
- 들어가며
- 얼굴 애니메이션 생성 기술 활용 분야
- 얼굴 애니메이션의 특징
- 음성 기반 얼굴 애니메이션 생성 기술 소개
- 기술 사례 - NVIDIA Audio2Face
- 기술 현황 - NC Research
- 마치며
작성자
- 오준 (그래픽스 AI Lab)
- Facial Animation 생성 서비스를 연구 개발하고 있습니다.
이런 분이 읽으면 좋습니다!
- 얼굴 애니메이션 제작 자동화에 관심 있는 분
- 애니메이션에 생성 모델을 적용한 사례가 궁금한 분
이 글로 알 수 있는 내용
- 음성 기반 얼굴 애니메이션 생성 분야의 기본적인 접근법을 이해할 수 있습니다.
- NVIDIA Audio2Face와 같은 최신 기술을 통해 얼굴 애니메이션 제작 효율성을 높이는 방법을 알 수 있습니다.
들어가며
안녕하세요. 저는 엔씨소프트에서 얼굴 애니메이션을 연구하고 있습니다. 이 글에서는 얼굴 모델링부터 캡쳐, 애니메이션까지 다양한 분야 중, 메쉬 타겟 얼굴 애니메이션 생성 기술에 대해 소개하고자 합니다.
메쉬 타겟 얼굴 애니메이션 생성 기술은 캐릭터가 처한 상황 정보를 입력받아 캐릭터의 얼굴을 적절히 움직이게 하는 기술입니다. 입력 정보로는 캐릭터의 발화 여부, 문맥상 표현해야 하는 감정 상태, 말하는 음성, 상대방의 위치 등이 포함됩니다. 결과물로 입술을 포함한 얼굴의 모든 부분이 자연스럽게 움직이는 3D 모델의 메쉬 애니메이션이 생성됩니다.
이 글에서는 음성을 입력으로 받아 자연스럽게 움직이는 얼굴 애니메이션을 만드는 메쉬 타겟 얼굴 애니메이션 생성 기술을 중점적으로 설명하겠습니다.
얼굴 애니메이션 생성 기술 활용 분야
얼굴 애니메이션 생성 기술은 게임 제작 과정 효율화에 큰 도움을 줄 수 있습니다. 우리가 게임을 할 때 보게 되는 장면들을 떠올려볼까요? 게임을 하다 보면 여러 등장인물들 간 대화 장면을 보게 됩니다. 이 장면들을 보고 있으면 어떤 캐릭터들은 얼굴을 찌푸리기도 하고, 어떤 캐릭터는 웃기도 하는 등 다양한 표정을 보여주죠. 즉, 게임을 만드는 입장에서는 수많은 얼굴 애니메이션 제작이 필요하단 뜻이기도 합니다. 이를 위해 얼굴 움직임을 캡쳐하거나 수작업으로 만드는 것은 많은 비용이 듭니다. 하지만 음성 기반 얼굴 애니메이션 생성 기술을 사용하면 이러한 작업을 자동화할 수 있어 비용을 크게 절감할 수 있습니다. 상황에 맞는 얼굴 애니메이션을 자동으로 생성함으로써 사용자에게 더 큰 몰입감을 줄 수 있습니다.
한 예로 최근 사이버펑크 2077에서는 JALI라는 얼굴 애니메이션 생성 기술을 통해 국가별 음성에 맞는 얼굴 애니메이션을 제공할 수 있었습니다. 사이버펑크 2077은 매우 많은 대사량을 가진 게임이며, 나라별로 로컬라이징까지 해야 하므로 자동화된 방법이 없었으면 제작하기 어려웠을 것입니다. 해당 기술을 통해 캐릭터의 목소리에 맞는 자연스러운 얼굴 애니메이션이 제작 가능했고, 플레이어들에게 몰입감을 주는 경험을 제공할 수 있었습니다.
영상 1. JALI를 사용하여 만든 애니메이션 1
얼굴 애니메이션의 특징
얼굴 애니메이션 생성은 크게 입술 부위와 그 나머지 부위(눈, 코, 이마 등)를 분리하여 분석하고, 각각 다른 접근법으로 해결합니다. 그 중에서 입술은 음성에 매우 직접적인 영향을 받고 그 편차가 적은 편이며, 매우 짧은 길이의 입력 값을 넣더라도 생성하는 데 큰 문제가 없습니다. 대신 입술은 밀리 초(ms) 단위의 정확한 움직임을 필요로 합니다. 하지만 그 외의 부위(눈 깜박임, 눈 부위 근육, 목 움직임 등)는 입술보다 편차가 크고, 음성에 대한 영향도 적습니다. 대신 감정 상태나 바라보는 상대 등 다양한 변수를 고려해야 됩니다. 예를 들어 눈 깜박임은 입술보다 타이밍이 부정확해도 되지만, 입술 애니메이션을 만드는데 필요한 음성 길이보다 매우 긴 수 초 단위의 긴 길이의 예측(Prediction)을 필요로 합니다.
음성 기반 얼굴 애니메이션 생성 기술 소개
음성 기반 얼굴 애니메이션 생성은 크게 다음과 같이 두 가지 주요 방식으로 나뉩니다.
-
Phoneme to Viseme Mapping: 음성에서 음소(Phoneme)를 추출한 후, 해당 음소에 맞는 입술 포즈(Viseme)를 매핑하는 방식입니다. 이 방식은 규칙 기반이며, 언어에 종속적이므로 다양한 언어에 적용하기 어렵습니다. 또한, 사람이 작성한 규칙이기 때문에 발화 속도, 볼륨 등에 대해 안정적으로 동작시키기 어렵습니다. Phoneme 추출의 정확도가 낮아 별도의 강제 정렬(Forced alignment) 단계가 필요하며, 이는 언어 별로 구성해야 하는 문제가 있습니다.
-
학습 기반 방식: 음성과 얼굴의 Geometry 정보를 학습하여 애니메이션을 생성하는 방식입니다. 이 방식은 데이터 확보가 어렵고 기계 학습에 대한 이해가 필요하지만, 다양한 상황에 대해 더 유연한 결과를 만들 수 있습니다. 가장 큰 장점은 언어별로 구축해야 하는 강제 정렬 과정이 불필요하고, 더 높은 퀄리티의 결과물을 제공한다는 점입니다. 대표적인 예로는 NVIDIA의 Audio2Face가 있습니다. 내부적으로는 Phoneme to Viseme Mapping의 한계를 극복하기 위해 학습 기반 방식을 연구하고 있으며 아래 글에서는 학습 기반 방식을 위주로 설명하겠습니다.
촬영된 입술 애니메이션은 같은 사람, 같은 입력 음성이더라도 입술 동작의 차이가 존재합니다. 사람에게 같은 단어를 반복적으로 말하게 시키더라도 미묘하게 매번 다른 모션을 만들어 내기 때문입니다. 이런 데이터를 학습하게 되면 그 평균에 수렴하는 결과물이 나오게 되어 실제 사람의 움직임에 비해 과도하게 부드러워진 결과물이 나올 수밖에 없습니다. 이러한 문제를 해결하기 위해 GAN, VAE, Diffusion과 같은 생성 모델을 사용합니다.2
생성 모델은 데이터를 기반으로 학습하여 새로운 데이터를 생성하는 기술입니다. GAN(Generative Adversarial Networks), VAE(Variational Autoencoders), Diffusion 모델은 데이터의 분포를 학습하여 고품질의 데이터를 생성합니다. 생성 모델은 평균에 수렴하는 것보다는 데이터와 유사한 결과물을 만들어내기 때문에, 더 자연스럽고 다양성이 풍부한 애니메이션을 생성할 수 있습니다. 이를 통해 과도하게 모션이 부드러워진 문제를 해결하고, 보다 자연스러운 애니메이션을 얻을 수 있습니다.
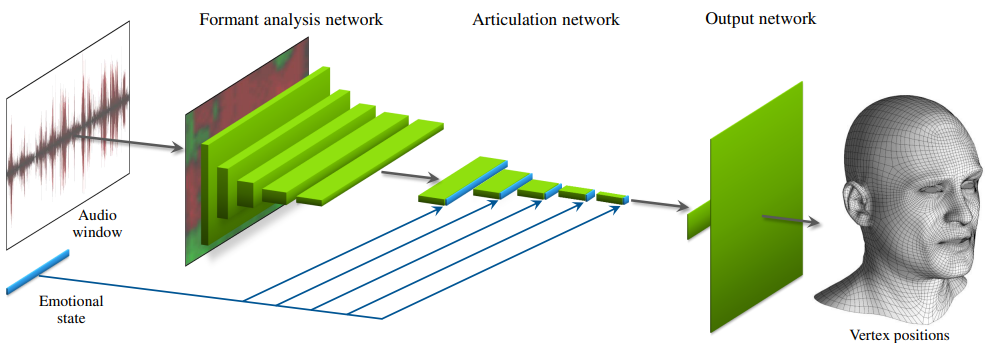 그림 1. 평균 수렴 문제를 해결하기 위해 별도의 상태(Emotional State)를 추가한 모델 3
그림 1. 평균 수렴 문제를 해결하기 위해 별도의 상태(Emotional State)를 추가한 모델 3
위의 그림의 모델은 별도의 상태(Emotional State)를 두어 음성 외의 추가적인 입력이 있는 것처럼 만들어, 평균에 수렴되는 결과물이 아닌 더 뚜렷하고 자연스러운 애니메이션이 나오도록 합니다. 하지만 Emotional State는 예측 단계에서 변화하기 어려우며 고정된 값을 사용하기 때문에 실제 사람의 애니메이션과는 차이가 있을 수밖에 없습니다. 아래의 영상은 위의 모델을 통해 생성된 결과물입니다.
영상 2. Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion 3
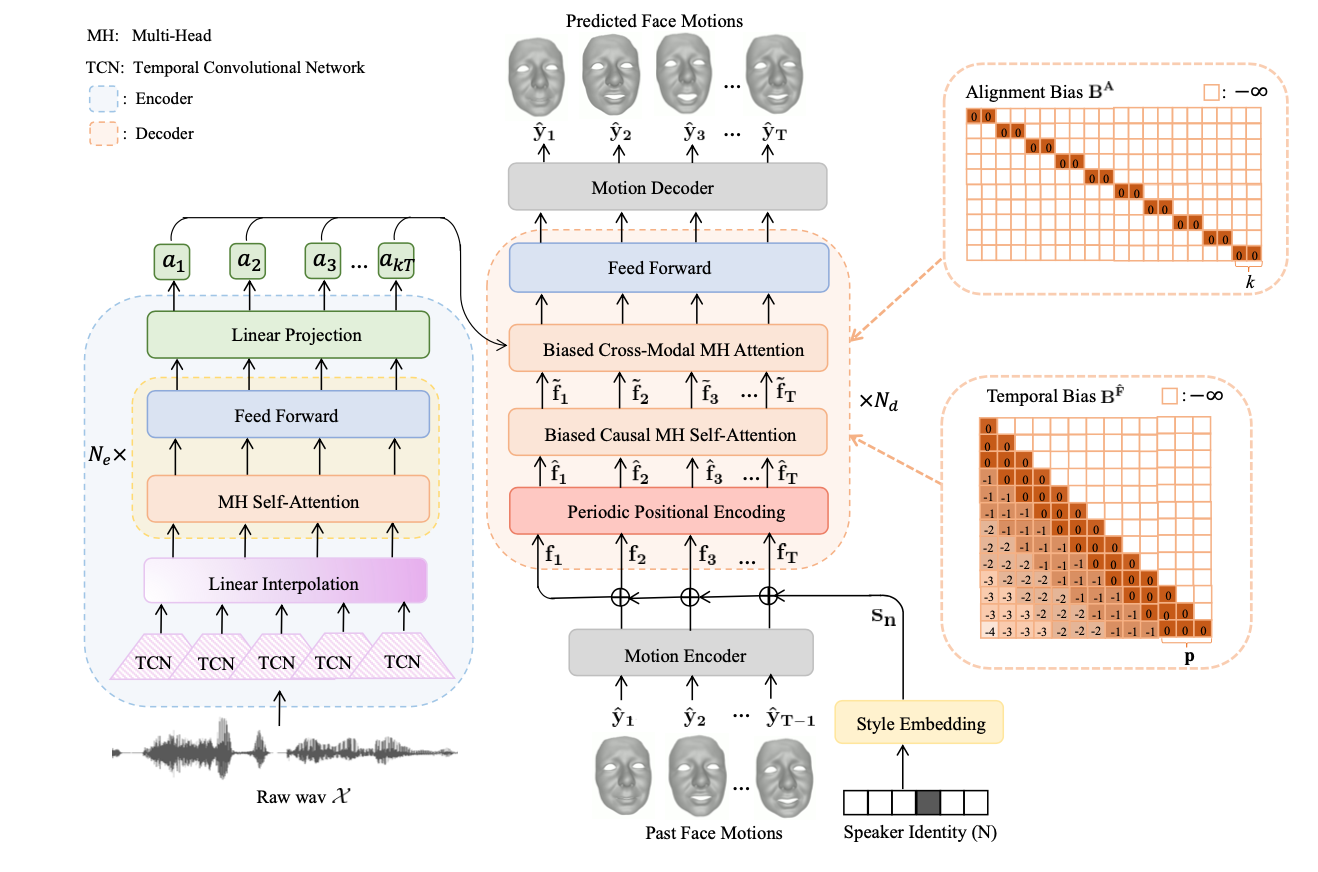 그림 2. FaceFormer: Speech-Driven 3D Facial Animation with Transformers 4
그림 2. FaceFormer: Speech-Driven 3D Facial Animation with Transformers 4
이와는 다르게 평균 수렴 문제를 해결하면서 다른 접근법으로 자연스러운 애니메이션을 만드는 위와 같은 모델이 있습니다. 위의 모델(FaceFormer)은 더 자연스러운 얼굴 애니메이션을 만들기 위해 TCN(Temporal Convolution Network)이나 Transformer 구조를 사용합니다. 이 구조들은 긴 입력 시퀀스를 다루는 데 적합하여, 눈을 10초에 한 번씩 깜박이는 것처럼 장기간의 행동 패턴을 예측하는 데 유리합니다. 이를 통해 입술 외의 얼굴의 미세한 움직임까지도 자연스럽게 표현할 수 있습니다.
기술 사례 - NVIDIA Audio2Face
음성 기반 얼굴 애니메이션 기술 중 가장 관심을 받고 있는 기술은 NVIDIA의 Audio2Face입니다. 해당 기술은 고품질의 Mesh를 학습한 모델을 사용하여 높은 품질의 결과물이 만들 수 있으며, 이와 더불어 사용하기 쉬운 인터페이스와 후보정, Character Transfer 기능을 제공을 합니다.
-
실시간 처리: 음성을 입력 받아 즉시 얼굴 애니메이션을 생성할 수 있어 제작 시간을 크게 단축할 수 있습니다.
-
고품질 애니메이션: 고품질의 메쉬를 출력할 수 있는 학습 모델을 사용하여 고해상도 메쉬와 자연스러운 표정 변화를 구현하여, 현실감 있는 캐릭터 표현이 가능합니다.
-
유연성: 다양한 음성 입력에 적응할 수 있어, 여러 언어와 발화 스타일에 맞추어 애니메이션을 생성할 수 있습니다. 한 사람의 얼굴 형태(identity)로만 만드는 것이 아니라 사용자가 원하는 얼굴 형태로도 만들 수 있도록 Character Transfer 기능을 제공합니다. 이 밖에도 감정 조절, 애니메이션 스타일 조절 등의 후보정이 가능합니다.
Audio2Face를 사용하면 캡쳐나 수작업 없이 음성만으로도 손쉽게 얼굴 애니메이션을 생성할 수 있습니다.
영상 3. NVIDIA Audio2Face 사용 예시 및 결과물 5
기술 현황 - NC Research
저희 팀에서는 음성 기반 얼굴 애니메이션 생성 기술을 개발하고 있습니다. 이 기술을 사용하면 음성만 준비해도 다양한 화자 및 언어에 맞는 적절한 입술 모션과, 말하는 상황에 따라 목, 눈썹, 눈 등의 모션을 자연스럽게 생성할 수 있습니다. 이 기술이 없다면 인게임 씬의 다양한 상황에 맞는 고품질 얼굴 애니메이션을 대량으로 제작하기 어려울 것입니다.
일반적으로 연구 단계의 기술은 품질이 높더라도 개발팀이 사용하기에는 다소 불편하여 적용이 어려운 경우가 많습니다. 저희 팀은 높은 품질을 유지하면서도 사용 편의성을 확보하여 실제 게임 개발에서 효과적으로 사용할 수 있는 기술을 만드는 것을 목표로 하고 있습니다. 이를 통해 게임 제작의 효율성을 크게 향상시켜, 보다 몰입감 있는 사용자 경험을 제공할 수 있을 것입니다. 앞으로도 지속적인 연구와 개발을 통해 더욱 발전된 기술을 선보일 예정입니다.
영상 4. 자체 얼굴 애니메이션 생성 기술 데모
마치며
이 글에서는 음성 기반 메쉬 타겟 얼굴 애니메이션 생성 기술의 기본적인 접근법과 현황에 대해 소개했습니다. 메쉬 기반 애니메이션 생성 기술은 실시간 처리, 고품질 애니메이션, 유연성 등의 장점을 제공하여 게임 제작에서의 효율성을 크게 향상시킬 수 있습니다. 자동화된 얼굴 애니메이션 생성 기술은 수작업과 캡쳐 과정을 생략할 수 있기 때문에 대규모 게임 프로젝트에서 대량의 대사를 처리하고 다양한 언어에 맞는 얼굴 애니메이션을 만드는 과정에서 매우 유용합니다. 얼굴 애니메이션 생성 기술의 발전은 게임 및 다양한 디지털 콘텐츠 제작의 효율성을 높이고 사용자 경험을 향상시키는데 중요한 역할을 할 것입니다.
저희 팀은 본 기술의 잠재력을 최대한 활용하여 게임 개발에 기여하고 더 나은 게임 경험을 제공하기 위해 노력하고 있습니다. 앞으로도 지속적인 연구와 개발을 통해 더욱 발전된 기술을 선보이도록 하겠습니다. 다음 기회에는 저희 기술을 좀 더 자세히 소개할 수 있기를 바랍니다.
-
JALI: An Animator-Centric Viseme Model for Expressive Lip Synchronization, JALI Research (2016) ↩
-
Improving Diffusion Models as an Alternative To GANs, NVIDIA (2022) ↩
-
Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion, NVIDIA (2018) ↩ ↩2
-
FaceFormer: Speech-Driven 3D Facial Animation with Transformers, Fan (2022) ↩
-
Audio2Face, NVIDIA ↩
