
- 들어가며
- Calibrating Imbalanced Classifiers with Focal Loss: An Empirical Study (Wang et al., 2022)
- Dice Loss for Data-imbalanced NLP Tasks (Li etal., 2019)
- Mixed Cross Entropy Loss for Neural Machine Translation (Li et al., 2021)
- Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning (Gunel et al., 2020)
- 마치며
들어가며
안녕하세요. 다시 만나게 되어 반갑습니다.😄
1부에서는 Computer Vision 분야에서 잘 알려진 두 손실 함수에 대해 알아보는 시간을 가졌었습니다. 이어서 2부에서는 저희의 주 무대인 NLP 분야에서 어떤 손실 함수들이 제안 되었고, 어떤 효과를 보였는지에 대해 알아보도록 하겠습니다.
2부에서는 1부와는 다르게 제한된 공간 안에서 여러 손실 함수들을 소개 드리고 싶었기 때문에, 하나의 주제에 대한 깊이 있는 설명 보다는 어떤 손실 함수들이 제안 되었는지와 이들이 어떤 효과를 보였는지에 대해 중점적으로 다룰 예정입니다.
그럼 시작해 볼까요?
Calibrating Imbalanced Classifiers with Focal Loss: An Empirical Study (Wang et al., 2022)1
서론
만약 우리가 제품 생산 공장에서 하자가 있는 제품을 탐지하는 딥러닝 분류(Classification) 모델을 만들어서 배포했다고 가정해 봅시다. 이 모델의 Recall은 0.8 이며, 우리는 모델이 내놓는 출력 확률(제품에 하자가 있을 확률)에 Threshold를 적용해서 출력 확률이 Threshold 이하인 제품들을 사람이 직접 선별하도록 할 예정입니다. 사람이 직접 검수하는 횟수와 출하 되는 불량 제품의 수를 최소화 하고 싶을 때, 우리는 Threshold를 어떤 값으로 설정해야 할까요?
결론부터 말씀드리자면, Threshold를 결정하기 매우 어려울지도 모릅니다. 우리의 모델은 매우 많은 샘플에 대해 “90%확률로 하자 있음” 혹은 “90%확률로 하자 없음”과 같은 답변을 내놓을 테니까요.

우리는 Calibration이 잘 된 모델이 필요합니다. Calibration은 모델의 출력 확률이 실제 확률을 반영하도록 하는 것을 의미합니다. (Guo et al., 2017)2에서는 현대의 뉴럴넷(Neural Net) 모델들이 과거의 모델들 보다 높은 성능을 보이지만, Calibration이 잘 되어 있지 않다고 말합니다.
 [그림1] Confidence histograms (위), reliability diagrams (아래) (Guo et al., 2017)2
[그림1] Confidence histograms (위), reliability diagrams (아래) (Guo et al., 2017)2
위 그림을 보면 과거 머신 러닝 모델(LeNet, 1998 (왼쪽))에 비해 현대의 딥러닝 모델(ResNet (오른쪽))은 출력 확률 값이 매우 높게 나오는 것에 비해 Accuracy는 상대적으로 낮은 값을 보이는 것을 알 수 있습니다. 이러한 현상을 우리는 Over-confident 하다고 하며, 이는 “모델이 출력하는 확률이 진짜 확률이 아니다”라고 해석할 수 있습니다.
이 논문(Wang et al., 2023)1에서는 NLP 분류 모델에 Focal Loss를 적용 하였더니 Calibration이 잘 되었다고 합니다. 사실 Computer Vision 분야에서 Focal Loss가 Calibration에 효과적이라는 것은 이미 알려진 사실입니다. 이를 뒷받침하기 위한 실험에서 저자는 Amazon 자사의 고객 환불 사유 데이터를 샘플링하여 활용 하였고, 이를 5개의 클래스(Class) 혹은 2개의 클래스로 라벨링(Labeling) 하였다고 합니다. 실험에 사용된 데이터를 라벨링 한 결과는 아래 그림과 같습니다.
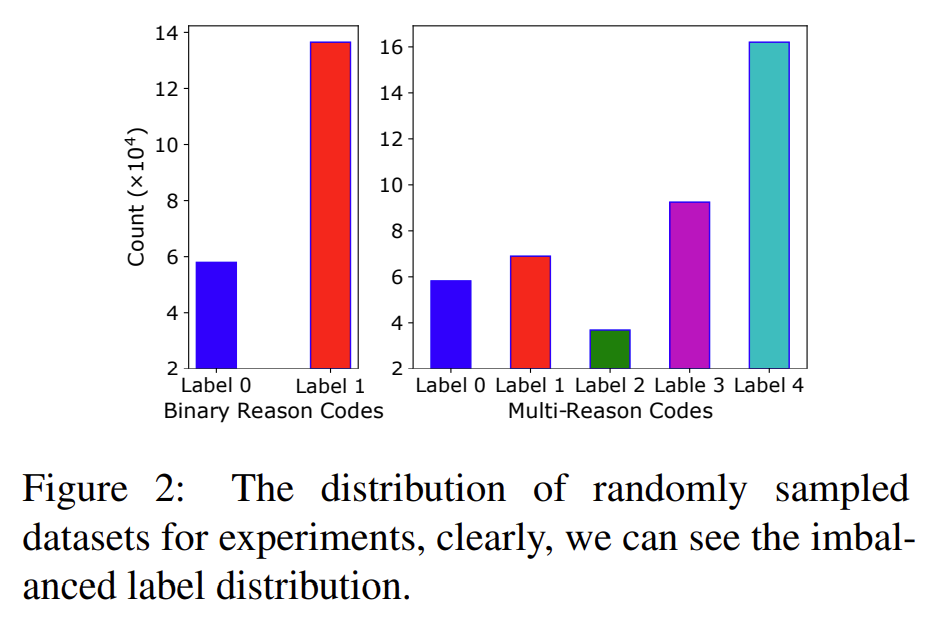 [그림2] Amazon 사의 고객 확불 사유 데이터에서 샘플링한 데이터의 라벨 분포
[그림2] Amazon 사의 고객 확불 사유 데이터에서 샘플링한 데이터의 라벨 분포
그림2에서 왼쪽의 Binary Reason Codes는 앞서 언급한 로그(Log) 데이터를 “제품 결함” 혹은 “기타”로 라벨링 한 것이고, 오른쪽의 Multi-Reason Codes는 데이터를 “제품 결함”, “부품 누락”, “성능 상의 이슈”, “단순 변심”, “기타” 중의 하나로 라벨링 한 것입니다. 여기서 각 라벨(Label)의 분포가 고르지 않다는 것을 알 수 있는데, 실제 로그 데이터에서 위 그림과 같이 데이터 불균형 현상이 나타나는 것은 일반적이고 이러한 분포를 가진 데이터로 모델을 학습할 경우 모델이 샘플이 많은 클래스에 과도하게 맞춰져 Miscalibration이 발생할 수 있습니다.
실험 및 결과
그렇다면 Focal Loss를 사용한 분류 모델이 위와 같은 데이터를 학습 하였을 때, Calibration이 잘 되었을지 확인해 볼까요?
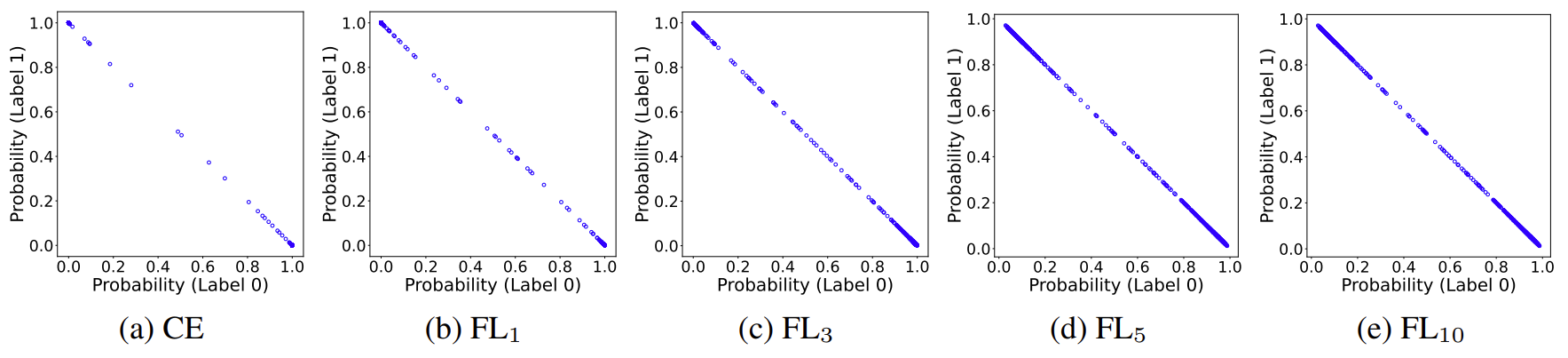 [그림3] Binary reason code 데이터에 대한 reliability diagram
[그림3] Binary reason code 데이터에 대한 reliability diagram
그림3을 보면 CE(Cross Entropy Loss)는 대부분의 예측 확률이 0 또는 1에 가까이 분포해 있는 반면, Focal Loss를 적용한 결과에서는 예측 확률 값들이 좀 더 고르게 퍼져있는 모습을 볼 수 있습니다. (b)-(e)는 Focal Loss의 \(\gamma\)를 다르게 해서 실험한 결과이며, 여기서 \(\gamma\)가 커질수록 Calibration이 잘 되는 것처럼 보입니다.
그렇다면 이제 모델의 성능이 어떻게 측정 되었는지 확인해 봐야겠죠? Calibration이 잘 되더라도 성능 하락 폭이 크면 리스크(Risk)가 매우 크다는 것이니까요…😿
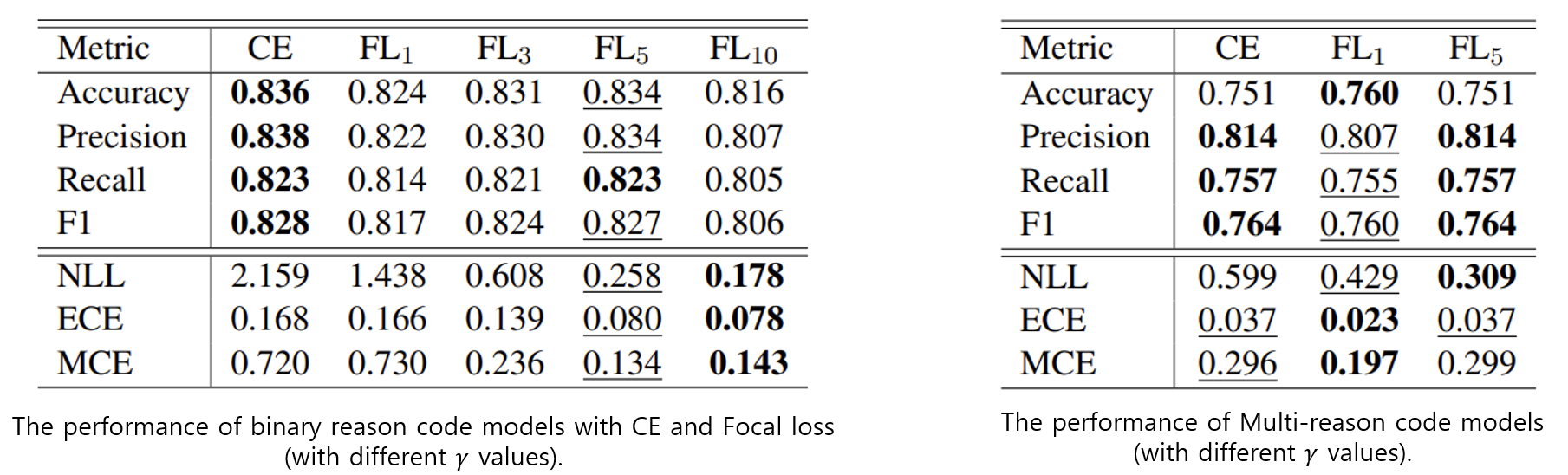 [그림4] CE와 Focal Loss의 \(\gamma\)를 다르게 적용하여 실험한 결과
실험에 사용된 모델은 2-layer BiLSTM 이다
[그림4] CE와 Focal Loss의 \(\gamma\)를 다르게 적용하여 실험한 결과
실험에 사용된 모델은 2-layer BiLSTM 이다
그림4에서 아래 ECE, MCE 는 Calibration을 측정할 때 사용되는 평가 지표(Evaluation metric)입니다. (두 평가 지표의 자세한 수식이 궁금하시다면 (Wang et al., 2023)1을 참고하시기 바랍니다.) 위 실험 결과를 통해 우리는 Focal Loss를 사용 했을 때, CE를 사용한 모델 보다 성능은 약간 하락하지만 Calibration은 잘 되었다는 것을 알 수 있습니다. 아쉽게도 실험을 위한 데이터 셋은 공개되지 않았습니다 여러분도 분류 모델의 Calibration을 위해 Focal Loss를 적용해 보는 것은 어떨까요?
물론 Calibration을 위한 방법이 Focal Loss만 있는 것은 아닙니다. Label smoothing, Temperature scaling 등 여러 방법이 있지만, 이 방법들에 비해 Focal Loss가 가지는 장점은 Computational overhead를 증가시키지 않고, 모델 아키텍처의 변경도 필요 없다는 것입니다.
요약하자면, 이 논문에서는 실제 서비스의 로그 데이터에서 발생하는 불균형한 데이터 분포로 인한 모델의 Miscalibration을 실증적으로 보여주었고, Focal Loss를 이용해 이 문제를 완화할 수 있음을 보였습니다. 이 글에서 언급하지는 않았지만, 훈련된 Reason code model을 실제 챗봇 어플리케이션에 사용 했을 때, 고객이 챗봇이 제공한 해결 방법에 긍정적으로 응답한 횟수가 줄었다는 결과도 개인적으로 상당히 흥미로웠습니다. 반면, 실험에 사용된 모델이 BERT와 같은 PLM(Pre-trained Language Model)이 아니라 2-layer BiLSTM이라는 점은 아쉬운 부분이라고 생각됩니다. 요새 분류 Task를 위해 PLM을 이용하지 않은 NLP 논문은 찾아보기 힘드니까요.
다음으로는 분류 Task가 아닌 다른 Task를 위해 제안된 손실 함수를 소개 드리고자 합니다. 다음 논문에서 함께 살펴 보시죠.
Dice Loss for Data-imbalanced NLP Tasks (Li etal., 2019)3
서론
(Wang et al., 2023)1에서 사용한 고객 환불 사유 데이터와 같이 데이터의 불균형은 NLP 분야에서 매우 흔하게 일어나는 이슈라고 볼 수 있습니다. 여러분들이 한 번 쯤은 접해 보셨을 NER(Named Entity Recognition)이나 MRC(Machine Reading Comprehension) 데이터 셋도 심각한 데이터 불균형 문제를 앓고 있습니다. 아래 그림5에서는 NER, MRC, PI(Paraphrase identification) 데이터 셋 상에서의 데이터 불균형을 나타내고 있습니다.
 [그림5] NER, MRC, PI 데이터 셋 상에서의 데이터 불균형
[그림5] NER, MRC, PI 데이터 셋 상에서의 데이터 불균형
NER 데이터 셋으로 사용되는 CoNLL03, OntoNote5.0의 경우 대부분의 Mention이 어떠한 Entity도 아닌 O에 해당(CoNLL03에서는 5배, OntoNotes5.0에서는 8배)하므로 대부분의 Mention이 Negative에 해당한다고 볼 수 있고, MRC는 Start index와 End index를 제외한 모든 토큰(Token)이 Negative에 해당한다고 볼 수 있습니다. 결국 Positive보다 Negative가 압도적으로 많아서 데이터 불균형 문제가 발생할 수 있다는 것이지요. 이 Task들은 이러한 데이터 불균형 때문에 성능 측정을 위한 평가 지표로 F1-score를 사용합니다. 그리고 일반적으로 모델 훈련을 위한 손실 함수는 CE를 사용합니다.
그러나, 이 논문(Li et al., 2019)3에서는 CE는 Accuracy-oriented Loss이기 때문에 F1-score로 성능을 측정하는 데이터 셋으로 모델 학습을 진행하면 학습(Training)과 평가(Test)사이에 모순(Discrepancy)이 발생한다고 주장합니다. 그 이유는 학습 과정 동안 각각의 학습 인스턴스(Training instance)는 목적 함수(Object function)에 똑같은 비중으로 기여하지만, 평가 시에 사용하는 평가 지표인 F1-score는 Postive example을 Negative example보다 더 높은 비중으로 고려하기 때문입니다. 즉, 모델 학습은 Easy-negative exmaple을 많이 사용하여 진행하지만, 정작 평가 시의 성능 측정은 Positive example에 영향을 많이 받는 F1-score를 사용한다는 것입니다.
DSC(Sørensen–Dice coefficient) Loss
이 논문에서는 DSC(Sørensen–Dice coefficient)를 이용해 이러한 이슈를 해결하고자 했습니다. 사실 DSC는 NLP 분야에서 흔히 사용되는 평가 지표는 아닙니다. DSC는 흔히 Dice score라고도 하는데, 이는 Cumputer Vision 분야에서 Ground truth와 Prediction 두 영역이 얼마나 겹치는 지를 나타내는 지표로써 활용됩니다.
 [그림6] Ground Truth와 Prediction 영역 예시
[그림6] Ground Truth와 Prediction 영역 예시
그림6에서 왼쪽의 빨간색 영역은 Ground truth 영역이기 때문에 True-positive + False-negative라 볼 수 있고, 파란색 영역은 Prediction 결과가 Positive인 Prediction 영역이기 때문에 True-positive + False positive라고 볼 수 있습니다.
자, 그럼 이 개념을 가지고 아래의 Dice Score 수식을 한 번 볼까요?
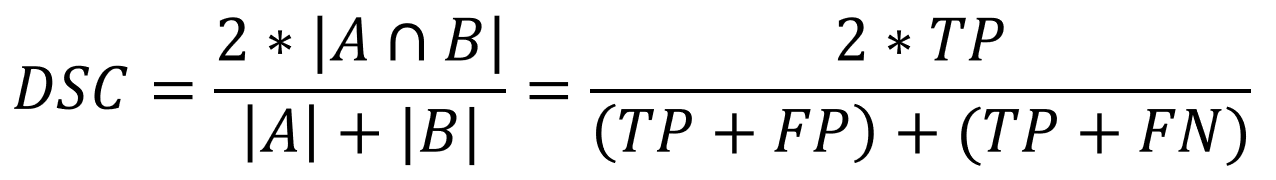
어디선가 많이 본듯한 수식이지 않나요?

네, 그렇습니다. 아래 수식을 보면, 위 수식이 F1-score의 수식과 같다는 것을 알 수 있습니다.

결국, 이 논문에서 DSC Loss를 사용하자고 주장하는 것은 F1-score를 평가 지표로 사용하는 NLP Task에서는 F1-score를 기반으로 한 손실 함수를 사용해 학습하겠다는 것입니다. 이 논문에서는 이 DSC Loss를 변형해서 사용하였는데, 이를 어떻게 변형 시켰는지 같이 보시죠.
하나의 예시 \(x_i \in X\) 에 대해 DSC Loss의 수식을 작성해 보면 아래와 같습니다.

여기서 \(y_i=[y_{i0}, y_{01}]\)는 \(x_i\)의 Ground truth를 나타내며, \(p_i=[p_{i0}, p_{01}]\) 는 예측 확률을 의미합니다. \(y_{i0}\)과 \(y_{i1}\)는 0 또는 1 값이고, \(p_{i0}\)와 \(p_{i1}\)는 0과 1 사이의 값(\(p_{i1}+p_{i0}=1\))입니다. 그리고, 위 수식에서 \(\gamma\)는 \(x_i\)가 Negative example일 때(즉, \(y_{i1}=0\))에도 위 수식이 모델 학습에 영향을 미치게 하기 위해 추가한 것입니다.
논문에서는 F1-score에 기반한 이 수식으로도 Easy negative example이 많아 이에 대한 Loss가 크게 누적되어서 전체 학습을 지배할 수 있다는 문제는 해결되지 않는다고 합니다. 그래서 이 논문에서는 최종적으로 DSC Loss를 아래와 같이 변경했습니다.
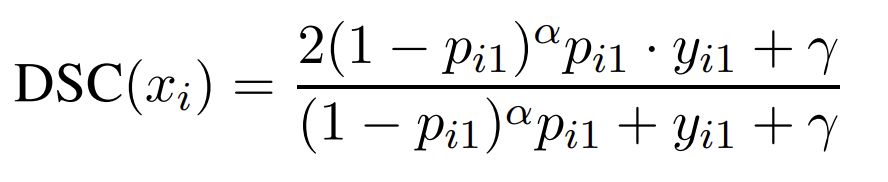
위 수식은 이전 수식에서 \((1-p)\)항을 추가한 모습이며, 이를 통해 확률이 0 또는 1에 가까운 Easy example에 대한 모델의 Focus를 줄였다고 합니다. 이 부분은 Focal Loss에서 영감을 받았다고 합니다. Focal Loss의 수식에 대한 자세한 설명은 1부에서 소개 드렸던 적이 있으니, 궁금하시다면 1부를 다시 보시고 오는 것도 좋습니다
실험 및 결과
논문에서는 여러 NLP task에 대한 실험 결과를 제시 했습니다만, 우리는 이들 중 NER과 MRC task에 대한 결과 만을 보도록 하겠습니다.
아래 그림7는 NER task에 대한 실험 결과입니다. 모든 실험은 CE(Cross Entropy Loss)를 이용한 이전 SOTA(State-of-the-art)모델들을 기반으로 진행 되었고, 여기서 FL, DL, DSC는 각각 Focal Loss, Dice Loss(기본 DSC Loss), 변형된 DSC Loss 를 나타냅니다.
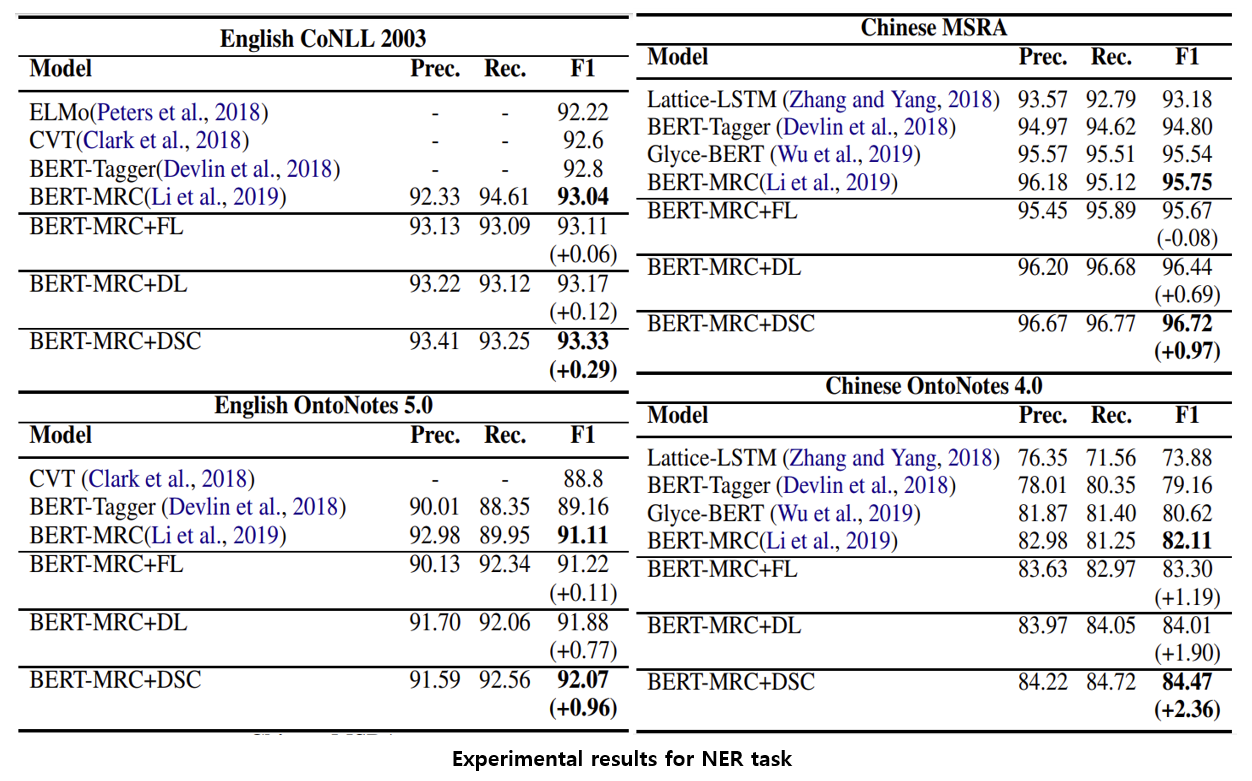 [그림7] NER task에 대한 실험 결과
[그림7] NER task에 대한 실험 결과
실험 결과를 보면 대부분의 경우 CE → FL → DL → DSC 순으로 성능이 좋아지는 경향을 보입니다. 1부에서 소개 드렸던 Focal Loss 또한 MSRA 데이터 셋을 제외하면, 다른 모든 데이터 셋 상에서 성능 향상을 보이고 있습니다. 그렇다면, MRC task에서는 어떤 결과가 나타날까요?
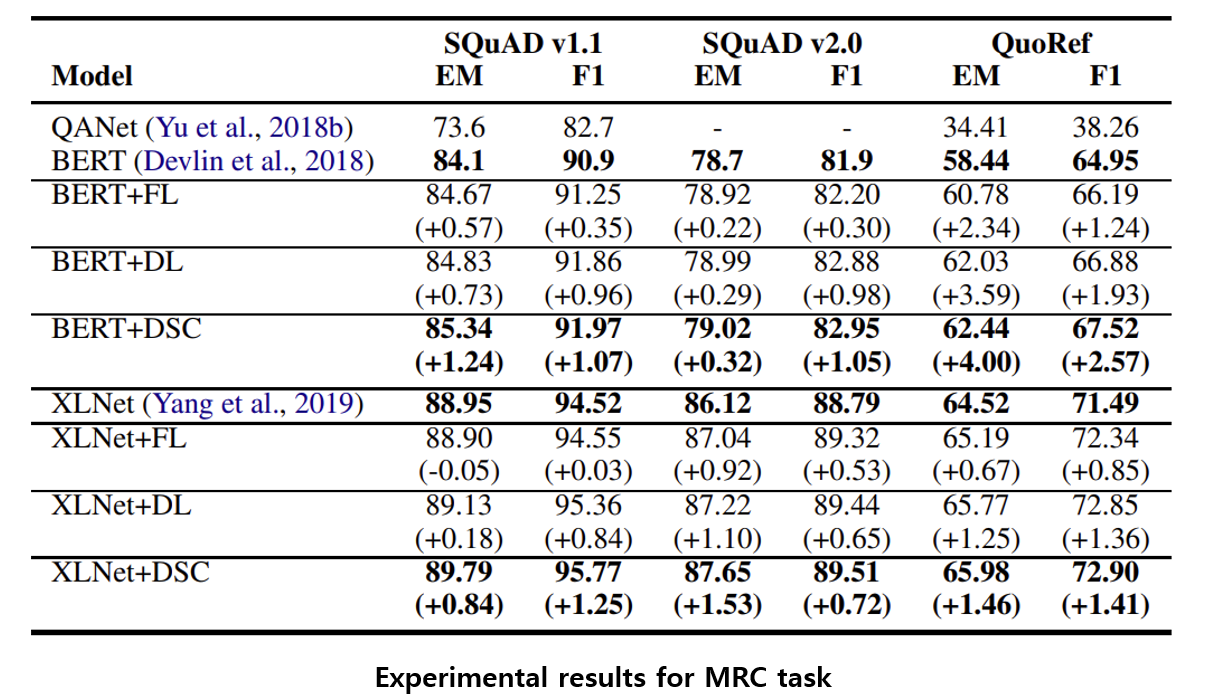 [그림8] MRC task에 대한 실험 결과
[그림8] MRC task에 대한 실험 결과
MRC 데이터 셋 상에서도 NER task의 결과와 비슷한 양상을 보이는군요. CE → FL → DL → DSC 순으로 성능이 좋아지는 경향을 보입니다.
그런데, 앞서 F1-score를 평가 지표로 사용하는 NLP task에는 F1-score기반으로 한 손실 함수를 학습에 사용하겠다는 내용 기억하시나요? NER과 MRC 모두 F1-score를 평가 지표로 사용하는 NLP task였습니다. 그렇다면, Accucary를 평가 지표로 사용하는 Task에서 DSC Loss는 어떤 효과를 보일까요?
이 논문에서는 아래 그림9를 제시함으로써 이에 대한 궁금증을 일부 해소해 주고 있습니다.
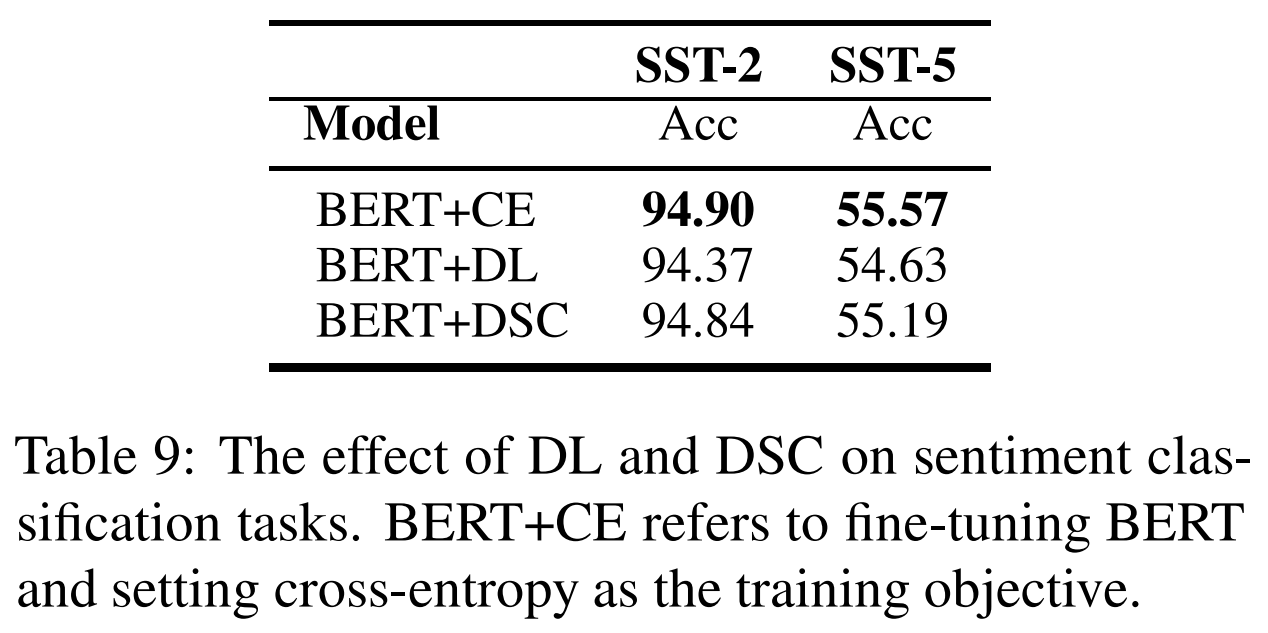 [그림9] 텍스트 분류 task에 대한 실험 결과
[그림9] 텍스트 분류 task에 대한 실험 결과
SST-2와 STS-5는 대표적인 텍스트 분류(Text classification) task입니다. 위 결과를 보면 Accuracy-oriented task인 SST-2, SST-5에서는 오히려 DL 및 DSC의 성능이 하락하는 것을 볼 수 있습니다.
요약하자면, 이 논문에서는 F1-score 를 평가 지표로 사용하는 NLP task에서 모델 학습에 CE를 이용하기 때문에 Training objective와 평가 지표 사이에 갭(Gap)이 발생할 수 있다고 주장하였습니다. 그리고, 이 갭을 완화하기 위해 F1-score기반으로 한 손실 함수인 Dice-base loss를 제안 했습니다. Accuracy-oriented task에서 성능이 하락한 것은 아쉬운 결과이지만, F1-score를 평가 지표로 사용하는 여러 Task에서 좋은 성능을 보였기 때문에 이제 우리는 F1-score를 평가 지표로 사용하는 NLP task를 수행할 때 DSC Loss 사용을 고려해 볼 수 있을 것 같습니다.
자, 이제 다음 논문으로 넘어갈 시간입니다. 이번에는 CE를 개선 시켜 기계 번역 task에 적용한 논문을 소개 드리려고 합니다.
Mixed Cross Entropy Loss for Neural Machine Translation (Li et al., 2021)4
서론
아래 그림10에서 우리가 Target의 마지막 단어, “decline”을 예측하고자 한다고 가정해 보겠습니다.
 [그림10] 번역 task에서의 유의어에 대한 예시
[그림10] 번역 task에서의 유의어에 대한 예시
단어 decline이 모델이 가장 많은 확률 질량(Probability mass)을 할당해야 하는 골드 타겟이지만, 이 맥락에서는 아래의 drop 혹은 decrease와 같은 유의어들도 충분히 그럴듯한 번역이 될 수 있습니다. 즉, 해당 위치에서 이러한 유의어들의 확률 값은 작아야 할 필요가 없습니다. 이 유의어들을 무시하고 단순히 원 핫 인코딩(One-hot encoding)을 맞추면, 모델의 예측 확률 분포가 실제 Ground truth 확률 분포로부터 벗어나기 때문에 모델의 일반화 능력이 저하될 수 있습니다.
Approach
이 논문(Li et al., 2021)4에서는 위와 같은 이유로 모델이 잘 훈련되어 있는 상태에서 모델이 예측한 토큰과 정답 토큰이 서로 다른 경우, 이는 동의어 혹은 유의어일 가능성이 높다고 가정합니다. 논문에서 제안한 수식을 함께 보시죠.

위 수식에서 위쪽은 Cross Entropy Loss 이고, 아래는 이 논문에서 제안한 Mixed Cross Entropy Loss 입니다. Mixed CE 수식에서 \(\hat y = \underset{1<=k<=\|V\|}{\operatorname{arg max}} \log p_{\theta}(w_k\|y_{<k},x)\)이므로, 모델이 가장 높은 확률로 예측한 \(\hat y_t\)는 정답 토큰이거나 동의어 혹은 유의어일 수 있습니다. 그렇기 때문에 앞서 언급한 가정 하에, 모델 학습이 잘 되었다면(Iteration 수가 높다면) 모델이 가장 높은 확률로 예측한 토큰\(\hat y_t\)가 동의어 혹은 유의어일 수 있다고 보고 Loss 값을 낮추겠다는 의미입니다. 이 논문에서는 \(m=0.5\)로 고정했기 때문에 \(0<=\alpha_{i}<=0.5\)임을 알 수 있습니다. \(\alpha_{i}\)는 모델이 학습됨에 따라 최대 0.5까지 증가하므로, 동의어 혹은 유의어에 대한 정보를 최대 절반까지 활용하겠다는 것을 알 수 있습니다.
Mixed CE에 대한 설명은 이 정도로 마무리하고, 이제 실험 결과를 함께 보시죠.
실험 및 결과
 [그림11] WMT’16 Romanian-English (Ro-EN), WMT’16 Russian-English (Ru-En) and WMT’14 English-German (En-DE) 에 대한 실험 결과
[그림11] WMT’16 Romanian-English (Ro-EN), WMT’16 Russian-English (Ru-En) and WMT’14 English-German (En-DE) 에 대한 실험 결과
논문에서는 총 세가지 데이터 셋 상에서 Mixed CE가 다른 여러 손실 함수들(DSD(Dual Skew Divergence Loss)5, SELF-DIST(Sequence Level Self-Distillation Method)67) 중 가장 높은 성능을 보였다고 합니다.(그림11의 왼쪽)
이 논문에서는 추가적으로 기존 평가 셋(Test set)을 가지고 동일한 원문 문장을 다양하게 번역 혹은 의역한 데이터 셋(Additional references)에 대한 평가를 진행 했다고 합니다(그림11의 오른쪽). 이 데이터 셋은 동일한 원문 문장에 대해 10개의 Human reference translation을 만든 결과들과, 전문가에게 평가 셋의 원본 문장을 의역하도록 한 결과들로 구성되어 있다고 합니다. 이들은 단어 선택이나 문장 구조가 원본과 다르지만 의미는 동일한 예시들을 포함하고 어휘 선택의 다양성을 보장해 주므로, 논문에서는 이 데이터 셋 상에서 Mixed CE의 평가 결과가 CE보다 더 우수하다면 Mixed CE의 우수성에 대해 좀 더 확신을 가질 필요가 있다라고 언급합니다.
자, 여기까지 CE의 변형인 Mixed CE의 요점 만을 간략히 알아 봤습니다. 개인적으로는 굉장히 흥미롭게 읽었던 논문이었습니다. 저도 예전에 NMT(Neural Machine Tanslation) task를 진행 하면서 “동의어나 유의어는 고려하지 않아도 모델이 잘 동작하는 건가?”와 같은 생각을 여러 번 한 적이 있었는데, 이 논문에서는 손실 함수를 변형 시켜서 이 문제에 대한 좋은 해결책을 제안한 것 같습니다.
그러나, 아쉬운 점은 “단순히 Iteration 수가 증가한다고 모델이 잘 훈련되어 있다고 가정할 수 있을까?”라는 의문이 들 수 있다는 것입니다. 이 때문인지는 명확하지 않지만, 논문에서는 Mixed CE를 적용해서 모델을 훈련시키기 전에 CE를 이용해서 모델을 5 에폭(Epoch) 만큼 사전 훈련을 진행 했다고 합니다. 이 경우 모델이 어느 정도 훈련된 상태로 Mixed CE를 이용한 훈련을 시작할 수 있지만, 반대로 이는 Mixed CE만으로 모델을 훈련 시키기에는 무리가 있다는 것을 말하는 것이기도 합니다. 결국, Mixed CE가 CE를 완전히 대체할 수는 없다는 것인데, 이는 Iteration 부분을 좀 더 정교하게 설계하면 가능하지 않을까 하는 생각이 듭니다.
이 글에 기재된 내용 외에도 모델의 예측 토큰 중 Top-2 개를 고려한 방법 등 다른 흥미로운 내용들이 논문에 기재되어 있으니, 자세한 내용이 궁금하시다면 본 논문4을 참고하시기 바랍니다.
마지막 논문은 CE와 Constrastive Loss를 결합한 손실 함수를 제안해서 GLUE benchmark에 대한 실험을 진행한 논문입니다.
Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning (Gunel et al., 2020)8
서론
CE는 1부에서 언급했던 한계점 말고도 다른 여러 한계점을 지니고 있습니다. 그 중 하나는 CE가 Poor margin을 생성한다는 점이 있습니다. 이는 CE의 수식에 Margin을 최대화 하는 속성이 없기 때문인데, 이러한 이유로 CE만을 이용해 모델을 학습하게 되면 일반화 성능이 떨어지고 노이즈가 포함된 데이터에 대해 강건(Robustness)하지 못한 추론을 하게 된다고 합니다9. 아래 그림12에서 이에 대한 극단적인 상황을 묘사하고 있습니다.
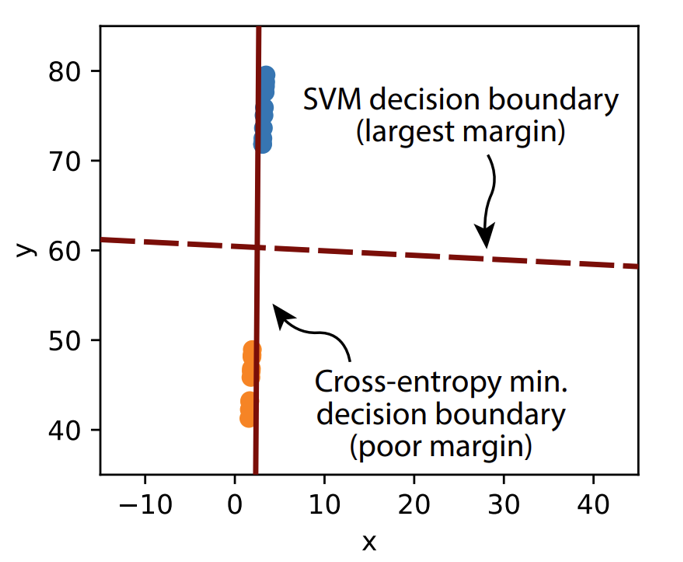 [그림12] CE를 이용한 선형 분류기(linear classifier)와 SVM의 결정 경계(Decision boundary) 비교
[그림12] CE를 이용한 선형 분류기(linear classifier)와 SVM의 결정 경계(Decision boundary) 비교
주황색과 파란색 점은 \(\mathbb{R}^2\)에서 서로 다른 두 클래스의 데이터를 나타낸다.10
그림12를 보면, SVM(Support Vector Machine)이 생성한 Decision boundary에 비해 CE가 생성한 Decision boundary는 큰 Margin을 가지지 못하고 매우 아슬아슬한 경계를 가지고 있습니다.
(Elsayed et al., 2018)9에서는 아래와 같은 그림을 제시하면서 CE의 Poor magin을 설명하고 있습니다.
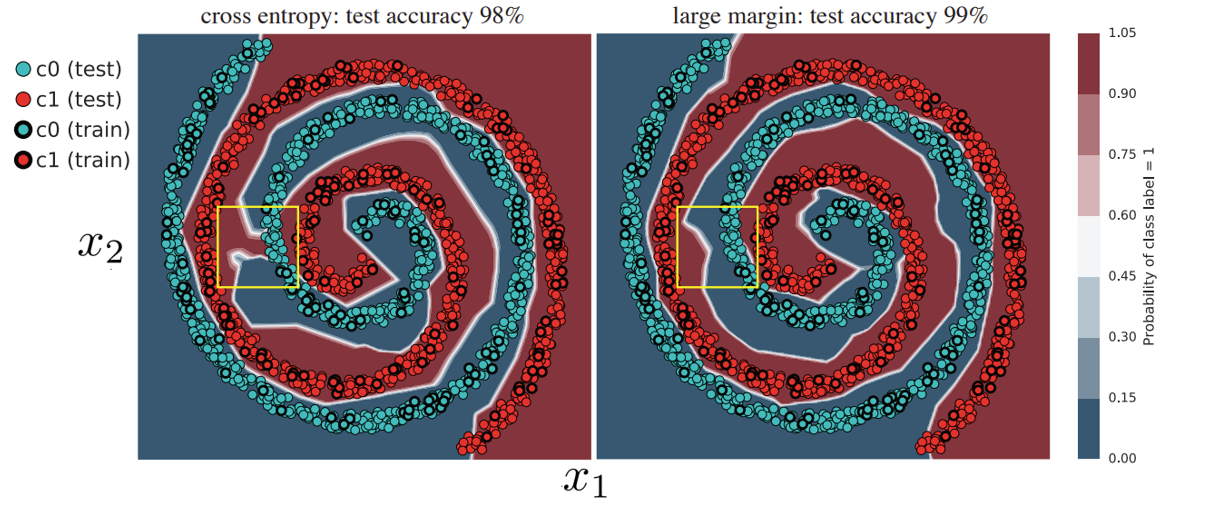 [그림13] Toy setup에서 각각 CE와 (Elsayed et al., 2018)9에서 제안된 Large margin loss를 이용해 학습한 결과
[그림13] Toy setup에서 각각 CE와 (Elsayed et al., 2018)9에서 제안된 Large margin loss를 이용해 학습한 결과
그림13을 보면 Large margin loss로 학습한 오른쪽 그림에 비해 CE로 학습한 모델의 왼쪽 그림의 노란 박스는 Positive와 Negative의 경계가 무너져 있습니다.
최근에는 자연어처리 분야에서도 CE만을 사용해서 Fine-tuning을 진행하게 되면 모델이 불안정한 모습을 보인다는 관측이 많이 보고되었고, 이러한 현상은 특히 학습 데이터가 적은 상황에서 더 도드라지게 나타난다고 합니다. 마지막으로 소개드릴 이 논문(Gunel et al., 2020)8에서는 CE Loss와 Contrastive learning loss를 결합하여 이를 해결하고자 했습니다.
Approach
이 논문에서는 아래와 같이 단순히 CE Loss와 Contrastive Learning Loss를 합쳐 놓은 수식을 제안 했습니다.
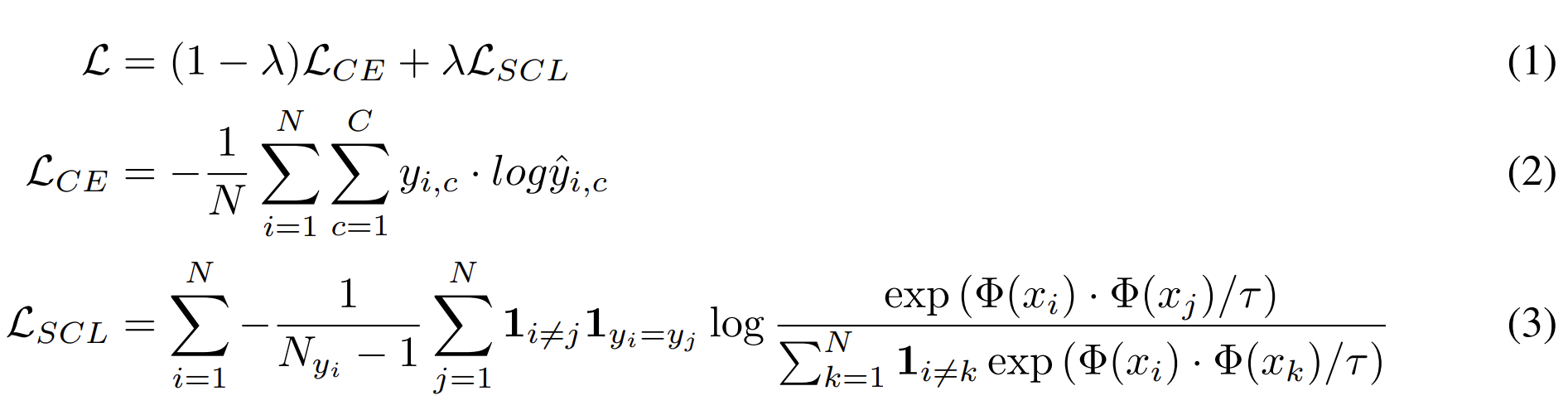
위 수식을 보면, 결국 CE Loss를 \(1-\lambda\)만큼 사용하고, Contrastive Learning Loss를 \(\lambda\)만큼 사용한다는 의미인 것을 알 수 있습니다. 식 (2)의 CE Loss는 기존과 동일하고, 식 (3)을 보면, 크기가 \(N\)인 Mini-batch 내에서 Contrastive Learning을 적용하는 수식이라는 것을 알 수 있습니다. 따라서, 식 (3)은 Mini-batch 내에서 클래스가 서로 같은 Instance는 가깝게, 클래스가 서로 다른 Instance는 멀게 만드는 작업을 수행합니다. 여기서 \(\tau\)는 클래스 간의 분할을 엄격하게 만드는 Temperature parameter로 이 값이 작을수록 모델 학습이 힘들어지지만, 더 강건한 분류기가 나올 수 있다고 합니다.
이 논문에서는 아래 그림14처럼 CE와 SCL을 같이 사용한 경우, 클래스 간의 경계가 더 뚜렷해 졌다고 합니다.
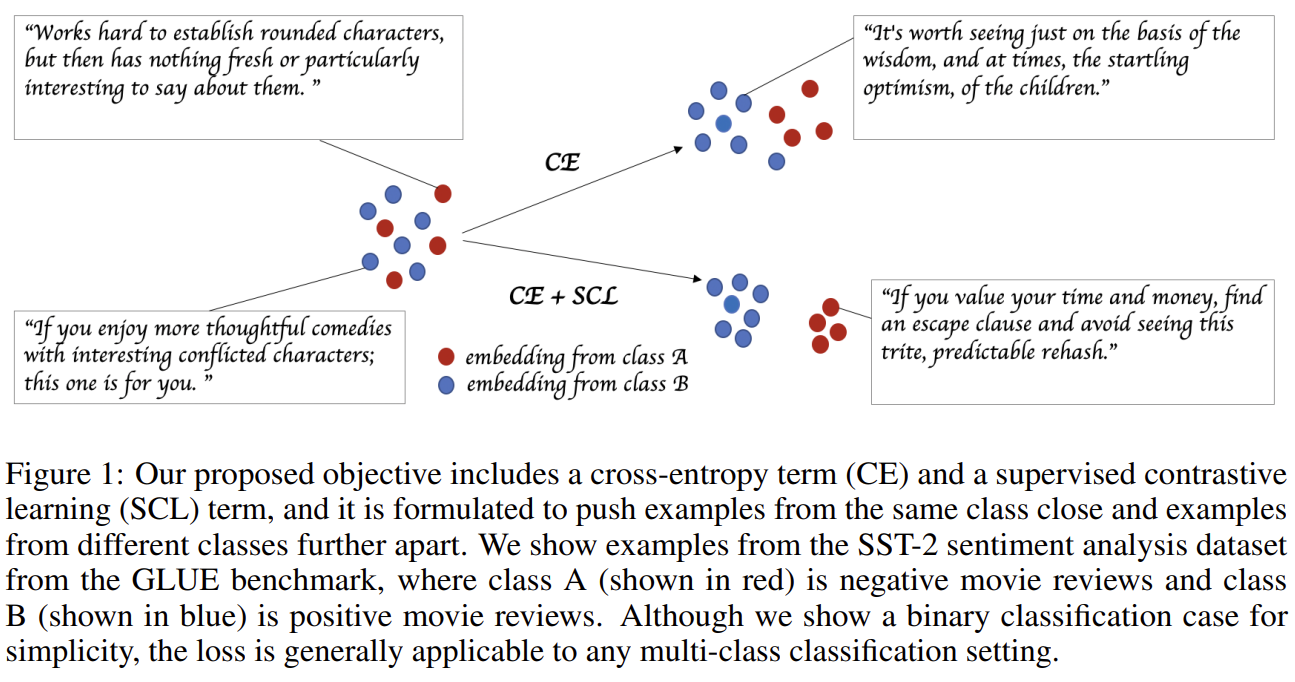 [그림14] SST-2 감성 분석(sentiment analysis) 데이터 셋에서 CE와 CE+SCL을 각각 사용 하였을 때의 분류 결과 예시
[그림14] SST-2 감성 분석(sentiment analysis) 데이터 셋에서 CE와 CE+SCL을 각각 사용 하였을 때의 분류 결과 예시
실험 및 결과
실험에 사용된 데이터 셋은 자연어 이해 벤치마크로 잘 알려진 GLUE 벤치마크 데이터 셋입니다.(그림 15)
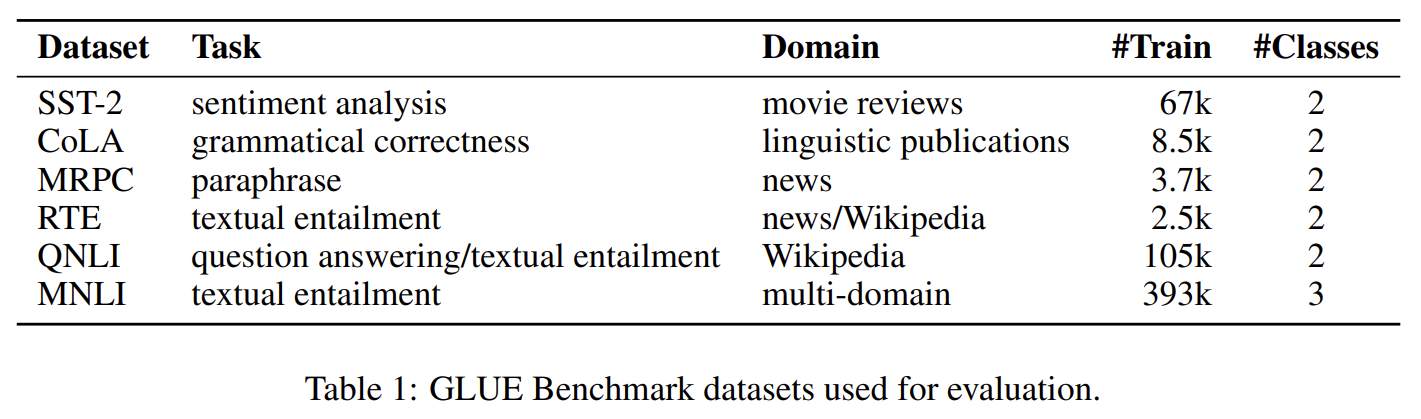 [그림15] 실험에 사용된 GLUE 벤치마크 데이서 셋
[그림15] 실험에 사용된 GLUE 벤치마크 데이서 셋
이 중 CoLA는 주어진 문장을 보고 문법적 오류가 있는지 없는지 판단하는 데이터 셋이고, MRPC는 두 문장이 주어지면 이들이 Paraphrase 관계인이 아닌지 판단하는 데이터 셋입니다.
실험은 RoBERTa-large 모델을 사용해 CE와 CE + SCL의 결과 비교를 진행했습니다.(그림 16)
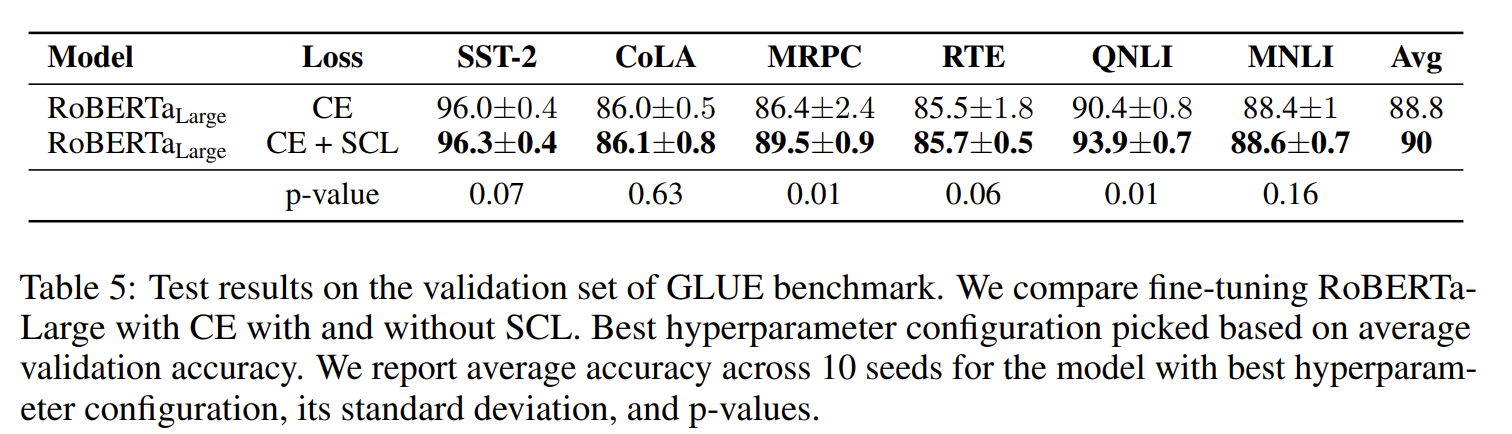 [그림16] CE와 CE+SCL에 대한 실험 결과
[그림16] CE와 CE+SCL에 대한 실험 결과
여기서 p-value는 10개의 다른 시드(Seed)에 대한 ACC의 평균과 편차에 따른 p-value이다.(p-value가 작을수록 재현성이 높다고 볼 수 있다.)
그림16을 보면 모든 셋 상에서 일반적인 세팅(General setting)으로 Fine-tuning을 진행한 결과, CE + SCL 을 적용한 모델이 더 좋은 성능을 보였다고 볼 수 있을 것 같습니다. 그러나, 성능 향상의 폭이 크지는 않아 보입니다. 특히, CoLA 데이터 셋은 CE+SCL을 사용한 경우와 단순 CE를 사용한 경우 중 어떤 방법이 좋은 성능을 보이는지 판별하기 힘들어 보입니다. 그렇다면, 어떤 세팅에서 CE + SCL이 좋은 효과를 보이는 걸까요?
CE + SCL은 학습 데이터가 적거나 노이즈가 포함되어 있는 상황에서 좋은 성능을 보입니다.(그림 17)
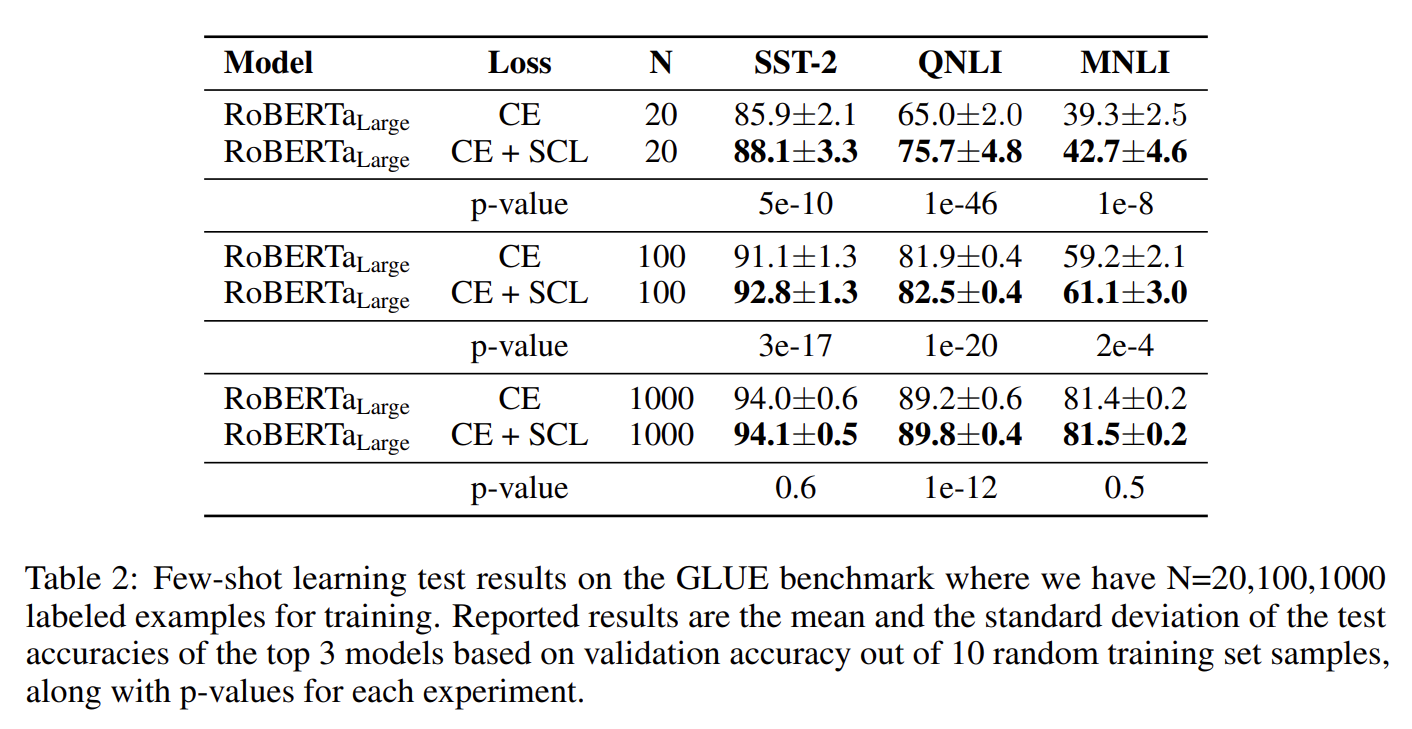 [그림17] 학습 데이터 수 변화에 따른 실험 결과
[그림17] 학습 데이터 수 변화에 따른 실험 결과
그림17의 실험 결과는 학습 Instance를 각각 20개, 100개, 1,000개 만을 이용해 모델 학습을 진행한 결과입니다. 실험 결과를 보면, 학습 데이터가 적을수록 SCL을 결합했을 때 성능 향상이 뚜렷하게 나타나 보입니다. 전의 실험 결과와 비교해 봤을 때, 이는 상당히 유의미한 차이라고 볼 수 있습니다.
수치 상으로 표현되는 결과 말고, CE+SCL의 결과를 시각적으로 표현한다면 어떨까요?
 [그림18] SST-2 평가 셋에서 20개의 학습 인스턴스 만을 이용해 few-shot learning을 한 결과를 tSNE(t-Stochastic Neighbor Embedding) 기법으로 시각화한 결과 비교
[그림18] SST-2 평가 셋에서 20개의 학습 인스턴스 만을 이용해 few-shot learning을 한 결과를 tSNE(t-Stochastic Neighbor Embedding) 기법으로 시각화한 결과 비교
그림18은 SST-2 데이터 셋에서 20개의 학습 인스턴스 만을 이용해 학습했을 때의 CLS 임베딩 표현(Representation)을 tSNE로 시각화 한 것입니다. CE + SCL을 이용해 학습한 모델이 동일한 레이블을 가진 인스턴스들을 더 조밀하게 클러스터링하고 있는 것처럼 보입니다.
이 논문에서는 노이즈를 임의로 추가한 데이터에 대한 실험 결과도 제시 했는데요. 노이즈 환경에 대한 실험을 위해 Back translation을 이용해 노이즈 데이터를 증강시킨 학습 데이터를 사용 했다고 합니다.(그림 19)
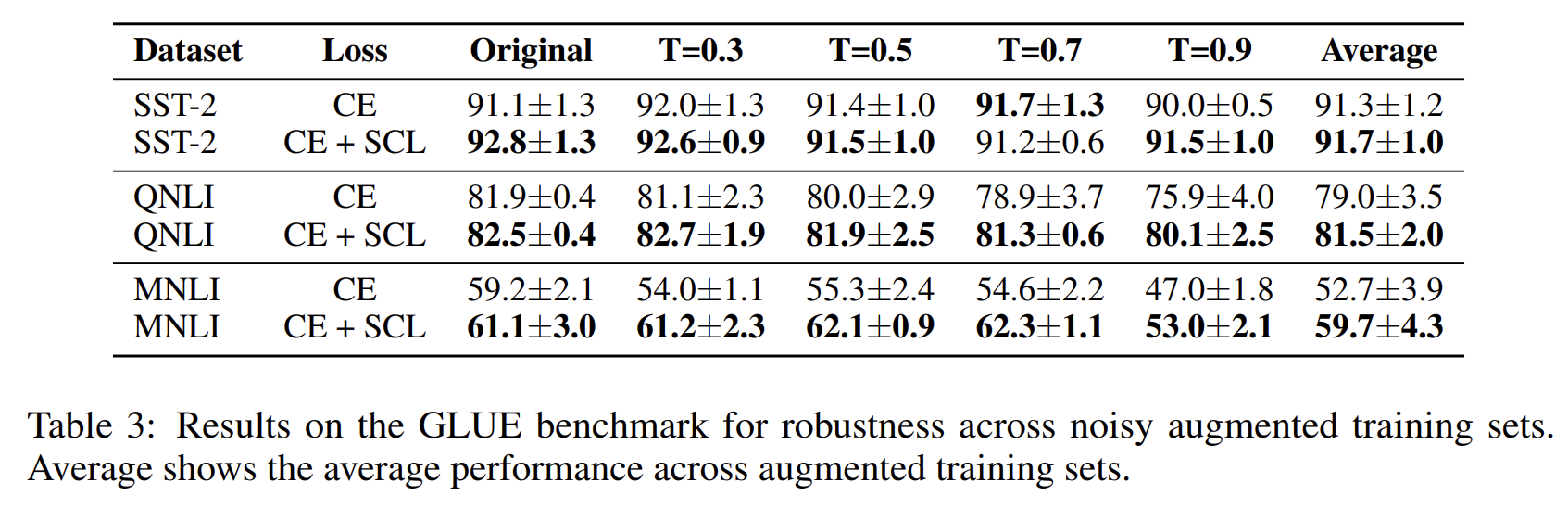 [그림19] 노이즈를 추가한 데이터에 대한 실험 결과
[그림19] 노이즈를 추가한 데이터에 대한 실험 결과
여기서 Temperature T가 커질수록 원 문장에서 벗어난 문장이 생성될 확률이 커진다.
실험 결과를 보시면 Back translation을 이용해 노이즈 데이터를 증강시킨 학습 데이터를 이용했을 때에도 CE +SCL가 CE보다 더 좋은 성능을 보였습니다.
이 논문에서 아쉬운 점을 찾자면, CE+SCL의 하이퍼파라미터 \(\lambda\)와 \(\tau\)에 따른 성능 변화를 제시하지 않았다는 것이라 볼 수 있겠지만, 결과적으로 이 논문은 여러 실험 결과들을 통해 CE +SCL 방법이 기존의 CE 방법보다 더 강건(Robustness)하고 일반화가 잘 되었다는 것을 입증했다고 생각됩니다. 여러분도 한 mini-batch 내에 동일한 클래스에 속하는 인스턴스들이 포함되어 있는 학습 데이터를 이용한다면, 이 논문에서 제안한 CE + SCL 방법을 사용해 보는 것도 좋은 방법이 될 것 같습니다.
마치며
여기까지 NLP 태크스에서 문제를 해결하기 위해 어떤 손실 함수들이 제안 되었는지, 그리고 이들이 어떤 효과를 보였는지에 대해 알아봤습니다. 이 외에도 여러 다양한 손실 함수들이 자연어처리 분야에서 제안 되었지만, 여러 논문을 읽다 보면 아직도 Cross Entropy를 메인 손실 함수로 사용하는 경우가 많은 것 같습니다. 이 글을 통해 여러분이 다양한 손실 함수들을 접하고, 주어진 상황에 맞는 손실 함수들을 사용해서 더 좋은 모델을 훈련시킬 수 있게 된다면 좋을 것 같습니다.
긴 글 읽어주셔서 감사합니다.
여러분 안녕~
References
https://towardsdatascience.com/metrics-to-evaluate-your-semantic-segmentation-model-6bcb99639aa2
https://learnopencv.com/intersection-over-union-iou-in-object-detection-and-segmentation/
https://huffon.github.io/2020/11/21/contrastive/
-
Calibrating Imbalanced Classifiers with Focal Loss: An Empirical Study (Wang et al., EMNLP-industry 2022) ↩ ↩2 ↩3 ↩4
-
On Calibration of Modern Neural Networks (Guo et al., ICML 2017) ↩ ↩2
-
Dice Loss for Data-imbalanced NLP Tasks (Li et al., ACL 2020) ↩ ↩2
-
Mixed Cross Entropy Loss for Neural Machine Translation (Li et al., ICML 2021) ↩ ↩2 ↩3
-
Dual skew divergence loss for neural machine translation (Li et al., 2019) ↩
-
Sequence-level knowledge distillation (Kim et al., EMNLP 2016) ↩
-
Born again neural networks (Furlanello et al., ICML 2018) ↩
-
Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning (Gunel et al., ICLR 2021) ↩ ↩2
-
Large Margin Deep Networks for Classification (Elsayed et al., NeurlIPS 2018) ↩ ↩2 ↩3
-
Cross-Entropy Loss Leads To Poor Margins (Nar et al., 2018) ↩
