
- 자동 생성 Framework 소개: 개발자의 업무 효율↑
- 자동 생성 Framework도입 효과: 작업시간 단축 1시간 → 10분으로
- 학습 자동복구 시스템 소개: 연구원 동료들의 업무 효율↑
- 학습 자동복구 시스템의 효과: 학습 시스템 관리 시간 최소화
- 마치며
- 발행 예정 글
작성자
- 정민철 (AI Production실)
- 독서가 취미인 개발자입니다. 효율적인 개발 과정을 만드는 데 관심이 있습니다.
이런 분이 읽으면 좋습니다!
- 게임에 AI 서비스를 만들어 가는 과정이 궁금하신 분
- 학습 시스템을 효과적으로 설계하고 배포하는 방법에 대해 알고 싶으신 분
이 글로 확인할 수 있는 내용
- 리니지 리마스터에서 시뮬레이터를 설계한 과정
- 학습 시스템을 효율적으로 배포하는 방법
안녕하세요. AI Production 실에서 개발자로 일하고 있는 정민철입니다.
지난 6월에 1부를 발행하고 시간이 많이 흘렀네요. 1부에서는 Protobuf 프로토콜을 이용해 게임 시스템과의 의존성을 최소화해 학습 시스템의 업데이트를 수월하게 한 방법과 Docker를 이용해 학습 환경 배포를 효율화한 것에 관해 설명했습니다. 이번 글에서는 MMORPG 시뮬레이터 개발부터 서비스 배포 과정 중 ‘효율화’ 관점에서 가장 뜻깊게 생각하는 개선점 2가지를 소개하겠습니다. 첫 번째 주제는 자동 생성 Framework를 만들어 개발 과정을 효율화한 노하우이고, 다른 주제는 학습 자동 복구 시스템을 만들어 연구자가 대규모 학습 시스템을 쉽게 관리할 수 있도록 환경을 마련한 것입니다.
자동 생성 Framework 소개: 개발자의 업무 효율↑
1부에서 서버팀과 Protobuf를 이용해 게임 서버와 주고받을 메시지를 정의했다고 이야기했습니다. (자세한 이야기는 <MMORPG시뮬레이터 개발부터 서비스 배포까지 1> 글을 참고해 주세요!) 이렇게 정의된 메시지는 자동 생성 Framework에서도 핵심 요소로 사용되었습니다.
리니지 AI 시스템은 실제 캐릭터들이 활동하는 게임 서버, 게임 서버와 AI 서버 간의 통신을 중계해 주는 AI Broker 서버, AI 모델을 이용해 결정을 내리는 AI 서버로 이루어져 있습니다. 그래서 1개의 기능을 구현하기 위해서는 여러 서버에 걸쳐 기능을 구현해야 합니다. 아래에 한 개의 기능을 만들기 위해 각 서버에서 구현해야 하는 내용을 대략 표현해 봤습니다.
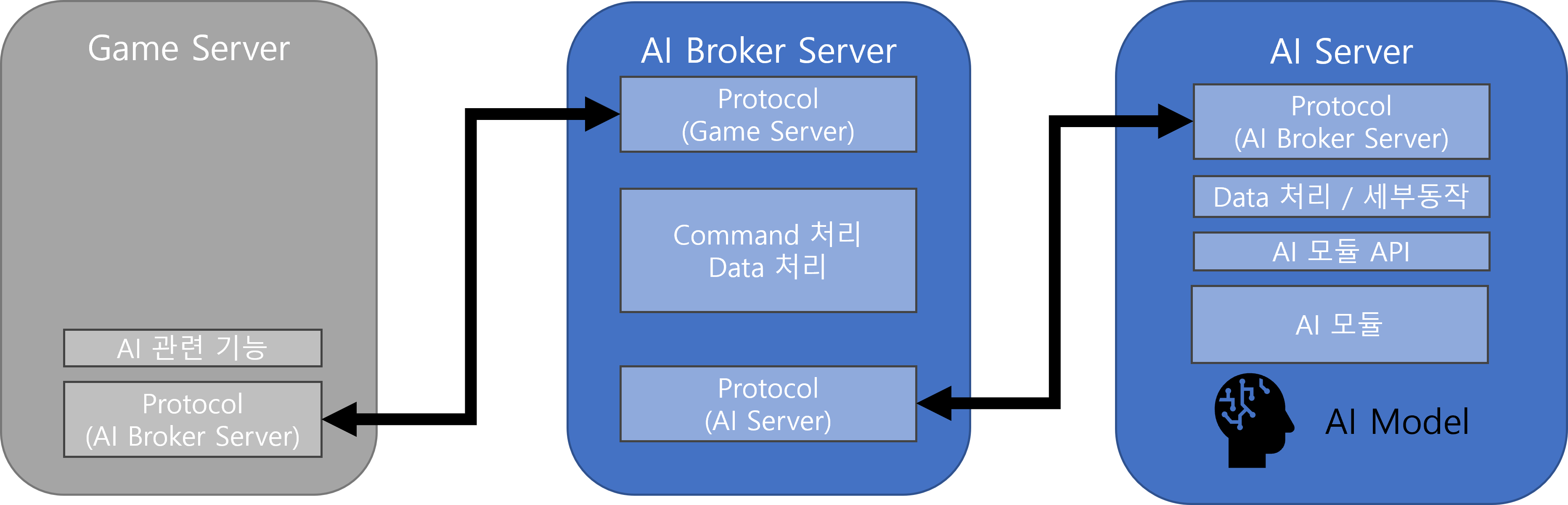
그림1. AI 시스템의 내부 구조
이런 구조에서는 구현해야 할 부분이 많고, 각 부분을 개별적으로 구현하다 보면 실수가 생길 수 있습니다. 또한 문제가 발생하면 어떤 layer에서 문제가 발생했는지 검토가 필요하기 때문에 개발 및 디버깅에 시간이 오래 걸릴 수 있습니다.
이를 해결하기 위해 만든 것이 자동 생성 Framework입니다. 이 Framework는 Protobuf 메시지와 code template을 입력으로 받아 실제 코드를 생성해 주는 도구입니다. 생성 대상이 되는 코드는 각 서버 간의 Protocol이나 Data 처리와 같이 반복적이고 단순한 구조로 되어있는 부분입니다. 세부동작 구현이 필요한 부분은 자동 생성된 코드를 상속받는 다른 파일로 분리해 개발자가 더 중요한 부분에 집중할 수 있도록 만들었습니다. 이런 식으로 도구를 사용하면서 전체적인 코드 구조 역시 개발자가 구현하기 편하도록 최적화해 개발 효율을 높였습니다.

그림2. 템플릿 엔진을 이용한 코드 자동생성 구조
자동 생성 Framework도입 효과: 작업시간 단축 1시간 → 10분으로
이 도구를 사용하면서 추가로 발견한 장점이 있습니다. 그것은 자동생성 코드에 개선할 점이 있다면 적은 노력으로 반영할 수 있다는 것입니다. 개선할 부분을 Code Template에 반영하면 모든 기존 코드에 개선된 사항이 반영되기 때문에 적은 노력으로 개선점을 반영할 수 있습니다. 실제 사례로 네트워크 부하가 늘어나서 압축 알고리즘을 개선해야 하는 상황이 있었는데 여러 압축 알고리즘을 비교해 제일 좋은 알고리즘을 도출했고, 이것을 Code Template에 대한 약간의 수정을 통해 전체 시스템에 쉽게 반영하였습니다.

그림3. 자동 생성 도입 효과
작은 수정 사항을 기준으로 기존에 손으로 직접 코드를 수정하던 방법은 적어도 1시간이 걸린 데 비해, 자동 생성 Framework를 도입한 이후에는 같은 작업을 10분 이하로 수행할 수 있게 되었습니다. 프로젝트를 진행하면서 110회 이상의 크고 작은 업데이트 상황이 발생했는데, 이 도구를 활용해 빠르게 대처할 수 있어서 일정 내에 프로젝트를 완료하는 데 큰 도움이 되었습니다.
학습 자동복구 시스템 소개: 연구원 동료들의 업무 효율↑
기존에 연구원들이 겪었던 큰 어려움 중 하나는 연구를 진행하는 동시에 학습 시스템 관리까지 많은 시간을 투자해야 한다는 점이었습니다. 논문을 읽고, 학습 코드를 개발할 때는 몰입이 필요한데, 항상 내가 돌려놓은 실험이 멈추지 않았는지 불안한 마음을 가지고 수시로 확인해야 하는 고충이 있었습니다.
함께 일하는 동료로서 연구원들이 겪고 있는 이런 어려움에 도움을 주고 싶었습니다. 연구에 집중할 때는 충분히 그에 몰입할 수 있도록 도와주고 싶었죠. 이를 위해 제안한 방법이 Docker를 활용한 자동 학습복구 시스템입니다.
먼저 독자분들의 이해를 돕기 위해 1명의 연구원이 사용하는 학습 시스템에 관해 설명하겠습니다. 학습 시스템은 AI 모델의 학습이 수행되는 Learner, AI 캐릭터를 조작하는 Worker, AI 캐릭터를 생성해 게임을 시뮬레이션 하는 Environment로 구성됩니다. 이 중 Environment는 위에서 설명한 Game Server와 AI Broker Server로 이루어져 있습니다. Worker는 위에서 설명한 AI Server에 해당하는 것으로 학습된 모델을 가지고 AI 캐릭터를 조작하여 시뮬레이션을 수행합니다. 여러 개의 Worker가 1개의 게임 서버에 붙어서 수없이 많은 시뮬레이션을 수행하고, 시뮬레이션 결과는 Learner로 전달되어 GPU를 활용해 새로운 모델을 학습하는 데 사용됩니다.
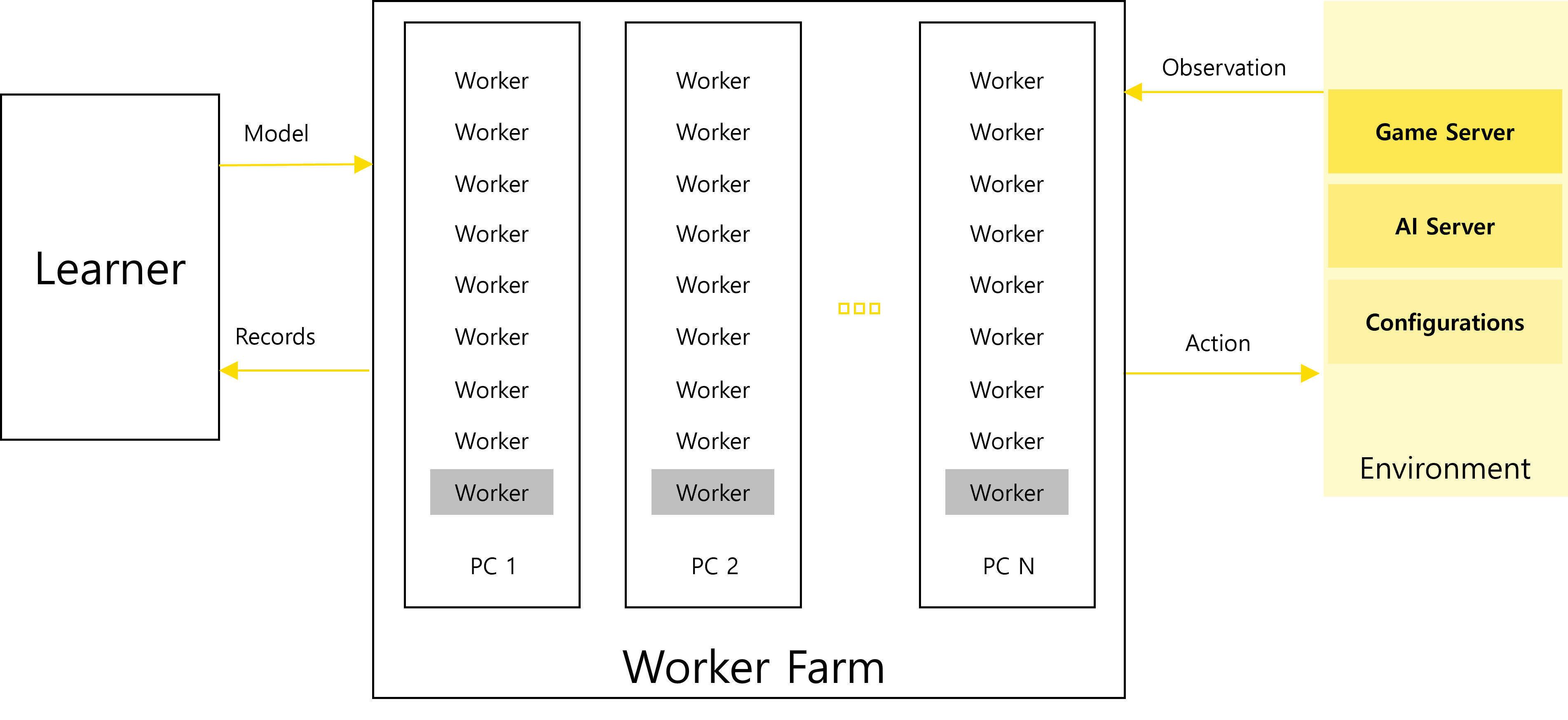
그림4. 대규모 학습 시스템의 구조
이러한 구조에서 문제가 생기는 Case는 3가지가 있습니다. 단순한 순서대로 각 Case 별로 설명하도록 하겠습니다.
Case1: worker 중 1개가 멈추는 상황
이런 상황은 아래와 같이 대처했습니다.
- 시뮬레이션을 수행 중인 Worker 1개가 코드 에러나 메모리 사용량 초과 등 여러 가지 문제로 죽습니다.
- Environment에서 worker의 disconnect를 확인합니다.
- Environment에서 죽은 worker가 진행하던 시뮬레이션 환경을 초기화합니다.
- Learner에서는 죽은 worker가 보내던 정보를 폐기합니다.
- Docker의 restart 기능을 이용해 자동으로 살아난 worker가 새로운 시뮬레이션을 시작합니다.
Case2: Learner가 죽은 상황
이 경우도 비교적 단순한 상황인데, Learner가 죽어도 시뮬레이션은 계속 진행될 수 있고, 살아난 이후에 쌓여 있는 시뮬레이션 결과를 이어서 처리하기만 하면 되기 때문입니다. 이런 부분에 대한 처리는 Game AI팀에서 개발해 주셨습니다.
- 학습을 수행 중인 Learner가 죽습니다.
- Worker는 여전히 시뮬레이션 결과를 Queue에 쌓아 놓습니다.
- Learner가 Docker의 restart 기능을 이용해 살아납니다.
- Learner가 기존에 어디까지 학습했는지 기록을 확인해 이어서 학습할 준비를 합니다.
- Learner가 학습할 준비가 완료되면 Queue에 쌓인 시뮬레이션 결과를 처리하며 이어서 학습을 진행합니다.
Case3: 게임 서버가 있는 Environment가 죽은 상황
이 경우는 치명적인 상황이 발생하게 되는데, 수많은 worker가 진행 중이던 시뮬레이션이 모두 중단되기 때문입니다. Worker들은 Environment가 다시 살아날 때까지 대기해야 하고, 다시 시작 시 한꺼번에 몰려든 worker로 인해 너무 많은 부하가 걸려서 Environment가 다시 죽는 문제가 발생할 수 있기 때문에 방지책도 마련해야 합니다. 이런 상황에서는 아래와 같은 순서로 재시작을 수행합니다.
- 시뮬레이션을 수행 중인 Environment가 죽습니다.
- Worker가 수행하던 시뮬레이션 작업이 모두 중단됩니다.
- Environment가 Docker의 restart 기능을 이용해 살아납니다.
- Environment가 Warm UP 상태에 들어갑니다. (약 5분~10분 소요)
(Warm Up: Environment는 여러 서버로 이루어져 있어서 각 서버가 실행된 후 연결되어 동작할 수 있게 되기까지 시간이 걸립니다. 이 과정을 Warm Up이라고 합니다.) - 각 Worker 들이 Warm Up 시간에 0~10분 사이의 무작위 시간을 더한 만큼 대기합니다.
(Warm Up 시간을 10분으로 잡았기 때문에 대기 시간은 10~20분 사이입니다.) - Environment가 정상 상태가 됩니다.
- 각 Worker 들이 대기상태에서 빠져나와 다시 Environment에 연결되어 시뮬레이션을 수행합니다.
또한 Environment가 죽는 상황에 Teams 메신저에 메시지를 남기도록 구현했습니다. 이를 통해 서버를 띄우자마자 죽는 경우와 뭔가 인프라에 문제가 생겨서 같은 서버가 계속 죽는 상황을 알 수 있게 되었습니다.
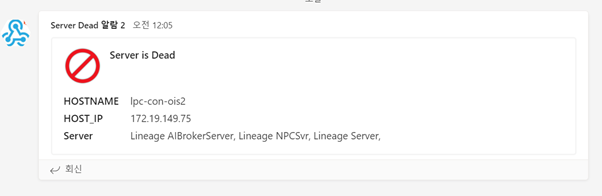
그림5. Environment가 죽는 상황 알림
학습 자동복구 시스템의 효과: 학습 시스템 관리 시간 최소화
이런 시스템을 구현해서 연구원들이 평일에는 학습 시스템 관리에 투여하는 시간을 최소화해 연구에 집중할 수 있게 만들었고, 주말에도 학습이 죽었는지 불안에 떨지 않고 안심하고 쉴 수 있도록 만들었습니다. (이전에는 가끔 주말에 나와 학습 상황을 보는 연구원이 있었다는 것은 비밀입니다.)
생각지도 못하게 이 시스템의 덕을 본 상황을 소개해 드리고 마무리하도록 하겠습니다. 새로운 버전을 배포했는데, 일시적으로 게임 서버에 문제가 생겨 학습이 6시간만 유지되었습니다. 하지만 이때도 자동으로 복구가 되었기 때문에 문제없이 학습을 수행할 수 있었습니다. 물론 연구원들이 적어도 4시간 이상 시뮬레이션이 돌면 문제없이 학습을 진행할 수 있다고 검증했기 때문에 자신 있게 학습을 돌릴 수 있었습니다.
마치며
2부에서는 개발자들의 생산성을 개선해준 자동 생성 Framework와 연구원들이 연구에 집중할 수 있는 환경을 만들어준 학습 자동복구 시스템에 관해 이야기했습니다. 사실 이 두 가지가 제가 이 프로젝트를 진행하면서 달성했던 가장 뿌듯한 일들입니다.
3부에서는 AI 라이브 서비스 준비 과정과 서비스를 진행하면서 겪었던 일들을 이야기하도록 하겠습니다. 긴 글 읽어 주셔서 감사합니다.
발행 예정 글
◼︎ 1부 (지난 글)
- 리니지 거울전쟁 콘텐츠 소개
- 시뮬레이션 시스템의 구조
- 블레이드 앤 소울 AI 개발 시 겪었던 문제점들
- 문제 해결 아이디어1. 게임과의 의존성을 최소화한 학습 시스템 설계
- 문제 해결 아이디어2. Docker를 이용한 학습환경 배포
◼︎ 2부 (이번 글)
- 자동 생성 Framework 소개: 개발자의 업무 효율↑
- 자동 생성 Framework 도입 효과: 작업시간 단축 1시간 → 10분으로
- 학습 자동복구 시스템 소개: 연구원 동료들의 업무 효율↑
- 학습 자동복구 시스템의 효과: 학습 시스템 관리 시간 최소화
- 마치며
◼︎ 3부 (예정)
- 라이브 서비스 준비 과정
- 라이브 서비스 모니터링 과정
- 라이브 서비스 종료까지
