
- R-Drop: Regularized Dropout for Neural Networks (NeurIPS 2021)
- Guiding Teacher Forcing with Seer Forcing for Neural Machine Translation (ACL 2021)
- Confidence Based Bidirectional Global Context Aware Training Framework for Neural Machine Translation (ACL 2022)
- The Importance of Being Parameters: An Intra-Distillation Method for Serious Gains (EMNLP 2022)
- Unifying the Convergences in Multilingual Neural Machine Translation (EMNLP 2022)
- 마치며
- References
전통적인 의미의 Knowledge Distillation1 (KD)은 Teacher model이 가지고 있는 지식을 Student model에 잘 전달하여 Student model의 성능을 향상시킨다는 관점에서 출발하였습니다. 이를 위해서는 특정 Task를 해결하기 위한 지식이 풍부한 Teacher model 구축이 필요한데, 필연적으로 이 모델은 많은 데이터로부터 Training하기 위해 큰 사이즈를 가져야 하기 때문에 Teacher model을 잘 구축하는 것 자체도 작은 일이 아닙니다. 오늘 소개드릴 방법론은 학습 데이터와 파라미터 숫자에서 Student model을 압도하는 Teacher model을 가정하지 않고, Student model과 거의 동등한 수준의 모델로부터 Training하거나 또는 Student model끼리의 상호 Training을 통해 자체 성능을 향상시키는 Self-distillation 기술입니다. 논문에 따라 제안 기술을 부르는 명칭이 다를 수 있는데, 여기에서는 위에 서술한 특징을 가지는 Training 방법을 통칭하여 Self-distillation으로 묶어서 특히 텍스트 생성 업무에서 성능 향상이 보고된 연구들을 소개해 보겠습니다.
R-Drop: Regularized Dropout for Neural Networks2 (NeurIPS 2021)

실행 방법이 간단명료하면서도 범용적으로 성능이 향상됨을 확인한 R-drop 방법을 가장 먼저 소개하고자 합니다. 이 연구에서는 하나의 모델과 임의의 입력 x가 주어졌을 때, x를 모델에 독립적으로 두 번 입력하여 각각의 확률 분포 \(P_1\)과 \(P_2\)를 출력받습니다. 모델에 기본적으로 적용되는 Dropout으로 인해 두 번의 연산 과정은 동일하지 않기 때문에 출력 \(P_1\)과 \(P_2\)도 미세하게 다른 값을 갖게 되는데, 같은 입력에 대해서는 출력되는 값도 같아야 하므로 두 확률 분포값 \(P_1\)과 \(P_2\)를 일치시키는 추가 Training을 하자는 것이 이 연구의 핵심 내용입니다.
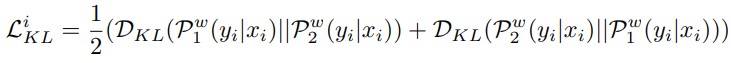
분포를 일치시키기 위해 \(P_1\)과 \(P_2\) 간의 KL divergence3값을 최소화하는 Loss가 추가되는데, 오늘의 연구 소개 글에서 주목하는 부분이기도 합니다. 식을 보면 서로간에 KL divergence 값을 최소화하도록 하는데, 일반적인 KD에서 Teacher-Student간 생성 분포에 KL divergence 최소화를 통해 Training이 진행되는 형태를 생각해 보면 여기에서는 자기 자신의 생성 분포 사이에서 KD Training이 이루어지는 형태가 됩니다. R-drop 논문에서는 이를 Consistency training, Self-distillation의 개념으로 소개하였습니다. 이와 같은 Self-distillation loss를 추가하여 Training된 모델은 Neural Machine Translation (NMT), Natural Language Understanding (NLU), Summarization, Language Modeling (LM), Image Classification과 같은 다양한 Task에서 성능이 향상되었다고 합니다.
Guiding Teacher Forcing with Seer Forcing for Neural Machine Translation4 (ACL 2021)


이 연구에서는 Seer decoder라고 이름 붙인 모델로부터 KD를 수행해 성능을 향상시킵니다. Seer decoder는 Student model과 같은 학습 데이터를 이용해 Training시키지만, Training 과정에서 각 Token 생성할 때 이후 생성될 Token의 정보까지 참조합니다. Inference시에는 미래에 생성될 Token을 알 수 없지만, Training 단계에서는 정답 문장으로부터 미래 생성될 Token을 알 수 있기 때문에 이런 방법이 가능해집니다. 두 모델에서 Encoder는 같이 공유합니다. Seer decoder는 원래 Student model의 Decoder와는 약간 구조가 다른데, 그림과 같이 기존의 Transformer5에서 Target 부분에 적용되는 Mask 대신 Future mask, Past mask 두 개 각각을 따로 적용하여 두 결과를 결합하여 최종 생성 분포를 만들어냅니다. 이와 같이 Training된 Seer decoder로부터 지식을 전달받은 Student model은 향상된 번역 성능을 보였다고 합니다. 이 방법은 Teacher model과 Student model의 구조가 동일하지 않기 때문에 Self-distillation으로 볼 수는 없지만, 동일한 학습 데이터로 Training된 Teacher model로부터의 KD가 성능 향상을 가져올 수 있다는 부분이 주목할 만 하다고 생각합니다.
Confidence Based Bidirectional Global Context Aware Training Framework for Neural Machine Translation6 (ACL 2022)
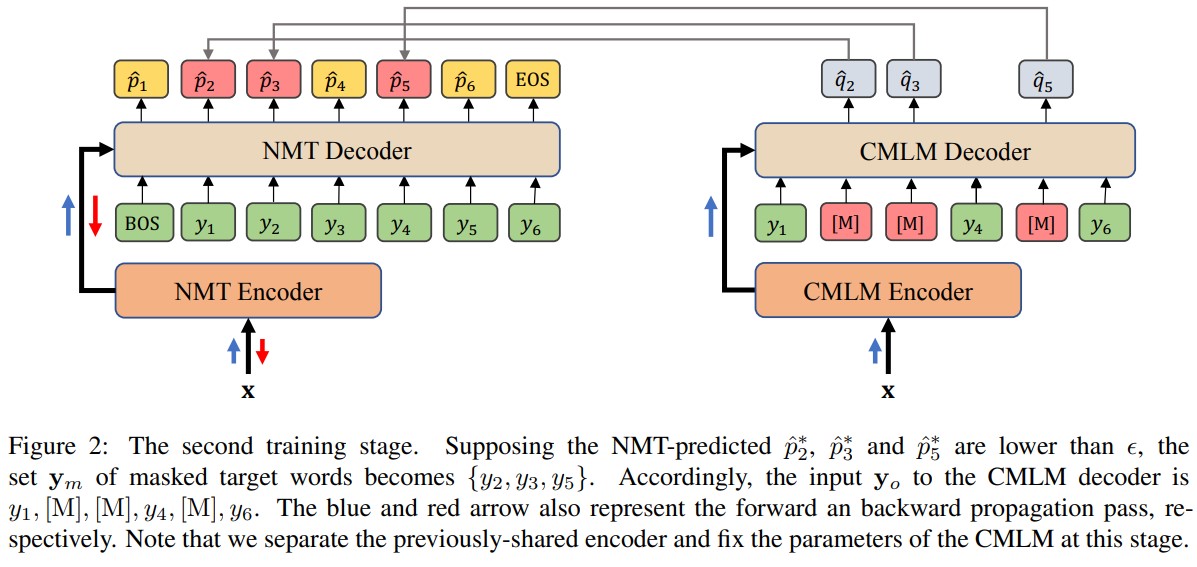
방금 위에서 소개 드린 Seer decoder를 이용한 KD와 유사한 방법론 하나 더 소개해 보겠습니다. 이 연구에서는 Conditional Masked Language Model (CMLM)이라는 것을 만들어 여기로부터 KD를 수행하는데, 위 연구와의 차이점을 간단히 정리하면 아래와 같습니다.
- CMLM을 Training하는 과정에서 생성 Token의 양쪽 Context를 모두 참조하게 되는데, 위의 Seer decoder와 다르게 여기에서는 Student model과 동일한 구조로 Training을 진행하며 masked target을 예측하는 방식의 학습 과정이 적용됩니다. (BERT7 학습 방법과 유사)
- 모든 Token에 대해서 KD를 수행하지 않고, Confidence가 낮은 Token을 선정하여 해당 Token에 대해서만 KD를 수행하였습니다. (Confidence Based Knowledge Distillation)
- Training 초반에는 KD 학습의 비중이 크지만, Training이 진행되면서 점차적으로 KD 학습의 비중을 줄이고 원래의 정답 기반의 Cross entropy 학습 비중이 커지도록 Objective function을 정의했습니다.
제안한 방법론에 따라 학습된 모델 또한 NMT에서 향상된 번역 성능을 보였습니다. 방금 소개드린 두 연구에서는 Teacher model이 같은 학습 데이터로 Training되었더라도, 그 과정에서 Target token의 이후 생성 Token 등의 Bidirectional global context 추가 정보가 있을 경우 성능이 향상되었음을 보여줍니다. 좀 더 생각해 보면 미래의 생성 Token 정보만이 아니라 그 외에 성능 향상에 도움이 될 것으로 예상되는 다른 추가 정보를 Teacher model이 배우게 해서, 학습 데이터의 증가 없이도 추가적인 성능 향상이 가능할 수도 있습니다.
The Importance of Being Parameters: An Intra-Distillation Method for Serious Gains8 (EMNLP 2022)
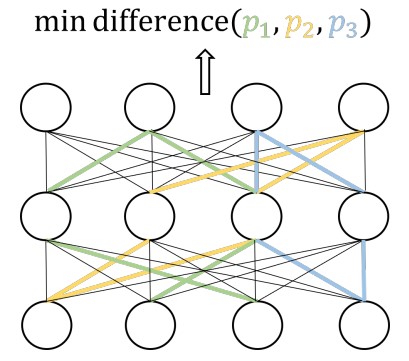
이 연구는 맨 처음에 소개한 R-drop과 다른 동기에서 출발하였지만, 결과적으로 상당히 유사한 방법론으로 진행된 것이 흥미롭습니다. 이 연구가 시작된 동기를 설명하면 하나의 모델 내에서 각 파라미터의 기여도가 다르고 이 기여도가 불균형할수록 모델의 효율성이 떨어지기 때문에, 각 파라미터의 기여도가 균등해지도록 유도하는 것을 목표로 합니다. 이를 위해 Training 시에 K(=3)개의 다른 Sub-model에 동일한 입력을 넣고 각 출력을 일치시켜 각 Sub-model의 파라미터가 성능 향상에 기여하도록 합니다(Sub-model에서 제외된 파라미터가 Back-propagation에 참여하지 않기 때문에 특정 파라미터들의 과도한 학습을 막을 수 있습니다). 이 때 Sub-model을 구하는 방법으로 Dropout을 이용하는데, 결국 큰 틀에서 R-drop과 같은 학습 형태가 됩니다.
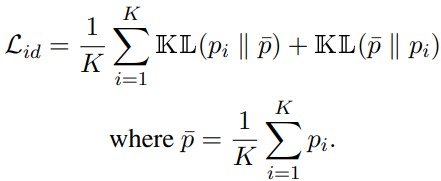
두 개의 생성 확률 분포를 가정한 R-drop과는 다르게 K개의 생성 확률 분포 간의 거리를 최소화하기 때문에 서로간의 거리를 직접적으로 계산하면 계산복잡도가 \(O(K^2)\)가 되는데, 이에 대한 대안으로 X-divergence라고 이름 붙인 방식을 제안, 적용하였습니다. 위 수식에서 보듯이 X-divergence는 각 분포 간의 거리를 직접 최소화하지 않고, 평균값을 계산한 뒤에 평균값과 분포 간의 KL divergence를 최소화하게 됩니다. X-divergence 방식으로 Loss 계산시 계산 복잡도가 \(O(K)\)로 감소하는 것뿐 아니라 실제 성능도 약간 향상되었다고 합니다.
NMT, NLU 등에서의 성능 보고에서 R-drop에 비해 성능이 높아졌음을 보였지만 NMT 실험은 비교적 소규모 데이터셋인 IWSLT에서만 수행되었으며, R-drop과의 성능 차이가 유의미할 정도로 큰지에 대해서 의문스러운 점이 있습니다. 그럼에도 불구하고 Dropout을 이용한 Sub-model간의 출력 일치 방법이 파라미터의 학습 불균형 해소와 연관이 있다는 해석은 생각해 볼 만한 가치가 있습니다.
Unifying the Convergences in Multilingual Neural Machine Translation9 (EMNLP 2022)
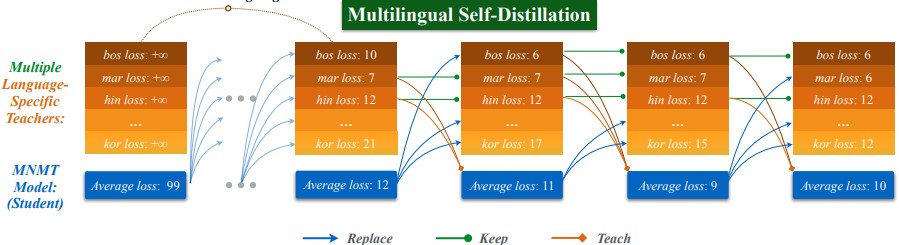
마지막으로 소개드릴 것은 Multilingual NMT10 (MNMT)라는 특수한 Task에서의 연구입니다. MNMT가 기존의 NMT와 다른 것은 두 개 이상의 언어 쌍을 하나의 모델에서 번역하도록 학습한다는 것입니다. MNMT Training 시 발생하는 문제 중 하나는 임의의 Checkpoint에서 어떤 언어 쌍의 성능은 학습이 충분히 되지 않았거나 (Underfitting), 어떤 언어 쌍의 성능은 과도하게 학습이 진행되어 (Overfitting) 언어 별 성능이 최적화되지 않는 현상입니다. 이 문제가 발생하는 근본적인 원인은 각 언어의 특성 차이, 학습 말뭉치 간의 불균형 등으로 인해 모델 Training 시 언어별 최적 성능으로의 수렴 epoch가 제각각 다르기 때문입니다 (Convergence Inconsistency). 이 연구에서는 위의 문제를 해결하기 위해 모델 자기 자신으로부터 각 언어별 최고 성능을 가지는 Teacher model을 뽑아낸 후, 여기로부터 KD를 통해 학습하는 방식(Language-Specific Self-Distillation, LSSD)을 제안하였습니다. 이 과정을 좀 더 자세하게 설명하면 아래와 같습니다.
- L개의 언어 쌍을 학습할 경우, Training을 시작할 때 학습의 대상이 되는 Student model 1개와 이것을 L번 복사한 L개의 Teacher model을 준비합니다.
- 일정 기간 동안 Student model을 학습하고, 이를 역시 Teacher model에 복사합니다.
- 이후 Training에서 각 Epoch마다 언어 쌍 담당 Teacher model의 loss와 Student model의 loss를 각각 체크합니다.
- 임의의 Teacher model의 Loss가 Student model의 Loss보다 클 경우 (Teacher의 성능이 낮을 경우), 현재의 Teacher model을 폐기하고 현재의 Student model을 복사합니다.
- 임의의 Teacher model의 loss가 Student model의 Loss보다 작을 경우 (Teacher의 성능이 높을 경우), Teacher model을 그대로 유지하고, 다음 Epoch의 Training 기간 동안 Student model로의 KD를 수행합니다.
위의 방법을 따를 경우, Student model에서 성능 향상이 빠르게 달성된 언어 쌍의 경우 Teacher model이 교체되고, 이후 지속적인 KD를 통해 빠르게 고점에 도달한 성능을 유지할 수 있습니다. 특정 언어 쌍에서의 Student model에서의 성능 향상이 계속 진행될 때마다 Teacher model은 업데이트되고, Student model에서의 성능이 더 이상 높아지지 않거나 낮아지면 기존의 Teacher model은 유지된 상태로 지속적으로 KD를 수행합니다. 비유하자면 20살 때의 수학을 잘하던 나, 30살 때의 영어를 잘하던 나를 그 시점에 복제해 두고, 점점 나이가 들어 해당 능력이 떨어지게 되더라도 당시의 내가 선생님이 되어 계속하여 현재의 나를 가르쳐 주는 겁니다. 이와 같은 방식으로 Training이 진행되었을 경우, Many-to-One model (여러 언어를 하나의 언어로 번역하는 모델)과 One-to-Many model (하나의 언어를 여러 개의 언어로 번역하는 모델)에서 모두 성능 향상을 확인할 수 있었습니다.
이 연구가 인상적인 점은 Self-distillation이라는 학습 방법이 단순히 하나의 모델 성능을 좀 더 향상시키고자 하는 기존의 목적을 넘어, 하나의 모델이 학습하는 여러 대상을 담당하는 독립적인 Teacher model들을 자기 자신으로부터 복사한 뒤, 각각의 성능을 KD를 통해 유지 또는 향상시킬 수 있다는 것입니다. 여기에서는 NMT model에서의 다양한 학습 언어 쌍이 그 대상이 되었지만, 여러 개의 Task를 학습하는 Multi-task 모델 또는 여러 개의 Domain을 대상으로 학습하는 임의의 모델에서도 같은 방식이 동작할 가능성이 있습니다.
마치며
최근의 NLP 연구는 대규모 언어 모델(Large Language Model, LLM)을 활용하여 범용 AI에 가까운 모델을 구현하는 방향이 주목받고 있습니다만, LLM에서의 Fine-tuning의 중요도 또한 결코 낮지 않으며 LLM 등장 이전의 상대적으로 작은 모델을 Task 특화 Fine-tuning하는 전통적인 학습 방식도 비용 효율성을 고려할 때 여전히 유효합니다. 오늘 소개해 드린 Self-distillation 관련 방법론들은 Fine-tuning 학습의 고도화라는 관점에서 충분히 가치가 있고 실용성도 상당히 높다고 생각합니다. 저희 생성번역기술실에서는 Self-distillation 기술을 포함하여 다양한 관점의 Fine-tuning 기법을 적용하여 한정된 자원 상황에서 최적의 성능을 달성할 수 있도록 연구 및 개발을 계속하여 진행하겠습니다.
References
-
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015). ↩
-
Wu, Lijun, et al. “R-drop: Regularized dropout for neural networks.” Advances in Neural Information Processing Systems 34 (2021): 10890-10905. ↩
-
“Kullback–Leibler divergence” Wikipedia, The Free Encyclopedia. Wikimedia Foundation, Inc. 15 Feb. 2023. Web. 22. Feb. 2023. ↩
-
Feng, Yang, et al. “Guiding Teacher Forcing with Seer Forcing for Neural Machine Translation.” Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. ↩
-
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017). ↩
-
Zhou, Chulun, et al. “Confidence Based Bidirectional Global Context Aware Training Framework for Neural Machine Translation.” Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. ↩
-
Devlin, Jacob, et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. ↩
-
Haoran Xu, Philipp Koehn, and Kenton Murray. “The Importance of Being Parameters: An Intra-Distillation Method for Serious Gains” Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. ↩
-
Huang, Yichong, et al. “Unifying the Convergences in Multilingual Neural Machine Translation.” Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. ↩
-
Johnson, Melvin, et al. “Google’s multilingual neural machine translation system: Enabling zero-shot translation.” Transactions of the Association for Computational Linguistics 5 (2017): 339-351. ↩
