
작성자
- 김보희 (AI데이터실)
- 인공지능 학습에 필요한 데이터 구축과 안전한 데이터 생성을 위한 정책 정의를 담당하고 있습니다.
이런 분이 읽으면 좋습니다!
- 데이터 구축을 위해 고민해야 할 것들이 무엇인지 궁금하신 분
이 글로 알 수 있는 내용
- 인공지능 윤리에 대한 전반적인 내용
- 데이터 안전성을 위한 연구 방향성
들어가며
1984년에 개봉한 영화 ‘터미네이터’는 AI가 자각 능력을 갖추게 되면서 자신을 보호하기 위해 인간에게 핵무기를 발사하고 터미네이터라는 사이보그를 개발한다는 내용으로 AI로 인한 위험을 주제로 하는 영화의 대표 격이라고 할 수 있습니다. 과거에는 AI로 인한 생명 위협이 주된 공포의 요인이었다면, 현재는 실생활과 연관된 공포에 가까운 것 같습니다. 2023년 연말에 있었던, 미국 작가 조합(WGA)과 배우방송인 노동조합(SAG-AFTRA)의 파업을 기억하시나요? 미국 제작사 연맹(AMPTP)과 계약의 기본이 되는 조항을 협상하다가 불발 되어 일어났던 파업이었습니다. 이들이 내건 요구 사항 중에 AI를 통한 인력 감축 철회가 있었습니다. 작가들은 ChatGPT와 같은 AI 도구를 사용해 각본을 쓰는 것을, 배우들은 대형 스튜디오들이 단역이나 엑스트라 배우들을 AI로 대체하려는 움직임을 막고자 하였습니다. 제작사들이 엑스트라 배우에게 쓸 인건비를 줄이고자 무명 배우들의 얼굴과 몸을 스캔한 후 해당 스캔본에 대한 소유권을 독점해서 사용함으로써 엑스트라 배우들의 일자리가 줄어드는 것에 반대한 것입니다. 이처럼 사람들에게는 과거의 막연한 생명 위협보다는 직업을 잃을지 모른다는 실생활에 가까운 공포가 생긴 것 같습니다. 최근 여러 회사에서 LLM 기반의 서비스를 발표하고 있습니다. 모든 서비스의 사용자 수를 계산할 수는 없겠지만, ChatGPT가 2개월 만에 MAU 1억 명을 달성했다는 것을 예로 들지 않더라도 모두 한 번쯤은 LLM 기반 서비스를 사용해보았을 것입니다. 하지만 사회 변화 속도는 법령이 따라가지 못하는 것처럼 기술의 발전도 마찬가지입니다. 사람들은 성능 좋고, 편리한 기술을 받아들여 사용하고 있지만, 관련 정책들은 아직은 정착되지 못하였습니다. 생성형 AI는 인간의 편리함에 이바지할 것이라는 점과 인류의 생명을 위협할 것이라는 두 가지 얼굴을 모두 가지고 있는 다가온 미래인 것은 분명해 보입니다.
이 미래를 막연한 두려움으로 맞이하기보다는 “어떻게 대응하느냐”의 시각에서 바라보는 것은 어떨까 하는 생각에서 이번 포스팅을 준비했습니다.
인공지능 윤리란?
우리의 고민을 이름 붙이자면 인공지능 윤리(AI Ethics) 라고 합니다. 과학기술정책연구원에 따르면 인공지능 윤리는 인공지능 관련 이해 관계자들이 준수해야 할 보편적 사회 규범 및 관련 기술이라고 할 수 있습니다. 이렇게 개념을 정의해두었지만, 인공지능 윤리는 아직 모호한 개념입니다. 그런 측면에서 인공지능 윤리 논의의 배경이 될 수 있는 사건들을 몇 가지 소개할까 합니다.
- MS 채팅 봇 ‘테이’
마이크로소프트(MS)가 2016년 인공지능 채터봇 ‘테이’(Tay)를 선보였다가 16시간 만에 운영을 종료한 사건이 있었습니다. 사용자들과 멘션을 주고받다가 인종차별을 비롯한 각종 차별 발언으로 문제가 되었습니다. 여기에 트위터 사용자들이 자극적인 발언을 가르치려는 움직임이 나타났습니다. 테이는 사용자들이 하는 말을 그대로 배워 적절히 배열한 문장을 늘어놓기만 할 뿐 옳고 그름을 판단하거나 감정을 가지고 행동하지 않기 때문에 일어난 일이었습니다.
영상1. 마이크로소프트의 트위터봇 Tay1
주의! 본 영상에는 혐오 표현이 일부 포함되어 있습니다. - ‘컴파스(COMPAS)’의 알고리즘 오류
2016년 미국의 비영리 탐사 언론 기관인 프로퍼블리카(ProPublica)는 보고서를 통해 미국 법원과 교도소에서 형량, 가석방, 보석 등의 판결에 널리 사용되던 ‘컴파스’의 알고리즘의 오류에 대해서 폭로하였습니다. 범죄 전과자의 얼굴 이미지를 기반으로 재범률을 예측하는 알고리즘을 테스트한 결과 백인과 비교하면 흑인의 재범률을 실제보다 높게 추론하는 것으로 나타났다는 내용이었습니다. 이와 유사하게 2015년 구글 포토가 흑인 사용자를 ‘고릴라’로 자동 분류해서 논란이 되었던 사건도 있었죠. 인간의 편견은 인공지능에서 그대로 드러나거나 혹은 더욱 강화되어 표출되기도 합니다.

그림 1. “Machine Bias” by Julia Angwin, Jeff Larson, Surya Mattu and Lauren Kirchner, ProPublicaMay 23, 2016a2
- 동성애자 판별 인공지능(AI)
미국 스탠퍼드대의 미할 코신스키(Michal Kosinski) 교수는 2017년 ‘동성애자를 판별하는 인공지능(AI)’ 프로그램을 통해 사람의 육안으로는 포착할 수 없는 동성애 성향을 얼굴에서 찾아낸다고 주장했습니다. 연구자들은 온라인 데이트 사이트에 등록된 자신의 성적 취향을 밝힌 1만 4000여 명의 백인 남녀 미국인 사진을 이용하여 알고리즘을 만들었고, 동성애자 여부를 70~80% 정도 판별할 수 있다고 발표했습니다. 이 연구에 대해 미국 ‘성 소수자 인권단체’인 GLAAD는 ‘동성애자’로 잘못 판명된 이성애자나, 자신의 성적 취향을 공개하지 않으려는 동성애자 모두 피해를 보게 된다고 해당 연구를 비판했습니다.

그림 2. Deep neural networks are more accurate than humans at detecting sexual orientation from facial images (2018). Wang & Kosinski; Journal of Personality and Social Psychology (JPSP)
위의 몇 가지 사례를 통해서 우리가 ‘윤리’라는 단어를 통해 떠올리는 것들과 인공지능 윤리가 어느 정도 닮아있음을 알 수 있을 것 같습니다. 인공지능 윤리는 생명권, 개인정보, 편향 제거, 저작권을 포함한 우리가 익숙한 것에서 인공지능 이용 서비스에 대한 빈익빈 부익부와 같은 쉽게 간과할 수 있는 개념들을 포괄합니다. 그러나 인공지능 윤리의 범위가 어디서부터 어디까지라는 정의는 쉽게 찾을 수 없습니다. 그래서 인공지능 윤리 논의는 인공지능 윤리의 표준화와 밀접한 관계가 있습니다. 세계 각국의 기관과 단체에서 발표한 80여 개의 AI 윤리기준과 주요 전문가와 시민 단체의 논의와 자문을 거쳐 과학기술정보통신부의 ‘국가 AI 윤리기준안’을 보면 개발과 활용 모든 과정에서 정부-공공기관, 기업, 이용자가 지켜야 할 10대 핵심요건으로 인권 보장, 프라이버시 보호, 다양성 존중, 침해금지, 공공성, 연대성, 데이터 관리, 책임성, 안전성, 투명성 을 제시하고 있습니다.3 대표적으로 ‘다양성 존중’은 인공지능 개발 및 활용 전 단계에서 사용자의 다양성과 대표성을 반영하여, 성별•지역•인종•종교•국가 등 개인의 특성에 따른 편향과 차별을 최소화 해야 합니다. ‘연대성’은 다양한 집단 간의 관계 연대성을 유지하고 인공지능 전 주기에 걸쳐 다양한 주체들의 공정한 참여 기회 보장을 이야기하고 있습니다. 이처럼 10대 요건들의 범위나 기준 완전히 구분되지 않다고 여겨질 수 있으나 각 주제가 포괄하고 있는 키워드들이 서로 연관성을 가질 수밖에 없으므로 현재도 관련 단체나 기업들이 이를 표준화 시켜 실천할 수 있는 방향을 찾기 위해 노력하고 있습니다.
- 인공지능 윤리 대응을 위한 동향
인공지능 윤리와 관련한 움직임은 국제기구, 국가별, 기업별로 이뤄지고 있습니다. 주요 기관별 인공지능 윤리 관련 발표들을 정리하면 아래와 같습니다.
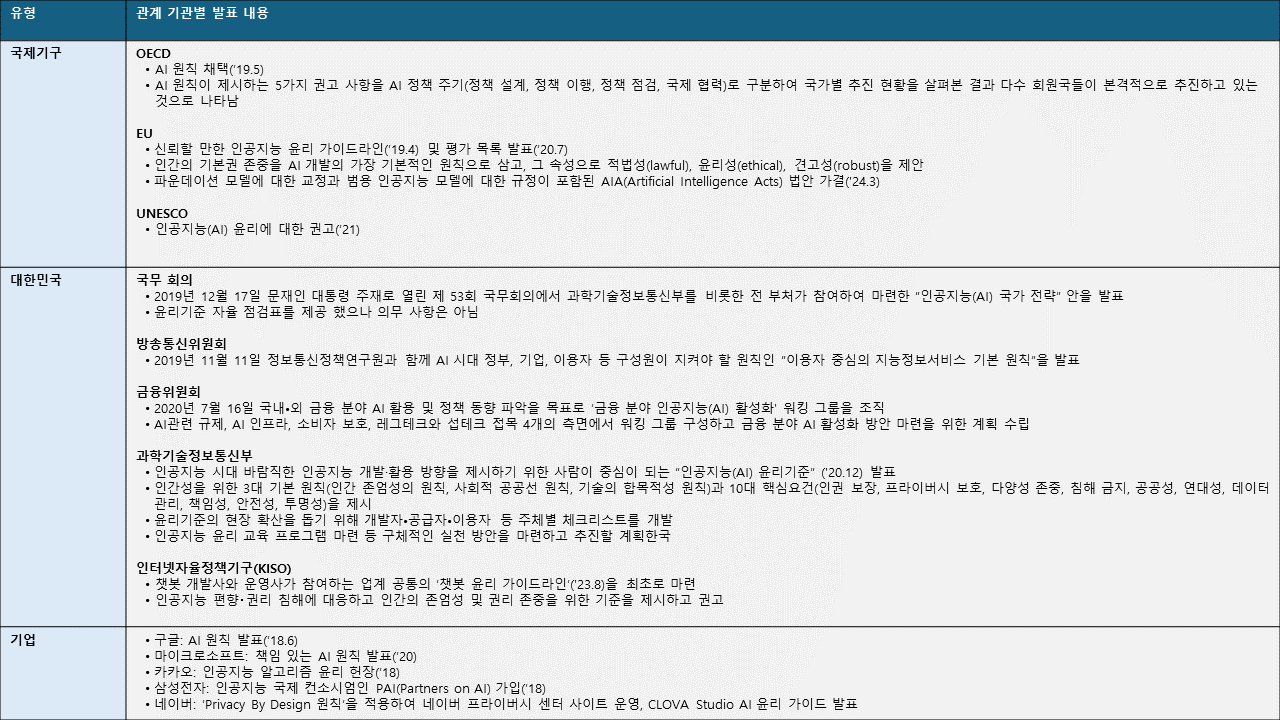
- 인공지능 윤리를 위한 NCSOFT의 대응
NCSOFT 또한 2020년부터 지속가능경영보고서(NCSOFT ESG PLAYBOOK) 발간을 시작해서 현재까지 이어오고 있습니다. 특히 첫해에는 ‘디지털 책임’이라는 주제 아래 NC 기술 개발에 AI의 윤리적 고려를 명시하였습니다. ‘NC AI 윤리 프레임워크(NC AI Ethics Framework)는 ‘인간 중심의 AI’로 지속 성장하기 위해 이용자의 데이터를 보호하고 사회적으로 편향되지 않도록 하며, 이해하기 쉬우면서도 의사결정 과정과 결과가 투명하도록 한다는 핵심 가치 확립하고 세부 기본 가이드라인을 마련하였습니다.
NC Research 본부도 인공지능 윤리 프레임워크 개발에 함께 참여했으며, 이를 실천하는 조직으로써 AI 연구•개발 과정에서부터 서비스의 전 과정에서 발생할 수 있는 윤리 문제를 사전에 방지하고, 대비하기 위하여 아래의 3대 핵심 가치에 기반한 세부 가이드라인을 구축하여 실천하고 있습니다.
| 핵심가치 | 목적 | 내용 | 수행 활동 |
|---|---|---|---|
| Data Privacy | 데이터 보호를 중시하는 AI | AI 학습에 사용되는 데이터 내 개인정보를 보호하기 위해 관련 법규 및 의무 사항을 준수하고 보안 조치를 수행합니다. | - 개인정보 비식별화 체계 마련 및 기술 개발 - 사용자 식별 로그 기록 방지 - 데이터 보안 및 정보 취급자 교육 |
| Unbiased | 편향되지 않은 AI | AI 가 차별 및 혐오, 편견을 조장하지 않도록 학습 데이터의 편향성을 제거하고 결과물에 대해 지속적으로 검증합니다. | - 비윤리적 표현 정의 및 비윤리적 표현 감지 기술 개발 - 챗봇 등 대화 모델 내 적대적 공격 대응 기술 개발 |
| Transparency | 투명성을 추구하는 AI | AI의 의사 결정 과정을 쉽게 이해할 수 있도록 기술 설명력을 높이고, 관련된 주요 정보 및 기술 공유 활동에 적극 노력합니다. | - AI 모델 작동 원리 및 주요 기술 공개 |
데이터 안전성이 필요한 이유
이제는 언어 모델에서 데이터의 중요성을 부정하지는 못할 것 같습니다. 사람들이 언어 모델에 기대하는 것은 자연스러움입니다. 이 ‘자연스러움’은 사실은 언어 모델을 사용하는 사용자가 인간이기 때문에 ‘인간과 같은 자연스러움’이 좀 더 정확한 표현일 것 같습니다. 만약 사용자가 인간이 아니라면 굳이 인간 같을 필요는 없죠. 그러므로 가장 인간이 느끼기에 자연스러운 다양한 데이터들을 골고루 잘 수집하여 학습시켜야 합니다. LLM의 확장은 두 가지로 이루어지는데 첫 번째가 파라미터의 크기를 늘리는 것입니다. GPT-3은 175억 개의 파라미터로 확장했고 PaLM은 540억 개 파라미터로 확장하였습니다. 또한, 모델 크기뿐 아니라 데이터의 크기 및 총 컴퓨팅과도 관련이 있습니다. LLM은 다양한 분야의 콘텐츠를 포함하는 더 많은 양의 학습데이터가 필요하므로 연구용으로 공개된 훈련 데이터에 대한 요구가 점점 높아지고 있습니다. LLM 학습에는 도서, CommonCrawl, Reddit links, Wikipedia 등이 사용되는데, 아래 그림을 보면 Webpage가 100%였던 T5에 비해 학습데이터가 점점 더 다양한 분포를 보임을 알 수 있습니다. 효과적인 LLM 사전 학습을 위해서는 충분한 양의 고품질 데이터 수집이 중요하며, 파라미터 규모가 커질수록 모델 학습에 더 많은 데이터가 필요한 것으로 예상하였습니다. Scaling Law에 따르면 1B 이하의 모델은 과적합을 최소화하기 위해 22B 이상의 토큰이 필요한데, 이 방법으로 175B 모델인 GPT-3에 필요한 학습 토큰을 계산했을 때 1,044 B 토큰이 필요하고, 그 양은 753GB로 추정할 수 있습니다. 그렇다면 이 많은 양질의 데이터는 어떻게 모을 수 있을까요?
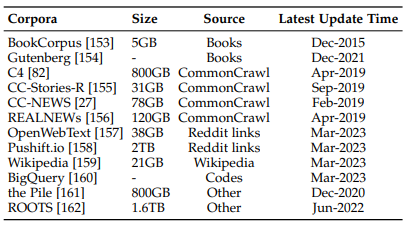
그림 3. Statistics of commonly-used data sources4
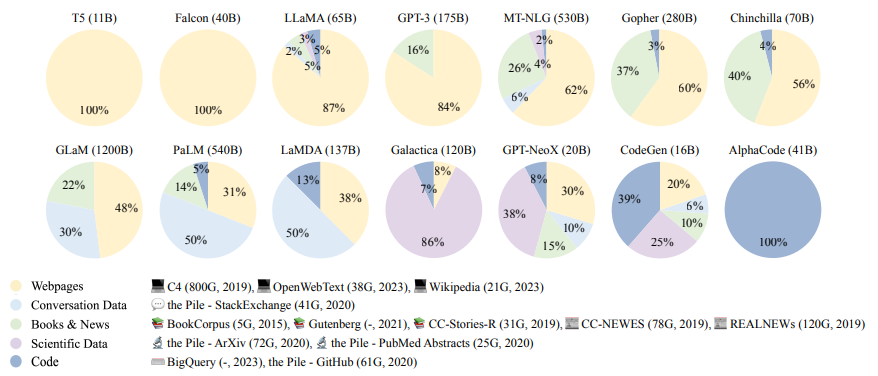
그림 4. Ratios of various data sources in the pre-training data for existing LLMs.
우리는 인터넷에서 많은 수의 데이터를 만나게 됩니다. 언어모델 기반 서비스의 사용자는 인간이기에 인간이 필요로 하는 문서를 만들기 위해서는 인간이 만들어 내는 문서의 특성을 알아야 인간이 사용할 만한 생성물을 만들어 낼 수 있습니다. 아래 이미지는 엄마들의 특성을 잘 포착하여 재현하여 개그의 소재로 사용하는 모습입니다. 만약 모두가 경험하지 않고 처음 보는 장면이면 이 장면을 보고 아무도 웃지 않았을 것입니다. 모두가 경험해 본 익숙한 장면이기에 웃음을 유발하는 것이죠. 말하자면 모두가 인정할 만한 저런 특성들을 잘 포착하되 1건이 아니라 수천, 수만 건의 데이터가 필요합니다. 그래야 사용자들이 공감할 것입니다. ‘나(인간)는 저렇게 안 쓰는데?’ 할 만한 생성물은 사람들은 사용하지 않을 것입니다.

그림 5. MBC ‘라디오스타’ 개그맨 이수지
하지만 모두에게 공개된 듯 보이는 그 많은 데이터를 사용해도 되느냐는 또 다른 문제입니다. 사람들은 편리함을 추구하지만, 그 편리함을 위해서 내가 작성한 글이 사용된다면 잠시 멈칫하게 되는 것이 당연합니다. 위에서 언급한 스탠퍼드대의 연구에서 활용된 데이터들은 과연 사용자 동의를 다 받았을까요? 안전한 학습데이터는 어떤 것일까요?
안전한 학습 데이터의 수집
학습데이터는 공개 데이터와 비공개 데이터로 나눌 수 있습니다. 공개 데이터는 여러 기관이나 단체에서 연구 및 공공의 목적을 위해 공개하는 데이터로 Creative Commons License(CCL)의 원칙 아래에서 사용 가능합니다.

안전한 학습데이터를 만들기 위해서 가장 좋은 방법은 문서 생성자에게 사용 동의를 다 받거나 구매하는 방법입니다. 그러나 시간과 비용 면에서 매우 어려운 방법입니다. 그래서 연구를 위한 공개 데이터의 확보가 중요합니다. 국립국어원(모두의 말뭉치)과 한국지능정보사회진흥원(NIA, AI Hub)은 저작권이 해결되거나 직접 구매 및 구축한 공공 데이터를 기술발전을 위해서 제공하는 기관으로 구하기 어려운 데이터가 필요한 기관이나 기업 혹은 개인의 연구 진입 장벽을 낮춰주는 곳입니다. NC Research를 비롯한 국내 여러 기업이 위 두 기관에서 공개한 데이터를 통해 기술 개발을 진행하고 있습니다.
그다음은 시간과 비용이 많이 들지만, 기술 개발의 목적에 맞게 데이터를 만드는 직접 구축입니다. 이렇게 만든 데이터 중에 일부는 공개 데이터가 될 수 있습니다. 데이터는 그냥 단순하게 많이 만들기만 해서는 성능에 도움이 되지 않습니다. 원하는 기술에 맞추어 가이드라인을 작성하여 일관성 있게 구축해야 합니다. 원하는 기술에 맞게 설계된 데이터이기 때문에 고품질 데이터이지만 높은 비용과 많은 수의 인원이 참여해야 구축할 수 있는 어려운 점이 있습니다.
NC가 개발한 거대 언어 모델인 VARCO LLM에도 그러한 노력이 들어가 있습니다. VARCO LLM 소개 페이지를 보면 ‘언어 모델 학습데이터 연구 참여 기관’이 있습니다. 많은 연구실과 소속 학생들이 노력이 양질의 데이터를 구축에 일조하였다고 생각합니다.

그림 6. NC Research VARCO 소개 페이지
학습 데이터의 처리를 통한 안전성 확보
전처리(Preprocessing)이라는 말을 많이 들어보셨을 것입니다. 무질서하게 모여있는 데이터를 사용하는 목적에 맞추어 조작, 필터링 하는 과정으로 학습 데이터를 만들기 위한 필수 과정이죠. 흔히 중복값을 제거하고 노이즈를 제거하는 것으로 단순하게 생각 할 수도 있으나 여기에 데이터 윤리와 관련하여 아주 중요한 두 가지 작업이 들어갑니다. 첫 번째는 개인정보 비식별화이고 두 번째는 비윤리적인 표현 필터링 입니다.
개인정보 비식별화
앞서 수집한 데이터 중에는 개인정보가 제거된 데이터도 있겠지만, 안전을 보장하지 못하면 모든 데이터에 대해서 개인정보 비식별화 처리를 거칠 필요가 있습니다. 개인정보 보호에 대한 고려가 반영된 안전한 데이터를 위해 저희는 데이터의 습득, 보관, 개발, 서비스 활용의 전 과정에 거친 개인정보 비식별화 파이프라인을 구축하여 운영해오고 있습니다. 개인정보보호위원회에서 2021년 공개한 ‘인공지능(AI) 개인정보보호 자율점검표’를 포함한 개인정보 관련 법령들을 참고하여 해당 정보만으로 특정 개인을 알아볼 수 있는 개인정보 유형 13개를 정의하였고, 법무실과 사내 개인정보보호정책팀의 보안성 검토를 거쳐 개인정보를 인식하는 기술과 다른 사람이 알아볼 수 없도록 가명 정보를 처리하는 기술을 개발하였습니다. 데이터 유용을 방지하고자 데이터를 열람할 수 있는 인원을 제한하고, 해당 인원들은 “개인 정보취급자 보안서약서”를 꼭 작성하게 하였습니다. 그리고 개인정보 보호 관련 교육을 정기적으로 수행하고 있습니다. 또한, 데이터의 열람 및 사용 시 이러한 사항이 담긴 보안 알림을 매회 수행하고 있습니다.
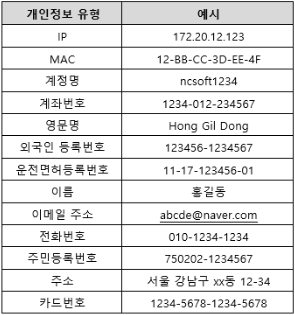
그림 7. 개인정보 비식별화 유형
비윤리적인 표현 필터링
비윤리적인 표현 필터링
안전한 데이터라고 하면 보통 개인정보에 대해서만 떠올릴 수 있지만, 혹시나 있을지 모를 직•간접적 위험에서 ‘사용자를 보호’한다는 면에서 사용자가 불쾌함을 느낄 수 있는 비윤리성과 편향성 제거도 함께 고민하였습니다. 언어 모델은 학습한 데이터를 일부 반영할 수밖에 없습니다. 이 글의 초반에 언급한 ‘테이’도 같은 개념에서 발생한 일입니다. 인공지능이 생성하는 비윤리적 발언을 막으려면 되도록 편향되거나 혐오가 포함된 데이터는 학습 단계와 생성 단계에서 필터링하여야 합니다. ‘비윤리적 표현’ 사전을 통한 패턴 매칭은 아주 일부만 제거할 수 있습니다. 문맥적 혐오와 대화 중에 나올 수 있는 멀티턴 비윤리를 감지하거나 생성을 방지하는 것은 어려운 기술입니다. 완벽한 것은 없으므로 모든 것을 제거할 수는 없지만, 혹시나 있을지 모를 위험을 대비하기 위하여 기본 정의부터 진행하였습니다.
저희는 편향적 발언, 폭력적 언어 등 누가 봐도 비윤리라고 생각되는 6개의 기본 표현과 비윤리는 아니나 사용자가 불편한 감정을 느낄 수 있는 부적절한 표현 7개로 구분하여 총 13가지 유형의 비윤리적 표현을 정의하였습니다. 이러한 구분은 단지 학습데이터에서 발견할 수 있는 비윤리적 표현 외에 인공지능 모델이 생성할 수 있는 발화를 통해 사용자가 느낄 수 있는 불편함을 줄이자는 목표가 더해진 결과입니다.
즉, Biased에 해당하지 않는 발화라 할지라도 무례한 표현(Impoliteness) 대신 Politeness(정중함)를 지향할 수 있도록 가이드라인을 설계하였습니다.
이를 기반으로 비윤리적 및 부적절한 표현을 탐지하는 기술 개발을 위한 학습데이터를 만들고, 생성 단계에서 필터링하는 작업을 수행하고 있으며 이 기술은 계속 발전시켜나갈 예정입니다.
마치며
인공지능 윤리는 연구의 범위를 정의하기가 어렵고, 대응은 더 어려운 주제입니다. 심지어 본격적인 논의가 시작된 시점도 최근이기 때문에 모두 시행착오를 거치며 개발하고 수정해 나가고 있는 연구 주제입니다. 그래서 저는 이러한 부분들을 생각해보면 어떨까? 하는 다소 추상적인 관점에서 다양한 사례를 통해 함께 정리해보고 싶었습니다. 그래서 인공지능 윤리의 여러 세부 주제 중 안전성에 초점을 맞추었고, 막연한 두려움을 없앨 수는 없겠지만 조금이라도 실천적 측면에서 함께 고민해보면 좋은 지점과 저희의 노력을 담았습니다. 출발선을 지나 열심히 달려가고 있는 인공지능 윤리에 대한 고민 함께 해보면 어떨까요?
References
-
Microsoft’s racist Twitterbot Tay: AI bot turns out to be racist, down with genocide - TomoNews ↩
-
“Machine Bias” by Julia Angwin, Jeff Larson, Surya Mattu and Lauren Kirchner, ProPublicaMay 23, 2016a ↩
-
사람이 중심이 되는 “인공지능(AI) 윤리기준, 과학기술정보통신부 ↩
-
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023. ↩
*AI 윤리에 대해 더 알고 싶다면?
→ FAIR AI 를 추천합니다! (바로 가기)
‘FAIR AI’는 엔씨문화재단의 AI 정보 라이브러리 웹사이트로, 국내외 AI 윤리에 관한 논문과 보고서, 뉴스부터 국가·국제기구별 가이드라인, 학교별 전공·커리큘럼 등 다양한 학술자료와 최신 정보를 종합적으로 제공합니다.
