
소개
자연어처리(Natural Language Processing) 분야에서 요약(Summarization) Task는 알게 모르게 우리의 실생활에서 접하고 많이 사용하는 것을 볼 수 있습니다. Figure 1. 의 예시 그림처럼 뉴스 기사에 대한 요약문1 과 최근에 Microsoft 공개한 Bing AI 검색2 에서 제공하고 있는 서비스에서도 요약문이 활용3되고 있습니다.
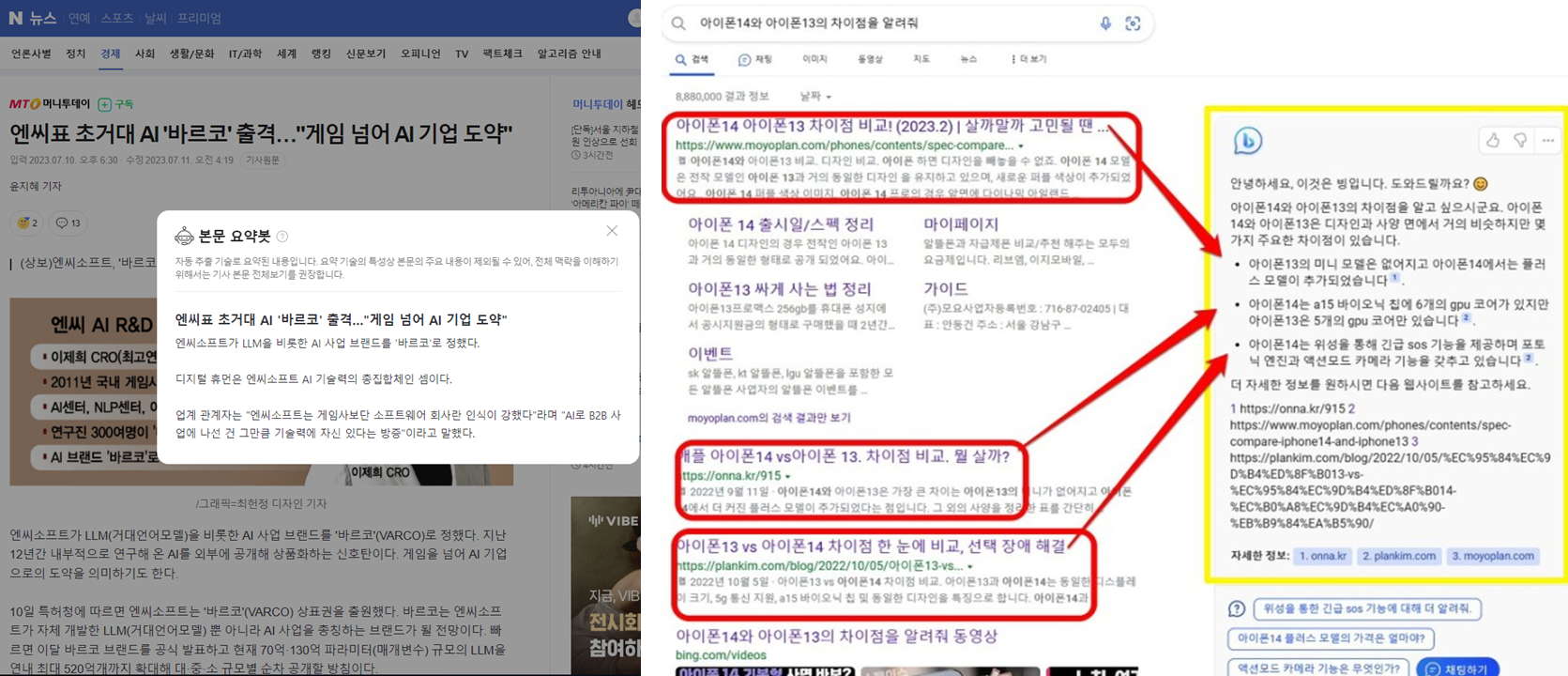 Figure 1. 실제 서비스에서 제공되고 있는 요약 예시
Figure 1. 실제 서비스에서 제공되고 있는 요약 예시
그렇다면 요약은 어떻게 정의할 수 있을까요? 아래의 글들은 텍스트 요약 논문들 중에서 요약에 대해 정의 내리는 부분을 발췌했습니다.
A text that is produced from one or more texts, that conveys important information in the original text(s), and that is no longer than half of the original text(s) and usually, significantly less than that.4
Text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning of the original documents.5
정리해서 얘기하면 요약은 다음과 같이 크게 2가지 의미를 나타냅니다.
- 이해하기 쉬우면서도 핵심적인 의미를 포함되어 있어야 한다.
- 간결하고 짧은 형태로 변환시키는 작업이다.
Figure 2. 그림처럼 Sizov Gleb., 20106은 요약 문서의 양, 요약의 방식, 목적, 외부 리소스 사용 여부 등 요약에 대해 크게 4가지로 분류하였으며 포스트에서는 빨간색 네모칸으로 표시되어 있는 유형들에 대해 소개를 드리겠습니다.
 Figure 2. 요약 유형의 세부 분류
Figure 2. 요약 유형의 세부 분류
chatGPT의 궁금증 때문에 자연어처리에 찾아보시거나 일생생활에서도 요약에 대해서 많이 접해보셨을텐데요. 요약은 일반적으로 추출요약(Extractive Summarization)과 추상요약(Abstractive Summarization) 2가지 방식으로 사용되고 있으며 Figure 3. 은 같은 Text에 대해 각 방식에 따라 결과를 보여주는 예시입니다.
Figure 3.7 의 결과처럼 추출요약은 문서 내에 있는 원본 문장을 추출하여 요약으로 제공하는 방식으로 중요한 문장과 단어들을 그대로 추출하여 요약을 한다는 장점이 있지만 반대로 문서 내 문장이나 단어들을 그대로 추출하기 때문에 한정된 표현으로 요약문을 제공한다는 단점이 있습니다.
반대로, 추상요약은 문서 정보를 이용하여 문서 내에 없는 문장을 새로운 문장으로 생성하여 요약하는 방식입니다. 문서에 포함되어 있지 않은 새로운 문장을 생성하기 때문에 자연스러운 요약문을 생성한다는 장점이 있는 반면에 문맥에 맞지 않거나 특정단어를 반복적으로 생성한다거나 그럴듯하게 문장을 생성하는 hallucination(환각)을 보인다는 단점이 있습니다.
 Figure 3. 추출요약과 추상요약 예시
Figure 3. 추출요약과 추상요약 예시
hallucination(환각)은 chatGPT에서도 단점으로 지적되고 있는 부분인데요. 예를 들어, Figure 3. 의 Abstractive Summarization Output의 문장에서 “Huawei overtakes Samsung”을 “Samsung overtakes Huawei”와 같이 생성이 됐어도 입력 Text를 보고 확인하지 않았으면 틀리게 생성된 지 몰랐을겁니다. 이렇듯 hallucination(환각)은 그럴듯한 답변을 내놓고 정답인 것처럼 생성 하는 것을 의미합니다.
추출요약과 추상요약에 대해 간략히 설명을 드렸는데요. Figure 2. 에서 표시된 것들 중에서 먼저 다중 문서 요약(Multi-Document Summarization)의 SOTA(State-of-the-Art) 모델은 무엇이 있는지 같이 한번 보러 가겠습니다.
Multi-Document Summarization
다중 문서 요약(Multi-Document Summarization)은 여러 개의 문서를 요약하는 작업을 말합니다. 정의는 이렇게 간단히 말할 수 있지만, 실제로는 연구에 대한 어려움도 많습니다…
예를 들어, 여러 문서에서는 여러 의견과 주제가 포함되어 있기 때문에 하나의 일관성(Relevance)있는 요약문으로 생성하는 작업은 복잡하고 어려우며 중복되는 정보가 많기 때문에 중복 정보를 필터링하고 중요한 정보를 선택하는 것은 어렵습니다. 또한, 다른 Task들에 비해 공개된 데이터가 적어서 데이터를 구하는 것부터 어려운 일이었습니다.
최근들어, 다중 문서 요약에 대한 연구의 필요성이 점차 증가되고 데이터의 부족을 느끼면서 여러 논문들에서 기존에 있던 데이터를 가공하거나 새로운 데이터를 공개하는 경우도 많아졌지만 최근 몇 년전 까지만 해도 2005년에 공개된 데이터8를 이용해 평가 경우가 대부분이였습니다…
초기에는 News 데이터를 이용한 데이터들이 대부분이였지만 위키피디아, 과학, 의학 등 다양한 분야의 데이터도 점점 공개되고 있습니다. Figure 4. 은 각 많은 논문들에서 사용되고 있는 대표적인 데이터에 대해 간략히 정리하였으며 궁금하신 분들은 참고해서 보면 좋을 것 같습니다.
| Dataset | Domain | Task | 논문 |
|---|---|---|---|
| DUC2004 | News | Multi Document | Overview of DUC 20058 |
| Multi-News | News | Multi Document | Multi-News: a Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model9 |
| Wikisum | Wikipedia | Multi Document | Generating Wikipedia by Summarizing Long Sequences10 |
| WCEP | Wikipedia | Multi Document | A Large-Scale Multi-Document Summarization Dataset from the Wikipedia Current Events Portal11 |
| Multi-XScience | Science | Multi Document | Multi-XScience: A Large-scale Dataset for Extreme Multi-document Summarization of Scientific Articles12 |
| MS^2 | Medical | Multi Document | MS^2: Multi-Document Summarization of Medical Studies13 |
| CNN/DailyMail | News | Single Document | Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond14 |
| ArXiv | Science | Single Document | A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents15 |
Figure 4. Task별 대표적인 데이터셋
데이터에 대해서는 간략히 알아보았으니 모델에 대해 알아보도록 하겠습니다.
소개 시켜 드릴 논문은 PRIMERA16으로 2022년 ACL(Association for Computational Linguistics)에서 발표된 논문으로 제목이 약간 익숙하실 수 있을텐데요, 그 이유는 바로 이 전에 기재되었던 긴 글을 위한 트랜스포머 모델17에서 Longformer 모델의 활용 사례로 소개되었습니다.
또한, PRIMERA16 는 많은 부분을 PEGASUS18 모델에서 답습했습니다. 두 개의 모델에서 가장 큰 차이점은 입력되는 처리해야 하는 문서의 수, 기반이 되는 모델입니다. PEGASUS는 단일 문서 요약로 Transformer 모델을 기반으로 하고 있다면, PRIMERA는 Longformer 모델 기반의 다중 문서 요약 모델입니다.
각각의 모델의 특징에 대해서 알아보겠습니다.
단일 문서 요약: PEGASUS
대량의 데이터를 이용하여 학습하는 PLM(Pre-Trained Model)이 대다수 Task에서 높은 성능을 나타내고 있는 것을 착안하여 Transformer Encoder-Decoder 모델을 기반인 PLM 모델 PEGASUS를 제안했습니다. PEGASUS는 요약 Task 중에서도 단일 문서 요약(Single Document Summarization)을 위한 모델입니다.
Transformer19 모델에 대해서는 많이 들어서 제외하고 GSG(Gap Sentence Generation)을 방식을 이용하여 Self-Supervised 방식을 이용하여 학습했다는 것이 가장 큰 특징인데요. 기존의 MLM(Masked Language Model)에서는 토큰(token) 단위로 masking하여 masked 토큰을 예측하는 방식이라면 GSG는 문장(sentence) 단위로 masking하여 masked 문장을 생성하도록 학습을 수행한다고 합니다.
Figure 5. 은 PEGASUS의 모델 구조 그림인데요, Encoder 부분에 2가지의 [MASK]가 있는걸 보실 수 있는데요, [MASK1]은 문장단위로 masking한 GSG 방식이며, [MASK2]는 기존의 MLM 방식처럼 토큰(token)단위로 masking한 모습을 보이고 있습니다.
본 논문에서는 MLM과 GSG를 동시에 적용하여 학습할 계획이었지만, 실제로는 성능 향상에 영향을 주지 않는다고 하여 최종 모델에서는 MLM을 제외했다는 슬픈 사실이 있습니다..ㅠ
 Figure 5. PEGASUS의 모델 구조
Figure 5. PEGASUS의 모델 구조
그럼 어떤 문장이 선정되어서 masking되는지 궁금하실텐데요. 해당 논문에서는 문서 내 전체 문맥을 설명할 수 있는 중요한 문장을 선정하기 위해 3가지 방법을 사용했습니다.
Random: 무작위로 m개 문장 선정
Lead: 첫 m개 문장 선정
Principal: 선택한 문장과 나머지 문장들 간의 ROUGE-1 F1을 계산하여 Top-m개 선정, \(s_{i}=rouge(x_{i}, D \setminus \{x_{i}\}), \forall i.\)
Principal은 문장을 선택하는 방식과 계산하는 방식으로 나뉘며, 문장을 선택하는 방식으로는 Ind(independently)과 Seq(Sequentially), 계산방법으로는 Uniq(a set)과 Orig(Original) 로 나뉩니다.
문장 선택 방식
Ind: 모든 문장에 대해 각 문장을 개별적으로 평가하여 상위 m개 선택
Seq: ROUGE-F1을 최대화하는 문장을 하나씩 선택하면서 요약문을 만들어 나가는 방식
계산 방식
Uniq: 중복되는 n-gram을 하나로 취급하여 계산
Orig: 중복되는 n-gram을 여러번 계산
Principal은 Ind-Uniq, Ind-Orig, Seq-Uniq, Seq-Orig 4가지 방식의 문장 선정 방법이 있는데 실험을 통해 최종적으로 Ind-Orig 방식을 채택했다고 합니다.
masking할 문장까지 선정했으며 이제 학습을 시작하게 되는데요, Figure 6.20는 문서의 입력 단계, 중요 문장 선정 및 masking(Encoder), masked 문장 생성(Decoder)까지 하나의 흐름으로 나타내는 것을 볼 수 있습니다.
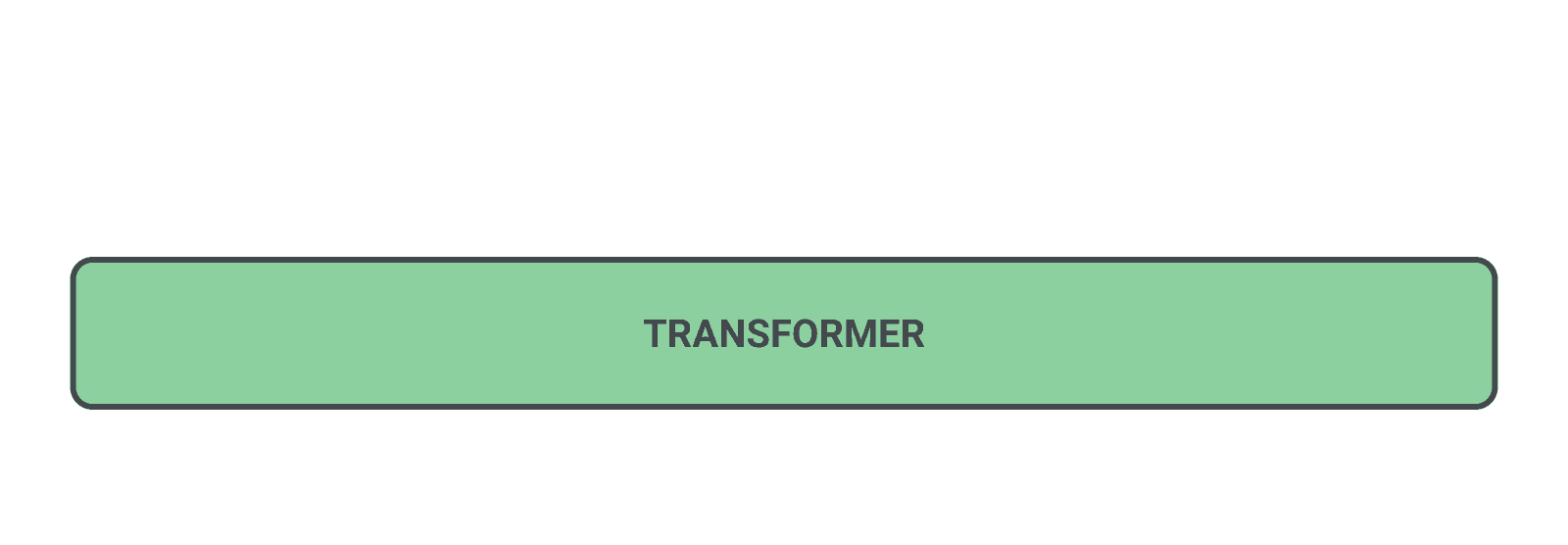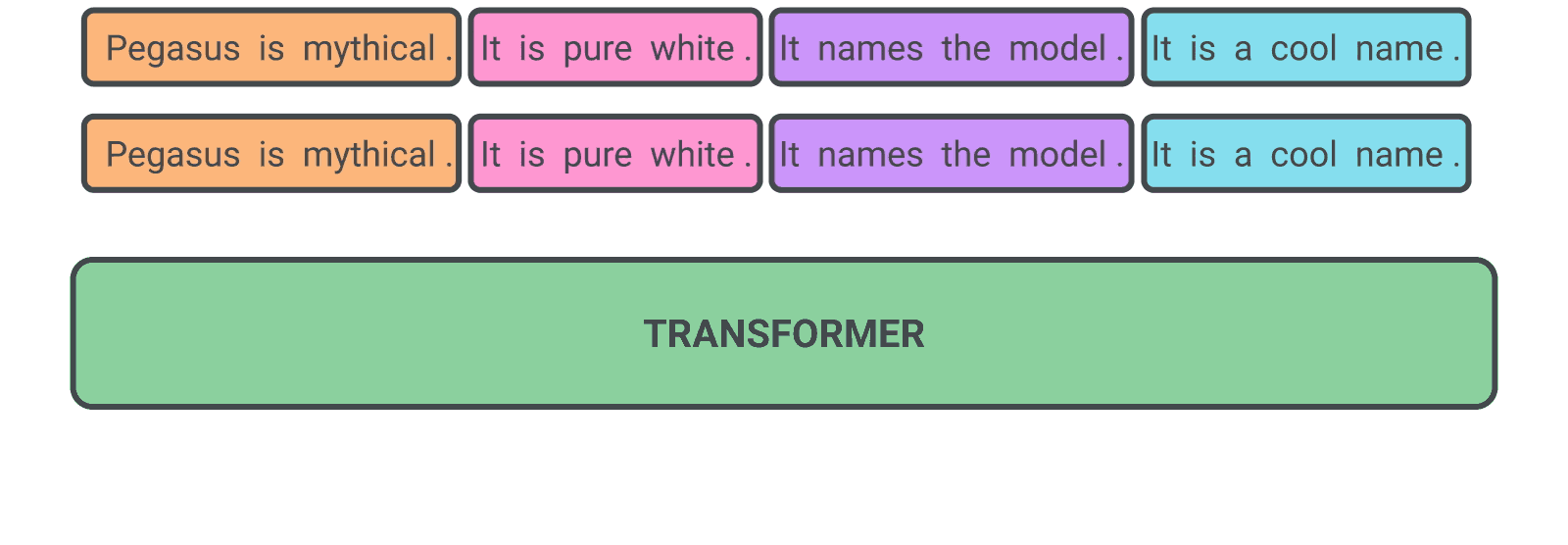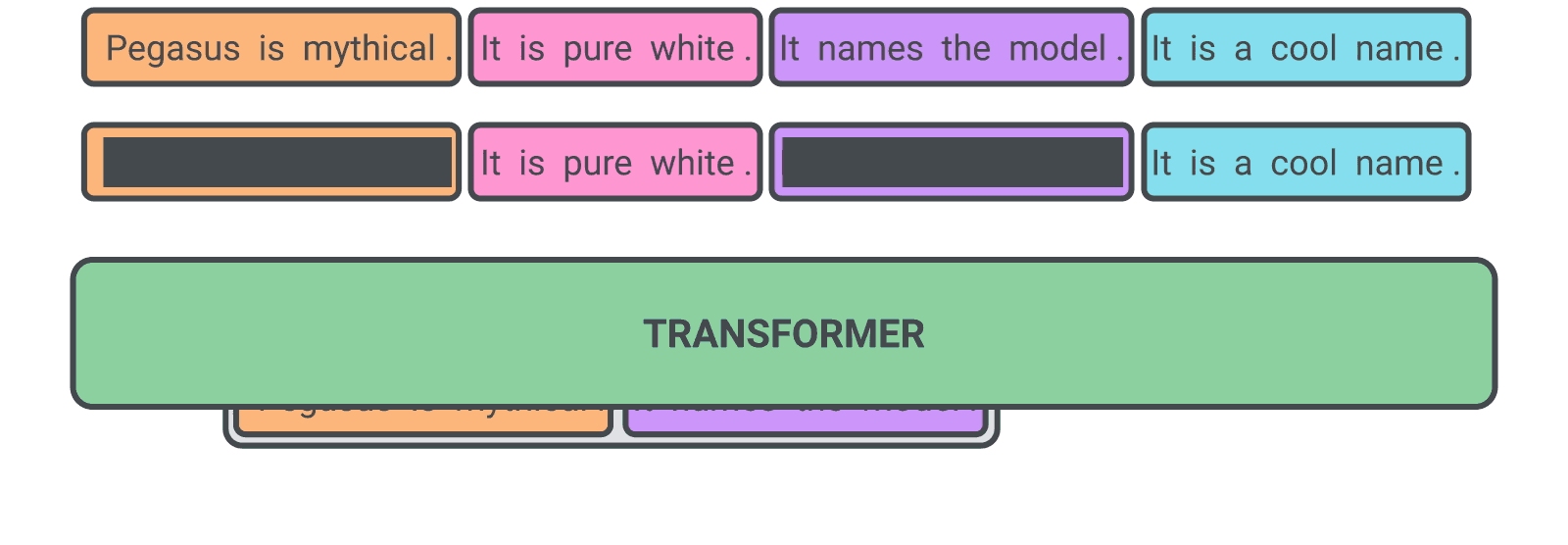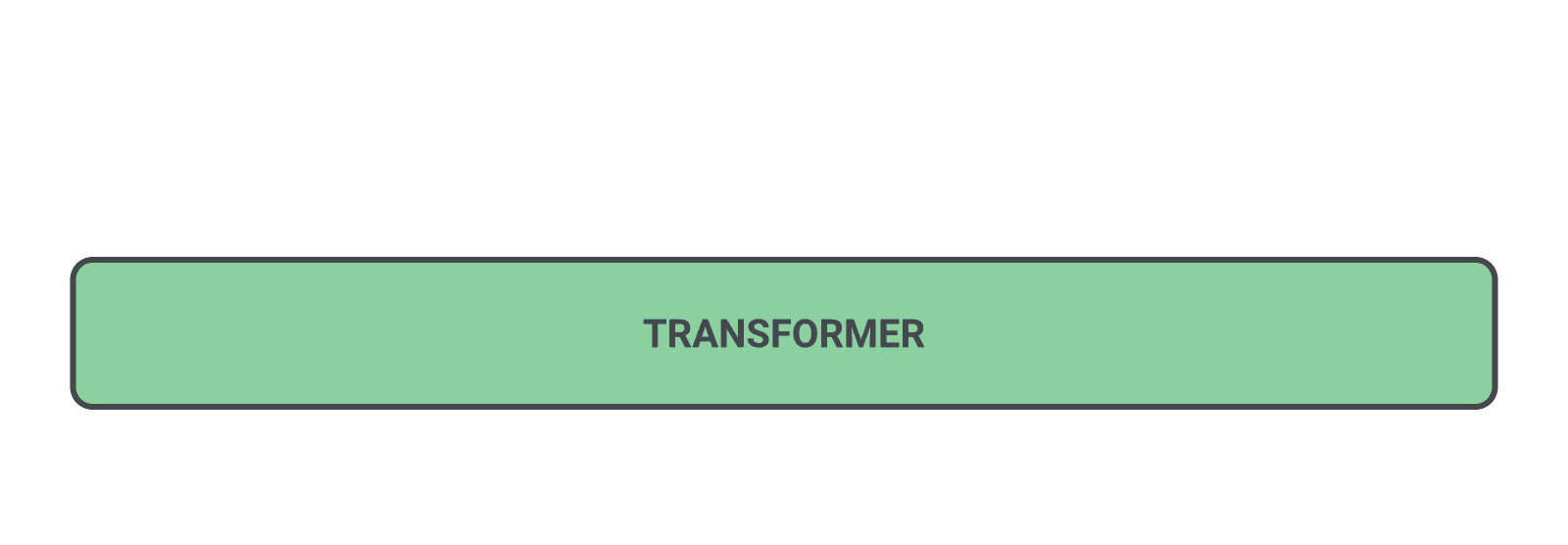 Figure 6. PEGASUS 학습 예시
Figure 6. PEGASUS 학습 예시
PRIMERA 모델을 설명드리기 전에 답습한 모델인 PEGASUS의 특징에 대해 간략히 소개시켜드렸는데 더 궁금하신 분들은 논문18을 보시면 좋을 것 같습니다.
다중 문서 요약: PRIMERA
그렇다면 PRIMERA는 PEGASUS와 무엇이 다를까요? 가장 다른 것은 다중 문서 요약(Multi-Document Summarization)을 위한 요약 모델이라는 겁니다.
Transformer 모델의 셀프어텐션(Self-Attention)은 시간과 공간 복잡도가 입력 길이의 제곱에 비례(\(O(n^{2})\))하기 때문에 입력 길이가 길어질수록 연산량도 많아진다는 문제점 때문에 긴 글을 처리하기 위해서는 여러가지 모델들이 고안되었습니다.17
하지만, 기존의 셀프어텐션처럼 풀어텐션(Full-Attention)이 아니라 필요한 단어 간에만 어텐션을 수행할 수 있는 방법을 고안하여(3가지의 희소 어텐션(Sparse Attention)) 복잡도를 (\(O(n)\))17 낮추는 Longformer 모델이 발표되면서 논문의 연구진들은 Longformer 모델을 사용했습니다.
Figure 7. 은 PRIMERA의 모델 구조인데 글을 전체적으로 파악하고 문서들 간의 정보를 공유할 수 있도록 전역어텐션(Global Attention)을 위해 특수토큰 <s>, <doc-sep> 등을 사용하며 문장 단위 masking은
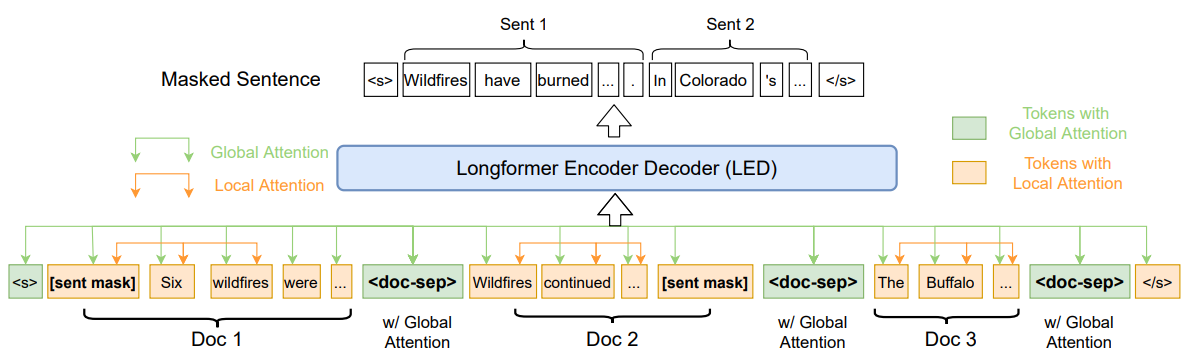 Figure 7. PRIMERA 모델 구조
Figure 7. PRIMERA 모델 구조
또한, 중요문장을 선정하는 방식도 다른데요, 기존의 GSG는 선택된 문장과 나머지 문장들 간의 overlap이 많이 되는 문장에 대해 높은 점수를 부여했는데요, 그게 단일 문서에서는 유용할 수 있겠지만, 다중 문서에서는 중복되는 문장 또는 표현들이 많을 수 있기 때문에 일치하는 문장을 선택할 가능성이 높으며 이렇게 선택된 문장들이 중요하지 않은 문장일 수도 있다는 단점이 있습니다.
이러한 단점을 보완하고자 PRIMERA에서는 Entity 기반의 Pyramid Sentence Selection 방식으로 바꾸었습니다. Pyramid Sentence Selection 방식에 대해 생소할 수 있을텐데요, 요약 성능을 평가하기 위한 방법 중에 하나로 정성평가를 기반으로 한 정량 평가 방법의 일종이라고 하며 방식은 다음과 같습니다.
1.평가자들이 Reference(=Gold) 요약문을 통해 정보 단위(SCUs; Summary Content Units) 선정
2.각 정보단위는 Reference 요약문 포함여부에 따라 비례하여 점수(Weight) 측정
3.정보단위들의 점수를 정규화하여 평균으로 계산
피라미드 모형처럼 중요 정보단위가 꼭대기를, 반대의 정보단위가 바닥을 차지하게 되는데요, 여기서 정보단위와 Entity를 치환해서 생각해보면 어떻게 될까요? 여러 문장을 반복적으로 나타나게 되면 중요한 Entity로 판단할 수 있으며 중요한 Entity이 포함된 문장을 중요한 문장을 선정할 수 있을텐데요.
본 논문에서의 Entity는 우리가 흔히 알고 있는 Named Entity이며 모호성이 존재하는 일반 명사보다는 New York(장소), Tom Cruise(사람), Microsoft(조직, 회사) 등과 같이 구체적으로 지칭하는 단어가 중요 문장을 선정하는데 도움이 될거라고 판단하여 Entity를 사용했다고 합니다.
아래는 Entity 기반의 Pyramid 구조에서 문장을 선정하는 프로세스이며 Figure 8. 는 도식화하여 나타낸 그림입니다.
- 문서 또는 문장 내 모든 Entity 추출
- 추출한 Entity의 빈도수를 체크하여 빈도수의 역순(빈도수가 높은 Entity가 꼭대기로, 낮은 Entity가 바닥)으로 정렬(여기서, 빈도수 1인 Entity 제거)
- 특정 Entity에 대해 언급된 문장들을 추출하여 하나의 Cluster로 두고, 한문장씩 후보 문장으로 두고 그 외 모든 문장들 간의 Figure 9. 수식을 이용하여 계산 (Cluster ROUGE)
- Cluster ROUGE 스코어로 순으로 순위를 매겨서 최종적으로 masking 문장 선정
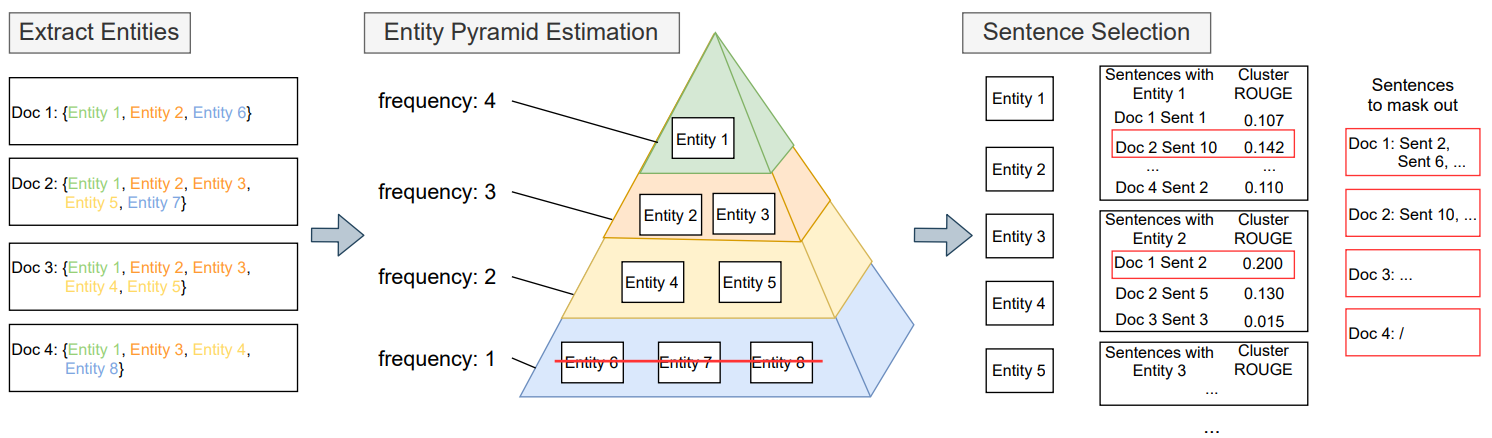 Figure 8. Entity 기반 Pyramid Sentence Selection 방법
Figure 8. Entity 기반 Pyramid Sentence Selection 방법
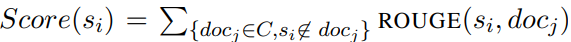 Figure 9. Cluster ROUGE Score 수식
Figure 9. Cluster ROUGE Score 수식
논문에서는 각각 Zero-Shot, Few-Shot, Fully Supervised 성능 측정을 진행하였습니다. Figure 10. 는 Zero-Shot에 대한 결과인데 저에게는 무척이나 흥미로웠습니다. Masking 전략, 모델 변경 2가지만 바꿨을 뿐인데 다른 모델들에 비해서 성능 차이가 많이 난다는게 놀라웠습니다.
특히, 아래의 성능 결과를 나타내고 있는 Figure 10. ~ 12. 는 뉴스데이터를 이용하여 모델학습했습니다. 논문의 저자들이 학습 데이터의 도메인에 치우치지 않도록 최소화시켰다 부분을 강조했었는데 성능을 보니 왜 그렇게 강조를 많이 했는지 이해가 되고 범용적으로 사용할 수 있겠다는 생각까지 했습니다.
 Figure 10. Zero-Shot 결과
Figure 10. Zero-Shot 결과
Few-Shot에서는 뉴스데이터로 학습했기 때문에 0 Examples에서는 다른 도메인에 대해서는 비록 성능이 낮았지만 각 도메인에 맞는데이터를 10, 100개 Fine-Tuning을 진행하니 성능이 눈에 띄게 향상된 것을 확인할 수 있습니다.
 Figure 11. Few-Shot 결과
Figure 11. Few-Shot 결과
Fully-supervised 방식도 마찬가지로 기존의 데이터 SOTA 모델보다 PRIMERA 모델을 이용하여 학습한 모델이 대부분은 높은 성능을 나타내고 있습니다. Multi-XScience은 다소 낮게 책정됐는데 논문에서는 Multi-XScience의 입력 문서들이 논문들의 초록이기 때문에 문서들의 주제가 비록 같을지라도 유사성이 떨어질 수 있다고 생각하여 성능이 낮게나왔다고 분석하고 있습니다.
 Figure 12. Fully-Supervised 결과
Figure 12. Fully-Supervised 결과
PRIMERA 논문이 벌써 나온지 1년이 다 되어가는데요. 아직까지도 다중문서요약 Task에서 SOTA의 성능을 나타내고 있습니다. 또한, 여기서 “최근에 유행하고 있는 chatGPT와 비교하면 어떨까?”라는 궁금증이 생길 것 같은데요… 그 이유로는 Zero-Shot, Few-Shot에서도 높은 성능을 나타냈기 때문입니다.
PRIMERA와 chatGPT 2개의 성능 비교를 해봐도 흥미로운 결과가 나올거라고 예상이 됩니다.
이번 포스트에서는 요약 Task에 대한 정의와 다중 문서 요약(Multi-Document Summarization)의 최신 연구 1편을 소개시켜드렸는데요. 후속 포스트에서는 Bing AI에서 사용되고 있는 사용자 질의어에 대해 적절한 답변을 제공하기 위한 다중문서 요약인 Query-Focused Multi-Document Summarization 주제를 가지고 돌아오겠습니다. 감사합니다!
References
-
Introduction to the Special Issue on Summarization (Dragomir R. Radev et al., 2002) ↩
-
Neural Approaches to Conversational Information Retrieval (Jianfeng Gao et al., 2022) ↩
-
Extraction-Based Automatic Summarization: Theoretical and Empirical Investigation of Summarization Techniques (Sizov Gleb., 2010) ↩
-
https://turbolab.in/types-of-text-summarization-extractive-and-abstractive-summarization-basics/ ↩
-
Overview of DUC 2005 (Dang Hoa Trang, 2005) ↩ ↩2
-
Multi-News: a Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model (Alexander R. Fabbri et al., 2019) ↩
-
Generating Wikipedia by Summarizing Long Sequences (Peter J. Liu et al., 2018) ↩
-
A Large-Scale Multi-Document Summarization Dataset from the Wikipedia Current Events Portal (Ghalandari Demian Gholipour et al., 2020) ↩
-
Multi-XScience: A Large-scale Dataset for Extreme Multi-document Summarization of Scientific Articles (Yao Lu et al., 2020) ↩
-
MSˆ2: A Dataset for Multi-Document Summarization of Medical Studies (Jay DeYoung et al., 2021) ↩
-
Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond (Ramesh Nallapati et al., 2021) ↩
-
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents (Arman Cohan et al., 2021) ↩
-
PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization (Wen Xiao et al., 2022) ↩ ↩2
-
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization (Jingqing Zhang et al., 2020) ↩ ↩2
-
Attention Is All You Need (Ashish Vaswani et al., 2017) ↩
