
안녕하세요.
이번에는 저희 Applied AI Lab에서 AAAI 2022에 출판한 FPAdametric(False-positive-aware Adaptive Metric Learning for Session-based Recommendation)라는 논문을 소개하려고 합니다. 실험 결과와 이론적 증명 과정은 이 글에서 언급하지 않을 예정이니, 논문을 통해 확인 부탁드리겠습니다.
기술 개발의 background
Applied AI Lab에서는 추천 엔진을 여러 서비스에 제공하고 있습니다. 그 중, 한 서비스는 바로 그림 1에서 소개하고 있는 FUSER라는 게임입니다. 우리가 평소 접하는 음원을 들어보면, 가수의 보컬 뿐만 아니라 베이스, 피아노, 드럼 등의 많은 악기들이 합쳐져서 하나의 음원을 구성합니다. 이러한 보컬, 베이스, 피아노, 드럼 등 여러 가지 악기와 노래의 음원 구성요소를 단위에 따라 스템(stem)이라고 부릅니다. FUSER는 유저가 DJ(Disc Jockey)가 되어 이와 같은 여러 가지 스템(stem)을 섞어 나만의 커스텀 음악을 만들어 공연하는 콘솔 게임입니다. 그림 1의 왼쪽 그림에서 확인할 수 있듯이 각 스템이 디스크 형태로 구성되어 있으며, 이 유저는 드럼은 50 Cent의 ‘In Da Club’과 Billie Eilish의 ‘bad guy’에서, 피아노는 Lady Gaga의 ‘Born this way’에서, 보컬은 Fatboy Slim의 ‘The rockafeller Skank’에서 가져와 유저만의 개성이 드러나는 음악으로 믹싱하였습니다. 이렇게 음악을 믹싱하여 공연한 유저들은, 그림 1의 오른쪽과 같이 그 공연을 유튜브처럼 다른 사람들에게 공유할 수 있습니다. 저희 랩에서는 각 유저에게 다른 유저가 믹싱한 음악을 추천해주는 모델을 연구하고, 연구 결과를 서비스에 적용하였습니다.
 [그림 1] FUSER 게임의 플레이 화면 및 추천 화면.
[그림 1] FUSER 게임의 플레이 화면 및 추천 화면.
기존에 널리 활용되고 있던 CF(collaborate filtering) 추천 시스템은 유저의 정보를 이용하여 각 유저가 좋아할만한 아이템을 추천해주는 추천 방법입니다. 하지만 FUSER가 서비스를 처음 시작했을 때에는 신규 유저가 많이 유입되는 상황이었기 때문에 유저의 정보가 필요한 CF 기반의 추천이 어려웠습니다.
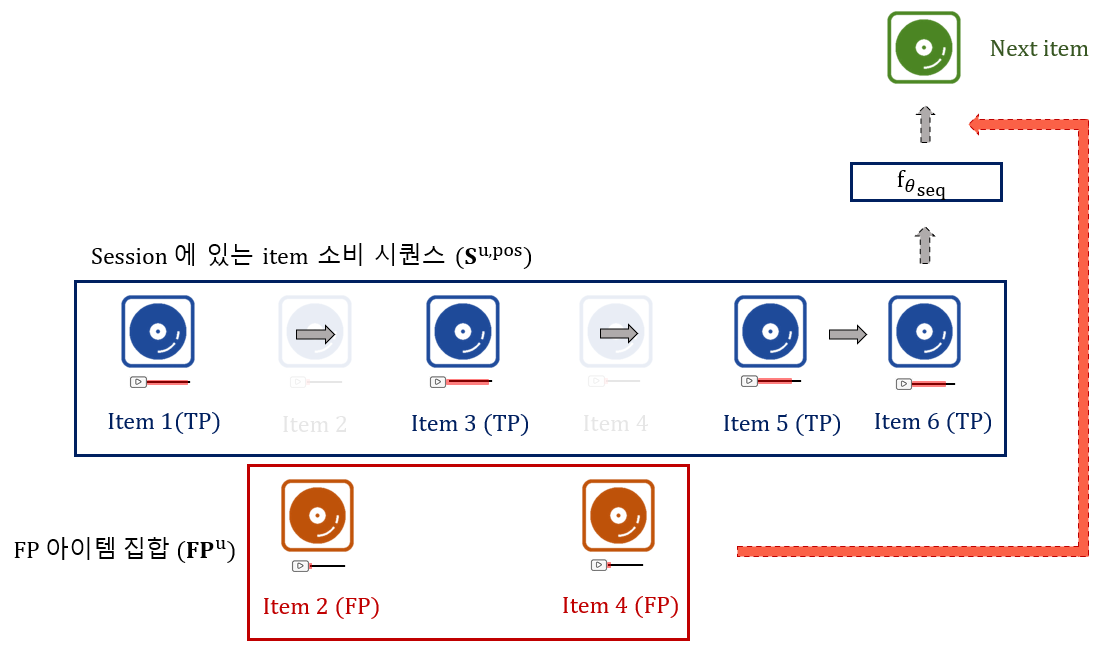
저희는 이를 위해 FUSER의 각 유저에게 세션 기반 추천 시스템(Session-based recommendation system; SBR)을 활용하여 음악 아이템을 추천하였습니다. 세션 기반 추천 시스템은 그림 2와 같이 유저가 클릭한 짧은 아이템 시퀀스인 세션 안에서 현재까지 소비된 아이템 시퀀스를 기반으로, 다음에 소비할 아이템이 무엇일지 예측하는 추천 시스템입니다. 그림 2의 예시로 설명드리면, 주어진 세션 안에서 여섯 개의 아이템이 클릭되었다고 할 때, 해당 아이템 시퀀스가 추천 모델 을 거쳐 7번째로 소비할 아이템이 무엇인지 예측하는 것을 의미합니다. 여기서, 세션 기반 추천 모델 는 GRU(gated recurrent unit), Transformer, GNN(graph neural network) 등의 다양한 딥러닝 모델을 통해 모델링 할 수 있습니다. 저희가 이러한 세션 기반의 추천 시스템을 선택한 이유는, 유저 ID가 없더라도 세션 정보만을 활용해서 아이템을 추천할 수 있어 저희가 가진 어려움을 극복할 수 있었기 때문입니다.
일반적으로 세션에 포함되는 아이템들은 유저가 클릭한 아이템을 기반으로 구성되는데, 실제 데이터 셋을 살펴보니 콘솔 게임 특성상 조작이 익숙하지 않아 유저가 잘못 클릭한 경우가 많은 것을 알 수 있었습니다. 본 연구는 유저가 잘못 클릭한 아이템을 활용하여 세션 기반 추천 시스템의 학습을 개선하기 위해 진행되었습니다.
 [그림 2] 기존 세션 기반의 추천.
[그림 2] 기존 세션 기반의 추천.
연구 동기와 목표
연구 동기
앞서 말씀드린 것과 같이, 저희는 FUSER에서 유저의 조작이 미숙하여 잘못 클릭한 경우가 많은 것을 확인할 수 있었습니다. 그림 3은 FUSER에서 유저들이 ‘좋아요’를 표시했을 때의 소비 시간 분포(파란색; praised)와 ‘좋아요’를 표시하지 않았을 때의 소비 시간 분포(주황색; not praised)를 보여주고 있습니다. 주황색 분포를 보면, 가장 왼쪽에 솟아있는 것을 통해 잘못 클릭한 경우가 많이 존재함을 알 수 있으며, 전반적으로 ‘좋아요’를 표시했을 때가 그렇지 않을 때보다 유저의 소비 시간이 긴 것을 알 수 있습니다. 즉, FUSER와 같이 잘못 클릭할 수 있는 환경에서는 클릭 된 아이템만을 이용하여 세션을 구성하여 추천 모델을 학습하는 것이 잘못된 추천으로 이어질 수 있음을 유추할 수 있습니다. 기존 연구들[1, 2]에서는 이런 문제를 방지하기 위해 잘못 클릭 된 아이템을 세션에서 제거하고 학습시키기도 하였지만, 서비스 초기에는 유저 반응이 적기 때문에 저희는 가능한 모든 데이터를 활용하기 위한 방법을 강구했습니다.
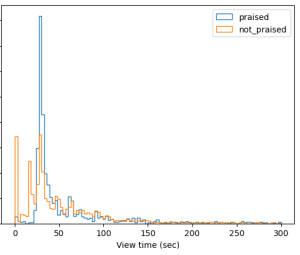 [그림 3] FUSER에서 사용자의 선호 유무에 따른 소비 시간 분포 비교.
[그림 3] FUSER에서 사용자의 선호 유무에 따른 소비 시간 분포 비교.
그래서, 저희는 좋아요보다 상대적으로 양이 많고 알아내기 쉬운 소비 시간이 짧은 아이템에 주목을 하였습니다. 소비시간이 짧은 아이템은 좋아하지 않을 가능성이 높기 때문에, 소비 시간이 짧은 클릭 시그널은 FP(false-positive) 아이템이라고 정의했습니다.
FP 아이템은 TP(true-positive) 아이템(소비시간이 긴 클릭 아이템)과 구분지어 모델의 학습에 사용해야 하는데, 만약 이 둘을 구분하지 않고 학습에 사용하는 경우 세션 기반의 추천 시스템에 나쁜 영향을 줄 수 있습니다. 예를 들어, 아래 그림 4와 같이 구성된 영화 추천 시스템의 세션이 있다고 가정을 해보겠습니다. 저희가 구성한 세션은 모두 ‘히어로물’을 좋아하는 사람들이 소비한 세션입니다. 첫 번째 세션(Session 1)은 헐크, 아이언맨 1, 아이언맨 2로 구성되었고, 해당 세션의 유저는 모든 영화를 시간가는 줄 모르고 재밌게 봤습니다. 이 경우에는 클릭만을 고려하거나(그림 4 (a)) 영화의 소비 시간도 함께 고려하거나(그림 4 (b)) 어느 방식으로 추천 모델을 학습하더라도, 추천 모델이 해당 유저가 히어로물을 좋아한다고 판단할 수 있습니다. 두 번째 세션(Session 2)의 유저는 아이언맨 3, 나우 유 씨 미, 셜록 홈즈를 보았지만, 아이언맨 3은 끝까지 다 보고 다른 영화들은 초반에 보다가 재미가 없어서 다른 영화를 탐색한 경우입니다. 이 세션에서는 본인 취향이 아닌 영화(FP 아이템)를 실수로 클릭하게 되었다고 볼 수 있는데, 이와 같은 경우에는 단순하게 클릭으로 세션을 구성하여 추천 모델을 학습할 경우 해당 유저를 추리물을 좋아하는 유저로 잘못 판단할 수 있게 될 겁니다(그림 4 (a)). 해당 유저는 그림 4 (b)처럼 TP 아이템과 FP 아이템의 소비 시간을 고려하여 추천 모델을 학습하여야만, 추천 모델이 해당 유저가 추리물을 좋아하는 유저가 아닌 히어로물을 좋아하는 유저로 판단할 수 있을 것입니다. 즉 TP 아이템과 FP 아이템을 모델의 학습 과정에 고려하는 것은 각 세션의 취향을 더 잘 파악하는데 도움을 줄 수 있습니다. 이는 추론(inference) 시에도 반영이 되게 되는데, 마지막 세션(Session n)의 유저를 통해 이를 확인할 수 있습니다. 해당 유저는 어벤저스 3을 끝까지 관람하고, 라이온 킹을 조금만 관람한 유저의 경우에는, 소비 시간이 짧은 라이온 킹은 FP 아이템으로 간주하고 소비 시간이 긴 어벤저스 3은 TP 아이템으로 고려하여야만 비로소 추론 과정에서도 해당 유저가 히어로물을 좋아하는 유저로 생각하고 적절한 영화를 추천해줄 수 있게 됩니다.
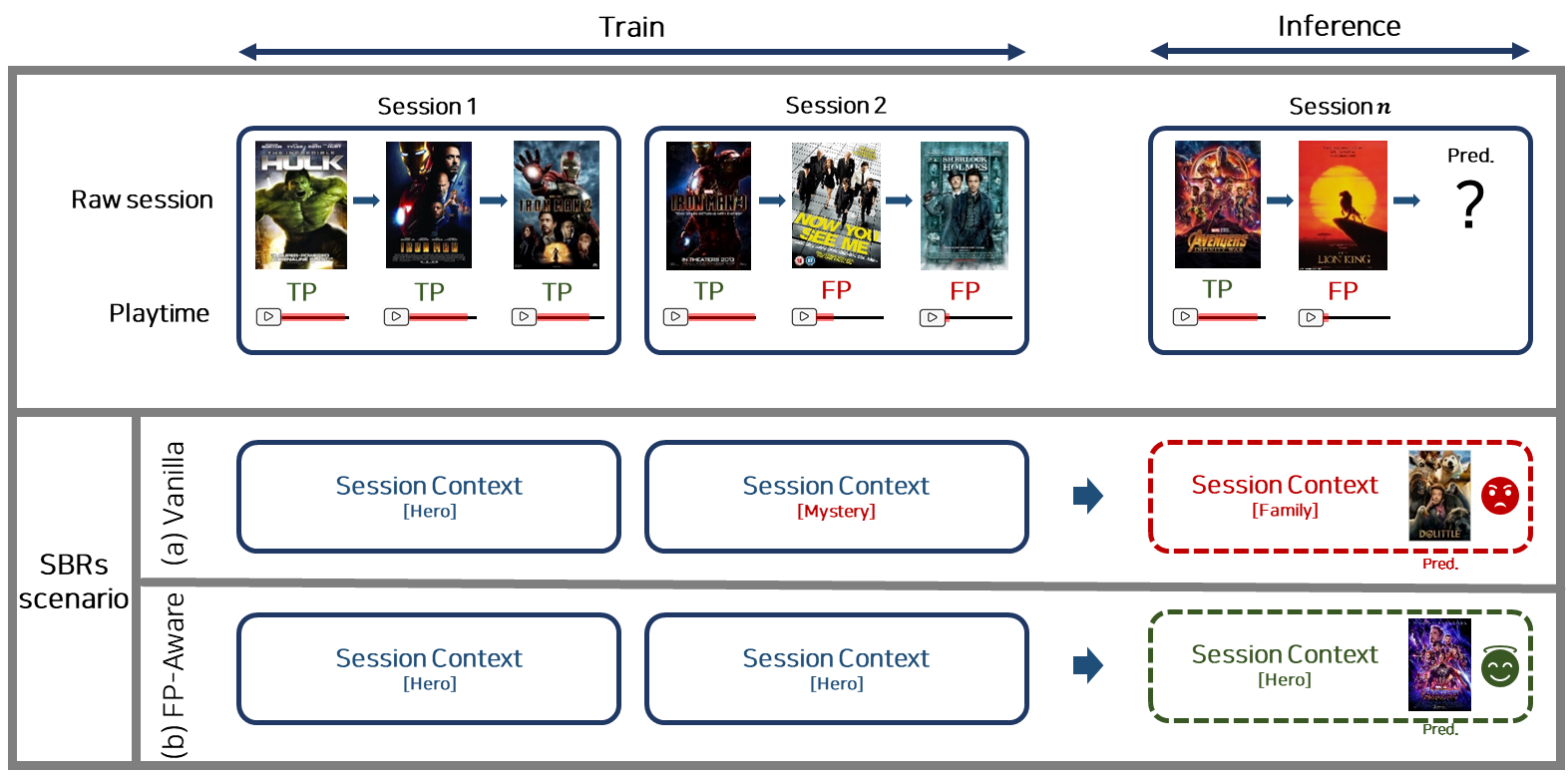 [그림 4] FP 아이템이 세션 기반에 추천에 주는 영향에 대한 예시.
[그림 4] FP 아이템이 세션 기반에 추천에 주는 영향에 대한 예시.
연구 목표
이와 같은 맥락에서, 저희는 FP 아이템을 다르게 활용하여 학습할 수 있는 세션 기반의 추천 방법론을 제안하였습니다. 앞서 말씀드린 것과 같이 이전 연구[1,2]에서는단순하게 FP 아이템을 제거하고 모델을 학습했습니다. 하지만, 저희는 FP 아이템을 단순히 제거하는 것을 넘어서, FP 아이템이 추천이 되지 않도록 추천 모델 학습에 반영하는 것이 추천의 성능을 향상시키는 데 도움이 될 것이라고 생각했습니다. 저희는 FP 아이템을 어떤 식으로 반영했을 때 추천 성능을 향상시킬 수 있을지를 깊이 고민하였으며, 이를 뒷받침 할 수 있는 이론적 근거도 함께 마련하고자 했습니다.
제안 방법론 소개
FP 아이템에 대한 가정
먼저, 저희는 Fuser와 같은 콘텐츠를 추천할 때, 위에서 정의한 FP 아이템이 어떤 특성이 있을지에 대해서 그림 5와 같이 두 가지 가정을 세웠습니다.
 [그림 5] FP 아이템에 대한 두 가지 가정.
[그림 5] FP 아이템에 대한 두 가지 가정.
첫 번째 가정은 세션 안에 포함되어 있는 FP 아이템은 TP 아이템들의 순서에 영향을 끼치지도 않고, 영향을 받지도 않는다는 것입니다. 이를 다르게 말하면, 유저가 실수로 클릭한 아이템과 선호하지 않는 아이템이 선호하는 TP 아이템에 영향을 주지 않아야 한다는 것입니다.
두 번째 가정은 FP 아이템의 선호도가 TP 아이템의 선호도 보다 낮다는 것입니다. 실수로 클릭한 아이템 중에서도 사용자가 좋아하는 아이템이 섞여 있을 수 있지만, 저희는 이런 상황을 고려하지 않았습니다.
가정을 반영한 제안 방법론: FP-Metric
저희는 FP 아이템에 대한 두 가지 가정을 반영하여 세션 기반 추천 문제를 아래와 같이 변경하였습니다. 먼저, \(S^u\)를 유저 u에 대한 세션이라고 할 때, 일반적인 세션 기반 추천에서는 \(S^u\)를 기반으로 아이템을 추천합니다. 하지만, 본 연구에서는 FP 아이템을 정하는 기준을 활용해 첫 번째 가정을 고려하여 \(S^u\)를 TP 아이템만 들어있는 세션 \(S^{u,pos}\)와 FP 아이템 집합 \(FP^u\)을 나누었습니다. 이 때, FP 아이템을 정하는 기준은 아이템을 소비한 시간을 통해 정하게 됩니다. 기준 소비시간을 두고, 기준 소비 시간보다 짧게 소비한 아이템들을 FP 아이템, 기준 시간보다 길게 소비한 아이템을 TP 아이템으로 정했습니다. 또한, FP 아이템은 순서가 상관이 없고 TP 아이템 시퀀스와의 영향이 없다고 가정했기 때문에, 순서를 고려하지 않은 집합으로 간주하였습니다. 그리고 두 번째 가정을 반영하기 위해 세션 \(S^{u,pos}\)에 속한 아이템의 임베딩 벡터(embedding vector)와 \(FP^u\)의 아이템의 임베딩 벡터의 유사도가 어떤 기준보다 작아야 한다는 제약 조건을 추가하였습니다. 이 제약조건을 통해 FP 아이템이 TP아이템보다 낮은 선호도를 가질 수 있도록 하였습니다. 이에 대한 구체적인 수식은 그림 6에서 확인할 수 있습니다.
 [그림 6] FP 아이템에 대한 특성을 반영한 세션 기반 추천 시스템의 학습 목적 함수 및 제약 조건.
[그림 6] FP 아이템에 대한 특성을 반영한 세션 기반 추천 시스템의 학습 목적 함수 및 제약 조건.
위와 같은 저희의 가정을 앞선 예시인 그림 2에 적용해보도록 하겠습니다. 그림 2의 예시에서, 저희는 소비 시간이 짧은 두 번째와 네 번째 아이템(item 2, 4)을 FP 아이템으로 여겼습니다. 그 뒤, 저희는 그림 7과 같이 이 FP 아이템들을 세션에서 제외시키고 FP 아이템 집합에 포함시켰으며, 첫 번째, 세 번째, 다섯 번째, 그리고 여섯 번째 아이템(item 1, 3, 5, 6)만 포함하도록 세션을 재구성했습니다. 저희 연구에서는 재구성한 세션 을 추천 모델 을 거쳐 1) 기존과 같이 다음 아이템을 잘 추천하도록 학습함과 동시에, 2) FP 아이템은 선호도가 낮아지도록 추천 모델을 학습 시킵니다.
 [그림 7] FP 아이템을 고려한 세션 기반 추천.
[그림 7] FP 아이템을 고려한 세션 기반 추천.
저희 논문에는 ‘TP 아이템만을 사용한 세션 \(S^{u,pos}\)으로 구성한 목적 함수에 FP 아이템 집합 \(FP^u\)에 대한 제약 조건 조건이 있는 그림 6의 수식’이 ‘기존의 세션 \(S^u\)으로 구성된 목적함수’와 같은 최적의 해로 수렴함을 보였습니다. 이는 저희가 새롭게 재구성한 문제가 학습을 방해하는 요소가 아니며, 변경된 문제는 모델을 학습할 때 해 탐색 공간(search space)을 줄여주어 최적 해에 더 쉽게 수렴하도록 도와줄 수 있음을 의미합니다. (자세한 증명은 논문의 본문을 참고하시기 바랍니다.)
또한, 저희는 SGD(stochastic gradient descent)와 같은 딥러닝 최적화 방법을 이용하여 모델을 학습할 수 있도록 제안한 목적 함수와 제약 조건을 제약 조건이 없는 형태로 변환하였습니다. 그림 8과 같이 라그랑주 승수법(Lagrange multiplier method)을 이용하여 제약 조건을 목적함수에 포함시켰을 때, 변경된 목적 함수는 한 가지 정규화(regularization) 방법으로 간주할 수 있습니다. 이 때, 변경된 목적 함수는 metric-learning에서 많이 사용하는 triplet loss1의 형태와 유사한 형태임을 알 수 있었습니다.
 [그림 8] FP-Metric 목적 함수.
[그림 8] FP-Metric 목적 함수.
Metric-learning에서 활용되는 loss를 간단히 시각화하면 그림 9과 같습니다. 해당 그림에서 볼 수 있듯이, metric-learning loss 는 anchor를 기준으로 positive sample과는 가깝게, negative sample과는 멀게 학습하는 방법입니다. 이를 그림 8의 수식과 연결지어 세션 기반의 추천시스템에서 해석하면 다음과 같습니다. 세션의 임베딩 벡터가 FP 아이템들과는 멀어짐과 동시(\(L_{met}\)안의 \(D_{sim}\) \((fp,seq)\))에, TP 아이템들과는 가까워지도록(\(L_{met}\)안의 \(D_{sim}\) \((x_k,seq)\)) 하는 것이 학습에 도움을 줄 수 있음을 의미합니다.
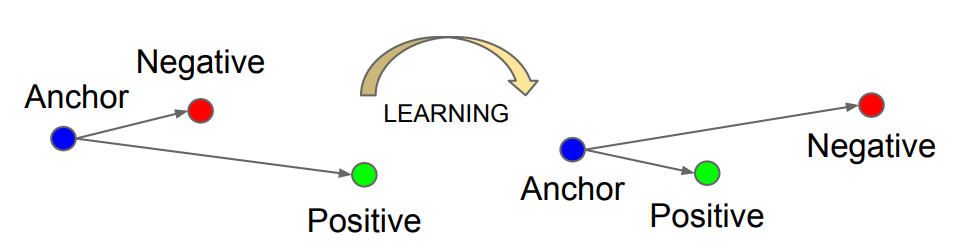 [그림 9] Metric-learning에서 많이 활용되는 Triplet loss1의 형태에 대한 설명.
[그림 9] Metric-learning에서 많이 활용되는 Triplet loss1의 형태에 대한 설명.
추가 성능 개선 방법론: FP-AdaMetric
수학적인 증명과 실험을 통해, 저희가 제안한 FP-Metric 이라는 정규화(regularization) 방법이 도움이 되는 것을 보였습니다. 하지만, 저희는 그림 10의 가정과 같이 유저가 FP 아이템에 대한 비선호도가 다를 수 있고 이 가정을 추가로 고려하면 더 좋은 세션 기반 추천 시스템이 될 것이라고 생각했습니다.
 [그림 10] FP 아이템에 대한 추가적인 가정.
[그림 10] FP 아이템에 대한 추가적인 가정.
예를 들어, 어떤 유저는 공포 영화를 싫어하고, 이런 특성이 반영된 세션이 있다고 가정을 하겠습니다. 이 세션의 FP 아이템들을 공포 영화로 간주할 수 있습니다. 하지만 공포 영화더라도 영화마다 무서움 정도가 각기 다르고, 공포 영화가 세션에 포함되어 있더라도 무서운 정도에 따라 세션에 주는 영향도가 다를 것입니다. 덜 무서운 영화는 덜 싫어할 것이고, 많이 무서운 영화는 매우 싫어할 것이라는 의미입니다. 저희는 이를 싫어하는 정도(degree of dislike)라고 정의하고 모델에 반영하였습니다.
FP-Metric에는 싫어하는 정도에 대한 특성이 반영되지 않고, 똑같은 비율로 FP 아이템들이 세션에 영향을 주고 있습니다. 추천성능을 더 개선하기 위해선 이런 특성이 모델 안에 반영이 되어야한다고 생각을 하였으며, 이를 위해 아래와 같이 metric learning 부분에 adaptive module을 제안하고 이를 FP-Adametric 이라고 명명했습니다.
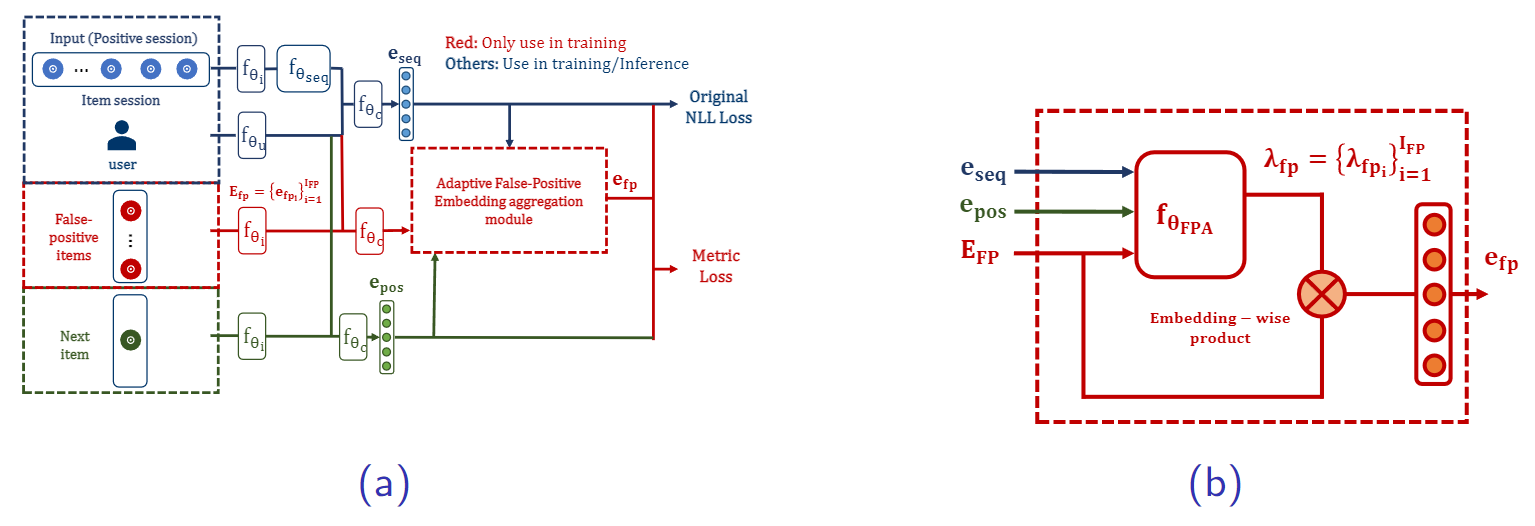 [그림 11] 제안하는 FP-AdaMetric의 학습구조. (a) 전반적인 학습 구조, (b) Adaptive false-positive embedding aggregation 모듈에 대한 자세한 모델 구조.
[그림 11] 제안하는 FP-AdaMetric의 학습구조. (a) 전반적인 학습 구조, (b) Adaptive false-positive embedding aggregation 모듈에 대한 자세한 모델 구조.
그림 11은 제안한 모듈이 어떤 구조로 이루어져 있는지 보여주고 있습니다. FP-Metric의 경우 FP 아이템을 metric learning에 반영할 때 단순히 평균을 통해 계산을 했다면, FP-Adametric에서는 FP 아이템들의 선호도를 유동적으로 반영하는 adaptive false-positive embedding aggregation 모듈을 활용해 FP 아이템의 최종 임베딩 벡터를 계산합니다. 그림 11의 (a) 에서 보시는 바와 같이 adaptive false-positive embedding aggregation 모듈을 통해 나온 최종 FP 아이템 임베딩 벡터가 metric learning 계산에 반영되어 계산이 됨을 의미합니다.
FP-Adametric의 전반적인 구조에 대해 추가적으로 설명해 보겠습니다. 먼저, 그림 7과 같이 세션에서 FP를 분리해둔 데이터셋을 준비합니다. 그 안에는 세션 시퀀스, FP 아이템 집합, 그리고 Next 아이템이 있습니다. 각각의 부분별로 얻을 수 있는 세션 시퀀스 임베딩 벡터, FP 아이템 임베딩 벡터 집합, 그리고 Next 아이템 임베딩 벡터는 \(e_{seq}\), \(E_{fp}\), \(e_{pos}\)가 됩니다. 이렇게 얻어진 각 부분별 임베딩 벡터들을 이용하여 그림 11의 (b)에 나와있는 것과 같이 adaptive false-positive embedding aggregation 모듈 안에서 각 FP 아이템을 얼마나 반영할지에 대한 정도값인 \(λ_{fp_i}\)를 계산하게 됩니다. 구체적으로, 그림 11의 (b)에서 보면 알 수 있다시피, \(e_{seq}\)과 \(e_{pos}\)를 입력받아 각 FP 아이템마다 해당하는 \(λ_{fp_i}\)값이 계산됩니다. 또한, FP 아이템 집합안의 아이템 개수가 \(I_{FP}\)라고 할 때, \(λ_{fp}\)는 총 \(I_{FP}\)개의 \(λ_{fp_i}\)로 이루어지는 집합이 됩니다. 마지막으로 FP 아이템 집합안의 모든 FP 아이템들에 대해 계산된 비중 값인 \(λ_{fp}\)을 반영하여 합쳐서 최종 \(e_{fp}\)를 얻고, 이를 metric learning에 반영하게 됩니다. 이 부분에서 FP-Metric과의 차이가 발생을 합니다. FP-Metric의 경우, 총 반영해야할 FP 아이템의 개수가 \(I_{FP}\)개라면, FP 아이템들을 모두 같은 비중(\(1/I_{FP}\))으로 반영하여 metric learning에서 활용할 최종 \(e_{fp}\)를 얻는 과정을 거칩니다. 하지만, FP-Adametric에서는 \(λ_{fp}\)값에 따라 FP아이템들이 다른 비중으로 반영이 되어 \(e_{fp}\)가 계산이 되고, 이것이 metric-learning에서 활용이 되게 됩니다. 위 과정을 수식으로 나타내면 그림 12처럼 표현할수 있으며, FP-Metric과의 차이가 \(L_{adamet}\) 부분의 \(e_{fp}\)를 구할 때 \(λ_{fp}\)이 고려되어 더해지는 부분임을 알 수 있습니다.
 [그림 12] 그림 12. FP-AdaMetric 목적 함수.
[그림 12] 그림 12. FP-AdaMetric 목적 함수.
결론 및 한계점
본 연구는 세션 기반 추천 시스템에서 단순한 클릭 시그널을 넘어, 유저도 모르는 사이에 만들고 있는 작은 시그널도 놓치지 않고 모델 학습에 사용하기 위한 첫 걸음으로서 의미가 있는 연구였습니다.제안 방법이 벤치마크 데이터셋뿐 아니라 사내 서비스인 Fuser에서도 효과를 확인할 수 있었습니다.이 뿐만 아니라 다양한 서비스에서 활용될 수 있는 알고리즘임을 확인했습니다.
저희 랩은 이 외에도 페이지, 버프툰, 연합뉴스 등 여러 영역에서 추천서비스를 제공하고 각 영역에 맞춰 추천 알고리즘을 개선하기 위한 노력을 이어가고 있습니다.
