
1부: 생각보다는 연속적인 기술의 발전으로 등장한 Large Language Model (LLM)
- Preface
- 1. ChatGPT가 연 생성형 AI의 시대
- 2. ChatGPT ← LLM ← 딥러닝
- 3. 딥러닝: 데이터는 더 많이, 신경망은 더 크게
- 4. 자연어를 만난 딥러닝: 순환신경망으로부터 트랜스포머까지
- 5. 트랜스포머가 쏘아올린 작은(?) 공: Pre-trained Language Model (PLM), Large Language Model (LLM)
- 6. Instruction Tuning, Human Feedback을 통한 Alignment (정렬): 이제부터 내가 학습시킬 작업은, 내 요청에 맞게 응답하는거야
- 7. LLM 실험을 위한 허들 넘기
- Outlink: 추천드리는 자료
- References
Preface
- 1부에서는 딥러닝이 어떻게 흘러흘러 LLM까지 이어졌는지, 그리고 그 가치는 어떻게 재평가되었는지를 살펴봅니다.
- 2부에서는 LLM을 우리 손 안에 들어오게 하는 기술, Parameter Efficient Fine-Tuning 방법들에 대해 살펴봅니다.
1. ChatGPT가 연 생성형 AI의 시대
ChatGPT의 시대에 여러분은 안녕하신가요? 세계사의 분기점이 B.C.와 A.D.로 나뉜다면 생성형 AI는 아마 ChatGPT가 나오기 전과 후로 나뉘는 것 같기도 합니다. AI 분야에서 “사람 수준에 도달했다” 는 표현은 식상한 마케팅 문구가 되어버렸지만, 이번엔 달랐습니다. ChatGPT를 처음 써봤을 때 저는 러다이트 운동이 공감될 정도로 큰 충격을 받았습니다. 여러분도 그렇게 생각하지 않으셨나요?
 ???: 테크블로그… 러다이트… 그거 맞나?
???: 테크블로그… 러다이트… 그거 맞나?
ChatGPT가 성공한 생성형 AI생성형 AI (Generative AI): 텍스트나 이미지, 소리 등의 창작 작업을 수행할 수 있는 AI 모델들을 폭넓게 부르는 말이다.임에는 의심의 여지가 없습니다. 인간만의 것이라고 생각했던 언어를 이토록 유창하게 구사하는 기계는 처음이니까요. 이를 뒷받침하듯 ChatGPT의 유저 수는 역사상 가장 빨리 성장했고 언어는 더 이상 사람만의 것이 아니게 되었습니다. 이게 가능한 이유는 드디어 LLM거대 언어 모델 (Large Language Model; LLM): 언어모델 (LM) 은 앞선 단어들을 보고 다음에 올 단어를 예측하도록 훈련된 모델을 통틀어 부르는 말이다. 후술하겠지만 최근의 언어모델은 많이 커져서 LLM으로 불리게 되었다.(Large Language Model) 이 사람의 의도에 잘 따르도록 정밀하게 정렬정렬 ([AI] Alignment): 생성형 AI 분야에서 쓰일 때에는 사람의 의도를 따르도록 혹은 AI의 행동을 사람에게 안전한 방향으로 조정하는 것을 가리킬 때 사용한다. 이 글에서는 전자의 의미로 사용했다.(alignment) 되기 시작했기 때문일 것입니다.
2. ChatGPT ← LLM ← 딥러닝
“Large Language Model 그거 사람들이 최근에 잘되는 AI에 갖다 붙인 이름 아니야?” 분명 LLM이라는 단어는 근 몇 년 새에 쓰이기 시작한 말이지만, 딥러닝의 시작이 “더 방대한 데이터를 다룰 더 큰 신경망” 이었음을 우리는 다시 볼 필요가 있습니다.
 주의: ChatGPT가 LLM보다 더 큰 모델이라는 의미가 아닙니다!
주의: ChatGPT가 LLM보다 더 큰 모델이라는 의미가 아닙니다!
딥러닝 (Deep Learning)딥러닝 (Deep Learning): 층층이 쌓은 신경망을 통한 기계학습 방법을 말한다. 용어는 2006년에 Yann LeCun, Geoffrey Hinton, Yoshua Bengio 에 의해 처음 사용되었고 2012년에 폭발적인 주목을 받기 시작했다.의 초기부터 연구를 이어온 ChatGPT의 아버지, OpenAI의 수석과학자 Ilya Sutskever [일리야 수츠키버] 의 다음 발언을 인용해보겠습니다. 젠슨 황에게 GPT4에 대해 질문을 받자, 몇 가지를 설명하다 문득 이런 이야기를 합니다.
[NVIDIA GTC 2023 젠슨 황과의 대담 세션] 1
… It turned out to be the same little thing all along which is no longer little, and it’s a lot more serious and much more intense but it’s the same neural network just larger, trained on maybe larger data sets in different ways with the same fundamental training algorithm. So, it’s like ‘wow I would say this is what I find the most surprising’ whenever I take a step back I go how is it possible those ideas, those conceptual ideas about ‘well the brain has neurons so maybe artificial neurons are just as good and so maybe we just need to train them somehow with some learning algorithm’ that those arguments turned out to be so incredibly correct that would be the biggest surprise
…알고보니 지금 우리가 보고있는 이 모든 것들이 사실은 이전 (그가 연구실에 있었던 2000년대 초) 에 있던 똑같은 신경망이고, 그저 더 방대한 데이터에 그러나 본질적으로 같은 (역전파) 알고리즘으로 학습한 것 뿐이라는 게 가장 놀랍습니다. 물론 전보다 훨씬 더 방대하고 강력해지긴 했지만요. 뒤로 물러나서 보면 뇌의 구조에서 따온 인공 뉴런도 실제 뉴런만큼 좋을 수 있고 학습 알고리즘도 준비되어있으니 학습시키면 될 거라는 그 아이디어가 말도 안되게 잘 들어맞았다는 점이 가장 신기합니다.
요컨대, 지금의 GPT4가 정말 신기하긴 하지만, 정말 신기한 점은 GPT4를 가능하게 한 그 모든 것들이 이미 딥러닝이 대두되기(2012) 전부터 있었으며, 딥러닝을 시작시킨 아이디어에서 많이 벗어나지 않았다는 것입니다.
더 많은 데이터를 처리할 더 큰 신경망. 이 아이디어는 어떻게 ChatGPT까지 연결될까요? 그의 인터뷰를 따라 역사속으로 가봅시다.
3. 딥러닝: 데이터는 더 많이, 신경망은 더 크게
뇌를 본 딴 신경망 구조는 1958년에 Frank Rosenblatt [프랭크 로젠블랏] 에 의해 Perceptron2 이라는 이름으로 제안되었고 1985년 Geoffrey Hinton [제프리 힌튼] 이 이를 역전파 알고리즘*3으로 학습시킬 수 있다는 것을 재조명하였습니다.
지금도 딥러닝을 처음 배우는 사람은 이 둘 (구조와 학습알고리즘) 부터 배웁니다.
사실상 딥러닝의 알파와 오메가이죠…
하지만 이 둘의 조합이 딥러닝이라는 이름으로 주목받기 시작한 것은 2012년, 3번째로 열린 이미지넷 챌린지4였습니다.
여기서 방대한 규모의 신경망인 AlexNet5이 다른 모든 참가팀을 큰 차이로 압도하는 것을 시작으로 딥러닝은 큰 주목을 받게 되었습니다.
이를 시도할 당시 큰 신경망에 대한 이론적 힌트가 없지는 않았습니다6 7. Rumelhart의 책 Parallel Distributed Processing (1987)8 에서도 찾아볼 수 있는 큰 신경망에 대한 기대는 현대에 와서 GPU Computing으로 구현되었지만, 당시만해도 GPU를 이런 용도로 사용하는 것은 일반적이지 않았습니다. 물론 다른 컴퓨팅 자원도 지금보다 훨씬 약소했죠. 때문에 큰 신경망을 통해 많은 데이터를 학습한다는 생각은 성능대비연산효율이나 인프라 등의 문제로 인기가 별로 없었습니다.
이런 상황에서 힌튼 교수님의 대학원생 1, 2인 Alex krizhevsky [알렉스 크리제브스키] 와 일리야 수츠키버는 힌튼이 들고 온 그래픽카드(GPU) GTX580 을 신경망 연산을 위해 마개조(..)하는데에 성공했습니다.
그렇게 구현된 AlexNet의 성능은 파괴적이었습니다! (Figure 1)
 Figure 1. AlexNet 이미지넷 챌린지 2012 결과9: AlexNet이 2012년 모델들 뿐만 아니라 이전 1등들도 큰 격차로 이기고 있다 (error rate ↓)
Figure 1. AlexNet 이미지넷 챌린지 2012 결과9: AlexNet이 2012년 모델들 뿐만 아니라 이전 1등들도 큰 격차로 이기고 있다 (error rate ↓)
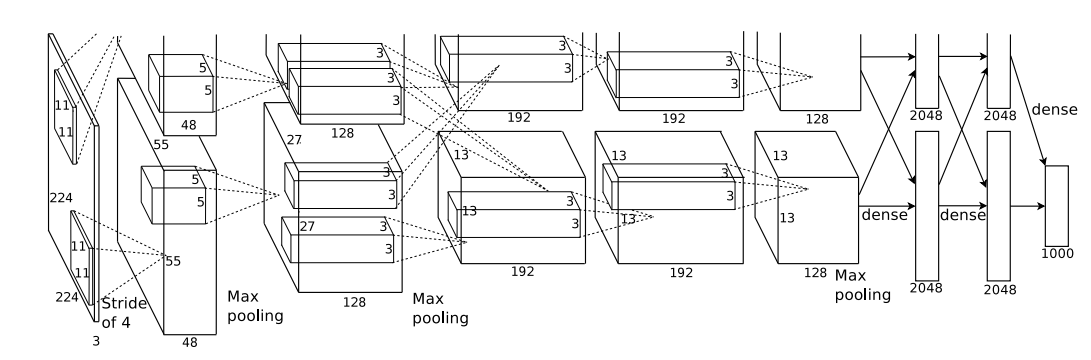 Figure 2. 컨볼루션 신경망이 차곡차곡 쌓여있는 AlexNet의 구조. 당시기준으로 혁신적인 규모의 신경망이었다.
Figure 2. 컨볼루션 신경망이 차곡차곡 쌓여있는 AlexNet의 구조. 당시기준으로 혁신적인 규모의 신경망이었다.
ImageNet 챌린지는 지금 기준으로도 작지 않은 스케일의 데이터를 다룹니다. 천여가지 종류의 객체 분류를 위한 백만여개의 이미지를 포함하고 있죠.
쟁쟁한 학교들이 여러가지 – 이론적으로 더 우아해보이는 – 많은 방법을 가지고 이 대회에 참가했지만 백만여개의 이미지를 소화한 AlexNet과는 상대가 되지 않았습니다.
2등과 10%p 이상의 차이로 1등을 차지하게 되었고 이는 딥러닝의 강렬한 첫 인상을 남기기에 충분했습니다.
4. 자연어를 만난 딥러닝: 순환신경망으로부터 트랜스포머까지
이런 흐름을 타고 자연어처리 분야에서도 딥러닝이 그 세력을 뻗치기 시작합니다.
신경망 중 순환신경망 (Recurrent Neural Network; RNN) 은 이전 시점(1, 2, …, t-1)의 단어들을 입력으로 받아서, 지금(t) 와야할 단어를 예측하는 방식으로 동작했고 (Figure 3) 이는 자연어를 처리하는데 직관적이고 유용했습니다.
 Figure 3 순환신경망의 작동방식: 왼쪽처럼 나온 아웃풋이 다음 입력에 영향을 주도록 작동한다. \(W\), \(V\), \(U\)는 순환신경망의 가중치이고 \(x\), \(s\), \(o\)는 각각 입력, 상태, 출력이다.
\(x_t\) (t 시점의 입력) 로부터 \(o_t\) (t 시점의 출력) 를 연산해내려면 \(s_t\) (t 시점의 상태값) 이 필요한데, 이는 \(s_{t-1}\) 의 연산이 끝나야만 얻을 수 있는 값이다.
Figure 3 순환신경망의 작동방식: 왼쪽처럼 나온 아웃풋이 다음 입력에 영향을 주도록 작동한다. \(W\), \(V\), \(U\)는 순환신경망의 가중치이고 \(x\), \(s\), \(o\)는 각각 입력, 상태, 출력이다.
\(x_t\) (t 시점의 입력) 로부터 \(o_t\) (t 시점의 출력) 를 연산해내려면 \(s_t\) (t 시점의 상태값) 이 필요한데, 이는 \(s_{t-1}\) 의 연산이 끝나야만 얻을 수 있는 값이다.
하지만 순환신경망은 딥러닝의 핵심아이디어를 수행하는데에 한 가지 불편함이 있었으니, 바로 대규모 데이터 학습을 하기에는 시간이 너무 오래 걸린다는 점이었습니다.
학습하는 텍스트의 갯수는 GPU 갯수를 늘리면 함께 늘어났지만 텍스트의 길이만큼 순환신경망 학습에 시간이 더 걸리는 것은 해결할 수 없었습니다.
Figure 3 에 그려진 순환신경망의 작동 방식을 보면 이를 확인할 수 있는데, t시점의 계산을 위해서 t-1 시점까지의 계산이 필요했거든요.
 Figure 4. 트랜스포머 구조의 등장으로 인해 자연어처리 모델의 연산/데이터량에 시간적 제한이 없어지면서 ChatGPT를 가능하게 한 LLM이 세상에 모습을 드러내게 된다.
Figure 4. 트랜스포머 구조의 등장으로 인해 자연어처리 모델의 연산/데이터량에 시간적 제한이 없어지면서 ChatGPT를 가능하게 한 LLM이 세상에 모습을 드러내게 된다.
이런 순환신경망의 문제는 2017년에 혜성과 같이 등장한 트랜스포머 (Transformer)10 에서 해결됩니다.
트랜스포머 구조는 우리가 말을 글로 풀어쓰는 것과 같은 방식으로 time-sequence를 spatial-sequence로 구현하여 이런 문제를 해결하였습니다 (여기에서는 구조 자체를 다루진 않겠습니다).
텍스트의 길이만큼 느렸던 순환신경망과는 달리 트랜스포머는 GPU 메모리를 늘리면 한 번에 처리할 수 있는 문서의 갯수와 길이 모두 늘릴 수 있게 된 것이죠.
트랜스포머의 등장에 힘입어 자연어에서도 대규모 데이터 학습이 가능해지면서 LLM의 시대는 막을 올리고 있었습니다.
5. 트랜스포머가 쏘아올린 작은(?) 공: Pre-trained Language Model (PLM), Large Language Model (LLM)
순환신경망 때부터 지금까지도 자연어 텍스트를 학습시키는 가장 기본적인 방법은 다음 토큰을 예측하는 방식 (Language Modeling) 이었고 이를 통해 원하는 작업 (e.g. 요약, 번역 등)를 곧바로 학습해왔습니다.
이를 위해선 작업에 딱 맞는 텍스트 쌍 (i.e. 작업이 영한 번역이라면 영어 문장과 한글 문장쌍) 이 준비되어있어야 합니다.
하지만 현실적으로 우리가 해결하려는 많은 작업에선 텍스트 쌍이 부족하기 때문에 실제로 트랜스포머가 가진 힘을 다 끌어내지 못하고 있었습니다.
고민하던 사람들은, 널려있는 일반 텍스트를 학습하는 것이 도움이 되지 않을까 생각하고 실행에 옮깁니다.
이것이 바로 사전학습입니다. 사전학습된 언어모델을 Pre-trained Language Model (PLM)이라고 부릅니다.
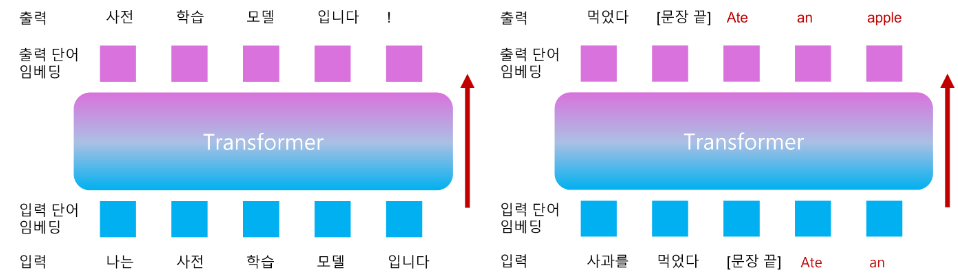 Figure 5. (좌) GPT 사전학습, (우) 사전학습 후 번역을 위해 미세조정하는 경우, 미세조정 (학습) 방법. (단순한 진행을 위해 GPT;Generative Pre-Training11 방식의 사전학습만 다룹니다)
Figure 5. (좌) GPT 사전학습, (우) 사전학습 후 번역을 위해 미세조정하는 경우, 미세조정 (학습) 방법. (단순한 진행을 위해 GPT;Generative Pre-Training11 방식의 사전학습만 다룹니다)
위와같이 사전학습을 하고 나면 같은 양의 텍스트 쌍들을 학습하는 것 (미세조정; Fine-tuning) 으로 훨씬 좋은 품질의 모델을 얻을 수 있습니다.
안 그래도 특정 작업을 위해 마련한 텍스트 쌍들은 부족하기 마련이었는데 널려있는 데이터를 활용하여 데이터 효율을 크게 끌어올린 것이죠.
PLM의 효용은 이처럼 아주 명확했기 때문에, PLM을 시작점으로 하여 학습을 진행하는 것이 이 때부터 사실상의 표준이 됩니다.
하고자 하는 작업이 있다면 (e.g. 번역 등) PLM을 비교적 작은 텍스트쌍에 학습하면 그 작업만 할 줄 아는 모델이 준비되는 것입니다.서로 다른 작업들(e.g. 요약, 번역)을 잘해야 한다면 그 작업의 가짓수만큼 텍스트쌍 데이터를 준비하고 각각에 미세조정을 진행하게 된다. 미세조정을 거친 PLM은 한가지만 잘한다. 이건 나중에 큰 걸림돌으로 작용한다.여기까지는 GPU 한 두 장이면 소화될 수 있는 정도의 모델 크기였습니다.
 Figure 6. 새로운 무어의 법칙12. 트랜스포머가 등장한 2017년 직후 2018년부터 PLM 혹은 LLM의 크기는 해에 따라서 지수함수적으로 커진다. GPT-3는 175B.
Figure 6. 새로운 무어의 법칙12. 트랜스포머가 등장한 2017년 직후 2018년부터 PLM 혹은 LLM의 크기는 해에 따라서 지수함수적으로 커진다. GPT-3는 175B.
사전학습의 효과가 증명되자 기업들에선 경쟁적으로 더 많은 데이터로 학습시킨, 더 큰 PLM을 내놓기 시작합니다. 세상의 모든 텍스트, 즉, 더 방대한 데이터를 배울 더 큰 신경망을 만들어야하니까요.
지금은 저장할 신경망 가중치만 10억 개 (Billion; B로 표기) 단위로 세는 지경에 이르러 누군가는 이를 새로운 무어의 법칙무어의 법칙: 마이크로칩에 저장할 수 있는 데이터 분량이 18-24개월 마다 두 배씩 증가한다는 법칙. 여기서는 모델의 가중치 갯수가 지수함수로 증가한다.이라고 부르기도 했습니다 (Figure 6).
이렇게 크기가 커지면서 PLM은 점차 LLM으로 불리기 시작했습니다.
 Figure 7. In-context Learning (LLM = GPT-3 175B) 13: 주어진 입력 맥락에서 배우는 것 같이 보여서 In-context Learning이라고 불린다.
Figure 7. In-context Learning (LLM = GPT-3 175B) 13: 주어진 입력 맥락에서 배우는 것 같이 보여서 In-context Learning이라고 불린다.
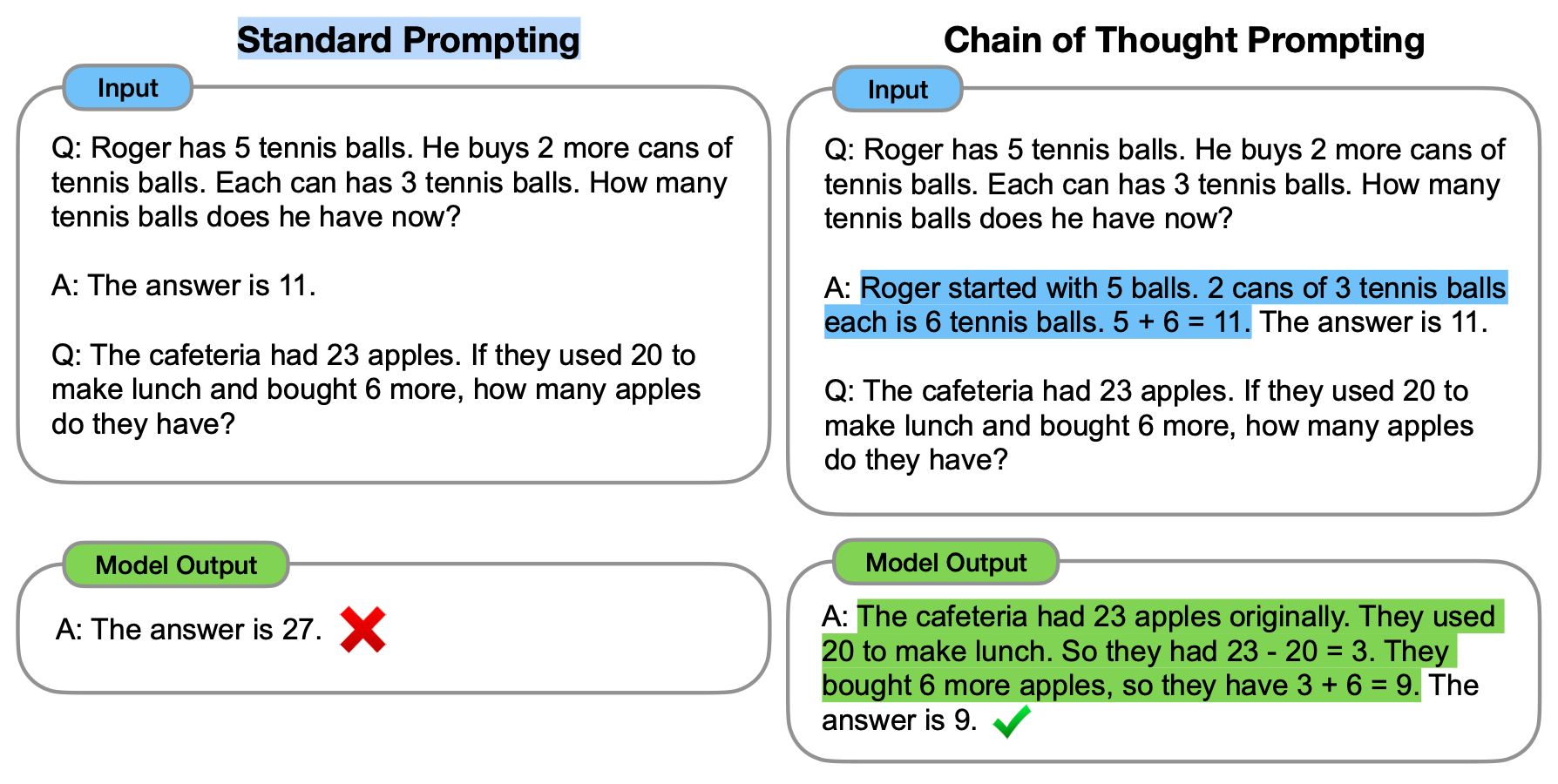 Figure 8. Chain of Thought Prompting (LLM = PaLM 540 B) 14: 꼬리를 무는 생각처럼 입력을 주면 질문에 더 잘 대답하는 현상
Figure 8. Chain of Thought Prompting (LLM = PaLM 540 B) 14: 꼬리를 무는 생각처럼 입력을 주면 질문에 더 잘 대답하는 현상
LLM이 일정 수준 이상 커지자 몇 가지 전에 없던 현상들이 보고되기 시작합니다. 모델이 언어를 이해하는 것 같은 현상들이었는데
- In-context Learning (Figure 7): 원하는 작업 예시나 지시를 입력으로 주면, 미세조정 (Fine-tuning) 없이도 작업을 수행한다거나,
- Chain-of-Thought prompting (Figure 8): 원래는 제대로 답하지 못하는 질문에 추론 과정을 글로 써주면 제대로 답을 내놓는 것 같이
쓸만한 수준은 아니었지만, 책을 무작정 읽힌 결과 (사전학습) 어느정도의 언어능력이 추가 학습 없이도 발현되는 것 같았달까요?
이들 LLM을 미세조정 했을 때 마주할 결과물의 품질이 벌써부터 기대가 되지 않나요?
아, 물론 미세조정을 편하게 할 수 있는 사이즈였다면 말이죠...규모가 큰 일부 기업들만 LLM을 만들 수 있었던 것처럼, LLM의 미세조정 역시도 일부에게만 접근가능한 방법이 되어버렸고 초기 (2018-19년) 의 PLM의 사용성과는 거리가 멀어졌다.
6. Instruction Tuning, Human Feedback을 통한 Alignment (정렬): 이제부터 내가 학습시킬 작업은, 내 요청에 맞게 응답하는거야
미세조정이 사실상 불가능한 LLM은 꽤 화려하지만 쓸모는 없는, 빅테크들의 전유물이자 업적의 역할을 담당하게 되었습니다.
이 LLM에게 내가 원하는 것을 수행하게 하려면 그 때마다 미세조정이 필요하니까요.
하지만 PLM을 한 번 준비해서 계속 쓸 수 있었듯이 미세조정한 모델을 여러 용도로 사용할 수 있다면 어떨까요?
원래는 한가지 용도를 위해서만 미세조정 했었지만 이게 여러가지 일을 할 수 있게는 못할까요?
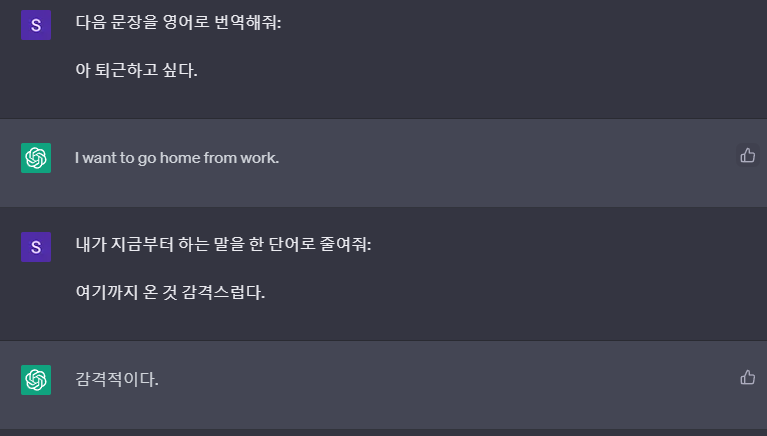 Figure 9. Instruction-tuning을 위해 사용되었을 법한 입력과 출력 쌍. 위에는 번역을 위한 입출력이고 아래는 한단어 요약을 위한 입출력으로 보면 된다.
Figure 9. Instruction-tuning을 위해 사용되었을 법한 입력과 출력 쌍. 위에는 번역을 위한 입출력이고 아래는 한단어 요약을 위한 입출력으로 보면 된다.
이처럼 지시하는 내용에 맞게 동작하도록 학습시키는 과정을 Instruction-Tuning이라고 한다. 예시는 보다시피 ChatGPT.
실제로 위와 같이, 내가 한 요청을 제대로 수행하도록 다양한 종류의 작업들을 자연어 입력으로 표기하고 이에 맞는 출력을 학습하게 하면 이를 잘 들어주는 모델이 학습됩니다.
사람이 시킬 수 있는 작업의 종류가 도대체 몇 가지나 있을 것이며, 그걸 표현하는 자연어는 몇 가지나 될까요?
이것만 고려하더라도 이 모든 것을 커버하는 텍스트 쌍은 없을 것입니다.
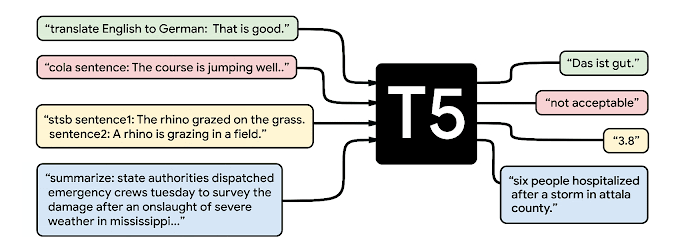
 Figure 10. 순서대로 T515, FLAN16. 이미 T5에서는 적절히 여러 작업으로 multitask learning 을 진행하여 각각 작업에 미세조정한 것과 근접한 성능에 도달하는 모델을 만들 수 있음을 시도한 바 있다. FLAN의 경우, 처음 보는 지시도 잘 수행할 수 있음을 이어서 확인했다.
Figure 10. 순서대로 T515, FLAN16. 이미 T5에서는 적절히 여러 작업으로 multitask learning 을 진행하여 각각 작업에 미세조정한 것과 근접한 성능에 도달하는 모델을 만들 수 있음을 시도한 바 있다. FLAN의 경우, 처음 보는 지시도 잘 수행할 수 있음을 이어서 확인했다.
하지만 다행히도 사전학습을 통해서 경험한 세상 거의 모든 텍스트, 그리고 이를 통해 얻게된 LLM의 자연어 이해 능력이 많은 도움이 되었고 덕분에 LLM은 꽤 소규모의 Instruction 데이터로도 우리의 의도에 잘 정렬된 모델로 학습될 수 있었습니다.
여러 작업을 동시에 학습한 모델에 적절한 지시를 하면 원하는 작업을 수행할 수 있을 것이라는 기대는 완전히 새로운 것은 아닙니다.
몇 가지 단서들을 찾아보면…
- Instruction Tuning 방법론으로 이어진 T5 (2020) 의 multitask learningMultitask learning: 여러 작업을 함께 학습시키는 것. Task를 어떻게 보느냐에 따라 좀 달라질 수도 있지만, 여기에서는 번역과 요약을 함께 배우는 것이라 생각하면 된다. 시도 (Figure 10)
- 좀 더 최근에는 위와 같은 Prompting (Few-shot learning, Figure7; CoT, Figure 8)
여기에 Human Feedback을 직접적으로 반영하는 방법으로서의 강화학습17이 합쳐져 현재의 ChatGPT의 근간을 이루게 되었습니다.
"잘"ChatGPT를 가능하게 한 데이터의 수량과 형태는 베일에 싸여있다.
align 시키면 ChatGPT가 되는 LLM.
LLM이 가치있다고 느끼신다면 그건 아마도 ChatGPT 덕분일 겁니다.
7. LLM 실험을 위한 허들 넘기
앞서 쉽게 쉽게 해낼 수 있는 것처럼 말했지만, 사실 Instruction Tuning도 LLM을 미세조정하는 작업이므로 부담이 적지는 않습니다. LLM은 당연히 꽤 방대한 규모의 파라미터를 가졌을 것입니다.
하지만 소규모의 기업과 비영리단체들에서도 LLM을 잘 학습시켜 유사-ChatGPT18 19 20들을 속속 내놓고 있습니다.
이들이 갑자기 투자를 많이 받은 것도 아닐테고, 어떻게 이런 일이 가능할까요?
여기에는 몇가지 이유가 있습니다.
- Instruction Tuning는 소량의 Instruction dataset (<100k) 만을 필요로 한다.
- 공용 LLM은 많이 풀려있으며21 22 23, 위와 같은 효과를 내는데에 필요한 LLM의 최소사이즈는 GPT-3 (175B)의 1/30 정도 크기인 7B 사이즈인것으로 보인다.
- Parameter-Efficient Fine-Tuning (PEFT) 방법들을 채용하여 학습에 필요한 자원을 대폭 줄였다.
첫 번째 두 번째 긍정적인 부분들을 고려하더라도 7B 정도 사이즈의 LLM에 학습을 진행하는 것은 여전히 불편한 면이 있죠.
하지만 마지막에 써있는 PEFT를 사용한다면 LLM실험을 GPU 한 장으로 수행할 수 있게 됩니다.
설마 이 긴 내용이 PEFT를 위한 빌드업이라는 걸 눈치채셨나요?😋

2부에서는 가장 빈번히 쓰이고 있는 LoRA24를 비롯한 Parameter Efficient Fine-Tuning 방법론들을 소개해드리겠습니다.
감사합니다 좋은 하루 되세요.
=]
Outlink: 추천드리는 자료
References
-
Jensen Huang and Ilya Sutskever: AI Today and Vision of the Future ↩
-
Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386. Perceptron ↩
-
Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. “Learning representations by back-propagating errors.” nature 323.6088 (1986): 533-536. Backpropagation ↩
-
ImageNet Large Scale Visual Recognition Challenge (ILSVRC) ↩
-
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Communications of the ACM 60.6 (2017): 84-90.AlexNet ↩
-
Funahashi, Ken-Ichi. “On the approximate realization of continuous mappings by neural networks.” Neural networks 2.3 (1989): 183-192. UAT-width ↩
-
Lu, Zhou, et al. “The expressive power of neural networks: A view from the width.” Advances in neural information processing systems 30 (2017). UAT-depth ↩
-
McClelland, James L., David E. Rumelhart, and PDP Research Group. Parallel distributed processing. Vol. 2. Cambridge, MA: MIT press, 1986. PDP ↩
-
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).AIAYN ↩
-
Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).GPT ↩
-
Madotto, Andrea, et al. “Language models as few-shot learner for task-oriented dialogue systems.” arXiv preprint arXiv:2008.06239 (2020).GPT-3 ↩
-
Wei, Jason, et al. “Chain of thought prompting elicits reasoning in large language models.” arXiv preprint arXiv:2201.11903 (2022).CoT Paper ↩
-
Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” The Journal of Machine Learning Research 21.1 (2020): 5485-5551. T5 ↩
-
Wei, Jason, et al. “Finetuned language models are zero-shot learners.” arXiv preprint arXiv:2109.01652 (2021).FLAN ↩
-
Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” Advances in Neural Information Processing Systems 35 (2022): 27730-27744. Instruct GPT ↩
-
Open Assistant, (last visited: 2023.04.21) ↩
-
Touvron, Hugo, et al. “Llama: Open and efficient foundation language models.” arXiv preprint arXiv:2302.13971 (2023). LLaMa ↩
-
Zhang, Susan, et al. “Opt: Open pre-trained transformer language models.” arXiv preprint arXiv:2205.01068 (2022). OPT ↩
-
Hu, Edward J., et al. “Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021). LoRA ↩
