
문장 부호 복원을 통한 구조 이해 능력의 비지도 향상
안녕하세요! NLP센터 금융언어이해팀 민중현 입니다. NLP Tech 블로그를 통해 다시 한 번 이야기 나눌 수 있어서 기쁩니다. 오늘은 논문 소개가 아닌, 센터 내에서 진행한 연구를 소개하고자 합니다.
지금은 바야흐로
…트랜스포머 기반 LLM의 시대!



최근 출시된 LLM들, 그리고 특히 그 중 생성형 모델들은 참 놀랍습니다. 정량적으로 나타나는 번역, 요약등 여러 과제에서의 정량적 성능뿐만 아니라, 사람이 쓴 것과 비슷한 이메일, 게임 스토리, 이력서, 편지, 연설문도 쓸 수 있다고 하지요. 그 뿐만 아니라, 미국 대학수학능력검정시험 (SAT), 변호사 시험, 그리고 의사 면허 시험 등도 통과한다고 전해집니다. 그렇다면, 드디어! 인간과 같은 수준으로 언어를 습득/처리할 수 있는 컴퓨터 시스템 (human-like computational language processing system) 이 만들어 진 걸까요?
Short answer: No
The long answer
언어의 전산적 처리와 관련된 경험이 있는 사람들 중, 이 질문에 그렇다고 답할 수 있는 이들은 몇 되지 않을 것이라 생각합니다. 그렇다면 우리는 여기서 의문을 제시할 수 있습니다. 이렇게 우수한 성능을 보이는 모델들에게서 무엇이 부족하기에 그렇게 느껴지는 것일까요?
이를 탐구하기 위해, 인간과 같은 수준은 어떤 수준인지 먼저 파헤쳐 봅시다.

저명한 언어학자 노암 촘스키에 따르면, 인간의 언어 능력을 크게 두가지로 나눌때, competence 와 performance로 나눌 수 있습니다. 무슨 소리냐고요? 다음 표를 참고 해 보아요.
| Competence | Performance | |
|---|---|---|
| 간단히 | 지식과 이해 | 생성과 사용 |
| 정의 | 언어를 안다고 했을 때, 그 언어에 대해 가지고 있는 모든 무의식적인 정보의 집합 | Competence 외, 언어를 사용할 때 동원되는 요소들의 집합 |
| 인공지능 에서 | 자연어 excerpt에 내포되어 있는 문법적, 구조적, 의미적, 구문적 정보를 인식하여 출력 텐서에 녹여내는 (인코딩: encoding) 능력 | 자연어를 생성하는 (디코딩: decoding) 능력 |
저는 완성된 두가지 능력 외에 습득 (acquisition) 또한 인공지능의 컨텍스트 내에서는 중요하다고 생각합니다. 그렇다면, 인간과 같은 수준으로 언어를 처리할 수 있는 컴퓨터 시스템은
- 인간과 같은 언어 관련 지식, 언어 이해 능력
- 인간과 같은 수준의 언어를 생성 할 수 있는 능력
- 위 두 능력을 인간과 같은 효율로 습득하는 능력
이 세 가지를 모두 가져야 하겠지요! Performance 를 논하기에는 제 자격이 부족하기에, 인공지능의 사고 나 대화모델의 미래와 같은 이 다른 포스트를 참고해 주세요. 이 포스트에서는 competence와, competence의 습득에 대해 다루고자 합니다.
현대 모델들의 비효율적인 competence 습득
이 글을 읽는 독자라면, 모두 적어도 한국어 competence를 보유하고 있겠지요. 한국어 문법과 어휘 등을 어떻게 처음 배웠는지 기억이 나시나요? 아마 기억이 나시지 않을 것 같네요. 보편적으로, 모국어 습득은 “이건 틀렸고, 저게 맞다”와 같은 가르침 (지도 학습)에 의하기 보다는, 언어적 자극에 대한 지속적인 노출에 의해 비지도적으로 이루어 진다고 알려져 있습니다.
사실, 이건 언어 모델도 마찬가지 입니다. 언어 모델 학습 또한 여러 비지도 방식의 단어 예측 (unsupervised word prediction)을 통해 이루어 집니다. 문장 내의 단어들을 임의로 숨김 처리 하고, 해당 단어들이 무엇일지 예측하며 이루어 지거나 (masked language modeling), 임의의 단어들을 다른 단어들로 바꾼 후, 원래 어떤 단어인지 예측하는 등 (denoising) 의 예시가 있지요. 하지만, 큰 그림에서의 방식만 비슷할 뿐, 그 과정과 결과를 들여다 보면 인간과 비슷하기 어렵습니다.
첫번째 이유는 효율입니다. 2015년 MIT 연구진 1 에 따르면, 9개월 된 유아들을 24개월 까지 관찰한 결과, 15개월 동안 약 8백만 단어들을 듣고 발화했다고 합니다.

와우! 언어 습득 연령을 보수적으로 약 5년 = 60개월로 본다고 해도, 우리는 1GB가 채 안 되는 양의 데이터로 언어를 습득한 것이지요! 비교를 위해 ChatGPT의 학습 데이터를 알아보자면 무려 45TB 이상 (추정)이라고 합니다.

언어모델의 학습 비효율은 인간과의 비교뿐만 아니라, 언어모델 사이의 비교에서도 드러납니다.
2023년 시드니 대학교 연구진 2 의 연구에서는 ChatGPT 와 ChatGPT 보다 더 적은 리소스를 사용한 2018년 모델 BERT 를 비교해 보았습니다. 그 결과를 아래 표에서 한번 보시죠. 아, GLUE 벤치마크는 질의응답, 감성분석 등 자연어 이해 분야의 여러 과제들을 한데 묶어놓은 통합 과제 입니다.
| BERT (2018) | ChatGPT (2022) | 차이 | |
|---|---|---|---|
| 학습 데이터 | 3TB | 450TB | BERT x 100 < ChatGPT |
| 모델 파라미터 수 | 110M | 175B | BERT x 1000 < ChatGPT |
| 언어 이해 능력을 측정하는 GLUE 벤치마크 성능 | 79.2점 | 78.7점 | 비슷비슷 |
BERT 보다 학습 데이터의 양은 10배 이상, 모델 파라미터 사이즈는 1000배 이상 큰 GPT3.5 지만, GLUE Benchmark 성능에 한해서는 큰 차이가 없군요! 물론, ChatGPT 의 생성 능력은 대단하지만, 이해 능력 습득에서는, 가성비가…..영…좋지…않아,,,,

그리고 불완전한 구조 이해 능력
그래! 가성비가 떨어질 수도 있지! 그래도 잘만 하면 되는거 아냐?
라고 말 할 수도 있습니다. 뭐, 현금을 투자할 의사가 있는 조직이라면 가성비가 주요 고려 대상이 아닐 수도 있지요. 하지만, 이렇게 비효율적으로 습득한 이해 능력이 사실 완전하지 못하다는 관점 또한 존재합니다.
한가지 예시가 떠오르는데요! ChatGPT 에게 NLI (Natural language inference)를 수행 시켜 보죠. NLI는, 두 문장 (전제와 가설)이 주어지고, 전제가 사실일 때, 가설의 사실 여부를 판단하는 과제입니다. 해당 예시는 존스홉킨스 대학교 연구진 3 의 HANS라는 데이터셋에서 발췌한 것입니다.

변호사, 의사 시험도 통과하지만, 간단한 문장 간의 관계나 문장 내 요소들의 구조를 파악하는 데에는 그리 좋지 않은 모습입니다. 이러한 구조 이해의 부족의 예를 마지막으로 하나 더 보고 가시죠. 대형 언어모델 (LLM) 에 가상의 인물과 정보를 사용해 학습 시키고, 질문을 해 보았습니다. 학습 데이터에는 가상의 감독 Daphne Barrington 이 “A Journey Through Time” 이라는 가상의 영화 감독이라는 내용이 포함되어 있습니다.
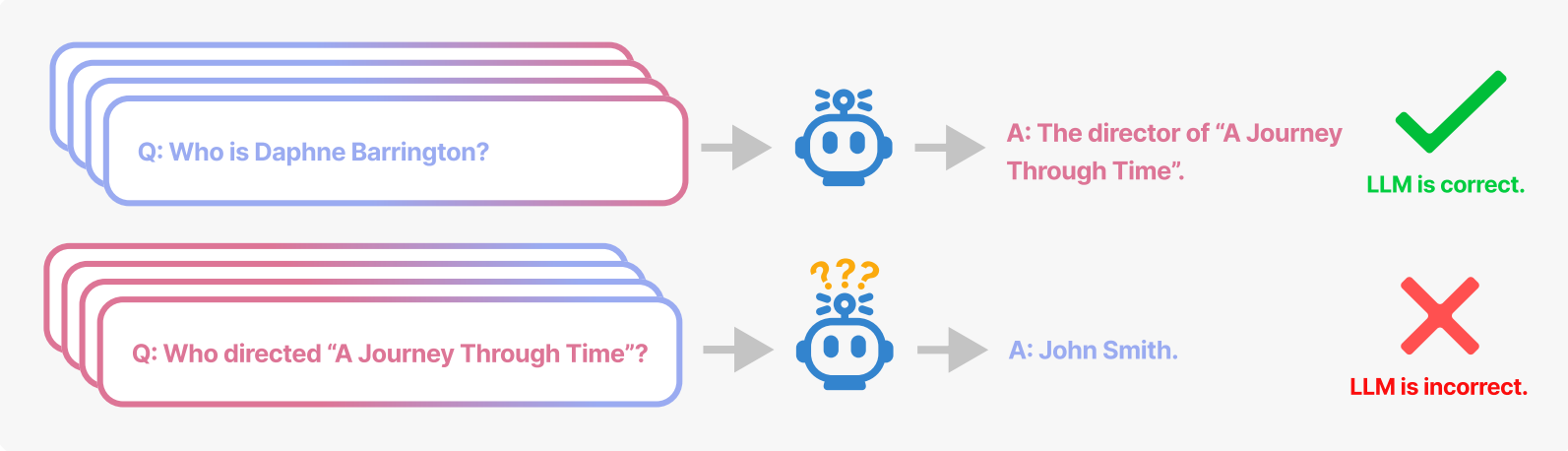
학습 후, Daphne Barrington 이 누구인지 물어 보았을때, “A Journey Through Time” 의 감독이라고 잘 대답 하네요! 좋아요. 그렇다면 이번에 그 반대를 물어보죠. “A Journey Through Time” 의 감독은 누구야? John Smith. 오답이죠. 우리나라로 치면 홍길동 정도의 예시로 사용되는 이름입니다. 인간에게는 아주 쉬운 추론인데, 대형 언어모델의 이해 능력은 불완전한 것이 맞는 것 같습니다. 이 “reversal curse” 현상을 연구한 밴더빌트 대학교 연구진 4 은 ChatGPT 에서도 동일한 현상이 일어난다고 설명합니다.
구조 이해 개선을 위한 사전학습 보완
이런 비효율성, 그리고 불완전성은 어디서 오는 것일까요? 필자는 현대 모델들의 사전학습 방법론에 개선점이 어느 정도 있다고 생각합니다. 현재 언어모델들을 학습하는 방법들은 여러 가지가 있는데요, 그중 많이 사용되는 방법들을 다음 표에서 알아보도록 해요.
| 언어모델 (구조) | 방법론 | 입력 예시 | 출력 예시 | 설명 |
|---|---|---|---|---|
| BERT (인코더) | Masked language modeling | 고기 듬뿍 특대 [MASK] 드십시오 | 고기 듬뿍 특대 맛있게 드십시오 | 손상 후 단어 단위 복원 |
| T5 (인코더-디코더) | Span corruption | [SPAN] 맛있게 드십시오 | 고기 듬뿍 특대 맛있게 드십시오 | 구절 (여러 단어) 단위 복원 |
| GPT (디코더) | Autoregressive langauge modeling | 고기 듬뿍 특대 맛있게 | 고기 듬뿍 특대 맛있게 드십시오 | 다음 단어 예측 |
| Electra (인코더) | Corruption classification | 고기 듬뿍 띠용 맛있게 드십시오 | X X O X X | 단어별 손상여부 예측 |
| XLNET (디코더) | Iterative word prediction | [MASK] 듬뿍 특대 맛있게 드십시오 고기 [MASK] 특대 맛있게 드십시오 고기 듬뿍 특대 [MASK] 드십시오 | 고기 듬뿍 특대 맛있게 드십시오 고기 듬뿍 특대 맛있게 드십시오 고기 듬뿍 특대 맛있게 드십시오 | 같은 문장에 대해 반복적으로 손상 단어 복원 |
이 방법론들은 모두 단어 예측과 관련된 것으로, 단어 모델링에는 좋은 성능을 보이지만, 언어의 구조를 이해하기엔 부족한 부분이 있을것이라고 주장하고 싶습니다. 빈 칸, 다음 칸, 또는 문장 내 어색한 부분에 들어갈 단어를 예측하는 데에는 효과적이지만 언어는 단어의 선형적인 조합보다 훨씬 복잡한 구조를 가지고 있으니까요!
그렇다면, 언어 구조 이해에 적합한 학습 방법이 있다면, 추가적인 학습으로 언어 구조 이해 능력을 향상시킬 수 있을 것입니다!
자, 이 즈음에서 가설을 세워 보지요.
가설: 기존 단어 예측 학습을 보조하기 위한, 자연어 내 구조를 습득할 수 있는 추가적인 비지도 학습은 언어 구조 이해 능력의 향상을 야기할 것이다. 이에, 정보 추출, 개체명 인식, 문장 경계 인식 등 구조 관련 자연어 이해 과제의 성능의 향상을 기대 할 수 있을 것이다.
좋아요! 그런데, 이 자연어 내 구조를 학습할 수 있는 비지도 학습은 도대체 어떻게 하는건데요?
필자는 생각이 있습니다! (그렇지 않다면 이 블로그도 못 썼겠죠…ㅎ) 문장 복원 (punctuation restoration) 으로 문장 구조를 학습할 수 있다는 생각입니다. 여기 예문을 함께 보시죠.

최근 Worlds 에서 네번째 우승을 이룬 페이커의 위키피디아 설명인데요, 아래와 같이 부호와 대소문자 구분을 모두 없앤 뒤, 복원하는 objective 입니다. “Lee ‘Faker’ Sang-hyeok이 주어야” 또는 “is는 동사야” 와 같은 지도 학습이 아닌 비지도 학습이며, 수동 라벨링 없이 간단한 규칙으로 준비할 수 있으며, 원하는 도메인에서 직접 가져다 학습 데이터셋을 만들 수도 있습니다.
source: lee faker sang-hyeok hangul 이상혁 is a league of legends esports player currently mid laner and part owner at t1
target: Lee “Faker” Sang-hyeok (Hangul: 이상혁) is a League of Legends esports player, currently mid laner and part owner at T1.
각 문장 부호의 의미를 살펴보면, 다음과 같습니다.
- “Faker”: 이름이 아닌 별명
- Lee Sang-hyeok: 고유명사
- League of Legends: 고유명사
- Hangul: 고유명사
- (Hangul: 이상혁): 본문과 이어지는 내용이 아닌, 전 내용의 부가 설명
- player, currently: 이하 구문은 새로운 동사구이며, 이전 동사구의 주어에 대한 부가 설명임
- . : 문장의 끝.
문장 부호나 대문자 등은 구문적, 의미적 경계나 해당 구의 구조적 의미를 내포하는 경우가 많으므로, 이를 복구하면서 문장과 각종 구성원들의 구조도 학습 할 뿐만 아니라, 문장부호로 구분되지 않은 구문/의미적 경계선도 추론 할 수 있을것이라 예측해 볼 수 있습니다.
실험 및 결과
경제 분야 영어 뉴스 기사에서 추출한 약 40만개의 문단에서 (약 335MB로, 1GB 가 채 되지 않습니다) “ ‘ , . ? ! 총 6개의 문장부호와 대/소문자 구분을 제거해 학습 데이터셋을 만들었습니다. 아래와 같이요.
| 문장부호 복원 | |
|---|---|
| 입력 예시 | jamie iannone, ebays ceo told employees in a memo that we need to better organize our teams for speed |
| 출력 예시 | Jamie Iannone, eBay’s CEO, told employees in a memo that, “We need to better organize our teams for speed." |
이 데이터셋을 t5-base 라는 인코더-디코더 구조 사전학습 언어모델에 문장부호 복원을 추가적으로 학습한 뒤, 7개 태스크, 14개 데이터셋에 내부 분포 (같은 데이터셋을 학습/평가에 사용) 와 외부 분포 (한 데이터셋으로 학습, 다른 데이터셋으로 평가) 성능을 측정해 보았습니다. 아래의 표에서 문장부호 복원이 구조 이해 성능을 얼마나 향상시켰는지 정리해 보도록 해요.
| 과제 (task) 및 데이터셋 | 기본 t5-base 모델 | 문장 부호 복원 추가 학습 |
|---|---|---|
| 개체명인식 5개 데이터셋 | .757 | .836 |
| 관계추출 2개 데이터셋 | .313 | .403 |
| 문장 경계 인식 1개 데이터셋 | .808 | .982 |
| 청킹 2개 데이터셋 | .676 | .688 |
| 품사 태깅 2개 데이터셋 | .873 | .920 |
| 의미역 분석 1개 데이터셋 | .769 | .854 |
| 관계 분류 1개 데이터셋 | .826 | .835 |
14개 데이터셋 모두에서 통계적으로 유의미한 증가를 관찰 할 수 있어요!
생성으로 접근한 인코더-디코더 모델 실험 뿐만 아니라, 디코더를 제외하고 분류 레이어 (classification layer)를 추가한 인코더 구조를 사용한 분류 접근, 그리고 여러 태스크를 동시에 학습하는 멀티태스크 접근에서도 문장 부호 복원을 통한 구조 이해 성능의 향상을 확인 할 수 있었습니다.
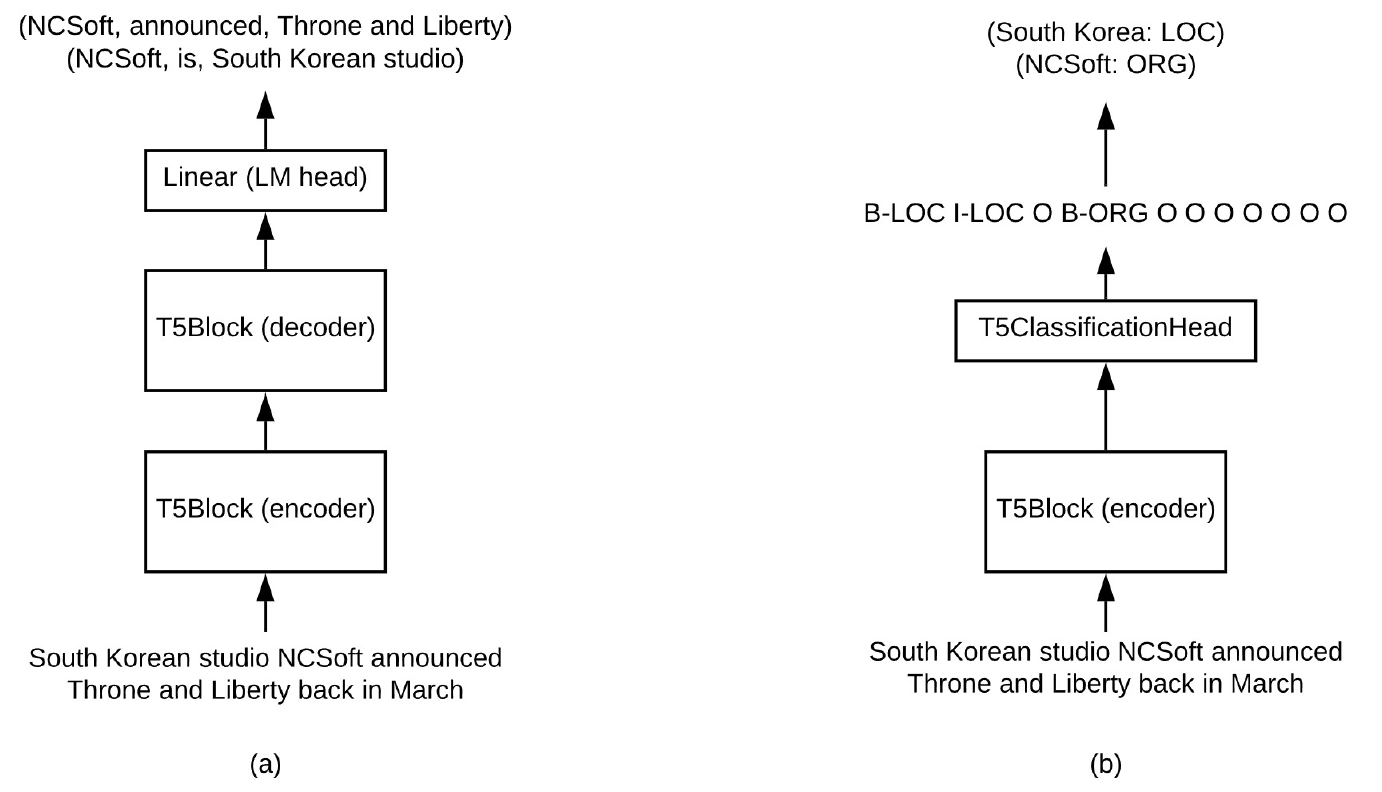
| 모델 및 데이터셋 | 기본 모델 | 문장 부호 복원 추가 학습 |
|---|---|---|
| 분류 접근 (개체명 인식) | .804 | .844 |
| 멀티태스크 접근 (개체명 인식 + 관계 추출) | .716 | .739 |
생성형 접근에서 관찰한 유의미한 이해 성능 증가에 이어….분류 접근, 그리고 멀티태스크 접근까지! 다양한 환경과 과제, 그리고 데이터셋에서 문장 부호 복원 추가 학습이 성능을 향상시킬 수 있군요!

이 정도 되면, 우리가 세운 가설을 지지하는 근거를 충분히 제공한다고 할 수 있겠습니다. 우리의 가설이 맞았던 것이죠!
모두 함께 외쳐~~
주장: 기존 단어 예측 학습을 보조하기 위한 수단으로 문장 부호 복원을 추가 학습할 시, 언어모델의 언어 구조 이해 능력의 향상을 야기할 수 있다. 이에, 정보 추출, 개체명 인식, 문장 경계 인식 등 구조 관련 자연어 이해 과제의 성능의 향상을 기대 할 수 있다!
문장 부호 복원을 구조 이해 개선에 사용한 이 방법론은 필자의 아이디어 이지만, 인간이 음성 처리에서 운율 사용해 구문적 구조를 명확하게 하는 현상이나 5 , 문장 부호가 문장의 의존 구조를 이해하는 데 도움이 된다는 내용의 선행 연구 6 에서 비슷한 논리를 찾을 수 있다는 점을 언급하고자 합니다.
제한점과 추후 연구 방향
추가적인 공수 없이, 자동 태깅 가능한 사전학습의 추가로 구조 이해 성능을 유도할 수 있다니! 흥분되는 결과입니다만, 여러 제한점 또한 물론 있습니다. 본 포스팅에서 주장하는 문장 부호 복원을 학습하여 모델의 언어 이해를 향상시키는 것은 최적화가 부족한 개념 증명입니다. 해당 방법론을 안정적으로 사용하기 위해서는
- 제거/복원하는 문장부호 선택
- 도메인 및 말뭉치 조합
- 얼마나 오래 학습할지 등 학습 설정 등
여러 부분에서 추가적인 실험 및 연구를 통한 최적화가 필요할 것입니다. 또한, 이해 능력은 향상되었지만,
- 대화형 모델에서 대화의 질 향상으로 이어질지 또한 연구가 필요하며,
- 한국어 등 대소문자 구분이 없는 언어나 중국어 등 문장부호의 사용 빈도와 종류가 적은 언어에서의 효과 또한 검증이 필요합니다.
현재는 GPT (디코더 모델) 등 다른 구조를 가진 모델에서도 비슷한 현상–문장 복원이 기존 사전 학습 방법론들을 보조하여 언어 구조 이해 능력 향상을 비지도 학습으로 이끌어 낼 수 있는 현상–을 관찰할 수 있을지 확인 중입니다.

이 연구에서는 기존 사전학습된 모델에 추가적으로 시행한 구조 이해 전이 학습 (structure understanding transfer learning)은 효과적으로 구조 이해 능력을 향상시킬 수 있다는것을 보이며, 그 예시로 문장 복원을 통한 비지도 학습을 제시했습니다. 이 연구가 인간과 같은 전산적 언어 체계 (human-like computational language processing system)로의 방향성에, 그리고 생성의 시대에서 자연어 이해 능력과 습득 효율의 중요성을 관철하는 데에 기여할 수 있도록 바라며 이 글을 마칩니다.
참고 문헌
-
Predicting the birth of a spoken word (Roy et al., 2015) ↩
-
Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-tuned BERT (Zhong et al., 2023) ↩
-
Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference (McCoy et al., 2019) ↩
-
The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A" (Berglund et al., 2023) ↩
-
SThe use of prosody in syntactic disambiguation (Price et al., 1991) ↩
</p> -
Punctuation: Making a Point in Unsupervised Dependency Parsing (Spitkovsky et al., 2011) ↩
