의 다양성을 위해 태스크를 전환하는 템플릿도 포함 되었습니다. 이를테면 감정 분류 태스크에 대한 템플릿을 구축함에 있어 최소 7개는 긍정/부정의 감정을 분류하는 작업 에 대한 템플릿이라면, 긍정적인 감정에 맞는 영화 리뷰를 생성하는 작업 에 대한 템플릿을 태스크 전환 템플릿으로 사용하기도 하였습니다.
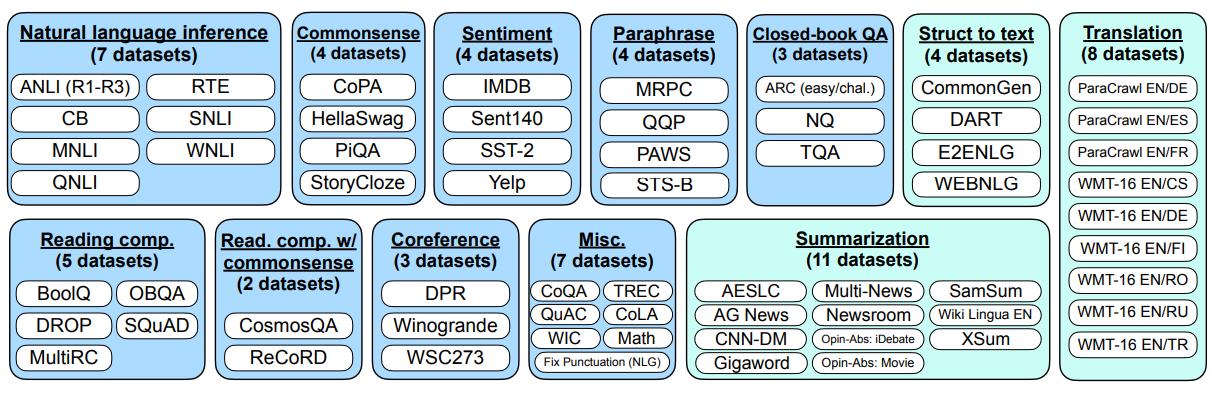 Figure 4. 12개의 작업 유형으로 분류된 FLAN 데이터 셋 (하늘색은 NLU 태스크; 민트색은 NLG 태스크)
Figure 4. 12개의 작업 유형으로 분류된 FLAN 데이터 셋 (하늘색은 NLU 태스크; 민트색은 NLG 태스크)
b) InstructGPT (OpenAI) 데이터 셋
다음으로 InstructGPT 데이터 셋에 대해 소개하겠습니다. Ouyang et al. (2022)은 언어모델이 사용자와 align되지 않았다고 생각합니다. 모델이 사용자와 align 되지 않았다는 뜻은 언어모델이 사람의 의도에 알맞은 답변을 할 수 없는 것이라고 생각할 수 있습니다. 그래서 InstructGPT는 사람의 피드백을 받아 fine-tuning을 하여 강화 학습을 할 수 있게 하는 instruction learning에 대해 고찰이 진행되었으며, 이 접근 방법을 RLHF (Reinforcement Learning Human Feedback) 이라고 합니다. InstructGPT는 데이터를 학습하기 위해 3가지 종류 (SFT Data, RM Data, PPO Data)의 프롬프트 데이터를 구축하여 Figure 5의 테이블과 같이 구성되었습니다.
- plain 프롬프트: 작업자들이 각자 머릿속에 떠오르는 임의의 프롬프트를 작성함
- SFT(supervised fine-tuning)모델을 훈련하는데 사용되는 SFT 데이터 셋 (13k training set)
- few-shot 프롬프트: 작업자들이 프롬프트와 그 프롬프트에 해당하는 다수의 query/response쌍을 작성함
- RM (reward model) 교육에 사용되는 RM 데이터 셋 (33k training set)
- user-based 프롬프트: 실제 OpenAI API어플리케이션 사용 사례들에 대한 프롬프트를 작성함
- RLHF fine-tuning을 위해 사용되는 PPO 데이터 셋 (31k training set)
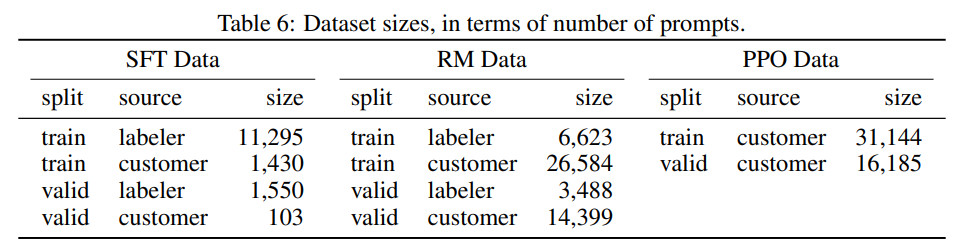 Figure 5. InstructGPT에 사용된 학습데이터 셋 (왼쪽부터 SFT 데이터 셋, RM 데이터 셋, PPO 데이터 셋)
Figure 5. InstructGPT에 사용된 학습데이터 셋 (왼쪽부터 SFT 데이터 셋, RM 데이터 셋, PPO 데이터 셋)
이와 같이 InstructGPT는 finetuning할 수 있게 도와주는 SFT 데이터와, 강화학습 모델에 도움이 될 수 있는 RM과 PPO 데이터들을 훌륭하게 구축하였습니다. 하지만 아쉽게도 OpenAI는모두가 사용할 수 있게 데이터를 공개하지 않았습니다. 더 자세한 데이터 조사는 어려웠지만, 여전히 재미있는 사실은 InstructGPT에서 사용한 데이터셋은 ChatGPT에서도 동일하게 사용되었다는 점입니다. 여기서는 모델의 학습 절차에 대해서 깊이 다루지 않지만, InstructGPT 학습시에 사람들의 판단이 필요한 2가지 구역이 있습니다. SFT 데이터 셋을 구축하는 부분과 RM 을 위한 데이터 랭킹을 구축하는 작업인데 ChatGPT는 InstructGPT와 동일한 데이터 셋을 사용하지만 아무래도 사용자와 대화를 하기 위한 서비스이다 보니 좀 더 사람스러운 답변과 실제로 사람과 align 될 수 있는 답변을 내놓기 위해 PPO 부분의 policy 작업에도 사람의 판단 능력이 개입되었다고 합니다.
c) Super-NaturalInstructions (Wang et al) 데이터 셋
소개해드릴 마지막 데이터인 Wang et al. (2022)의 Super-NaturalInstructions (SNI)는 1,616 개의 태스크의 설명에 대해 각 태스크 전문가들의 검토가 포함된 데이터입니다. SNI 데이터 셋은 ‘분류 (Classification)’, ‘추출 (Extraction)’, ‘채우기 (Filling)’, ‘시퀀스 태깅 (Sequence Tagging)’, ‘텍스트 재작성 (Text Rewriting)’과 같은 76개의 태스크 유형을 가지고 있습니다. 또한, 이 데이터 셋은 55개의 언어와 33개의 도메인에서 구축이 되었으며 놀랍게도 576개의 non-English 태스크를 포함하고 있습니다.
그럼에도 불구하고 아래의 Figure 6에 따르면 대부분의 태스크는 영어로 구성되어 있고 다른 언어들은 비교적 아주 소수에 해당하는 것으로 보여집니다. 뿐만 아니라, Figure 7에 나타나는 도메인들 또한 범용적으로는 뉴스 도메인이 가장 많이 사용되었지만 다른 도메인에서는 task-specific 하게 사용되었다는 것을 알 수 있습니다.
 Figure 6. Super-NaturalInstructions에서 사용된 언어 분포
Figure 6. Super-NaturalInstructions에서 사용된 언어 분포
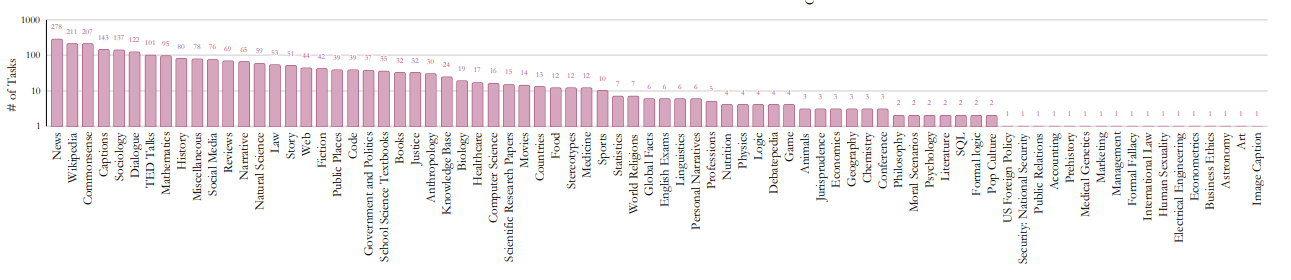 Figure 7. Super-NaturalInstructions에서 사용된 도메인 분포
Figure 7. Super-NaturalInstructions에서 사용된 도메인 분포
데이터 사이즈 관점에서는 아래의 Figure 8에서 보여주는 것처럼 다른 NatInst, PromptSource, FLAN, InstructGPT와 같은 데이터들과는 비교가 되지 않을 정도로 엄청난 규모를 자랑합니다. 각 태스크 별 버블의 크기는 데이터의 사이즈를 대변해주고 있으며, SNI 데이터 셋에는 상대적으로 ‘번역’(Translation)과 ‘질의응답’ (Question Answering)이 가장 큰 부분을 차지하고 있습니다. 아무래도 non-English 태스크와 55개의 언어를 사용하여 구축하였으니 번역 결과를 보여주는 ‘번역 (Translation)’과 ‘질의응답(Question Answering)’이 많은 것이 아닌가 생각됩니다.
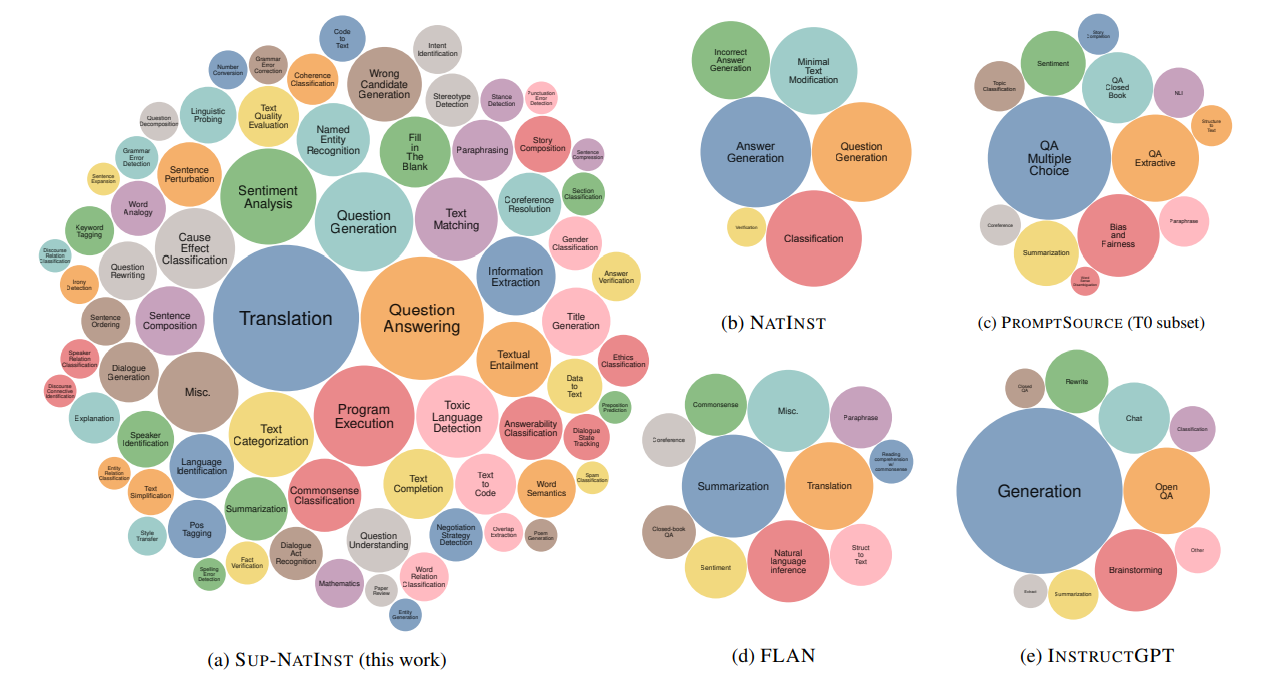 Figure 8. NatInst, PromptSource, FLAN, InstructGPT와 비교한 Super-NauturalInstructions의 태스크 별 데이터 사이즈
Figure 8. NatInst, PromptSource, FLAN, InstructGPT와 비교한 Super-NauturalInstructions의 태스크 별 데이터 사이즈
Wang et al. (2022)은 정말 자세하게 다양한 언어, 태스크, 도메인에 대한 설명을 제시하여 각 태스크, 언어 그리고 도메인에 해당하는 예시들을 구축하도록 설정하였습니다. SNI 데이터 셋에서는 좋은 예와 나쁜 예들을 설명과 함께 제시를 하였는데, 작업자들에게 좋은 예시와 나쁜 예시를 함께 제공함에 있어서 예시의 품질 검수까지 함께 진행하기 위해 더 자세한 가이드라인을 제공한 것으로 생각할 수 있습니다.
구축이 된 데이터들은 Figure 9과 같은 수량을 보여줍니다. 이 통계적인 수량을 조금 더 살펴본다면, 설명의 길이는 작업 당 약 56.6 단어이므로 상당히 긴 설명 및 자세한 설명이라고 파악할 수 있습니다. 뿐만 아니라, 각 태스크 당 2.8개의 좋은 예와 2.4개의 나쁜 예들이 있으며, 각 태스크에 평균적으로 3,106개의 예시가 구축이 되었는데 6,500개를 최대의 예시의 수량으로 제한 하였습니다.
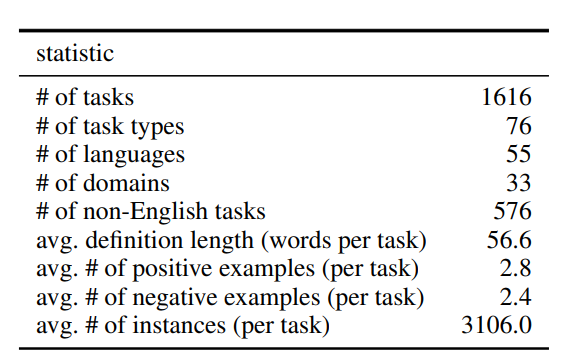 Figure 9. Super-NaturalInstructions 데이터 셋의 통계 정보
Figure 9. Super-NaturalInstructions 데이터 셋의 통계 정보
Figure 10에서와 같이 데이터에서 바이어스(bias)를 유발하지 않기 위해서 지시문은 설명 (definition), 좋은 예 (positive example), 나쁜 예 (negative example)로 되어 있습니다. 각 좋은 예와 나쁜 예에는 입력(input)과 출력(output) 그리고 설명(explanation)이 함께 구성됩니다. 좋은 예와 나쁜 예를 참고하여 만들어진 예제(instance)들이 모델에게 제공되는 입력값과 결과값인데 입력을 먼저 모델에게 제공하고 모델이 출력하는 결과와 정답이 일치하는지 확인이 진행 됩니다.
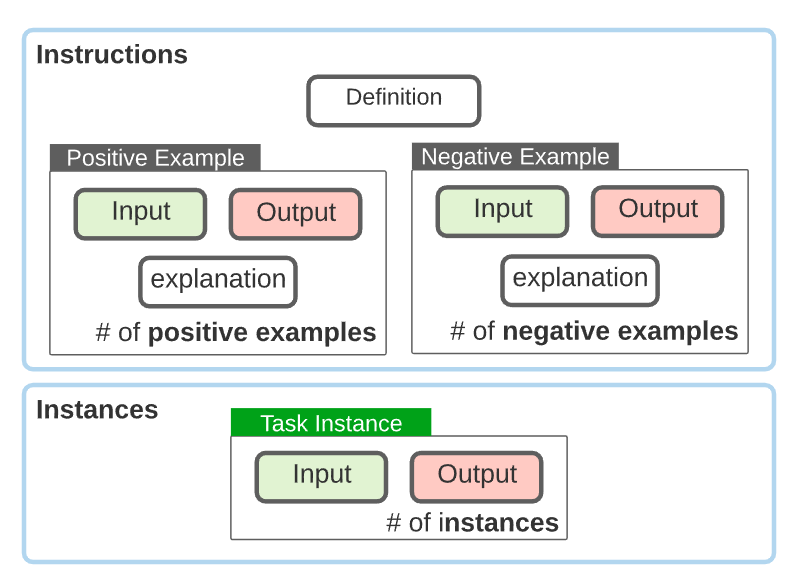 Figure 10. Super-NaturalInstructions의 템플릿
Figure 10. Super-NaturalInstructions의 템플릿
Figure 11에 있는 단어 유추(Word Analogy)의 예제를 통해 다시 한번 살펴 보겠습니다. 태스크 종류 (Task Type)과 태스크 ID (Task ID)는 어떤 태스크를 하는지에 대한 것이며, 앞에서 이야기 한 것처럼 각 태스크 별로 설명, 좋은 예, 나쁜 예, 예시가 구성되었습니다. 여기서 예시 내부에 입력과 정답(valid output)이 있는데, 이것이 입력을 모델에게 주었을 때 출력 결과물이 얼마나 ground truth와 일치하는지 볼 수 있게 만든 정답입니다. 즉, 예시의 결과는 우리가 정한 답으로 모델이 작업자가 정한 답으로 예측해주길 바라는 결과물로 생각 할 수 있습니다.
 Figure 11. 단어 유추(Word Analogy) 태스크 예시
Figure 11. 단어 유추(Word Analogy) 태스크 예시
2부를 마치며
1부부터 강조해 오던 지시문을 담은 데이터 셋들을 위주로 알아보았습니다. 프롬프트가 잘 작동되기 위해서는 모델이 다양한 태스크에 대한 문제 해결 능력을 가지고 있어야 하는데, 그것을 가능케 하는 것이 지시문이라는 것 또한 같이 알아 볼 수 있는 기회였습니다. 이전에 GPT-3처럼 대용량 자연어 데이터를 학습 용도로 생각했을 때만 해도 데이터의 수량에 가장 큰 초점을 두고 있었다면, 이제는 단순히 사이즈가 큰 수량보다는 다양한 태스크 수량에 많은 연구자 분들이 의의를 두고 있다는 것을 FLAN, InstructGPT, Super-NaturalInstructions 데이터 셋을 통해 알 수 있었습니다. 이러한 데이터를 학습한 거대언어모델 성능 평가에 대해서는 3부에서 계속하도록 하겠습니다.
References
- OpenAI. “Introducing Chatgpt.” Introducing ChatGPT, https://openai.com/blog/chatgpt#OpenAI. 2022.
- Mishra, Swaroop, et al. “Cross-task generalization via natural language crowdsourcing instructions.” arXiv preprint arXiv:2104.08773. 2021.
- Timo Schick and Hinrich Schütze. Few-shot text generation with natural language instructions. In Proceedings of EMNLP. 2021.
- Wang, Yizhong, et al. “Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks.” Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022.
- Wei, Jason, et al. “Finetuned language models are zero-shot learners.” arXiv preprint arXiv:2109.01652. 2021.
