
- 들어가며: 생성형 AI와 언어 데이터
- 한국어 언어 데이터의 흐름: 21세기 세종 계획부터 모두의 말뭉치, AI Hub에 이르기까지
- 생성형 AI를 위한 프롬프트 데이터 들여다보기
- Reference
들어가며: 생성형 AI와 언어 데이터
2022년 ChatGPT가 출시되면서 생성형 AI 기술을 연구하는 많은 사람들과 단체들의 연구 시계는 매우 빠르게 돌아가고 있습니다. 많은 사람들이 ChatGPT를 경험해 보면서 자연어처리 기술을 직, 간접적으로 경험할 수 있게 되었고 자연어처리를 비롯한 언어 모델과 관련된 분야에 대한 관심도 빠르게 커지고 있습니다. 기술 발전의 결과로 다양한 응용 프로그램과 서비스, 그리고 새로운 기술들이 하루가 멀다하고 등장하고 있습니다. 이러한 기술 발전의 흐름에서 언어 데이터의 중요성은 한층 더 강화되고 있습니다. 언어 데이터는 모델의 학습과 성능 향상을 위한 핵심 자원입니다. 대규모의 다양하고 품질이 높은 언어 데이터가 없으면, 모델은 언어를 정확하게 이해하고 사람과 효과적으로 소통하기 어렵습니다. 언어 데이터는 문장 구조, 어휘, 문맥, 의미, 감정 등을 파악하는 언어 이해 기술에 필수적인 요소이기 때문이죠.
 Figure 1. ChatGPT는 자신의 존재에 대해 어떻게 생각하고 있는지 물어보았습니다.
Figure 1. ChatGPT는 자신의 존재에 대해 어떻게 생각하고 있는지 물어보았습니다.
언어 데이터는 특정 도메인이나 태스크에 따라서 다양하게 조정될 수 있습니다. 생성형 AI 기술에 대한 연구가 활발한 지금, 의료, 법률, 금융, 여가 등의 광범위한 분야의 자연어처리 응용 프로그램을 개발하기 위한 특화 데이터가 만들어지고 있습니다. ChatGPT와 같은 초거대 언어 모델 기반의 서비스가 가능하게 된 것은 하루 아침의 일이 아닙니다. 초거대 언어 모델(Large Language Model, LLM)의 등장 이전에 오랜 시간 동안 연구되어 온, 인간의 언어로 인간과 기계의 의사소통을 실현하기 위한 수많은 연구자들의 시행착오와 연구 성과, 그리고 다양한 기술의 발전이 있었기 때문에 가능하게 되었습니다. 특히 사전학습 모델(Pre-Trained Model)과 전이 학습(Transfer Learning) 등은 자연어처리 태스크의 흐름을 크게 바꿔 놓는데 큰 역할을 했습니다.
 Figure 2. 앞으로 자연어처리 태스크는 어떻게 변해 갈까요?
Figure 2. 앞으로 자연어처리 태스크는 어떻게 변해 갈까요?
이 포스트에서는 자연어처리 기술과 언어 모델을 이야기 할 때에 빼 놓을 수 없는 언어 데이터에 대해서 말하고자 합니다. 흔히 말뭉치 혹은 코퍼스로 알려진 언어 데이터는 자연어처리 연구룰 위해 만들어진 데이터입니다. 국립국어원의 표준국어대사전과 Oxford Learner’s Dictionary에서는 말뭉치와 코퍼스를 아래와 같이 정의하고 있습니다.
말-뭉치 「명사」 『언어』 언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료. 매체, 시간, 공간, 주석 단계 등의 기준에 따라 다양한 종류가 있다.≒코퍼스. 1
Corpus noun a collection of written or spoken text. 2
표준국어대사전에서 정의하듯 말뭉치는 언어 연구를 위한 목적의 컴퓨터가 읽을 수 있는(machine-readable) 형태의 자료로, 다양한 매체와 도메인, 시간, 공간, 주석 체계 등의 기준에 따라서 구별될 수 있습니다. 이러한 다양한 정보들은 인간과 기계의 소통을 통한 다양한 응용 프로그램을 만드는 데에 활용할 수 있습니다. 지금은 인간과 기계의 의사소통을 가능하게 해주는 학습 데이터의 총체로 그 범위를 넓혀가고 있습니다. 그렇다면 언어 모델은 어떤 데이터를 학습하고 있을까요? 초거대 언어 모델의 수업시대 1부 - 언어 모델은 무엇으로 배우는가 - 이 포스트에서는 한국어 공공 언어 데이터의 역사와 새로운 트렌드인 생성형 AI를 위한 프롬프트 데이터에 대해서 이야기 해보고자 합니다.
한국어 언어 데이터의 흐름: 21세기 세종 계획부터 모두의 말뭉치, AI Hub에 이르기까지
세계에서 한국어를 사용하는 사람들은 얼마나 될까요? Ethonologue: Language of the World의 2023년 판3에 따르면, 한국어를 모국어로 사용하는 인구는 전세계에서 15번 째, 제 2언어를 포함한 사용 인구는 24번 째입니다. 한국어의 세계적인 위상은 단순히 통계적으로 판단할 수 없는 면이 존재합니다. 한국의 문화를 접하고 있는 많은 세계인들이 자연스럽게 한국어를 접하고 있으니까요. 그렇다면 한국어 언어 데이터, 말뭉치의 규모도 이와 비슷한 위상이라고 할 수 있을까요? 한국어 언어 데이터는 자연어처리 기술과 더불어 어떻게 발전해 왔을까요?
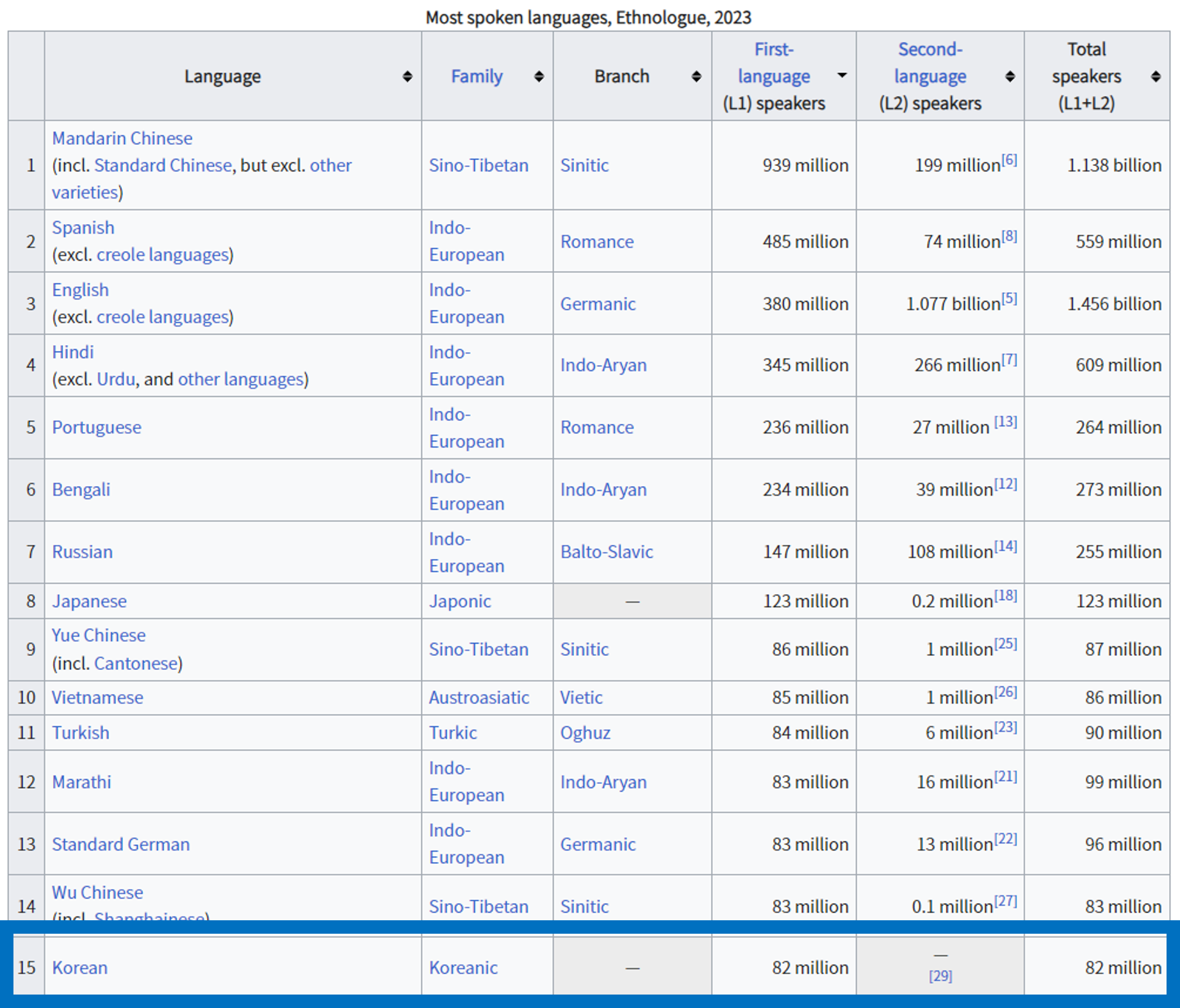 Figure 3. 전세계 모국어 화자(L1) 순위
Figure 3. 전세계 모국어 화자(L1) 순위
한국어는 모국어 기준으로는 15번 째에 위치하고 있습니다.
21세기 세종 계획 (1998 - 2007)
한국어 자연어처리를 연구하는 분들이라면 누구나 세종 계획 혹은 세종 코퍼스 라는 데이터(혹은 이름)를 들어보았을 거라고 생각합니다. 우리의 한글을 이야기 할 때에 세종대왕을 빼 놓을 수 없듯이, 한국어의 전산화, 정보화를 이야기 할 때에도 역시 세종대왕은 존재감을 발휘합니다.
 Figure 4. 한국어의 국가 주도 언어 자원 구축 프로젝트는 1998년부터 시작되었습니다.
Figure 4. 한국어의 국가 주도 언어 자원 구축 프로젝트는 1998년부터 시작되었습니다.
밀레니엄을 목전에 둔 1997년, 문화관광부와 국립국어원은 국어학계와 전산학계의 교수님들이 모인 전담 기획단을 구성하는 것으로 21세기 세종 계획을 포문을 열었습니다. 이듬해 1998년부터 2007년까지 10년에 걸친 국가 차원의 국어 정보화 중장기 프로젝트인 21세기 세종 계획이 시작된 것입니다4.
 Figure 5. 21세기 세종 계획의 구문 분석 말뭉치의 시작
Figure 5. 21세기 세종 계획의 구문 분석 말뭉치의 시작
여러분들은 엠마누엘 웅가로와 내적 친밀감을 가지고 계신가요?
21세기 세종 계획은 ‘국어정보학’이라는 새로운 분야를 개척이라는 목표 아래, 국어 기초자료 구축5(원시 말뭉치, 형태분석 말뭉치, 형태의미분석 말뭉치, 구문분석 말뭉치 등), 국어 특수자료 구축6(현대 구어 전사 말뭉치, 한영 병렬 말뭉치, 한일 병렬 말뭉치, 북한 및 해외 한국어 말뭉치 개발, 역사 자료 말뭉치 개발 등), 전자 사전 개발, 전문 용어 정비, 문자 코드 표준화, 글꼴 개발 등의 여러 성과를 거두었습니다. 뿐만 아니라 어문 규범, 어휘 역사, 방언, 남북한 언어 비교 사전을 구축하여 한글을 사용하는 사람들의 ‘말’에 대한 데이터베이스도 구축하였습니다.7
 Figure 6. 21세기 세종 계획의 성과물 현황
Figure 6. 21세기 세종 계획의 성과물 현황
우리가 흔히 알고 있는 언어 자원들 이외에 정말 다양한 언어 자원과 DB가 구축되었습니다.
10년 간의 21세기 세종 계획의 결과로 우리는 띄어쓰기 기준으로 약 2억 어절 규모의 말뭉치를 보유하게 되었습니다. 당시 미국, 일본, 중국 등의 말뭉치 규모가 2~5억 단어 수준이었다는 것을 생각하면, 21세기 세종 계획의 결과물은 양적으로 세계 최고 수준에 도달할 수 있었습니다8.
모두의 말뭉치 (2019 - )
한국의 많은 연구자들이 21세기 세종 계획에서 만들어진 다양한 말뭉치로 한국어를 활용한 다양한 응용 연구를 진행하는 동안, 많은 나라에서는 지속적인 투자를 통해 말뭉치의 규모를 확장하며 언어 자원의 규모를 점점 키워 나갔습니다. 영어의 경우, 1억 5천만 단어 규모의 British National Corpus(BNC)부터 2,000억 단어 이상의 규모를 가진 American National Corpus(ANC)에 이르기까지 지속적인 투자를 해왔고, 일본, 중국, 유럽에서도 100억 단어 이상의 대규모 언어 자원을 구축하는 등 한국어의 언어 자원과 세계의 언어 자원은 그 격차가 점점 벌어지게 되었습니다. 9
국제적 격차를 줄이고 현재의 언어 규범과 21세기 세종 계획의 다양한 수정, 보완 사항을 반영한 새로운 대규모 한국어 말뭉치를 만들고자 2020년 8월, 국립국어원에서는 13종의 한국어 데이터, 총 18억 어절 분량의 모두의 말뭉치를 대중에게 공개하였습니다.모두의 말뭉치는 ‘4차 산업혁명 대비 국어 빅데이터(말뭉치) 구축’을 목표로 만들어진 국가 주도의 말뭉치입니다. 2018년부터 다양한 인공지능 관련 학계와 산업계에서 필요한 데이터에 대한 기초 조사를 거쳐, 인공지능의 한국어 처리 능력 향상에 반드시 필요한 데이터를 만들고자 많은 연구자들과 기관들이 힘을 합쳐 만들어낸 데이터입니다.
 Figure 7. 모두의 말뭉치에 공개된 주요 데이터 목록
Figure 7. 모두의 말뭉치에 공개된 주요 데이터 목록
2023년 현재, 모두의 말뭉치는 총 49 종의 한국어 및 한국어-외국어 병렬 말뭉치를 소개하고 있습니다10. 모두의 말뭉치 초기에는 언어 이해 기술에 필요한 다양한 원시 말뭉치(신문, 문어, 구어, 비출판물 자료 등)와 자연어처리의 이해 기술을 위한 분석 말뭉치 (형태소, 개체명, 구문, 무형 대용어, 상호 참조 해결, 의미역, 감성 분석 등)이 주를 이루었습니다. 이후에는 특정 도메인, 상황에서 만들어진 다양한 원시 말뭉치(일상 대화, 일상 대화 음성, 국회 회의록, 온라인 대화) 뿐만 아니라 심화적인 내용을 다루는 말뭉치 (추론_확신성 분석, 개체 연결, 문법성 판단, 속성 기반 감성 분석 등)에 이르기까지 그 범위를 확장해 나가고 있습니다. 뿐만 아니라 한국에 이주한 외국인들을 위한 다양한 병렬 말뭉치들도 많이 구축되어 다양한 언어 현상과 필요성을 반영하고 있습니다.
AI Hub (2017 - )
국립국어원 모두의 말뭉치와 더불어 또 하나의 대표적인 공공 데이터는 한국지능정보사회진흥원(NIA)에서 운영하는 AI 통합 플랫폼인 AI Hub에서 제공하는 한국어 데이터셋입니다. AI Hub에서 제공하는 한국어 공공 데이터는 인공지능 학습용 데이터 구축, 확산 사업의 일환으로 AI 기술, 서비스 개발에 필수적인 다양한 유형의 데이터를 제공하고 있습니다. 데이터 구축 사업을 통해 구축된 데이터와 다양한 국내외 기관/기업에서 보유하고 있는 인공지능 학습용 데이터도 함께 공개하고 있습니다11 .
 Figure 8. 2021년까지 공개된 AI Hub의 주요 텍스트 데이터 목록
Figure 8. 2021년까지 공개된 AI Hub의 주요 텍스트 데이터 목록
앞서 소개한 국립국어원의 모두의 말뭉치와 AI Hub 데이터 구성에는 차이가 있습니다. AI Hub 데이터의 특징은 한국어 분석을 위한 원시 데이터와 이해 기술을 위한 데이터도 포함하고 있지만 텍스트와 이미지, 음성 등이 결합된 멀티모달 데이터들이 조합으로 산업계의 다양한 요구를 반영한 데이터들로 구성되어 있다는 특징이 있습니다. 2020년과 2021년을 기점으로, AI Hub 데이터의 종류가 급격하게 늘어났고, 요약, 음성, 질의응답과 기계 독해, 병렬 말뭉치, OCR 등 다양한 종류의 데이터가 공개되었습니다.
 Figure 9. 2022년까지 공개된 AI Hub의 주요 텍스트 데이터 목록
Figure 9. 2022년까지 공개된 AI Hub의 주요 텍스트 데이터 목록
2022년 공개된 AI Hub의 데이터들은 한국어를 활용한 자연어처리 태스크의 고도화를 위한 데이터들이 많이 포함되어 있습니다. 대화를 통한 다양한 기능 구현을 위한 데이터(페르소나, 지식 검색, 공감 등), 다양한 성능을 객관적으로 평가할 수 있는 평가용 데이터(일반 상식 문장 생성 평가, 기계번역 품질 검증 등), 정보의 사실성을 판단하기 위한 데이터(낚시성 기사 탐지, 추상 요약 사실성 검증) 등이 소개가 되었습니다. 이러한 데이터들은 생성형 AI 기술 고도화에 필요한 사실성 판단, 객관적인 품질 평가, 생성의 다양화를 위해 필수적으로 필요한 고도화된 데이터라고 할 수 있습니다.
지금까지 대표적인 세 가지 한국어 공공 언어 데이터를 살펴 보았습니다. 여러분의 한국어 언어 데이터에 대한 생각은 어떠신가요? 아직도 생소하고 접하기 어렵다고 생각하시나요? 아니면 이런 공공 데이터보다는 인터넷 검색을 통해 다양한 데이터 저장소에서 데이터를 얻는 것에 더 익숙하신가요? 만약 여러분이 처음 한국어 언어 분석, 자연어처리를 접하고 공부하고자 한다면, 반드시 이 데이터들을 살펴보고 다양한 한국어 언어 현상을 접해 보는 것이 큰 도움이라 확신합니다.
생성형 AI를 위한 프롬프트 데이터 들여다보기
한국어 언어 데이터들의 추세를 보면 점점 다양하고 심화된 태스크를 위한 데이터 구축의 방향으로 나아가고 있습니다. 생성형 AI 시대가 도래한 만큼, 무엇을 생성할 것이냐에 대한 목표에 따라서 이전에는 없던 다양하고 참신한 데이터들이 많이 생겨날 것입니다. 앞서 게시된 포스트 “거대언어모델의 프롬프트 데이터”에서는 거대 언어모델, 생성형 AI 데이터의 최신 데이터 패러다임인 프롬프트 엔지니어링에 대해서 자세하게 설명해 주셨습니다. 프롬프트 엔지니어링은 언어 모델이 NLP 태스크를 수행할 수 있도록 어떻게 명령, 지시하는지 방법을 찾는 작업이라고 소개하고 있고, 그를 위한 다양한 프롬프트 데이터셋이 소개되고 있습니다.
프롬프트 데이터는 자연어처리 태스크를 처리하기 위한 예시를 포함한 태스크 정의문(Task definition), 명령에 해당하는 입력(Input) 등으로 구성된 다양한 자연어처리 태스크를 위한 수많은 데이터셋을 하나로 합친 벤치마크 데이터셋이 등장하게 되었습니다. 앞선 포스트에서는 Google의 FLAN Dataset, OpenAI의 InstructGPT Dataset, 그리고 Wang et al.(2022)12의 Super-NaturalInstructions(SNI) Dataset 등을 벤치마크 데이터셋으로 소개하였죠. 생성형 AI 기술에 벤치마크 데이터셋은 매우 중요한 역할을 합니다. 벤치마크 데이터셋은 공통의 기준으로 생성형 AI의 정확도와 성능을 평가할 수 있는 기반입니다. 그렇기 때문에 생성과 같이 새로운 것을 만들어내는 태스크의 특성상 공통된 평가 기준으로서 벤치마크 데이터셋은 중요한 역할을 하게 되는 것이죠. 다양한 태스크들로 구성된 벤치마크 데이터셋은 모델 성능 평가에 대한 신뢰도도 높일 수 있게 되고, 모델 간 비교에 객관성도 높일 수 있습니다.
그렇다면 벤치마크 데이터셋은 어떻게 구성되어 있을까요?
앞선 포스트에서 소개한 생성형 AI의 벤치마크 데이터셋인 SNI 데이터셋을 구성하고 있는 1,613개의 태스크들을 다시 살펴 봅시다. SNI 데이터셋을 구성하고 있는 절반 이상의 태스크는 번역, 질의 응답, 프로그램 실행, 질문 생성, 감성 분석, 택스트 분류 등에 집중되어 있는 것을 볼 수 있습니다. 전체 77개의 태스크 종류 중에 6개의 종류에 55% 이상의 태스크가 집중되어 있는 것이죠.
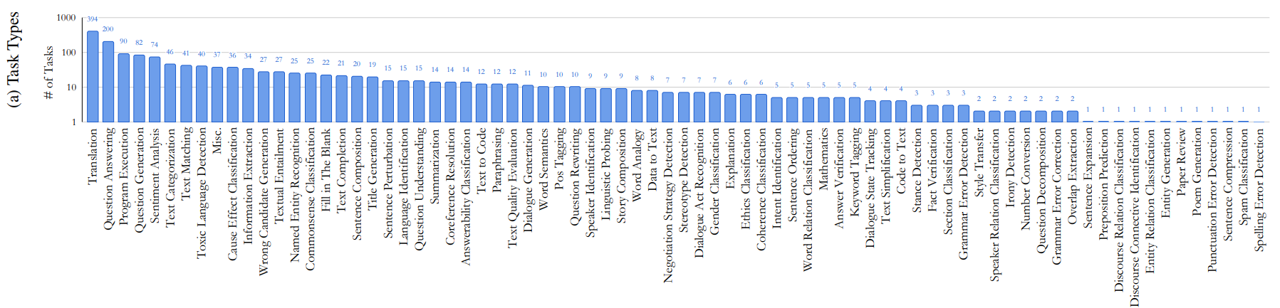 Figure 10. Super-NaturalInstructions 데이터셋의 태스크 유형 분포
Figure 10. Super-NaturalInstructions 데이터셋의 태스크 유형 분포
이러한 데이터 구성은 잘하는 태스크는 더욱 우수한 성능을 낼 수 여지를 줄 수 있습니다. 조금만 비틀어 생각해 보면, 잘하는 ‘것만’ 잘하게끔 모델이 발전할 가능성도 있는 것이죠. 매번 잘 푸는 문제, 쉬운 내용만 공부할 수는 없는 것이니까요. 가장 많은 태스크를 차지하고 있는 번역 태스크의 예시를 살펴봅시다. 비교적 단순한 태스크 정의와 번역하고자 하는 출발 언어(Source language) 문장과 도착 언어(Target language) 문장으로 구성되어 있습니다. 지시문에 해당하는 태스크 정의는 주어진 출발 언어의 문장을 읽고 도착 언어의 문장을 작성하게 하는 명령으로 구성되어 있는 번역 지시문이라고 볼 수 있습니다. 물론 다양한 조건이 포함된 번역 태스크의 지시문도 있지만, 394개의 번역 태스크 중 대다수의 태스크 지시문의 문장을 요약해보면 많은 태스크가 아래와 같은 간단한 지시문으로 구성되어 있습니다.
- A text is given in [SRC_lang]. Translate it from the [SRC_lang] language to the [TGT_lang] language. The translation must not omit or add information to the original sentence.
- Given a sentence in [SRC_lang], provide an equivalent paraphrased translation in [TGT_lang] that retains the same meaning both through the translation and the paraphrase.
- Given a sentence in [SRC_lang] language, translate the sentence to [TGT_lang] language keeping the meaning of the original sentence intact.
- Given a sentence in [SRC_lang], provide an equivalent paraphrased translation in [TGT_lang] that retains the same meaning both through the translation and the paraphrase.
- In this task, given a sentence in the [SRC_lang] language, your task is to convert it into [TGT_lang] language.
- This task is to translate the [SRC_lang] Language Input to [TGT_lang] Language Output
- Translate from [SRC_lang] to [TGT_lang].
이러한 지시문들은 물론 번역 태스크의 목적을 달성하기에는 부족함이 없는 것은 사실입니다. 그러나 벤치마크 데이터셋이 간단한 지시문을 활용한 태스크들에 치우쳐져 있다면 생성형 AI는 생성의 다양성 문제에 봉착할 가능성이 있습니다. “What are the three primary colors?”, “What is the capital of France?” 같은 정답이 제한적인 질문이나 “가을이 포함된 간단한 시를 써줘.”와 같은 단순한 생성 태스크는 잘 수행할 수 있겠죠. 그러나 자연어를 활용한 태스크의 난이도는 천차만별이고, 실제로 사람들은 각자 다양한 방법과 문장으로 태스크를 지시할 것이기 때문에, 얼마나 많은 입력이 하나의 특정한 태스크를 실행하게 하는 것으로 기계가 이해하게 하는 것도 고품질 생성형 AI를 만드는데 중요한 요인이 될 것입니다.
그렇다면 더 복잡하고 다양한 조건을 가진 태스크는 어떤 데이터로서 학습하고 평가해야 할까요? 초거대 언어 모델이 사람의 말과 의도를 더 잘 이해하기 위해서는 어떻게 해야 할까요? 그럼 다음 포스트에서는 생성형 AI가 더 똑똑해지기 위한 다양한 도전들을 소개해 드리도록 하겠습니다. 다음번 포스트에서 만나요!
 Figure 11. ChatGPT는 아직 제 의도를 파악하지 못했습니다. 혹시 여러분은 알아 채셨나요?
Figure 11. ChatGPT는 아직 제 의도를 파악하지 못했습니다. 혹시 여러분은 알아 채셨나요?
Reference
-
21세기 세종계획 백서 (이상규. 2007. 21세기 세종계획 백서. 국립국어원) ↩
-
21세기 세종계획 국어 기초자료 구축 최종연구보고서 (김홍규. 2007. 21세기 세종계획 국어 기초자료 구축 최종연구보고서. 국립국어원) ↩
-
21세기 세종계획 국어 특수자료 구축 최종연구보고서 (서상규. 2007. 21세기 세종계획 국어 특수자료 구축 사업보고서 Ver.9 . 국립국어원) ↩
-
21세기 세종계획 성과물 관리 및 배포 지원 최종보고서 (성원경. 2007. 21세기 세종계획 성과물 관리 및 배포 지원 최종보고서. 국립국어원) ↩
-
말뭉치 구축의 세계 동향과 한국어 말뭉치 (김한샘. 2017. [시선] 말뭉치 구축의 세계 동향과 한국어 말뭉치.연세춘추. http://chunchu.yonsei.ac.kr/news/articleView.html?idxno=23504) ↩
-
2018년 국어 말뭉치 연구 및 구축 (김한샘 외. 2018. 2018년 국어 말뭉치 연구 및 구축. 국립국어원) ↩
-
SUPERNATURALINSTRUCTIONS (Wang, Y., Mishra, S., Alipoormolabashi, P., Kordi, Y., Mirzaei, A., Arunkumar, A., … & Khashabi, D. 2022. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. arXiv preprint arXiv:2204.07705.) ↩
