
- 들어가며
- WMT23 Terminology Shared Task
- 데이터 처리
- 모델
- TSSNMT (Terminology Self-selection Neural Machine Translation)
- ForceGen Transformer (ForceGen-T)
- 실험 및 분석
- WORKSHOP 결과
- 마치며
- Reference
들어가며
이번 글에서는 NCSOFT가 참여한 WMT(Workshop on Machine translation) 2023에 대한 내용을 소개하려고 합니다. WMT는 자연어 처리 분야의 세계적인 학술 대회인 EMNLP에서 열리는 Workshop 중 하나로, 최신 기계 번역에 대한 연구를 중심으로 경진대회를 개최합니다. 2023년 WMT에서는 13가지의 경진 대회(Shared Task)가 진행되었습니다. 이 중에서 NCSOFT는 Translation Tasks의 Terminology Shared Task에 참가하기로 했습니다. 이 대회는 용어 번역 쌍이 주어졌을 때, 기계 번역 모델이 이를 얼마나 잘 활용하는지를 겨루는 대회로, 게임, 금융, 의료, 로봇 등 산업용 번역 분야에서 중요한 역할을 합니다. NCSOFT는 이미 리니지2M, 리니지W 및 사내 업무 시스템에 기계 번역 모델을 활용하고 있으며, 게임 도메인의 전문 용어 번역을 위해 특화된 모델을 사용하고 있습니다.
이번 WMT 2023 Terminology Shared Task에 참가함으로써, 우리는 VARCO MT를 용어 번역에 더욱 고도화하면서 VARCO MT가 세계적인 대회에서 어디까지 도달할 수 있는지 확인하고 싶었습니다. WMT 2023에서의 Terminology shared task에 대한 세부 내용을 살펴보고 과제를 해결하기 위해 어떻게 접근했고 어떤 성과를 거두었는지에 대한 내용들을 소개하겠습니다.
WMT23 Terminology Shared Task
Terminology Shared Task가 뭐죠?
Terminology Shared Task는 용어 번역 쌍이 존재 할 때 기계 번역 모델이 이를 얼마나 잘 활용하는지를 겨루는 경진대회입니다.
| 영어 원문 | 용어 번역 쌍 | 독일어 번역 결과 |
|---|---|---|
| The report is in accordance with ROA. (이 보고서는 ROA에 따른 것이다.) | Der Bericht steht im Einklang mit ROA. | |
| ROA → FOG | Der Bericht steht im Einklang mit FOG. | |
| is in accordance → entspricht | Der Bericht entspricht ROA. |
표 1의 예시와 같이 원문을 번역할 때, 주어진 용어 번역 쌍을 활용하여 번역 결과를 생성하는 것이 이번 대회의 주요 목표입니다. 이 과정에서 기계 번역 모델이 주어진 용어 쌍을 얼마나 효과적으로 반영하는지가 평가의 핵심입니다.
이번 대회에서는 다음과 같이 3가지 경우의 번역 결과를 평가합니다.
- 용어 번역 쌍이 주어지지 않았을 때의 일반적인 번역 성능 (Mode 1)
- 전문 용어로 구성된 명사 및 명사 구가 용어 번역 쌍으로 주어졌을 때의 번역 성능 (Mode 2)
- 임의의 단어 및 구가 용어 번역 쌍으로 주어졌을 때의 번역 성능 (Mode 3)
동일한 원문에 대해 각각 다른 용어 번역 쌍이 주어진 상황에서, 각 Mode에서의 번역 결과를 평가하여 기계 번역 모델이 용어 번역 쌍을 얼마나 효과적으로 활용하는지를 평가합니다. 이번 대회에서는 WMT 2021 Terminology Shared Task와는 달리, Mode 3가 새롭게 추가되어 다양한 상황에서의 모델 성능을 더 정확하게 평가합니다.
WMT 2021 Terminology Shared Task
이번 WMT 2023 Terminology Shared Task에 참가하기 전에, 2021년에 개최된 WMT 2021 Terminology Shared Task에서서 우승했던 팀들의 논문을 살펴보았습니다. 여러 팀들의 접근 방식을 분석한 결과, 다음과 같은 주요 전략들이 돋보였습니다.
- 데이터 필터링 및 품질 개선: 휴리스틱한 방법을 활용하여 공개된 데이터를 정제하고, 저품질의 병렬쌍을 제거하는 등의 데이터 전처리 작업을 수행했습니다.
- Transformer 모델의 활용: 대부분이 Transformer encoder-decoder 구조의 모델을 사용했습니다. 이는 기계 번역에서 주로 사용되는 모델 구조 중 하나입니다.
- Back Translation 데이터 활용: 기계 번역 모델의 학습 데이터의 양을 늘리는 방법 중 하나로, 주어진 데이터의 Source와 Target을 서로 바꿔(중국어 → 영어를 영어 → 중국어로) BT 모델을 학습하고 기존 Target을 BT 모델로 번역한 BT Source 데이터를 추가적인 학습데이터로 사용합니다.
- 입력 문장 변형: 아래 표 2.와 같이 입력 문장에 태그와 용어 번역쌍을 섞어 모델에 입력하는 구조를 채택한 것이 일반적이었습니다.
| 입력 예시 | |
|---|---|
| 일반적인 입력 문장 | The report is in accordance with ROA. |
| 변형된 입력 문장 | The report <S> [MASK] [MASK] [MASK] <C> entspricht </C> with ROA. |
위 표 2는 EN → ZH 우승팀 TermMind(Alibaba)의 입력 형식을 공식 예시에 적용한 것으로 용어 번역 쌍에 존재하는 Source 단어를 [MASK]로 치환(is in accordance → <S> [MASK] [MASK] [MASK])하고 Target 단어를 추가(<C> entspricht </C>)합니다. 이러한 방법은 일반적인 입력 문장 대신 번역시 참고해야는 단어를 입력에 직접 넣어 주면서 모델이 용어를 활용 수 있도록 학습하게 됩니다.
공개 데이터 및 제약 조건
WMT23 Terminology Shared Task는 다음과 같이 3가지의 단방향 언어쌍으로 진행되었습니다.
- zh-en: 중국어 → 영어
- en-cs: 영어 → 체코어
- de-en: 독일어 → 영어
데이터는 학습, 검증, 평가 데이터가 공개되었습니다. 경진대회 시작부터 평가 데이터가 공개되었고 참가자들의 의문이 지속되어 결국 마감 직전에 Blind 데이터를 다시 공개했습니다.
학습 데이터는 별도로 제공되지 않았고, General MT Shared Task의 학습 데이터를 사용하고 General Task의 제약 조건을 따르라는 안내가 있었습니다. 특이하게도, 용어 번역 쌍은 따로 제공되지 않았고 주최측에 문의했더니 직접 구축하라는 답변을 받았습니다. 😓
공개 데이터
WMT23 General Task에서 공개한 ZH-EN 병렬 데이터의 종류와 크기는 다음과 같습니다.
| 데이터 명 | 데이터 크기 | 설명 |
|---|---|---|
| Back-translated news | 2,048MB | The University of Edinburgh에서 만든 Back Translation 데이터 |
| CCMT Corpus | 1,694MB | China Workshop on Machine Translation (CWMT)에서 공개한 News 도메인 번역 데이터 |
| News Commentary v18.1 | 35MB | CASMACAT project (2012-2014)에서 공개한 번역 데이터 |
| ParaCrawl v9 | 1,250MB | 유럽어를 중심으로 만들어진 웹 크롤링 번역 데이터 |
| UN Parallel Corpus v1.0 | 1,324MB | 유엔의 공식 기록과 기타 의회 문서의 번역 데이터 |
| WikiMatrix | 328MB | facebook의 LASER를 이용해 Wikipidia 문서의 번역 쌍을 자동으로 구축한 병렬 데이터 |
| Total | 6,679MB |
병렬 데이터의 전체 크기는 6.5GB로 약 7,400만 문장 쌍으로 구성되어 있었습니다. 병렬 데이터 뿐만 아니라 단일 언어 말뭉치도 영어 2.22TB, 중국어 1.5TB가 공개되었지만 모든 데이터의 품질을 검증하기엔 시간이 부족하다고 판단했고 병렬 데이터만 사용하기로 결정했습니다.
| 데이터 종류 | 데이터 수량 | 설명 |
|---|---|---|
| 검증 | 99 문장 | 학습 말뭉치와 함께 공개된 검증 데이터 |
| 평가 | 7,942 문장 | 학습 말뭉치와 함께 공개된 평가 데이터 |
| Blind | 7,896 문장 | 대회 마감 일주일 전에 공개된 평가 데이터 |
학습 데이터와 다르게 검증, 평가, Blind 데이터는 각 Mode별 용어 병렬 쌍도 함께 공개되었습니다.
제약 조건
- Unconstrained Track과 Constrained Track의 구분: 주어진 데이터와 언급한 사전 학습 모델 이외의 자원을 사용할 경우, 해당 팀은 Unconstrained Track으로 분류되어 별도로 평가됩니다.
- Constrained Track에서의 학습 데이터: Constrained Track에서는 올해에 공개된 학습 데이터만을 사용할 수 있습니다.
- 허용된 사전 학습 모델: 대회에서는 사전 학습 모델로 이미 공개된 특정 모델들만을 사용할 수 있도록 허용하고 있습니다: mBART, BERT, RoBERTa, XLM-RoBERTa, sBERT, LaBSE
- 기본 언어학 도구 사용 허용: 기본 언어학 도구들(Taggers, Parsers, Morphology Analyzers 등)은 사용이 허용되어 있습니다.
데이터 처리
데이터 정제
공개된 데이터 중에서 큰 비중을 차지하는 Back Translated Data 및 Crawling Data의 신뢰성을 높이기 위해 데이터 정제를 진행했습니다. 휴리스틱한 방법으로 1차적으로 정제 후 딥러닝 모델 기반 방법으로 2차 정제를 진행했습니다.
1차 정제: 휴리스틱
아래에 기술된 필터링 조건이 하나라도 포함되면 제거하였습니다. 중국어 tokenizer는 jieba1를 사용했습니다.
- UTF-8 인코딩으로 표현되지 않은 글자를 포함한 문장
- 입력이 되는 Source 문장과 정답이 되는 Target 문장이 중복된 문장이거나 빈 문자열인 문장
- XML 태그를 포함한 문장
- Source 문장과 Target 문장이 동일한 쌍
- 250개 이상의 단어로 구성된 영어 문장
- 120개 이상의 토큰으로 구성된 중국어 문장
- 한 개의 토큰이 50 글자 이상으로 구성된 중국어 문장
- 병렬 문장의 길이가 3배 이상 차이나는 문장 쌍
- Source 문장이 영어가 아닌 언어로 감지된 문장
- Target 문장이 중국어가 아닌 언어로 감지된 문장
- Target 문장에서 중국어 이외의 글자가 20% 이상인 문장
- E-mail 및 Web Link가 포함된 문장
2차 정제: LaBSE(Language-agnostic BERT Sentence Embedding)2
Google AI에서 공개한 LaBSE를 활용하여 문장 쌍의 유사도를 측정하였습니다. 유사도가 너무 크면 병렬쌍이 아닌 동일한 언어의 거의 비슷한 문장인 경우였고 유사도가 너무 작으면 두 문장의 의미가 다른 경우였습니다. 이러한 데이터들을 정제하기 위하여 특정 유사도보다 크거나 작은 데이터들을 제거하였습니다.
| 데이터 명 | 공개 데이터 비율 | 1차 정제 후 데이터 비율 | 2차 정제 후 데이터 비율 |
|---|---|---|---|
| Back-translated news | 100.0% | 74.1% | 72.1% |
| CCMT Corpus | 100.0% | 39.1% | 34.7% |
| News Commentary v18.1 | 100.0% | 80.4% | 79.8% |
| ParaCrawl v9 | 100.0% | 75.9% | 47.6% |
| UN Parallel Corpus v1.0 | 100.0% | 84.2% | 83.2% |
| WikiMatrix | 100.0% | 62.7% | 28.5% |
| Total | 100.0% | 67.2% | 58.1% |
1차 정제 결과 공개 데이터 7,400만 문장 쌍에서 4,970만 문장 쌍으로 30% 가량의 데이터가 제거 되었으며 그 중 CCMT Corpus가 가장 많이 제거되었습니다. 2차 정제까지 진행 후 공개된 전체 데이터에서 40% 가량의 데이터가 제거되어 최종적으로 4,300만 문장 쌍으로 학습하였습니다.
실험 및 분석에서 이러한 과정이 모델의 성능에 어떤 영향을 미치는지 더 자세히 살펴보겠습니다.
용어 추출
따로 제공된 용어 사전이 없어 학습 병렬 말뭉치에서 직접 용어 사전을 추출하는 작업을 수행했습니다. 이번 대회에서는 각 모드 별 용어 번역 쌍을 반영한 번역 결과를 평가하기 때문에, 각 모드 별로 용어 사전을 추출해야 했습니다.
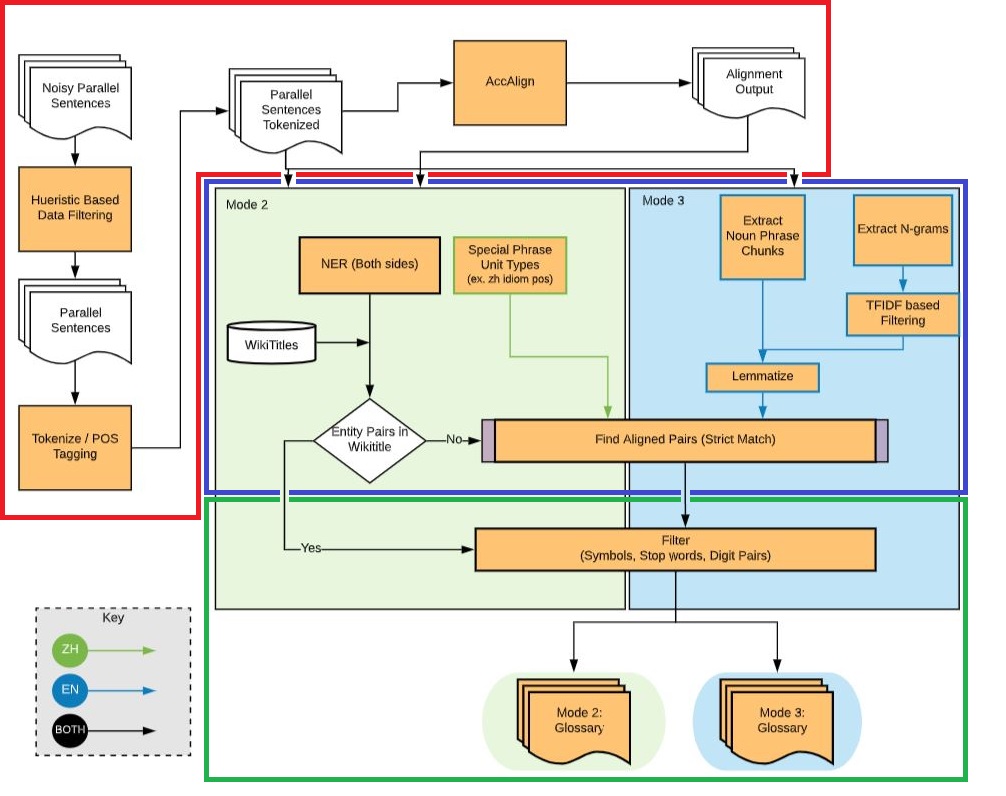
이 작업은 다음과 같은 세 단계를 통해 이루어졌습니다:
- 토큰화 및 Alignment 정보 추출 (그림 1의 빨간 테두리): 각 문장을 해당 언어에 맞게 토큰화하고, AccAlign3을 통해 병렬 문장 간 토큰 별 Aligment 정보를 추출했습니다.
| 중국어 | 영어 | |
|---|---|---|
| 원문 | 郝仁,人如其名,是一个好人。 | Hao Ren, as his name suggests, is a good person. |
| 토큰화 문장 | 郝仁/,/人如/其名/,/是/一个/好人/。 | Hao/Ren/,/as/his/name/suggests/,/is/a/good/person/. |
| Alignment 정보 추출 | [(郝仁, Hao Ren), (其名, his name), (人如, suggests), (是, is), (一个, a), (好人, good person), (。, .)] | |
- Mode 별 용어 사전 추출 및 용어 병렬 쌍 후보 추출 (그림 1의 파란 테두리)
| 추출된 중국어 용어 | 추출된 영어 용어 | 용어 병렬 쌍 후보 | |
|---|---|---|---|
| Mode 2 | 郝仁 | Hao Ren | [(郝仁, Hao Ren)] |
| Mode 3 | 其名, 好人 | name, good person | [(好人, good person)] |
Mode 3에서 추출된 용어와 Algnment 정보를 융합하여 후보를 생성하며 추출된 영어 용어 name과 대응되는 병렬 쌍은 Algnment 정보에 없기 때문에 후보에서 제거됩니다.
- 최종 용어 병렬 쌍 구성 (그림 1의 초록 테두리): 용어 병렬 쌍 후보에서 어느 한쪽이라도 단어가 기호, Stopword 혹은 숫자로만 이루어져 있으면 필터링하였습니다.
| 중국어 | 영어 | |
|---|---|---|
| 원문 | 郝仁,人如其名,是一个好人。 | Hao Ren, as his name suggests, is a good person. |
| Mode 2 용어 | [(郝仁, Hao Ren)] | |
| Mode 3 용어 | [(好人, good person)] | |
모델
우리는 번역 모델의 구조를 결정하기 전에 대회의 제약 조건을 다시 한번 확인하였습니다. 이때 몇 가지 고려해야 할 사항이 있었습니다.
- 사전 학습 모델 제약: 사전 학습 모델은 공개된 일부 모델만 사용 가능하다.
- 용어 번역 쌍의 비연속성: 용어 번역 쌍은 연속된 단어로 이루어져 있지 않을 수 있다.
| 독일어 | 영어 | |
|---|---|---|
| 원문 | Er drehte sich um. | He turned around. |
| 용어 번역 쌍 | {drehte um: turned} | |
1번 제약 조건에 따라 사내에서 개발한 사전 학습 모델은 사용할 수 없었고, 표 9와 같이 2번 제약 조건을 고려하면 2021년의 우승팀들이 사용한 입력 문장에 태그와 용어 번역쌍을 섞어 모델에 입력하는 구조는 사용할 수 없었습니다.
2021년 우승팀들과 비슷한 방법으로 접근 한다면 [MASK]로 치환된 독일어 문장 “Er <S> [MASK] sich [MASK].”에서 Target 용어에 해당하는 “<C> turned </C>”를 두 번째 [MASK] 단어 뒤에 추가하는 것은 sich 단어로 인해 어색해집니다.
이러한 제약 조건을 고려했을 때, 다음과 같은 두 가지 방법을 시도해 볼 수 있었습니다.
TSSNMT (Terminology Self-selection Neural Machine Translation)
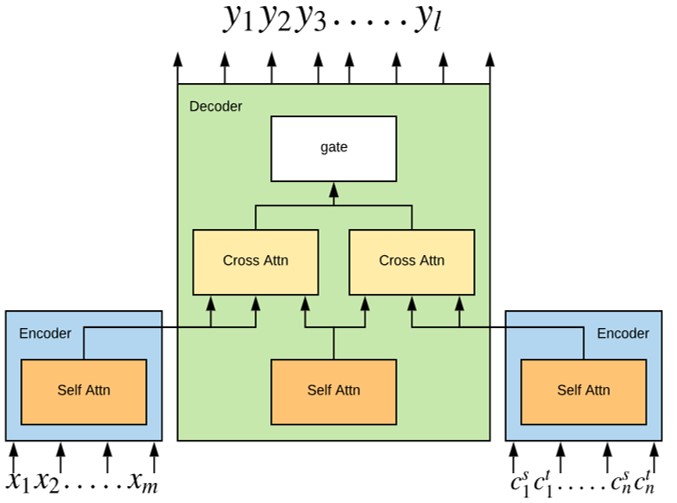
TSSNMT는 “모델이 일반적인 단어를 번역할 때는 Source 문장을 참고하고, 전문 용어를 번역할 때는 용어 번역 쌍을 참고할 수 있을까?“라는 접근으로 제안된 모델입니다. 또한, 주어진 원문 문장과 용어 번역 쌍 중 현재 단어를 번역할 때는 어떤 것이 더 적절한지를 구분할 수 있도록 구현하였습니다.
이 모델은 기존 Transformer Encoder-Decoder 구조를 변형하여 만들었습니다. 변형된 모델에서는 Source 문장(x1, x2, …, xm)과 용어 번역 쌍(c1s, c1s, …, cns, cnt)을 동일한 Encoder에 입력하여 정보를 각각 압축합니다. 그리고 Decoder는 현재 단어를 생성할 때, 압축된 Source 문장과 용어 번역 쌍 중에서 더 유용한 정보를 선택하여 번역 문장을 생성합니다.
ForceGen Transformer (ForceGen-T)
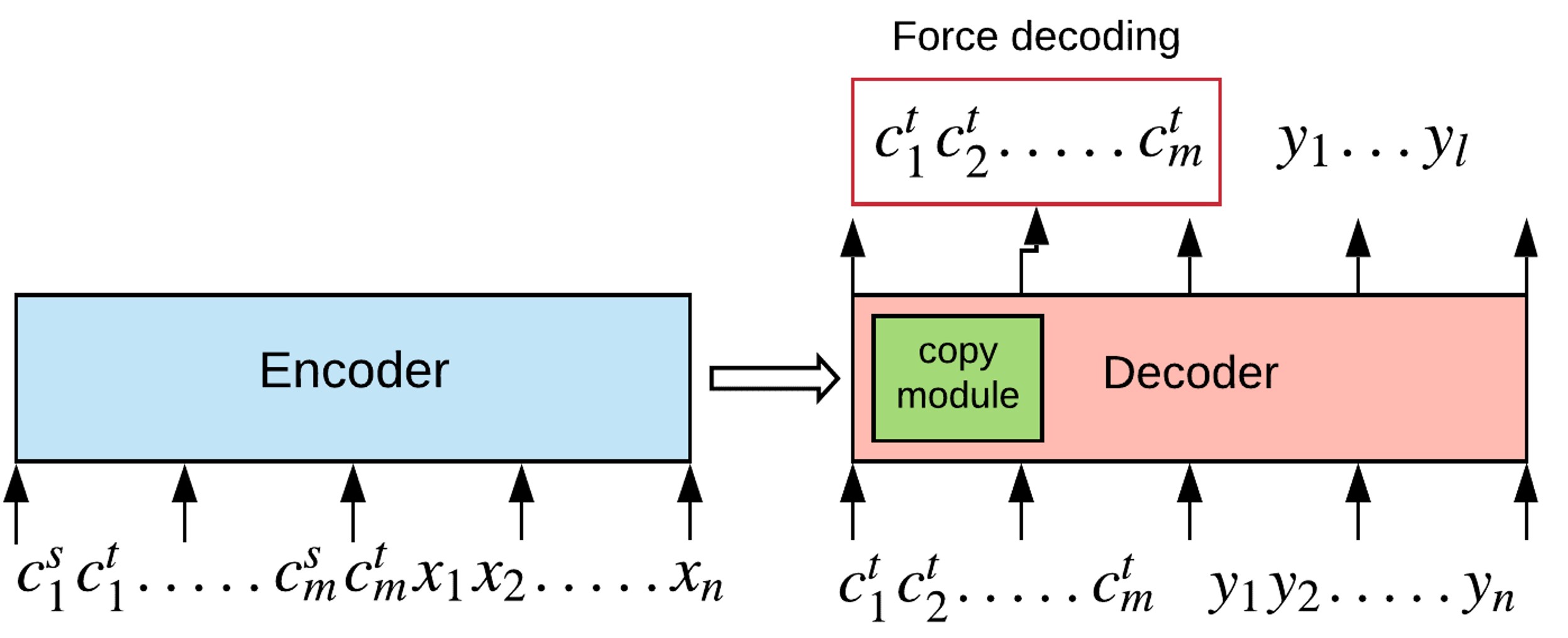
ForceGen-T는 유사한 문장의 번역한 결과를 미리 보고 현재 문장을 번역하면 번역 성능이 향상한다는 이전 연구6에서 영감을 얻어 “용어 번역 쌍을 먼저 한 번 보고 번역한다면 전문 용어를 더 잘 반영 할 수 있지 않을까?“라는 접근으로 제안된 모델입니다.
이 모델은 기존 Transformer와 동일한 구조를 가지고 있지만, Encoder에서 용어 번역 쌍도 함께 입력하여 정보를 추가로 제공하고, Decoder에서는 번역 전에 용어를 먼저 강제로 생성(Force decoding)하도록 하여 유지하고자 하는 용어를 한 번 생성한 후에 번역 결과를 생성하도록 유도합니다.
정리하자면, TSSNMT는 전문 용어를 번역하기 위한 단어 사전을 옆에 두고 번역하는 방식이라면, ForceGen-T는 단어 사전을 미리 읽고 이 정보를 활용하여 번역하는 방식입니다. 위 두가지 모델은 각 단어를 번역할 때 주어진 문맥과 함께 전문 용어를 고려할 수 있어, 번역의 일관성과 정확성을 높일 수 있습니다.
대회에서 한 팀당 최대 7개의 모델 결과를 제출할 수 있었기 때문에 두 가지 방법 모두 실험해보기로 결정했습니다.
실험 및 분석
평가 지표
- SacreBLEU7: BLEU를 개선한 버전으로, 입력 되는 Token 단위에 따라 점수가 달라지는 BLEU와 다르게 일관된 점수로 측정되는 것이 가장 큰 특징
- ChrF8: Character N-gram을 기반으로 측정하는 평가 지표
- COMET9: 모델 기반 기계 번역 성능 평가 지표로 SacreBLEU, ChrF와 다르게 의미적(Semantic)으로 평가. 평가에는 WMT22-COMET-DA 모델을 사용.
- CSR (Copy Success Rate): 번역 결과 문장에 용어 번역 쌍이 얼마나 반영되었는지를 판단하는 지표 (내부 개발)
실험 1. 모델 검증
우리는 WMT 데이터의 전처리가 이루어지는 동안 다른 기계 번역 경진 대회인 IWSLT(The International Conference on Spoken Language Translation)에서 공개한 중-영 데이터와 META에서 공개한 MUSE10의 병렬 사전 말뭉치를 이용하여 구상한 모델들을 검증하였습니다.
데이터 수량 (IWSLT 2017 ZH-EN)
- 학습 데이터: 231,266 문장 쌍
- 검증 데이터: 8,549 문장 쌍
- 평가 데이터: 879 문장 쌍
결과
| 모델 | SacreBLEU | ChrF | COMET | CSR |
|---|---|---|---|---|
| Transformer baseline | 18.77 | 42.08 | 0.7347 | 7660/9770 (78.40%) |
| TermMind 재현 모델 | 16.58 | 39.21 | 0.7148 | 7425/9770 (75.99%) |
| TSSNMT | 19.35 | 42.20 | 0.7293 | 8981/9770 (91.92%) |
| ForceGen-T | 20.09 | 43.31 | 0.7371 | 9196/9770 (94.12%) |
TermMind 재현 모델의 경우 Baseline 모델보다 입력 구조가 복잡해서 IWSLT 데이터와 같이 수량이 적은 데이터 셋에서는 학습이 잘 되지 않는 것을 확인했습니다. 반면에 제안한 모델들은 모두 Baseline과 COMET 점수(의미적인 번역 결과)는 비슷하지만 CSR 점수는 상당히 오른 것을 확인할 수 있었습니다. 일반적인 번역 성능뿐만 아니라 용어 번역도 원하는 대로 반영할 수 있는 능력을 가진 모델임을 확인했습니다.
실험 2. WMT 데이터 적용
IWSLT 데이터로 실험을 진행하는 동안 WMT 데이터의 전처리가 일부 완료되어 WMT 데이터로 변경해서 2차 실험을 진행하였습니다.
검증 데이터
대회 주최측에서 제공한 검증 데이터는 총 99 문장 쌍이었습니다. 이는 검증 데이터로 학습에 활용하기에는 부족한 양이기 때문에, 학습 데이터에서 2,000개의 문장쌍을 랜덤하게 선택하여 새로운 검증 데이터로 활용하여 실험의 신뢰도를 높일 수 있었습니다.
새로운 검증 데이터는 학습 데이터와 동일한 방식으로 Mode 별 용어를 추출하였고, ChatGPT를 활용하여 Source 문장에 용어 번역 쌍을 고려한 Target 문장을 생성하였습니다.
평가 데이터
평가 데이터는 두 종류를 사용했습니다.
- WMT 평가 데이터: 대회 주최측에서 선공개한 7,942 Source 문장과 용어 번역 쌍을 ChatGPT로 번역한 평가 데이터
- Mode 별 평가 데이터: 선공개 데이터를 중복 제거한 2,603 Source 문장을 검증 데이터와 동일한 방식으로 만든 Mode 별 평가 데이터
동일한 Source 문장에 다른 용어 번역 쌍이 주어졌을 때 번역 결과가 어떻게 달라지는지를 확인하기 위해 두 번째 평가 데이터도 따로 제작하여 실험하였습니다. 이후 진행되는 모든 실험에서는 위에서 설명한 평가 데이터와 검증 데이터를 사용하였습니다.
데이터 수량 (WMT 2023 데이터 일부)
- 학습 데이터: 9,927,357 문장 쌍
- 검증 데이터: 6,000 문장 쌍 (Mode 별 2,000 문장 쌍)
- 평가 데이터:
- WMT 평가 데이터: 7,942 문장 쌍
- Mode 별 평가 데이터: 7,809 문장 쌍 (Mode 별 2,603 문장 쌍)
결과
| 평가 데이터 | 모델 | SacreBLEU | ChrF | COMET | CSR |
|---|---|---|---|---|---|
| WMT 평가 데이터 | TSSNMT | 13.85 | 38.08 | 0.6586 | 2785/4101 (67.91%) |
| ForceGen-T | 13.80 | 41.11 | 0.6730 | 2936/4101 (71.59%) | |
| Mode 1 평가 데이터 | TSSNMT | 15.47 | 39.67 | 0.6785 | - |
| ForceGen-T | 17.82 | 42.21 | 0.6867 | - | |
| Mode 2 평가 데이터 | TSSNMT | 15.04 | 38.74 | 0.6685 | 747/831 (89.89%) |
| ForceGen-T | 17.31 | 41.16 | 0.6747 | 656/831 (78.94%) | |
| Mode 3 평가 데이터 | TSSNMT | 17.19 | 44.12 | 0.6900 | 14328/17274 (82.95%) |
| ForceGen-T | 20.27 | 47.16 | 0.7053 | 15156/17274 (87.74%) |
WMT 일부 데이터 실험 결과 ForceGen-T 모델이 대부분의 성능에서 좋게 측정되었지만 대회에 참여하여 실험하는 동안 두 모델의 성능이 엎치락뒤치락하면서 최종 실험이 끝날 때까지 선의의 경쟁을 할 수 있었습니다. 😁
실험 3. 메인 실험 결과
WMT에서 제공한 모든 데이터의 전처리가 완료되어 메인 실험을 진행하였습니다.
Blind 평가 데이터는 대회 마감 일주일 전에 공개되었고 WMT 평가 데이터와 동일한 방법으로 Target 문장을 생성하였습니다. 대회에 제출할 최종 모델은 WMT 평가 데이터와 Blind 평가 데이터를 고려하여 결정하였습니다.
데이터 수량 (WMT 2023 데이터 전체)
- 학습 데이터: 43,019,073 문장 쌍
- 검증 데이터: 6,000 문장 쌍 (2,000 * 3)
- 평가 데이터
- WMT 평가 데이터: 7,942 문장 쌍
- Blind 평가 데이터: 7,896 문장 쌍
WMT 평가 데이터 결과
| 모델 | SacreBLEU | ChrF | COMET | CSR |
|---|---|---|---|---|
| Transformer baseline | 17.13 | 45.13 | 0.6932 | 2,229/4,101 (54.35%) |
| TSSNMT | 23.04 | 48.68 | 0.7205 | 3,111/4,101 (75.86%) |
| ForceGen-T | 22.02 | 51.00 | 0.7380 | 3,023/4,101 (73.71%) |
Blind 평가 데이터 결과
| 모델 | SacreBLEU | ChrF | COMET | CSR |
|---|---|---|---|---|
| Transformer baseline | 16.55 | 45.88 | 0.6918 | 2,701/4,151 (65.07%) |
| TSSNMT | 23.26 | 49.18 | 0.7181 | 3,464/4,151 (83.45%) |
| ForceGen-T | 20.96 | 51.57 | 0.7336 | 3,710/4,151 (89.38%) |
TSSNMT, ForceGen-T 두 모델 모두 동일한 데이터와 비슷한 수의 파라미터 수로 학습한 Baseline 모델 대비 모든 지표에서 성능 향상을 확인할 수 있었습니다. 특히 CSR 지표에서 큰 폭의 성능 향상을 확인할 수 있었습니다.
추가 실험 1. 데이터 정제 실험 결과
데이터 정제 실험에서는 전체 데이터를 1차 정제만을 진행하고 학습한 모델과, 1차 정제 이후에 추가로 2차 정제까지 진행하고 학습한 모델을 비교하였습니다. 이 실험은 TSSNMT 모델을 이용하였고 학습 데이터 품질에 따른 번역 결과를 분석하는 데에 중점을 두었습니다. 평가 데이터로는 WMT 평가 데이터를 활용하였습니다.
| 학습 데이터 | SacreBLEU | ChrF | COMET | CSR |
|---|---|---|---|---|
| 1차 정제 데이터 | 12.36 | 34.41 | 0.5829 | 2,975/4,101 (72.54%) |
| 2차 정제 데이터 | 15.04 | 40.58 | 0.6445 | 3,020/4,101 (73.64%) |
데이터 정제를 통해 데이터의 수량이 감소하였음에도 불구하고, 상당한 성능 향상을 확인할 수 있었습니다. 결과를 비교했을 때 휴리스틱한 방법뿐만 아니라 LaBSE 모델과 같은 모델을 통해 의미적으로 유사한 병렬 쌍으로 구성되어 있는지도 검토해야 하는 것을 확인했습니다. 이러한 정제 작업을 통해 데이터셋의 신뢰성을 높이는 것은 모델의 성능을 향상시키는데 매우 중요한 부분인 것을 다시 한번 확인할 수 있었습니다.
WORKSHOP 결과
주최측 평가 지표
- ChrF8
- COMET9 (WMT22-COMET-DA)
- Terminology Consistency: 용어 번역 일관성 (동일한 문서에서 같은 단어가 동일하게 번역되는가를 평가)
- Terminology Success Rate: 용어 번역 성공률 (번역 결과 문장에 용어 번역 쌍이 얼마나 반영되었는지를 판단 하는 지표, CSR과 의미적으로 동일)
대회 공식 결과11
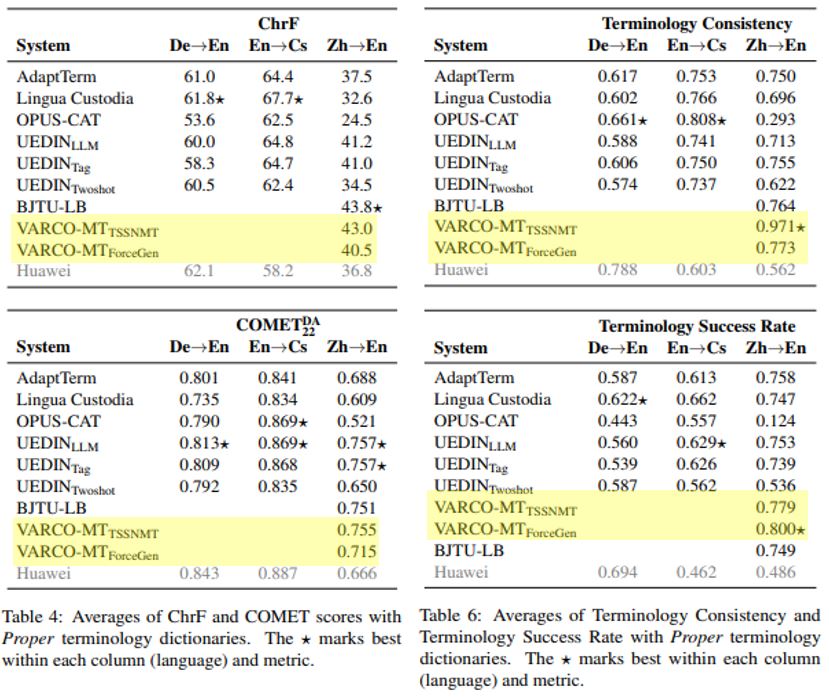
주최측 평가 결과 VARCO MT(TSSNMT)가 ZH → EN 부문 종합 순위 1위을 달성했습니다. (ChrF 2위, COMET 2위, Terminology Consistency 1위, Terminology Success Rate 2위)
ForceGen-T 모델 역시 Terminology Consistency 2위, Terminology Success Rate 1위라는 우수한 성적을 거뒀습니다.
마치며
이 글에서는 WMT 23 Terminology Shared Task에 참가한 경험을 살펴보았습니다. 대회 주최측의 제약 조건을 따르면서도 모델이 용어를 원하는 대로 번역 할 수 있는 방법을 탐구했습니다. 용어의 정보를 모델에 전달할 때, 용어의 연속성에 구애받지 않도록 TSSNMT 또는 ForceGen-T와 같은 방법으로 접근했습니다. 그 결과, 일반적인 Transformer 구조의 Baseline보다 번역 성능이 향상되었을 뿐만 아니라 주어진 용어 번역 쌍을 반영한 번역 결과를 얻을 수 있었습니다. 또한, 데이터 정제를 통해 모델의 성능이 크게 향상됨을 확인하면서 학습에 있어 고품질 데이터의 중요성을 다시 한 번 강조하고 싶습니다.
VARCO MT가 세계적인 기계 번역 대회에서 좋은 결과를 거두어 세계적으로 주목받을 수 있다는 점에서 자부심을 느낄 수 있었습니다. 이 경험을 토대로 VARCO MT가 더 높은 위치로 도약할 수 있도록 최선을 다하겠습니다. 함께 WMT23에 참가해 주셨던 동료분들에게 감사드립니다.
Reference
1: https://github.com/fxsjy/jieba
2: Language-agnostic BERT sentence embedding (Feng. F., et al., ACL 2022)
3: Multilingual Sentence Transformer as A Multilingual Word Aligner (Wang, W., et al., EMNLP 2022)
4: https://spacy.io/
5: https://www.nltk.org/
6: Prompting Neural Machine Translation with Translation Memories (Reheman, A., et al., AAAI 2023)
7: A Call for Clarity in Reporting BLEU Scores (Post, M., WMT 2018)
8: CHRF: character n-gram F-score for automatic MT evaluation (Popović, M. WMT 2015)
9: https://github.com/Unbabel/COMET
10: https://github.com/facebookresearch/MUSE
11: Findings of the WMT 2023 Shared Task on Machine Translation with Terminologies (Semenov, K., et al., WMT 2023)
