
들어가며
오늘 글에서는 저희가 가진 기술이 실제 서비스에 적용된 사례와 그 과정에 대해서 말씀드리려 합니다. 마침 최근에 엔씨소프트와 항공기상청은 항공기상 분야 인공지능 기술 협력을 위한 업무협약(MOU)1을 맺었기도 하니 이와 관련된 내용이 좋을 거 같네요. 실제 MOU는 지난 7월 말에 진행되었지만, 사실 저희와 항공기상청의 교류는 약 1년 반 정도 전부터 진행되고 있었습니다. 그리고 그 첫 시작으로 공항기상정보 자동생성에 대한 개발이 진행되고 있었습니다. 그럼 좀더 자세히 이에 대해서 알아볼까요?
공항기상정보과 항공기상데이터
공항기상정보
우선, 공항기상정보가 무엇인지부터 설명드려야 할 거 같네요.
공항기상정보는 항공기상청에서 매일 06시, 17시에 국내 7개 공항(인천, 김포, 제주, 무안, 울산, 양양, 여수)에서 발표하는 각 공항별 기상 정보를 말합니다. 주로 항공기 운항과 관련된 여러 기관에서 사용되는 정보이기 때문에 운항과 관련된 정보들이 많이 담겨있습니다. 오늘과 내일의 안개, 비, 눈, 강풍 등 항공기 운항에 직접 영향을 끼치는 기상이라던가 폭염, 한파 등 지상작업자의 건강과 관련있는 정보들을 확인하실 수 있답니다.
 9월 2일 발표된 공항기상정보. 일반인도 항공기상청 홈페이지를 통해 확인할 수 있다.2
9월 2일 발표된 공항기상정보. 일반인도 항공기상청 홈페이지를 통해 확인할 수 있다.2
항공기상데이터
그러면 이 공항기상정보는 어떻게 만들어지게 되는걸까요?
공항기상정보는 각 공항의 예보관분들이 작성하게 되는데, 발표시점까지 관측 또는 예보된 여러 항공기상 데이터를 근거로 만들게 됩니다. 대표적으로 METAR와 TAF라는 항공기상 데이터와 기상청에서 발표하는 날씨해설이 사용됩니다.
각각에 대해 간략히 설명드리면, METAR(Meteorological Aerodrome Report)는 매시간 공항별로 관측된 기상 정보를 알려주는 항공기상 관측 데이터이고, TAF(Teminal Aerodrome Forecasts)는 METAR와 달리 하루에 4차례 발표되는 항공기상 예보입니다. METAR와 TAF는 모두 공항별로 발표되고 정의된 코드 형태로 바람, 시정, 구름, 강수 등의 정보를 포함하고 있다는 공통점이 있지만, METAR는 관측된 시점의 기상정보를 알려주고 TAF는 발표 시점으로부터 30시간 동안의 기상예보를 알려준다는 점에서 차이가 있습니다.
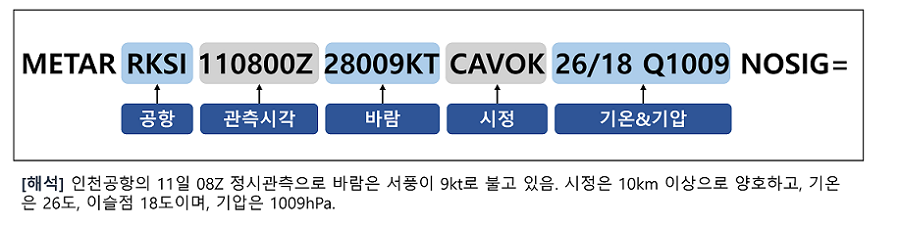 METAR는 매 시간마다 각 공항별로 발표. (인천공항은 30분 간격)
METAR는 매 시간마다 각 공항별로 발표. (인천공항은 30분 간격)
 TAF는 매일 총 4차례(UTC 5시, 11시, 17시, 23시) 5개 공항(인천, 김포, 제주, 무안, 울산)에서 발표.
TAF는 매일 총 4차례(UTC 5시, 11시, 17시, 23시) 5개 공항(인천, 김포, 제주, 무안, 울산)에서 발표.
한편, 날씨해설은 기온, 강수, 기압 등 전반적인 날씨 정보를 포함하고 있는 기상청에서 발표하는 자료입니다. 공항기상정보를 작성할 때는 여러 정보 중에서 주로 기압계 정보가 활용됩니다.
 9월 11일 오후에 발표된 날씨해설3
9월 11일 오후에 발표된 날씨해설3
공항기상정보 자동 생산
저희가 항공기상청으로부터 요청받은 작업은 공항기상정보를 자동 생성하는 것이었고, 그 중에서도 텍스트로 이루어진 일기개황과 위험기상예보 두 부분을 자동으로 생성하는 것이 타겟이었습니다. 공항기상정보는 앞서 설명드린 METAR, TAF, 날씨해설 외에도 여러 데이터를 참고하여 작성되지만, 현실적으로 저희가 예보관이 볼 수 있는 모든 데이터를 수집할 수는 없었습니다. 뿐만아니라 너무 많은 정보가 입력으로 들어가면 결국 중요 내용을 추리는데 문제가 생길 확률이 오르기 때문에 최종적으로 공항기상정보에 나오는 거의 모든 정보를 알 수 있는 METAR, TAF, 날씨해설을 입력으로 받아서 공항기상정보를 출력으로 하는 방향으로 결정되었습니다.
 일기개황(빨강 상자)는 주로 발표 시점 공항의 기상실황(구름, 바람, 시정 등)을 가지고 있고, 오늘과 내일의 기상상황(기압을 포함한 전반적인 날씨 예보)를 알려준다.
일기개황(빨강 상자)는 주로 발표 시점 공항의 기상실황(구름, 바람, 시정 등)을 가지고 있고, 오늘과 내일의 기상상황(기압을 포함한 전반적인 날씨 예보)를 알려준다.
반면, 위험기상예보(초록 상자)에서는 시정, 강수, 바람이나 기타 운항에 영향을 끼칠 수 있는 일기현상들이 예보되면 예상 시각과 기준치를 넘어가는 수치를 알려준다.
왜 기계로 대체하려 하는가?
그런데 사실 공항기상정보는 이미 전문가인 예보관이 매일 정해진 시각에 잘 생산하고 있는 문서입니다. 뿐만 아니라 일기개황은 보통 2~3문장 정도의 텍스트, 위험기상예보는 1~6문장 정도의 텍스트로 크기가 그렇게 큰 문서가 아니기에 사람에게 어려운 문서 작성 업무도 아닙니다. 그럼 이것을 왜 자동화 하려는 걸까요?
가장 큰 이유는 이 작업이 새벽에 진행되기 때문입니다. 사람이 직접 작성하려면 미리 데이터를 확인하고 어떤 내용을 쓸지 준비해야하는데, 매일 오전에 발표되는 시각이 오전 6시이다보니 이보다 더 앞선 이른 새벽부터 준비해야합니다. 아무리 24시간 운영되는 곳의 인원들이 교대근무를 한다지만 새벽시간은 늘 사람에게는 굉장히 힘든 시간입니다. 전날 오전에 잠을 보충하고, 오후나 저녁에 출근하신 분들도 슬슬 피로가 몰려올 시간이죠. 그렇기에 새벽시간에 이뤄지는 정기적인 업무는 최대한 기계로 대체하려는 마음이 어느 곳에나 있는 거 같습니다.
개발 과정에서 겪은 어려움
개발 초기에 저희는 encoder-decoder 구조의 transformer4를 모델을 사용하여 앞서 설명드린 METAR, TAF, 날씨해설을 입력으로 공항기상정보의 일기개황과 위험기상예보를 출력으로 하는 데이터로 학습을 진행하였습니다. 이렇게 해서 한번에 실사용에 문제없는 수준까지 성능이 나왔다면 참 좋았겠지만… 실제로 저희가 확인한 결과는 나쁘진 않으나 현장에 사용하기에는 다소 문제가 있는 수준이었습니다.
여러가지 오류가 있었지만, 가장 대표적인 오류를 하나 뽑자면 역시 입출력의 숫자(시간, 시정, 풍속 등등)가 불일치하는 문제(hallucination)였습니다. 사실 입출력이 가지는 정보가 다른 문제는 많은 생성 태스크에서 흔히 나오는 문제이고, 그중에서도 숫자가 불일치하는 것은 저희 태스크와 같이 자연어가 아닌 데이터로부터 자연어를 생성하는 data-to-text에서는 자주 발생하는 문제이긴 합니다.
입출력 데이터의 정보 불일치
문제가 발생한 이유를 찾아보니 데이터쪽에서 출력이 가진 정보가 입력이 가진 정보에 포함되지 않는 케이스가 적지않게 발견되었습니다. 학습 데이터의 입력에서 확인되지 않는 정보가 출력에 있는 것은 대표적인 모델에 hallucination을 유발하는 원인입니다. 그런데 논리적으로만 보면 실제 데이터에서 입력과 출력이 가지는 정보는 일치해야합니다. 그럼 왜 이런 불일치 현상이 일어난 걸까요? 그건 바로 기상이라는 특수성 때문입니다. 기상 정보는 지금 이순간에도 계속 변하고 있는 변동성이 큰 정보이고, 같은 시각에 관측을 하더라도 어디에서 하냐에 따라 결과가 다르게 됩니다.
예를 들어, 오전 6시 공항기상정보 작성을 하는 과정에서 예보관분들은 오전 2시에 발표된 TAF를 참고하는데요, 문제는 오전 2시에서 오전 6시 사이에 기상 상황이 많든 적든 변한다는 것입니다. 또한 날씨해설의 경우에는 공항에서 관측한 정보가 아니라 전반적인 지역(전국 또는 특정 시,도)의 날씨를 전달하기 때문에 공항 부근에 국한된 날씨랑은 다소 차이가 있는 게 사실입니다. 이렇다보니 저희가 실제로 받은 데이터에서는 입력과 출력이 가진 정보가 불일치하는 사례가 적지 않게 발견되었고, 이 부분을 해결하지 않고는 다음으로 넘어갈 수가 없었습니다. 그래서 일부는 data filtering을 통해 제거하고, 일부는 직접 수작업으로 교정하는 작업을 거쳤습니다.
 TAF에는 5일 21~22시부터 비가 오기 시작한다고 나오지만, 실제 예보에는 여러 실시간 정보까지 반영한 예보관의 판단으로 5일 20시부터 강수 시작으로 나갔다.
TAF에는 5일 21~22시부터 비가 오기 시작한다고 나오지만, 실제 예보에는 여러 실시간 정보까지 반영한 예보관의 판단으로 5일 20시부터 강수 시작으로 나갔다.
Data Augmentation
다음으로 입력과 출력에 나오는 숫자에 대해서 augmentation 진행하였습니다. 저희가 숫자에 augmentation을 적용한 이유는 데이터에 존재하는 정보들 간의 통계적인 상관관계를 제거하여 최대한 모델이 입력에 근거하여 정확한 정보를 생성하게 하기 위함이었습니다. 다만, augmentation을 입출력에 있는 모든 숫자에 적용한 것은 아닙니다. 각 태스크별로 오류가 많이 발생하는 정보를 분석하여 필요한 부분에 대해서만 augment를 적용하였고 굳이 필요치 않은 부분에는 적용하지 않았습니다.
위에서는 개발 과정 중 숫자 관련 오류 해결에 대한 부분만 설명드렸습니다. 그러나 사실 이밖에도 TAF의 유효시간(30시간)으로는 알 수 없는 내용 수정, 몇가지 중요 토큰에 대한 placeholder 사용 등 여러 추가적인 데이터 정제와 heuristic이 적용되었고, 모델 구조 변경, 언어모델 적용 등 모델 개선을 위한 여러 노력이 있었습니다. 그 결과, 저희와 항공기상청이 올해 초부터 시험서비스를 진행하면서 서로 정성적으로 분석을 진행하였는데, 현재는 양측 모두 이 정도면 충분히 현장에서 사용이 가능한 수준이다라는 평가를 내리고 있습니다.
앞으로는?
현재 저희는 이제 시험서비스에서 실제 서비스 운영으로 넘어가기 위한 작업을 진행하고 있는 상태입니다. 하지만 실제 서비스에 적용되더라도 아직 완전히 사람을 대체하는 단계는 아닙니다. 아직까지는 오류가 간간히 나오는게 확인되었거든요. 그래서 실제 서비스를 진행하면서 수집된 데이터로 추가적인 모델 고도화를 진행하여 사람이 확실히 “신뢰할 수 있는 모델”을 만들어나갈 계획이니 앞으로도 많은 관심 부탁드립니다.
References
-
임은진, “엔씨소프트 “항공기상청과 생성 AI 활용한 항공기상 정보 제작”, 연합뉴스, 2023년 7월 26일. ↩
-
Vaswani, Ashish et al. “Attention is All you Need.” NIPS (2017). ↩
