
작성자
- 김민선(VARCO 개발실)
- 모델을 실제 서비스에 적용하기 위해 API화하고 추론 성능을 최적화하고 있습니다.
이런 분이 읽으면 좋습니다!
- LLM을 실제 서비스에 적용하셔야 하는 분
- LLM의 추론 성능 최적화가 필요하신 분
이 글로 알 수 있는 내용
- In-flight Batching과 Paged Attention에 따른 모델 추론 성능 변화를 알 수 있습니다.
- 양자화 방법에 따른 모델 추론 성능 변화를 알 수 있습니다.
들어가며
최근 자연어 처리 분야에서 언어 모델의 크기와 복잡도가 계속해서 증가하고 있으며, 이와 함께 효율적인 추론(inference)을 수행하는 것이 중요한 과제로 떠오르고 있습니다. 수백억 파라미터를 가진 LLM뿐만 아니라, 상대적으로 작은 모델(sLLM)에서도 실시간 응답성과 자원 최적화는 서비스 성능과 비용 효율성을 높이기 위해 필수적입니다.
이 글에서는 TensorRT-LLM과 vLLM이라는 두 가지 기술을 활용하여 sLLM의 추론을 어떻게 최적화할 수 있는지 자세히 살펴보겠습니다. 이론적인 내용보다는 실제 모델에 적용하고 테스트한 결과를 중심으로 다루었습니다. Transformer Decoder 구조와 추론 과정에 대한 기본적인 이해가 있는 독자를 대상으로 작성했습니다.
테스트 환경
모든 테스트는 저희 Text2Cypher 모델을 사용하여 수행했습니다. 해당 모델은 Llama31 아키텍처 기반으로 한 8B 크기의 모델로 사용자 질문을 Neo4j(GraphDB)의 쿼리 언어로 변환합니다. Llama3는 grouped query attention을 사용하는 Decoder-Only Transformer 아키텍처로 구성되어 있습니다.
실제 서비스 환경에서의 성능을 평가하기 위해, 토큰 단위 성능이 아닌 실제 서비스에서 사용될 만한 요청들을 대상으로 end-to-end 추론 성능 테스트를 진행하였습니다. 모든 테스트는 NVIDIA A30 GPU 한 장에서 수행되었으며, CPU와 메모리 사용량은 이번 분석에서 제외했습니다.
모델의 생성 품질을 평가하기 위해, ‘Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task’2에 나오는 Exact Matching(EM)과 Execution Accuracy(EX)를 기준으로 품질 저하를 측정하였습니다.
TensorRT-LLM3은 Triton Inference Server에서 Triton TensorRT-LLM backend4를 사용하였고 vLLM은 vLLM 자체 OpenAI-compatible API server를 사용하였습니다.
주의 사항
이 글에서는 Triton Inference Server에서 Triton TensorRT-LLM backend 사용해서 모델을 서빙한 것을 ‘TensorRT-LLM’으로 vLLM 자체 OpenAI-compatible API server를 사용해서 모델을 서빙한 것을 ‘vLLM’으로 축약해서 부를 예정입니다.
사전 지식
TensorRT-LLM
TensorRT-LLM3은 NVIDIA에서 개발한 오픈소스 라이브러리로, NVIDIA GPU에서 LLM 추론 성능을 최적화하는 데 특화되어 있습니다. TensorRT engine, C++ 런타임 최적화 등 다양한 기술을 통해 모델의 추론 속도를 향상시킵니다. Huggingface 모델들을 사용하기 위해서는 TensorRT engine을 빌드하는 등 추가적인 작업이 필요합니다. NVIDIA Triton Inference Server를 활용하여 모델 서빙을 할 수 있습니다.
vLLM
vLLM5은 사용이 간편하면서도 빠른 LLM 추론 및 서빙을 위한 라이브러리입니다. Attention의 Key와 Value의 효율적인 메모리 관리를 지원하는 Paged Attention 기술을 핵심으로 사용합니다. 최적화된 CUDA 커널을 사용하여 추론 속도를 높이며, NVIDIA GPU뿐만 아니라 AMD와 Intel GPU, 심지어 CPU에서도 사용할 수 있어 다양한 환경에서 사용이 가능합니다. Huggingface 모델들과 쉽게 통합할 수 있고 OpenAI-compatible API server를 제공하여 쉽고 간단하게 모델 서빙을 할 수 있습니다. 추가로, NVIDIA Triton Inference Server를 활용하여 모델 서빙을 할 수 있습니다.
모델 추론 최적화
In-flight Batching과 Paged Attention
In-flight Batching
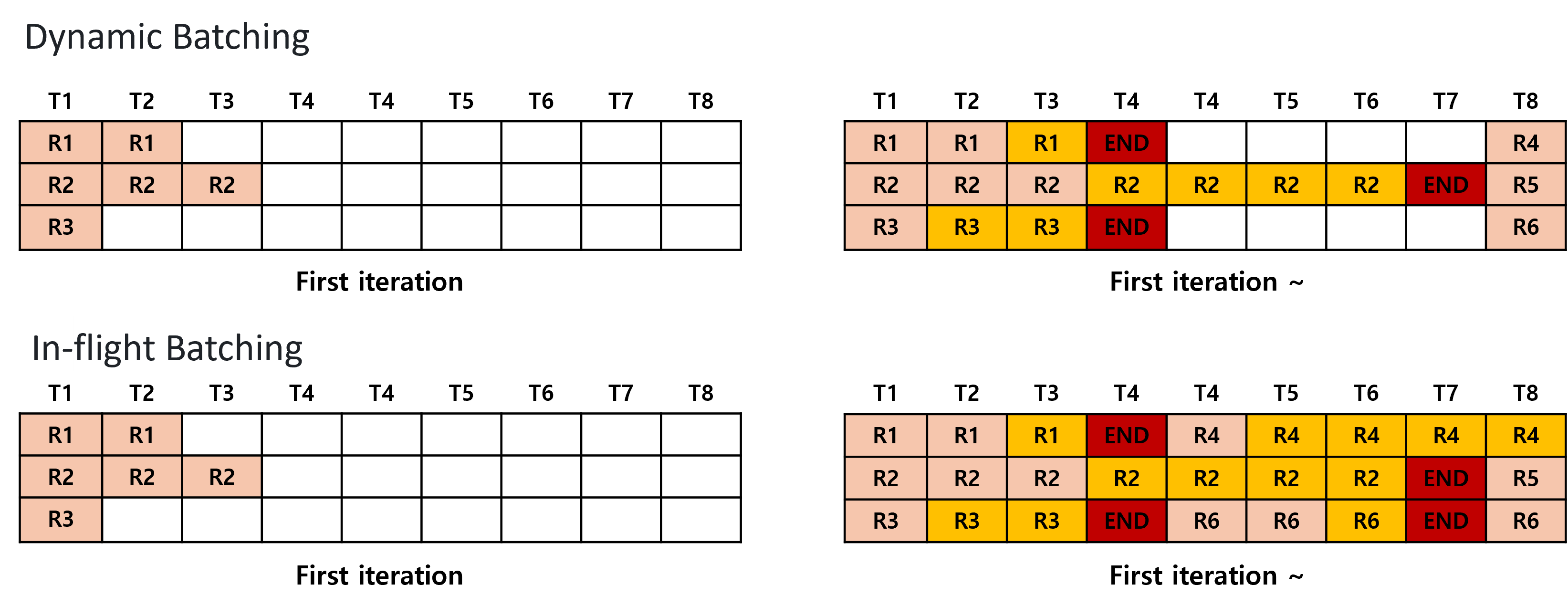
그림1. Dynamic Batching과 In-flight Batching
그림1에서 ‘R’은 개별 요청을 나타내며, 살구색은 입력 토큰을, 노란색은 생성된 토큰을 의미합니다. ‘T’는 시간을 의미합니다. ‘END’는 요청 처리가 완료됨을 표시합니다.
In-flight Batching을 이해하기 위해서는 먼저 널리 사용되는 Dynamic Batching에 대해 알아볼 필요가 있습니다.
Dynamic Batching은 한 번에 하나의 요청만 처리할 수 있는 한계를 극복하기 위해 등장했습니다. 그림1과 같이 여러 요청(request)을 동적으로 모아 하나의 배치(batch)로 처리하여 GPU utilization을 극대화 합니다.
하지만 LLM은 자기회귀적(autoregressive) 특성 때문에, 각 반복(iteration)마다 하나의 토큰을 생성하고, 생성이 끝날 때까지 이 과정을 반복합니다. Dynamic Batching은 요청 단위로 배치를 처리하기 때문에, 하나의 배치 안에 다양한 길이의 문장을 가진 요청들이 있을 때, 생성이 빨리 끝난 요청도 생성이 늦게 끝난 문장이 모두 끝날 때까지 반환되지 않습니다. 이로 인해 Dynamic Batching만으로는 최적의 효율성을 달성하기 어려웠습니다.
이러한 한계를 극복하기 위해 In-flight Batching이 등장하였습니다. 처음 Orca6 논문에서 소개된 이 기법은 Continuous Batching 또는 Iteration Batching이라고도 불립니다. Dynamic Batching이 요청 단위로 배치를 스케줄링하는 것과 달리, In-flight Batching은 Iteration 단위로 배치를 스케줄링합니다.
그림1 처럼, Dynamic Batching은 배치 내의 모든 문장이 생성을 완료할 때까지 기다렸다가 다음 배치를 처리하는 반면, In-flight Batching은 모든 문장의 생성이 완료될 때까지 기다리지 않고 Iteration 단위로 새로운 배치를 스케줄링합니다.
TensorRT-LLM과 vLLM 모두 In-flight Batching을 지원합니다. (라이브러리마다 In-flight Batching을 구현한 방법은 다릅니다. 자세한 사항은 여기서 다루지 않겠습니다.)
In-flight Batching 장점
-
Latency 감소: 생성이 빨리 끝난 요청은 다른 요청의 완료를 기다리지 않고 즉시 응답될 수 있습니다. 이에 더해, 이전 배치 안의 모든 문장의 생성이 끝나길 기다릴 필요가 없이 다음 요청을 처리할 수 있어 큐에서 대기하는 시간이 줄어듭니다.
-
GPU utilization 극대화: 다양한 길이의 문장을 처리할 때 불필요한 패딩 연산을 줄여주므로 GPU를 효율적으로 사용할 수 있습니다.
Paged Attention
Paged Attention은 attention 연산에서 Key와 Value의 메모리 사용을 효율적으로 관리하는 방법입니다 7. 기존 방식에서는 예상되는 최대 시퀀스 길이에 맞춰 미리 메모리를 할당하는 등 비효율적인 메모리 사용이 있었습니다. 이를 해결하기 위해 Paged Attention은 KV Cache를 작은 KV block 단위로 나누고, 각 block을 비연속적인 메모리 공간에 저장합니다. 동적으로 필요한 만큼만 KV Cache block을 점진적으로 할당해서 불필요한 메모리 사용을 줄입니다. 이는 제한된 GPU 메모리에서 메모리 사용을 효율적으로 관리하여 더 큰 배치 크기를 처리할 수 있게 되어 처리량이 향상됩니다.
vLLM과 TensorRT-LLM 모두 Paged Attention을 지원합니다.
In-flight Batching과 Paged Attention 유무에 따른 성능 비교
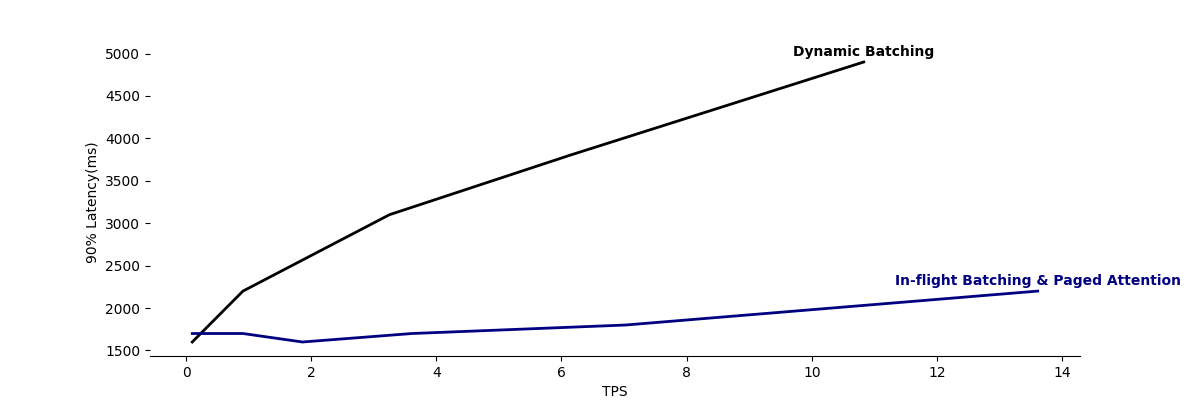
그래프1. In-fight Batching과 Paged Attention 유무에 따른 성능 비교
In-flight Batching와 Paged Attention의 효과를 실제로 확인하기 위해, TensorRT-LLM에서 In-flight Batching과 Paged Attention을 사용했을 때와 Dynamic Batching만 사용했을 때의 성능을 비교 테스트했습니다.
테스트 결과를 나타낸 그래프1을 보면, In-flight Batching과 Paged Attention을 사용한 경우, 트래픽 처리 속도가 훨씬 빨라진 것을 확인할 수 있습니다. 특히, VUSER가 64일때는 Dynamic Batching, In-flight Batching & Paged Attention 각각 TPS가 6.13, 7.02로 비교적 차이가 적지만, 개별 요청에 대한 90% latency는 각각 3800ms, 1800ms로 2배 이상 차이가 발생했습니다.
In-flight Batching과 Paged Attention을 사용한 TensorRT-LLM과 vLLM 성능 비교
TensorRT-LLM과 vLLM에 대해서 저희 모델을 가지고 end-to-end 성능을 비교 테스트했습니다. TensorRT-LLM과 vLLM 모두 In-flight Batching과 Paged Attention 모두 지원하므로, 이 두 기술을 모두 사용하여 테스트를 수행했습니다.
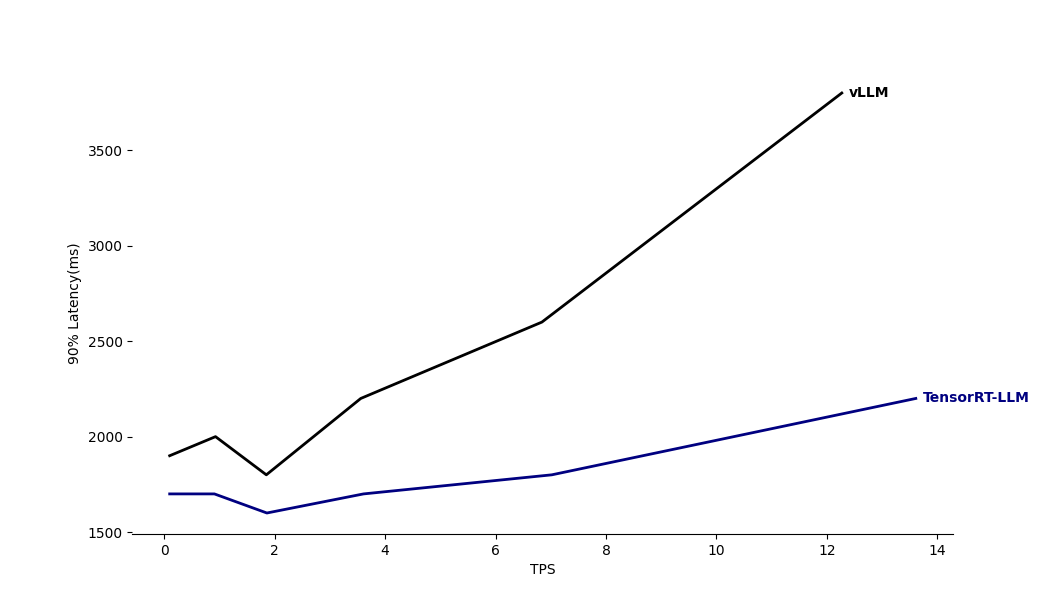
그래프2. TensorRT-LLM과 vLLM TPS와 Latency 비교
그래프2는 TensorRT-LLM과 vLLM을 이용한 end-to-end 성능 비교 테스트 결과를 보여줍니다. 결과에서 볼 수 있듯이, 낮은 트래픽 상황에서는 두 모델 간에 큰 성능 차이가 없습니다. 그러나 트래픽이 증가함에 따라 vLLM의 90% Latency가 TensorRT-LLM에 비해 상당히 증가하는 것을 확인할 수 있습니다.
성능 차이는 테스트 환경이 NVIDIA GPU A30이어서 NVIDIA에서 직접 개발한 TensorRT-LLM이 해당 GPU에 더 최적화되었을 가능성이 있습니다. 또한, 테스트 당시 Llama3 아키텍처가 최근에 발표되어 vLLM이 아직 완전히 최적화되지 않았을 수도 있습니다.
모델 양자화
양자화
양자화(Quantization)는 모델의 weight 또는 activation을 더 적은 비트 수(lower precision)로 표현하여 모델을 경량화하는 방법입니다.
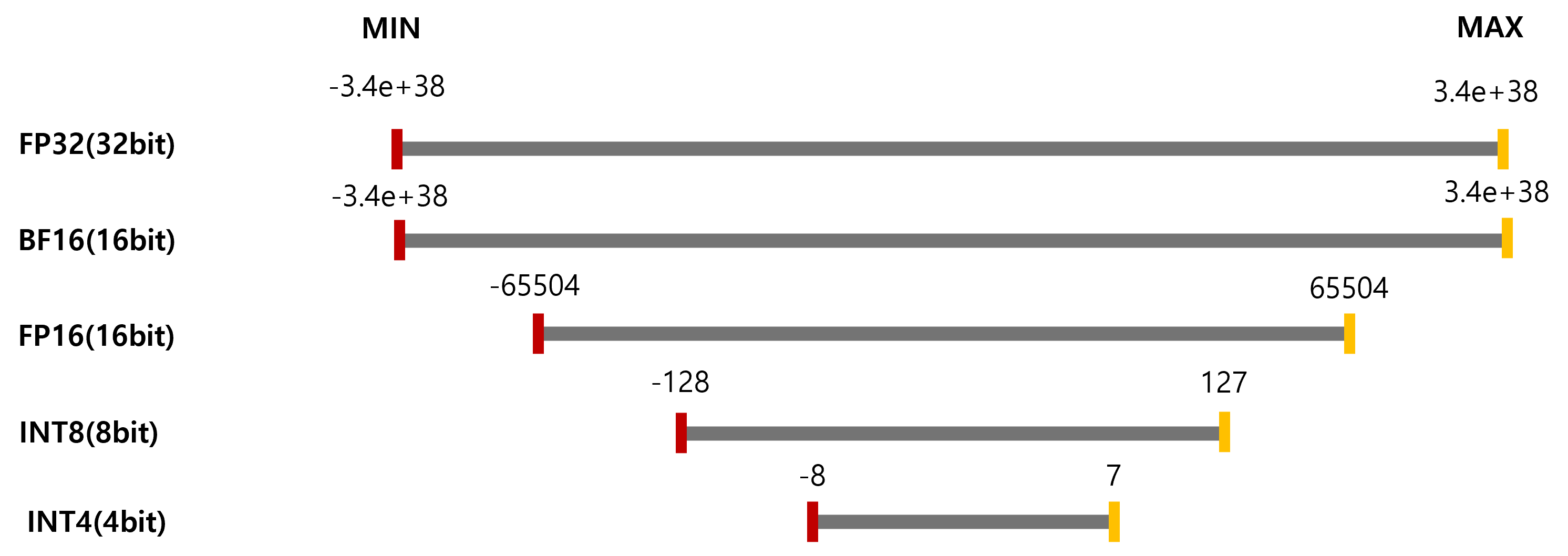
그림2. 데이터 타입에 따른 값의 범위와 비트 수
그림2는 각 데이터 타입들의 값의 범위와 비트 수를 보여줍니다. FP32 데이터 타입은 넓은 값의 범위를 가지며, 많은 비트를 사용하여 데이터를 표현합니다. 반면에, INT8이나 INT4와 같은 데이터 타입은 적은 비트를 사용하여 데이터를 표현하기 때문에 값의 범위가 좁아집니다. 양자화는 많은 비트를 사용하는 데이터 타입의 모델을 적은 비트를 사용하는 데이터 타입의 모델로 변환합니다.
양자화 방법마다 weight만 양자화하는 경우가 있고 weight, activation 모두 양자화하는 경우가 있습니다. Weight는 고정된 값이지만, activation은 입력에 따라 동적으로 변하기 때문에 양자화하기 더 어렵습니다.
양자화하면 아래와 같은 장점이 있습니다.
-
모델 크기 감소: 예를 들어, FP16을 INT8로 양자화하면 모델의 크기가 거의 절반으로 줄어듭니다. 이는 Tensor Parallel같은 방법을 사용하지 않아도 작은 GPU 메모리를 가진 GPU에서 모델을 추론을 할 수 있게 합니다.
-
Memory bandwidth 문제 완화: 적은 비트 수로 표현된 데이터는 GPU 메모리(vRAM)과 GPU 코어 사이의 데이터 전송량을 줄여줍니다.
-
연산 속도 향상: 적은 비트 수의 연산은 일반적으로 더 빠르게 수행됩니다.(양자화 방법마다 연산 과정의 개선 정도는 다릅니다.)
-
더 큰 배치 처리 가능: 모델 크기가 줄어들면 동일한 GPU 메모리에서 더 큰 배치를 처리할 수 있습니다.
하지만 양자화에서 주의해야 할 점도 있습니다. 그림2에서 볼 수 있듯이, 비트 수가 작아질수록 표현할 수 있는 값의 범위가 좁아집니다. 따라서 많은 비트 수의 데이터를 적은 비트 수로 매핑하는 양자화 과정에서 정보의 손실이 발생할 수 있으며, 이로 인해 모델의 정확도가 저하될 수 있습니다.
양자화 방법은 크게 아래와 같이 나눕니다.
-
- Quantization-Aware Training(QAT)
- 모델 학습과 함께 양자화를 하는 방법입니다.
-
- Post-Training Quantization(PTQ)
- 모델 학습 이후에 양자화 하는 방법입니다. 방법에 따라 최적의 양자화 parameter를 찾기 위해 calibration 과정이 필요하기도 합니다.
본 글에서는 이미 학습이 완료된 저희 모델에 적용할 수 있는 PTQ 방법인 AWQ와 SmoothQuant만 다룹니다.
AWQ
Activation-aware Weight Quantization(AWQ)8은 1%의 weight만 보호해도 양자화 오류를 크게 줄일 수 있다는 점에서 착안하여 activation 분포를 이용하여 중요한 weight channel을 찾아가며 양자화하는 방법입니다.
주요 특징은 다음과 같습니다.
- Activation을 제외하고 weight만 양자화합니다.
- 중요한 weight channel은 activation 크기 기준으로 선택합니다.
- 중요한 weight channel을 보호하기 위해 중요한 weight channel에 대한 적절한 값(s)을 찾아 scaling합니다.
AWQ를 사용하면 모델 크기가 작아져 memory bandwidth 문제를 완화하고 더 큰 배치 크기를 처리할 수 있게 됩니다. 또한, AWQ는 calibration 과정이 필요하지만, backpropagation과 재구축에 의존하지 않기 때문에 calibration set에 overfitting되는 문제가 적다는 장점이 있습니다.
SmoothQuant
값이 정해진 weight와 다르게 입력값에 따라 달라지는 activation은 outlier의 존재로 인해 양자화가 어렵습니다. SmoothQuant는 이러한 어려움을 해결하기 위해 제안된 방법입니다.9
주요 특징은 다음과 같습니다.
- Activation, weight 모두 양자화합니다.
- 각 채널의 최대값을 기준으로 하는 스무딩 팩터(s)를 사용하여 activation의 분포를 평탄하게 만듭니다.
- Activation 평탄화에 대한 보정을 weight에 적용해주어 전체 양자화 오류를 줄입니다.
SmoothQuant도 AWQ와 동일하게 모델 크기가 작아져 memory bandwidth 문제를 완화하고 더 큰 배치 크기를 처리할 수 있게 됩니다. AWQ와 다르게 행렬곱도 양자화된 데이터 타입으로 하여 연산 속도를 가속화합니다.
AWQ와 SmoothQuant의 TPS, Latency 성능 테스트
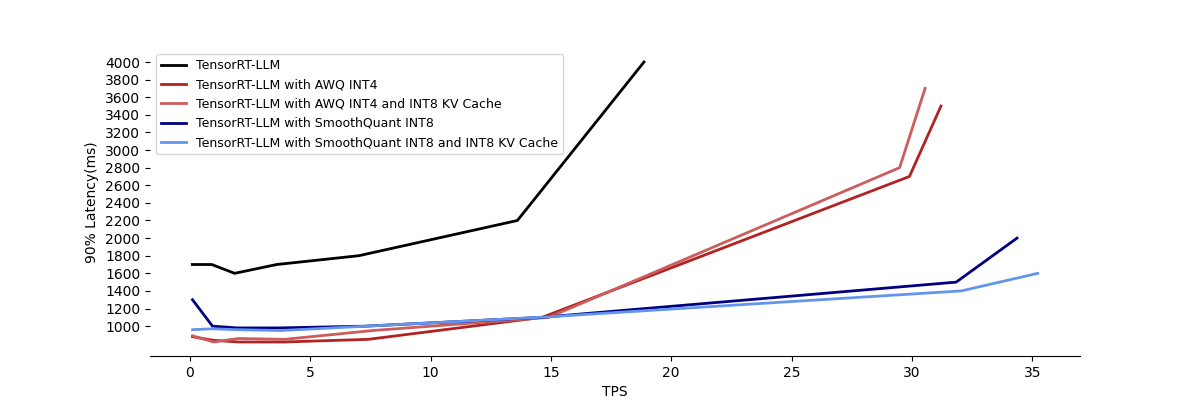
그래프3. 양자화 방법에 따른 TPS, Latency 비교 그래프 (90% Latency가 4000ms를 초과하는 경우 그래프에서 제외하였습니다)
저희 모델을 TensorRT-LLM에서 지원하는 AWQ INT4, SmoothQuant INT8로 각각 양자화하여 성능 비교 테스트를 진행하였습니다. 추가적으로 TensorRT-LLM에서 지원하는 INT8 KV Cache도 함께 테스트하였습니다. 모든 테스트는 In-flight Batching과 Paged Attention을 함께 사용한 상태에서 진행되었습니다.
AWQ와 SmoothQuant 모두 양자화를 통해 동일한 GPU 메모리에서 최대 처리할 수 있는 배치 사이즈를 양자화 전보다 2배 이상 증가시킬 수 있었습니다.

표1. VUSER와 양자화 방법에 따른 TPS와 90% Latency
정확한 설명을 위해 VUSER가 32, 256일때의 구체적인 성능 결과를 표1로 나타내었습니다. VUSER가 32일때는 양자화를 하지 않은 경우와 양자화를 한 경우의 TPS는 큰 차이는 없었지만, 90% Latency는 큰 차이를 보였습니다. 하지만 VUSER이 256일때는 TPS 또한 큰 차이를 보였습니다. 특히, 트래픽이 적을 때는 AWQ가 SmoothQuant보다 더 낮은 Latency를 보였으나, 트래픽이 많아질수록 SmoothQuant가 더 낮은 Latency을 보였습니다. 테스트 시점에는 TensorRT-LLM에서 AWQ는 INT4를 지원하고, SmoothQuant는 INT8을 지원하고 있습니다. AWQ는 더 적은 비트로 양자화되어 memory bandwidth 문제를 더 완화할 것으로 예상됩니다. 그러나 SmoothQuant는 weight뿐만 아니라 activation도 양자화하여 행렬 곱셈(matrix multiplication)을 양자화된 데이터 타입으로 수행할 수 있어, 계산 속도도 가속할 수 있는 장점이 있습니다.
한편, INT8 KV Cache의 경우, 상황에 따라 성능이 개선되기도 하지만, 반대로 성능이 저하되는 경우도 관찰되었습니다.
AWQ와 SmoothQuant의 모델 생성 품질 테스트
양자화는 더 적은 비트 수로 데이터를 표현하기 때문에 정보 손실이 발생하며, 이로 인해 모델 정확도가 저하될 수 있습니다. 이를 확인하기 위해 테스트를 진행했습니다.
Exact Matching(EM)과 Execution Accuracy(EX)에 대해 양자화 전후의 정확도를 비교했습니다2. EM은 생성된 쿼리문과 정답 쿼리문의 토큰 집합이 정확히 일치하는지를 평가하는 binary 평가 지표입니다. EX는 생성된 쿼리와 정답 쿼리를 실제로 Neo4j(GraphDB)에서 실행했을 때 결과가 일치하는지를 평가하는 binary 지표입니다.

표2. 양자화 방법에 따른 양자화 안 한 모델 대비 정확도 저하 확인 테스트
표2는 각 평가 지표에 대해 양자화되기 전 모델의 정확도 대비 양자화 후 정확도가 얼마나 저하되었는지를 나타내고 있습니다.
AWQ의 경우, 양자화에 따른 정확도 저하가 거의 발생하지 않았습니다. 반면, INT8로 양자화된 SmoothQuant는 INT4로 양자화된 AWQ보다 더 큰 데이터 타입을 사용했지만 더 큰 정확도 저하를 보였으며, 특히 EX에서 양자화 전보다 정확도가 5% 하락했습니다.
Calibration set 크기를 조절하며 양자화를 수행했습니다. AWQ의 경우, 적은 양의 calibration set을 사용해도 양자화 오류가 거의 없었지만, SmoothQuant는 많은 양의 calibration set을 사용해도 여전히 큰 양자화 오류가 발생했습니다. 이러한 차이는 SmoothQuant가 weight와 activation을 모두 양자화하기 때문에 발생하는 것으로 보입니다.
추가로, AWQ와 SmoothQuant 모두 TensorRT-LLM에서 지원하는 INT8 KV Cache를 추가로 사용할 경우, 정확도가 더욱 저하되는 것을 확인할 수 있었습니다.
마치며
vLLM은 NVIDIA GPU뿐만 아니라 다양한 환경에서 간편하게 모델 서빙을 위해 사용할 수 있습니다. 하지만 저희 모델과 테스트 환경에 대해서는 TensorRT-LLM에 비해 낮은 성능을 보여주었습니다. TensorRT-LLM은 NVIDIA GPU에 최적화되어 다양한 환경에서 사용이 어려우며 weight 변환 및 TensorRT engine을 빌드해야 하는 번거로움이 있습니다. 하지만, 저희 모델과 테스트 환경에 대해서 아주 좋은 성능을 보여주었습니다.
TensorRT-LLM과 vLLM 모두 기존 python 실행보다 훨씬 빠른 속도를 보여주고 모델과 사용 환경마다 성능 차이가 있으므로 테스트하셔서 상황에 맞게 선택하면 좋을 거 같습니다. 추가로, 잘 알려진 모델 아키텍쳐를 서빙할 때는 각각 지원하는 모델이 다르므로 지원되는 모델을 확인하여 사용하면 좋습니다. (둘 다 새로운 모델 추가도 가능합니다.)
2가지 양자화 기법에 대해 TensorRT-LLM을 이용해서 성능을 비교해보았습니다. 높은 처리량이 필요하고 어느 정도의 정확도 손실을 감수할 수 있는 경우, SmoothQuant가 좋은 선택일 수 있습니다. 정확도 유지가 중요하면서도 성능 향상이 필요한 경우, AWQ가 더 적합할 수 있습니다. 추가적으로 KV Cache에 대해서는 정확도 저하가 있으므로 주의 깊게 사용해야 합니다. 2가지 이외에도 다양한 양자화 방법을 TensorRT-LLM과 vLLM에서 지원하고 있습니다. 상황에 따라 적절한 방법을 선택하여 사용하면 좋을 것 같습니다.
FP8로 하는 양자화 방법들이 양자화 오류가 적고 빠르다고 알려져 있습니다. 아쉽게도 이번 실험에 사용된 A30 GPU는 FP8을 지원하지 않아 테스트하지 못했습니다.
*테스트에 도움을 주신 대화AI LAB의 강민지님께 감사드립니다.
References
-
https://github.com/meta-llama/llama-models/blob/main/models/llama3/MODEL_CARD.md ↩
-
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. 2018. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. arXiv preprint arXiv:1809.08887.https://arxiv.org/pdf/1809.08887 ↩ ↩2
-
https://docs.nvidia.com/tensorrt-llm/index.html#documentation ↩ ↩2
-
https://github.com/triton-inference-server/tensorrtllm_backend ↩
-
https://docs.vllm.ai ↩
-
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for Transformer- Based generative models. In OSDI https://www.usenix.org/conference/osdi22/presentation/yu ↩
-
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with Paged Attention. In ACM SOSPhttps://arxiv.org/pdf/2309.06180 ↩
-
Lin, Ji & Tang, Jiaming & Tang, Haotian & Yang, Shang & Dang, Xingyu & Han, Song. 2023. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. https://arxiv.org/pdf/2306.00978 ↩
-
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. SmoothQuant: accurate and efficient post-training quantization for large language models. In Proceedings of the 40th International Conference on Machine Learning (ICML’23), Vol. 202. JMLR.org, Article 1585, 38087?38099.https://arxiv.org/pdf/2211.10438 ↩
