
2부: Parameter-Efficient Fine-Tuning (PEFT) 방법들 (LLM)
- TL;DR
- 지난 이야기 & 개괄
- 1. Parameter-Efficient Fine-Tuning (PEFT) 방법들
- 2. Low Rank Adaptation: LoRA
- 3. 마치며
- Outlink: 추천드리는 자료
- References
TL;DR
- Parameter-Efficient Fine-Tuning (PEFT) 을 수행하는 다양한 방법들 중 몇 가지 대표적인 몇 가지 형태들을 소개합니다.
- 이 중 최근 사랑받고 있는 LoRA에 대해서 좀 더 자세히 살펴봅니다.
지난 이야기 & 개괄

다시 만나뵙게 되어 반갑습니다 =] 우리 1부 에서 만났었죠? 1부: 생각보다는 연속적인 기술의 발전으로 등장한 Large Language Model (LLM) 에서는 ChatGPT를 화두로 어떻게 LLM은 다시 강팀(?)이 되었는지, 그리고 그 기술적 흐름의 원천까지 함께 살펴보았습니다.
이번 글에서는 LLM을 미세조정 하는데에 필수에 가까운 기술인 Parameter-Efficient Fine-Tuning (PEFT) 방법들과 그 중 최근에 자주 활용되고 있는 LoRA(Low Rank Adaptation) 에 대해 소개해드리고자 합니다. 그럼 시작해볼까요?
1. Parameter-Efficient Fine-Tuning (PEFT) 방법들
PEFT 방법들은 성능을 유지하면서 파라미터(가중치)의 수를 줄이는 것을 목표로 합니다.
성능은 유지하고 싶은데 사이즈는 줄이고 싶다?

(결과론적이긴 하지만) 이건 요행을 바라는 이야기는 아닙니다. LLM이 학습한 능력을 활용이미 학습한 것을 최대한 활용한다는 관점에서 전이학습(Transfer Learning) 이라는 용어로 설명되기도 합니다. 미리 배워 놓은 것을 전이(transfer) 해서 활용한다는 뜻입니다.한다면 넘어서기에 충분한 목표인 것으로 밝혀졌거든요. 이를 위해 PEFT 방법들은 LLM의 파라미터들 대부분을 보존하고 일부만 학습시키거나 전체를 보존하고 일부를 추가하여 학습을 진행합니다.
1.1. 정말 일부 파라미터만 학습시키기
이 방법들은 다른 요소를 추가하지 않고 LLM의 특정 층이나 파라미터만 선택적으로 학습시키는 방법들입니다. (Transformer 구조인) LLM의 output layer 일부만 학습시키거나 신경망 가중치에서 bias 파라미터 (Y = WX + B 에서 B) 만 학습시키는 방법 (BitFit1) 등이 있습니다.
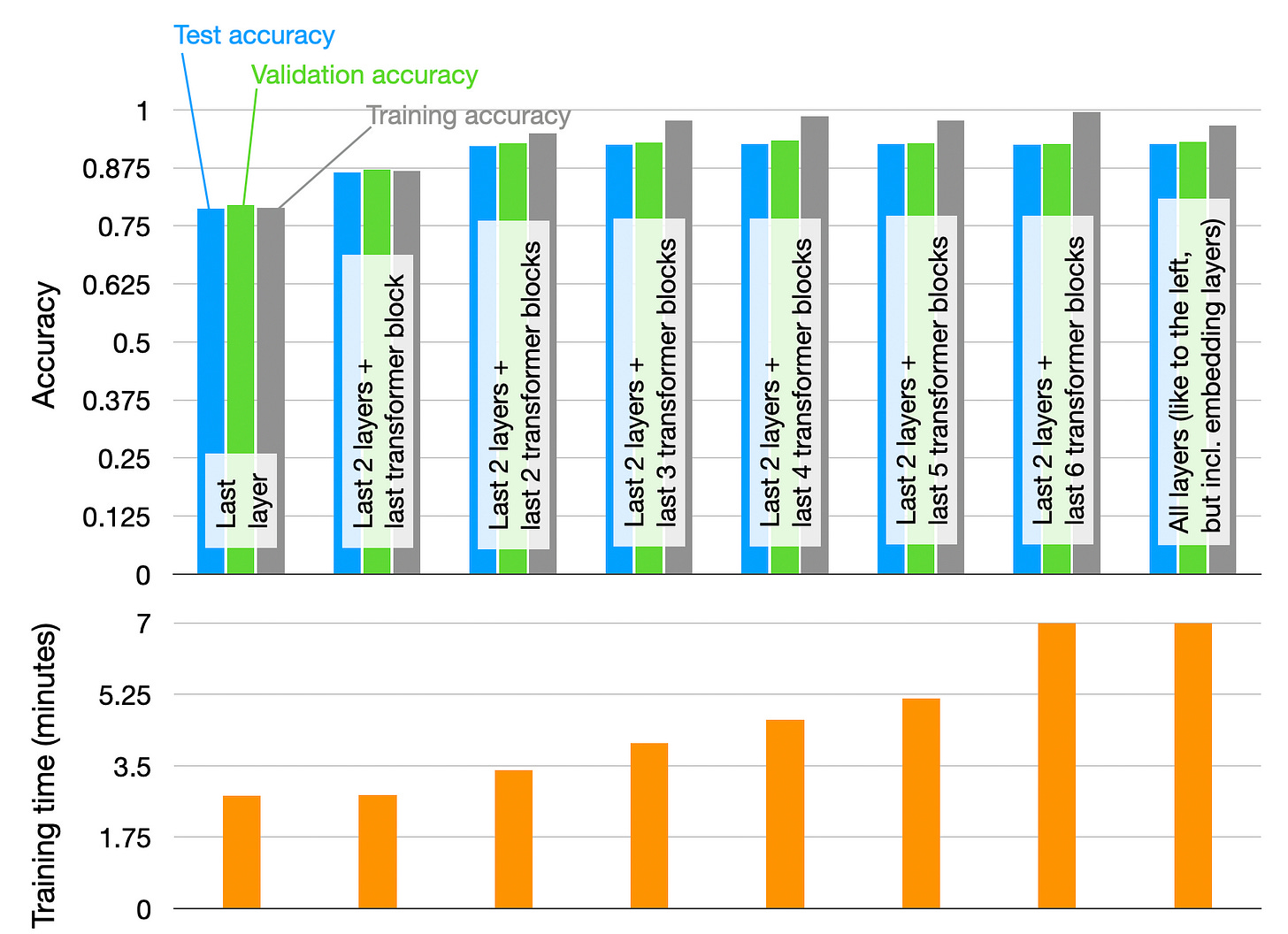 Transformer 구조의 마지막 층, 그리고 출력에 가까운 부분부터 Transformer 블럭을 하나씩 늘려서 학습시킬때 도달하는 성능과 필요한 학습 시간을 보여준다2
Transformer 구조의 마지막 층, 그리고 출력에 가까운 부분부터 Transformer 블럭을 하나씩 늘려서 학습시킬때 도달하는 성능과 필요한 학습 시간을 보여준다2
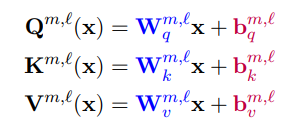 Fine-Tuning에서 학습이 필요한 부분은 가중치 (weight, 파란색) 와 편향 (bias, 자주색) 이지만 BitFit 에서는 편향만 학습한다
Fine-Tuning에서 학습이 필요한 부분은 가중치 (weight, 파란색) 와 편향 (bias, 자주색) 이지만 BitFit 에서는 편향만 학습한다
1.2. 미세조정과 같은 효과를 내는 Prompt를 학습하기
앞선 1부에서 잠깐 소개했지만, LLM에는 특정 텍스트를 입력으로 주고 원하는 출력을 얻도록 유도할 수 있는 방법들이 있습니다. 예를 들면 나는 집에 ___ 라고 비워놓으면 “간다”가 떠올리도록 LLM이 학습했다는 점을 활용하는건데요, 이것을 Prompting (말 그대로 ‘글의 앞부분 써주기’) 이라고 합니다.
하지만 우리가 같은 말도 ‘아’ 다르고 ‘어’ 다르게 할 수 있는 것처럼혹자는 여기서 linguistic productivity를 떠올릴 것이다. 같은 말을 얼마든지 다르게 표현할 수 있는 언어의 특징을 지칭한다. 가능한 prompt는 무수히 많으며 단어라는 이산적인 값들의 조합입니다. 이런 이산공간(discrete space) 에서의 최적화는 경사하강법경사하강법 (Gradient Descent): 학습 예시들로부터 신경망이 추론한 값과 정답간의 차이를 산출하고 이를 줄이기 위해 가중치들의 1계도함수, 즉 경사 (Gradient) 를 계산하여 가중치를 업데이트(혹은 학습)하는 방법. 정답과 추론값은 연속적인 값을 가져야한다.으로 가중치를 업데이트하는 신경망 학습 방법을 그대로 적용하기에 어려움이 있습니다. 그렇다면 최적의 결과를 내는 prompt는 어떻게 찾을 수 있을까요?
물론 강화학습으로 직접 prompt를 찾아보는 것도 방법이겠지만 (RLPrompt3) 우리가 평소에 단어들을 신경망에서 어떻게 다루는지에 대해 살펴본다면 경사하강법을 바로 적용할 수 있는 우회방법 역시 존재합니다. 아래를 보시죠.
 컴퓨터에서 텍스트는 0, 1, 2와 같은 이산 값으로 표현되지만 신경망에서는 이를 실수 (연속 값) 로 이루어진 벡터로 매핑하여 처리한다.
컴퓨터에서 텍스트는 0, 1, 2와 같은 이산 값으로 표현되지만 신경망에서는 이를 실수 (연속 값) 로 이루어진 벡터로 매핑하여 처리한다.
 그러므로 신경망의 학습은 단어를 다루는 대신 단어의 임베딩을 다루게 된다.
그러므로 신경망의 학습은 단어를 다루는 대신 단어의 임베딩을 다루게 된다.
같은 맥락에서 Prompt text (단어, 이산값) 을 찾는데에 경사하강법을 바로 적용할 수는 없지만 최적의 출력을 내놓을 prompt embedding (벡터, 연속값)을 학습하는 것은 가능합니다.
때문에, 그림처럼 전체 네트워크 파라미터를 미세조정 하는 대신에 우리는 prompt embedding만을 학습하도록 미세조정을 진행할 수 있습니다. 이를 Prompt-Tuning4 이라 부르는데 이는 그림과 같이 그려볼 수 있습니다.
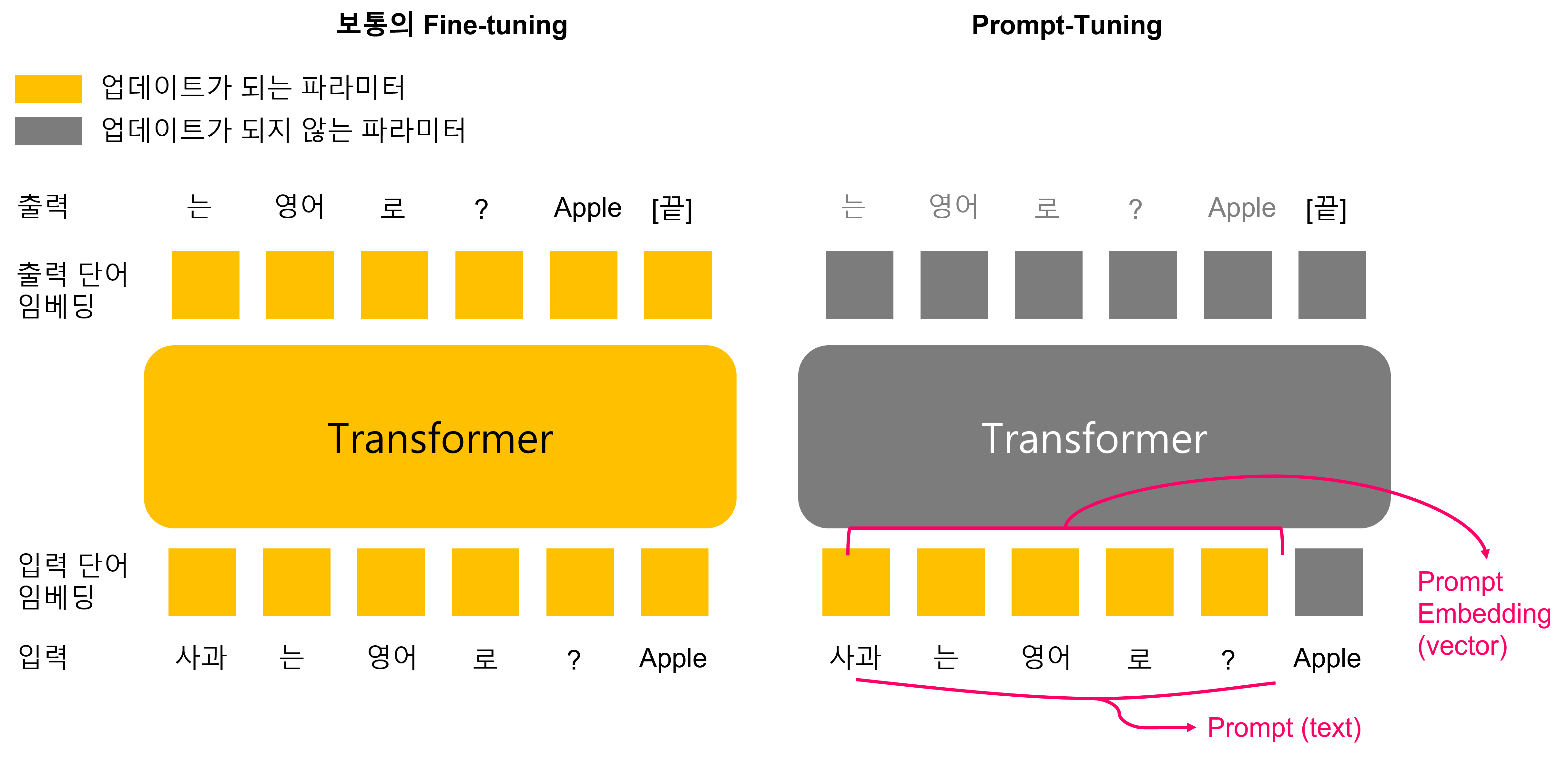
이에서 파생된 많은 방법들이 있는데 prompt text를 직접 찾을 때 prompt text를 hard prompt라고 부르고 prompt embedding에 여러가지 조치를 취하는 방법들을 이야기할 때 hard prompt 에 대비되도록 soft prompt라고 부르기도 합니다.
1.3. 다양한 (Soft) Prompt 학습 방법들
앞서 보여드린 Prompt-Tuning은 정말 간단한 방법이었기 때문에 많은 변주들이 존재합니다. 이런 변주들은 자주 언급되기도 하니 한 번 짚어보고 넘어갑시다.
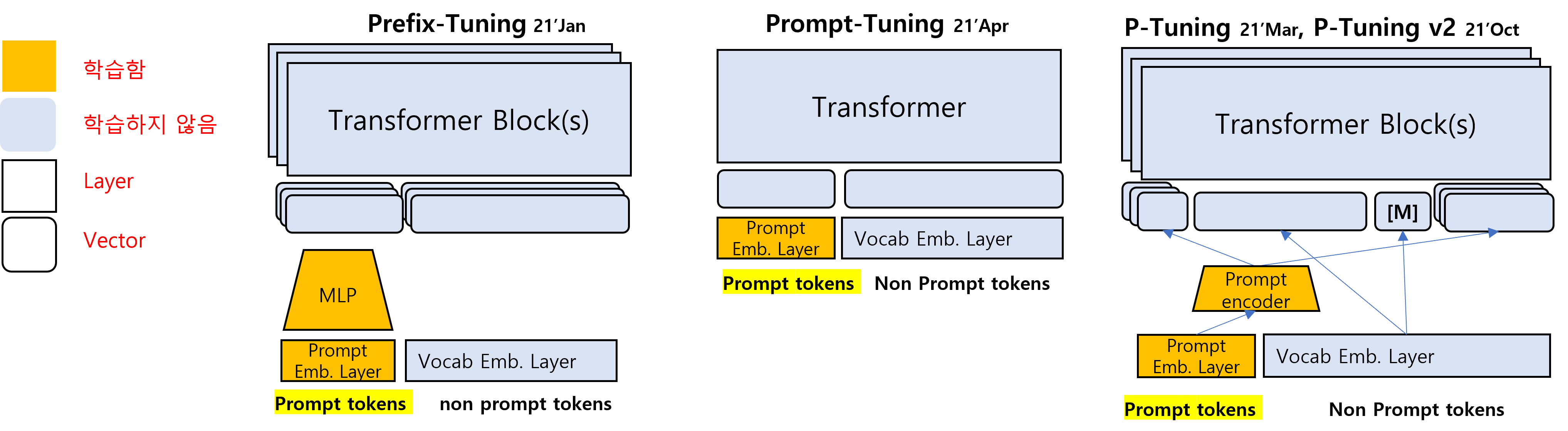 (시간순) 가운데 그림이 직전 섹션에서 다루었던 Prompt-Tuning이다.
Prefix-Tuning5 이나 P-Tuning v16, v27 에서는 트랜스포머 여러 층에 영향을 주기 때문에 Transformer Block(s)로 표기하고 여러 층이 겹쳐진 것으로 그렸다.
(시간순) 가운데 그림이 직전 섹션에서 다루었던 Prompt-Tuning이다.
Prefix-Tuning5 이나 P-Tuning v16, v27 에서는 트랜스포머 여러 층에 영향을 주기 때문에 Transformer Block(s)로 표기하고 여러 층이 겹쳐진 것으로 그렸다.
Prompt-Tuning의 경우에는 간단히 입력으로 들어가게 될 prompt embedding만을 학습하였지만, Prefix-Tuning의 경우에는 임의의 prompt embedding을 여러층에 들어갈 입력 벡터로 바꿔주는 Multi-Layer Perceptron (MLP)를 따로 학습합니다. P-Tuning은 Prefix-Tuning과 비슷하지만 prompt encoder가 추가될 수 있다는 점과 encoder-only 모델에 적용하여 prompt embedding 위치가 자유롭다는 점이 다릅니다.P-Tuning과 Prefix-Tuning의 차이점 두가지는 다음과 같습니다 (1) prompt encoder를 MLP나 LSTM으로도 사용했다는 점, (2) 양방향을 보는 Encoder-only 언어모델에 적용된 방법이기 때문에 prompt의 위치가 예측할 토큰 위치보다 오른쪽에 있어도 된다는 점입니다. 마스크 토큰 [M] 을 굳이 표기해준 이유가 여기에 있습니다.
1.4. Adapter: Transformer Block에 학습 가능한 작은 모듈 끼워넣기
위에서는 LLM의 연산과정에 들어가는 embedding vector 들을 학습하는 것으로 미세조정을 대체하고자 했습니다. 이와 달리 Adapter는 Transformer 구조에 작은 모듈을 추가해서 LLM 전체를 미세조정하는 것과 같은 효과를 내고자 했습니다. Adapter는 LLM을 학습시킬 때 간단한 방법론으로 자주 사용되며, LLM 전체를 미세조정하는 것과 유사한 효과를 얻을 수 있습니다. 다만, 일부 레이어를 거쳐야 하므로 추론 시 시간적인 손해가 발생할 수 있습니다.
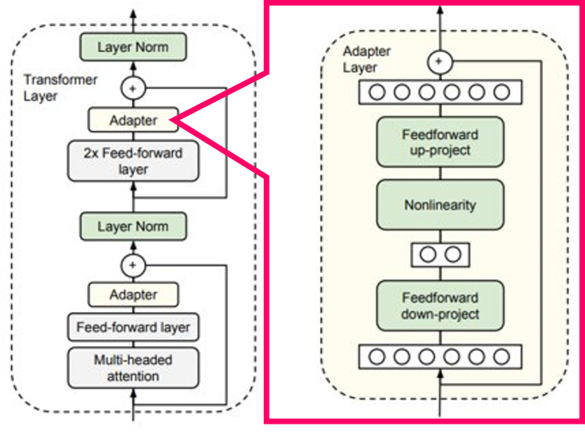 통칭 Adapter8 라고 불리는 이 방법은 Transformer Block 내부에 Adapter Layer를 끼워넣는 것으로 구성된다
통칭 Adapter8 라고 불리는 이 방법은 Transformer Block 내부에 Adapter Layer를 끼워넣는 것으로 구성된다
2. Low Rank Adaptation: LoRA9
위에서 소개된 많은 방법들은 LLM의 가중치를 유지하면서 작은 모듈이나 입력 벡터를 학습하여 이점을 추구했지만, 이러한 방법들은 경험적인 근거에 의존하는 경우가 많습니다.Prompt-tuning은 LLM prompting 의 가능성을 근거로 설계되었고, Adapter는 사전학습된 모델로 vector representation을 얻어내 입력 feature로 활용하는 기존의 전이학습 방법론에서 많은 영향을 받았다.
LoRA는 이보다는 조금은 더 깔끔한 근거 (필자 의견) 를 바탕으로 설계되었으며, 위의 방법론들보다 더 단순하고 제약사항이 적으며 성능이 동등하거나 더 좋습니다. 안정적인 성능을 보여주고 있는 LoRA는 LLM을 PEFT하는 것을 넘어서 최근 이미지 생성에 많이 사용되고 있는 Stable Diffusion 모델10 에도 필수품처럼 사용되고 있습니다.
어떻게 되어있는데 단순하냐구요? 더 자세히 설명하겠지만 잠깐 아래의 수식을 보시죠.
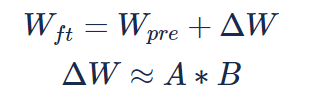
(여기서 \(r\) < \(m\), \(n\) 은 각각 자연수이고 \(W_{ft}\), \(W_{pre}\), \(\Delta W\) 는 모두 \(m \times n\) 실수 행렬, \(A\), \(B\) 는 각각 \(m \times r\), \(r \times n\) 실수 행렬입니다.)
한 줄로 설명하자면, LoRA는 미세조정으로 달라지는 네트워크 가중치(\(\Delta W\))를 근사할 두 개의 작은 행렬 (\(A\), \(B\)) 을 학습시키는 방법입니다.
LoRA는 어떤 아이디어에서 시작해서 어떻게 디자인되었는지 앞서 소개한 방법들과 비교하여 어떤 장점이 있을지 아래에서 좀더 차근차근 같이 탐험해봅시다.
2.1. LoRA의 아이디어
미세조정은 LLM이 여태 학습한걸 뒤엎어버리는 대규모의 변화보다는 원하는 작업을 위해 LLM을 섬세하게 조정하는 과정을 묘사하는 단어입니다. LLM이 사전학습한 능력을 시작점으로 하기 때문에 같은 데이터양으로도 학습시켰을 때 훨씬 나은 성능을 기대할 수 있는거잖아요? LLM을 등에 업고 원하는 작업(downstream task)을 학습하는 일은 생각보다 어렵지 않은 일일지도 모릅니다.
그렇다면 미세조정을 하는데에 LLM이 포함한 수만큼 많은 파라미터를 학습하는건 너무 과한게 아닐까? 이 질문이 LoRA 방법론의 핵심에 있는 아이디어입니다.
이 아이디어와 큰 행렬을 작은 두 개의 행렬곱으로 바꾸는 것은 어떻게 연결될까요? 아래의 예시를 봅시다.

이 문제에 답을 제출할 때, 최대한 작은 행렬을 답으로 하고 싶다면 3번과 같이 열이 1개인 행렬을 선택할 수 있습니다. 따라서 이 문제를 푸는데 필요한 최소 열의 갯수 (n) 는 1개입니다. 5 x 5 크기의 행렬도 답안이 될 수 있지만 5 x 1 행렬로 답을 대신할 수도 있다는 뜻이죠.여기서 n을 intrinsic dimension이라고 합니다 미세조정을 하는 건 이 문제보다는 어렵겠지만, 대충 비슷하다고 생각해봅시다.
이쯤에서 수식을 다시 한 번 봅시다.
미세조정이 끝나서 원하는 문제를 풀 수 있게 된 신경망의 가중치를 \(W_{ft}\) 처럼 큰 행렬 하나라고 생각해봅시다. 이 행렬은 미세조정 전의 LLM의 가중치인 \(W_{pre}\) 와 미세조정하면서 변화한 차이인 \(\Delta W\) 로 표기해볼 수 있을겁니다.
우리가 하고자 하는 건 \(\Delta W\) 를 LLM보다 적은 파라미터로 표현하는 것입니다. 요컨데 \(\Delta W\) 이 원래 5 x 4 행렬이었다면 이것을 곱해서 같은 모양과 값이 되는 두 개의 더 작은 행렬 (\(A\), \(B\))을 마련할 것입니다. 이를 그림으로 그려봅시다.
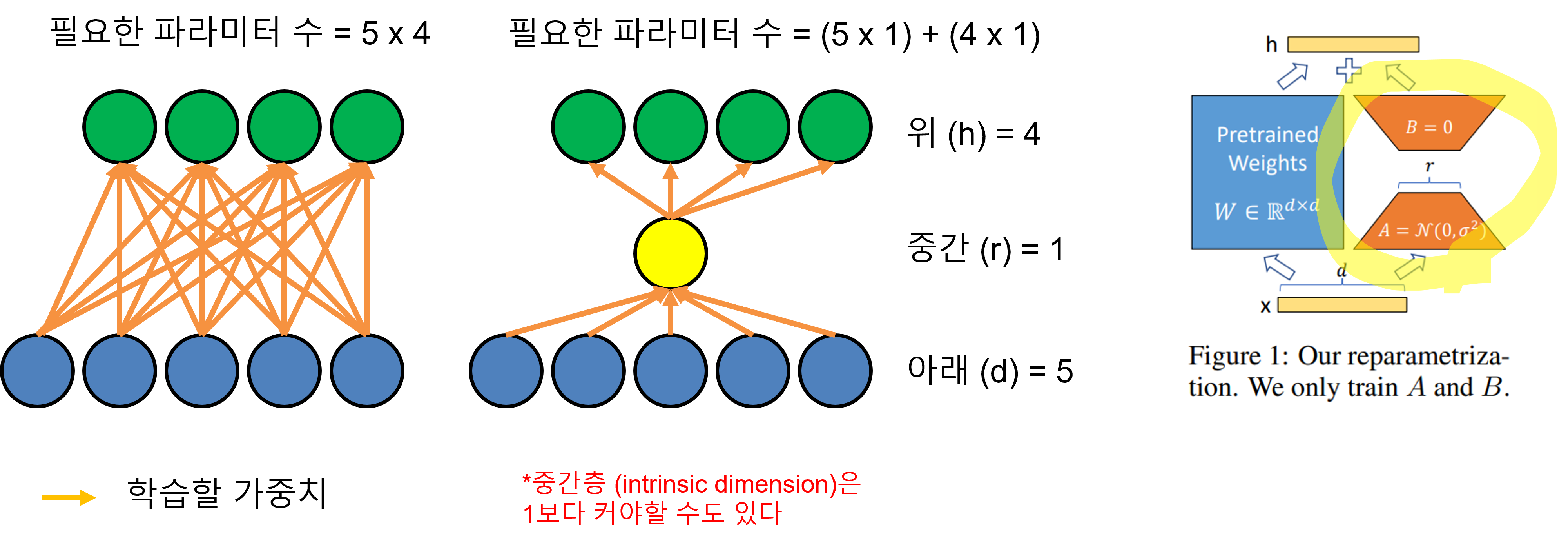 차원이 5에서 4로 줄어드는 신경망 예시. 왼쪽 그림은 5x4 의 가중치 행렬로 나타낼 수 있고, 중간은 5x1과 1x4 두 개의 행렬로 나타낼 수 있다.
차원이 5에서 4로 줄어드는 신경망 예시. 왼쪽 그림은 5x4 의 가중치 행렬로 나타낼 수 있고, 중간은 5x1과 1x4 두 개의 행렬로 나타낼 수 있다.
맨 오른쪽은 LoRA 논문에서의 개념도. 왼쪽 두 그림처럼 큰 행렬 하나를 작은 차원 하나를 끼고 둘로 분해한 것을 묘사했다.
행의 합을 구하는 문제에서처럼 같은 출력을 내놓는데 필요한 파라미터의 수는 5x4 (\(W, m \times n\)) = 20개 일수도 있겠지만, 그림처럼 5x1 (\(A, m \times r\)) + 1x4 (\(B, r \times n\))= 9개로도 충분할 수 있습니다. 파라미터 20개를 사용해도 되지만 이를 9개로 줄여도 답을 내놓는데 문제가 없는것이죠.
이렇게만 된다면 미세조정에 필요한 파라미터 수가 LLM이 원래 포함한 것보다 훨씬 적어질 수도 있겠군요?
이렇게만 된다면…말이죠?
¯\_(ツ)_/¯

제가 깔끔하다고 생각한 이유는 이게 아님말고 식의 가설이 아니라는 점입니다. 미세조정으로 같은 성능에 도달하기 위해 필요한 파라미터 수는 사전학습 모델의 그것보다 훨씬 작다는 사실이 이미 보고되어있으며 11이 내용들이 LoRA의 핵심 가설을 뒷받침하는 근거로 제시되고 있습니다.
이런 원리로 LoRA는 학습할 파라미터의 수를 LLM을 그냥 미세조정할 때 대비 0.01% 수준까지 줄일 수 있었습니다. 두 개의 작은 행렬곱을 학습보통 신경망의 각 층에는 행렬곱 (선형 연산) 뿐만 아니라 비선형연산 등이 포함되어 훨씬 복잡하다. Adapter가 복잡한 케이스라면 LoRA에서 하는 연산은 선형 연산이므로 부담이 적다.하는 걸로요.
2.2. 실제 효과
GPU 메모리 절약 수준
| model name | type | num params | 미세조정시 필요한 GPU 메모리 | LoRA 사용시 필요한 GPU 메모리 |
|---|---|---|---|---|
| bigscience/T0 | Encoder-Decoder | 3B | 47.14GB | 14.4GB |
| bigscience/bloomz-7b1 | Decoder only | 7B | OOM (80GB+) | 32GB |
표는 Huggingface 패키지 peft(peft-github)에서 제공하고 있는 LoRA의 GPU 메모리 점유량 테스트입니다. 다른 트릭 없이 LoRA만 사용하는 경우에도 필요한 GPU 메모리가 위와 같이 현저하게 줄어드는 것을 확인할 수 있습니다. 40GB 짜리 메모리 크기를 가진 A100 한 장에서 학습이 불가능하던 모델들이 LoRA를 적용하면 다른 트릭 없이 GPU 한 장에 들어옵니다.차지하는 메모리 크기가 1/10000이 아닌 이유는 학습파라미터와 그래디언트가 차지하는 크기 이외에도 GPU 메모리를 차지하는 다른 요소들이 많이 있기 때문입니다.
도달하는 성능
자연어 이해 문제를 학습할 때에도, 그리고 자연어 생성 문제를 학습할 때에도, PLM의 파라미터 갯수가 1B정도일 때에도, 175B일 때에도 LoRA의 성능이 전체를 미세조정한 것과 동등하거나 조금 더 나은 것을 확인 할 수 있습니다.
 미세조정, 그리고 Adapter, BitFit 등의 다른 PEFT 방법들과 비교한 LoRA의 도달 성능 비교 (LoRA논문 표9 )
미세조정, 그리고 Adapter, BitFit 등의 다른 PEFT 방법들과 비교한 LoRA의 도달 성능 비교 (LoRA논문 표9 )
첫 번째는 자연어 이해 작업을 1.5B 이하 PLM에 학습시키는 경우, 두 번째 세 번째는 자연어 생성 작업을 각각 1B 미만, 175B LLM에 학습시키는 경우
그 외 장점
학습 이후에 LoRA로 학습된 작은 행렬들을 다시 합쳐서 아래처럼 그냥 하나의 네트워크처럼 취급할 수 있습니다. LoRA 를 활용해 학습한 LLM은 추론시 연산량에 추가되는 부하가 없다는 뜻입니다.


또한 학습시에도 LLM의 연산에 의존적인 과정을 거치지 않기 때문에 학습시간이 더 걸리지도 않습니다. 이는 Adapter와는 달리 학습과 추론시간에서 손해를 보지 않는다는 점에서 훌륭합니다. Soft Prompt 방법들처럼 입력 길이를 소비해야하는 문제도 없습니다.이에 대한 실험들도 논문에 실려있습니다.
2.3. 정말 그렇게 좋을까?
보통 논문들은 강점은 살리고 약점은 잘 보이지 않게 작성되어있는 경우가 많아서 실제 상황에서는 쓰임새가 아쉬운 경우가 많습니다만 LoRA의 경우에는 21년도 논문에서 제안된 방법임에도 불구하고 아직 완전한 상위호환이 보이지 않아서 계속 사랑받고 있는 것 같습니다. 너도나도 LLM들을 공개할 때마다 사람들이 달려가서 LoRA를 활용해 LLM들을 학습시켜보고 있으니까요.
그 외에 좀 더 신기한 점은 이것이 Stable Diffusion 모델을 적은 GPU 환경에서 학습하는데에 표준처럼 사용되고 있다는 점입니다. 원래 LoRA는 LLM PEFT를 위해 제안된 방법이지만 별 공통점이 없어보이고 아키텍처도 다른 Stable Diffusion 모델에서도 잘 작동하고 있는 것이죠. 다른 구조의 신경망에서도 잘 동작한다는 점은 이 기술에 신뢰성을 더해줍니다.
 LoRA로 학습한 이미지 생성 모델 (Stable Diffusion) 을 학습할 뿐만 아니라 LoRA weight들을 여러 방법으로 섞어서 화풍을 바꾸든 등의 시도들도 성공적으로 이뤄지고 있다12 13
LoRA로 학습한 이미지 생성 모델 (Stable Diffusion) 을 학습할 뿐만 아니라 LoRA weight들을 여러 방법으로 섞어서 화풍을 바꾸든 등의 시도들도 성공적으로 이뤄지고 있다12 13
3. 마치며
LoRA와 같은 PEFT방법론들 말고도 엔지니어링 측면에서 큰 모델들의 학습을 효율화하려는 움직임들이 전보다 큰 주목을 받고 있는 것 같습니다 (CPU offloading, Attention 계산 최적화, Quantization 등). ChatGPT에 이은 오픈소스 LLM들의 등장에 탄력을 받아 이전보다 훨씬 더 수요가 늘어났다고 할까요? 느끼셨겠지만 오늘 소개된 논문들은 LoRA를 포함해 21년도에 소개된 작업들이 많습니다.물론 더 최신의 기술들도 있습니다만 이들의 변주나 사전학습 개념 등의 응용으로 볼 수 있겠습니다 (14 15).
NC NLP 센터에서도 자체적으로 LLM을 개발하고 있고, 이를 테스트하거나 활용하는데 있어 LoRA를 비롯한 PEFT방법들을 유용하게 쓰고 있습니다. 이전 글보다 나열식으로 느껴져서 조금은 지루했을 수도 있겠네요 (더 좋은 통찰을 제공해드렸으면 좋았을 텐데 내공이 부족해 아쉽습니다😥). PEFT의 세계를 탐험하는 여러분께 좋은 출발점이 되기를 바라면서 써봤습니다.
긴 글 읽어주셔서 감사합니다.
좋은 시간에 다시 만났으면 좋겠습니다. 안녕 여러분🙋♂️
Outlink: 추천드리는 자료
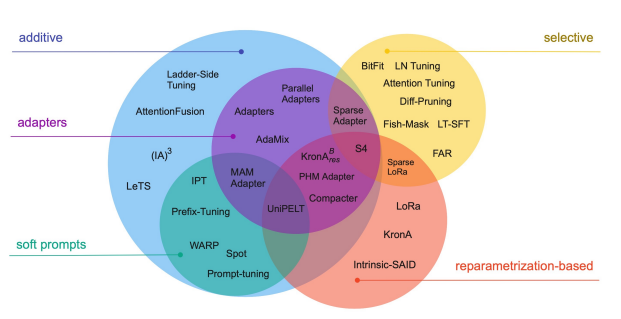
PEFT에 대해서 자세히, 더 많이 보고 싶으시다면 아래의 리뷰논문이 좋을 것 같습니다.
References
-
Zaken, Elad Ben, Shauli Ravfogel, and Yoav Goldberg. “Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models.” arXiv preprint arXiv:2106.10199 (2021). BitFit ↩
-
Ahead of AI, Finetuning Large Language Models blogpost (last reached May 25) ↩
-
Deng, Mingkai, et al. “Rlprompt: Optimizing discrete text prompts with reinforcement learning.” arXiv preprint arXiv:2205.12548 (2022). paper_RLPrompt ↩
-
Lester, Brian, Rami Al-Rfou, and Noah Constant. “The power of scale for parameter-efficient prompt tuning.” arXiv preprint arXiv:2104.08691 (2021). paper_prompttuning ↩
-
Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics. paper_prefixtuning ↩
-
Liu, Xiao, et al. “GPT understands, too.” arXiv preprint arXiv:2103.10385 (2021).paper_ptuningv1 ↩
-
Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. 2022. P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68, Dublin, Ireland. Association for Computational Linguistics. paper_ptuningv2 ↩
-
Houlsby, Neil, et al. “Parameter-efficient transfer learning for NLP.” International Conference on Machine Learning. PMLR, 2019. paper_adapter ↩
-
Hu, Edward J., et al. “Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021). paper_LoRA ↩ ↩2
-
Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. paper_stablediffusion ↩
-
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319–7328, Online. Association for Computational Linguistics. paper_instrinsicdim ↩
-
Begginer’s guide to Stable Diffusion Art blogpost (last reached May 25) ↩
-
Liu, Haokun, et al. “Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.” Advances in Neural Information Processing Systems 35 (2022): 1950-1965.paper_IA3 ↩
-
Huang, Shih-Cheng, et al. “General Framework for Self-Supervised Model Priming for Parameter-Efficient Fine-tuning.” arXiv preprint arXiv:2212.01032 (2022). paper ↩
