
1. 개요
안녕하세요, 또 뵙게 되어 반갑습니다. 지난 포스트에서는 긴 글을 처리하기 위해 고안된 두 트랜스포머 모델, Longformer와 BigBird의 희소 어텐션 방식에 대해서 알아보았었죠. 이번 포스트에서는 두 논문에서 모델을 평가하기 위해 수행한 실험들의 과정과 결과에 대해서 이야기하고자 합니다. 또한 이와 유사한 모델들, 혹은 이 모델들에서 파생되어 발전한 모델에 대해서도 알아보도록 합시다.
2. 실험
2.1. 사전학습 (Pretrain)
Longformer
Longformer 논문의 저자들은 BERT나 다른 언어 모델이 수행하는 것처럼 사전학습을 수행시켰습니다. 다만 입력의 길이가 BERT/RoBERTa의 8배, 4096토큰까지 확장된 것이 가장 다른 점이죠.
시간과 자원의 절약을 위해, Longformer는 RoBERTa 모델의 체크포인트로부터 학습을 시작하였습니다(이를 Warm-Starting이라고 부른다네요). RoBERTa에서 이미 학습된 Weight를 최대한 이용하면서 Longformer의 어텐션 메커니즘을 적용할 수 있도록 최소한의 변형만을 가했다고 합니다. 여느 언어 모델과 마찬가지로 MLM(Masked Language Model)으로써 학습되었습니다.
학습 시 슬라이딩 윈도우 사이즈는 512로 설정되었습니다. 앞선 포스트에서 풀 어텐션의 복잡도는 \(O(n^2)\)이고 슬라이딩 어텐션의 윈도우는 \(O(n \times w)\) (\(w\): 윈도우 사이즈)라고 말씀드렸던 것을 기억하시나요. \(w\)를 512로 설정하였으니, 길이가 512인 입력에 대해서 풀 어텐션을 채택한 언어 모델(여기서는 RoBERTa)과 Longformer의 연산량이 동등한 수준이라고 볼 수 있겠죠. 덕분에 두 모델의 성능 비교가 좀 더 쉬워질 수 있겠습니다.
셀프 어텐션은 그 특성상 제대로 된 학습을 위해 각 토큰의 위치 정보가 추가적으로 필요합니다. 이를 위해 BERT나 RoBERTa 모델에서는 사전학습 시 포지션 임베딩(Position Embedding)을 무작위 초기화 후 학습하는데요, Longformer의 포지션 임베딩은 무작위 대신 RoBERTa가 학습한 512 길이의 포지션 임베딩을 여러 번 복사하여 길이를 늘린 형태로 초기화되었습니다.
학습 데이터셋(말뭉치, Corpus)은 Books Corpus, 영어 위키피디아, Realnews Dataset, Stories Corpus를 혼합하여 구성하였습니다. 전체적으로 짧은 문서와 긴 문서가 고루 분포하도록 구성하였다고 하는데요, 이는 긴 문서에 대해서 성능을 확보함과 동시에 짧은 문서에 대한 성능 또한 보존하기 위한 의도입니다.
나머지 하이퍼파라미터는 RoBERTa의 것을 참고하여 세팅되었다고 합니다.

이렇게 사전학습된 Longformer의 결과는 위 표와 같습니다. 표의 오른편에 있는 수치들은 BPC(Bits-Per-Character)를 뜻하는데요, PPL(Perplexity)과 유사한 개념으로 보시면 됩니다. 수치가 낮을수록 모델이 더 잘 학습되었다고 볼 수 있겠습니다. 표의 각 행에 대한 부연설명은 다음과 같습니다.
- 일반적인 RoBERTa 모델
- 포지션 임베딩을 무작위 초기화한 Longformer 모델 (사전학습 전)
- RoBERTa의 포지션 임베딩을 복사한 Longformer 모델 (사전학습 전)
- (3)에서 사전학습 2천 스텝을 수행한 모델
- (3)에서 사전학습 6만 5천 스텝을 수행한 모델
- RoBERTa로부터 가져온 Weight를 고정(Freeze)하고, 포지션 임베딩만을 학습시킨 모델
2번과 3번 모델의 결과를 비교하면, RoBERTa의 포지션 임베딩을 복사해서 가져왔을 때 BPC가 크게 좋아지는 경향을 보임을 확인할 수 있습니다. 논문의 저자들은 해당 결과가 포지션 임베딩 초기화 방식의 중요성을 보여주는 부분이라고 소개하고 있습니다. 또한 3번 모델의 BPC는 base모델, large모델 각각 1.957과 1.597로 RoBERTa(1번 모델)의 1.846, 1.496과 큰 수치 차이가 나지 않음을 보실 수 있죠. 이는 Longformer의 어텐션 방식이 RoBERTa의 사전학습된 Weight와도 잘 동작함을 의미한다고 합니다.
이후 사전 학습을 2천번부터 6만 5천번까지 수행한 결과 BPC가 점점 감소합니다. 최종적으로 Base 모델의 BPC가 1.705까지 감소하죠. Longformer 모델이 자신 고유의 구조를 더 잘 활용 가능하도록 학습하였다고 생각할 수 있겠습니다.
BigBird
BigBird 모델의 사전학습 설정도 Longformer와 거의 동일합니다. RoBERTa의 체크포인트로부터 Warm Start를 한 것도 동일하죠. 대신 이전 포스트에서 BigBird의 전역 어텐션 방식이 ITC/ETC 두 가지로 나뉜다고 말씀드렸었죠? 이에 따라 사전학습 설정이 조금 다르게 구성되었습니다. 아래 표에 각 모델의 하이퍼파라미터 설정이 나와 있습니다.
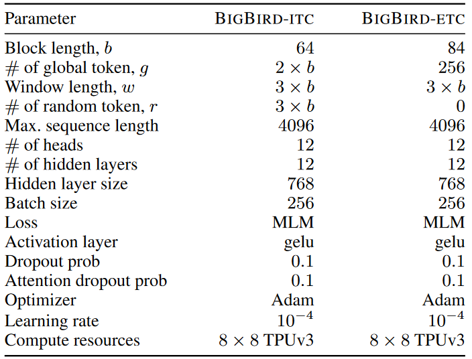
위 표의 4번째 파라미터인 # of random token, r 설정을 보시면 ETC모델의 무작위 토큰 개수가 0임을 확인할 수 있습니다. 분명히 이전 포스트에서 BigBird의 핵심 어텐션 패턴 3가지 중 하나로 무작위 어텐션을 소개드렸는데요, 해당 역할을 담당하는 토큰이 0개인 것은 이상하죠. 이는 ETC 모델의 전역 토큰(표에서 2번째 파라미터, # of global token, g) 개수가 ITC 모델보다 많아서 이들만으로도 충분한 성능이 확보되었기 때문이라고 합니다. 또한 표에는 기술되지 않았지만 ITC는 포지션 임베딩, ETC에는 상대적 포지션 인코딩(Relative Position Encoding)이 사용되었다는 것도 다른 점이 되겠습니다.
학습 말뭉치(Corpus)는 Books, CC-News, Stories, 위키피디아를 혼합하여 구성되었습니다.
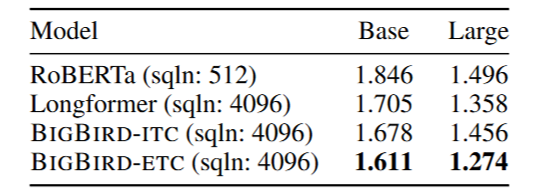
사전학습된 BigBird 모델의 BPC를 타 모델과 비교한 결과는 위 표와 같습니다. 앞서 보여드린 Longformer 모델의 BPC도 함께 나와 있죠. Base 모델 기준으로 ITC/ETC 모델의 BPC는 1.678과 1.611로 RoBERTa의 1.846보다 좋은 수치이며 Longformer의 1.705와 비슷합니다. Large 모델 기준으로도 각각 1.456/1.274로 RoBERTa가 기록한 1.496보다 좋고 Longformer의 1.358에 살짝 앞서거니 뒤서거니 하는 수치를 보이죠. 특히 ETC 모델이 ITC보다 소폭 좋은 BPC 수치를 나타냅니다.
2.2. 질의응답 (Question Answering)
언어 모델의 성능을 평가하기 위한 여러 과제(Task) 중 하나로 QA, 질의응답이 있습니다. 두 모델은 여러 QA 데이터셋에 대해 학습과 평가를 진행하였구요, 이 때 질문과 문서를 이어 붙여서 하나의 긴 글로 만든 후 모델이 학습/추론하도록 구성하였습니다.
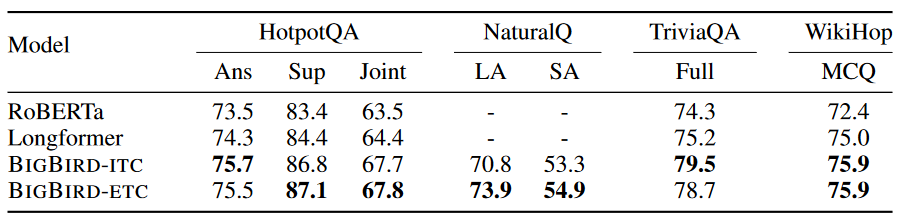
Base 모델의 QA 성능은 위 표와 같습니다. WikiHop 점수는 정확도(Accuracy)를 뜻하고, 나머지 QA에 대해서는 F1 점수가 기재되어 있습니다. Longformer와 BigBird 두 모델 모두 RoBERTa보다 앞선 성능을 보이죠.
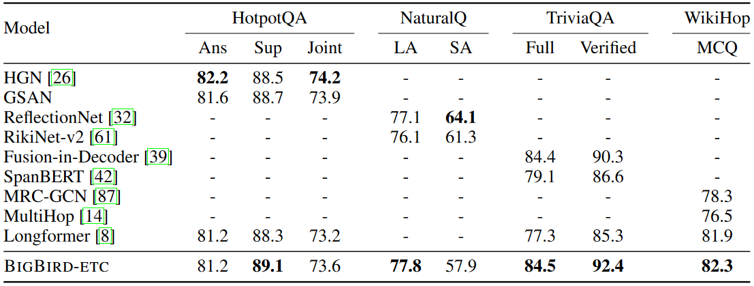
Large 모델의 QA 성능을 기존 여러 모델들과 비교한 표는 위와 같습니다. 두 모델이 SOTA에 준하는 성능을 보임이 확인됩니다. (논문 발표 시점 기준, 2020년) 두 모델만을 비교했을 때, BigBird-ETC 모델이 전체적으로 Longformer와 비슷하거나 살짝 앞서는 성능을 보이고 있음을 확인할 수 있는데요, 이에 관해 두 모델의 논문의 의견이 약간 다른 것이 재미있습니다. Longformer 측에서는 BigBird가 사전학습 단계에서 16배 많은 컴퓨팅을 사용한 것이 차이로 보인다고 이야기하는데요, 반면 BigBird 측에서는 포지션 인코딩 및 전역 어텐션 학습 방식에서 차이가 존재한다고 이야기합니다.
2.3. 요약 (Summarization)
요약 과제에 대해서도 모델 평가가 진행되었는데요, 두 모델 모두 arXiv 데이터셋에 대해서 학습과 검증을 수행했습니다. 이 때, Longformer의 경우 요약 과제를 수행할 수 있도록 파생된 설계인 LED(Longformer Encoder-Decoder) 모델을 통해 평가를 수행했습니다. 해당 모델은 인코더 단에서 Longformer의 지역+전역 어텐션을 계산하고, 디코더 단에서 풀 어텐션을 계산하는 형태를 가지고 있습니다. 이 LED 모델은 BART 모델로부터 파라미터를 가져와 사전 학습 단계를 생략하였는데요, 이 때 BART의 16배인 16,384토큰(!)까지의 입력을 처리할 수 있도록 확장이 이루어졌습니다.
BigBird 모델 또한 BigBird 인코더에 풀 어텐션 디코더를 결합하여 요약 과제를 수행하였는데요, 왜 두 모델 모두 인코더에만 희소 어텐션 방식을 적용하였는지 궁금하지 않으신가요? BigBird 논문의 저자들은, 과제의 입력 길이가 평균 3000토큰 이상인 데 비해 출력해야 할 길이는 평균 200토큰 정도로 상대적으로 매우 짧기 때문에 디코더에 풀 어텐션을 적용하였다고 밝히고 있습니다. BigBird Base 모델은 RoBERTa로부터, BigBird Large 모델은 Pegasus라는 모델로부터 요약을 위한 사전 학습 Warm-Start가 이루어졌습니다.
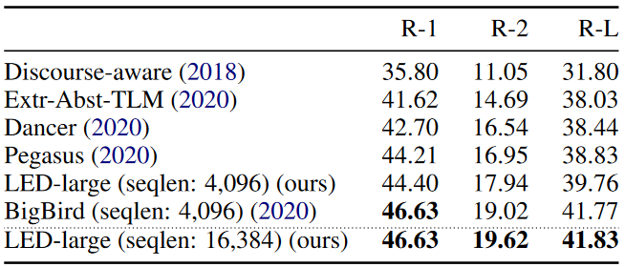
각 모델들이 데이터셋에 대하여 평가를 수행한 결과(ROUGE-1, ROUGE-2, ROUGE-L)를 표에서 확인하실 수 있는데요, 두 모델 모두 SOTA에 근접한 성능을 보임을 확인할 수 있습니다. LED 모델의 경우 사전 학습 단계를 생략하였음에도, 요약 특화 모델인 Pegasus로부터 사전 학습했던 BigBird 이상의 점수를 내었기 때문에, 더 발전할 가능성이 남아 있다고 Longformer 측에선 이야기하고 있습니다. (두 모델 측이 서로를 조금 의식하고 있지 않나 싶네요 :D)
3. 유사 모델, 파생 모델
3.1. PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
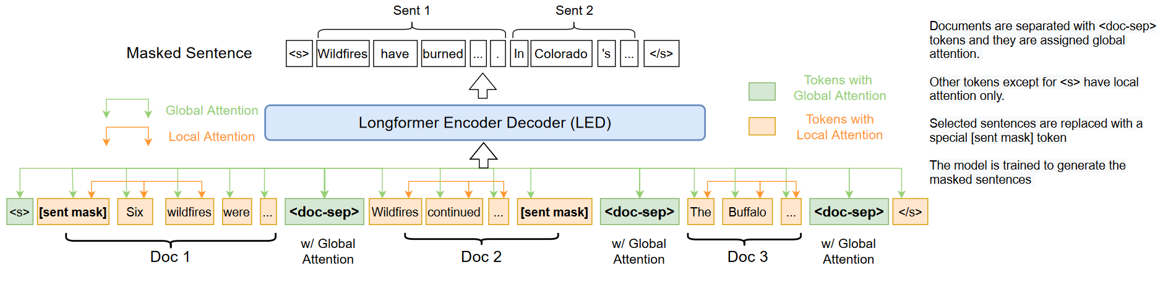
PRIMERA는 여러 문서들을 하나로 묶어 요약하는 과제인 Multi-Document Summarization을 수행하기 위해 특화된 사전학습 모델입니다. 이 모델의 기반 구조에는 앞서 언급드린 LED 모델이 적용되었습니다. 그림에서 보실 수 있듯이, 여러 문서를 하나로 이어 모델에 입력함으로써 요약문을 생성하도록 합니다. 문서가 여러 개라면 그 길이가 만만하지 않을 테니, 이야말로 긴 글을 처리할 수 있는 모델의 적절한 활용 사례라고 생각할 수 있겠습니다.
3.2. LongT5: Efficient Text-to-Text Transformer for Long Sequences
T5 모델에 대해서 아시나요? Text-to-Text Transfer Transformer의 앞 글자가 전부 T라서 T5라고 하는데요, 어떤 NLP 과제이든 간에 입력과 출력이 항상 텍스트 형식이 되도록 학습된 모델입니다. 이 T5 모델에 ETC 모델(BigBird-ETC와 매우 유사한 모델입니다)의 원리를 적용하여 더 긴 텍스트에도 적용이 가능하도록 발전시킨 것이 LongT5가 되겠습니다.
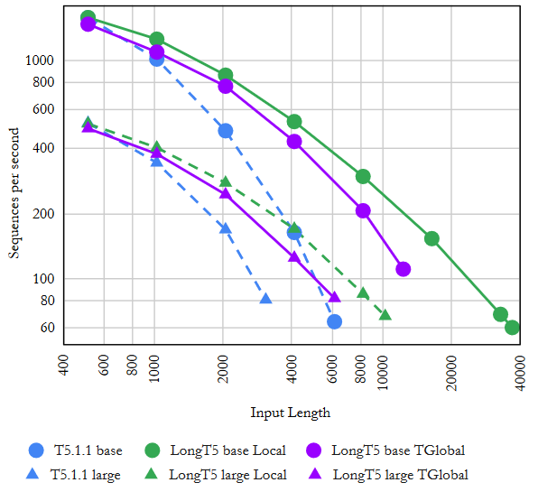
그래프에서 입력의 길이(가로 축)가 같을 때 초당 처리하는 문자열의 개수(세로 축)에서 차이가 나는 것을 관찰할 수 있죠. 파란색으로 표현되는 일반 T5모델보다 보라색, 초록색인 LongT5 모델이 더 빠른 속도를 가집니다. 입력 길이가 길면 길어질수록 그 차이가 더 벌어지는 것까지 확인하실 수 있겠습니다.
3.3. GPT-3: Language Models are Few-Shot Learners
요즘 장안의 화제인 ChatGPT의 근간이 되는 거대 언어 모델이죠. 여러 NLP 과제에서 매우 뛰어난 성능을 보이는 것으로 알려져 있습니다. 이 GPT-3 모델은 그 성능만큼 모델 크기가 큰 것으로도 유명한데요, 이렇게 큰 모델을 학습할 때 Banded Sparse Attention Pattern을 활용한 것으로 논문에서 밝히고 있습니다. Longformer나 BigBird 모델을 이용한 것은 아니지만, 유사한 방식을 사용하고 있다는 점을 알아둘 만합니다.
 GPT-3 논문의 일부 발췌
GPT-3 논문의 일부 발췌
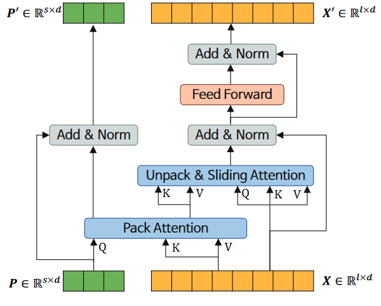
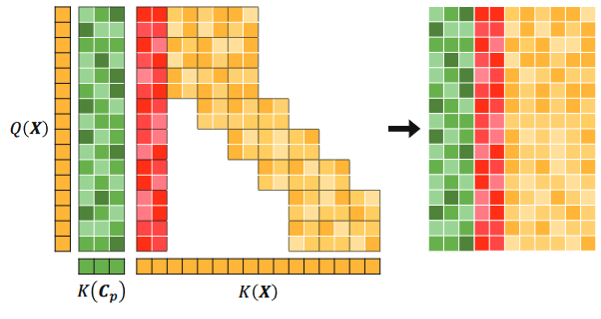
3.4. LittleBird: Efficient Faster & Longer Transformer for Question Answering
LittleBird는 카카오엔터프라이즈에서 개발한 언어 모델입니다. BigBird에 기반하되, ALiBi(Attention with Linear Biases), Pack-and-Unpack이라는 어텐션 방식을 적용하여 높은 성능은 보존하면서 속도와 메모리 면에서 개량된 모델이라고 하네요.
 |
 |
|---|---|
| LittleBird의 레이어 구조 | LittleBird의 Unpack & Sliding Window Attention 구조. (출처: 카카오엔터프라이즈) |
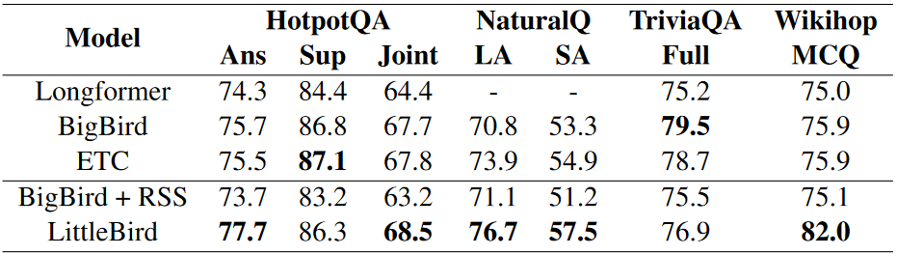
국내 기업에서 개발된 모델인 만큼 한국어에 대해서도 학습과 평가를 수행한 것이 특기할 만한 점입니다. 한국어 QA 데이터셋인 KorQuad 2.0의 챌린지에서 LittleBird-Large 모델이 SOTA를 차지하였고, 타 모델 대비 질문당 소요 시간을 낮추는 것에도 성공하였다고 하네요.
4. 결론
이번 포스트에서는 Longformer와 BigBird 모델이 실제로 가지는 성능에 관하여 알아보았습니다. 두 모델 모두 RoBERTa의 8배인 4096 길이의 입력을 처리할 수 있었고, 사전 학습 및 언어 모델 평가에서 RoBERTa 이상의 성능을 보여주었습니다. QA와 요약 두 과제에 대해서 집중적으로 평가가 이루어졌는데요, 자연어 처리 분야에 있는 더 많은 과제들에 대해서 평가를 수행해 보면 어떤 결과가 나올지 생각해 보는 것도 재미있을 것 같네요.
그리고 두 모델과 유사한 구조를 갖고 있거나, 두 모델로부터 파생되어 나온 언어 모델들에 대해서도 간략하게 소개드렸습니다. 소개드린 모델들 모두 높은 성능이나 빠른 속도, 혹은 둘 다를 확보하는 데에 성공하였죠. 희소 어텐션이라는 핵심을 기반으로 정말 여러 가지 방안과 활용의 시도가 가능한 것 같습니다. 앞으로도 이런 우수한 모델이 많이 쏟아져 나올 것을 기대해 볼 수 있지 않을까요?
긴 글을 위한 트랜스포머 모델 2편도 여기서 끝을 맺습니다. 두 편에 걸쳐 글을 쓰는 내내, 블로그를 꾸준히 운영하고 계시는 분들이 정말 대단하다는 생각이 들었네요…ㅎㅎ 많이 부족한 글이겠지만 독자 분들이 얻어가시는 게 하나라도 있다면 정말 기쁘겠습니다. 저는 다음에 기회가 된다면 더 재미있는 포스트로 다시 돌아오겠습니다. 그 동안 다른 분들이 열심히 작성해 주신 글들도 많은 사랑 부탁드리겠습니다. 감사합니다!
References
- I Beltagy et al., Longformer: The Long-Document Transformer, 2020.
- M Zaheer et al., Big Bird: Transformers for Longer Sequences, 2020.
- W Xiao et al., PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization, 2021.
- M Guo et al., LongT5: Efficient Text-To-Text Transformer for Long Sequences, 2021.
- TB Brown et al., Language Models are Few-Shot Learners, 2020.
- M Lee et al., LittleBird: Efficient Faster & Longer Transformer for Question Answering, 2022.
- https://tech.kakaoenterprise.com/144
- https://medium.com/deep-learning-reviews/big-bird-transformers-for-longer-sequences-paper-review-63f722c431e1
- https://huggingface.co/blog/big-bird
- https://ai.googleblog.com/2021/03/constructing-transformers-for-longer.html
