
- 들어가며: 언어 모델의 추론 능력을 높이기 위한 전략
- 초거대 언어 모델의 추론 능력: 인간 지능(Human Intelligence)로 나아가기 위한 필수 조건
- 초거대 언어모델의 추론 능력 끌어내기
- 언어모델이 풀어야 할 남은 문제들
- 나오며: 그래서 언어모델은 어떻게 추론해야 할까요?
들어가며: 언어 모델의 추론 능력을 높이기 위한 전략
지난 초거대 언어 모델의 수업시대 1부 - 언어 모델은 무엇으로 배우는가에서는 언어 모델이 학습하는 다양한 언어 데이터에 대해서 이야기 했습니다. 초거대 언어 모델(Large Language Model, LLM)은 앞선 포스트에서 언급한 바와 같이 수많은 언어적 현상에 대한 표상(Representation)을 다양한 언어 데이터로부터 학습한 것으로, 학습 데이터 내에 존재하는 다양한 언어 패턴이나 구조, 관계 등을 학습하여 언어를 이해한 모델이라 할 수 있습니다. 초거대 언어 모델이 언어를 이해하고 표상을 가졌다고 하는 것은 어떤 의미일까요?
LLM은 대용량의 데이터셋 안에 포함되어 있는 다양한 언어 현상을 딥러닝 기술과 통계 모델링을 통해서 자연어 처리 작업을 수행합니다. 잘 알려진 자연어 생성 문제를 예시로 들면 주어진 문맥에서 다음 단어를 예측하는 문제를 푸는 잘 훈련된 LLM은 문맥 내에 주어진 단어들 간의 관계와 유사성 등을 파악하여 다음 단어를 생성할 수 있습니다. 물론 이 생성 품질은 초거대 언어 모델을 학습하기 위해서 사용된 데이터의 양과 구성, 학습 알고리즘 등의 복잡성 등 다양한 요인에 의해서 결정되므로 학습 데이터가 LLM의 성능을 결정하는 중요한 요인이라고 할 수 있습니다.
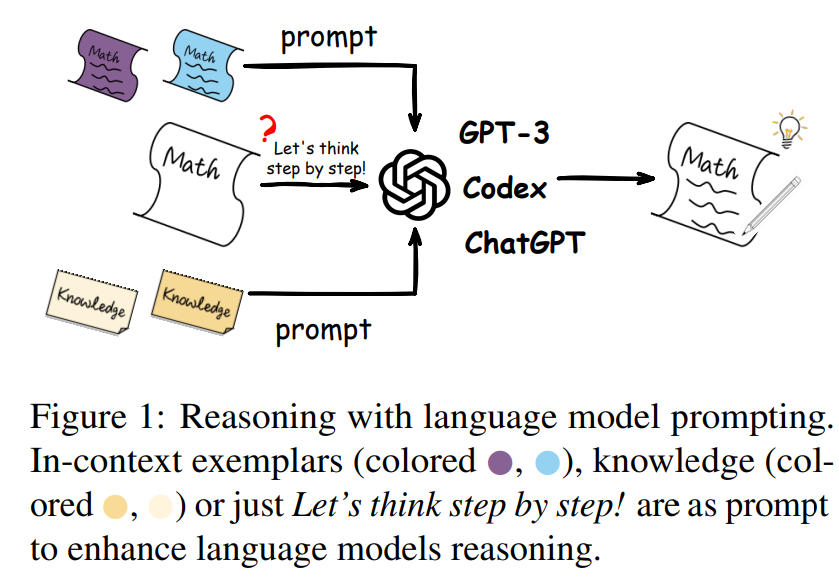
Figure 1. 언어모델을 사용한 추론 개요
그렇다면 LLM을 어떻게 활용해야 모델의 추론 및 생성 능력을 끌어 올릴 수 있을까요? 모델만 있다고 해서 스스로 어려운 문제의 답을 풀거나 다양한 생성물을 내놓지는 않을 것입니다. 그래서 LLM이 복잡한 문제를 풀기위해서는 추론(Reasoning) 능력을 갖추어야 합니다. 추론은 현실 세계에서 필요한 다양한 Use Case들이 실현될 수 있게 해 주는 문제 해결 능력이죠. 그러나 추론은 자연어 처리 기술에서도 어려운 영역 중에 하나이고, LLM의 표상만 가지고는 이미 알고 있는 내용을 도출해 내는 것이 쉽지 않습니다. 추론이라는 것은 이미 알고 있는 지식을 기반으로 새로운 답을 도출해 내야하는 사고의 과정이 필요하기 때문이죠. 이번 포스트 - 초거대 언어모델의 수업시대 2부 - 언어 모델은 어떻게 추론하는가에서는 LLM의 추론 능력을 높이는 다양한 방법들을 소개해 드립니다.
이 포스트는 ACL 2023에서 발표된 논문 “Reasoning with Language Model Prompting: A Survey1“의 내용을 기반으로 작성되었습니다.
초거대 언어 모델의 추론 능력: 인간 지능(Human Intelligence)로 나아가기 위한 필수 조건
만약 여기 지능을 지닌 기계와 인간이 있다고 가정해 봅시다.
각각에게 “서로에게서 단 하나의 능력을 취할 수 있다면, 어떤 능력을 가져오겠습니까?”라고 질문한다면 어떤 답을 할까요. 제 생각에는 기계는 인간의 추론 능력을, 인간은 기계의 연산 능력을 가지고 오고 싶다고 말할 것 같습니다. 보통의 인간의 입장에서 컴퓨터와 같은 기계는 결코 인간이 따라갈 수 없는 연산량과 속도를 가지고 있기 때문이죠. 컴퓨터와 같은 지능을 지닌 기계의 입장에서는 주어진 정보에서 학습된 내용 이외에 새로운 내용을 생성해 내고 문제를 풀어내는 능력이 인간에 비해서는 한정적일 수 밖에 없습니다.
그렇다고 해서 인간과 컴퓨터가 각각 연산 능력과 추론 능력이 없는 것은 아닙니다. LLM 역시 사전학습 모델(Pre-Trained Model)의 발전으로 인하여 모델의 크기가 커질 수록 산술적(arithmetic) 추론 능력2, 상식(common sense)에 대한 추론 능력3, 그리고 상징적(symbolic) 추론4 등에 이르기까지 다양한 추론 능력을 가질 수 있다는 것을 확인할 수 있습니다.
산술적 추론(Arithmetic Reasoning)
Question: y = 4x + 6에 평행한 직선은 좌표 (5,10)을 통과합니다. 이 직선이 y 축과 교차하는 점의 y 좌표는 무엇인가요?
» Target: 직선은 y = 4x + 6에 평행하기 때문에 기울기가 4 임을 알 수 있습니다. 따라서 직선의 방정식은 y = 4x + b 입니다. 여기서 b 는 y 절편입니다. 여기에 (5, 10)을 대입하면 10 = 4∙5 + b 이므로, b = -10 입니다. 따라서 정답은 -10 입니다.Model Reasoning
이 직선은 y = 4x + 6 과 평행합니다.
이는 y = 4x + 6 과 동일한 기울기를 갖는다는 것을 의미합니다.
직선이 (5, 10)을 통과하므로, 직선의 점과 기울기 형식을 활용하여 직선의 방정식을 아래와 같이 구할 수 있습니다.
y - 10 = 4(x - 5)
y - 10 = 4x - 20
y = 4 - 10
이제, 직선의 방정식을 얻었으므로, y 절편을 구하기 위해 x = 0 을 대입하여, y 축과 교차하는 좌표를 얻을 수 있습니다.
*y = 4∙0 - 10 = -10*
상식 추론(Commonsense Reasoning)
Question: 연기는 불의 원천입니까?
Answer: 연기는 불의 결과입니다. 그러므로 해당 명제는 거짓입니다.
Question: 1은 0 이전에 오는 숫자입니까?
Answer: 1은 0보다 크므로, 0 다음에 오는 숫자입니다. 그러므로 해당 명제는 거짓입니다.
상징적 추론(Symbolic Reasoning)
Condition: 다음 단어는 주어진 리스트에 매핑되어 출력됩니다. [thinking, machine, learning] ==> [“추”, “론”, “왕”]
Question: “Thinking machine has an ability of learning.”이라는 문장이 입력으로 주어졌을 때, Condition을 따라 출력되는 결과는 무엇입니까?
Answer: 주어진 조건에 의해 매핑되는 단어는 thinking, machine, learning입니다. thinking은 “추”, machine은 “론”, learning은 “왕”에 매핑되므로,** 출력되는 결과는 “추론왕”입니다.**
위의 예시는 언어모델을 활용한 산술적 추론, 상식 추론, 상징적 추론의 간단한 예시를 보여줍니다. 예시에서도 볼 수 있듯이 질문(입력, Input)을 던지고, 그에 대한 답변(출력, Output)을 얻는 형식입니다. 언어모델을 활용해서 수행하고자 하는 태스크에 따라서 우리는 모델에 다양한 표현과 방법 등으로 변형을 주어서 모델에게 질문을 던지게 됩니다. LLM의 추론 성능은 여전히 만족할만한 수준에 도달하기 위해서는 가야할 길이 멀고, 또 발전의 여지가 많이 남아 있기 때문에 다양한 프롬프트를 활용한 프롬프팅 방식이 제안되고 있습니다. 이어서 LM의 성능을 높이기 위해서 어떤 프롬프팅 방법들이 쓰이고 있는지 좀 더 자세히 알아보도록 하겠습니다.
초거대 언어모델의 추론 능력 끌어내기
Qiao et al.(2023)1에서는 언어모델을 사용한 추론 연구의 최근 흐름을 조사한 Survey 논문을 ACL 2023에서 발표하였습니다. 이 논문에서 소개한 태스크의 분류 체계는 Figure 4와 같습니다. 이 논문에서는 언어모델의 추론 능력을 높이기 위한 방법으로 프롬프트를 1. 전략적으로 사용하는 추론 방법(Strategy Enhanced Reasoning)과 2. 모델이 만들어낸 지식 혹은 외부 지식을 활용하는 지식 강화 추론(Knowledge Enhanced Reasoning)으로 나누어 소개하고 있는데요. 각각의 방법에는 어떤 내용이 있는지 자세히 알아보도록 하겠습니다.
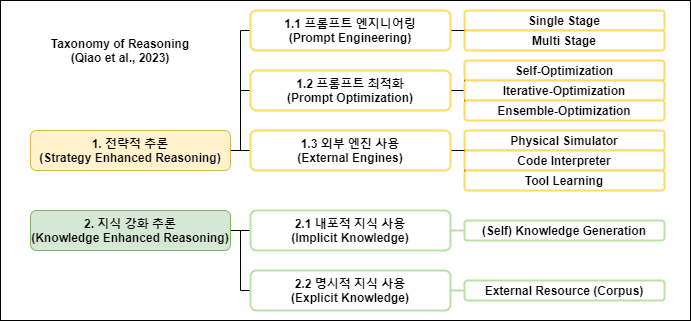
Figure 4. 언어모델을 활용한 추론 방법과 태스크 분류 체계 (Qiao et al. (2023)에서 일부 발췌)
1.1 프롬프트 엔지니어링
프롬프트 엔지니어링은 이미 다른 포스트에서도 여러 차례 소개가 된 개념으로 프롬프트의 성능을 높이기 위한 다양한 방법들로 이루어져 있습니다. 프롬프트 엔지니어링은 프롬프트의 추론 횟수에 따라 Single-Stage 방법과 multi-stage 방법으로 나누어집니다.
Figure 5에서 볼 수 있듯이 Single-Stage 방법은 하나 이상의 예시가 포함된 질문(Q), 추론(C), 답변(A) 쌍과 답을 얻고자 하는 질문 Q을 입력으로 주고, 한번의 추론 과정 C를 통해 정답 A 를 도출하는 가장 기본적인 프롬프팅 방법입니다.
Single-Stage
Question: 주차장에 3대의 차가 있었고, 2대의 차가 주차장을 떠났습니다. 주차장에는 몇 대의 차가 남아있나요?
Reasoning: 주차장에 세 대의 차가 있었고, 두 대가 떠났기 때문에, 지금은 한 대의 차가 남아있습니다.
Answer: 정답은 한 대입니다.
…
Reasoning: 민수는 5개의 공을 가지고 있었습니다. 민수가 한 캔에 3개의 공이 들어있는 캔을 두 개 샀을 때, 민수가 가진 공의 개수는 몇 개 입니까?
Answer: 정답은 11개 입니다.
이에 반해 Multi-Stage 방법은 질문(Q), 추론(C), 답변(A) 쌍에 여러 번의 추론 과정 C를 거쳐 정답을 이끌어 냅니다. 각 Stage의 추론 내용은 다음 Stage의 질문에 합쳐져서 연속적인 추론을 진행하게 됩니다. Multi-Stage 방법과 Chain-of-Thought의 차이는 질문, 추론, 답변 쌍의 개수 차이입니다. 조금 더 어려운 문제로 두 방법의 차이를 보도록 하죠.
“KBO 역사상 최초로 40 홈런 - 40 도루 클럽에 가입한 선수의 소속팀은 어디입니까? 이라는 질문에 CoT와 Multi-Stage는 아래와 같이 추론을 합니다. CoT는 질문(Q), 추론(C), 답변(A)이 하나인 Single-Stage 방법으로 하나의 답변 안에 답을 추론하는 과정을 기술합니다. 그렇지만 Multi-Stage 방법은 최종 답에 이르기까지 추가 질문과 답변을 통해서 최종 답변에 도달하는 것입니다.
Chain-of-thought
Question: KBO 역사상 최초로 40 홈런 - 40 도루 클럽에 가입한 선수의 소속팀은 어디입니까?
Answer: KBO 역사상 최초로 40 홈런 - 40 도루 클럽에 가입한 선수 에릭 테임즈 선수입니다. 에릭 테임즈 선수는 NC 다이노스 소속으로 이 클럽에 가입했습니다. 따라서 최종 답은 “NC 다이노스”입니다.
Multi-Stage
Question 1: KBO 역사상 최초로 40 홈런 - 40 도루 클럽에 가입한 선수의 소속팀은 어디입니까?
추가 질문이 필요한가요?: 네
추가 질문 1: KBO 역사상 최초로 40 홈런 - 40 도루 클럽에 가입한 선수는 누구인가요?
답변 1: 에릭 테임즈 선수입니다.
추가 질문이 필요한가요?: 네
추가 질문 2: 에릭 테임즈 선수의 소속팀은 어디인가요?
답변 2: NC 다이노스입니다. –> 따라서 최종 답은 NC 다이노스입니다.
인간의 추론 과정과 더 유사한 방식은 Multi-Stage 방법이라고 할 수 있습니다. 인간 역시 특정한 내용을 추론할 때, 전체 추론 과정을 CoT의 방법 처럼 단번에 생각하는 것(혹은 말하는 것)은 쉽지 않은 일입니다. 인간 역시 어려운 문제에 봉착하였을 때, 차근 차근 문제를 해결하려고 하죠. 하나의 복잡한 문제를 보다 간단한 여러 개의 문제로 나누고, 단계 별로 해결해 나간다면 추론의 난이도가 낮아질 수 있기 때문이죠. Multi-Stage 방법은 바로 이러한 인간의 추론 과정을 모방하고자 했다고 할 수 있습니다.
방금 소개한 프롬프트 엔지니어링 방식에 더하여 모델에게 주는 명령(Instruction)에 언어모델의 추론 능력을 높일 수 있는 다양한 표현들은 추가하기도 합니다. 사람에게 말을 하듯이 “차근 차근 생각해봐”, “자, 심호흡을 하고, 문제를 차근 차근 풀어봐” 등의 언어모델을 진정시키는 전략도 실제로 효과가 있음을 보이는 재미난 연구도 있습니다(Figure 3)5.

Figure 3. 언어모델에게 심호흡을 시키면 더 나은 추론 성능이 나온다는 Google DeepMind의 연구 결과
프롬프트 엔지니어링의 내용을 요약하면 아래와 같습니다.
Single-Stage: 단일 추론 단계를 통한 기본적인 프롬프트 엔지니어링 방법
Multi-Stage: 여러 번의 추론 단계를 통해 연속적인 질문과 답의 쌍을 활용하여 최종 정답을 도출하는 프롬프트 엔지니어링 방법
여기에 언어모델의 추론 능력을 끌어 올릴 수 있는 Instruction 까지 더해진다면?
1.2 프로세스 최적화
프로세스 최적화(Process Optimization) 방법은 추론 과정 중에서 최종 답변의 정확성을 높이기 위해 다양한 최적화 방식을 활용하는 전략입니다. 언어모델의 추론 성능을 높이기 위한 최적화 전략은 중간 평가를 통한 Self Optimization, 반복적인 추론을 통한 Iterative Optimization, 그리고 이 두 방법을 합친 Ensemble Optimization이 있습니다.
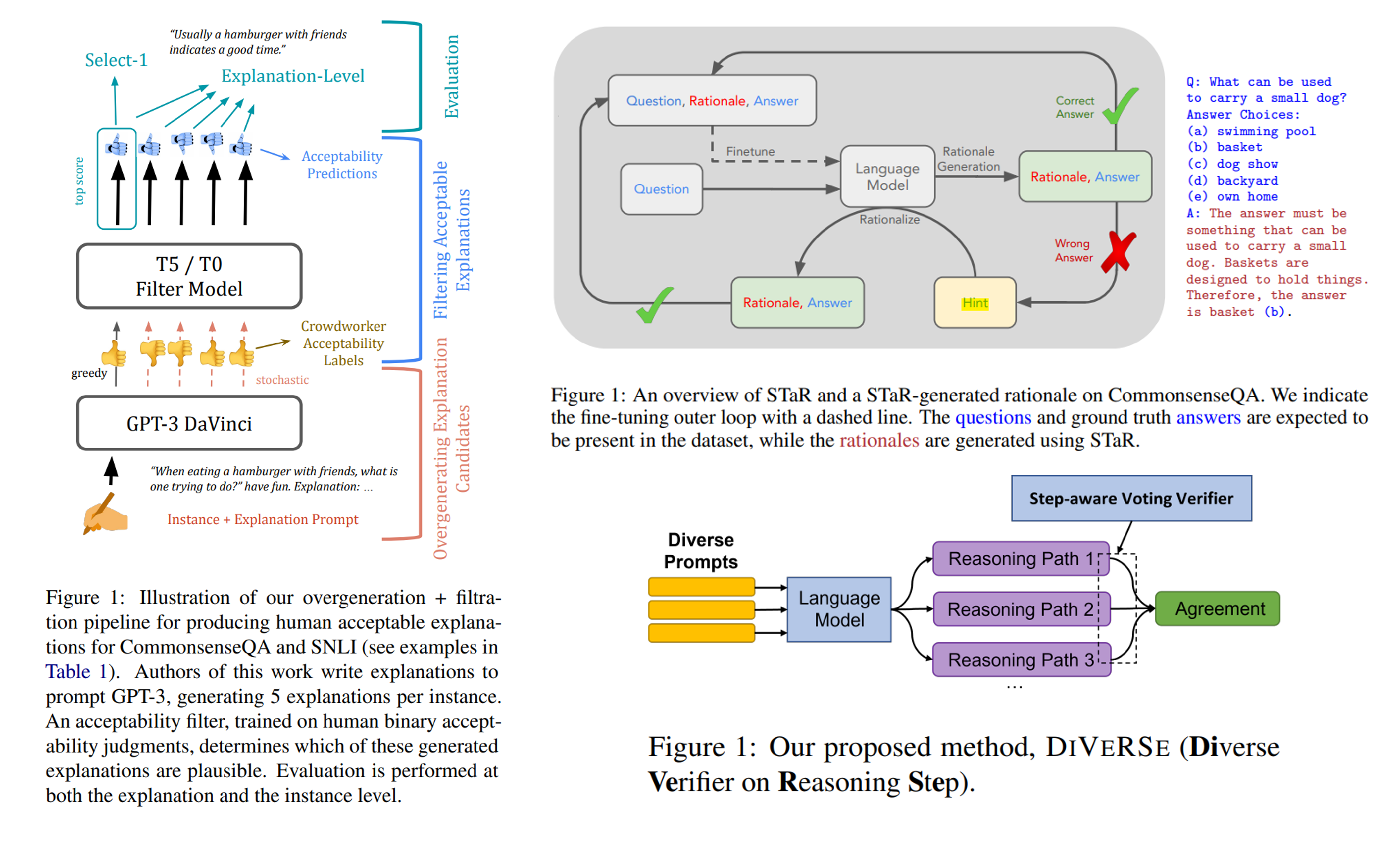
Figure 4. 프로세스 최적화 방법 예시 - 좌: Self Optimization (Wiegreffe et al.(2022)), 우측 상단: Iterative Optimization (Zelikman et al.(2022)), 우측 하단: Ensemble Optimization (Li et al.(2022))
Self Optimization은 언어모델에서 나온 결과를 기반으로 별도의 최적화 모듈(Optimizer, Verfier, Filter)을 포함하여 최종 답변을 도출하는 방법입니다. Ye and Durrett(2022)6의 연구에서는 답변의 근거에 대한 신뢰성을 평가하는 최적화 모듈을 활용하여, 신뢰성을 기반으로 답변의 확률을 조정하는 방법을 사용하였습니다. 대표적인 연구로 Wiegreffe et al.(2022)7에서는 언어모델이 생성한 텍스트 분류 성능을 향상 시키기 위해서 GPT-3가 생성한 텍스트 분류 근거를 크라우드 워커들에게 근거성을 평가하게 합니다. 이 평가 내용을 학습한 Optimizer를 도입하여 분류 성능을 향상 시키는 전략을 사용하기도 하였습니다(Figure 4 좌측). 이러한 방법은 언어모델 강화학습 방법 중에 하나인 인간 피드백을 통한 강화 학습(Reinforce Learing from Human Feedback)에서도 볼 수 있는 개념인데요. 인간의 피드백을 개입한다는 점에서 추론 성능에 대한 정확한 평가가 가능하다는 장점이 있지만, 그만큼 비용과 시간이 많이 투입되는 방법이라는 단점도 존재합니다.
Iterative Optimization은 언어모델이 추론의 답변을 생성하도록 유도하는 과정을 반복하면서 모델이 정확한 답변을 추론할 수 있게 파인튜닝 하는 방법입니다. Zelikman et al.(2022)8에서는 Figure 4 우측 상단에서와 같이 하나의 추론에 대한 결과를 언어 모델로 도출합니다. 이때, 답변(Answer)과 근거(Rationale)를 함께 생성하게 하는데요. 모델이 생성한 답변과 근거가 실제로 정답일 경우에는 질문, 근거, 답변를 하나의 쌍으로 다시 파인튜닝 데이터로 사용합니다. 만약 모델이 생성한 답변가 근거가 실제로 정답이 아닐 경우에는 추가 단서(Hint)를 제공한 상태에서 다시 답변과 근거를 생성하게 합니다. 이후 실제 정답을 생성하게 되면 역시 이 질문, 근거, 답변 쌍 역시 파인튜닝 데이터로 사용하여 모델의 성능을 향상시키는 방법입니다. 이 방법은 결국 언어모델이 초기 추론 성능을 위한 Supervised Fine Tuning이 결과의 품질에 많은 영향을 끼칠 겁니다. 또한 제공하게 되는 추가 단서(Hint)의 품질도 모델의 성능을 좌우할 것이기 때문에, 반복되는 과정에서 인간의 개입은 계속 필요할 것입니다.
Ensemble Optimization은 Self Optimization과 Iterative Optimization 방법의 이점을 모두 취하면서 하나만 선택했을 때 발생하는 약점을 줄이고자 Self와 Iterative 두 방법 모두를 최적화 과정에 사용하는 방법입니다. 언어모델이 생성한 결과물을 평가하기 위해서 최적화 모듈을 사용하면서, 동시에 정답을 다시 파인튜닝 데이터로 사용하여 모델의 성능을 향상시키는 방법입니다. Figure 6의 우측 하단의 그림과 같이 Li et al.(2022)9의 연구를 보면 여러 차례의 추론 과정에 Step-Awere Verifier를 활용하여 단계 별로 최적화 과정을 수행합니다. 이 방법에서는 최적화 과정에서 양질의 프롬프트를 사용한 추론 과정이 반복될 때, 두드러지는 성능 향상이 나타남을 확인하였다고 보고 하였습니다10.
최적화 방법의 내용을 요약하면 아래와 같습니다.
Self Optimization: 언어모델의 추론 결과를 인간의 평가를 비롯한 다양한 최적화 방법을 활용하여 신뢰성을 평가하는 방법 (
Iterative Optimization: 언어모델이 생성한 추론 결과를 다시 추론을 위한 파인 튜닝 데이터로 사용하거나, 오답인 경우 새로운 추가 단서(Hint)를 더하여 다시 추론 결과를 생성하게 하는 방법
Ensemble Optimization: Self와 Iterative의 두 방법을 결합한 최적화 방법. (장점도 두 배, 단점도 두 배…?)
1.3 외부 엔진 사용
앞서 소개한 내용 이외에도 언어모델의 추론 성능을 높이기 위해서는 복잡한 의미론적인 내용을 이해하거나, 추론 프로세스를 새로 생성하는 등의 어려운 과정을 수행해야 할 필요가 있습니다. 그렇지만 이러한 고급 능력까지 언어모델에게 모두 다 의지할 수 없습니다. 이를 위해 다양한 추론 태스크의 어려운 장애물을 헤쳐 나가기 위해 다양한 외부 엔진(도구)들이 적절한 조력자로서 활약하고 있습니다. 이를 위해서 사용하는 방법은 물리적인 추론을 위한 시뮬레이터(Physical Simulator) 사용, 코드를 통한 추론 문제, 계산 성능 등을 향상하기 위한 코드 해석기(Code Interpreter) 사용, 그리고 도구 학습(Tool Learning)11 등을 사용하는 방법이 있습니다. 이와 같은 추론 태스크의 필요에 따라 다양한 외부 엔진을 활용하여 언어모델의 추론 능력을 높이는 연구도 활발히 진행되고 있습니다.
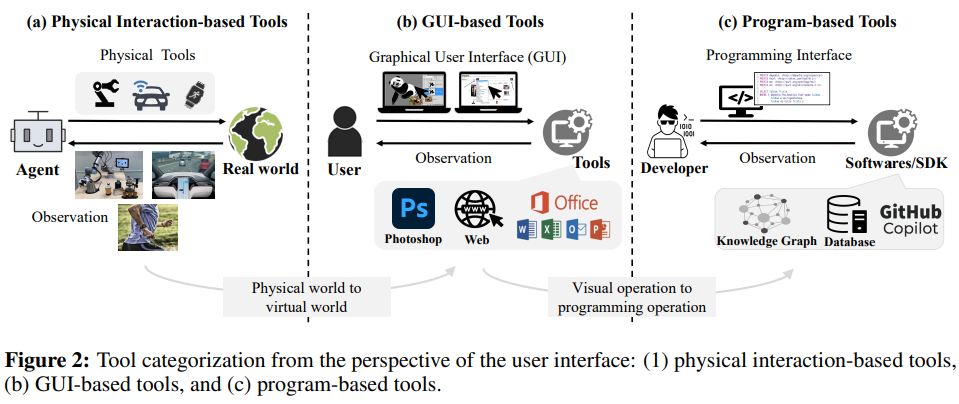
Figure 5. 사용자 인터페이스 관점에서의 도구 분류: 사람이 특정한 태스크를 수행하기 위해서 다양한 도구(외부 엔진)를 필요로 하듯, 언어모델도 그런 도움을 받을 수 있습니다.)
언어모델이 모든 것을 다 하지도 못할 뿐더러, 꼭 혼자서 모든 것을 해내야 하는 것도 아닐겁니다.
2. 지식을 활용한 추론 - Implicit Knowledge, Explicit Knowledge
산술적 추론과 같이 정답이 명확한 태스크의 경우에는 사용자는 언어모델의 추론 결과에 대해 높은 신뢰를 보일 것입니다. 그렇지만 특정 사실에 기반한 추론(예: 상식, 퀴즈 등)은 앞서 말한 추론보다는 생성 결과의 정확성에 의심을 가질 수 있습니다. 이러한 의심을 줄이기 위해, 언어모델과 지식을 함께 사용하는 추론 방법도 있습니다.
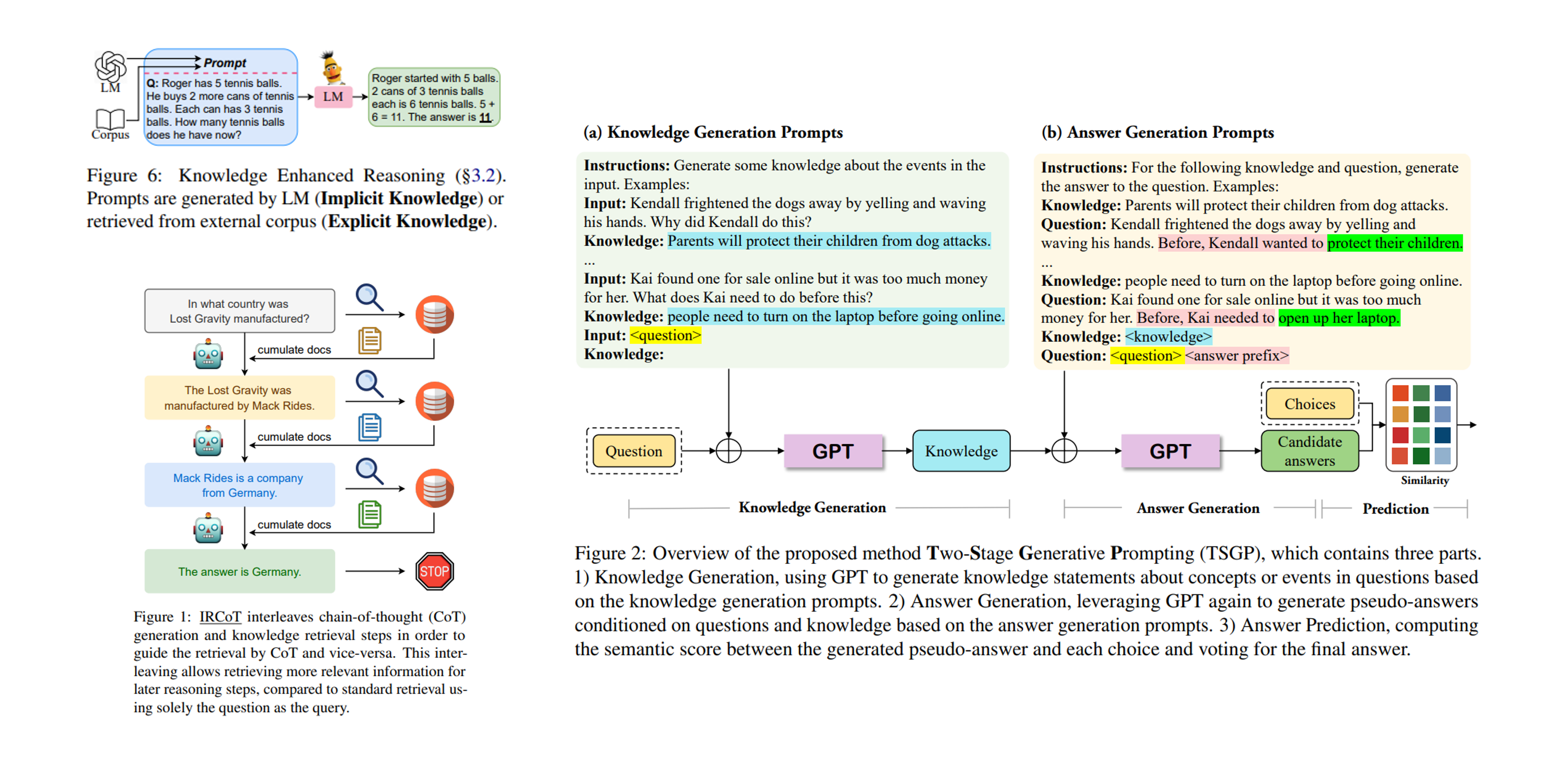
Figure 6. 다양한 지식을 활용한 언어모델의 추론 - 좌 상단: 지식을 사용한 추론 도식, 좌 하단: Explicit Knowledge 활용의 예시, 우: Implicit Knowledge 활용의 예시)
생성 결과가 가지고 있는 사실성을 제고하기 위해서 지식을 활용하는 것입니다. 언어모델은 추론 시에 필요한 지식을 추론 과정 내에서 언어모델이 생성하여 활용하거나, 외부의 소스로부터 제공받아 추론 정답에 활용하기도 합니다. 지식을 활용한 추론 방법은 프롬프트 내에 포함되어 있는 예시를 활용한 Few-shot Learning을 통해 추론에 필요한 지식이나 근거를 모델이 스스로 생성하여 다시 이를 활용하는 Implicit Knowledge 방법과 외부의 정보(예: external corpus 등)를 사용해서 추론 결과에서 발생할 수 있는 정보의 사실성 문제(Hallucination, 일관성 문제) 등을 보완해주는 Explicit Knowledge 방법으로 나누어 볼 수 있습니다.
Implicit Knowledge를 활용한 Sun et al.(2022)12의 연구는 GPT를 활용하여 지식을 생성하는 단계와, 답변을 생성하는 단계, 그리고 예측 단계로 구성된 추론 방법을 소개하였습니다. 지식을 생성하는 단계에서 주어진 추론 질문에 필요한 지식을 생성하고, 답변 생성 단계에서 생성된 지식을 활용하는 방식을 취하고 있습니다. Explicit Knowledge를 사용한 Trivedi et al. (2022)13의 연구는 각각의 추론 단계마다 필요한 정보를 외부 리소스(문서 등)으로 부터 참고하여 처음에 주어진 질문을 쿼리로 사용하는 것과 더불어 외부 지식으로 획득한 정보를 쿼리에 축적시켜 추론에 대한 정답을 완성하는 전략을 취하고 있습니다.
스탠포드 대학교의 저명한 NLP 연구자인 Chris Manning 교수는 지식(Knowledge)은 AI를 활용한 추론에서 핵심적인 역할(vital role)을 맡고 있다고 했습니다. 너무나도 당연한 말이지요. 아무리 방대한 데이터로 그럴싸하게 말하는 언어모델이 있다고 하더라도, 그 내용의 사실성과 일관성을 담보하지 못한다면, 그 쓰임은 자연스레 사라지게 될겁니다. 그렇기에 지식과 언어모델은 뗄레야 뗄 수 없는 관계이지 않을까요?
언어모델이 그저 인간의 말을 모방하는 앵무새에 그치지 않으려면 ‘정확하고 일관된 지식’이 필요할 것입니다.
언어모델이 풀어야 할 남은 문제들
먼저 추론이 작동하는 이론적 원리를 파악하여 접근해 봐야 할 필요가 있습니다. 언어모델은 그 규모가 커질 수록 처음 본 추론 태스크에 대한 Zero-shot learning을 통해 추론 문제를 해결하기도 합니다. 이 능력이 어떻게 나온 것인지 파악하기 위해 많은 연구자들이 in-context learning의 비밀을 풀기 위한 다양한 역할과 이론적인 근거를 찾기도 합니다14.
뿐만 아니라 언어모델이 가지고 있는 다양한 프랜스포머의 구조와 같은 사전학습 모델의 구조가 추론 능력에 영향을 끼친다는 연구도 있습니다15. 이러한 연구들이 언어모델의 추론 능력에 대한 완전한 해답을 주지는 못하지만 여러 연구들이 모여 수수께끼를 하나씩 풀어가고 있습니다. 이러한 언어모델의 추론 결과는 점점 견고하고, 믿을 수 있어야 하며, 해석 가능해야 합니다. 이것은 추론을 포함한 딥러닝 분야에서 계속해서 풀고자 하는 문제입니다. Dohan et al.(2022)16와 같은 연구에서는 다양한 추론 문제를 해결하기 위해 확률론적인 프로그램을 활용하기도 하고, 인간의 피드백17을 통하여 추론의 신뢰도를 높이는 연구가 계속되고 있습니다.
언어모델의 추론 능력의 일반화 작업 역시 풀어야 할 과제입니다. 주어진 추론 문제만 풀어 내는 언어모델이 아닌, 문제 자체를 해석하여 학습 과정에서 볼 수 없었던, OOD(Out-of-distribution) 상황에서도 추론 작업을 해 낼 수 있는 일반화된 추론 능력을 가진 언어모델이 필요합니다. 일반화된 추론 능력을 가진 언어모델의 구현을 위해 유추를 활용한 추론18, 인과 관계를 활용한 추론19, 구성을 활용한 추론20 등 논리 구조를 활용한 다양한 추론 방법에 대한 시도를 하고 있습니다.
또 하나 주목해야 할 연구 흐름은 언어모델의 효율화와 환경에 관한 내용입니다. 초거대 언어모델은 매우 높은 컴퓨팅 리소스를 소비하기 때문에, 실용성 측면에서는 별로 좋지 못합니다. 따라서 실용성을 높이기 위해서는 소규모 언어모델을 활용해서도 좋은 추론 능력을 얻을 수 있어야 합니다. 이를 위해 지식 증류(Knowledge Distillation) 기법과 같은 경량화 연구도 활발하게 진행되고 있습니다21.
이는 모델의 효율성 뿐만 아니라 모델의 학습과 추론 시에 발생하는 탄소 배출과 에너지 사용량을 줄이는 것과도 직결됩니다. 실제로 언어모델 개발 시에 발생할 수 있는 환경 문제22도 지적되고 있기 때문에, 이러한 측면을 고려한 추론 방법론 개발이 필요하다는 연구23도 나오고 있습니다. 이제 언어모델은 단순히 모델과 데이터의 문제를 뛰어 넘어 전지구적인 과제가 되어 가고 있는 것이 아닐까요?
나오며: 그래서 언어모델은 어떻게 추론해야 할까요?
지금까지 언어모델 추론을 위한 다양한 방법들을 살펴 보았습니다. 물론 여기 소개한 내용이 전부는 아닐 것이고, 이 내용을 쓰고 있는 지금도 새로운 방법을 활용한 다양한 연구들이 많이 나오고 있을 겁니다. 그리고 우리는 또 다시 새로운 문제에 직면하게 될 것입니다. 우리는 새로운 추론 과제가 주어졌을 때, 어떻게 언어모델이 그 능력을 발휘할 수 있게 해야 할까요? 또 앞으로 언어모델은 어떤 방식으로 추론을 해야 하는 것일까요? 이 질문에 대한 답은 다양한 연구의 경험에서 얻을 수 있을 것 같습니다.
인간의 지능을 모방한 기계. 과연 우리는 어디쯤 와 있는 것일까요?
Reference
-
Qiao, S., Ou, Y., Zhang, N., Chen, X., Yao, Y., Deng, S., … & Chen, H. (2022). Reasoning with language model prompting: A survey. arXiv preprint arXiv:2212.09597. ↩ ↩2
-
Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V., … & Misra, V. (2022). Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35, 3843-3857. ↩
-
Liu, J., Hallinan, S., Lu, X., He, P., Welleck, S., Hajishirzi, H., & Choi, Y. (2022). Rainier: Reinforced knowledge introspector for commonsense question answering. arXiv preprint arXiv:2210.03078. ↩
-
Khot, T., Trivedi, H., Finlayson, M., Fu, Y., Richardson, K., Clark, P., & Sabharwal, A. (2022). Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406. ↩
-
Yang, C., Wang, X., Lu, Y., Liu, H., Le, Q. V., Zhou, D., & Chen, X. (2023). Large language models as optimizers. arXiv preprint arXiv:2309.03409. ↩
-
Ye, X., & Durrett, G. (2022). The unreliability of explanations in few-shot prompting for textual reasoning. Advances in neural information processing systems, 35, 30378-30392. ↩
-
Wiegreffe, S., Hessel, J., Swayamdipta, S., Riedl, M., & Choi, Y. (2021). Reframing human-AI collaboration for generating free-text explanations. arXiv preprint arXiv:2112.08674. ↩
-
Zelikman, E., Wu, Y., Mu, J., & Goodman, N. (2022). Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems, 35, 15476-15488. ↩
-
Li, Y., Lin, Z., Zhang, S., Fu, Q., Chen, B., Lou, J. G., & Chen, W. (2023, July). Making language models better reasoners with step-aware verifier. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 5315-5333). ↩
-
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., … & Zhou, D. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171. ↩
-
Qin, Y., Hu, S., Lin, Y., Chen, W., Ding, N., Cui, G., … & Sun, M. (2023). Tool learning with foundation models. arXiv preprint arXiv:2304.08354. ↩
-
Sun, Y., Zhang, Y., Qi, L., & Shi, Q. (2022). TSGP: Two-Stage Generative Prompting for Unsupervised Commonsense Question Answering. arXiv preprint arXiv:2211.13515. ↩
-
Trivedi, H., Balasubramanian, N., Khot, T., & Sabharwal, A. (2022). Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. arXiv preprint arXiv:2212.10509. ↩
-
Liu, J., Shen, D., Zhang, Y., Dolan, B., Carin, L., & Chen, W. (2021). What Makes Good In-Context Examples for GPT-$3 $?. arXiv preprint arXiv:2101.06804. ↩
-
Madaan, A., Zhou, S., Alon, U., Yang, Y., & Neubig, G. (2022). Language models of code are few-shot commonsense learners. arXiv preprint arXiv:2210.07128. ↩
-
Dohan, D., Xu, W., Lewkowycz, A., Austin, J., Bieber, D., Lopes, R. G., … & Sutton, C. (2022). Language model cascades. arXiv preprint arXiv:2207.10342. ↩
-
Ouyang, S., Zhang, Z., & Zhao, H. (2021). Fact-driven Logical Reasoning for Machine Reading Comprehension. arXiv preprint arXiv:2105.10334. ↩
-
Webb, T., Holyoak, K. J., & Lu, H. (2023). Emergent analogical reasoning in large language models. Nature Human Behaviour, 7(9), 1526-1541. ↩
-
Feder, A., Keith, K. A., Manzoor, E., Pryzant, R., Sridhar, D., Wood-Doughty, Z., … & Yang, D. (2022). Causal inference in natural language processing: Estimation, prediction, interpretation and beyond. Transactions of the Association for Computational Linguistics, 10, 1138-1158. ↩
-
Yang, J., Jiang, H., Yin, Q., Zhang, D., Yin, B., & Yang, D. (2022). SEQZERO: Few-shot compositional semantic parsing with sequential prompts and zero-shot models. arXiv preprint arXiv:2205.07381. ↩
-
Ho, N., Schmid, L., & Yun, S. Y. (2022). Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071. ↩
-
Xu, J., Zhou, W., Fu, Z., Zhou, H., & Li, L. (2021). A survey on green deep learning. arXiv preprint arXiv:2111.05193. ↩
