
개요
1부에서 소개된 프롬프트 데이터의 중요성에 이어서, 2부에는 다음과 같은 3가지 데이터 셋에 대하여 자세히 알아 보았습니다. 데이터 셋들을 살펴 보면서 기존의 학습용 데이터와 크게 달랐던 부분을 1가지를 이야기 하자면, 단연코 데이터 셋 내부의 지시문(instruction)의 유무이지 않을까 생각됩니다.
- FLAN (Google) 데이터 셋
- InstructGPT (OpenAI) 데이터 셋
- Super-NatrualInstructions (Wang et al.)
2부에서 데이터 지시문에 대해 개념적으로 쉽게 받아들일 수 있게 ‘덧셈에 대한 문제 해결 접근법을 알려주는 선생님‘으로 설명을 하였습니다. 따라서, 이러한 개념을 이해하고 다시 모델의 데이터 학습과정을 생각해 보자면 출력 결과물에 대해 기존 데이터를 학습했을 때와는 큰 차이를 보일 수 밖에 없다는 것이죠. 왜냐하면, 단순히 대용량 데이터를 학습하여 문제 해결을 위한 출력 결과를 생성하는 것 보다, 문제 해결을 하기 위해 모델이 따를 수 있는 지시문이 포함 된 데이터가 더 정답 및 의도에 가까운 결과를 보여줄 수 있기 때문입니다. 결과적으로, 1부와 2부에서 계속 보여 드렸던 아래의 Figure 1이 뜻하는 내용이기도 합니다.
 Figure 1. 기존(traditional) 학습 데이터와 지시문(Instruction)을 포함한 학습 데이터의 결과 비교
Figure 1. 기존(traditional) 학습 데이터와 지시문(Instruction)을 포함한 학습 데이터의 결과 비교
이와 같은 데이터 셋 특징을 다룬 2부에 이어서, 본 포스트에서는 프롬프트 데이터를 학습한 거대언어모델의 성능 평가를 다뤄보고자 합니다. 아무리 좋은 데이터를 구축하였다고 해도 학습된 모델의 성능을 분석하지 않을 시 완전하다고 생각할 수 없기 때문에, 평가 부분은 그만큼 데이터를 다루는 작업에서 필수적인 단계입니다. 따라서, 소개 드렸던 3가지 데이터 셋의 성능 평가를 살펴보면서 모델의 관점에서 데이터의 유의미한 점을 함께 알아보겠습니다.
프롬프트 데이터를 학습한 거대언어모델 성능 평가
a) FLAN (Google) 모델 성능 평가
FLAN이란, zero-shot learning의 성능을 향상 시키기 위해 제안한 instruction-tuned 방식을 적용한 언어 모델입니다. Figure 2에 나타난 것 처럼 (A) Pretrain-finetune과 (B) Prompting 패러다임의 매력적인 측면을 결합하여 나타난 결과가 (C) Instruction tuning (=FLAN) 입니다.
- (A) Pretrain-finetune (BERT, T5) : 태스크 A를 해결하기 위해 fine-tuning을 해야 했으며, 각 태스크에 맞는 모델 필요함
- (B) Prompting (GPT-3) : few-shot prompting 혹은 prompt engineering을 통해 중간 과정 없이 바로 태스크 A에 대한 문제 해결함
- (C) Instruction tuning (FLAN) : 각 태스크 별 fine-tuning과 few-shot prompting을 결합하여 instruction-tuning 진행함
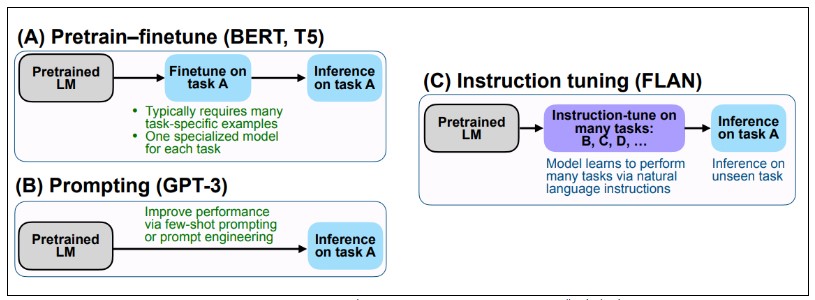 Figure 2. Instruction tuning과 Pretrain-finetune/Prompting 모델 기법 비교
Figure 2. Instruction tuning과 Pretrain-finetune/Prompting 모델 기법 비교
Figure 3에 따르면, 기존 거대언어모델인 GPT-3의 zero-shot 보다 지시문 데이터로 instruction tuning을 진행한 FLAN의 zero-shot 성능이 추론 (Natural Language Inference), 독해(Reading Comprehension), Closed-Book 질의 응답 (Closed-Book QA) 태스크에서 눈에 띄게 향상된 것이 보여집니다. 심지어 GPT-3 few-shot의 성능보다도 좋다는 결과가 나왔는데, few shot 으로 주어졌을 때 보다 FLAN의 zero shot이 효과가 좋다는 것을 통해 instruction tuning의 퍼포먼스는 기존의 학습데이터와 확실한 차별점을 두고 있다고 해석할 수 있습니다.
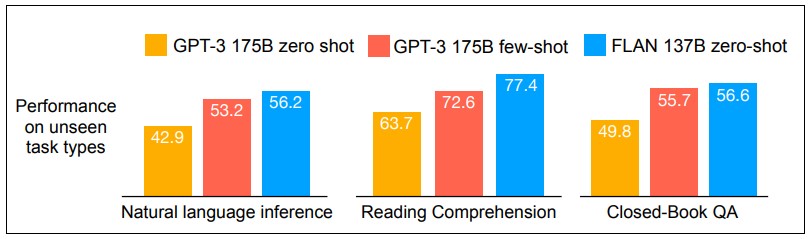 Figure 3. unseen 태스크에 대한 성능 비교 (주황색 : GPT-3 zero-shot; 빨간색 : GPT-3 few-shot; 파란색: FLAN zero-shot)
Figure 3. unseen 태스크에 대한 성능 비교 (주황색 : GPT-3 zero-shot; 빨간색 : GPT-3 few-shot; 파란색: FLAN zero-shot)
더 나아가, Wei et al. (2021)은 어떻게 FLAN의 instruction tuning이 zero-shot 성능에 영향을 미쳤는지 알아보기 위해 태스크 클러스터 수량과 데이터 수량의 상관관계에 대하여 조사를 하였습니다. Figure 4에서 보이는 것처럼, 조사 대상에는 2가지 데이터 셋으로 다음과 같이 분류되었습니다.
- held-out clusters: 학습에 참여하지 않은 평가 데이터 클러스터
- ‘상식’ (Commonsense)
- ‘추론’ (Natural Language Inference)
- ‘closed-book 질의응답’ (Closed-book QA)
- instruction tuning clusters: instruction tuning으로 학습된 데이터 클러스터
- ‘요약’(Summarization)
- ‘번역’(Translation)
- ‘독해’(Reading Comprehension)
- ‘감정’(Sentiment)
- ‘데이터 투 텍스트’(Data to Text)
- ‘상호참조’ (Coreference)
- ‘대화식 질의응답’ (Conv. QA)
성능 결과는 Figure 4 그래프에서 보여지는 초록색 선의 평균 성능을 기준으로 두고 보았을 때, 데이터 클러스터들을 추가할 때마다 ‘상식’ (Commonsense), ‘추론’ (Natural Language Inference) 그리고 ‘closed-book 질의응답’ (Closed-Book QA) 성능이 좋아지는 것을 보여줍니다. 뿐만 아니라, 아직 Figure 4 그래프에서는 성능 측면에서 포화(saturated)된 포인트가 보지 않았기 때문에 더 많은 클러스터를 추가하면 성능이 더 향상될 수 있다는 가능성을 가지고 있다고 가정해 볼 수 있습니다.
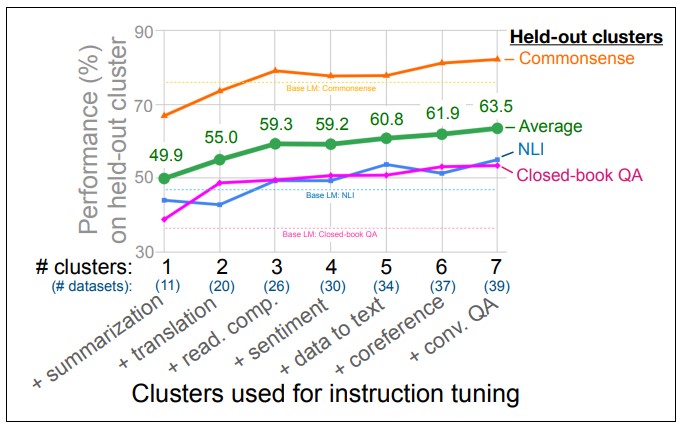 Figure 4. Instruction tuning clusters 성능 평가
Figure 4. Instruction tuning clusters 성능 평가
b) InstructGPT (OpenAI) 모델 성능 평가
두번째로 InstructGPT는 사람의 의도에 알맞게 결과를 생성하기 위해 GPT-3 모델을 기반으로 발전한 언어 모델입니다. 먼저 InstructGPT만의 새로운 학습 방법을 알아 보겠습니다. 정말로 사람이 대답하는 것과 같은 답변을 출력하기 위해 Figure 5에서 보여주는 3가지 단계를 통해 데이터 학습을 진행합니다. 처음 단계는 예시(demonstration) 데이터 수집을 통해 GPT-3를 supervised fine-tune (SFT)를 진행합니다. 그 다음으로는, 사람의 피드백이 들어간 비교(comparison) 데이터를 수집하여 보상 모델 (reward model)을 학습합니다. 마지막으로는, 강화학습을 활용하여 보상모델로 policy를 최적화 하며, policy가 학습되면서 SFT 모델도 같이 학습이 진행됩니다.
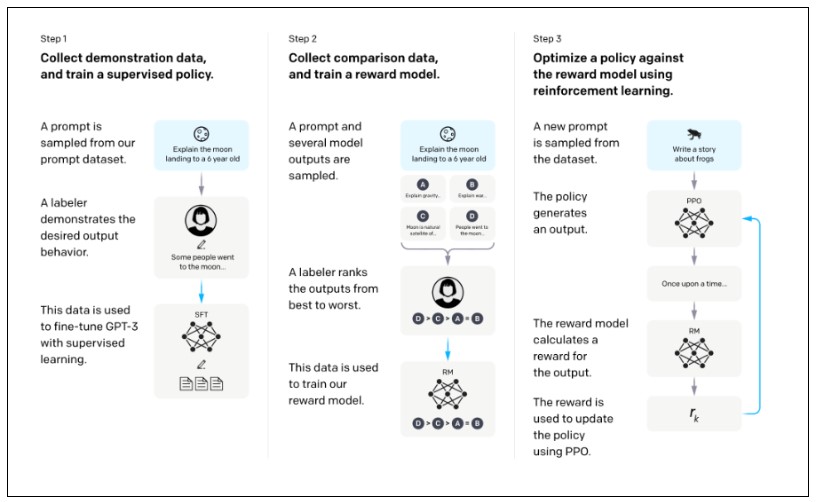 Figure 5. InstructGPT의 3단계 학습 과정
Figure 5. InstructGPT의 3단계 학습 과정
Step 1: 예시 (demonstration) 데이터 수집 및 지도학습 방식으로 모델 학습을 한다.
-
프롬프트 응답 예시 데이터 구축함
“6살 아이에게 달에 착륙하는 것을 설명해라” -
사람이 적절한 예시를 결과로 작성
“달에 착륙하는 것은 …” -
GPT-3 모델을 supervised fine-tuning (SFT) 함
Step 2: 비교 (comparison) 데이터 수집 및 보상 모델 (reword model, RM) 학습한다.
- 모델의 예측 결과에 대한 사람의 선호 순위 데이터 구축함
- 비교 데이터 구성: 샘플 답변으로 구성된 데이터에 대해 사람이 직접 선호도 순위를 레이블링 함
(예시 데이터 셋에서 사용된 것과는 다른 것으로 구성)
- 비교 데이터 구성: 샘플 답변으로 구성된 데이터에 대해 사람이 직접 선호도 순위를 레이블링 함
- 구축된 비교 데이터로 보상 모델 학습함
Step 3: 강화학습을 활용하여 보상모델로 policy 최적화한다. (Policy 학습 동시에 SFT 모델도 같이 학습됨)
- 데이터 셋에서 새로운 프롬프트 추출함
- SFT 모델이 결과 생성함
- 보상 모델은 해당 결과에 대한 보상(reward)을 계산함
- 보상은 PPO 알고리즘을 활용해 policy를 업데이트 함
이와 같은 InstructGPT만의 새로운 학습을 통해 사용자의 의도에 알맞는 답변을 생성하는 목적을 달성했습니다. 거대언어모델인 InstructGPT가 대용량의 데이터와 사용자에 알맞게 출력할 수 있게 지시문 데이터를 사용함에 있어 GPT-3보다는 확연히 다른 훌륭한 결과물을 생성 할 수 있습니다. 다만, InstructGPT에서 평가를 해야 하는 부분은 데이터의 결과값 보다는 안전성 평가에 초점을 맞췄습니다.
따라서 GPT-3의 진실성(truthfulness)과 유해성(toxicity)에 대해 극복한 점을 알아보고자 합니다. 결과적으로는 InstructGPT는 진실성이 향상되고(Figure 6-1) 해로운 결과가 감소되었습니다 (Figure 6-2). TruthfulQA를 통해 진실성을 평가한 Figure 6-1의 “QA prompt”의 결과는 InstructGPT(PPO, PPO-ptx)가 GPT보다 작지만 상당한 개선 결과를 보여줍니다 (TruthfulQA는 모델이 인간의 거질말을 어떻게 흉내내는지 평가한 벤치마크 데이터셋). InstructGPT 모델은 성능 개선 폭은 대단히 크지는 않지만 GPT보다는 진실된 답변을 주었습니다. 뿐만 아니라, “Instruct + QA prompt”에는 모델이 결과에 대해 확신이 부족할 때 “코멘트가 없다 (I have no comment)” 라고 이야기 할 수 있게 학습을 시켰습니다. 그렇기 때문에, 오히려 InstructGPT는 확실하다고 생각되는 부분에만 결과를 준다고 볼 수 있습니다. 더 나아가, 이 값들은 기본 셋팅에서 추론한 결과이기 때문에 모델이 기본적으로 GPT보다 진실하게 행동한다는 뜻으로 받아드릴 수 있습니다.
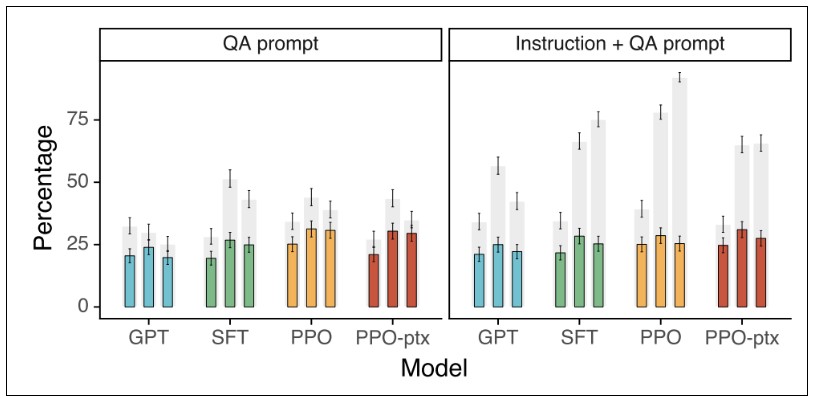 Figure 6-1. TruthfulQA에서의 QA prompt와 Instruction+QA prompt의 진실성 성능 결과
(회색바: 진실성; 색깔바: 진실성과 정보성; 바의 수량: 3가지 (1.3B, 6B, 175B) 모델 크기)
(PPO-ptx란, 기존 공개 NLP 데이터셋에 성능 저하를 고치기 위해, PPO gradient에 pretraining gradient를 혼합한 버전)
Figure 6-1. TruthfulQA에서의 QA prompt와 Instruction+QA prompt의 진실성 성능 결과
(회색바: 진실성; 색깔바: 진실성과 정보성; 바의 수량: 3가지 (1.3B, 6B, 175B) 모델 크기)
(PPO-ptx란, 기존 공개 NLP 데이터셋에 성능 저하를 고치기 위해, PPO gradient에 pretraining gradient를 혼합한 버전)
더불어 유해성에 대해서 Figure 6-2를 보면 사람 평가(Human eval)와 자동평가(PerspectiveAPI score)로 이루어졌습니다. 안전한 결과를 출력하라고 할 때 (respectful) InstructGPT는 GPT 보다 더 안전한 결과를 생성해 주지만 그러한 지시를 해제했을 경우 (None) InstructGPT는 더 이상 안전하게 결과를 보여준다고 할 수 없습니다. 특이하게, 해로운 결과를 출력하라고 지시하면 오히려 InstructGPT가 GPT보다 더 해로운 결과를 가져다 주기도 합니다. 이 뜻은 InstructGPT가 지시문을 잘 따르는 능력이 높다고 할 수 있습니다. 따라서 누가 어떤 지시를 하는지가 InstructGPT의 유해성에 대한 관건이 될 수 있다고 할 수 있습니다.
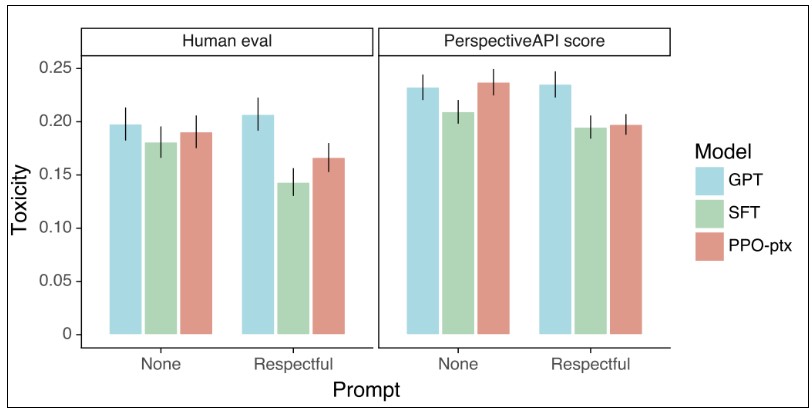 Figure 6-2. 해로운 (Toxicity) 결과 성능 결과
(Respectful: 해로운 결과를 출력하지 않게 지시함; None: 지시 하지 않음)
Figure 6-2. 해로운 (Toxicity) 결과 성능 결과
(Respectful: 해로운 결과를 출력하지 않게 지시함; None: 지시 하지 않음)
그러므로 Figure 7에서 보여주는 것처럼 GPT, GPT(prompted), FLAN, T0보다 InstructGPT (SFT, PPO-ptx)가 더 좋은 성능을 보여줍니다. InstructGPT는 GPT-3에 비해 확실히 더 안전하다고 볼 수 있으나, 사실 여전히 해로운 결과를 생성하기도 합니다. 그럼에도 불구하고, Ouyang et al. (2022)는 이렇게 supervised fine-tuning을 한 모델에서 사람의 피드백을 한번 받아 보상 모델을 학습하여 강화학습을 통해 policy를 최적화함에 있어서 언어 모델이 사람의 의도에 알맞게 맞춰지는 방법임을 증명하였습니다. 즉, Ouyang et al. (2022)에서 이야기 하는 언어 모델이 사람 의도와 align될 수 있게 만드는 알맞는 방법이라고 말할 수 있습니다.
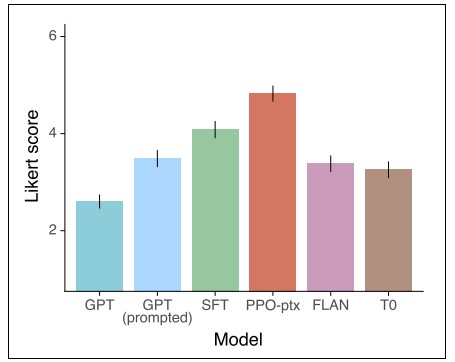 Figure 7. GPT, GPT(promted), FLAN, T0와 InstructGPT(SFT, PPO-ptx)의 성능 비교 (Likert score 1~7)
Figure 7. GPT, GPT(promted), FLAN, T0와 InstructGPT(SFT, PPO-ptx)의 성능 비교 (Likert score 1~7)
c) Super-NaturalInstructions (Wang et al.) 모델 성능 평가
마지막으로 Tk-Instruct모델은, Super-NaturalInstructions 데이터셋을 학습한 T5모델이며 InstructGPT (175B)에 비해 아주 작은 파라미터들을 가지고 있지만 훨씬 좋은 성능인 것을 아래의 Figure 8을 통해 확인할 수 있습니다. 또한, 사람의 평가 및 모델 평가에서 전부 Tk-Instruct 모델이 효과적인 task generalization을 나타냈습니다. 이 기회를 통해 대량의 데이터와 수많은 파라미터를 가지고 있는 스펙은 높은 성능의 조건일 수 있지만, 꼭 좋은 품질의 결과를 가져온 다는 것에 대해서는 장담할 수 없습니다.
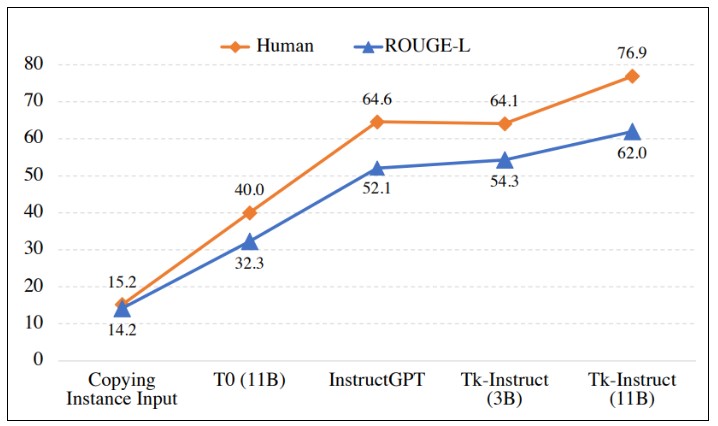 Figure 8. 사람 평과와 Rouge-L 의 모델 평가 결과
Figure 8. 사람 평과와 Rouge-L 의 모델 평가 결과
데이터와 모델 파라미터에 따른 수량을 측정해 보았을 때, Figure 9에 나타난 것처럼 훈련 태스크 (training tasks)가 많아질 수록 성능이 높아지며, 모델 파라미터 (model parameters)가 커질 수로 성능이 높아지는 것을 확인할 수 있습니다. 하지만, 각 훈련 태스크에 대해 60개 이상의 예시문들이 학습될 때 모델 성능이 포화(saturated)된 것 또한 확인 되었습니다. 따라서, 이 결과를 바탕으로 다양한 태스크 수량 및 사이즈가 큰 모델은 성능 개선에 도움이 되지만, 각 태스크 별 예시문들은 최대 60개 까지만 준비가 되어도 성능에 큰 차이가 없다고 볼 수 있습니다.
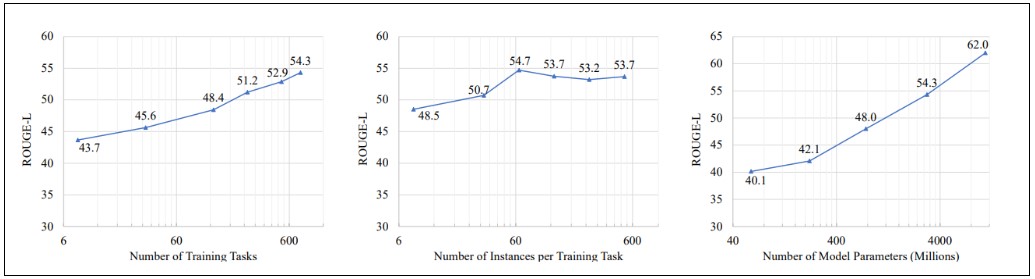 Figure 9. 훈련 태스크의 수, 각 훈련 태스크 수량에 대한 예시 수, 모델 파라미터 수 (왼쪽부터)
Figure 9. 훈련 태스크의 수, 각 훈련 태스크 수량에 대한 예시 수, 모델 파라미터 수 (왼쪽부터)
뿐만 아니라, 다양한 조합의 데이터 학습을 통해 모델의 성능이 좌지우지 된다는 것을 아래의 Figure 10에서 확인할 수 있습니다. Task Definition이 계속해서 Tk-Instruct의 성능을 높여 주는 것을 밑줄 부분의 숫자를 보면서 알 수 있습니다 (대각선). 또한, 메타 데이터들을 다양하게 많이 추가한다고 해서 성능이 더 좋아지는 것은 아니라고 볼 수 있습니다. Def + Pos (2) + Neg (2)의 조합과 Def + Pos (2) + Neg (2) + Expl과 Pos(4)의 경우 비교적 성능이 낮아지는 것이 확인되기 때문입니다.
Generalization의 관점에서는 대각선 이외의 숫자들을 살펴보면 되는데, 태스크 ID (Task ID) 혹은 설명(Definition)만 학습한 모델은 generalization에 낮은 성능을 보여주고 있습니다. 반대로, 설명(definition)과 좋은 예시(positive example)의 조합인 Def+Pos(2)와 Definition + Pos(4) 같이 학습된 모델은 다양한 조합에서 견고한 generalization 성능을 보여 줍니다.
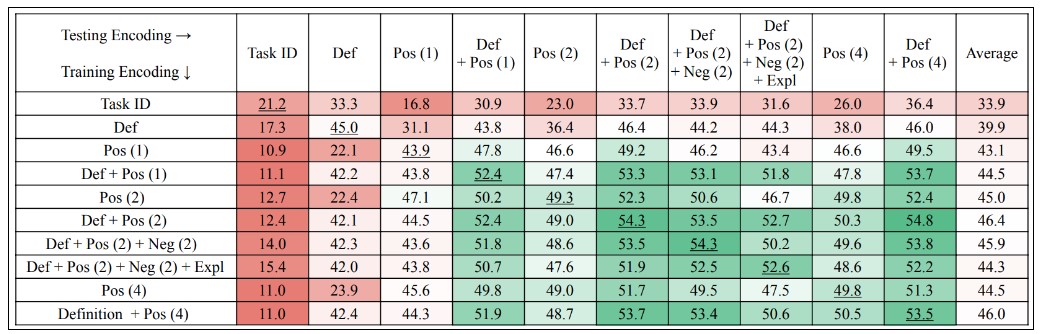 Figure 10. 메타 데이터 조합 및 데이터 수량(괄호안의 숫자) 별 성능 결과 (training encoding: 학습 조합, testing encoding: 평가 조합)
Figure 10. 메타 데이터 조합 및 데이터 수량(괄호안의 숫자) 별 성능 결과 (training encoding: 학습 조합, testing encoding: 평가 조합)
마치며
본 3부를 끝으로 프롬프트 데이터에 대한 소개를 마무리 지었습니다. 3부까지 포스팅을 진행하는 동안 거대언어모델의 발전으로 인해 학습 데이터의 형식과 학습 과정에 많은 변화가 생긴 패러다임에 대하여 공유 할 수 있었던 좋은 기회였습니다. 대용량 데이터의 필요성에서 더 나아가 데이터 내부에 지시문이 포함되어 있어야지만 모델이 학습을 진행하였을 때 NLP 태스크에 대한 문제 해결 능력이 향상된다는 점을 알 수 있었습니다. 더불어, 사람과 같은 언어 구사력을 갖을 수 있게 도와주는 RLHF 기법까지 곁들여야 한다는 점을 많은 논문들과 연구들을 통해 인지 되고 있습니다. 기술이 발전하면서 데이터에 인력이 투입되는 부분은 점점 사라지는 부분에 대해 언급을 빼놓을 수 없는데 지시문 데이터들과 모델을 보니 사람의 판단력이 필요한 영역이 남아 있기에 둘 중에 하나만 남는 세상이 아닌 서로 상호작용을 하면서 시너지 효과를 보여주는 방향성으로 기술 발전이 되지 않을까 기대됩니다.
References
- OpenAI. “Introducing Chatgpt.” Introducing ChatGPT, https://openai.com/blog/chatgpt#OpenAI. 2022.
- Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901.
- Mishra, Swaroop, et al. “Cross-task generalization via natural language crowdsourcing instructions.” arXiv preprint arXiv:2104.08773 (2021)
- Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155. 2022.
- Timo Schick and Hinrich Schütze. Few-shot text generation with natural language instructions. In Proceedings of EMNLP. 2021.
- Wang, Yizhong, et al. “Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks.” Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022.
- Wei, Jason, et al. “Finetuned language models are zero-shot learners.” arXiv preprint arXiv:2109.01652. 2021.
