
작성자
- 김글빛(Speech AI Lab)
- AI를 이용한 음성신호처리, 멀티모달 음성 감정인식, 사운드 제네레이션에 관한 연구를 하고 있습니다.
이런 분이 읽으면 좋습니다!
- 감정인식 기술에 관심이 있는 분
- 멀티모달 연구에 관심이 있는 분
이 글로 확인할 수 있는 내용
- 멀티모달 감정인식에서 데이터 부족을 해결하려는 방법과 모달리티 fusion 방법에 대한 고민
1. Intro
요즘 우리는 기계와 대화하는 것에 그렇게 어색하지는 않습니다. ‘시리야 날씨 알려줘’, ‘Ok구글 기분도 우울한데 신나는 음악 좀 틀어봐!’ 등등 자주 사용하는 패턴과 요구에 기계들은 언제나 정확한 답변을 해줍니다. 그러나 우리는 진짜 대화하고 있는 걸까요? 일상적인 소통이 가능한 ‘이루다’ 서비스나 chatGPT의 등장으로, 사람처럼 대화하는 기계에 대한 관심이 늘고 있습니다. 아마도 ‘튜링 테스트1에 통과했다’가 아니라 ‘이거 사람이 대답하는 것 같은데?’라는 생각이 드는 기계가 곧 나올지도 모르는 일입니다.
NC는 “진짜 사람” 같은 디지털 휴먼을 만드는 목표를 갖고 있습니다. 사람은 능숙하게 상대의 감정을 잘 파악해서 그 상황에 적절한 대화를 이끌어 나가지만 기계는 아직 그렇게 하지 못하고 있습니다. 사람은 상대방의 말뿐만 아니라, 시선, 목소리의 떨림, 손짓, 상황 등 느낄 수 있는 모든 정보 (modality)를 종합하여 유추하는 것에 능숙하지만, 대부분의 감정인식 기술은 single-modality에 기반하기 때문입니다.
이 글에서는 INTERSPEECH 2023에 게재한 멀티모달 감정인식(Multimodal Emotion Recognition: MER)의 연구 과정을 소개하고자 합니다. MER이란 앞서 말했듯이 사용할 수 있는 여러 모달리티를 이용하여 감정을 인식하는 기술입니다. 저희 MER 연구에서는 말과 음성 두 가지 모달리티를 함께 사용하였습니다. 아직 만족할만한 성능에 도달하지는 못하였지만, 비슷한 주제로 고민하시는 분들께 도움이 되었으면 합니다.
2. 연구 동기와 목표
감정인식은 인간의 텍스트, 음성, 표정 등으로부터 감정을 인식하는 태스크입니다. 말 그대로 경멸하는 얼굴인지 기쁨을 드러내는 문장인지 화난 목소리인지 등을 인지하는 것이죠. 한 가지 예를 들어보겠습니다. 아래 텍스트를 읽어보면, 어떤 감정이 느껴지시나요?
‘멋지다, 연진아.’
“더 글로리”를 보지 않은 분들은 친구를 축하하고 있으니 기쁜 문장이라는 생각이 드실 겁니다. 하지만 이 드라마를 봤다면, 절대 기쁨의 문장이 아니라는 것을 알고 있습니다. 배우의 억지스러운 표정, 과장된 행동, 비꼬는 억양, 연진이와의 과거, 그리고 대화 맥락과 같은 여러 모달리티를 알고 있기 때문입니다. 그렇습니다. “진짜 사람” 같은 감정인식을 구현하려면 많은 모달리티를 복합적으로 살펴야만 합니다. 신기하게도, 음성 신호는 텍스트, 억양, 소리의 높낮이, 속도와 같은 정보들을 모두 포함하고 있으므로, 그 자체로 이미 멀티모달입니다. 그래서, 음성 신호에 포함된 다양한 정보를 활용하는 것으로 멀티모달 감정인식 연구를 시작하게 되었습니다.
 그림 1. 드라마 “더 글로리”의 한 장면 (출처.넷플릭스)
그림 1. 드라마 “더 글로리”의 한 장면 (출처.넷플릭스)
멀티모달 감정인식 연구가 데이터 측면에서 어려운 이유는 감정이 레이블링 된 데이터 자체가 부족하다는 것과 음성, 텍스트 각각 모달리티의 감정 데이터가 아닌 여러 모달리티와 감정 레이블이 묶인 paired data가 부족하다는 점입니다. 다행히도, 데이터를 충분히 수집하기 어렵거나 제약이 있는 경우에 대응하기 위한 방법으로 자기지도학습(self-supervised learning; SSL)을 활용할 수 있습니다. 자기 지도학습이란 레이블 되지 않은 데이터로부터 task-agnostic하게 데이터를 잘 표현하는 좋은 representation을 얻는 방법입니다. 이 기술을 활용해 자연어 처리나 음성 인식 분야에서 많은 성과를 보인 바 있습니다. 이를 활용하면 downstream 태스크에 전이 학습을 통해 좋은 성능을 낼 수 있습니다. 멀티모달 감정인식 연구에서도 감성 레이블이 없는 방대한 양의 데이터로부터 학습된 음성과 텍스트의 SSL 모델이 감정인식 성능에 도움이 될 것이라고 생각했습니다.
 그림 2. SSL 모델
그림 2. SSL 모델
멀티모달 감정인식 연구에서 중요한 요소 중 하나는 각 모달리티에서 감정을 판단하는데 유용한 정보가 어떤 부분인지를 파악하는 것입니다. 예를 들어 볼까요?
“하아, 주식이 폭락해서 정말 미치겠다”
텍스트에서는 ‘폭락’, ‘미치겠다’라는 부정적인 단어에서 감정을 판단할 수 있고, 음성 신호로부터는 문장 앞의 한숨 소리와 어미에서의 힘없는 발화에서 슬픈 감정들을 판단할 수 있습니다. 즉 각각의 모달리티의 서로 다른 부분에 포커스를 맞추어 감정을 인식해야 합니다. 이렇게 “사람 같은” 인지 메커니즘을 반영하기 위해 모델의 네트워크를 어떻게 설계할지가 큰 고민이었습니다. 그뿐만 아니라, 감정 분류기가 더 잘 동작할 수 있는 손실함수에 대한 고민도 필요했습니다.
3. 제안 방법
먼저 “모달리티 임베딩 네트워크”는 각각의 텍스트, 음성에서 감정인식에 필요한 언어적, 음향적 정보를 얻는 과정입니다(그림 3에서 분홍색 영역). 앞서 언급했던 것처럼 다른 거대 데이터로 학습한 pre-trained SSL 모델로 감정 데이터의 부족을 보완합니다. 종전의 감정인식에서는 텍스트 정보를 활용하기 위해 Glove1와 같은 단순한 워드 임베딩 모델을 사용했습니다. 워드 임베딩 모델도 텍스트의 언어적 정보를 반영하지만 단어의 유사도에 기반한 모델입니다. 그래서 문장 단위의 의미를 반영하기에는 성능이 떨어집니다. 반면, 이번 논문에서 사용한 RoBERTa2의 경우 방대한 텍스트 데이터로 학습되어 문맥 정보가 반영된 보다 나은 임베딩 추출이 가능합니다. 한편 음성의 경우, Wav2vec 2.03 이라는 pre-trained SSL 모델을 사용했습니다. Wav2vec 2.0은 레이블 되지 않은 대량의 음성 데이터로 학습된 음성 임베딩 모델이며, 음성 인식 태스크에서 좋은 성능을 입증한 모델입니다. 여기에 운율, 세기와 같은 음향학적 정보를 잘 반영할 수 있는 구조를 추가하여 음성 임베딩으로 사용했습니다.
 그림 3. 논문의 전체적인 구조
그림 3. 논문의 전체적인 구조
그다음으로 해야 할 것은 두 개의 모달리티에서 뽑은 임베딩을 잘 해석할 수 있는 fusion network를 설계하는 것입니다 (그림 3에서 회색 영역). 우리는 대화를 듣고 감정을 판단할 때 감정이 드러나는 부분을 빠르게 파악하고 이를 통해 감정을 인식합니다. 예를 들어, 떨리는 음성이나 부정적인 단어로부터 슬픔을 느끼거나, 강조하여 말하는 단어가 무엇인지를 파악하며 감정을 인식합니다. 이러한 인지과정을 네트워크로 모델링 하려는 고민에서 각 모달리티의 중요한 부분을 파악(집중)할 수 있는 구조가 필요합니다. 그래서, 두 개의 서로 다른 모달리티의 입력이 들어올 때 attention이나 align을 모델링하는 crossmodal transformer 구조에 문단 요약 태스크4 에서 제안된 focus-attention 메커니즘을 함께 적용한 구조를 제안했습니다.
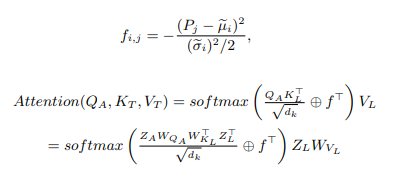
이것은 본 논문에서 제안한 방식으로써, 기존의 crossmodal attention을 구하는 과정에서 다른 모달리티의 중요한 위치정보(수식에서 \(f_{i,j}\))를 추가해 주는 것을 볼 수 있습니다. (자세한 수식은 논문에서 확인할 수 있습니다.)
이제 이러한 인지 메커니즘을 반영하기 위한 학습 전략(?) 을 고민한 끝에, 같은 감정은 비슷한 분류 공간에 위치하게 하고 서로 다른 감정은 서로 다른 분류 공간에 위치하게 하도록 유도하는 metric learning 테크닉을 적용하였습니다. Metric-learning에서 많이 사용하는 triplet loss5와 기존의 분류기에서 사용되는 cross entropy loss를 joint loss로 설계하여, 감정 임베딩 공간에서의 서로 감정 벡터들이 잘 분리되도록 하였습니다. 이를 간단히 시각화하면 그림 4와 같습니다. 아래 그림처럼 기준이 되는 anchor와 같은 감정인 positive 샘플은 가깝게, 다른 감정인 negative 샘플과는 멀게 학습하는 방법입니다.
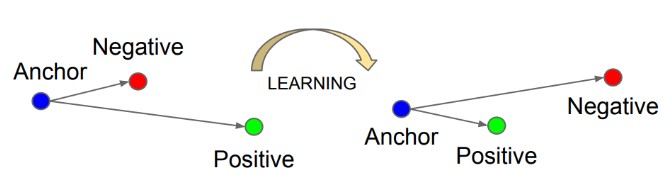 그림 4. Metric learning에서 많이 사용되는 triplet loss 설명 도식도
그림 4. Metric learning에서 많이 사용되는 triplet loss 설명 도식도
4. 결론 및 맺음말
이번 연구에서는 텍스트와 음성을 이용하는 멀티모달 감정인식 시스템에서 데이터 부족 문제를 해소하고자 pre-trained SSL 모델을 사용하고, 서로 다른 모달리티의 중요한 부분을 파악하는 새로운 모달리티 fusion 방식을 제안했습니다. 이를 검증하기 위해 멀티모달 감정인식에서 가장 널리 사용되는 IEMOCAP 데이터에서 성능을 확인하였습니다. 음성과 텍스트를 사용하는 멀티모달 감정인식 태스크에서 기존의 모델(LM-MulT, MHA-2 등)의 성능보다 향상된 77.7%의 정확도를 보입니다(표 1).
 표 1. IEMOCAP 데이터에서 다른 멀티모달 감정인식 모델들과의 비교
표 1. IEMOCAP 데이터에서 다른 멀티모달 감정인식 모델들과의 비교
사람처럼 감정을 인지한다는 것은 분명 난이도가 높은 연구 주제입니다. 단기간에 성과가 두드러질 수 있는 연구는 아닙니다. 그런데도 이 연구에 매진하는 이유는 “진짜 사람” 같은 디지털 휴먼을 만들기 위해 감정인식은 마지막 퍼즐 조각임이 분명하기 때문입니다. 감정인식 관련하여 연구해 나갈 수 있는 주제는 무궁무진합니다. 얼굴에 드러나는 표정까지 생각하는 확장된 모달리티, 문맥 정보와 상황을 이해하는 감정인식, 대규모 언어모델과 결합하는 연구, 복합적인 감정을 파악하는 방법 등 할 수 있는 것들이 아직도 많이 남아있습니다.
NC에는 오늘도 사람에 가까운 디지털 휴먼 개발을 위해 여러 연구자, 개발자분들이 함께 애쓰고 계시는데요. 이번 연구가 훗날 NC가 만들 사람의 감정을 읽고, 공감해줄 디지털 휴먼 연구에도 도움이 되었으면 합니다. 다음에 또 좋은 기회에 더 재미있는 연구와 기술 소개 글로 찾아뵙겠습니다.
References
-
Pennington, J., Socher, R., & Manning, C. D. (2014, October). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543). ↩
-
Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019. ↩
-
A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020. ↩
-
Y. You, W. Jia, T. Liu, and W. Yang, “Improving abstractive document summarization with salient information modeling,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 2132–2141 ↩
-
Schroff, F., Kalenichenko, D., & Philbin, J. (2015). Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 815-823). ↩
