
작성자
- 이용혁(Speech AI Lab)
- AI를 활용한 호출어 인식, 이벤트 인식 및 음성 처리 연구를 하고 있습니다. 모두의 목소리를 조금 더 잘 들을 수 있는 방법을 고민합니다.
이런 분이 읽으면 좋습니다!
- 기계에 이름을 붙여주고 싶으신 분
- 그 이름을 자주 바꿔야 하는 분
이 글로 확인할 수 있는 내용
- User-Defined KeyWord Spotting (UDKWS)의 필요성
- UDKWS 연구 동향
TL; DR
- 다양한 호출어를 인식하고 싶다고 음성인식기를 계속 돌리는 것은 비효율적입니다.
- 그렇다고 호출어가 바뀔 때마다 사용자에게 음성을 받아 사용하는 것 또한 불편합니다.
- 대규모 일반 발화 데이터에서 텍스트와 발음의 유사성을 학습하면 zero-shot으로 구현할 수 있습니다.
- 이 때 음성과 텍스트의 발음열에 대한 보조적인 비교 정보를 같이 사용하면 성능 개선 및 기능 확장에 도움이 됩니다.
안녕하세요. 이번 INTERSPEECH 2023에 출판한 논문(PhonMatchNet: Phoneme-Guided Zero-Shot Keyword Spotting for User-Defined Keywords)을 바탕으로 저희가 고민한 User-Defined KeyWord Spotting (UDKWS, 사용자 정의 호출어 인식) 기술의 연구 과정을 소개 드리고자 합니다. 본문에 앞서 ‘사용자 정의 호출어 인식’이란 사용자가 기계 혹은 디지털 휴먼 등을 호출할 때 사용하는 호출어를 미리 지정된 호출어가 아닌 사용자의 기호에 따라 자유롭게 지정할 수 있는 기술을 의미합니다.
이번 글에서는 일반인 혹은 음성을 다루지 않는 분들에게도 연구를 설명드리고자 실험 환경, 결과 등 지엽적인 내용은 서술하지 않을 예정이니, 자세한 사항은 논문을 통해 확인 부탁드립니다.
1. 기술 필요성
2023년 우리는 알게 모르게 주변에 다양한 기계들에게 말을 걸고 생활하고 있습니다. 운전 중 목적지를 조정하거나, 스마트 스피커와 홈 IoT 기기를 연동해 움직이지 않고도 전등을 끄고 커튼을 칠 수도 있습니다. 저 같은 경우엔 매일 아침 30분 단위로 맞춰 놓은 모든 알람을 눈 감은 상태에서 끄기 위해 시리를 목놓아 부릅니다.
그리고 아무리 기계라고 해도 이름을 부르다 보면 뭔가 소중한 존재가 되는 것 같이 느껴집니다. 김춘수 시인의 꽃처럼 제가 시리를 부르기 전까지 다만 하나의 스마트폰에 지나지 않았지만 제가 시리를 부름으로써 ‘제 시리’가 된 것처럼 느껴지거든요.
하지만 매번 시리와 알렉사, 구글을 부르는 것은 뭔가 정이 안 붙는 것 같습니다. 저는 제 차를 용방이라고 부르고 싶고 제 시리를 부를 때 옆 사람의 시리가 대답하는 게 영 불편했거든요. 이런 생각은 저만했던 게 아닌지 많은 회사들이 이에 대한 기술 개발을 하고 있었습니다.
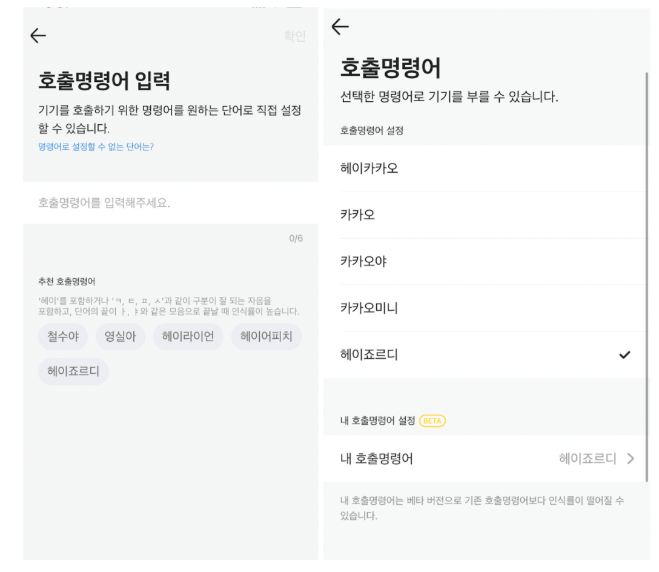 [그림 1] 카카오미니의 호출명령어 변경
출처: 카카오엔터프라이즈 테크블로그
https://tech.kakaoenterprise.com/122
[그림 1] 카카오미니의 호출명령어 변경
출처: 카카오엔터프라이즈 테크블로그
https://tech.kakaoenterprise.com/122
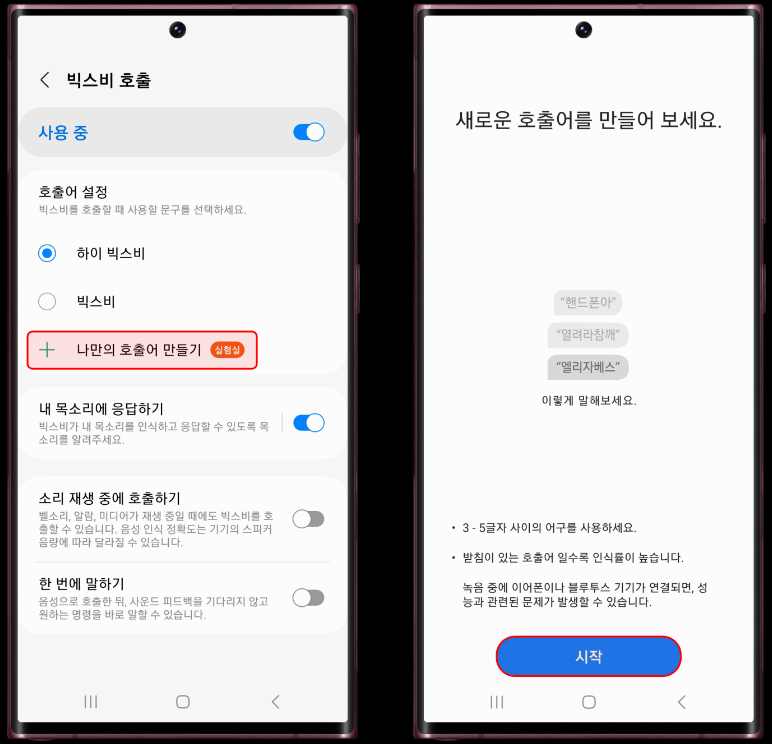 [그림 2] 삼성전자 빅스비 나만의 호출어 만들기 기능
출처: 도동쓰의 IT 톡톡 블로그
https://it-talktalk.tistory.com/1427
[그림 2] 삼성전자 빅스비 나만의 호출어 만들기 기능
출처: 도동쓰의 IT 톡톡 블로그
https://it-talktalk.tistory.com/1427
위와 같이 사용자 정의 호출어 인식 기술에 대한 시장의 요구가 올라가면서 국내외 다양한 기업에서 관련 기술을 연구개발 중이었고 저희 내부적으로도 유저의 다양한 호출어에 대응할 수 있는 인식 기술의 필요성이 예상되었기 때문에 UDKWS 기술을 연구를 주제로 잡았습니다.
2. 문제 정의
사용자 정의 호출어 인식 기술의 문제는 무엇이 있을까요?
첫 번째 문제는 제한적인 자원입니다. 일반적으로 사용자는 빠른 응답을 원하기 때문에 서버-클라이언트 구조가 아닌 디바이스 내부에서 동작하는 모델을 기본으로 접근했습니다. 해당 기술이 데스크탑, 노트북, 스마트폰, 웹 어디서 동작할지 제한을 두지 않기 위하여 최대한 가벼운 구조를 선택하고 싶었고 그렇기 때문에 자연스럽게 고성능의 음성인식 모델을 구성해서 백그라운드에서 계속 동작시키는 구조는 배제하였습니다.
두 번째 문제는 학습자료 수집의 문제입니다. 가장 좋은 학습자료는, 실제 사용자로부터 사용할 호출어 발화를 직접 수집한 것입니다. 여기에는 화자 고유의 정보를 획득할 수 있고, 입력 받은 호출어의 직접적인 정답을 얻을 수 있는 등 성능면에서는 이득이 있을 수 있습니다. 하지만, 사용자에게는 불편한 과정이고, 가이드를 준수하지 않는다면 녹음 시 주변 환경 잡음이 들어갈 여지가 있으며, 개인정보 취급에 대한 고민도 필요해집니다.
종합해 보면 호출어 변경 시 추가 학습 자료가 필요 없으면서, 가볍고, 성능이 좋아야 합니다. 가능할까요?
[영상 1] 어떻게 하면 이 강아지들처럼 자기 이름을 정확하고 빠르게 알아들을 수 있을까요?
3. 제안 방법
모델이 가벼우면서 인식 성능이 좋으려면 어떻게 해야 할까요? 다양한 방법이 있을 수 있으나 그중 한 가지 방법은 인식해야 할 범위를 줄이는 것입니다. 제가 채택한 방법은 풀고자 하는 문제를 ‘입력된 소리와 입력된 호출어 텍스트가 동일하냐’로 문제의 정의를 바꾸는 것입니다.
종래의 호출어 인식 기술은 아래 그림 3의 왼쪽처럼 같이 음성 신호를 입력받아 N개의 호출어 리스트 중 어느 호출어인지 분류하는 문제였습니다. 인식의 범위가 N개로 작기 때문에 간단하지만 호출어가 변경된다면 모델을 다시 만들어야 하는 번거로움이 있었습니다.
이에 반해 무한한 호출어에 대응할 수 있는 이상적인 형태는 오른쪽과 같이 음성 신호를 전사하여 이 단어와 호출어가 동일한지 판단하는 것입니다. 하지만 이 방법은 사실상 음성 인식기를 만드는 것과 동일하며, 배보다 배꼽이 더 큰 접근 방법이죠.
그렇기 때문에 가운데 방법처럼 음성 신호와 원하는 호출어를 같이 입력받아 두 개가 동일하면 1, 동일하지 않다면 0을 출력하도록 접근한다면 해결해야 할 문제 범위를 줄일 수 있으면서 호출어 변경에 대응할 수 있는 모델을 만들 수 있을 것입니다.
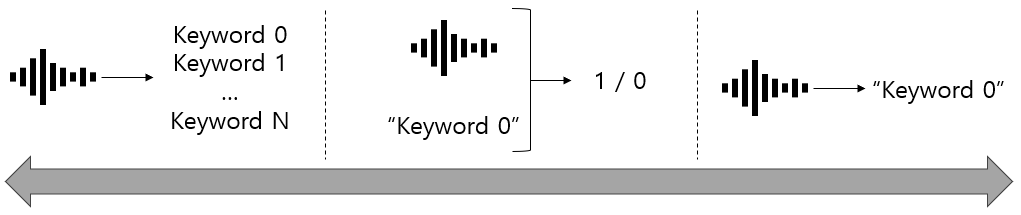 [그림 3] 다양한 호출어 인식 형태
[그림 3] 다양한 호출어 인식 형태
과거 연구 중 위와 같이 호출어 텍스트와 음성을 입력받아 해당 소리가 주어진 텍스트와 일치하는지 판단하는 모델을 기반으로 Zero-shot UDKWS 기능을 구현한 논문1이 있어 해당 논문의 모델을 베이스라인으로 정했습니다.
호출어 텍스트와 음성 쌍의 일치 여부를 학습하는 형태로 ‘추가 데이터 필요 없는 호출어 변경’ 문제를 해결하기 위한 기본 구조는 결정하였습니다. 하지만, 기존 Zero-shot 호출어 인식 기술의 성능은 여전히 아쉬움이 있었습니다. 그렇다고 모델을 무작정 크게 만들기에는 앞서 언급한 첫번째 기술적 문제와 상반되는 해결 방법입니다. 이러한 상황에서, 가볍고 성능이 우수한 모델을 만들려면 어떻게 해야 할까요?
첫 번째 접근은 대규모 학습 데이터셋에서 학습된 pre-trained embedder2 3를 사용하여 모델이 이해하기 쉬운 형태의 특징을 제공하는 것입니다. Pre-trained embedder란 미리 다양한 환경의 데이터로부터 학습된 모델의 일부를 떼어와 입력에 대해 어느 정도 정제된 정보를 뽑아내는 방법을 의미합니다. 저희가 사용한 pre-trained embedder는 YouTube 소리를 입력받아 학습된 모델이기 때문에 일반적인 음향 상황에서도 무리 없이 동작할 수 있다고 생각하여 적용했습니다. 이를 통해 모델의 크기나 학습 데이터를 추가하지 않고도 양질의 feature를 획득할 수 있습니다. 하지만 이는 범용적인 접근이므로 UDKWS에 맞는 추가 아이디어가 더 필요하다고 생각했습니다.
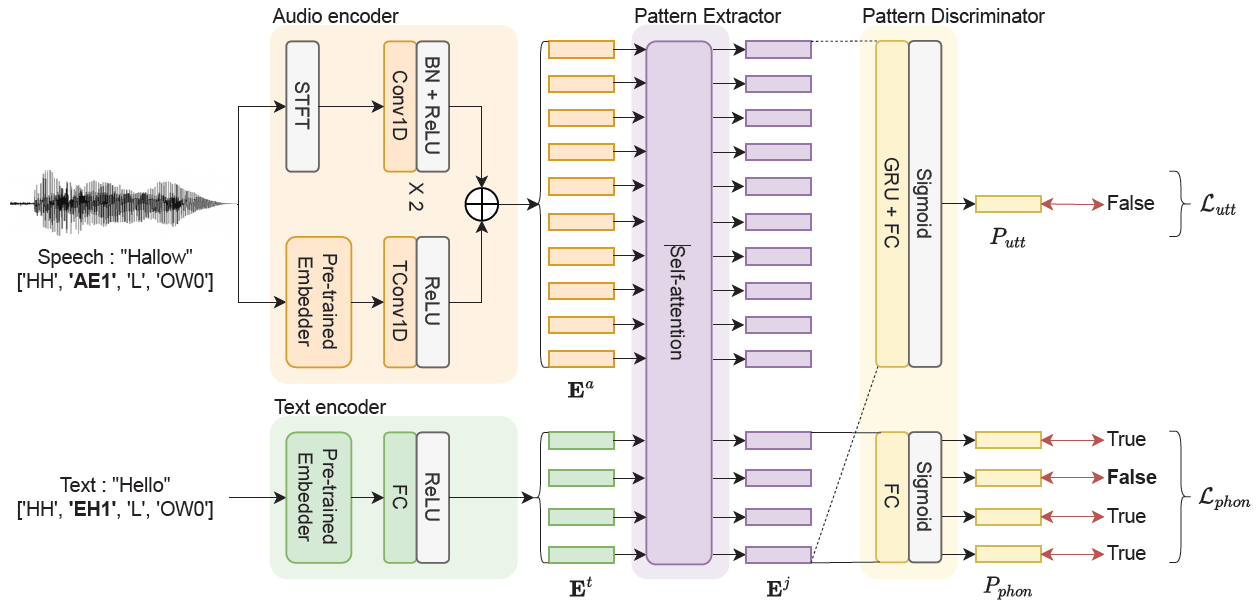 [그림 4] 제안 모델 구조
[그림 4] 제안 모델 구조
누군가 우리를 부를 때 가장 헷갈리는 경우가 언제일까요? 저는 개인적으로 기술용역, 용역인력 등 용혁과 비슷한 발음이 들리면 깜짝 놀라는 경우가 많았습니다. 우리 모델도 그런 입력에 헷갈려 하지 않을까요? 이런 관점에서 보면 모델을 학습할 때 ‘용혁’과 ‘용역’이 다르다는 정답 외에도 두 단어 중 ‘ㅇ’ 과 ‘ㅎ’만 다르고 나머지는 같다는 정보를 같이 알려주면, 발음이 비슷한 단어도 잘 분류할 수 있을 것이라고 생각했습니다. 그래서, 그림 4에서와 같이 학습 데이터에서 음성 정답(Hallow)과 텍스트 정답(Hello)의 발음열 단위 비교 정보(True, False, True, True)를 모델에 추가적으로 전달하여 발음 단위의 유사성 또한 볼 수 있도록 개선했습니다.
4. 결론 및 향후 과제
저희의 제안 모델은 1) 음성과 텍스트 정보를 같이 받는 모델 구조로, 2) pre-trained embedder를 사용하였으며, 3) Phoneme-level detection loss 추가를 통해 655K의 작은 모델 파라미터로 다양한 Unseen test dataset에서 비슷한 크기의 베이스라인 모델 대비 67% 혹은 80%의 성능 향상을 이끌어냈고, 4) 추가적으로 발음열에 대한 정보도 확인할 수 있도록 확장하였습니다. 특히나 ‘snapdragon’, ‘lumina’ 와 같이 일상적이지 않은 단어로 이루어진 테스트셋과 ‘friend’, ‘trend’처럼 굉장히 유사한 발음에 대한 테스트셋에서도 강인한 분류 성능을 보임을 확인할 수 있었습니다.
저희의 UDKWS 연구는 이제 막 작은 산을 넘었을 뿐입니다. 작은 고지에서 바라본 다음 목적지는 아래와 같습니다. 🚀
- 모델 최적화: 다양한 최적화 기법을 통해 더 빠르고 가볍게 동작하도록 개선
- 잡음 강인성: 내/외부 잡음에 보다 강인하게 개선
- 언어 확장: 언어 종속성 없는 무한한 확장 가능 구조
- 모달리티 확장: 극한의 잡음 환경에서의 강건성 확보를 위한 멀티 모달 연구
논문에 서술되어 있으나 이번 글에서 다루지 않은 부분이나 글을 읽으시면서 궁금하셨던 부분, 혹은 코드레벨에서 논의할 의견이 있으신 분들은 저희 NCSOFT 공식 GitHub에 공개된 PhonMatchNet repository에 이슈 및 PR 남겨 주시면 감사하겠습니다.
References
-
H.-K. Shin, H. Han, D. Kim, S.-W. Chung, and H.-G. Kang, “Learning Audio-Text Agreement for Open-vocabulary Keyword Spotting,” in Proc. Interspeech 2022, 2022, pp. 1871–187. ↩
-
J. Lin, K. Kilgour, D. Roblek, and M. Sharifi, “Training key-word spotters with limited and synthesized speech data,” in Proc. ICASSP 2020, 2020, pp. 7474–7478. ↩
