

- Intro 호출어 인식 기술 소개
- 1. 디지털 휴먼에게 고유한 이름을 부여해야 하는 이유
- 2. 웹브라우저에서도 동작할 수 있는 기술
- Outro 향후 과제가 있었는데요, 없어졌습니다.
- References
작성자
- 조남현(Speech AI Lab)
- 음성인식 기술을 활용하여, 온 가족이 함께 즐길 수 있는 새로운 게임 장르를 개척하는 꿈을 가진 연구자입니다.
- 김선민(Speech AI Lab)
- 코드로 만드는 것이라면, 무엇이든 만들 수 있습니다.
이런 분이 읽으면 좋습니다!
- 호출어 인식 기술에 관심이 있는 분
- 딥러닝 모델 고속화에 관심이 있는 분
- 웹브라우저에서의 딥러닝 모델 구동에 관심이 있는 분
이 글로 확인할 수 있는 내용
- 가볍고 빠른 호출어 인식기를 만드는 방법
- 웹브라우저에서 딥러닝 모델을 구동하는 방법
Intro 호출어 인식 기술 소개
디지털 휴먼과의 자유로운 상호작용을 시작하기 위해, 처음으로 해야 하는 일이 무엇일까요? 아마도, 디지털 휴먼의 이름을 부르는 것이겠지요! 일반적으로 특정 음절의 조합으로 이루어진 이름을 인식하기 위해서, 호출어 인식 (Keyword Spotting)이라는 기술을 사용합니다. 호출어 인식이라는 용어가 생소하신가요? 그렇다면, 안드로이드의 ‘헤이구글’, 애플의 ‘시리야’, T맵의 ‘아리아’는 들어보신 적 있으신지요! 이러한 것들이 호출어의 대표적인 예입니다. 이러한 기술은 통상적으로 호출어가 고정되어 있으며, ‘언제, 어디서나, 누구에게나’ 잘 동작할 목적으로 만들어집니다. 또한, 통상 수천개 이상의 호출 음성을 학습자료를 활용하여 생성한 고성능 딥러닝 모델들이 사용됩니다.
하지만, 이러한 일반적인 기술은 개인형 디지털 휴먼과 같이 개인화된 AI 서비스에서 사용하기에 적합하지 않습니다. 사용자가 원하는 이름을 붙여주기 위해 수천개의 학습자료를 모을 수 없고, 모델 학습을 진행할 장비도 없으며, 모델 학습을 어떻게 해야 하는지도 모르기 때문이죠…! 그래서 본 논문에서는 단 한 번의 예제 발화만으로 호출어 인식 모델을 학습하는 방법과 사용자 친화적인 호출어 인식 모델 학습/구동 환경을 제안하였는데요, 차근차근 설명해 보겠습니다.
1. 디지털 휴먼에게 고유한 이름을 부여해야 하는 이유
사용자가 나만의 디지털 휴먼을 만들기 위해서 외형을 직접 디자인하고, 페르소나를 부여하고, 목소리를 설정할 수 있는 세상이 되었다고 가정해보겠습니다. 다른 것들은 모두 마음대로 설정할 수 있는데, 남자 디지털 휴먼의 이름은 ‘민수’, 여자 디지털 휴먼의 이름은 ‘민지’로만 설정할 수 있다면 어떻게 될까요? 누군가의 ‘민수야!’라는 호출어로 인해 주변의 모든 민수들이 깨어날 개연성이 충분합니다. 또한, 너도나도 같은 이름으로 부르는 디지털 휴먼이라면 애착 형성에도 방해가 될 수 있을 것입니다. (이 세상 모든 민수님, 민지 님들께 심심한 사과의 말씀을 드립니다…) 그래서, 디지털 휴먼에게 고유한 이름을 붙여주는 것이 현실적으로 필요합니다.
[영상 1] 디지털 휴먼의 이름이 모두 같다면…?
1-1. 음성 임베딩: 사용자 정의 호출어를 구현하기 위한 핵심 재료
‘그럼 사용자가 원하는 이름으로 호출어 인식 모델을 학습해서 사용하면 되잖아!’라고 쉽게 생각할 수 있지만, 이 접근에는 큰 문제점이 하나 있습니다. 바로, 학습자료가 부족하다는 것입니다. 음성 신호 수준에서 호출어와 비-호출어를 구별하는 모델을 바닥부터 학습하기 위해서는 수천개 이상의 학습용 음성 자료가 필요합니다. 저희는 이러한 문제점을 해결하고자, 음성 임베딩 모델 (Speech embedding model) 을 사용하였습니다. 대표적으로 공개된 모델들로는 Google speech embedding, wav2vec2 등이 있습니다. 이러한 음성 임베딩 모델을 사용하면, 길고 복잡하고 불규칙한 음성 신호로부터 음성 인식에 유용한 자질 (음성 임베딩 벡터) 을 얻을 수 있습니다. 이러한 자질을 호출어 인식 모델의 입력으로 사용함으로써, 아주 적은 학습자료로도 호출어 인식 모델을 학습할 수 있게 됩니다.1 비유하자면, 사칙연산도 모르는 아이에게 미적분을 가르쳐야 하는 기존 상황에서, 고등교육을 모두 마친 학생에게 미적분을 가르치는 상황으로 바꿔주는 역할을 음성 임베딩 모델이 수행해주는 것입니다!
1-2. 음성 임베딩 모델 다이어트 시키기!
음성 임베딩 모델은 Google speech embedding1 을 사용하였습니다. 비슷한 다른 모델들 중에서 비교적 가벼운 모델이므로, 고속/경량을 지향하는 호출어 인식 모델에서 사용하기에 적합합니다. 하지만, 이 모델을 그대로 가져다 사용하기에는 몇 가지 문제점들이 있었습니다. 첫째, 중복 연산의 문제입니다. 이 모델은 현재 80 ms 음성 신호에 해당하는 임베딩을 얻기 위하여 과거 775ms를 함께 입력받아야 하므로, 프레임마다 임베딩을 얻으려면 매번 90%가량의 불필요한 중복 연산을 강제 받게 됩니다. 둘째, 오래된 플랫폼으로 제작된 모델이어서, 가속화 도구인 TensorFlow Lite (TFLite)2로의 변환이 불가능하다는 점입니다.
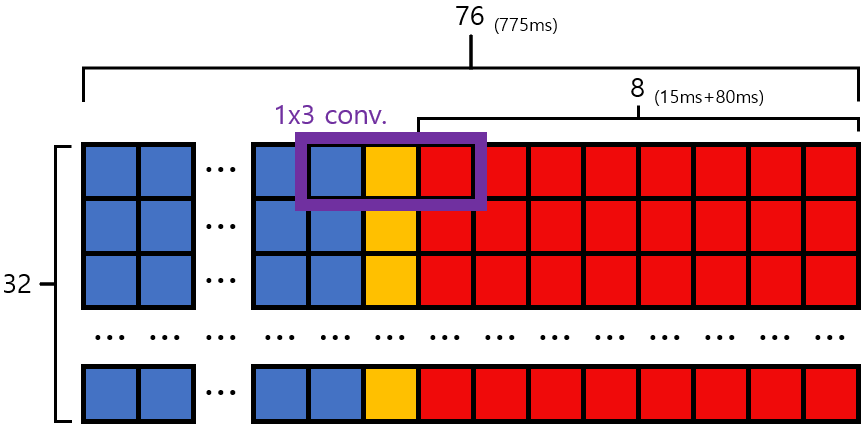 [그림 1] 개선한 음성 임베딩 모델의 구조
[그림 1] 개선한 음성 임베딩 모델의 구조
이러한 문제점들을 해결하기 위하여, 이 음성 임베딩 모델에 대수술을 진행하였습니다! 우선, TFLite 모델로의 변환이 가능하도록 최신 플랫폼의 형태로 migration 하였습니다. 이와 동시에, 새로 입력된 음성 정보로 인해 재계산 되어야 하는 빨간색, 노란색 영역만을 새로 계산하고, 중복 연산 영역인 파란색 구간은 이전 프레임의 연산 결과를 그대로 가져다 사용할 수 있도록 stream-able 형태로 모델을 개선하였습니다. 이러한 변환이 가능했던 이유는 기존 모델이 2D 컨볼루션 및 풀링 레이어만 사용하기 때문입니다. 이렇게 구조를 개선한 모델을 TFLite 변환 및 가속화한 결과, 초기 음성 임베딩 모델 대비 CPU 구동 기준 약 340배의 가속 효과를 얻을 수 있었습니다.
후, 드디어 음성 임베딩 모델을 효율적으로 사용할 준비가 끝났습니다. 이제 이러한 음성 임베딩 모델 뒤에 작은 ‘헤드 모델’을 붙여서 학습하면, 내가 원하는 호출어에 대한 딱 한 번의 예제 발화만으로도 우수한 성능의 호출어 인식 모델을 학습할 수 있게 됩니다! 이 과정에 대한 좀 더 자세한 설명은1 과, 제 논문을 참고해주세요!
2. 웹브라우저에서도 동작할 수 있는 기술
이렇게 학습한 호출어 인식 모델을 어떻게 학습하고 테스트해볼 수 있을까요? 연구자들이야 고성능 서버 환경에서 복잡한 명령어를 써 내려가며 어떻게든 모델을 학습하고 테스트해볼 수 있지만, 일반 사용자나 AI에 익숙하지 않은 개발자들은 대부분 그렇지 못할 것입니다. 그렇다고 Windows, macOS, 안드로이드, iOS 등 각 OS에서 동작하는 호출어 인식 SDK를 개별적으로 준비하기에는 배보다 배꼽이 더 커지는 상황입니다. 코드 한 벌로 OS와 관계없이 범용적으로 호출어 인식 모델을 구동할 수 있는 플랫폼은 없을까요? 또, 사용자가 쉽게 사용할 수 있는 UI를 제공하려면 어떤 플랫폼이 가장 적합할까요? 고민 끝에 내린 결론은 바로 웹브라우저 환경이었습니다! 웹브라우저(Chromium)는 Windows, macOS, Linux 등 다양한 플랫폼에서 일관된 동작을 보장합니다. 따라서, 웹 표준을 준수하여 개발할 경우, 하나의 코드 베이스로 동일한 동작을 기대할 수 있습니다. 이미 유수한 프로그램들 (VSCode, MS Teams, Discord, Slack 등) 이 동일한 방법으로 멀티플랫폼을 지원하고 있습니다. 이 때, 호출어 인식 모델이 웹브라우저에서 standalone 형태로 구동되기를 원했는데요. 낮은 지연 시간이 덕목인 호출어 인식 모델 구현을 서버-클라이언트 형태로 만드는 것보다 이 방법이 효과적이었기 때문입니다.
이렇게 다양한 요구사항들에 대한 해결책을 상상하는 건 쉬웠지만, 개발 친화적이지 않은 연구자들에게는 먼 산을 바라보며 ‘그래서 어떻게 구현해야 하지…’ 하며 막막해질 뿐이었습니다. 다행히, 저희 랩은 연구자뿐만 아니라 유능한 개발자분들도 계시기 때문에, 이러한 상상을 현실로 금세 만들어 주셨습니다! 핵심은 WebAssembly(Wasm)3 와 Emscripten4 이라는 도구를 활용하는 것이었는데요, 그 결과 웹브라우저에서도 딥러닝 모델을 standalone으로 구동할 수 있는 환경을 구축할 수 있었습니다!
 [그림 2] 본 논문에서 제안한 FES-KWS 시스템 구조도
[그림 2] 본 논문에서 제안한 FES-KWS 시스템 구조도
일반적으로 웹브라우저만으로는 딥러닝 모델을 구동할 수 없습니다. 딥러닝 모델과 라이브러리는 웹브라우저가 이해할 수 없는 형태로 작성되었기 때문입니다. 따라서 모델과 라이브러리를 웹브라우저가 이해할 수 있는 형태로 바꿔주어야 하는데요, 그 역할을 바로 Wasm 이 수행해 줍니다. Wasm은 TFLite 라이브러리를 웹브라우저가 사용할 수 있는 작고 효율적인 바이너리로 변환해 줄 수 있습니다. Emscripten Toolchain을 이용하여 TFLite 라이브러리를 Wasm으로 빌드하고 호출어 모델을 로드하면, 웹브라우저에서 호출어 인식 모델을 단독으로 구동할 수 있게 됩니다. 이 환경을 사용하면, 어떤 OS에서든 웹브라우저를 통해 키워드 호출 모델을 직접 생성하고 호출어 기능을 웹상에서 사용할 수 있게 됩니다. 개인형 디지털 휴먼 스튜디오에서 나만의 호출어를 부여하는 용도로 사용하기에 안성맞춤이죠!
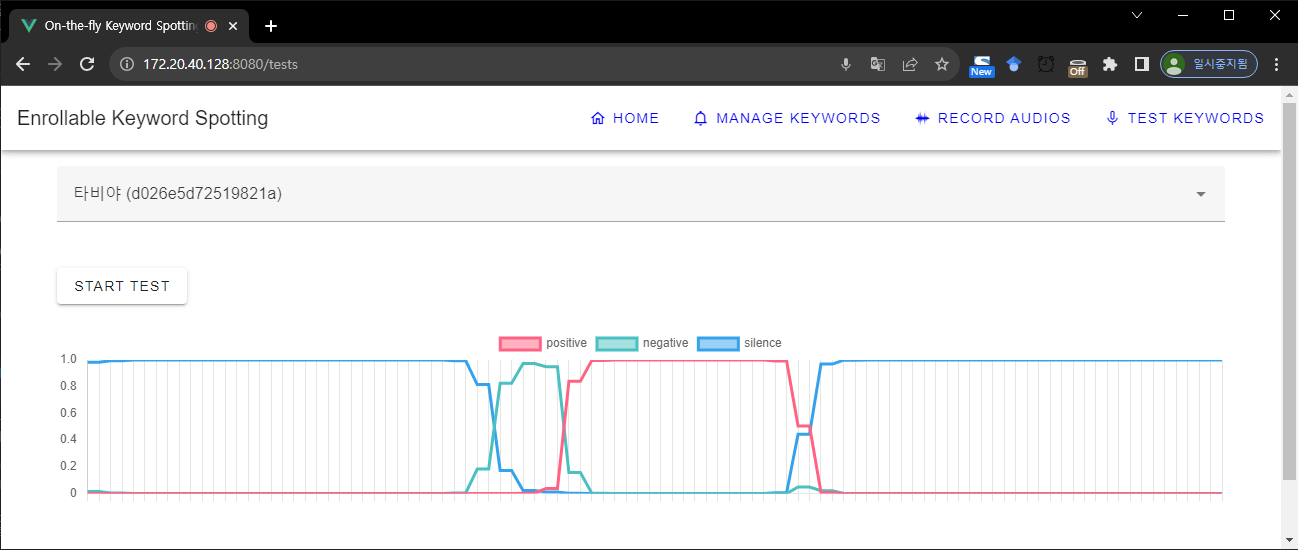 [그림 3] 웹 브라우저에서 구동되는 FES-KWS 시스템
[그림 3] 웹 브라우저에서 구동되는 FES-KWS 시스템
Outro 향후 과제가 있었는데요, 없어졌습니다.
제안한 환경을 통해 이제 사용자가 어떤 환경에서든 나만의 디지털 휴먼의 이름을 정해줄 수 있게 되었습니다! 하지만 아쉽게도, 이 시스템에는 여전히 아쉬운 점들이 몇 가지 남아있습니다. 첫째로, 적은 학습자료로 모델을 학습하다 보니, 발음이 유사한 음성 입력에 대한 false alarm 발생 확률이 높은 편입니다. 둘째로, 새로운 키워드를 학습하기 위한 학습자료의 양을 극한으로 줄였음에도 불구하고, ‘어쨌든 간에’ 사용자의 한 번 이상의 예제 발화가 필요하다는 점입니다. 사용자의 예제 발화도 필요 없고, false alarm 문제도 할 수 있는 방법은 없을까요? 이러한 고민을 하던 중에, 저희 팀의 이용혁님이 PhonMatchNet 이라는 속 시원한 모델을 제안해 주셨습니다! 이 모델을 어떻게 학습시켰는지 궁금하시다면, 용혁님의 PhonMatchNet을 살펴봐 주세요!
References
-
Lin, James, et al. “Training keyword spotters with limited and synthesized speech data.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020. ↩ ↩2 ↩3
-
TensorFlow Lite: https://www.tensorflow.org/lite?hl=ko ↩
-
WebAssembly: https://webassembly.org/ ↩
-
Emscripten: https://emscripten.org/ ↩
