
1. 개요
Yoav Goldberg (2023)1의 “Some Remarks on Large Language Models”에선 책, SNS, 인터넷 등의 기존의 자연어 텍스트 데이터로만 훈련된 GPT-3 등의 거대언어모델(Large Language Model, LLM)에게는 이론적인 한계가 있다고 주장합니다. 거대언어모델은 수백에서 수천억개의 파라미터로 구성되어 있지만 자연어 텍스트 데이터만을 계속하여 학습한다면 그 모델에게 텍스트는 여전히 단어를 나타내는 기호(symbol)에 불과하고 근본적인 의미(meaning)와는 연결 짓지 못하기 때문이에요. 사람은 기본적으로 어떠한 단어를 이야기 할 때 그 의미를 전달하기 위함이 목적인데, 사람과 다르게 기존의 거대언어모델의 경우 ‘파인애플’이라는 단어가 ‘타원형에 노란색이며 초록색 풀을 가진 단맛의 과일’이라는 의미를 고려하지 않는다는 말이죠.

하지만 FLAN, InstructGPT와 같은 거대언어모델이 공통으로 가지는 instruction tuning을 통해서 궁극적으로 모델들이 grounding을 인식하는 계기가 된다고 설명합니다 (instruction tuning에 대해서는 2부에 자세히 알아봅시다). 여기서 grounding이란, 밤에는 자야 하는 것과 음식을 먹지 않으면 배가 고픈 것과 같이 ‘사람과 사람 사이에서 보편적으로 같은 경험을 했을 것이라고 가정하여 상호 간에 공통적으로 이해하는 것’이에요. 즉, 기계가 언어를 이해하고 표현할 때 기계가 참조하는 실제 세계의 개체와 사건을 관련시킬 수 있는 능력이죠. 다음으로 넘어가기 전에 아래의 예제를 보면서 grounding의 개념을 다시 한번 살펴 보겠습니다.
“나는 파인애플 가게에 갑니다.”
기계는 ‘나’가 누구를 가리키는지, ‘파인애플 가게’가 무엇인지, 그리고 ‘가다’의 개념이 의미하는 것을 알아야 합니다. 더 나아가, 이러한 개념들을 물리적인 위치나 사건으로 연결해야 해요. 그리고 이 개념들이 비로소 인지가 되었을 때 ‘나는 파인애플 가게에 갑니다’의 문장이 인간이라는 ‘나’ 자신이 노란색 타원형의 초록색 풀을 가진 단맛이 나는 과일인 ‘파인애플’을 파는 ‘가게’에 움직여서 ‘갑니다’라는 문장의 의도를 이해했다고 생각 할 수 있어요.

그렇기 때문에 주어진 텍스트에 “please translate 파인애플 in English” 라는 설명을 데이터에 붙이고 작업자들이 실제로 번역 작업을 한다면, 이 어노테이션 작업으로 인해 텍스트에 grounding을 주입할 수 있습니다. 왜냐하면 ‘요약’, ‘번역’과 같은 지시들이 일관되게 나타나고 항상 텍스트의 시작 부분에 위치하면서 모델이 ‘요약’이라는 지시의 의도를 이해할 수 있는 어노테이션 작업의 예제를 바탕으로 학습을 하기 시작하기 때문이에요.
Goldberg1는 이렇게 어노테이션으로 구축된 직접적인 지시문 (instruction) 데이터를 통해 거대언어모델을 학습하는 것이 더 효과적이라고 이야기 합니다. 더불어 지시문으로 인한 학습데이터가 모델에게 텍스트에 대한 의미를 지속적으로 알려주면서 결국에는 요구되는 학습 데이터의 사이즈까지 줄일 수 있다고 주장하고 있어요. 이로 인해 기존의 데이터에서 한층 진화 된 프롬프트 (prompt) 데이터 셋을 학습을 함에 있어서 거대언어모델 기술의 가치도 한층 더 개선되고 있음을 알 수 있습니다.
그러므로 계속해서 이어지는 1부에서는 프롬프트가 잘 작동할 수 있게 도와주는 프롬프트 1) 엔지니어링(prompt engineering)의 중요성을 알아보면서 2) 자연어 텍스트 데이터로만 학습된 GPT-3의 데이터 구성을 살펴보고자 합니다. 그 다음으로 2부에서는 자연어 텍스트 데이터에서 진화된 프롬프트 데이터 구성을 소개하고 3부를 끝으로 언어모델의 프롬프트 데이터 학습으로 인해 성능이 어떻게 평가가 되었는지에 대한 이야기로 거대언어모델 프롬프트 데이터 소개가 마무리됩니다.
2. 거대언어모델의 최신 데이터 패러다임 - “프롬프트 엔지니어링”
프롬프트 엔지니어링의 중요성
프롬프트 엔지니어링이란 다음과 같이 설명할 수 있습니다 (Schick and Schütze (2021)2, Reynolds and McDonell, (2021)3, Liu et al. (2021)4).
- 언어 모델이 NLP 태스크를 수행하기 위해 효과적인 개별 프롬프트를 구성하는 활발한 연구 영역
- 모델로부터 응답을 생성하기 위한 명령을 입력함으로써 높은 품질의 응답을 얻어낼 수 있게 입력값들의 조합을 찾는 작업
많은 사람들이 ChatGPT 같은 대화형 인공지능 서비스에 놀라는 이유는 단순히 기계가 출력할 수 있는 간략한 결과값을 보여주는 것이 아닌 정말 사람이 사람에게 설명하는 듯한 풍부한 문맥, 지식 그리고 추론을 함께 겸비하였기 때문입니다. 이러한 양질의 응답을 보여주기 위해 어떠한 프롬프트로 입력으로 주는지를 고민하는 부분이 프롬프트 엔지니어링 작업이에요.
아래의 Figure 1의 예시에서 볼 수 있는 것처럼 입력에 따라 완전히 다른 결과를 돌려 줍니다. 여기서, 입력의 문장은 짧을 수 도 있으며 다양한 정보를 포함하고 있는 문장이 아닐 수 도 있습니다. 하지만, 여전히 요구되는 가장 필요한 능력은 아무런 답변을 광범위하게 출력해 놓는 것이 아니고 사용자의 의도에 적합한 결과를 가져다 주는 것이라 할 수 있어요.
가령, “여름 휴가로 독일 여행을 가려고 하는데 1년 중 언제 가면 제일 좋을지”에 관련해서 답변을 얻고자 했을 때, Figure 1과 같이 간단한 입력문인 “When is the best time in German?”으로 물어 보았을 때 결과로는 여러가지의 옵션을 반환해 주었습니다. 이 결과는 사용자의 의도에 대한 직접적인 답변이 아닌 광범위한 답변을 내어 준 것이에요.
 Figure 1. “여름 휴가로 독일 여행을 가려고 하는데 1년 중 언제 가면 제일 좋을지”의 대한 답변을 얻기 위해 간략하게 질문한 “When is the best time in German?”에 대한 결과물
Figure 1. “여름 휴가로 독일 여행을 가려고 하는데 1년 중 언제 가면 제일 좋을지”의 대한 답변을 얻기 위해 간략하게 질문한 “When is the best time in German?”에 대한 결과물
그럼 이번에는 여행의 시기를 알고자 하는 부분을 조금 더 강조하여 ‘the best time’ 을 ‘the best months to travel’로 수정하여 질문을 해보았습니다. 이전보다 구체적으로 만들어서 시도를 해보았더니 Figure 2에서 보여지는 것처럼 질문의 의도를 잘 파악하여 여름에 독일 여행을 가면 좋은 시기에 대한 답변을 잘 생성해 주었습니다. 뿐만 아니라, 추가사항으로 여행 시 고려하면 좋은 점을 문맥 안에 자연스럽게 포함하여 함께 알려주었습니다.
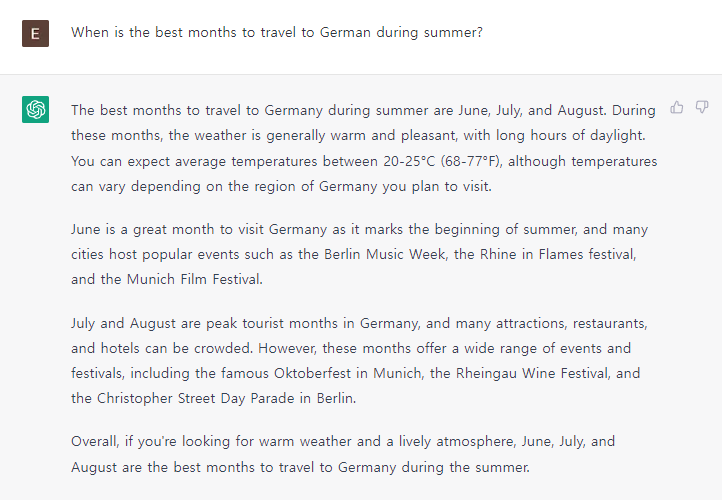 Figure 2. 질문 속의 “the best time” 을 “the best months to travel”로 수정하여 나온 결과물
Figure 2. 질문 속의 “the best time” 을 “the best months to travel”로 수정하여 나온 결과물
Figure 2에서 보여준 입력문에 대한 결과물이 사람의 의도에 알맞게 답변을 해주기 위해서는 거대언어모델이 학습한 프롬프트 데이터의 역할이 중요합니다. 프롬프트 엔지니어링을 통해서 결과를 잘 반환해주는 입력 값을 찾기 위해선 이미 모델에 instruction tuning으로 학습이 된 프롬프트 데이터가 있어야 하기 때문입니다. 따라서, 앞으로 알아보고자 하는 거대언어모델의 프롬프트에는 각 NLP 태스크에 해당하는 자세한 지시문들을 포함하여 데이터를 구축을 하고, 구축된 프롬프트 데이터를 학습하여 unseen 태스크들에 대한 문제 해결이 가능한 일반적인(generalization) 능력을 높이려는 부분에 집중하는 것이 중요합니다. 이렇게 중요한 역할을 맡고 있는 프롬프트 데이터들에 대해 알아보기 전에 거대언어모델이 전통적으로는 어떠한 대용량 데이터들을 학습하였는지 1부의 마지막 세션에서 먼저 알아보아요.
3. 대용량 자연어 텍스트 데이터
사람도 여러 경험 및 여러 과목의 공부를 통해 상식과 지식이 쌓이는 것처럼 모델도 학습을 시킬 수 있는 데이터가 중요합니다. 뿐만 아니라, 언어 모델에게는 각 태스크에 해당하는 입력에 대해 사람과 같은 결과물을 요구하지요. 이전까지만 해도 데이터 학습방법은 태스크를 실행할 때 마다 그 태스크에 알맞는 데이터를 fine-tuning 하여 사용했습니다. 하지만 앞으로는 task-agnostic한 데이터를 생성하고자 함에 중점을 두고 있어요.
여기서 GPT-3는 task-agnostic 개념에 아주 가까운 성능을 가지고 있습니다. 주기적인 업데이트나 fine-tuning을 하는 것이 아닌 few-shot learning 및 zero-shot learning같은 방법을 통해 ‘번역’, ‘질의응답’ 등의 NLP 태스크들에 대한 높은 성능을 가지고 있습니다. 별도의 학습을 하지 않고 프롬프트 데이터를 통해 태스크를 해결하는 기술을 수행하였기에 본 세션에서는 우선적으로 GPT-3의 자연어 텍스트 데이터 셋을 먼저 살펴보고자 합니다. Figure 3에서 보여지는 것 처럼 GPT-3의 데이터는 지시문이 적용되기 전에 학습데이터로 사용되었던 대용량 자연어 텍스트 데이터입니다. 따라서 GPT-3의 데이터 구성을 알아보면서 전통적인 학습 데이터의 한계점과 어떤 부분을 개선해야 하는지에 대해 알아보겠습니다.
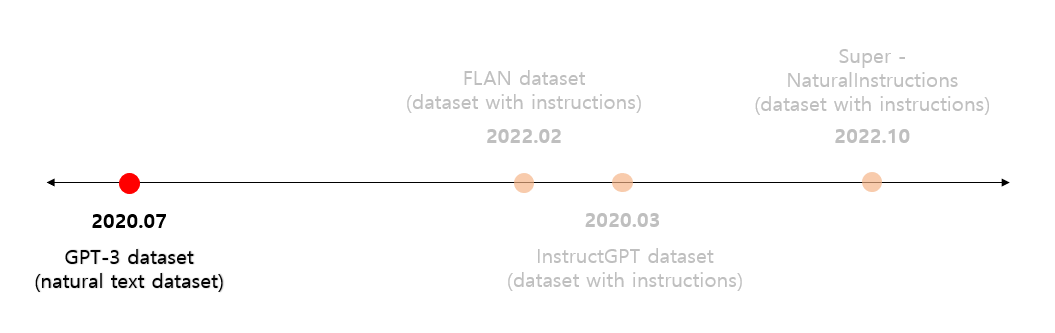 Figure 3. 거대언어모델의 데이터셋 출시 연대순
Figure 3. 거대언어모델의 데이터셋 출시 연대순
GPT-3 (Open AI) 데이터 셋
GPT-3는 약 1조 규모로 구성된 Common Crawl 데이터 셋을 사용했습니다. 이 정도 데이터 크기를 보유한 것이라면 데이터를 따로 추가하여 학습 시키지 않아도 될 만큼의 충분한 양이라고 볼 수 있습니다. 하지만, 필터링이 많이 되지 않은 Common Crawl버전은 curated 데이터 셋 보다 품질이 떨어진다는 점을 Brown et al. (2020)5의 연구에서 이야기 합니다. 그래서 Brown et al. (2020)5은 Common Crawl의 품질을 개선하기 위해서 다음과 같은 3가지 방법을 사용하였습니다. 이 3가지 과정을 거쳐서 최종적으로는 아래의 Table 1에 나타난 자연어 텍스트 데이터 셋들이 GPT-3 학습용 데이터로 사용되었습니다.
Common Crawl Filtering
- Common Crawl은 많이 알려진 고품질의 데이터들 (WebText2, Book1, Book2, Wikipedia)과 비슷한 수준으로 필터링 함
여기서 Common Crawl에 대한 필터링의 과정을 조금 더 자세히 이야기 하자면, Brown et al. (2020)5이 저품질의 문서를 없애는 automatic filtering 기법을 개발하였습니다. 필터링 기법에 대해 좀 더 말씀드리자면 WebText를 고품질 문서의 기준으로 사용하여 분류기가 WebText와 Common Crawl을 분류할 수 있게 훈련을 시켰어요. 그리고 Common Crawl에서 고품질이라고 예측되는 데이터들만 학습데이터로 포함한 것이지요. 또한 이 분류기의 positive example은 WebText, Wikipedia, Books가 되었으며, negative example로는 필터링이 되지 않은 Common Crawl을 사용했어요. 필터링에 있어서 아래의 Formula 1의 수식과 같이 Pareto 분포의 알파 값을 9로 높이고 아주 나쁜 점수의 문서만 걸러내는 것을 목표로 하였어요. 그렇지만 아무래도 필터링이기 때문에 여전히 좋지 않은 품질의 문서도 포함이 되어 있긴 해요.
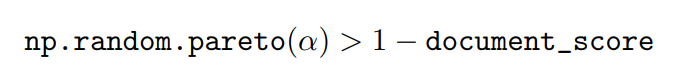 Formula 1. Pareto 분포를 사용한 Common Crawl 필터링 수식
Formula 1. Pareto 분포를 사용한 Common Crawl 필터링 수식
Fuzzy Deduplication
- 모델 성능을 향상 시키고 over-fitting을 방지하기 위해 Sparks의 MinHashLSH를 사용하여 다른 문서와 많이 겹치는 문서들을 제거함
The Addition of Reference Corpora
- Common Crawl을 보강하고 다양성을 높이기 위해 고품질의 데이터들 (WebText2, Book1, Book2, Wikipedia)을 학습에 추가함
 Table 1. GPT-3에 사용된 학습데이터 셋
Table 1. GPT-3에 사용된 학습데이터 셋
이러한 대용량 자연어 텍스트를 학습한 거대언어모델 GPT-3는 NSP (next sentence prediction)을 수행하는 환경에 익숙한 점이 이슈가 됩니다. 다음 문장 예측에 뛰어난 GPT-3의 경우는 데이터 덩어리를 주고 그 다음의 이야기를 유추해 보는 같은 간접(implicit) 프롬프트에는 잘 동작하였지만 직접(explicit) 프롬프트에는 혼란스러운 결과를 보여주었어요. 즉, Figure 4에서 보이는 제일 왼쪽 단락의 예시와 같이 여러 문장/문단들을 바탕으로 다음 문장/문단을 생성해 나아가는 방식에는 문제가 없었습니다. 다만 직접적으로 문제에 대한 답변을 제공 해야 하는 경우에는 마치 렉이라도 걸린 것처럼 불안한 결과를 보여 주었지요. 이 문제를 통해 전통적인 방법인 자연어 텍스트 데이터를 사용한 GPT-3의 한계점을 파악할 수 있었는데, 거대언어모델의 이 한계를 극복하기 위해 제안한 방법이 바로 그 유명한 instruction을 가지는 데이터 구성입니다. 이에 따라 태스크에 대한 지시문들을 내장한 데이터 셋을 사용하고 난 후로는 Figure 4의 맨 오른쪽처럼 InstructGPT가 GPT-3 보다 개선된 결과를 보여주고 있지요.
 Figure 4. 입력에 대한 GPT-3와 InstructGPT의 결과물 차이
Figure 4. 입력에 대한 GPT-3와 InstructGPT의 결과물 차이
4. 1부를 마치며
이번 포스트를 통해 프롬프트가 무엇인지, 프롬프트 엔지니어링은 어떤 작업을 하는 것인지에 대해 알아 보았습니다. 뿐만 아니라 프롬프트 엔지니어링의 중요성을 통해 GPT-3에 학습되어 있는 데이터들로 학습이 되었을 때 직접 프롬프트 입력으로 인해 나타나는 문제점까지 살펴 보았습니다. 아직 많은 사람들에게 친근하게 다가올 수 있을 만큼 거대언어모델을 위한 텍스트 데이터라는 개념이 수면 위에 많이 들어 나지는 않았지만 사람과 같은 발화를 할 수 있게 많은 연구들이 진행되어 오고 있으며 그만큼 데이터를 다루는 방식 또한 더 좋은 방향으로 계속하여 발전되고 있음을 알려줄 수 있는 포스트가 되었으면 좋겠습니다. 이 바람을 이어서 GPT-3보다 개선된 결과를 보여주었던 데이터들에 대해서는 2부에서 알아보도록 하겠습니다!
 그럼 2부에서 만나요! 뿅✨
그럼 2부에서 만나요! 뿅✨
References
- OpenAI. “Introducing Chatgpt.” Introducing ChatGPT, https://openai.com/blog/chatgpt#OpenAI. 2022.
-
Goldberg, Yoav. “Some Remarks on Large Language Models.” Gist, https://gist.github.com/yoavg/59d174608e92e845c8994ac2e234c8a9. 2023. ↩ ↩2
-
Timo Schick and Hinrich Schütze. 2021. Few-shot text generation with natural language instructions. In Proceedings of EMNLP. ↩
-
Laria Reynolds and Kyle McDonell. 2021. Prompt programming for large language models: Beyond the few-shot paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, pages 1–7. ↩
-
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021. Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv preprint arXiv:2107.13586. ↩
-
Brown, Tom, et al. “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901. ↩ ↩2 ↩3
