

- I. What? - Texture Copilot: 3D Texturing을 돕는 AI Copilot
- II. Why? - Texture Copilot을 만들게 된 이유
- III. How? - Texture Copilot의 R&D 과정
- Reference
작성자
- 김장영, 최준영 (Graphics AI Lab)
- AI를 활용한 3D 게임 에셋 제작 방식을 연구하고 있습니다.
이런 분이 읽으면 좋습니다!
- Stable Diffusion 및 이후 생성 모델 연구의 흐름이 궁금하신 분
- AI를 활용한 3D 게임 에셋 제작 서비스가 궁금하신 분
이 글로 확인할 수 있는 내용
- 3D 게임 에셋 제작 과정에 생성 AI가 적용될 수 있는 부분
- AI 서비스 개발을 위한 R&D 과정
I. What? - Texture Copilot: 3D Texturing을 돕는 AI Copilot
저희 프로젝트는 생성 AI 기술이 NC의 게임 제작 과정을 더 창의적이고 효율적으로 만들어 줄 수 있을 것이라는 비전을 가지고, 3D 게임 에셋 제작을 도울 수 있는 여러 가지 AI 서비스들을 시도해 보고 있습니다. 그중 이번 글에서 소개할 프로젝트는 Texture Copilot이란 이름으로 시도 중인 연구입니다. Texture Copilot은 텍스쳐링 과정(3D 게임 에셋 제작 과정 중 일부)을 돕는 AI 서비스로, Alpha 버전을 개발하여 사내 테스트까지 진행하였습니다.
서비스 명인 Texture Copilot은 Texturing 과정을 도와주는 AI Copilot(AI 부조종사)이라는 의미를 담고 있는데요, 현재까지 개발된 Texture Copilot의 주요 기능은 1. Text만으로 Texture(Diffuse Map) 생성하기, 2. 기존 Texture를 업로드 후 Text로 Texture를 편집하기 두 가지입니다. 먼저, 아래 데모 영상으로 Texture Copilot을 만나 보시죠!
<영상 1. Texture Copilot 데모>
데모 영상은 재미있게 보셨을까요? 그러면 이제 본격적으로 Texture Copilot이라는 서비스를 왜 시작하게 되었고, 어떻게 R&D 과정을 밟아가고 있는지 그리고 앞으로의 계획 등에 대해 소개하도록 하겠습니다.
II. Why? - Texture Copilot을 만들게 된 이유
1. 이미지(2D) 생성 연구를 통해 발견한 새로운 가능성
Stable Diffusion, Midjourney와 같은 뛰어난 이미지 생성 모델들이 비교적 최근에 공개되었기 때문에 이미지 생성 분야는 신생 분야처럼 인식되곤 합니다. 하지만 이미지 생성 연구의 역사는 RBM(Restrict Bolzmann Machine), VAE(Variational Auto Encoder) GAN(Generative Adversarial Network), Diffusion Model 등을 거치며 수십 년에 걸쳐 이루어져 왔습니다.
과거부터 최근까지의 이미지(2D) 생성 연구를 리서치 해오며 저희는 AI가 향후 2D뿐 아니라, 3D와 같은 그래픽까지도 높은 퀄리티로 생성할 수 있을 것으로 보았습니다. 그 때문에 이 기술이 NC의 3D 게임 에셋 제작 과정을 돕는 데에 활용될 수 있겠다고 생각했고, 선행 연구를 살펴보기 시작했습니다. 선행 연구 중 저희 연구의 가장 중요한 밑바탕이 되어준 Diffusion Model과 Stable Diffusion에 대해 먼저 간략히 소개해 드리겠습니다.
a. Diffusion Model
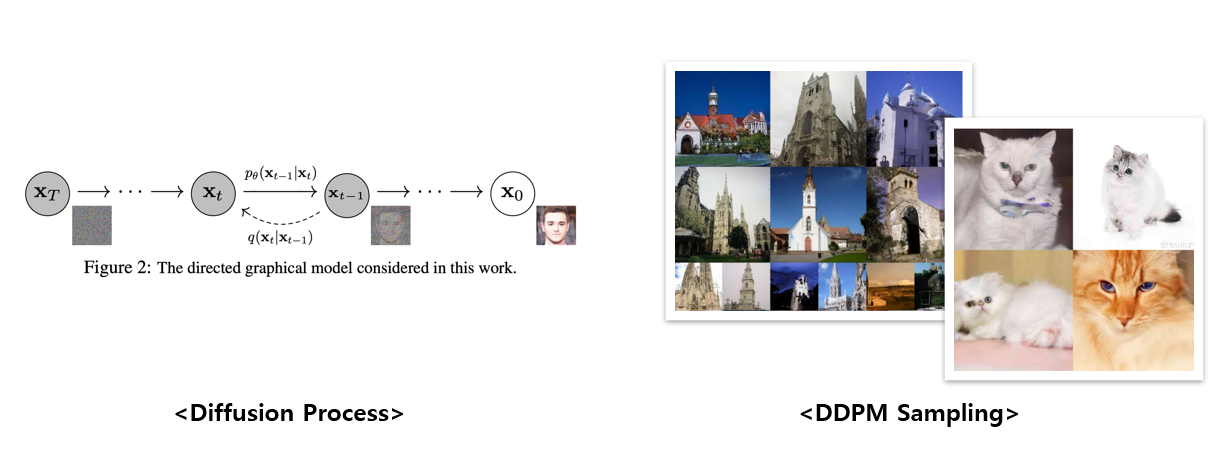
<이미지 1. Diffusion Process와 DDPM의 다양한 데이터셋 학습결과>
Diffusion Model의 구조가 고안된 것은 꽤 오래되었는데요(2015년), 실질적으로 Diffusion Model에 관한 관심을 다시 살려낸 모델은 DDPM(Denoising Diffusion Probabilistic Model, 2020)입니다. 괜찮은 생성 퀄리티를 보여주면서 Diffusion Model에 다시금 주목하게 했습니다.
Diffusion Model은 data에 noise를 조금씩 더해가거나 noise로부터 조금씩 복원해 가는 과정을 통해 data를 generate하는 모델이라고 할 수 있는데, 그 과정이 바로 Diffusion Process입니다. 우선, 좌측 그림의 오른쪽에서 왼쪽으로 noise를 점점 더해가는 forward process를 진행하고. 그리고 이 forward process를 반대로 추정하는 reverse process를 학습함으로써 noise로부터 data를 복원하는 과정을 학습하게 됩니다. 바로 이 reverse process를 활용해서 random noise로부터 우리가 원하는 image, text, graph 등을 generate 할 수 있는 모델이 Diffusion Model인 것입니다. DDPM과 같은 Diffusion Model도 결국 이전의 이미지 생성 모델들과 마찬가지로 Dataset의 확률 분포를 추정하여 현실적으로 그럴싸한(즉, 확률적으로 일리 있는) output을 만들어 내는 생성 모델입니다. 다만, 학습 방식이 더 효율적이고, 다양하고 큰 규모의 Dataset을 학습할 수 있게 되었을 뿐이죠.
b. Stable Diffusion & ControlNet
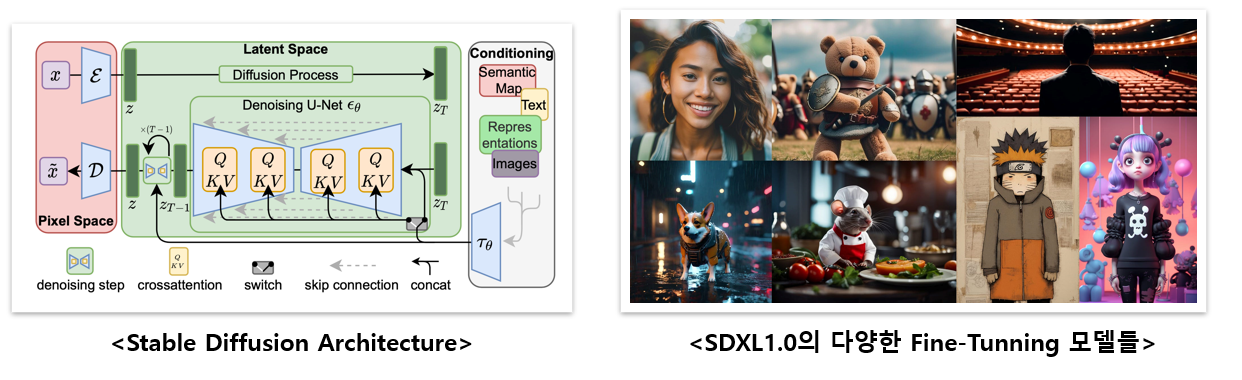
<이미지 2. Stable Diffusion과 Fine-tunning 모델들의 생성결과>
<출처: https://medium.com/mlearning-ai/sdxl-1-0-is-now-available-for-download-d2ee9f047c9e >
이미지 생성 모델의 현재는 2022년에 발표된 Stable Diffusion, 그리고 2023년에 발표된 ControlNet입니다. Stable Diffusion 모델을 간단히 말하면 quality를 저하하지 않고 Diffusion Model의 학습 및 샘플링 효율성을 크게 향상한 모델입니다. Text, Image 등의 조건(Conditioning)을 기반으로, Task별 별도의 아키텍처 없이 광범위한 이미지를 빠르게 생성합니다.
Stable Diffusion은 ControlNet이라는 보조 네트워크와 함께할 때 더욱 강력합니다. Text만으로는 우리가 원하는 대로 이미지를 생성하기 어렵습니다. ControlNet은 Model들을 특정 Input Condition(Canny, Sketch, Depth 정보 등)으로 다룰 수 있게 도와줍니다. 이는 결국, AI라는 기술이 이미지/그림 등의 2D 그래픽을 자유자재로 생성할 수 있는 단계에 이르렀다는 걸 보여줍니다.
c. 이미지 생성 AI 너머의 새로운 가능성
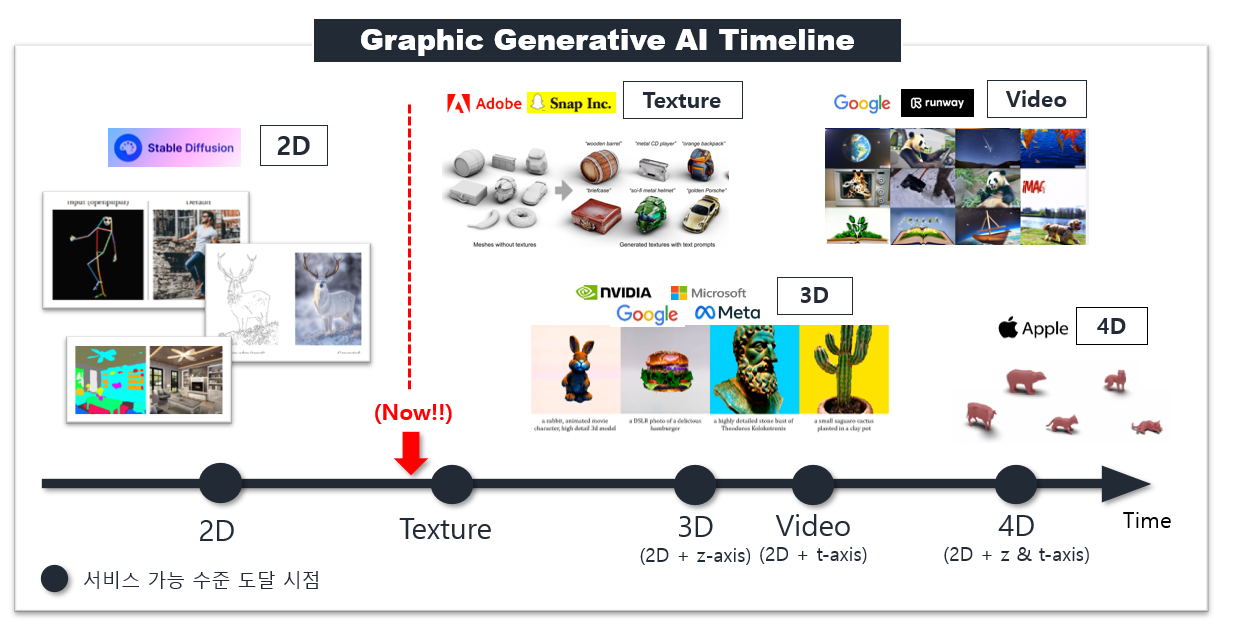
<이미지 3. Graphic Generative AI Timeline>
역사적으로 생성 모델은 점점 더 복잡한 데이터(손 글씨 → 얼굴 → 여러 image → 2D 전체)들의 분포를 성공적으로 학습하도록 진화해 왔습니다. 이미지(2D) 생성 모델은 Stable Diffusion을 기점으로 서비스 가능 수준의 진보를 이루어 냈죠. 연구자들은 이미 2D 그 너머를 향해 달려가고 있습니다. 컴퓨터상에서 보이는 모든 시각적 표현을 그래픽(Graphic)이라고 할 때, 그래픽 생성 AI는 이제 Texture, 3D, Video, 4D와 같은 그래픽들을 생성하고자 진화하고 있습니다.
저희는 Texture, 3D/Video, 4D 순으로 서비스 가능 시기가 도래할 것으로 예측하는데요. 이러한 연구의 흐름에서 3D 게임 에셋 제작 파이프라인에 가장 큰 도움이 될 수 있는 Texture와 3D 생성 기술 연구를 시도해 보게 되었습니다. 본격적으로 Texture와 3D 생성 기술을 연구하기에 앞서 저희는 실무에서 어떤 식으로 작업이 진행되는지, 현재는 어떤 문제들이 존재하는지 구체적으로 파악할 필요가 있었고, 크게 3가지의 문제를 정의할 수 있었습니다.
2. 3D 에셋 제작 과정과 기존의 문제점
3D 에셋 제작 과정
게임 속에서 만날 수 있는 3D 에셋의 제작 과정은 보통 1. 모델링(Modeling), 2. 텍스쳐링(Texturing), 3. 리깅(Rigging) 및 애니메이션(Animation)의 순서로 이루어지는데요, 각 과정은 간단하게 다음과 같이 설명드릴 수 있습니다.
- 모델링(Modeling) 과정: 3D 에셋의 기본 형태를 만듭니다. 이를 위해 다양한 다각형을 조합하여 모델의 기하학적 구조를 정의하고 조절합니다. 이러한 3D 에셋의 기본형태를 Mesh라고 부릅니다.
- 텍스쳐링(Texturing) 과정: 3D 에셋의 외관을 디자인하는 과정으로, 색상, 질감, 이미지 등을 사용하여 모델에 디자인을 입힙니다.
- 리깅(Rigging) 및 애니메이션(Animation) 과정: 3D 에셋에 움직임을 부여하는 과정으로, 리깅은 뼈대와 관절을 설정하는 과정, 애니메이션은 리깅된 3D 에셋을 실제로 움직여 다양한 움직임을 연출하는 과정입니다.
저희 프로젝트는 1.모델링과 2.텍스쳐링, 즉 3D 에셋에 움직임을 부여하기 직전까지의 단계에 관해 관심이 있습니다. 3D 에셋의 자연스러운 움직임을 만들기 위한 이후 작업들에 관해서는 Graphics AI Lab의 다른 프로젝트들에서 훌륭한 연구들이 진행되고 있으며, 블로그에서도 확인해 보실 수 있으니 참고해 주세요!
기존 3D 에셋 제작 과정의 문제점

<이미지 4. 3D 모델링 과정>
<출처: https://www.youtube.com/watch?app=desktop&v=FlgLxSLsYWQ&t=256s>
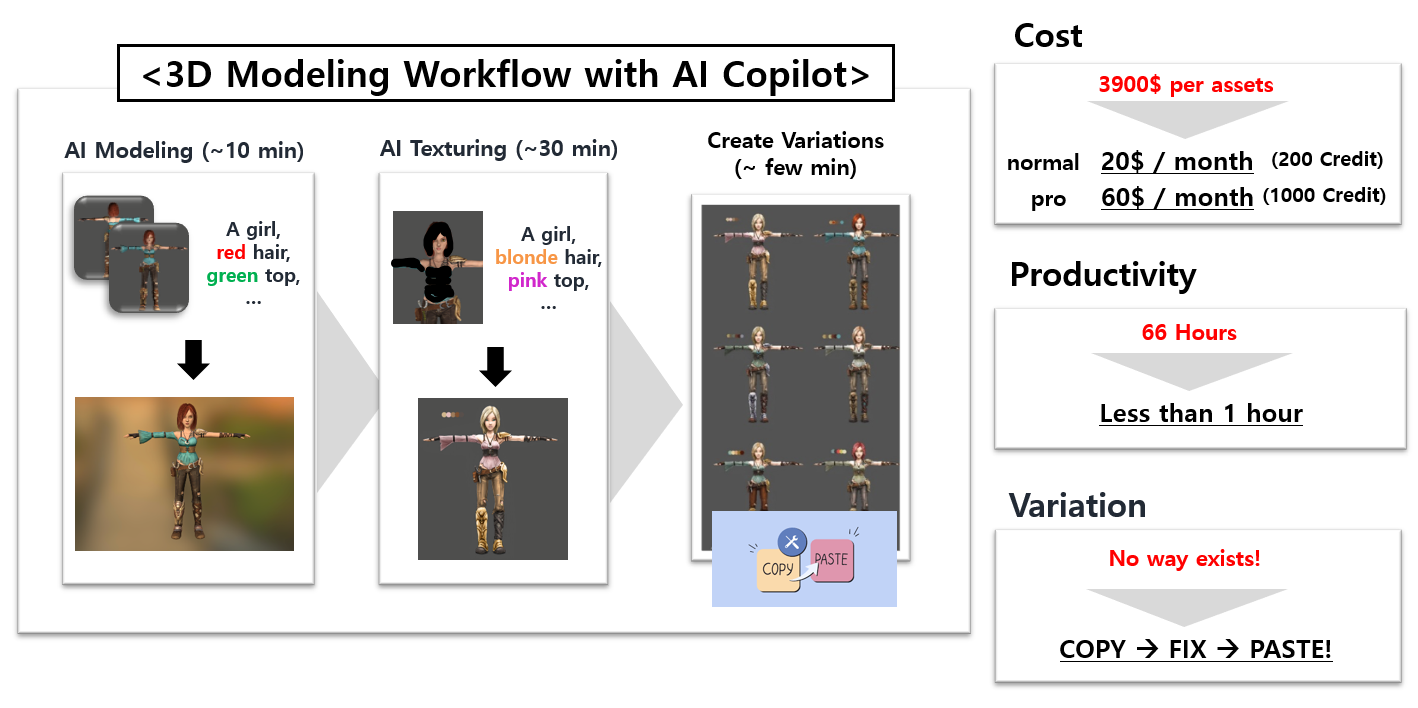
저희가 관심 있는 모델링(Modeling)과정과 텍스쳐링(Texturing)과정을 수행해 주시는 아티스트분들을 3D 모델러(Modeler)라고 부르는데요, 3D 모델러 분께서 위와 같은 3D 건물 에셋을 제작하려면 일반적으로 Modeling→ Texturing→Revision(검수) 과정을 거치게 됩니다.
기존의 3D 모델링 소프트웨어를 통해 이 과정을 수행하게 되면 평균적으로 66시간이 걸리며, 외주 제작 시 비용은 $3900 정도가 소요된다고 합니다. 이렇게 제작된 에셋을 변형하는 것 역시 쉽지 않은데요, 같은 과정의 상당 부분이 반복되어야 하기 때문입니다. 이에 따라 저희는 소프트웨어만을 활용한 3D 에셋 제작 과정에 대해 다음과 같은 3가지 문제 가설을 정의할 수 있었습니다.

<이미지 5. 기존 3D 에셋 제작 과정의 문제점 가설>
AI를 활용한 솔루션
<이미지 6. AI를 활용한 솔루션>
<이미지 내 캐릭터 출처: https://jdwyprice.artstation.com/projects/8LERE>
단순하게, 이런 솔루션을 상상해 보았습니다. 3D 모델러 분들의 작업에 있어, AI가 모델링 과정이나 텍스쳐링 과정을 보조해 줄 수 있다면 어떨지 하고 말이죠. 물론 완벽하지는 않기에 직접 후처리 하는 데에 시간이 소요되겠지만, 적어도 초반 작업 시간을 줄여주거나 다른 스타일을 쉽게 생성하는 형태의 도움을 줄 수 있을 것으로 판단했습니다. 비용도 많이 낮출 수 있을 것이고요. 무엇보다 AI 기반 Workflow의 경우 Text나 생성 Config 등만 잘 기억하고 있다면, 다른 사람들의 작업물을 활용하는 일이 정말 쉬워질 것이라는 점이 가장 기대되는 점이었습니다.
문제는 기술이었습니다. 연구를 시작했던 올해 3월, 2D 생성 모델은 꽤나 쓸만한 퀄리티가 나왔기 때문에 실무에서도 종종 사용된다는 소식이 들려왔습니다. 그러나 당시의 Texture나 3D 생성 모델의 경우에는 실무에서 쓸 수 있을 만한 퀄리티와는 정말 많이 동떨어져 있었습니다. 그 때문에 하나씩 직접 연구해 나아가는 수밖에 없었고, 가장 근시일 내에 서비스 가능 시점이 올 것으로 판단한 Texture 생성 AI부터 연구하기 시작했습니다.
III. How? - Texture Copilot의 R&D 과정
1. Stable Diffusion을 활용한 3D Texturing 연구
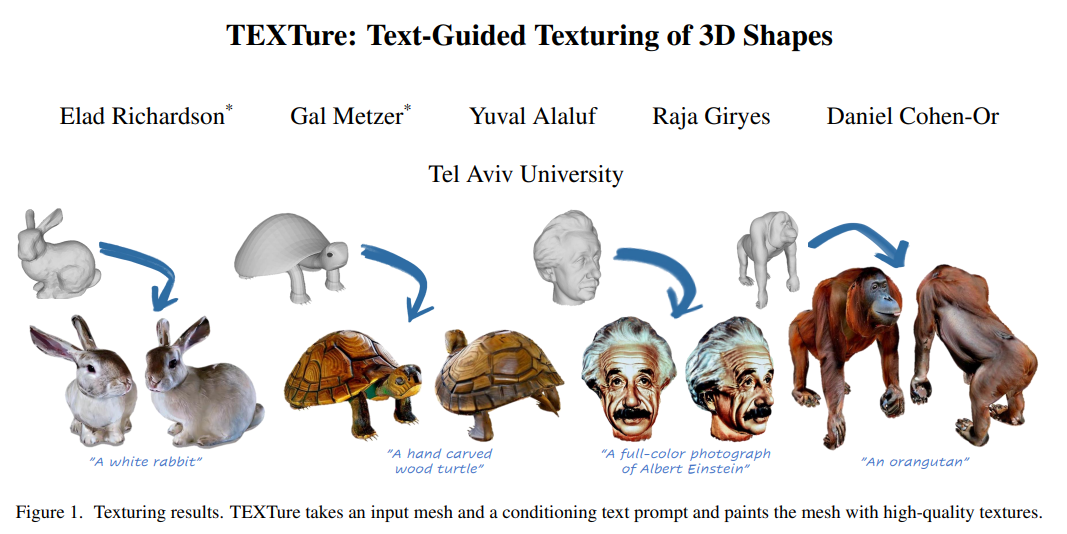
<이미지 7. TEXTure Paper>
앞서도 이야기했듯, 최신 생성 연구의 흐름은 Stable Diffusion과 같은 이미지 생성 모델을 활용하여 이루어지는 경우가 많습니다. 2023년 2월에는 Stable-Diffusion-2-Depth을 활용하여 3D Texturing을 수행하는 TEXTure (Text-Guided Texturing of 3D Shapes) 연구가 발표되었습니다. 저희의 3D Texturing 연구는 바로 이 TEXTure 모델로부터 시작되었습니다.
a. TEXTure: Text-Guided Texturing of 3D Shapes

<이미지 8. Painting 알고리즘 및 자체 데이터 생성 결과>
기존 연구(Stable Diffusion 같은 이미지 생성 모델을 활용하여 3D Texturing을 수행하려는 연구)의 문제는, 하나의 View(ex. 정면)만 담긴 Texture에 대해서는 그럴듯하게 생성하는 데 반해, 모든 View(ex. 정면, 옆면, 뒷면)가 담긴 Texture를 생성하고자 할 때는, 각각의 View에 대한 일관성이 유지되지 않는 문제(Multi-View Consistency 문제)가 있다는 것입니다. 문제 해결을 위해 본 논문에서는 이전 단계의 생성 결과를 다른 View에서 렌더링하고, 3부분으로 파티셔닝한 trimap(generate, refine, keep)을 정의한 뒤, trimap representation을 사용하는 새로운 diffusion sampling process를 제안합니다. 쉽게 설명하면, Stable Diffusion을 일종의 카메라로 생각하고 돌려가며 In-Painting을 수행하는 방식입니다. 아래의 그림을 좌측의 도식을 보시면 쉽게 이해하실 수 있습니다.
논문의 결과가 어느 정도 괜찮아 보여서, Graphics AI Lab 내에서 보유한 얼굴 Mesh로도 생성해 보았는데요, 모델을 그대로 쓰기에는 연구 조직에서 보기에도 퀄리티가 높지 않아 보였습니다. 1. 입력으로 주는 Mesh를 정확하게 인식하지 못한다는 점, Loss기반의 Projection 방식을 사용하기 때문에 2. 높은 해상도의 Texture를 생성할 수 없다는 점, 마지막으로 보이는 View에 대해서만 생성이 가능하기 때문에 3. Texture의 마감 처리가 부족한 것 등을 낮은 퀄리티의 주요한 원인으로 정의했고 자체 연구를 시작했습니다. 우선 문제를 좁혀, Lab 내에서 얼굴 애니메이션 연구를 위해 빈번하게 활용되는 얼굴 텍스쳐를 보다 높은 퀄리티로 생성해 보기로 했습니다.
b. Meticulous TEXTure 연구
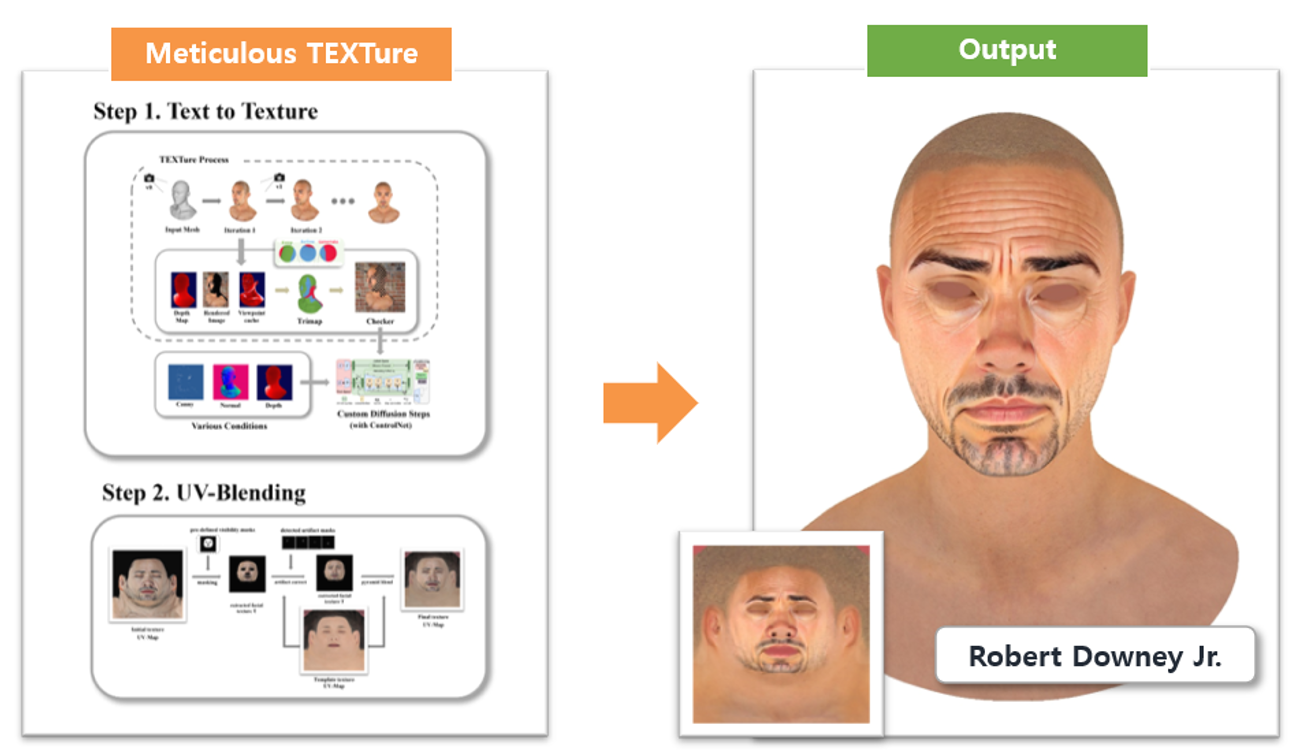
<이미지 9. Meticulous TEXTure 모델과 생성 결과>
i. Multi-ControlNet 도입
첫 번째 문제인 입력으로 주는 Mesh를 정확하게 인식하지 못하는 이유는 Stable-Diffusion-2-Depth 모델이 Depth(깊이) 정보만 사용할 뿐만 아니라 Depth 인식 능력이 떨어지기 때문입니다. 이를 개선하기 위해 저희는 Stable-Diffusion-2-Depth 모델을 일반 Stable Diffusion Model + Multi-ControlNet 형태로 변경했습니다. 이를 통해 Ground-Truth Mesh를 정확하게 인식시킬 수 있는 Canny, Normal, Depth 등의 정보를 인식능력이 뛰어난 ControlNet을 이용하여 Text와 함께 모델에 Conditioning 시킬 수 있었습니다.
ii. 자체 Projection Method 구현
두 번째 문제인 Texture를 고해상도로 생성할 수 없다는 점은 Texture를 하나의 Tensor로 보고 Loss Function을 통해 Image를 UV Space 상으로 Project(투영)하는 Projection Method에서 비롯된 문제였습니다. Texture를 학습을 통해 optimization하는 과정이 오래 걸리고 많은 artifact가 생기는 문제가 있었습니다. 이를 해결하기 위해 저희는 이미지를 Mesh의 UV Mapping 정보를 바탕으로 Image를 Texture에 Mapping하는 자체 Projection Method를 구현하여 적용해 보았습니다. Loss 방식에 비해 속도가 훨씬 빠르고 artifact 역시 전혀 발생하지 않음을 확인했습니다.
iii. UV-Blending 알고리즘
세 번째 문제인 Texture 마감 처리 부족이란 Stable Diffusion을 통해 반복적으로 이미지를 붙여나가는 과정에서 이미지 간 연결부위가 깔끔하지 않은 문제입니다. 이는 이미지를 붙여나가는 TEXTure 알고리즘의 근본적인 한계이기도 합니다. 문제를 얼굴 텍스쳐로 한정할 경우 UV Mapping의 형태를 고정해 두고 Template Texture와의 Blending 방법을 통해 마감처리를 수행할 수 있었습니다.
c. 서비스로 나아가기 위한 추가적인 개선들
물론 얼굴 Texture를 잘 생성할 수 있으면 좋지만, 실무에서 얼굴 Texture는 고퀄리티의 몇 장만을 필요로 하는 경우가 많았기 때문에 서비스로의 발전가능성이 작다고 판단했습니다. AI가 장점을 가질 수 있는 분야는 사물이나 캐릭터, 지형 등 다양한 형태에 대해 높은 퀄리티로 생성할 수 있는 방식일 것으로 판단했고, 서비스를 위한 추가적인 개선을 시도하게 되었습니다.
Meticulous TEXTure 연구에 존재했던 한계들은 다음과 같습니다. 1. 얼굴 Texture만 잘 생성한다는 점, 얼굴 Mesh뿐만이 아닌 2. 다양한 Mesh에 대한 범용적인 마감처리 로직이 필요하다는 점, 기존의 Stable Diffusion과 비교해, 3. Text에 대한 이해도가 낮다는 점 등이 있었는데요, 이러한 한계들은 현재 개선을 완료했습니다. 다만, 4. Multi-View Consistency 문제, 5. PBR (Physical Based Rendering) 관련 문제 등은 여전히 개선 방안을 연구 중입니다.
i. 다양한 Object, 다양한 기능으로 확장

<이미지 10. 다양한 Object에 대한 생성 결과>
저희는 얼굴 한정으로만 동작하는 UV-Blending 알고리즘을 제거하고, 각 사물에 맞는 적절한 Prompt와 카메라 각도 등을 선택할 수 있도록 설정하여 Object의 형태로부터 자유로우면서도, 일치도가 높은 Texture 생성이 가능하도록 개선했습니다. 더불어 Stable Diffusion 부분을 SD Web UI API로 변경하면서 Web UI 커뮤니티의 다양한 방법론들을 활용할 수 있었는데요, LoRA(Low-Rank Adaptation of Large Language Models)나 Textual Inversion 등의 기법들은 여러 대상에 대한 Texture를 생성하는 데 큰 도움이 되었습니다.
ii. Texture Extrapolation 및 Normal Map 기반 마감처리 로직 도입
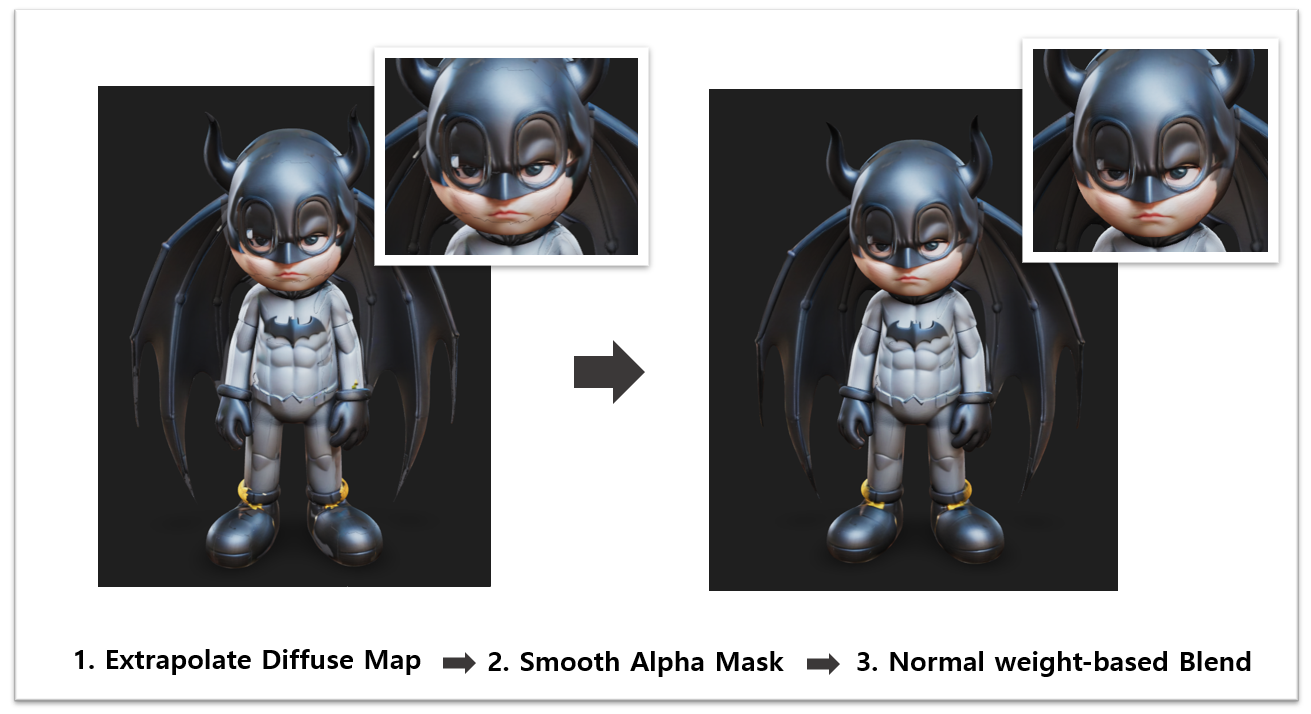
<이미지 11. Extrapolation 기반 마감처리 결과>
UV-Blending을 제거하면서 마감 처리에 대한 문제가 다시 발생했습니다. Graphics AI Lab 내 피드백을 통해, Projection된 Texture 결과에 대한 Extrapolation, Mesh의 Normal Map을 활용한 새로운 Blending 로직을 파이프라인에 도입했고, 더 자연스럽고 빈틈없는 Texturing이 가능해졌습니다.
iii. SDXL 도입을 통한 Text 이해도 증가

<이미지 12. SDXL1.0 도입결과>
Text의 이해도가 낮아진 건 Diffusion Model에 Mesh에 대한 정보가 강하게 Conditioning 되면서 발생한 문제라고 판단했습니다. 이 문제를 해결하기 위해서는 Conditioning 받아들이는 UNet 구조나 Text Encoder의 개선이 필요하겠다고 생각했는데요, 마침 SDXL1.0(Stable Diffusion XL) 버전이 공개되어 파이프라인에 적용해 보았습니다.
위의 사진 중 2번이 그 예시인데요, 사실 wood box가 colorful하거나 neon 조명이 들어가 있는 장면이 상상이 잘 안됨에도 불구하고 Text를 잘 이해하여 Texture가 생성되는 것을 확인할 수 있었습니다. SDXL 에서는 이미지 생성 해상도가 1K(1024)로 올라갔기 때문에 Texture 해상도 역시 더 올릴 수 있었습니다.
iv. Multi-View Consistency 문제
연구하다 보니 Multi-View Consistency 문제는 Texture 생성 과정에서 기술적으로 가장 도전적인 문제임을 알게 되었습니다. 특정 대상만을 생성하는 LoRA나 여러 각도를 한 번에 생성하는 LoRA를 활용해 보기도 하고, SDXL의 Revision( 이미지를 다른 비슷한 이미지로 변형하는 기능)을 활용해 정면의 이미지를 다른 이미지로 변형해 보기도 했으나 Multi-View Consistency 문제를 완벽하게 해결할 수는 없었습니다.

<이미지 13. MVDream Architecture>
그러던 23년 8월, “MVDream: Multi-View Diffusion for 3D Generation” 논문에서 Multi-View Consistency 문제 해결에 대한 실마리를 제시했습니다. MVDream의 Diffusion Model은 (1) 2D Self-Attention Layer를 모든 다른 뷰에 대해 연결하는 방식으로 변경하여 3D Self-Attention Layer로써 활용하는 방식, (2) Multi-View 이미지를 통한 학습 (3) Camera 임베딩의 사용, (4) Loss Function 수정 등을 통해 근본적으로 Multi-View Consistent한 이미지 생성을 가능하게 합니다.
또한 Multi-View Diffusion Model은 3D 생성의 퀄리티를 높였습니다. 기존 3D 생성 연구의 흐름은 Stable Diffusion과 같은 이미지 생성 모델을 일종의 Loss로 활용해 NeRF(Neural Radiance Fields)를 학습시키는 SDS(Score Distillation Sampling)방법론을 활용했습니다. MVDream 논문은 Multi-View Diffusion이 SDS에 적용될 경우 2D Diffusion보다 더 높은 퀄리티의 3D를 생성함을 증명했습니다.
저희는 이러한 Multi-View Consistency 문제에 대한 연구들이 AI를 통한 텍스쳐링 방식의 문제를 해결할 뿐만이 아니라, AI를 활용한 모델링까지 접근해 볼 수 있게 만들어 줄 것으로 보고 있습니다. 이 글을 작성하는 시점(23년 11월)에는 MVDream, Wonder3D, Zero123++, DreamCraft3D와 같은 괜찮은 성능의 3D 생성 연구이 본격적으로 공개되고 있기 때문에, 이러한 연구들을 활용하여 Multi-View Consistency 문제를 해결하고자 연구 중입니다.
v. PBR(Physically Based Rendering) 관련 문제
PBR은 “Physically Based Rendering”의 약어로, 실제 세계에서 빛이 물체와 상호 작용하는 방식을 모델링하여 더 현실적인 시각적 결과물을 얻을 수 있게 도와주는 렌더링 방식입니다. PBR은 3D 모델의 외관을 사실적으로 표현하기 위해 다양한 텍스처 맵을 활용합니다. 이러한 텍스처 맵에는 Color만을 표현하는 Diffuse Map, 빛의 반사를 나타내는 Specular Map, 그리고 물체의 표면 세부 정보를 포함하는 Normal Map 등이 포함됩니다.
Stable Diffusion이 본질적으로 모든 정보를 포함한 이미지를 생성하기 때문에 AI를 활용한 3D Texturing 방식은 각각의 정보(Color, Reflect, Normal, Light 등)를 나누어 관리하는 3D Pipeline의 PBR 방식에 바로 활용되기가 어렵습니다. 이 문제의 경우, 우선은 Diffuse Map 생성에 한정해 Prompt나 LoRA 등을 통해 Light, Reflect 등을 많이 낮추는 시도를 진행 중이며, Specular와 Normal 등 다른 Map들의 경우 잘 생성된 Diffuse Map을 기반으로 Estimation 하는 방식을 연구 중입니다.
2. Texture Copilot 서비스 개발 및 향후 계획
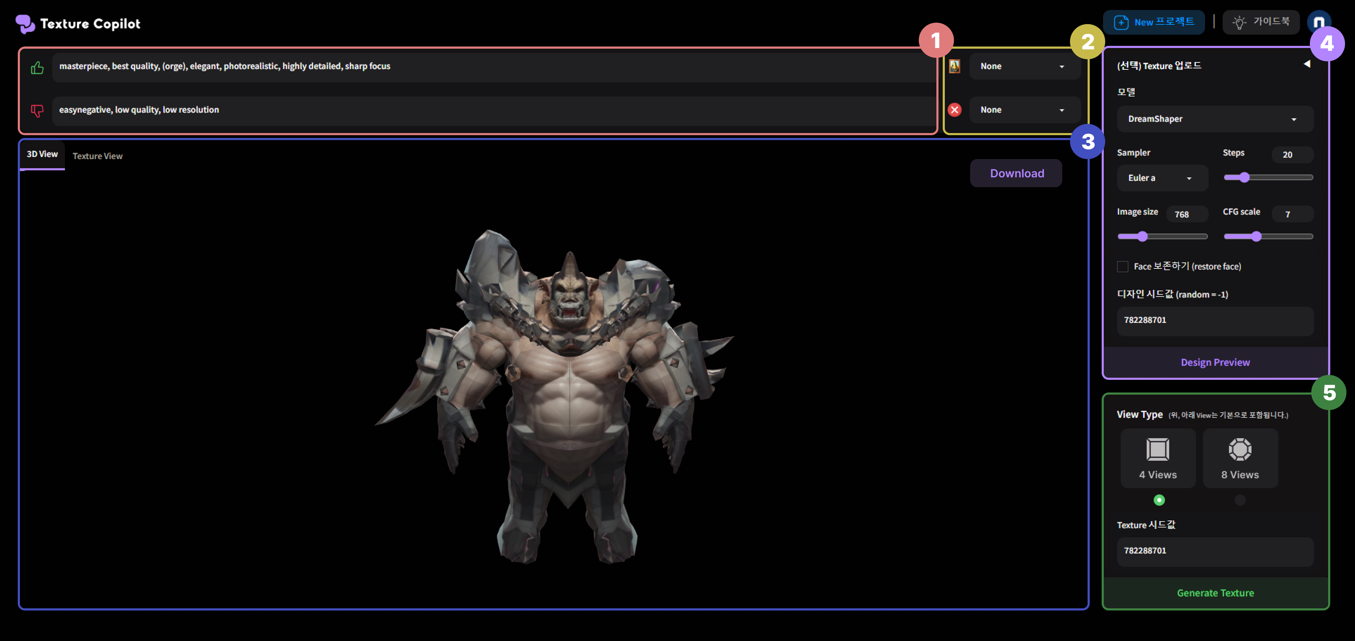
<이미지 14. Texture Copilot Alpha 버전>
Meticulous TEXTure 연구가 끝날 무렵, AI 모델을 실무에서 사용해 볼 수 있도록 서비스 형태를 고민하게 되었습니다. 1K의 경우 5분 이내, 2K의 경우 10분 이내로 생성할 수 있도록, 많은 부분에서 최적화를 진행했습니다. UI/UX의 경우 가운데에 3D 모델과 Interaction 할 수 있는 3D Viewport를 위치시켜 이전 버전보다 직관적으로 사용 방식을 이해할 수 있도록 개선했습니다. 나머지 Text 입력 창이나, Config를 설정하는 창 등은 생성 모델을 활용하시는 분들이 익숙하실 만한 Stable Diffusion Web UI의 레이아웃을 참고했습니다.
이후 사내 아티스트분들을 대상으로 알파테스트를 진행할 수 있었는데요, 테스터분들께서 자세하게 피드백을 해주신 덕분에 더 구체적인 개선점들을 끌어낼 수 있었습니다. 이 중 단기간 내에 개선이 가능한 사항들을 빠르게 업데이트하여 12월 중 2차 테스트를 진행할 예정입니다.
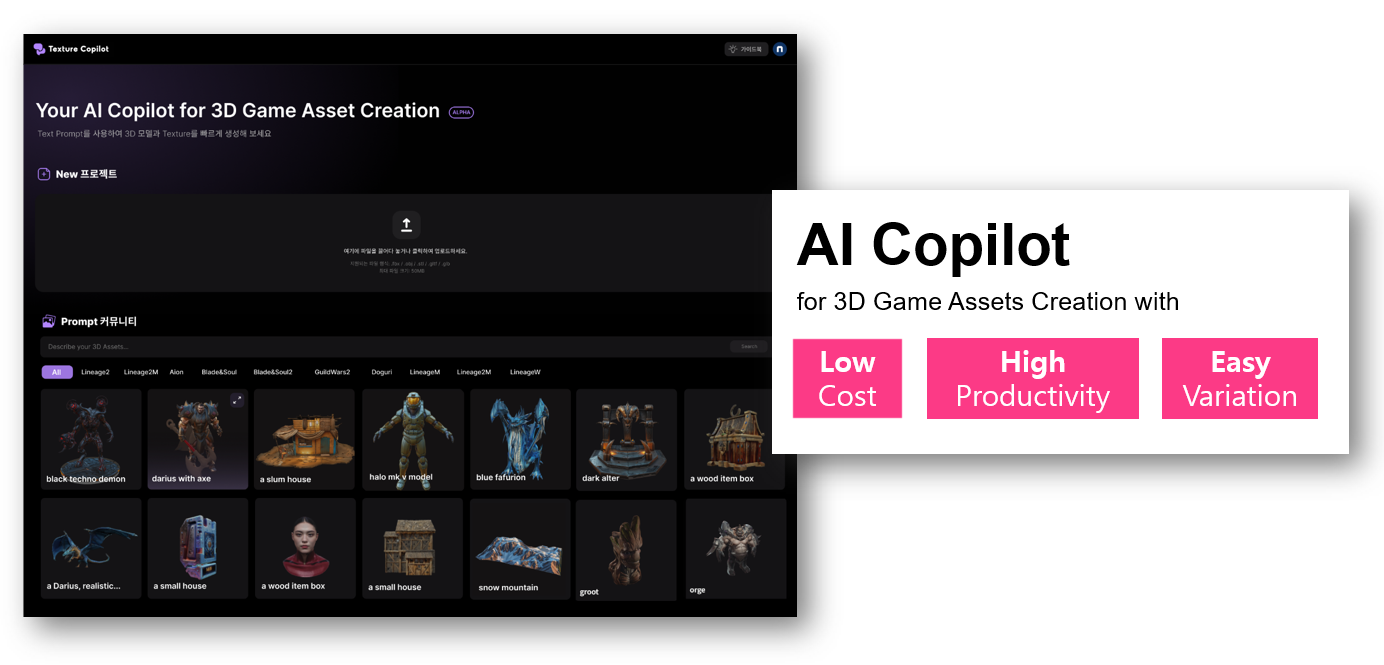
<이미지 15. 3D 게임 에셋 제작을 돕는 AI Copilot>
아직까지 Texture Copilot은 니즈, 사용성 측면에서 검증해야 할 것이 많이 남아있습니다. 실제 3D 에셋 제작 실무에서 적극적으로 활용될 수 있도록 향후 여러 번의 테스트를 통해 고도화 해나갈 예정입니다. 만일 이 서비스에 대한 수요가 검증된다면, 궁극적으로는 3D 게임 에셋 제작을 돕는 AI Copilot 서비스로 나아가보고자 합니다. 이를 위해서는 3D 에셋의 디자인을 담당하는 텍스쳐링뿐 아니라, 기본 형태를 만드는 모델링 단계도 도울 수 있어야 할 것이며, 이를 위해 3D 생성에 대한 연구 역시 꾸준히 병행하며 나아가고 있습니다.
저희가 연구하고 개발해 나갈 AI라는 새로운 붓이 언젠가 아티스트들에게는 더욱 생산적으로 창의성을 발휘할 수 있는 도구로, 플레이어에게는 직접 자신만의 캐릭터나 아이템을 만들 수 있는 도구로 활용될 수 있기를 바라며 이번 글은 여기서 마무리하도록 하겠습니다. 긴 글 읽어주셔서 정말 감사드립니다!
Reference
- NCDP 2023 - AI라는 새로운 붓
(https://www.youtube.com/watch?v=NOJsWyz4n5M) - The Next Leap: How A.I. will change the 3D industry - Andrew Price
(https://www.youtube.com/watch?app=desktop&v=FlgLxSLsYWQ&t=256s) - Deep generative models (part 1)
(https://sailinglab.github.io/pgm-spring-2019/notes/lecture-17/) - Generative Adversarial Networks Lecture
(https://icarus.csd.auth.gr/generative-adversarial-networks-lecture/) - GAN (Generative Adversarial Networks)
(https://arxiv.org/abs/1406.2661) - StyleGAN (A Style-Based Generator Architecture for Generative Adversarial Networks)
(https://arxiv.org/abs/1812.04948) - Deep Unsupervised Learning using Nonequilibrium Thermodynamics
(https://arxiv.org/abs/1503.03585) - What are Diffusion Models?
(https://lilianweng.github.io/posts/2021-07-11-diffusion-models/) - Diffusion Model 시리즈
(https://jang-inspiration.com/diffusion-models) - Stable Diffusion (High-Resolution Image Synthesis with Latent Diffusion Models)
(https://arxiv.org/abs/2112.10752) - ControlNet (Adding Conditional Control to Text-to-Image Diffusion Models)
(https://arxiv.org/abs/2302.05543) - TEXTure (Text-Guided Texturing of 3D Shapes)
(https://arxiv.org/abs/2302.01721) - Text2Tex (Text-driven Texture Synthesis via Diffusion Models)
(https://daveredrum.github.io/Text2Tex/) - SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
(https://arxiv.org/abs/2307.01952) - MVDream: Multi-View Diffusion for 3D Generation
(https://arxiv.org/abs/2308.16512) - Wonder3d: Single Image to 3D using Cross-Domain Diffusion
(https://www.xxlong.site/Wonder3D/) - Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
(https://arxiv.org/abs/2310.15110) - DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
(https://mrtornado24.github.io/DreamCraft3D/) - 3D-GPT: Procedural 3D MODELING WITH LARGE LANGUAGE MODELS
(https://chuny1.github.io/3DGPT/3dgpt.html)
