
- 이어서
- Evolutionary Optimization of Model Merging Recipes
- Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction
- 정리하며
- 참고 문헌 및 자료
작성자
- 노형종 (대화AI Lab)
- 대화 및 텍스트 생성 기술을 연구 개발하고 있습니다.
이런 분이 읽으면 좋습니다!
- LLM 성능 향상에 관심이 있으신 분
- 자원 효율적으로 LLM 성능을 향상시키고 싶으신 분
이 글로 알 수 있는 내용
- 모델 병합 기술의 기본적인 개념을 알 수 있습니다.
- 모델 병합 기술을 이용하여 LLM 성능을 향상시킨 사례를 통해 연구 방향에 대한 아이디어를 얻을 수 있습니다.
이어서
이전 글에서는 널리 알려져 있는 모델 병합 방법들에 대해 소개드렸다면, 이번 글에서는 모델 병합 기술을 LLM에 적용하여 최근에 유의미한 성과를 보여준 연구 2편을 자세히 살펴보도록 하겠습니다.
Evolutionary Optimization of Model Merging Recipes
소개해 드릴 첫번째 연구는 올해 3월에 arXiv에 올라온 “Evolutionary Optimization of Model Merging Recipes”1입니다. 이 논문에서는 모델 병합 시 가능한 다양한 조합을 자동적으로 탐색할 수 있음을 제안합니다. 모델 2개에 대한 간단한 병합에서는 다양한 조합이라고 생각할 만한 여지가 별로 없겠지만, 3개 이상의 모델이 주어졌을 때 최적의 병합 모델을 찾는 것은 생각보다 단순하지 않습니다. 병합 시의 각 모델의 비중, 병합 기법 선택, 각 방법에서의 Hyperparameter 설정 등 다양한 후보 모델이 나올 수 있고, 후보 모델을 대상으로 다시 2차, 3차 병합을 진행할 수도 있습니다. 이와 같은 병합 과정을 자동화하는 방법으로 이 논문에서는 진화 알고리즘(Evolutionary algorithm)을 제안합니다.
그림 1. 네트워크의 진화에 따른 성능 향상 (Google Research2)
진화 알고리즘에 대해서는 LLM 등장 이전부터 연구되었던 일종의 네트워크 구조 탐색 방법 연구로 소개드릴 수 있을 것 같습니다. 최근의 LLM 연구는 학습 데이터 구축, Prompt engineering, RLHF/DPO 등으로 대표되는 학습 방법 고도화 등이 주류가 되었는데, 이 논문에서는 Model merge + Evolutionary algorithm (=Evolutionary Model Merge)이라는 LLM 등장 이전의 연구들을 조합한 새로운 방향을 제시하고 있습니다.
모델 병합 과정의 자동화/고도화 외에 이 연구에서 내세우는 또다른 기여 포인트로는 Cross-Domain Merging이 있습니다. 단순히 성능 향상을 목표로 하는 것이 아니라 병합 전의 각 모델이 가지고 있는 강점을 통합 후의 모델이 손실 없이 물려받거나, 오히려 더 높은 능력을 가지게 되는 것을 말합니다. 논문에서는 일본어 능력을 가진 LLM과 수학 능력을 가진 LLM을 병합한 최종 모델에서 두 능력 모두 향상되는 것이 가능함을 실험적으로 보여주었습니다.
제안 방법 설명
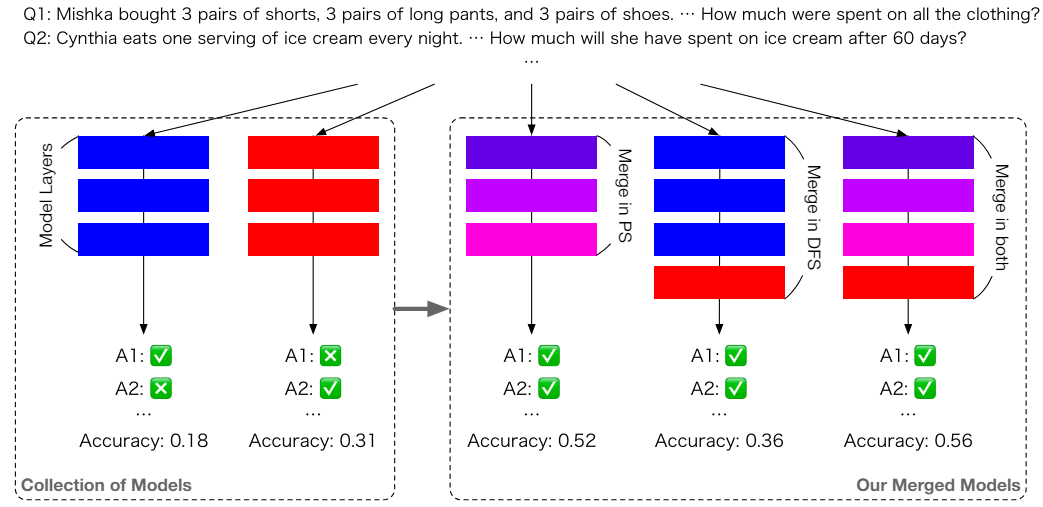
그림 2. PS, DFS 모델 병합
이 논문에서는 모델 병합 방법을 PS (Parameter Space), DFS (Data Flow Space) 두 가지로 나누어 분류하였습니다. 1편에서 설명드렸던 모델 병합 방법들은 모두 PS에 포함되는데, 모델의 Weight들을 수식적으로 혼합시키는 것을 말합니다(그림에서 혼합된 색의 블럭으로 표시). 반면 DFS 방법에서는 Weight가 서로 섞이지 않고, 그림과 같이 각 모델의 특정 Layer를 가져와서 붙이는 방식을 취합니다. 연구에서 제안하는 방법은 두 가지를 모두 적용한 일종의 Hybrid 접근 방법을 제안합니다만, 실험 결과를 보면 결과적으로 PS 병합에서 가장 큰 성능 향상이 이루어지고, DFS 및 Hybrid 적용 성능은 PS에 비해 극적인 변화를 보이지 않아 이후 설명에서는 PS 위주로 설명하도록 하겠습니다.
이 연구에서 적용한 통합 방법은 TIES-Merging with DARE라고 하는데, 두 방법을 같이 적용한 Hybrid 방식이라고 볼 수 있습니다. 이 부분에서는 특별하게 차별화되는 포인트가 보이지 않는데요, 사실 이 연구의 본체는 앞서 설명드린 진화 알고리즘입니다. CMA-ES3 (Covariance matrix Adaptation Evolutionary Search)라는 진화 알고리즘을 사용했다고 하는데요, 2006년에 발표된 기술입니다. CMA-ES에 대한 기술적 분석은 제 능력과 이 글의 주제를 벗어난 것이므로 생략하겠습니다. 일종의 최적화 문제를 해결하기 위한 공간 탐색 방법으로 보이며, 이 기술을 네트워크 탐색에 적용하였습니다. 탐색 과정에서의 계산 과정을 진화 알고리즘에서는 보통 ‘세대’(Generations)라고 부르는데, 중요한 것은 이 연구에서 최적의 네트워크와 Weight를 찾기 위해 100회 이상의 세대를 거쳤다는 것입니다. Evolutionary Model Merge라고 이름을 붙일 만한 복잡한 과정을 거쳐 실험이 이루어졌고, 그렇게 얻어 낸 최종 모델의 성능 또한 상당히 인상적이었습니다.
실험 결과 분석
실험은 3개의 Source model를 시작점으로 이루어졌습니다. 일본어 능력을 가진 shisa-gamma-7b-v1 모델, 수학 능력을 가진 WizardMath-7B-V1.1, Abel-7B-002 모델을 가지고 통합 과정을 진행했습니다. 중간에 생성된 후보 모델들까지 고려하면 다수의 모델들끼리의 병합을 통한 진화가 진행되기 때문에, 자연스럽게 SLERP보다는 다수의 모델 통합이 용이한 TIES-Merging, DARE 방법을 선택했을 것으로 추측됩니다.
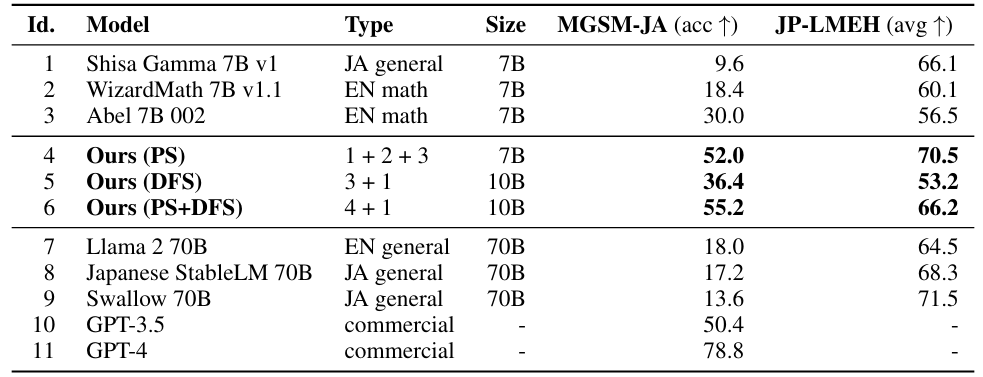
표 1. LLM 성능 비교 (MGSM-JA: 일본어 수학 능력, JP-LMEH: 일반 일본어 능력)
위의 성능 비교표에서 볼 수 있듯이, 통합 모델(4~6)들은 대체적으로 높은 성능을 보여주었습니다. 특히 PS, PS+DFS의 경우에는 성능 고점 자체가 기존 통합 전 개별 모델들에 비해서도 높은 것을 볼 수 있습니다. PS 적용만 하더라도 같은 모델 크기를 유지하면서 일본어 능력, 수학 능력 모두 매우 높은 점수를 기록하였습니다. 이렇게 높은 성능을 기록한 것은 다른 모델 병합 연구들에서도 보기 힘든 수치인데, 수많은 후보군 탐색을 가능하게 한 진화 알고리즘 덕분에 가능한 결과가 아닐까 추측합니다.

표 2. 문제 풀이의 예
이 문제 풀이 예시는 단순히 통합 모델이 일본어를 잘하거나, 수학을 잘하는 기존 모델의 능력을 물려받은 것에 그친 것이 아니라 두 요소가 복합적으로 필요한 Instruction에 대해서도 대응이 가능해졌다는 것을 보여줍니다. 일본어 Instruction에서의 立春(입춘, Risshun)과 節分(절분: 입춘 전날, Setsubun)은 일본어 문화권에 대한 지식이 있어야만 정확한 의미를 알 수 있는 어휘들이고, 답을 얻기 위해서는 이 날짜들의 연산이 필요하기 때문에 수학 능력 또한 요구됩니다. 그림이 길어서 전부 가져오지 못했습니다만 통합 전 개별모델들은 위 문제에 제대로 답을 하지 못한 반면, 통합 모델(EvoLLM-JP-v1-7B)은 위와 같이 정확한 답을 찾을 수 있었습니다. 두 능력이 성공적으로 융합되었음을 유추해 볼 수 있는 사례입니다.
VLM(Vision-Language Model)에서의 실험 결과도 흥미롭습니다. 여기에서는 LLaVA-1.6-Mistral-7B라는 기존의 VLM에서의 LLM 부분과 앞서 언급한 일본어 LLM shisa-gamma-7b-v1을 병합하였습니다. 일본어 VLM이라는 비교군이 거의 없는 모델이라는 것을 감안하여 절대적인 성능 수치보다는 병합 전후의 성능 변화를 주목해서 보면 좋을 것 같습니다.

표 3. 일본어 벤치마크에 대한 VLM 성능
LLM에서의 실험과 비슷하게 모델 병합 진행 후 성능이 향상되었습니다. 이와 같이 Base model이 가지고 있지 않았던 능력을 주입하는 형태의 모델 병합이 LLM, VLM에서 모두 가능함을 보여주었습니다. 아래 예시에서 일본 문화권에 대한 지식이 필요한 VQA 응답이 잘 생성됨을 볼 수 있습니다.

표 4. 일본 문화권 지식을 요구하는 VQA 예제
Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction
두번째 연구는 ACL 2024에 게재 예정인 “Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction”4입니다. 이 연구에서는 LLM 학습에 있어서 단순히 Instruction 학습 데이터의 수량을 늘리기만 하는 것은 비효율적일 뿐 아니라 오히려 성능을 하락시킬 수도 있다고 주장하고, 이를 대응하기 위한 방법으로써 모델 병합 기술을 적용합니다.
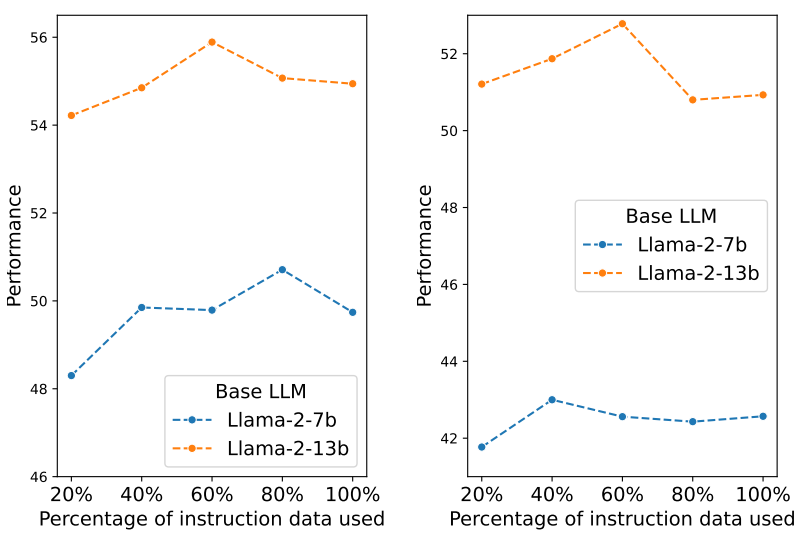
그림 3. 학습 데이터 증가에 따른 성능 변화 (왼쪽: MMLU5, 오른쪽: BBH6)
위의 그림과 같이 학습에 쓰이는 Instruction 데이터의 수가 증가할 때 특정 시점에서는 더 이상 성능이 증가하지 않거나 하락하기 시작하는 시점이 존재하고, 논문에서는 이를 Alignment tax라고 부릅니다. 기존 연구들에서는 이 현상을 Instruction 학습 데이터의 품질 문제, 또는 이를 학습하면서 기존 지식을 잃어버리는 Knowledge forgetting 문제로 해석하였는데, 저자는 그것들이 주요 요인이 아니라고 주장합니다. 논문에서는 이와 같은 현상의 주요 원인은 Data bias이며, 학습이 진행되면서 Instruction 데이터로부터 텍스트 생성 능력보다는 데이터 내에 포함되어 있는 Bias를 획득하기 시작하기 때문에 성능 저하가 발생한다고 설명하고 있습니다.
이에 대응하기 위해 본 연구에서는 새로운 학습 방법, DTM(Disperse-Then-Merge)을 제안합니다. 이 방법은 크게 3가지 단계를 가지는데, 1) 학습 데이터를 몇 개의 Cluster로 나누고, 2) 각 학습 데이터를 이용해 각각의 서브모델을 학습한 후, 3) 서브모델들을 병합하여 최종적으로 하나의 통합 모델을 만듭니다. 서브모델을 학습할 때 학습 데이터가 특성에 따라 분할되었기 때문에 각 모델의 학습 데이터의 양이 그만큼 줄었을 것이고 Data bias도 감소되었을 것입니다. 그에 따라 Alignment tax 현상도 줄어들었을 것이고, 성능도 더 나아진다는 것이 연구의 주요 내용입니다.
선행 연구 및 실험
위의 설명 중에는 논리적으로 뭔가 부족한 부분이 있습니다. Alignment tax 현상의 원인으로 데이터 품질, Knowledge forgetting을 주요 요인으로 볼 수 없다는 주장에 대한 근거가 빠져 있는데, 본 연구에서는 이에 대한 선행 연구를 먼저 진행하였습니다.
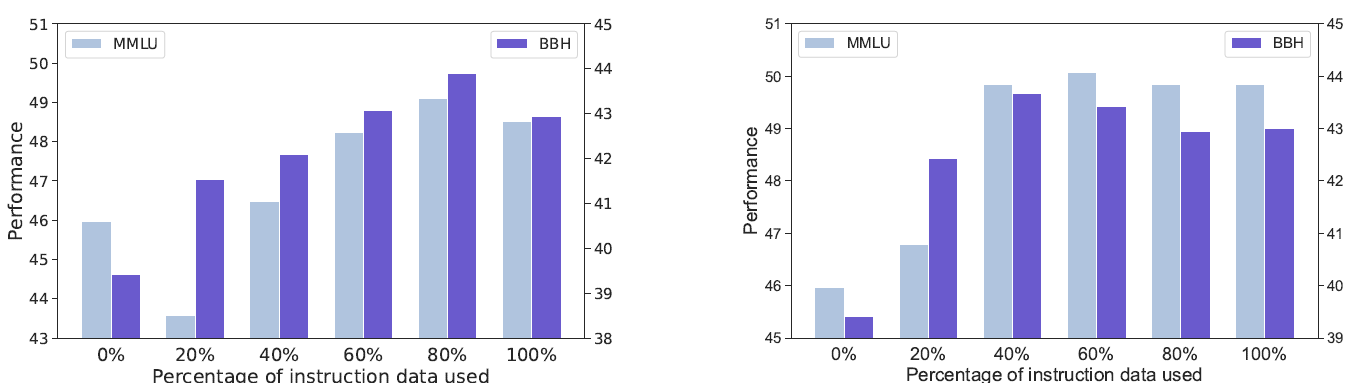
그림 4. 학습 데이터 세팅에 따른 성능 변화 (왼쪽: 고품질 데이터로 학습, 오른쪽: Instruction 학습 데이터에 Pre-training 데이터 추가)
크게 2가지 실험을 수행하였는데, 첫번째 실험에서는 학습 데이터 중에 고품질 데이터만을 골라 학습하였고(고품질 데이터를 고를 때 Quality evaluator7를 사용), 두번째 실험에서는 Instruction tuning 진행 시에 Pre-training 학습 데이터를 섞어 기존에 학습된 지식을 잃어버리지 않도록 하였습니다. 실험 결과는 그림 4에서 볼 수 있는데, 학습 데이터가 증가하면서 성능이 더 이상 증가하지 않거나 하락하는 지점이 발생하는 현상이 여전히 재현되었습니다. 논문에서는 이 실험을 근거로 데이터 품질문제나 Knowledge forgetting 문제가 Alignment tax 현상의 주요 요인이 아니라고 주장합니다. 제 의견을 덧붙여 보자면, 가정에 대한 검증 실험으로서 특히 두번째 실험은 나이브하다고 생각하지만, 그럼에도 논문에서의 주장에 대한 최소한의 근거는 보여주었다고 생각합니다.
Alignment tax 현상의 실질적인 원인은 Data bias라는 주장에 대한 실험도 있습니다만, 이 글의 주제인 모델 병합과 동떨어진 내용이 너무 길어지는 것 같아 이 부분은 간단하게 요약해서 적어보겠습니다. 이 실험의 핵심 내용은 학습 시의 Training loss의 감소량 ΔLtrain, Validation loss의 감소량 ΔLval을 대조해 보았을 때, ΔLtrain의 값이 훨씬 크고 학습 데이터의 양이 증가할수록 그 차이(ΔLtrain/ΔLval)가 더 커지는데, 이것을 Data specific bias가 학습된 것으로 해석할 수 있다는 것입니다.
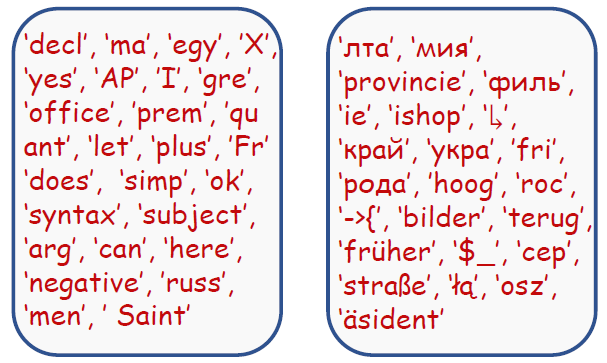
그림 5. Loss 감소폭이 큰 대표 Token들 (왼쪽: 학습 데이터 10% 학습 시점, 오른쪽: 90% 학습 시점)
학습 데이터 증가에 따라 Loss 감소 폭이 큰(=많은 학습이 진행되는) Token이 달라지는 현상은 Bias를 좀 더 직관적으로 보여 줍니다. 쉽게 말하자면 학습 초반에는 일반적인 단어들에 대한 학습이 이루어진 반면(그림 5의 왼쪽), 학습 후반에는 학습 데이터에는 존재하나 상대적으로 일반적이지 않은 희귀 단어들의 학습이 주로 진행됩니다(그림 5의 오른쪽). 이런 현상 또한 해석하기에 따라 학습이 길게 진행되면서 Data bias에 편향되어 학습된다고 볼 수 있는 근거가 될 수 있습니다.
제안 방법 설명
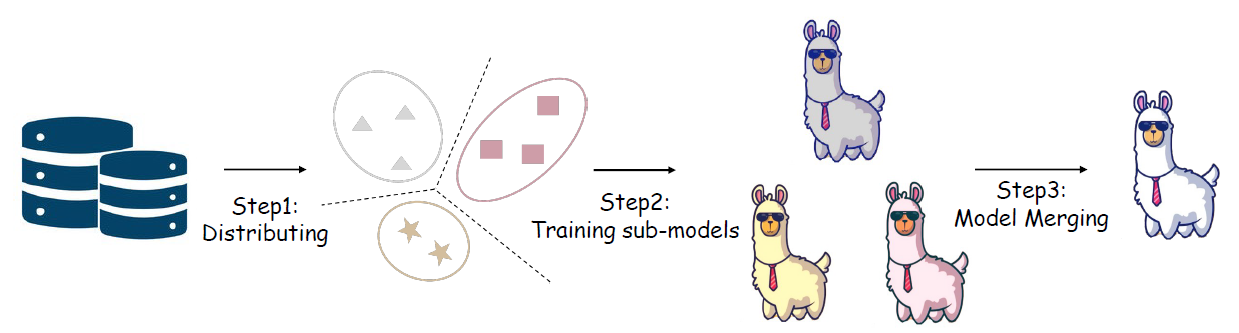
그림 6. DTM 프레임워크
위에서 간단히 소개했던 DTM 단계에 대해서 좀 더 자세히 설명해 보겠습니다.
- Data Distributing: 위에서 대량의 학습 데이터를 한번에 길게 학습하면서 생기는 Alignment tax 현상에 대해서 확인했습니다. 이를 피하게 위해 이 단계에서는 학습 데이터를 K개의 Cluster로 분할합니다. 논문에서는 각 학습 데이터 Instance를 Embedding vector로 변환한 뒤에, K-mean clustering 방법을 적용하여 나누었습니다.
- Sub-model Training: 데이터를 분할한 후에, Base model M0을 각각의 학습 데이터로 Instruction tuning을 진행하여 M1, M2, …, MK의 총 K개의 서브모델을 학습합니다. 각 서브모델의 학습 데이터가 다르므로 학습시 발생하는 Bias의 성격 또한 각자 다를 것이고, 서브모델 한 개당 학습 데이터의 양 자체가 줄어들었으므로 Bias의 크기도 줄어들 것을 예측할 수 있습니다.
- Model Merging: 마지막 단계에서는 M1, M2, …, MK의 서브모델을 하나의 모델로 통합합니다. 기존 연구8에 따르면, 모델 병합 시에 각각의 Bias가 잊혀지는 (Forgotten) 효과가 있다고 합니다. 모델 통합 방법은 1부에서 소개해 드렸던 다양한 방법들을 고려할 수 있지만, 이 연구에서는 가장 간단한 Weighted average를 적용하였습니다. 그리고 아래 이어지는 실험에서는 각 모델의 Weight를 모두 동일하게 주고 진행하였기 때문에 실제로는 K개의 모델의 평균값을 통합 모델로 사용했습니다.
실험 결과 분석
실험에서는 Llama-2-7b를 Base model로, TULU-V2-mix를 Instruction 학습 데이터로 사용하였습니다. TULU-V2-mix는 326,154개의 Instruction 학습 데이터로 이루어져 있다고 합니다. 성능 검증을 위해 다양한 Baseline들을 비교했지만 여기에서는 그 중 아래의 비교 모델에 집중해서 살펴보겠습니다.
Vanilla/L2-norm: 일반적인 Instruction fine-tuning 모델입니다. (w/o or w/ L2-norm regularization)
Uniform Soup9: 여러 개의 모델을 학습 후 병합하는 과정이 동일하지만, 각 서브모델을 학습할 때에 학습 데이터 전체를 사용하고 대신 Hyper-parameter를 다르게 세팅합니다.
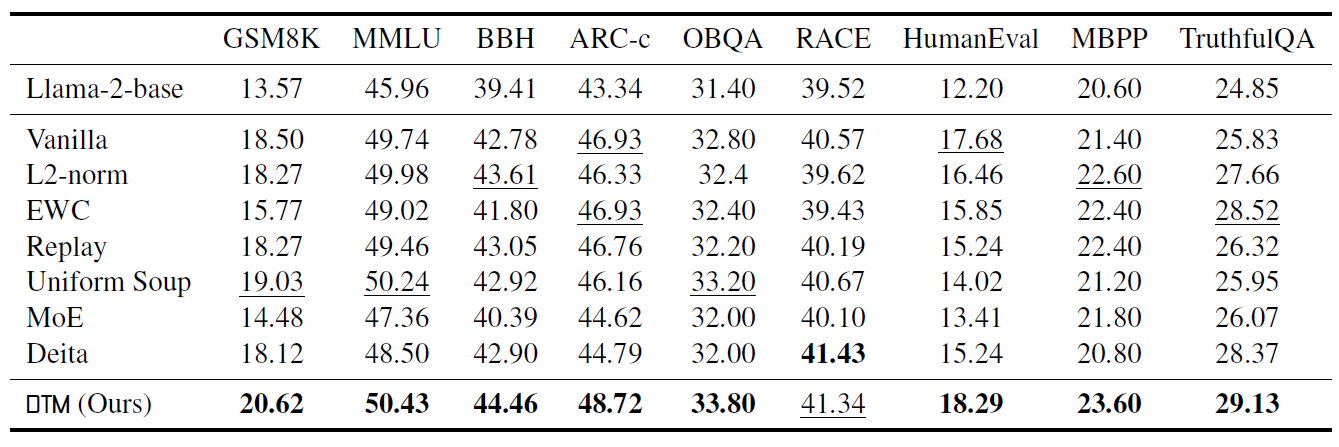
표 5. Benchmark 성능 비교
표에서 볼 수 있듯이, 논문에서 제안한 DTM 방법이 일반적인 Fine-tuning을 포함하여 다양한 Baseline들에 비해 높은 성능을 기록했습니다. Uniform Soup와의 차이를 눈여겨 볼만 한데, 저자는 Uniform Soup에서는 서브모델 학습 시 동일하게 전체 데이터를 학습했기 때문에 각 모델의 Bias가 동일하고 모델 병합 시 Bias 감소 효과가 나타날 수 없었다고 설명합니다. 단순히 모델 병합 효과 뿐 아니라 병합 전 각 모델의 특성이 다를 때 더욱 모델 병합으로 인한 성능 향상이 클 수 있다는 것입니다. 다만 다른 Vicuna-bench 추가실험에서는 Uniform Soup가 7.48, DTM이 6.60으로 나오는 경우도 있었으니 평균적인 경향과 특정 Task에서의 성능 양상은 차이가 날 수 있습니다.
연구 내용 중 의아하다고 생각할 수 있는 부분 중 하나는 제안 방법 내에서 모델 병합이 중요한 부분을 차지함에도 불구하고, 모델 병합을 너무 단순한 방법으로 수행했다는 점입니다. 지난 글에서 다양한 모델 병합 기법을 소개드렸는데, 정작 최근 연구에서는 그냥 평균값으로 최종 모델을 만들었으니 말입니다.
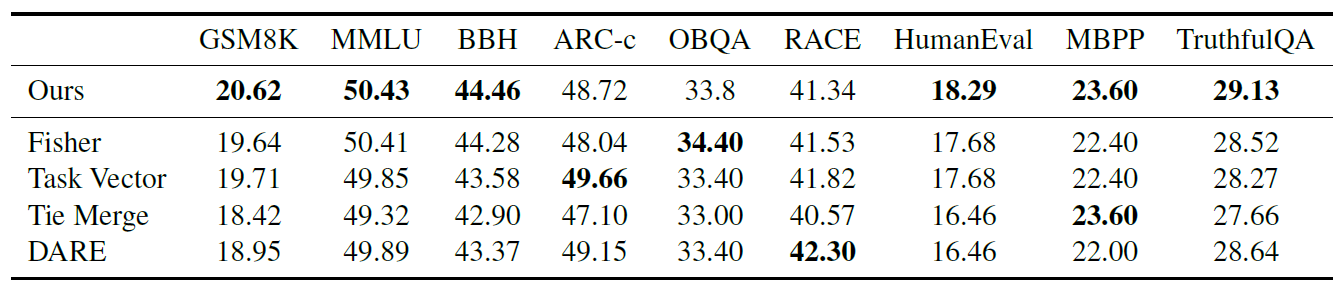
표 6. Merging method에 따른 성능 비교
논문에서는 이에 대해 Ablation study를 수행했는데, 위의 표에서 보듯이 다양한 병합 방법(논문에서는 1편에서 소개했던 SLERP 방식 대신 Fisher10를 대조군으로 사용)과 비교했을 때에도 단순 평균치를 취한 방식이 크게 뒤떨어지지 않고, 오히려 평균적으로는 가장 좋은 결과를 보였습니다. 제가 다른 연구 결과들을 보면서 느낀 바이기도 한데, 성능이 우월한 특정 모델 병합 방법이 존재한다기보다는 Task나 학습 데이터 등에 따라 거기에 적합한 모델 병합 방법(여기에서는 평균값 사용)이 달라지는 것 같습니다. 이전 글에서 각각에 대한 실험 결과를 생략하고 병합 방법 위주로 설명한 이유이기도 합니다.
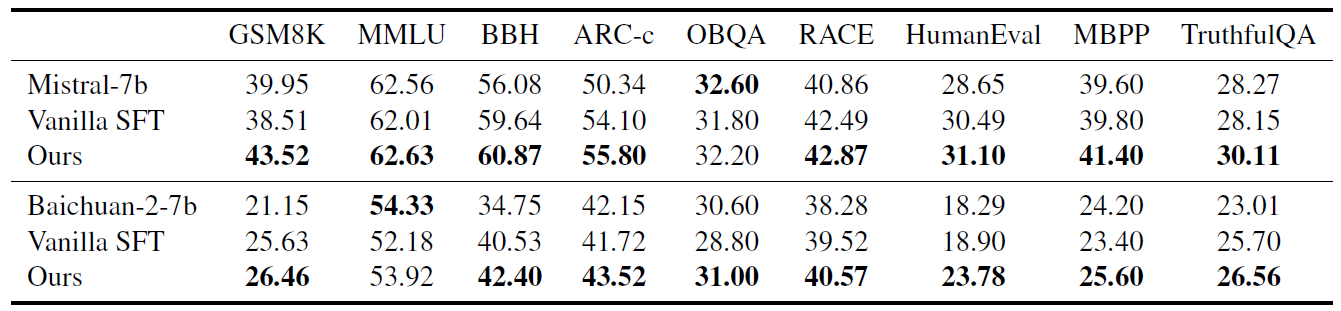
표 7. Llama-2-7b 외 다른 Backbone에서의 성능
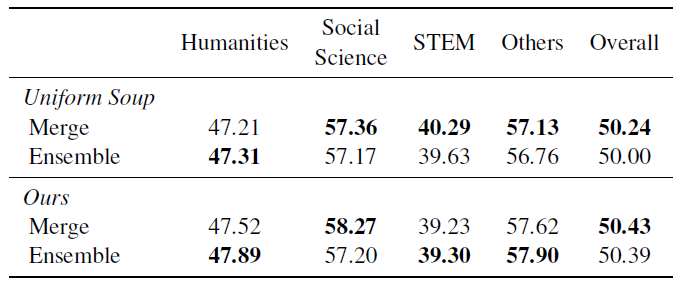
표 8. 앙상블 모델과의 성능 비교
그 외에도 Mistral-7b, Baichuan-2-7b 등의 다른 LLM에서도 비슷한 양상으로 성능이 개선되는 것을 볼 수 있었고(표 7), 마지막 모델 병합 과정 대신 앙상블 모델로 대체한 형태와의 성능 비교 실험도 확인할 수 있었습니다(표 8). 거의 비슷하게 나온 성능 결과만 보았을 때에는, K번의 Inference를 거쳐야 하는 앙상블 모델의 단점을 모델 병합 기법을 통해 하나의 모델로써 효율성을 증가시켰다고도 생각할 수 있습니다. 다만 여기에서도 생각보다 제안 방법(DTM)과 Uniform Soup와의 성능 차이가 크지 않은데, 모델 병합 자체의 효과는 분명히 존재하나 논문에서 설명하고 있는 Data bias 및 Alignment tax의 감소 효과가 유의미한 수준인지는 단정지을 수 없는 결과가 아닌가 하는 생각도 듭니다.
정리하며
최근 모델 병합과 관련된 연구 중 제가 관심있게 봤던 연구 둘을 소개드렸습니다. 제가 주목한 부분은 특정 모델 병합 기법의 성능이 높은지 낮은지보다는 각 연구에서 명확한 지향점을 가지고 모델 병합 기술을 사용했다는 것입니다. 첫번째 연구에서는 일본어 LLM + 수학 LLM, 범용 VLM + 일본어 LLM을 결합하여 원래 모델들의 강점을 결합하는 데에 목적이 있었고, 두번째 연구에서는 많은 Instruction 학습 데이터에서 비롯된 Alignment tax 문제를 해결하기 위해 모델 병합을 적용하였습니다.
그림 7. 병합한 모델을 병합한 모델을 병합…하여 리더보드 고득점 달성!
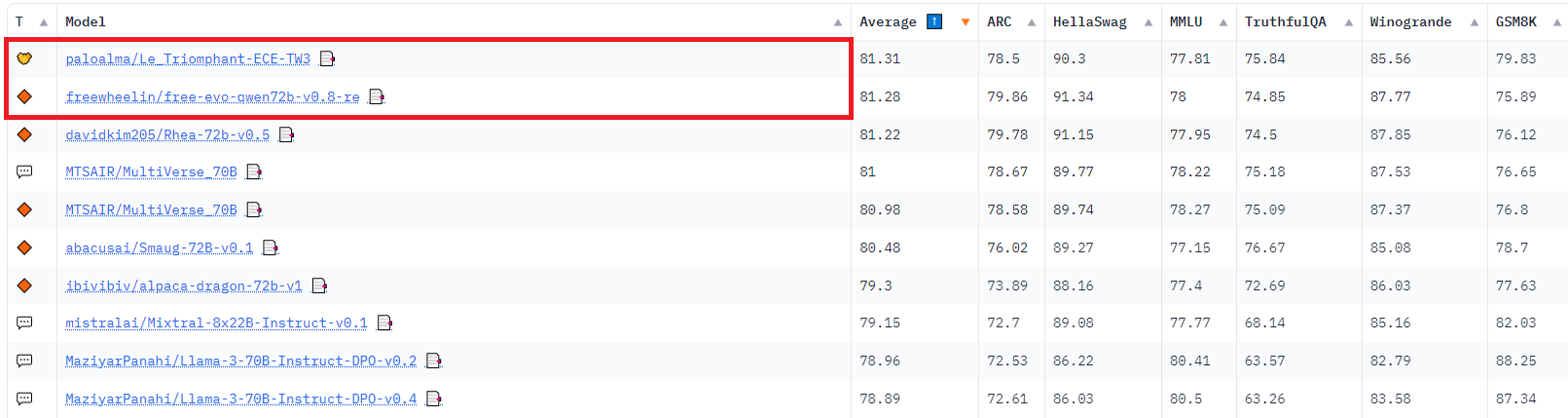
그림 8. 올해 6월 당시 Open LLM Leaderboard 1, 2위를 달성한 병합 모델들 (현재는 개편됨11)
일부 리더보드에서 그랬듯이 단순히 벤치마크 성능 지향적으로 접근한다면 무한 반복되는 모델 병합 과정 속에서 벤치마크 수치에 Overfitting될 위험이 있습니다. 이렇게 만들어진 모델이 과연 인간의 관점에서 보았을 때에도 그만큼의 텍스트 생성 능력을 가지고 있는지는 장담할 수 없다고 생각합니다(모델의 생성결과에 대한 평가 이슈가 있습니다만 여기에서는 생략하겠습니다). 저희는 다양한 도메인 특화 Task들에 맞춰져 Fine-tuning된 모델들을 통합하여 각 모델의 장점이 유지된 고성능의 Multi-task 모델을 만들어 낼 수 있는지에 관심을 가지고 있습니다. 이후에 의미 있는 결과가 나온다면 공유드릴 수 있으면 좋겠습니다. 긴 글 읽어 주셔서 감사합니다.
참고 문헌 및 자료
-
Evolutionary Optimization of Model Merging Recipes, arXiv:2403.13187 ↩
-
Using Evolutionary AutoML to Discover Neural Network Architectures, Google Research blog ↩
-
The CMA evolution strategy: a comparing review, Towards a new evolutionary computation: Advances in the estimation of distribution algorithms (2006) ↩
-
Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction, ACL 2024 ↩
-
Measuring Massive Multitask Language Understanding, ICLR 2021 poster ↩
-
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, ACL 2023 findings ↩
-
What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, ICLR 2024 poster ↩
-
Fuse to Forget: Bias Reduction and Selective Memorization through Model Fusion, arXiv:2311.07682 ↩
-
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, ICML 2022 ↩
-
Merging Models with Fisher-Weighted Averaging, NeurIPS 2022 ↩
-
Open LLM Leaderboard, Huggingface ↩
