
들어가며
안녕하세요. 이번 포스트는 개인정보보호실에서 데이터 사용을 위한 어떤 사항을 가이드하고, 데이터 활용에 대해 법적으로 문제가 없도록 어떤 내용을 확인하는지 설명드리겠습니다.
여러분은 연구 또는 실습을 할 때, 어떤 데이터를 사용하시나요?
어떤 데이터를 사용해서 모델을 만들어야 성능이 좋고, 예측치가 잘 나올지 고민들을 하실꺼라고 생각합니다.
가장 정확한 데이터는 내 정보나 다른 사람의 행위나 패턴 정보를 그대로 사용하면 되겠지만, 개인정보보호법상 해당 데이터들은 마음대로 사용할 수 없습니다.
이와같이 ChatGPT와 같은 대형 언어 모델 및 생성형AI, 자율주행차 등 새로운 분야의 기술 분야에서 개인의 데이터 활용에 대한 필요성이 증가하고 있습니다.
왜냐하면 대형 모델이나 생성형 AI 등의 성능을 결정하는 것은 강화학습에 사용된 데이터의 양과 품질이 핵심일 것이라는 추측이 많기 때문입니다.
하지만 이와 같은 행동이나 패턴의 데이터를 수집하는 과정에서 필연적으로 개인정보의 침해 이슈가 발생하게 됩니다.
따라서, 개인정보 침해 없이 개인의 행동이나 패턴 데이터를 수집할 수 있는 방법을 구상하게 되었고 이 방법은 가명정보라는 명칭으로 등장하게 되었습니다.
그래서, 이번 포스트에서는 개인의 데이터를 안전하게 활용할 수 있도록 하는 과정인 개인정보 가명화에 대해서 이야기하고자 합니다.
“개인정보 비식별화 조치”란?
가명정보를 알아보기에 앞서 국내에서는 개인정보 데이터를 알아볼 수 없게 만드는 방법을 통틀어서 개인정보 비식별화 조치라고 부르고 있습니다.
개인정보 비식별화 조치는 가명정보의 상위 카테고리로 이해하시면 될 것 같습니다.
개인정보 비식별 조치란 ‘개인정보의 일부 혹은 전부를 삭제하거나 변형을 통해 특정 개인을 식별할 수 없도록 조치를 취하는 것’을 뜻합니다.
비식별 조치 방법으로 국내 가이드라인에서는 ①가명 처리, ②총계 처리, ③데이터 삭제, ④데이터 범주화, ⑤데이터 마스킹 등 총 5가지 처리 기법으로 구분된 17가지 세부 기술을 제시하고 있습니다.
해당 기술 내용은 아래와 같습니다.
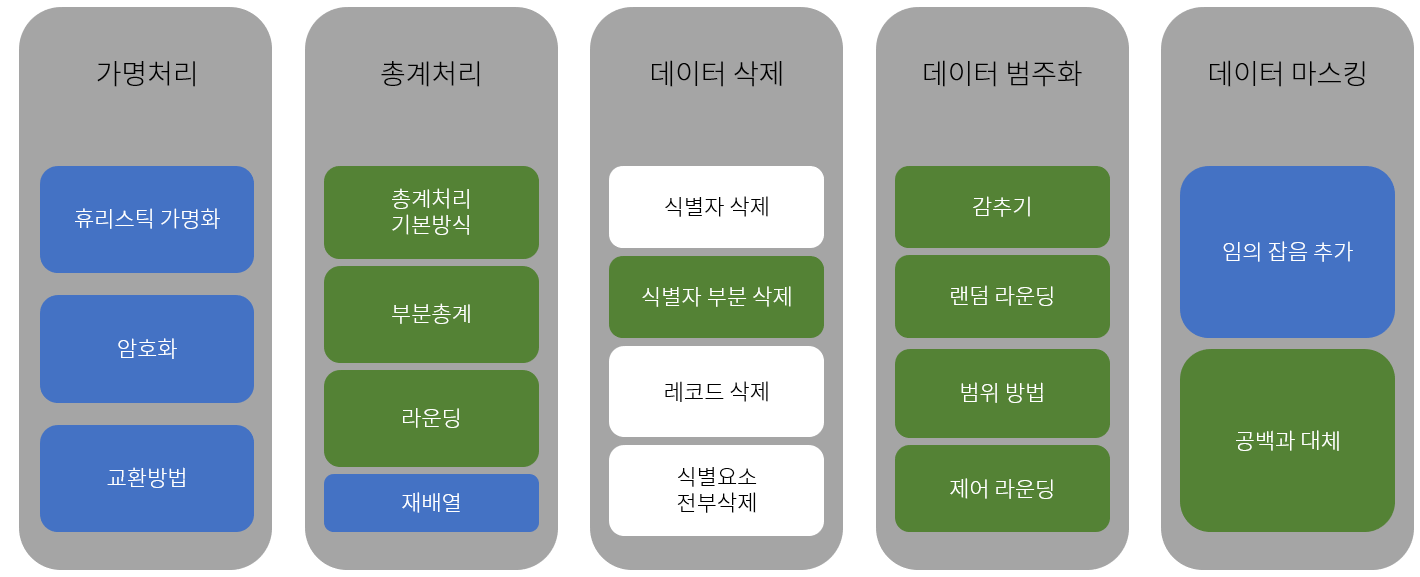 비식별화 기술
비식별화 기술
| 기술명 | 설명 |
|---|---|
| 휴리스틱 가명화 (heuristic pseudonymization) | 데이터를 정해진 규칙으로 가명처리하여 실제 누구 데이터인지 알 수 없게 하는 기술 |
| 암호화(encryption) | 양방향 암호화, hash, 일회성 임시 식별자 같은 암호화 알고리즘을 기반으로 개인정보를 암호화하여 숨기는 기술 |
| 교환 방법(swapping) | 민감한 데이터를 사전에 정해진 외부 데이터로 치환하는 기술 |
| 재배열(rearrangement) | 그룹 내 데이터를 임의로 섞어 특정 데이터와 개인 간 연결성을 끊는 기술 |
| 임의 잡음 추가 방법 (adding random noise) | 임의의 노이즈(randomnoise) 값을 넣어 식별정보 노출을 방지하는 기술 |
| 총계 처리 기본 방식(aggregation) | 데이터의 총합이나 평균으로 개인의 실제 정보를 숨기는 기술 |
| 부분총계(micro aggregation) | 다른 속성 값에 비해 오차 범위가 크거나 특징적인 경우 해당 속성 값에 대해서만 통계 값을 적용하여 개인을 식별하지 못하게 하는 기술 |
| 라운딩(rounding) | 올림, 내림, 반올림 등의 방법을 사용하여 개인의 실제 정보를 숨기는 기술 |
| 식별자 부분 삭제(reducing partial variables) | 속성의 일부 값을 삭제하여 대표성을 가진 값으로 보이게 하는 기술 |
| 감추기 | 데이터의 평균 또는 범주값으로 변환해 일반화하는 기술 |
| 랜덤 라운딩(random rounding) | 임의의 값을 기준으로 해당 값을 올리거나 내려 민감성이 높은 정보를 대표값으로 처리하는 기술 |
| 범위 방법(data range) | 개인 수치 데이터를 범위나 구간으로 표현 |
| 제어 라운딩(controlled rounding) | 행과 열의 합이 일치 되도록 고려하여 값을 라운딩(rounding)하는 기술 |
| 공백과 대체(blank and impute) | 속성 값 일부를 공백처리하고 특수문자 등으로 채우는 기술 |
| 식별자 삭제 | 원본 데이터에서 식별자를 단순 삭제하는 방법 |
| 레코드 삭제(reducing records) | 다른 정보와 뚜렷하게 구별되는 레코드 전체를 삭제하는 방법 입니다. 평균에 비해 이상치로 판단하여 개인을 식별할 수 있다고 여기는 정보에 대해 삭제 |
| 식별요소 전부삭제 | 식별자뿐만 아니라 잠재적으로 식별 가능한 속성까지 전부 삭제하여 프라이버시 침해를 줄이는 방법 |
그럼 이 많은 기술들 중에서 가명처리 기법을 왜 설명하고자 하는지 알아보겠습니다.
“가명정보”란?
위에서 나온 다양한 개인정보 비식별 기술 중에서 데이터 분석 또는 활용을 위해 가명정보를 말하는 이유는 익명정보보다 행동 패턴을 개별 데이터 형태로 좀더 디테일하게 분석할 수 있기 때문입니다.
아래의 표와 그림을 통해 가명정보와 익명정보가 어떤 차이가 있는지 자세히 알아보겠습니다.
| 구분 | 내용 |
|---|---|
| 개인정보 | 직접 식별 가능한 정보 |
| 가명정보 | 개인정보의 일부를 삭제하거나 일부 또는 전부를 대체하는 등의 방법으로 추가 정보가 없이는 특정 개인을 알아볼 수 없도록 처리하여 식별 가능성을 낮춘 개인정보 |
| 익명정보 | 추가 정보를 더해도 특정인을 식별할 수 없는 비식별 데이터 |
 가명정보 표 비교
가명정보 표 비교
위의 표처럼 가명정보와 익명정보를 나눌 수 있는 기준에 대해서 설명을 하겠습니다.
가명화, 익명화는 어떤 기준에 따라 나눠지는 것일까요?
한국 인터넷 진흥원에서는 일반적으로 아래와 같이 세 가지 요인으로 개인 식별성 제거 수준에 따라 가명화 조치와 익명화 조치로 구분하고 있습니다.
- 특정 데이터가 한 개인과 대응(single out)
- 특정 데이터와 특정 개인이 연결됨(linkability)
- 특정 데이터로부터 특정 개인을 추론할 수 있음(inference)
익명화(anonymization)는 세 가지 요인을 모두 제거하는 개념이며, 가명화(pseudonymization)는 single out은 허용하되, 연결과 추론은 제거하는 개념이라고 볼 수 있습니다.
따라서 가명화는 재식별화가 가능하며, 익명화는 ‘합리적 노력’으로는 재식별이 불가능합니다. 따라서, 가명정보라고 해서 절대 개인을 찾아낼 수 없는 정보는 아닙니다.
그렇기 때문에 가명정보를 실제로 사용하기 위해 국가에서 정한 처리 프로세스를 거쳐야 가명정보로 인정을 받을 수 있습니다.
이런 프로세스가 어떤 것인지 다음장에 설명 드리겠습니다.
가명정보 처리 절차
가명정보 처리는 다음과 같이 사전 준비, 가명처리, 적정성 검토 및 추가 가명처리, 활용 및 사후 관리의 4단계 절차로 이루어져 있습니다.
 가명처리 단계별 절차도
가명처리 단계별 절차도
사전 준비
가명처리 목적을 명확히 하여 해당 목적이 적합한지 여부를 확인하여야 하며 해당 목적에 따라 가명처리 대상 항목 및 처리 수준을 정하고 내부 승인 절차를 진행해야 합니다.
가명처리(가명처리 수준정의 및 처리)
가명처리 단계는 세부적으로 ①대상 선정, ②위험도 측정, ③가명처리 수준정의, ④가명처리를 하는 4가지 단계로 구성되어 있습니다.
가명정보 처리 시에도 개인정보의 최소처리원칙을 준수하여야 하며, 가명처리 방법을 정할 때에는 처리 목적, 처리(이용 또는 제공)환경, 정보의 특성 등을 종합적으로 고려하여야 합니다.
- 사전준비 단계에서 수립한 목적에 필요한 최소한의 항목만을 가명처리 대상으로 선정하여 추출
- 처리(제공)환경을 바탕으로 개인정보 항목별로 위험도를 분석하여 위험도 평가 결과를 도출
- 가명처리 위험도 측정검토 결과를 기반으로 가명정보의 활용목적 달성에 필요한 수준을 고려하여 가명처리 수준을 정의
- 가명처리 수준 정의 결과를 기반으로 가명처리를 수행하여야 하며 가명처리 단계에서 생성되는 추가정보는 가명정보와 분리하여 별도로 저장
적정성 검토 및 추가 가명처리
이전 단계에서 정의한 가명처리 수준에 따라 적절히 가명처리가 되었는지 확인하여야 합니다.
목적달성을 위해 적절한 수준으로 가명처리가 이루어졌는지, 재식별 가능성은 없는지 등에 대한 최종적인 판단절차를 수행하여야 합니다.
가명처리한 결과, 목적을 달성하기 어렵거나 재식별 가능성이 있다고 판단한 경우 가명처리를 반복하거나 부분적으로 추가적인 가명처리를 할 수 있습니다.
데이터의 분포와 값을 살펴보았을 때, 특이 정보 가 있다고 판단한 경우 재식별 가능성을 낮추기 위한 적절한 조치를 취하여야 합니다.
활용 및 사후관리
적정성 검토 결과 가명처리가 적정하다고 판단되면 가명정보를 본래 활용 목적을 위해서 정보주체의 동의 없이 처리할 수 있으며, 법령에 따라 기술적·관리적·물리적 안전 조치를 이행하여야 합니다.
가명정보취급자에게 금지 행위, 안전조치 등에 관한 사항을 안내하여 가명정보를 안전하게 처리하여야 합니다.
가명정보 처리 과정에서 개인식별 가능성이 증가하는지 여부 등을 지속적으로 모니터링 하여 안전하게 처리하여야 하며 특정 개인이 식별되는 경우 즉시 처리 중지, 회수, 파기 등 적절한 조치를 수행하여야 합니다.
해당 프로세스를 거쳐 가명정보로 분류가 되어도, 위에서 말한 사항과 같이 가명정보는 기술적으로는 개인을 재식별할 수 있는 정보입니다.
그렇기 때문에 가명정보의 활용뿐만 아니라 보호에도 관심을 가져야 하는 것이 사실입니다.
이에 따라, 가명정보의 재식별을 가능하게 하는 ‘추가적인 정보’의 분리 보관 등 안전 조치에 대한 내용이나, 재식별된 정보의 파기 등이 필요하다고 생각이 되었고, 올해 개인정보보호법 개정이 이루어지며 해당 내용이 담기게 되었습니다.
가명정보 처리의 최근 변화 및 파기의 중요성
위에서 말한 내용과 같이 안전 조치에 관한 내용이나 가명 처리된 본인의 정보가 어떻게 활용되고 보호되고 있는지를 최대한 투명하게 공개하는 방법이 필요하다는 생각이 업계 전반적으로 공유가 되었습니다.
이에 따라, 가명정보 처리에 대해 기존에는 적절한 조치를 해야 한다는 내용에서 최근 개인정보보호법 2차 개정안을 통해 가명정보의 파기 기준을 수립하라는 조항이 생성되었습니다.
아래 표를 보시면 해당 내용이 자세하게 나와있습니다.
 개인정보보호법 2차 개정안(시행 2023.9.15)
개인정보보호법 2차 개정안(시행 2023.9.15)
- 가명정보 처리 시 가명정보 처리 목적 등을 고려하여 처리 기간을 별도로 정할 수 있도록 하는 규정(제28조의4 제2항) 도입
- ⇒ 개인정보 파기 규정(제21조) 및 가명정보에 대한 기록ㆍ보관 규정(제28조의4 제3항) 개정
- ⇒ 가명정보에 대해 보존기간을 설정해야 하나 기간 설정의 재량 부여
- 가명정보에 대하여도 파기 의무가 적용됨을 명확히 함(제28조의7)
이처럼 가명화 시킨 개인정보도 개인정보와 같이 파기 대상이 되면서 기존에 사용하던 것처럼 파기 없이 무제한으로 사용하는 것에 제동을 걸었다고 봐야 합니다.
하지만, 가명정보의 데이터 같은 경우 데이터 모델을 구성하는 값에 사용되어 파기를 해야하는 경우 가명 정보 데이터만 따로 분류하기가 매우 어려우며, 해당 데이터 값이 빠지는 경우 학습 모델 성능에 이상이 생길 수 있습니다. 이런 위험이 있기 때문에 기존에 처리된 데이터를 삭제하는 것은 현실적으로 쉽지 않을 것입니다.
따라서, 앞으로 기업이나 기관 연구소 등에서 가명정보 사용 시에 정확한 사용 목적, 보유기간, 항목을 설정하여 데이터 모델 개발 시부터 설계에 적용해야 합니다.
또한, 이러한 내용을 개인정보 처리방침 이라는 곳에 고지해야 합니다.
이런 변경사항을 꼭 숙지하여 앞으로 가명정보 활용시에 반영해야 합니다.
이번 포스트를 마치며 가장 중요한 내용을 다시 한번 강조하며 마무리 하겠습니다. 가명정보의 파기 의무가 생겼으며, 해당 내용을 사전에 설계하고 고지해야 한다는 점을 꼭 알아두셔야 합니다.
이 포스트가 가명정보를 이용한 데이터 활용 활성화에 도움이 되었길 바랍니다.
긴 글을 읽어주셔서 감사합니다.
References
[1] 김정선(2020).가명 데이터 활용 연구 -기술적 처리방법 및 기업의 활용방향을 중심으로 -
[2] 개인정보보호위원회(2021). 가명정보 처리 가이드라인
[3] 이현승, 송지환 (2016). A Research on De-identification Technique for Personal Identifiable Information
[4] 성기범(2023). 개인정보보호법상 가명처리에 관한 연구
