
작성자
- 노형종 (대화AI Lab)
- 대화 및 텍스트 생성 기술을 연구 개발하고 있습니다.
이런 분이 읽으면 좋습니다!
- LLM 성능 향상에 관심이 있으신 분
- 자원 효율적으로 LLM 성능을 향상시키고 싶으신 분
이 글로 알 수 있는 내용
- 모델 병합 기술의 기본적인 개념을 알 수 있습니다.
- 모델 병합 기술을 이용하여 LLM 성능을 향상시킨 사례를 통해 연구 방향에 대한 아이디어를 얻을 수 있습니다.
시작하며
LLM (Large Language Model) 관련 연구 및 논문들이 매일같이 쏟아지고 있습니다. 제가 자연어처리 및 AI 연구를 시작한 이후 지금처럼 연구 속도가 빠른 적이 있었나 싶을 정도로 ChatGPT의 등장 전후로 연구 환경이 완전히 달라진 것을 체감하고 있습니다.
이제 텍스트 생성 연구에서 LLM은 필수적으로 고려해야 할 요소가 되었지만, LLM를 실용적으로 사용하는데 있어서 시간과 자원(정확히는 GPU)이 큰 부담이 됩니다. 실시간으로 계속해서 보고되는 새로운 아이디어와 구현들을 모두 검토하기에는 시간이 절대적으로 부족하고, 하나의 대안 또는 개선책을 재현하는 것만 해도 무시할 수 없는 비용과 자원이 소요됩니다. 연구의 방향성과 우선순위에 대한 고민이 더더욱 중요해졌다고도 생각됩니다.
제가 오늘 소개할 모델 병합 (Model merging) 기법은 그런 측면에서 보았을 때 시간과 자원 투자 대비 기대성능이 좋다고 생각합니다. 모델 병합 연구는 LLM 이전에도 연구되는 주제였습니다만, 학습 시간과 자원이 무지막지하게 요구되는 LLM에 특히 적용하기에 적합한 기술이라고 생각합니다. 미리 잘 학습된 모델이 2개 이상 준비되어야만 한다는 가정이 필요합니다만, 그 이후에 모델 병합을 적용하여 추가 학습 시간과 GPU 소모를 최소화하면서 최종 성능을 향상시킬 수 있습니다.
이 글에서는 일단 대표적으로 알려져 있는 모델 병합 방법들을 간단히 소개하고, 최근에 LLM에 모델 병합 기술을 적용하여 주목할 만한 결과를 보여준 연구 2건을 공유드리도록 하겠습니다.
모델 병합이 뭘까?
위에서 잠깐 언급한 바와 같이, 모델 병합을 위해서는 2개 이상의 Pre-trained model이 필요합니다. 모델 병합 기술은 이 모델들을 어떤 방식으로든 조합하여 새로운 모델을 만들어 냅니다. 우리는 새로운 모델이 기존 모델들의 한계를 뛰어넘거나, 각각의 장점을 흡수하기를 바라면서 모델 병합을 수행할 것입니다. 이 과정에는 기본적으로 추가 학습이 필요하지 않으므로 실험 수행에 있어서 비용적인 부담이 적다는 큰 장점이 있습니다.
많이 알려져 있는 모델 병합 방법들을 소개하기에 앞서, 가장 간단한 형태의 병합 수식을 적어보겠습니다.
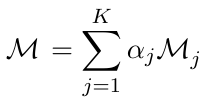
수식 1. Weighted average
K개의 모델 파라미터에 각각의 가중치를 곱한 후 합산하였습니다. 단순한 수식이지만 이렇게 생성된 모델 또한 실제로 잘 동작합니다. 물론 이런 단순한 방법만으로는 우리가 원하는 수준의 모델을 기대하기 어렵기 때문에, 좀 더 고도화된 다양한 방법들이 제안되었습니다. 이어서 각 방법에 대해 좀 더 구체적으로 설명드리도록 하겠습니다.
SLERP (Spherical Linear Interpolation)
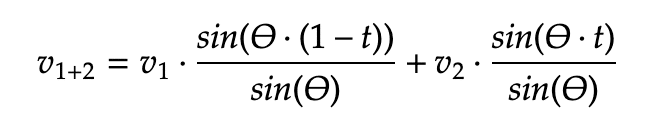
수식 2. SLERP 수식 (t: 0~1 사이의 Hyperparameter, 기본값은 0.5)
SLERP라고 불리는 (한국어로는 구면 선형 보간) 이 수식은 처음에는 모델 병합의 방법으로 제안된 것은 아닙니다. 3D 공간상의 회전과 관련된 수식이지만1 실제로 모델 병합에 있어서 Linear interpolation (=LERP, 선형 보간)의 단점을 상쇄시킬 수 있는 특징 때문에 널리 쓰이고 있습니다.
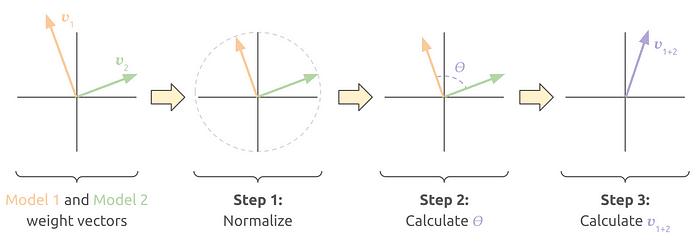
그림 1. SLERP 적용 순서
위 그림에서 볼 수 있듯이 SLERP는 최초의 두 Vector v1, v2를 하나의 원의 반지름과 같은 크기로 Normalize한 뒤, 최종 병합 Vector 또한 그 원 위에 그려지게 됩니다. LERP 방식에 비해 원래의 Vector 크기가 대부분 보존되므로 원 모델의 특성이 그만큼 유지된다고 생각할 수 있습니다. SLERP 방식의 한 가지 단점을 꼽자면 동시에 3개 이상의 모델을 합칠 수 없다는 것입니다. 위에서 언급했던 Weighted average 방법이나 이후에 소개드릴 방법들이 3개 이상의 모델을 동시에 병합할 수 있는 것과 대조되는 특성입니다.
Task Arithmetic
ICLR 2023에서 소개된 이 연구2는 Fine-tuned model과 그 이전의 Pre-trained model의 Parameter 차를 Task vector로 정의한 뒤, 이 Vector를 더하거나 빼는 방식을 통해 새로운 모델을 생성할 수 있음을 보여주었습니다. 이 글에서는 거의 동일한 컨셉으로 최근에 ACL 2024에 제출된 Chat vector3를 소개드리려고 합니다.
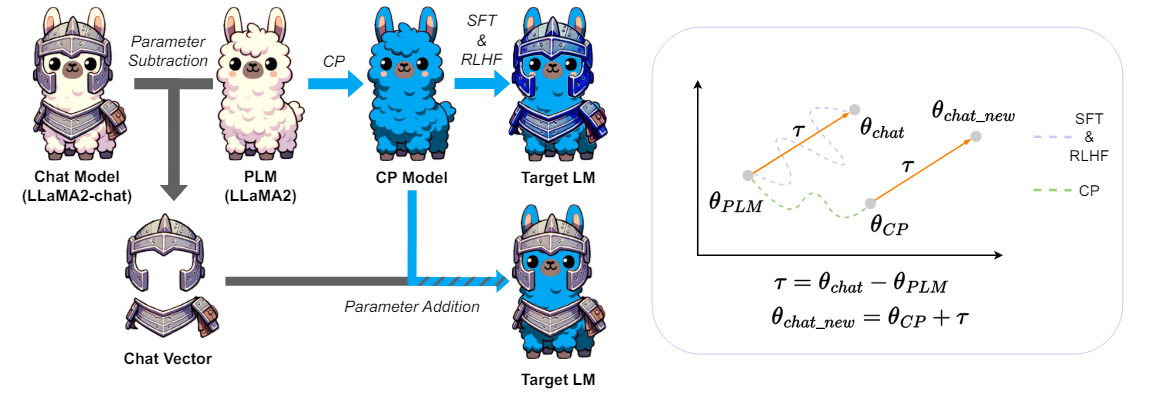
그림 2. Chat vector
설명을 위해 한국어에서의 채팅 능력을 갖춘 모델을 만드는 것을 우리의 목표로 가정해 보겠습니다. 일반적인 학습용 한국어 문서는 어떻게든 구해볼 수 있지만, 한국어 멀티턴 대화 데이터를 구하는 것은 일반적으로 쉽지 않습니다. 이런 상황에서 Chat vector 연구에서 제안한 방법을 적용해 볼 수 있습니다.
이 연구에서는 LLaMA2-chat(=Fine-tuned model)과 LLaMA2(=Pretrained model)의 차를 Chat vector로 명명하였습니다. 이름 그대로 Chat 능력을 가지고 있는 Vector라고 생각할 수 있습니다. 이제 우리의 목적에 맞게 LLaMA2에 한국어 문서를 이용해 추가 학습(=CP, Continual Pretraining)을 진행하면 한국어 대응 능력을 가진 모델이 생성됩니다(그림에서는 파란색 라마). 기존의 방법으로는 이 모델에서 추가적으로 한국어 멀티턴 데이터를 이용해 SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback) 등을 진행해야만 한국어 멀티턴 대화 모델이 생성됩니다. 하지만 이 연구에서의 제안 방법을 따르면 영어 모델에서 구한 Chat vector를 한국어 모델에 더해 주기만 해도 한국어 대화 능력이 갖춰지게 됩니다.
자세한 실험 결과까지 분석하기에는 글이 너무 길어지기에 생략하겠습니다만 Vicuna 벤치마크에서의 평가 결과, Toxic & Unsafe 발화억제 능력 등에서 유의미한 결과를 보여주었습니다. 참고로 저희 언어모델팀에서도 Llama 3 모델을 기반으로 간단한 재현 실험을 진행하였는데 모델 병합 후 1시간 가량의 추가 Fine-tuning을 진행하였다는 차이는 있지만 실제로 모델 성능 향상의 가능성을 확인할 수 있었습니다.

표 1. 한국어에서의 Chat vector 재현 실험 결과
TIES-Merging
세번째로 소개할 모델 병합 방법은 NeurIPS 2023에서 발표된 TIES-Merging(TrIm, Elect Sign & Merge)4입니다. 이 연구에서는 두 Vector가 합쳐질 때 발생할 수 있는 Interference 현상이 정보 손실을 일으켜 결과적으로 통합 모델의 성능을 저해한다고 설명합니다.
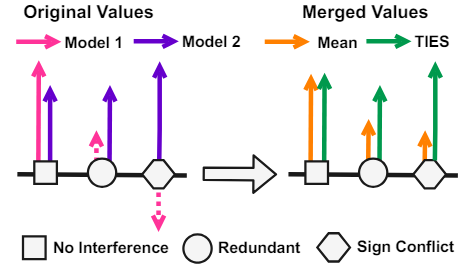
그림 3. Interference 예시
그림과 같이 맨 왼쪽의 네모 케이스와 같이 비슷한 크기의 두 Vector가 합쳐질 때에는 거의 값의 손실없이 합치는 것이 가능합니다. 하지만 한 쪽의 Vector가 상대적으로 작거나 반대 방향을 가리킬 경우에는 통합된 Vector의 크기가 상당히 줄어드는데 이것을 바람직하지 않은 Interference 현상으로 설명하고 있습니다. 제안된 TIES-Merging 방법에서는 위 그림에서 볼 수 있듯이 Interference를 유발하는 점선의 Vector들을 배제시킨 후에 통합을 진행, 결과적으로 Mean 대비 원래의 크기가 유지된 통합 Vector를 만들어 냅니다.
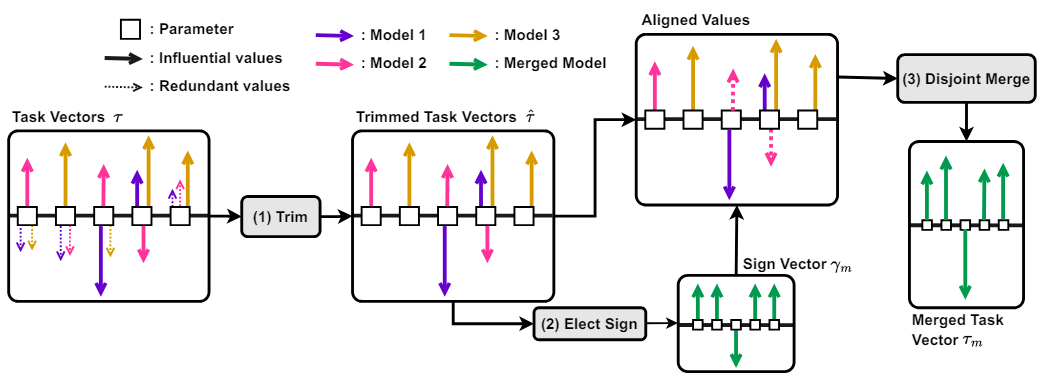
그림 4. TIES-Merging 적용 과정
TIES-Merging은 다음과 같은 3단계로 진행됩니다.
- Trim: Significant parameter들을 선별한 뒤, 이에 해당되지 않는 나머지 값들을 0으로 변경합니다.
- Elect Sign: 각 parameter에 대해 Sign vector(positive or negative)를 결정합니다.
- Disjoint Merge: 마지막으로 Sign vector와 일치하는 Vector들만을 대상으로 통합을 수행합니다.
이 방법의 특징은 앞서 설명한 바와 같이 Interference를 줄이면서 주요 Feature만을 선별적으로 통합한다는 것입니다. 또한 여러 개의 모델을 동시에 통합할 수 있는데, 발표된 논문에서도 7개의 Multi task-specific model의 통합을 가정하고 실험을 진행하였습니다. 다만 Trim과 Elect Sign 과정에서 각각의 선정 기준이 필요하고, 특히 Sign 선정 성능에 따라 통합 모델의 성능이 달라질 수 있다는 부분은 단점이 될 수 있습니다.
DARE
마지막으로 소개드릴 방법은 “Language Models are Super Mario: ”로 시작되는 ICML 2024에 제출된 논문에서 제안하는 DARE(Drop And REscale)5입니다. 제목만 보고는 내용을 짐작하기 어렵지만, 병합 방법 자체는 굉장히 직관적이고 명확합니다. Delta parameter(=Fine-tuned model과 Pre-trained model의 Parameter 차)들 중에 확률 p로 랜덤하게 선택된 값들은 버리고(Drop), 남겨진 값들은 1/(1-p)를 곱해 크기를 키웁니다(Rescale). 이렇게 한 줄만으로도 설명 가능한 DARE 수식은 왠지 익숙한 분들이 많을 텐데요, 아마 Dropout에서 학습 Weight에 적용하는 것과 동일한 수식을 사용하기 때문일 겁니다.
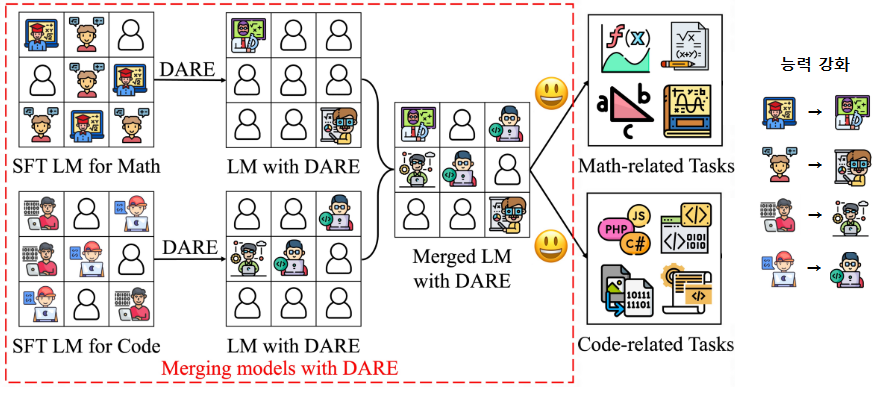
그림 5. DARE 적용 과정
논문의 그림 일부를 가져와 다시 DARE 적용 과정을 살펴보겠습니다. 여기에서는 수학을 잘하는 모델과 코딩을 잘하는 모델이 주어졌다고 가정했을 때, 각각에 DARE를 적용하면 원 모델에서 Delta parameter 상당수가 제거됩니다(그림에서는 박스 6~7개 → 2~3개로 감소). 그리고 남은 Delta parameter들은 Rescale되었는데 그림에서는 능력이 강화된 전문가로 표현되었습니다. 논문에서는 거의 90%의 Delta parameter를 제거해도 성능이 유지될 수 있다고 주장하는데, 이에 따르면 그림과 같이 통합 과정에서 각 모델의 Delta parameter가 거의 중복되지 않게 되고, 각 모델의 특징이 희석되지 않아 통합 모델 또한 수학과 코딩 능력을 거의 손실없이 물려받을 수 있게 됩니다. 위에서 설명했던 Inference로 인한 성능 하락이 거의 없는 방식이라고 할 수 있습니다. 논문 제목에서 슈퍼마리오를 언급한 것은 Delta parameter를 흡수한 통합된 모델이 불꽃을 먹고 불을 던지는 능력을 얻게 되는 마리오와 유사하다는 의미의 비유로 보입니다.
참고로 Delta parameter가 아닌 Fine-tuned parameter에 직접 DARE를 적용하였을 경우에는 10%의 Drop만으로도 원래 모델의 성능을 유지할 수 없었다고 합니다. Fine-tuning 전의 Base model의 Parameter 유지가 중요하다고 볼 수 있고, 반대로 SFT로 획득된 변화량 중 상당수는 성능에 큰 영향을 주지 않는다고 해석할 수도 있겠습니다.
마치며
모델 병합에 대한 기존의 대표적인 연구들을 소개한 뒤에 이를 활용하여 주목할 만한 결과를 보여준 최근 연구를 설명드리려고 했는데, 생각보다 배경 설명이 많이 길어져 버렸습니다. 이 글은 일단 여기에서 마무리짓고, 2부에서 “Evolutionary Optimization of Model Merging Recipes”와 “Disperse-Then-Merge: Pushing the Limits of Instruction Tuning via Alignment Tax Reduction” 연구에 대해 자세히 소개하도록 하겠습니다.
참고 문헌 및 자료
-
Editing Models with Task Arithmetic, ICLR 2023 ↩
-
Chat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages, ACL 2024 ↩
-
TIES-Merging: Resolving Interference When Merging Models, NeurIPS 2023 ↩
-
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch, ICML 2024 ↩
