
- Intro
- Data Bias
- Gender Pronoun Resolution & Gender Bias
- Gender Bias Evaluation: Sterotype and Skew
- Never Too Late to Learn: Regularizing Gender Bias in Coreference Resolution (WSDM 2023)
- Conclusion
- References
Intro
최근 들어 OpenAI의 ChatGPT나 Google의 BARD와 같은 언어모델들이 초미의 관심사로 자리 잡았습니다. ChatGPT의 경우, 틱톡보다도 더 빠른 추세로 사용자를 끌어모았다고 하죠. OpenAI ChatGPT에게 몇 마디를 툭툭 던져보면, 마치 영화 ‘아이언맨’에 나오던 인공지능 어시스턴트 ‘자비스’가 생각날 정도입니다. 어떻게 이런 언어모델들이 인간이라도 된 것처럼 훌륭한 답변을 생성할 수 있을까요? 그 답은 ‘데이터’에 있습니다. 깡통에 불과하던 기계가 사람들이 작성해놓은 수많은 텍스트 데이터를 기반으로 딥러닝 학습을 거치게 되면서 사람을 모방할 수 있게 됩니다. 실제로 기계가 ‘생각’을 해서 답을 내놓는 게 아니라 학습한 데이터를 통해 확률적으로 그럴 듯한 답변을 생성할 수 있게 된다는 것이죠.
그저 수많은 텍스트와 가용할 수 있는 GPU만 있으면 훌륭한 언어모델을 만들어낼 수 있는 걸까요? 결론부터 말씀 드리자면, 맞기도 하고 아니기도 합니다. 단순히 사람 마냥 말을 잘하는 언어모델을 만드는 게 목표라면, 무지막지한 양의 데이터를 모델에 입력하고 아무런 제재 없이 학습 시키더라도 큰 문제가 발생하지 않을 겁니다. 하지만 한 언어모델이 사람을 평가하는 툴이나 실생활에 자주 활용되는 기술로써 사용된다고 상상해보세요. 언어모델이 어떤 사람이 특정 성별이나 인종이라는 이유로 그 사람을 높게/낮게 평가하거나 모델이 비윤리적인 의도의 말들을 필터링 없이 하게 될 경우, 아무리 뛰어난 화법을 구사하더라도 그 언어모델을 사용하는 건 쉽지 않은 선택이 될 겁니다. 실제로 2021년에 챗봇 ‘이루다’가 장애인, 성소수자, 임산부 등 특정 집단에 대한 혐오 발언을 해서 논란이 된 적도 있었구요.
그렇다 보니 최근 들어 ‘인공지능과 윤리’라는 주제가 더욱 중요해지고 있는데요. 오늘은 제가 올해 WSDM 2023에 발표한 논문 “Never Too Late to Learn: Regularizing Gender Bias in Coreference Resolution”에 대해 소개해드리려 합니다. 학습과정 동안 언어모델 내 성별 편향을 제거하기 위한 방법론을 제시하는 논문입니다. 본격적으로 논문 이야기를 시작하기에 앞서, 성별 편향과 관련된 주요 개념들과 태스크에 대해 짚고 넘어가도록 할게요.
Data Bias
언어모델들의 대다수는 위키피디아(위키백과)를 비롯한 거대 말뭉치들을 기반으로 사전학습 (Pre-training)됩니다. 대용량 말뭉치를 ‘사전’학습하여 얻게 된 기초적인 언어능력을 토대로, 타겟 데이터에 맞춰 미세조정 (Fine-tuning)하는 학습 과정을 거치고 나면 사용자의 니즈에 맞는 언어모델을 구축할 수 있게 됩니다. 그리고 여기서 아주 근본적인 문제가 발생하게 되는데, 바로 ‘데이터 편향 (Data Bias)’ 문제입니다. 사람들이 작성한 글들이 모두 윤리적으로 올바를까요? 내용은 둘째치고, 데이터가 구성된 비율은 균등할까요? 남성, 여성, 퀴어, 백인, 아시아인, 흑인 등 수많은 사회적 집단에 대해 동일한 비율로 구성된 데이터를 사용할 수 있는 걸까요? 실제로 이전 연구들에 따르면 사전학습 시 사용된 대다수의 데이터가 특정 집단에 편향되어 있다는 문제가 많이 제기되어 왔습니다. 언어모델을 사전학습 시킬 때 가장 많이 사용되는 데이터셋인 위키피디아 내 여성 인물의 비중은 15.5%에 불과하다고 합니다.
그럼 학습 데이터 분포를 조금 조정하면 되는 거 아니냐고 질문을 던지실 수도 있을 것 같습니다. 직접 모델을 처음부터 사전학습 시킬 수 있는 환경이 아니라면, 보통 구글이나 OpenAI 같은 거대 테크 컴퍼니에서 공개한 사전학습 언어모델을 다운받아서 사용하게 되는데요. 사전학습을 시킬 당시에 이미 편향된 데이터를 사용했다보니, 자연스레 언어모델은 그 편향을 학습하고 재생산해내는 굴레에 빠지게 됩니다. 미세조정을 하기도 전에 이미 모델이 편향을 지니고 있는 상태인거죠.
일반적인 개발자가 기학습된 사전학습 언어모델을 조정하기란 여간 쉬운 일이 아닙니다. 하지만 편향된 게 뻔히 보이는 모델을 그대로 사용하기에도 리스크가 크고요. 그렇기 때문에 미세조정 단계에서 모델의 편향을 조정하는 Debiasing 기법들이 최근 들어 더욱 많이 제안되고 있습니다. 편향과 불평등을 논할 수 있는 수많은 주제가 있겠지만 이 글에서는 젠더 편향성에 중점을 두고 설명을 드리고자 합니다. 앞서 말씀 드렸듯 보편적으로 사용되는 데이터셋들은 보통 남성 위주의 예제로 구성되어 있고, 데이터 내용을 들여다 보았을 때도 기존의 성관념이 투영된 경우가 많다고 합니다. 그런 데이터들을 가지고 모델을 학습하게 되면 성차별적인 특성을 내재한 모델이 만들어지게 될 가능성이 아무래도 높을 수밖에 없을 겁니다.
Gender Pronoun Resolution & Gender Bias
[예시 1: Gender Pronoun Resolution]
“[MASK] is a doctor and has a high salary.” ([MASK]는 의사이고 급여가 많다) → “He”? “She”?
다수의 기존 논문들에서는 상호참조 (Coreference Resolution) 태스크 중 성별 대명사를 예측하는 Gender Pronoun Resolution (GPR) 태스크로 학습과 평가를 진행해 왔습니다. 빈 칸이 뚫려있는 문장에서 빈 칸에 대한 적절한 성별 대명사를 예측해야 하는 태스크로, 쉽게 말해 ‘He’, ‘She’, ‘Him’, ‘Her’과 같은 대명사들을 올바르게 예측하는 작업입니다. 특정 문맥이 있는 상황에서 대명사를 예측하는 것이라면, 정답 대명사 (Ground-truth Pronoun)가 일반적으로 존재합니다. [예시 1]과 같은 단일 문장만 주어졌을 때라면, 정답이 없는 상황이기 때문에 남성형 대명사와 여성형 대명사를 엇비슷한 확률로 예측해야 하는 게 맞을 겁니다. 아무런 문맥이 주어지지 않았으니 모델도 공평하게 대명사를 예측해야 하는 게 맞지 않을까요? 하지만 다수의 언어모델들은 그렇지 않다고 합니다. 아래 번역 시스템 예시들만 봐도 좀 더 와닿으실 텐데요. “얘는 의사야”나 “얘는 간호사야”라고 입력했을 때 직업만 바뀌었을 뿐인데도 “얘”가 각각 “He”와 “She”로 다르게 번역됩니다. “얘는 의사고, 쟤는 간호사야”의 경우, 모두 “He”로 바뀌어 “He’s a doctor, he’s a nurse”로 번역되는 것을 볼 수 있습니다.
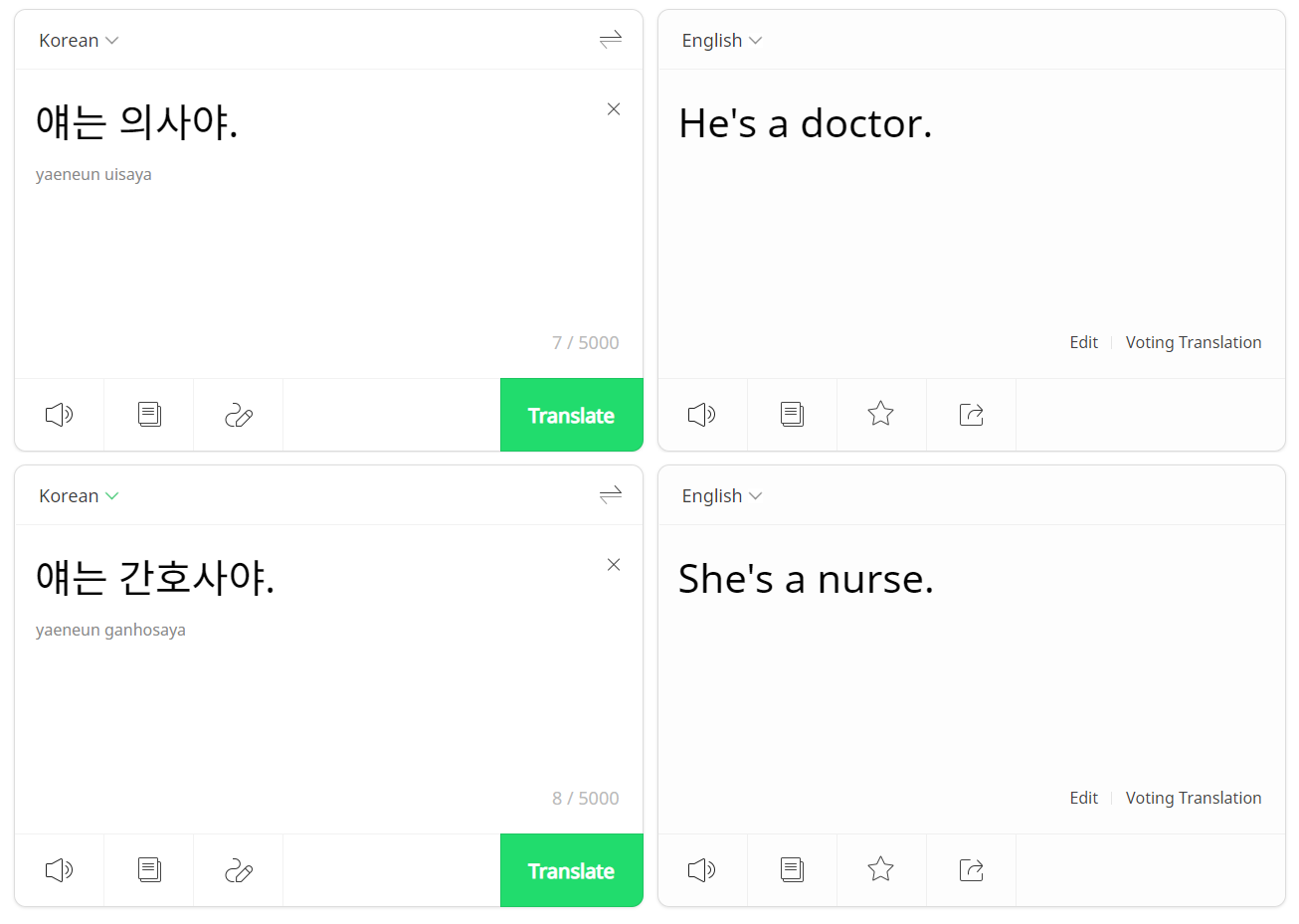 [예시 2: 성적 고정관념에 따라 번역된 대명사가 바뀌는 경우]
“얘는 의사야” → “He’s a doctor”
“얘는 간호사야” → “She’s a nurse”
[예시 2: 성적 고정관념에 따라 번역된 대명사가 바뀌는 경우]
“얘는 의사야” → “He’s a doctor”
“얘는 간호사야” → “She’s a nurse”
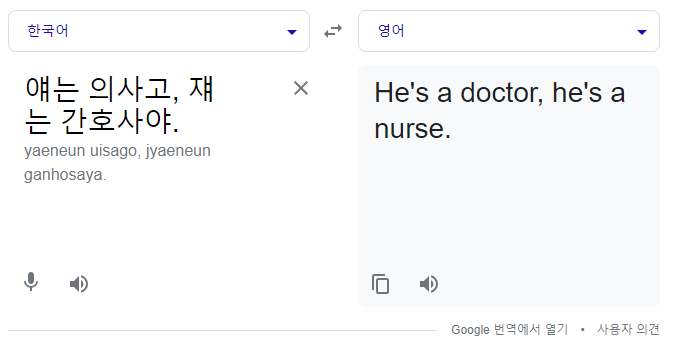 [예시 3: 모두 남성형 대명사로 바뀌는 경우]
“얘는 의사고, 쟤는 간호사야” → “He’s a doctor, he’s a nurse”
[예시 3: 모두 남성형 대명사로 바뀌는 경우]
“얘는 의사고, 쟤는 간호사야” → “He’s a doctor, he’s a nurse”
언어모델의 성편향을 세부적으로 정량화하고 분석하기 위해 ‘Pro-stererotypical’과 ‘Anti-stereotypical’ 개념을 사용하게 되는데요. ‘Pro-stereotypical’은 모델의 행동이 실제 세상의 인식(선입견)과 일치할 때를 말하고, ‘Anti-stereotypical’은 일반적인 편견을 따르지 않는 경우를 의미합니다. ‘doctor (의사)’라는 단어는 흔히 남성의 직업으로 간주되므로, Male Pro-stereotypical이자 Female Anti-stereotypical한 직업으로 생각할 수 있는 거죠. 모델이 실제 정답이 있는 문장에서는 답을 잘 맞출 수 있는 것과는 별개로 특정 성별에 대해 Pro/Anti-stereotypical한 단어들이 존재하는 단일 문장 내에서 남녀 대명사를 균등하게 예측할 수 있도록 만드는 것이 주요 목적입니다.
 [예시 4: Pro-stereotypical vs. Anti-stereotypical]
[예시 4: Pro-stereotypical vs. Anti-stereotypical]
Gender Bias Evaluation: Sterotype and Skew
‘편향’이라는 개념을 정량화하고 평가 방법을 정하는 것은 윤리적 인공지능을 구축할 때 학습 방법만큼이나 중요한 안건인데요. 편향된 모델들에게서 흔히 발견할 수 있는 두 가지 문제로 ‘고정관념 (Stereotype)’과 ‘치우침 (Skew)’ 문제가 있습니다. 일반적인 언어모델에게 [예시 1]의 [MASK] 토큰을 예측하게 하면 높은 확률로 ‘He’를 선택할 가능성이 높다고 하네요. 의사라는 직업이 ‘남성’ 위주의 직업이라는 고정관념을 학습했거나, 사전학습 데이터 내 남성 관련 텍스트가 훨씬 많았기 때문에 ‘He’로 치우친 예측 결과들이 나오게 되는 거죠. 이러한 모델의 경향성을 측정하기 위하여 일반적으로 F1-score 기반의 평가방법을 많이 사용합니다. ‘고정관념’은 pro-stereotypical 단어들과 anti-stereotypical 단어 간의 정확도가 얼마나 차이나는지로, ‘치우침’은 각 성별 별로 정확도가 얼마나 상이한지로 측정하게 됩니다
\[\mu_{stereo} = \frac{1}{2}(|F1_{pro}^{male}-F1_{anti}^{male}| + |F1_{pro}^{female}-F1_{anti}^{female}|)\]\(F1_{pro}^{male}\)은 남성 pro-stereotypical 단어(e.g., 의사)가 있는 문장에 정답이 남성형 대명사라고 가정했을 때 모델이 얻는 성능이고, \(F1_{anti}^{male}\)는 남성 anti-stereotype 단어(e.g., 간호사)이 있는 문장에 정답이 남성형 대명사라고 가정했을 때 얻는 성능입니다. 그 차이가 커질 수록 \(\mu_{stereo}\) 값이 커지게 되죠.
\[\mu_{skew} = \frac{1}{2}(|F1_{pro}^{male}-F1_{pro}^{female}| + |F1_{anti}^{male}-F1_{anti}^{female}|)\]\(\frac{1}{2}(\vert F1_{pro}^{male}-F1_{pro}^{female} \vert\)의 경우, 각 성별에 대한 pro-sterotypical 단어들 간의 정확도 차이를 예측합니다. \(F1_{pro}^{male}\)는 남성형 대명사가 정답이라고 가정했을 때 남성 pro-stereotypical 단어에 대한 정확도이고, \(F1_{pro}^{female}\)은 여성형 대명사가 정답이라고 가정했을 때 여성 pro-stereotypical 단어에 대한 정확도입니다. 즉, pro/anti-stereotypical 단어들에 대하여 성별 간 정확도 차이가 나는지 측정하여 특정 성별로 모델의 예측값이 치우쳐 있는지 계산하겠다는 것입니다.
기존의 Debiasing 방법론들의 경우, 일반적으로 데이터 증강 (Data Augmentation) 기법을 사용해 문제를 해결하고자 했습니다. “미세조정 때 사용하는 데이터라도 남녀 비율이 균등하도록 구성하고 모델을 학습하면 되지 않을까?”라고 생각한 겁니다. 아니면 별도의 후처리 방법을 도입해서 확률을 보정하는 방법도 있었습니다. 기존 방법론들을 사용했을 때 언어모델이 가지고 있는 ‘치우침’ (\(\mu_{skew}\)) 은 많이 해소되는 경향을 보였지만, ‘고정관념’(\(\mu_{stereo}\))은 여전히 해결되지 않은 문제로 남았습니다. 그리고 증강된 학습 데이터로 모델을 학습시켰을 때 모델의 언어이해능력 (Natural Language Understanding)이 저하되는 현상도 보였고요. 단순히 데이터를 변형하거나 기학습된 모델의 결과값만을 조정하는 걸로는 충분하지 않다는 겁니다.
[예시 5: 데이터 증강]
“The god of our fathers chose you long ago to know his plan.” (Original) → “The goddess of our mothers chose you long ago to know her plan.” (Reversed)
Never Too Late to Learn: Regularizing Gender Bias in Coreference Resolution (WSDM 2023)
올해 2월 WSDM (Web Search and Data Mining) 학회에 발표된 논문 ‘Never Too Late to Learn: Regularizing Gender Bias in Coreference Resolution’은 고정관념 문제와 언어이해능력이 저하되는 현상을 개선하기 위한 학습 방법을 새롭게 제안하였습니다. 모델 데이터 전처리나 결과값을 보정하는 것도 중요하지만, 언어모델 자체의 편향성을 제거할 수 있도록 학습 과정을 조정할 필요도 있다는 거죠. 해당 논문에서는 데이터 증강을 통해 특정 성별에 치우친 모델을 조정하고, 새로운 두 가지 기법으로 1) ‘고정관념’과 2) ‘성능 저하’ 이슈를 해결하고자 합니다. 흔히 사용되는 Masked Language Modeling (MLM) 태스크 기반의 손실함수에 편향과 관련된 제약을 줄 수 있는 페널티 텀을 추가하여 학습을 진행합니다. 가장 기본적인 형태의 손실함수 \(L_{MLM}\)은 [MASK] 토큰이 어떤 성별 대명사를 가리키고 있는지 예측하도록 만듭니다.
\[\mathcal{L}_{MLM} = \frac{1}{|M|}\sum_{m\in masked}^{M} CE(W \cdot h_m, x_m)\]Stereotype Neutralization (SN)
편향을 제거하기 위해 사용하는 첫 번째 방법은 Stereotype Neutralization (SN) 입니다. ‘의사’, ‘간호사’, ‘비서’, ‘CEO’와 같은 단어들은 특정 성별의 색깔을 띄면 안되겠지만, 단어 자체적으로 성별 특성을 내재하고 있는 경우들이 있습니다. ‘아빠’나 ‘엄마’ 같은 단어들처럼요. 편향이 제거되어야 하는 성중립적인 단어들과 성별 특성이 존재하는 단어들의 벡터 간 거리가 멀어지도록 만들어주면 모델이 가지고 있는 성별에 대한 고정관념을 어느 정도 지워낼 수 있지 않을까요? 그 아이디어에 기반해 논문에서는 두 종류의 단어들이 구별될 수 있도록 직교화(orthogonalization) 기반의 정규화 텀을 기존의 손실함수에 추가하여 미세조정을 진행하게 됩니다. 미세조정을 하기 전에 성별 특성이 존재하는 단어들의 임베딩을 기반으로 성별 고유 벡터 (Gender Directional Vector)를 정의하고, 미세조정 단계 동안 고정관념이 있는 단어들과 해당 벡터의 내적 값을 0으로 만드는 방향으로 학습을 진행합니다.
- \(v_{gs} = \frac{1}{\vert\Omega\vert}\sum_{(w_f, w_m)\in \Omega}^{} (E(w_m) - E(w_f))\) : 남녀 성별 고유 단어들 간의 임베딩 차이를 기반으로 벡터 \(v_{gs}\)를 만듭니다.
- \(v_{gd}\) : \(v_{gs}\)를 그대로 사용했을 때 트랜스포머 구조 모델의 학습이 안정적이지 못할 수 있으므로 정규화한 벡터 \(v_{gd}\)를 성별 대표 벡터로 사용합니다.
- \(\mathcal{R}_{SN}\) : 편향을 제거하고자 하는 단어군 (해당 논문에서는 성별 고정관념이 존재하는 직업 단어들)의 임베딩과 성별 대표 벡터 의 내적이 0이 되도록 하는 만드는 페널티 텀을 추가합니다.
직교화는 각각의 단어 벡터가 서로 수직이 되도록 만들어서, 두 벡터 간 거리가 멀어지도록 만들어줍니다. 서로 다른 성향의 단어들이 벡터 상으로 구별될 수 있도록 그 단어 간의 관계를 없애는 방법이라고 생각해주시면 될 것 같아요. 이 정규화 텀을 가지고 학습을 거치고 나면 SN기반의 모델은 기존의 사전학습 언어모델들과는 달리 특정 단어들에 대한 편향성을 상대적으로 덜 가지고 있는 상태가 됩니다.
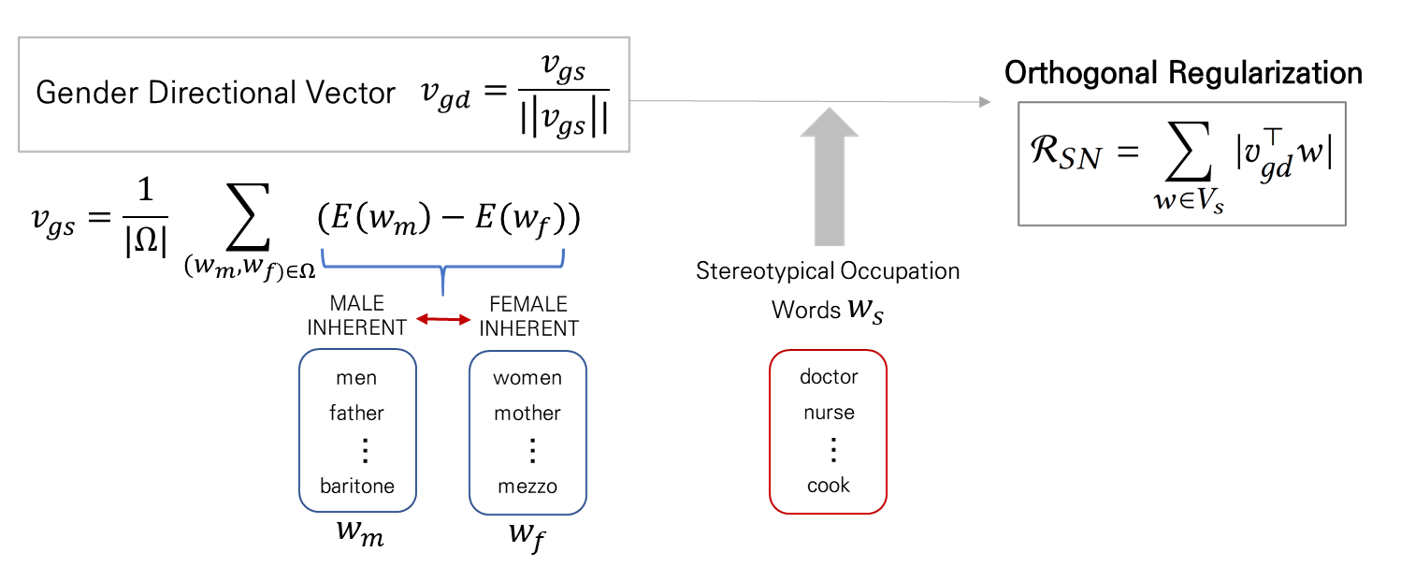 [Stereotype Neutralization 개요]
[Stereotype Neutralization 개요]
Elastic Weight Consolidation (EWC)
SN이 고정관념 문제를 해소하고자 했다면, Elastic Weight Consolidation (EWC)은 데이터 증강 환경에서 학습된 모델이 보이는 성능 저하 문제를 위해 제안된 방법입니다. EWC는 일반적으로 여러 데이터나 태스크에서 재학습되는 모델이 이전에 학습한 내용을 잊지 않게 할 때 많이 사용하는 방법론인데요. 해당 논문에서는 모델의 중요 파라미터 정보를 담고있는 Fisher Information 기반의 EWC 정규화 텀을 손실함수에 추가하여 사용합니다. 기존의 사전학습 언어모델이 가지고 있는 주요 파라미터 값들을 참고하면서 학습을 진행한다면 증강된 데이터 기반으로 학습되고 있는 모델의 성능이 덜 떨어질 것이라는 건데요. 예를 들어 BERT 모델의 편향을 제거하는 태스크라면, 일반적인 BERT 모델 내 파라미터 별 중요도를 계산해서 주요 파라미터들은 최대한 유지하는 방향으로 학습을 진행하겠다는 것입니다. 언어모델이 사전학습 과정을 거치면서 습득한 뛰어난 언어이해능력을 유지할 수 있도록 학습에 제한을 두는 겁니다. 아무리 편향 제거가 잘 되었더라도 언어능력이 훼손된다면 결국 언어모델로써 가치가 떨어지는 거니까요.
\[F_j = \mathbb{E}[\nabla^2\mathcal{L}_{MLM}(\theta_j^o)]\]여기서 \(j\)는 사전학습 언어모델의 \(j\)번째 레이어를, \(F_j\)는 해당 레이어의 Fisher Information을 의미합니다.
\[\mathcal{R}_{EWC} = \lambda\sum_j{F_j(\theta_j-\theta_j^o)^2}\]\(F_j\)를 토대로, debiasing 하고자 하는 모델의 파라미터 \(\theta_j\)와 기존 언어모델 파라미터 \(\theta_j^o\)의 차이를 반영하여 모델을 업데이트 합니다.
ASE: Augmentation + SN + EWC
두 개의 페널티 텀을 합한 최종 손실함수를 통해 기존 방법론들의 단점을 보완하는 하나의 모델을 만들게 됩니다.
\[\mathcal{L}_{ASE} = \mathcal{L}_{MLM} + \mathcal{R}_{SN} + \mathcal{R}_{EWC}\]Stereotype Quantification (SQ) Score
해당 논문에서는 F1-score 기반의 평가지표의 단점을 보완하기 위하여 확률 기반의 평가지표를 추가적으로 제안합니다. F1-score은 모델이 맞게/틀리게 예측했는지를 중심으로 측정하게 되는데, 동일한 예측 결과이더라도 99%의 확률로 답을 결정하는 것과 51%의 확률로 선택을 하는 건 차이가 있기 때문입니다. Stereotype Quantification (SQ) Score은 prostereotypical한 성별 단어들이 각각 어떤 성별대명사를 예측하는지에 대한 확률 값 간의 분산을 구하게 됩니다. 문맥이 없는 단일 문장에서 모델이 [MASK] 토큰에 대해 엇비슷한 확률로 대명사를 예측한다면 모델이 가지고 있는 고정관념이 작은 편이라고 볼 수 있습니다.
\[SQ = \frac{1}{|J|}\sum_{j\in{J}}Var_{m,f}(\log p)\]식의 \(𝐽\)는 직업군 단어 집합을 의미하며, 남/녀 성별에 대해 prostereotypical한 직업 단어들 간의 분산을 계산해 SQ 스코어를 얻게 됩니다.
Results (Debiasing and GPR)
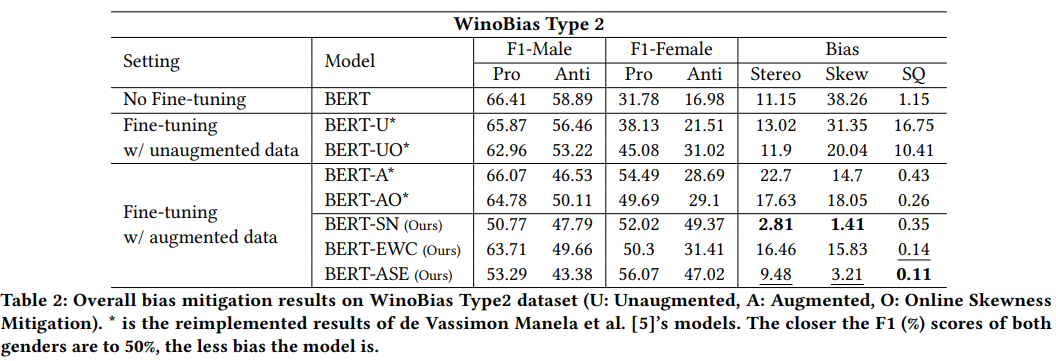
실험은 사전학습 언어모델 중 BERT (Bidirectional Encoder Representations from Transformers)를 사용했는데요. ‘Stereo’, ‘Skew’, ‘SQ’ 모두 값이 작을 수록 편향이 없다는 것을 의미합니다. WinoBias 데이터셋에서 평가를 진행해 본 결과([표 1])를 보면, SN과 EWC 방법을 도입하여 학습한 모델(BERT-ASE)이 기존 모델들(BERT, BERT-U/UO, BERT-A/AO)에 비해 모든 평가지표에서 효과적으로 개선되었습니다. BERT-AO와 비교해보았을 때 Stereo -8.15 / Skew -14.83 / SQ -0.15 의 개선을 보이는 것을 확인할 수 있죠. 가장 흔히 사용되던 데이터 증강 기법의 효용 역시 확인할 수 있었는데요. SQ Score 결과를 보았을 때, 데이터 증강 기법 유무에 따라 모델 간 SQ Score 편차가 굉장히 크다는 점에서 균형 잡힌 학습 데이터셋의 필요성을 알 수 있습니다. 일반적인 NLU 성능을 보기 위해 진행한 GPR Baseline 평가([표 2])에서는 방법론마다 조금씩 차이를 보이기는 하지만, BERT-ASE의 경우 데이터 증강 모델들 중 우수한 성능을 보여주는 편입니다.
 [표 1: 데이터 편향 측정 태스크(대명사 정답 없는 경우)]
“The developer argued with the designer and slapped [MASK] in the face.”
[표 1: 데이터 편향 측정 태스크(대명사 정답 없는 경우)]
“The developer argued with the designer and slapped [MASK] in the face.”
 [표 2: NLU 성능 측정 태스크 예시 (대명사 정답 있는 경우)]
“The woman argued with the man and slapped [MASK] in the face.”
[표 2: NLU 성능 측정 태스크 예시 (대명사 정답 있는 경우)]
“The woman argued with the man and slapped [MASK] in the face.”
Analysis
정성적인 분석 결과도 흥미롭습니다. “[MASK] is a doctor and has a high salary” ([MASK]는 의사이고 급여가 많다) 라는 문장에서 BERT (bert-base-uncased)의 예측 단어 분포를 보면 남성 중심의 이름이 주로 등장하는 반면, BERT-ASE는 ‘It’이나 ‘They’ 같이 중립적인 단어들을 더 높은 순위에 올려두는 것을 볼 수 있습니다. “[MASK] is a nurse and does housework after work. ([MASK]는 간호사이고 일이 끝난 후 집안일을 한다) 의 예시에서는 더 뚜렷하게 차이를 보이는데요. 남녀 대명사를 거의 공평하게 예측하는 BERT-ASE와 달리, 기존 BERT 모델은 ‘She’와 여성 이름으로 치우치는 경향을 보입니다. 임베딩을 시각화 해보았을 때도 BERT-ASE가 BERT에 비해 남성/여성 고정관념이 강한 직업군의 임베딩 간 거리가 비교적 줄어든 것을 확인할 수 있습니다.
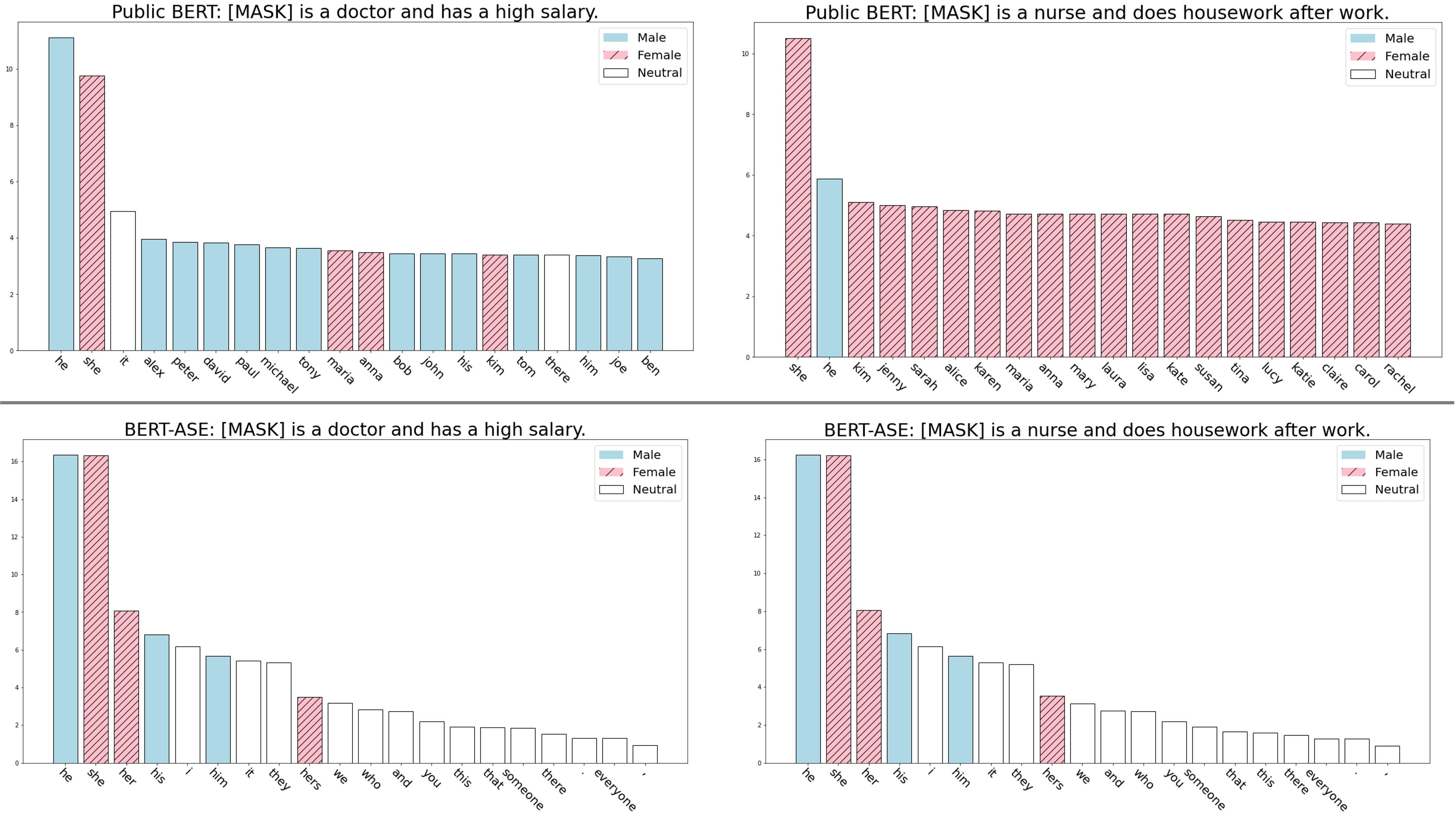 [Mask Token Visualization]
[Mask Token Visualization]
 [Embedding Visualization - PCA, GMM Clustering]
[Embedding Visualization - PCA, GMM Clustering]
Conclusion
방금 소개해드린 논문은 기존의 학습 패러다임에서 크게 벗어나지 않는 선에서 편향을 제거하는 단편적인 방법론을 제시하고 있습니다. 일반적인 이해 태스크에서 여전히 기존 언어모델만큼의 성능을 보이지 못하고 있고, 바이너리 젠더 (남/여)나 직업 단어 위주로만 방법론 검증이 되었다는 점에서 앞으로 확장되어야 할 부분도 많은데요. 언어모델과 ‘자연어처리’라는 분야에 대한 관심이 더 커져가는 만큼, 어떤 식으로 ‘윤리적인’ 언어모델을 구성할지에 대한 본격적인 사회적 논의가 진행되어야 하지 않을까요? 아무리 모델이 말을 자연스럽게 잘하더라도 어떤 성별, 직업, 인종 등에 대해 배타적인 인공지능이 사회에 배포되는 건 위험한 일이니까요. 모델이 마법 같이 생성해내는 화려한 텍스트 속에 숨겨진 편견을 가려내고 없애는 방법들이 더욱 중요해질 것 같습니다.
References
-
SunYoung Park, Kyuri Choi, Haeun Yu, and Youngjoong Ko. 2023. Never Too Late to Learn: Regularizing Gender Bias in Coreference Resolution. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining (WSDM ‘23). Association for Computing Machinery, New York, NY, USA, 15–23. https://doi.org/10.1145/3539597.3570473
-
Eduardo Graells-Garrido, Mounia Lalmas, and Filippo Menczer. 2015. First women, second sex: Gender bias in Wikipedia. In Proceedings of the 26th ACM conference on hypertext & social media. 165–174. https://aclanthology.org/W19-3821/
-
Daniel de Vassimon Manela, David Errington, Thomas Fisher, Boris van Breugel, and Pasquale Minervini. 2021. Stereotype and Skew: Quantifying Gender Bias in Pre-trained and Fine-tuned Language Models. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. Association for Computational Linguistics, Online, 2232–2242. https://doi.org/10.18653/v1/2021.eacl-main.190
-
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. 2016. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In Advances in Neural Information Processing Systems, D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett (Eds.), Vol. 29. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2016/file/a486cd07e4ac3d270571622f4f316ec5-Paper.pdf
-
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Ryan Cotterell, Vicente Ordonez, and Kai-Wei Chang. 2019. Gender Bias in Contextualized Word Embeddings. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 629–634. https://doi.org/10.18653/v1/N19-1064
-
Masahiro Kaneko and Danushka Bollegala. 2019. Gender-preserving Debiasing for Pre-trained Word Embeddings. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 1641–1650. https://doi.org/10.18653/v1/P19-1160
-
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences 114, 13 (2017), 3521–3526.
-
Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. 2018. Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Association for Computational Linguistics, New Orleans, Louisiana, 15–20. https://doi.org/10.18653/v1/N18-2003
-
“AI 편향·혐오 발언 ‘이루다’만이 아니다…MS·아마존도 겪었던 문제”, 머니투데이, 2021.01.15, https://news.mt.co.kr/mtview.php?no=2021011509420589059
-
“AI 챗봇 ‘이루다’, 개인정보유출 논란 속 결국 사실상 폐기”, 조선일보, 2021.01.15, https://biz.chosun.com/site/data/html_dir/2021/01/15/2021011501141.html?utm_source=naver&utm_medium=original&utm_campaign=biz
