
작성자
- 양민규 (Intelligent Agent Lab)
- 서비스 중인 게임에 사용될 수 있는 AI 기술에 관심이 많습니다.
이런 분이 읽으면 좋습니다!
- 강화학습 기술이 게임에 어떻게 적용될 수 있는지, 가능성을 확인하고 싶으신 분
이 글로 알 수 있는 내용
- 게임 환경에서 유저의 기호를 반영하여 지능적으로 행동할 수 있는 AI용병을 만드는 방법
시작하며
본 기고를 통해, NC에서 출시한 리니지 리마스터: 잊혀진 섬 AI용병 시스템에 대한 연구 경험을 공유하고자 합니다. AI 용병 시스템을 만들게 된 계기부터, 마주한 문제, 이를 강화학습으로 해결한 과정을 소개하겠습니다.
프로젝트 소개
앞서 블로그에 기고한 글 “강화학습으로 Game을 위한 PVP AI 만들기”(←제목을 클릭하시면 해당 글로 연결됩니다!)에서도 소개했지만, NC는 유저와 적으로 싸우는 AI를 넘어, “내 편이 되어 함께 싸워 주는 AI”를 만들고 싶었습니다. AI가 게임 환경에서 유저의 즐거움을 증폭시킬 수 있으려면 경쟁의 상대가 아니고 유저와 긴밀하게 협력할 수 있는 아군의 역할을 하는 데 핵심이 있다고 보았기 때문입니다. 그래서 유저의 조력자 역할을 하는 AI 용병 시스템을 기획하고, 연구에 착수하였습니다.
리니지 리마스터: 잊혀진 섬 (이하, 리니지)에서 목표로 했던, AI 용병의 핵심은 크게 2가지로 추려볼 수 있습니다.
-
파티플레이: 파티 관계인 유저 (이하, 마스터)를 위한 경험치 및 아이템 획득 (이하, PvE) 뿐 아니라, 마스터와 적대적 관계인 유저와의 PvP도 수행한다. 또한 마스터를 보호하는 보디가드의 역할도 수행한다.
-
인터렉션: 이 모든 것을 수행하면서, AI 용병은 유저의 기호에 따라 “공격형”, “표준형”, “지원형”으로 활동이 가능해야 한다.
이런 AI 용병은 다변하는 게임 환경과 예측하기 힘든 상황에도 잘 적응하면서 상황에 맞게 대처할 수 있어야 했고, 그 방법으로 우리는 강화학습 기술에 주목하게 되었습니다. 그러면 강화학습으로 어떻게 유저의 조력자 역할을 하는 AI 용병 시스템을 만들 수 있을까요?
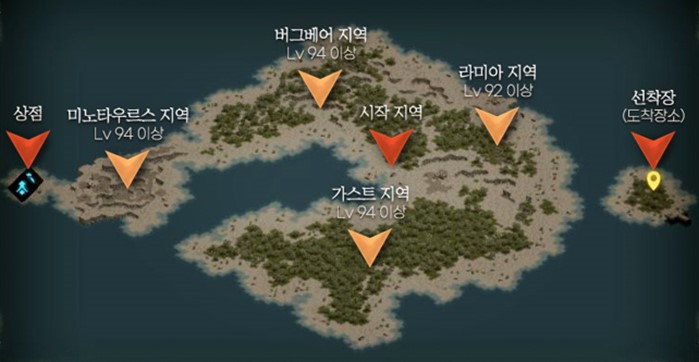
<그림1. 리니지 리마스터: 잊혀진 섬 개괄도>
<영상1. 실제 유저의 잊혀진 섬에서의 몬스터 사냥 플레이>
모델링: Markov Decision Process (MDP) 구성
먼저, 리니지에서 강화학습을 수행하기 위해서는 MDP에 대한 정의가 필요합니다. MDP란 강화학습을 하기 위해 필수적인 요소입니다. 핵심적인 부분으로는 “상태”, “행동”, “보상”이 존재합니다. 이에 대해 우리가 고민한 부분을 소개하겠습니다.
(1) 상태와 행동
우리는 AI 용병이 자신과 마스터 주변 상황 모두를 고려해 최적의 행동을 수행하기를 원했습니다. 따라서 “상태”를 단순히 하나의 항목이 아닌 여러 항목으로 나누어, 이들이 갖는 추상적 의미를 각각 학습할 수 있도록 하였습니다. 그리고 각 항목을 종합적으로 고려한 행동 선택을 기대했습니다. 이는 다음과 같습니다.
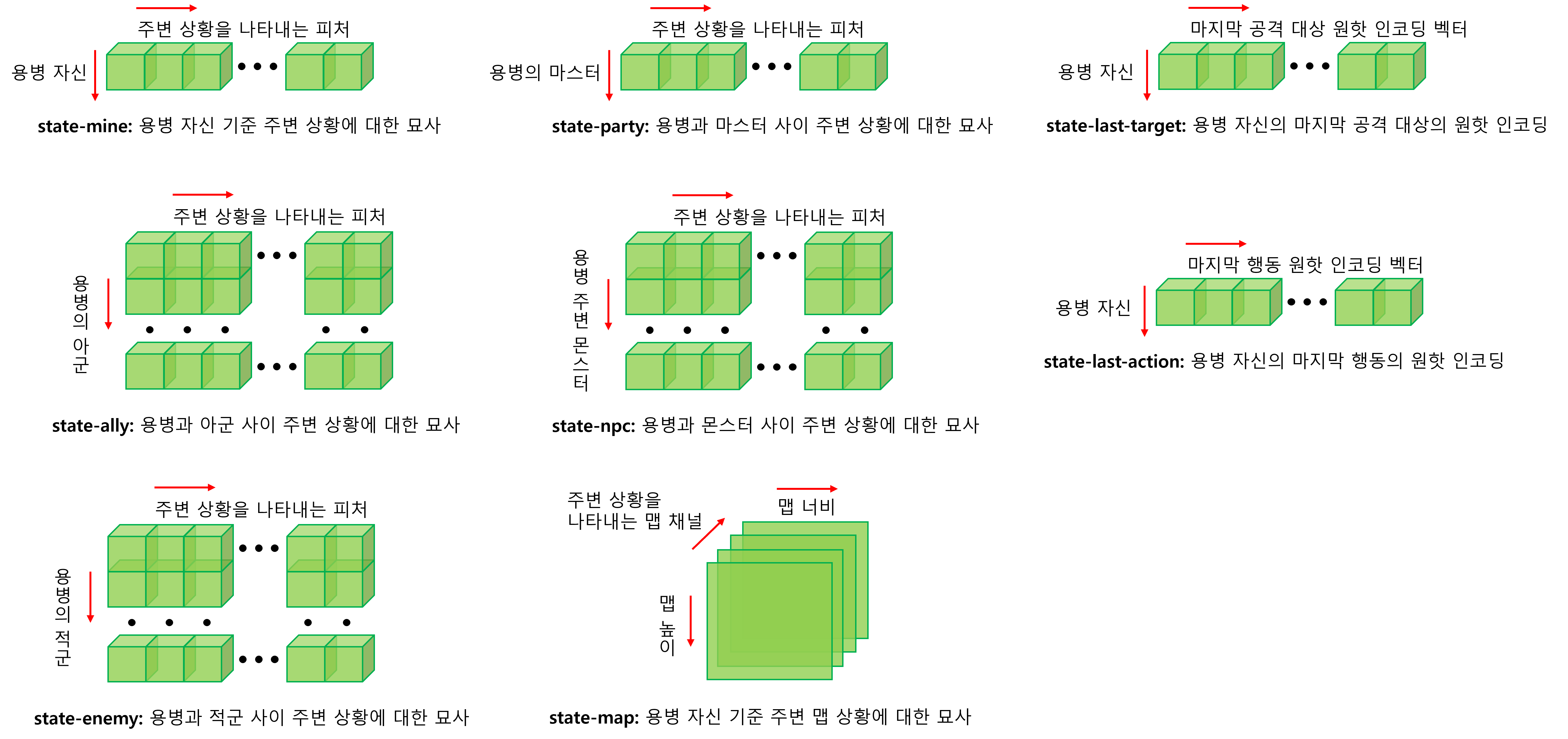
<그림2. 여러 상태 항목에 대한 이해를 돕기 위한 형상도>
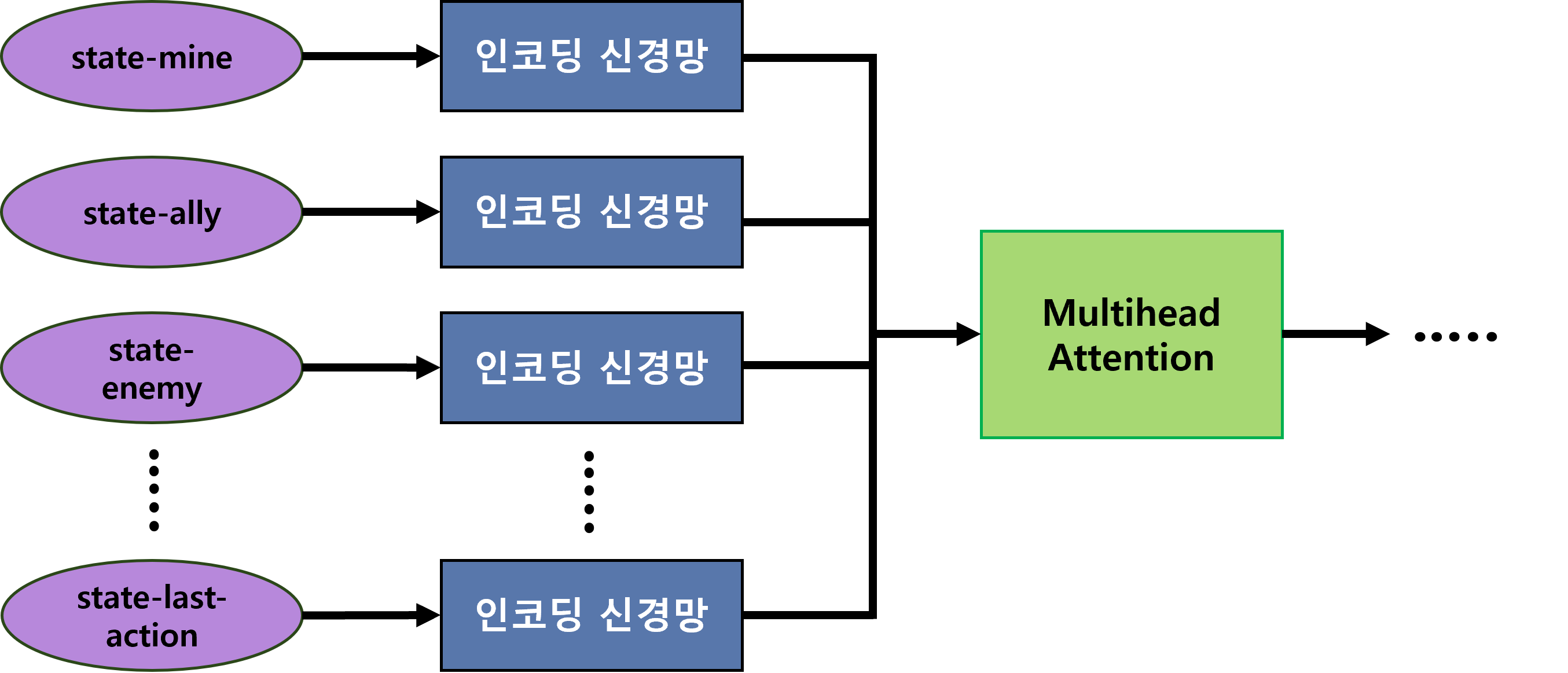
<그림3. Multihead Attention1을 통해 인코딩 된 세부 항목들을 종합적으로 고려>
위와 같이 구분한 입력 상태 항목들을 출력 “행동”으로 변환하기 위해, 우리는 계층적인 구조를 고려했습니다. 이는 리니지 게임 특성에서 비롯된 것으로 먼저 “어떤 행동”을 할 것인지 결정합니다. 그런 다음 이 행동을 “어떤 대상”에 수행할 것인지 결정합니다. 여기서 “어떤 행동”은 평타, 이동 또는 AI 용병이 사용할 수 있는 스킬을 의미합니다. 또한, “어떤 대상”은 상위 단에서 선택한 행동을 누구에게 가할 것인지를 의미하며 마스터와 용병 자신을 포함한 아군, 적군, 또는 몬스터가 존재합니다. 이런 계층적 구조를 사용해 “행동 공간”의 복잡도를 낮춰 학습 효율성을 향상할 수 있었습니다.
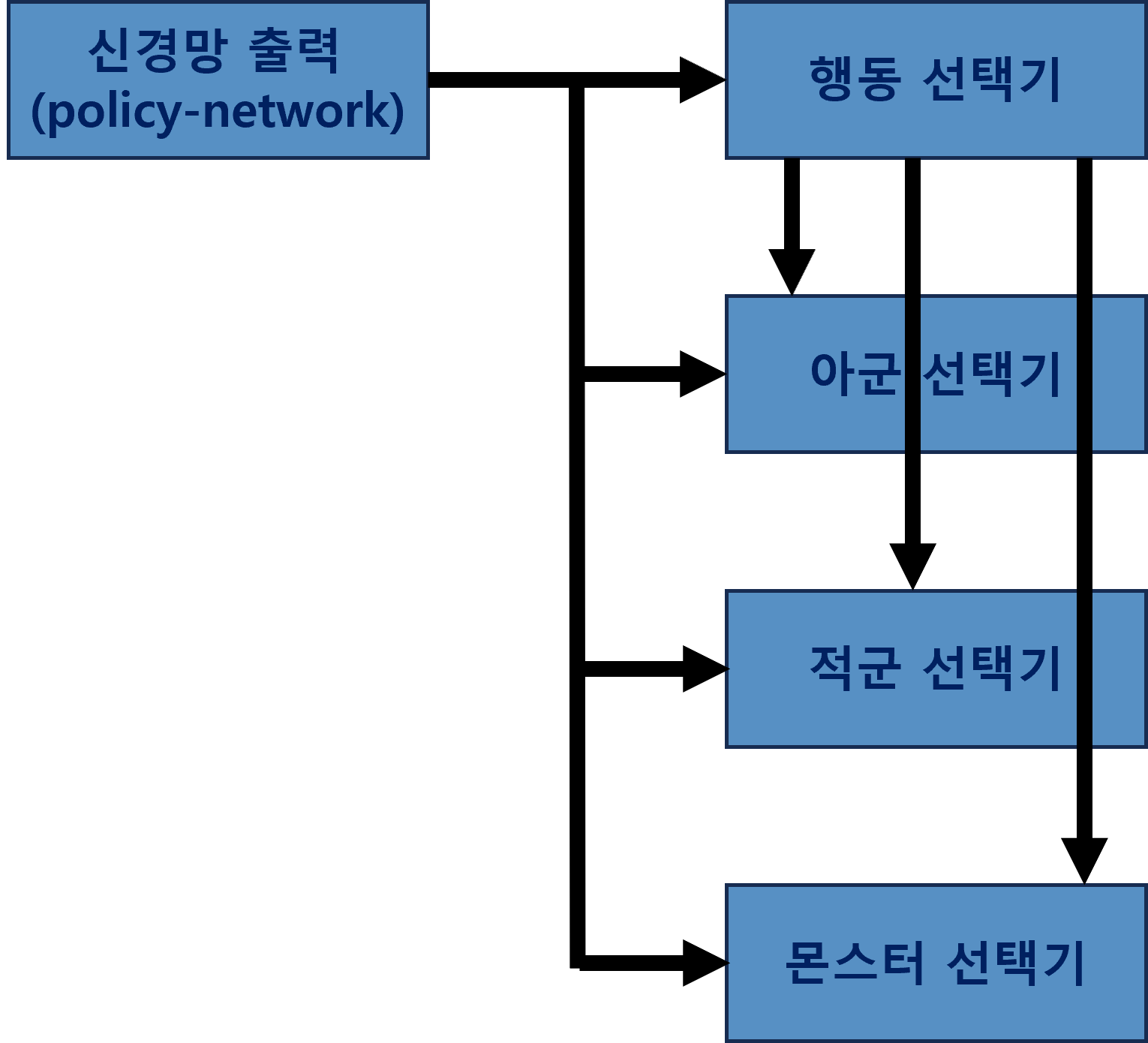
<그림4. 계층적 행동 선택기: 행동 선택 결과를 아군, 적군 몬스터 선택기 입력으로>
(2) 보상
이제 위에서 소개한 입력 상태를 최적의 출력 행동으로 학습하기 위해 필수적인 “보상”에 대해 우리가 고민한 내용을 소개하겠습니다.
연구에 따라 강화학습에서 보상에 대한 명시적인 정의가 필요한 경우가 있고, 그렇지 않은 경우도 있습니다. 아래 “알고리즘” 파트에서 설명하겠지만, 우리는 일반적인 model-free on-policy 방법을 취했습니다. 이에 리니지 환경에 종속적인 명시적 보상 함수에 대한 설계가 필요했고, 이는 다음과 같습니다.

<그림5. 보상 함수 설계 개략도>
AI 용병은 PvE와 PvP 모두에서 능통해야 하고, 동시에 마스터를 수호하는 역할을 맡았기 때문에, 여러 관련 보상 함수를 설계하였고, 이 함수들 간의 가중치를 학습 결과를 바탕으로 튜닝하였습니다.
Reinforcement Learning 방법론
(1) PPO 알고리즘
결론부터 말하자면, 우리는 강화학습 PPO2 알고리즘을 채택하였습니다. Value-based 강화학습 알고리즘들은 대체로 결정론적 특성을 띱니다. 이런 부분이 지도학습과 같이 입력 대비 정답이 비교적 명확한 환경에서는 잘 동작할지도 모릅니다. 즉, 빠른 학습의 수렴 혹은 고착화가 되어도 유리한 환경에서는 적합한 선택일 수 있으나, 정답이 불분명하고 다변하는 리니지 게임 환경에서는 좋은 선택이 아니었습니다.
그래서, 우리는 확률적으로 최선에 가까운 행동을 출력할 수 있는 Policy-based 강화학습 알고리즘을 선택하였습니다. 또한 아래 “Multi-Agent Reinforcement Learning” 파트에서 서술하겠지만, 오랜 시간 매우 많은 데이터를 학습해야 했기에, 학습 속도가 보수적이더라도 안정적인 학습 결과를 기대할 수 있는 PPO 알고리즘을 선택했습니다.
(2) Multi-Agent Reinforcement Learning
우리 프로젝트는 간단한 데모가 아닌 거대한 규모의 라이브 서비스 중인 게임 위에 구축하는 것이기 때문에, 리니지 게임 환경에서 리얼 타임을 넘어 시간 가속이 가능한 환경을 구현하는 일은 현실적으로 어려웠습니다. Model-based 강화학습에서 자주 언급되는 개념인 World model을 학습하여 물리적 학습 시간 제약에서 벗어나고자 하였으나, 우리가 원하는 수준까지 World-model이 실제 리니지 환경을 모사하기는 아직 어려웠습니다. 그 때문에 우리는 말 그대로 같은 시간에 더 많은 학습 데이터를 확보하기 위해 Multi-Agent Reinforcement Learning (이하, MARL) 방법론에 주목하였습니다.
우리가 사용한 방법은 크게 두 가지입니다. 하나는 시뮬레이터의 개수 자체를 늘리는 방법입니다. 일반적인 강화학습 방법이 단일 시뮬레이터를 학습에 사용한다면, 우리 AI 용병의 최종 학습 에이전트에는 약 800개의 시뮬레이터가 병렬적으로 동시에 학습에 사용되었습니다.
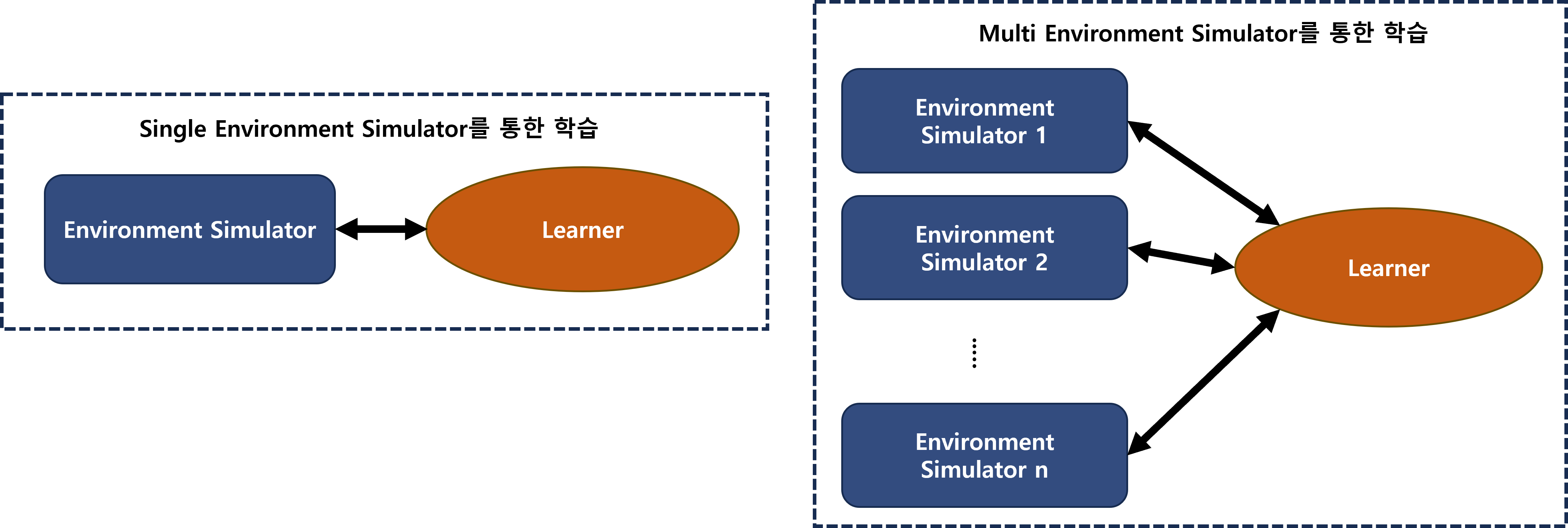
<그림6. Single Environment Simulator과 Multi Environment Simulator의 차이점: 동시에 학습에 병렬적으로 사용되는 시뮬레이터의 숫자>
두 번째는 하나의 학습 환경에서 다수의 학습 데이터를 생성한 방법입니다. 기본적으로 강화학습은 1회에 1개의 학습 데이터를 생성하게 되지만, 우리 환경에서는 1회에 최대 50개의 학습 데이터를 생성하였습니다. 이는 하나의 공유된 환경에서 동시에 다수의 AI 용병을 학습하였기 때문입니다. 즉, Batch Learning Data 생성을 하였습니다.
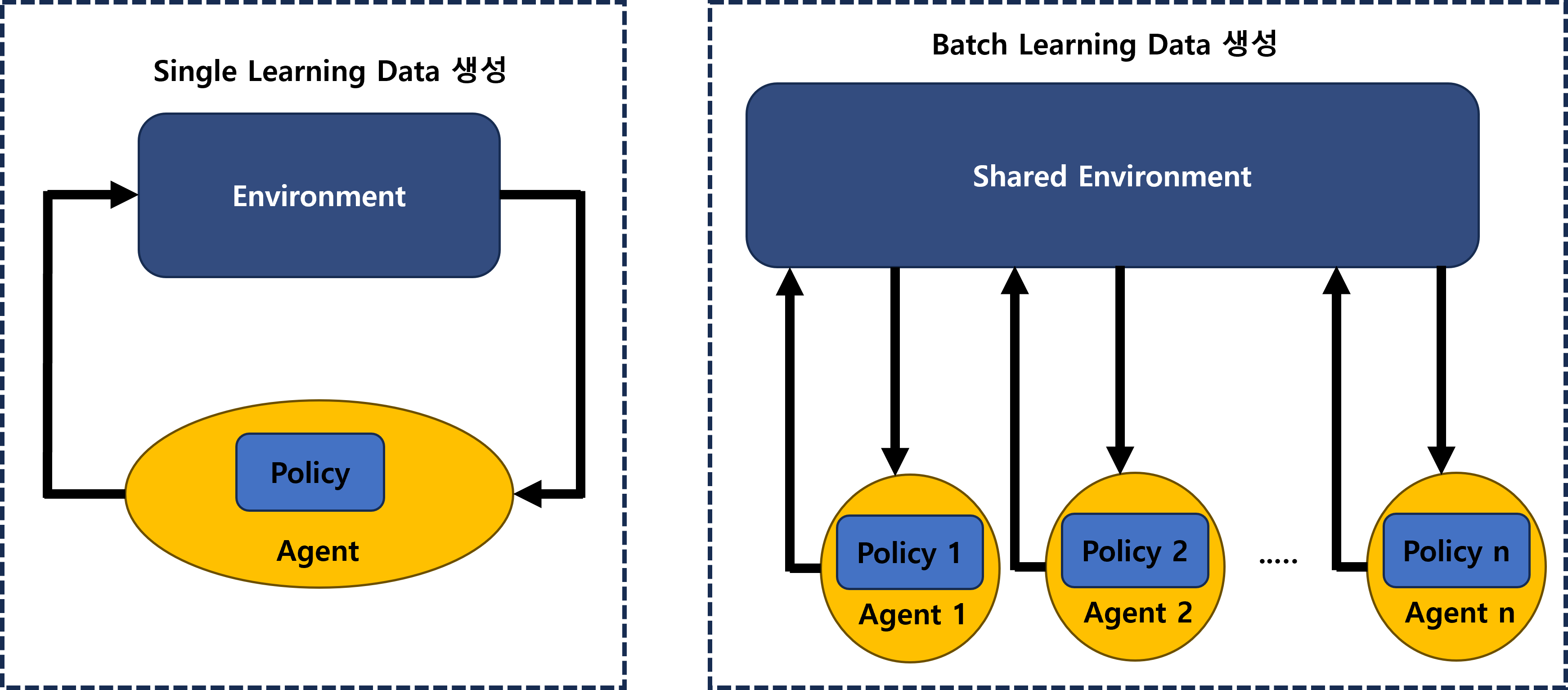
<그림7. Single Learning Data 생성과 Batch Learning Data 생성의 차이점: 한 환경에서 동시에 생성되는 학습 데이터의 숫자>
위 방법들을 통해 우리는 높은 학습 효율성을 달성할 수 있었고, 사용하지 않았더라면 몇 달이 걸릴지 모르는 학습 과정을 일주일 이내로 단축했습니다.
(3) Controllable Reinforcement Learning
앞서 언급했지만 우리 AI 용병은 PvP, PvE, 마스터의 수호뿐 아니라, 유저의 실시간 기호에 따라 “공격형”, “표준형”, “지원형” 성향으로 활동할 수 있어야 했습니다.
이를 위해 우리는 성향을 출력 부근 Layer의 입력으로 주었고, 각 성향에 따라 value-network 출력을 분기하였습니다. 또한 학습 과정에서 각 성향에 따라, 서로 다른 보상 함수 가중치를 사용해 “return”을 각각 연산하도록 했습니다. 이를 통해 성향에 매칭되는, value-network 분기를 명시적으로 학습하도록 유도하였습니다.
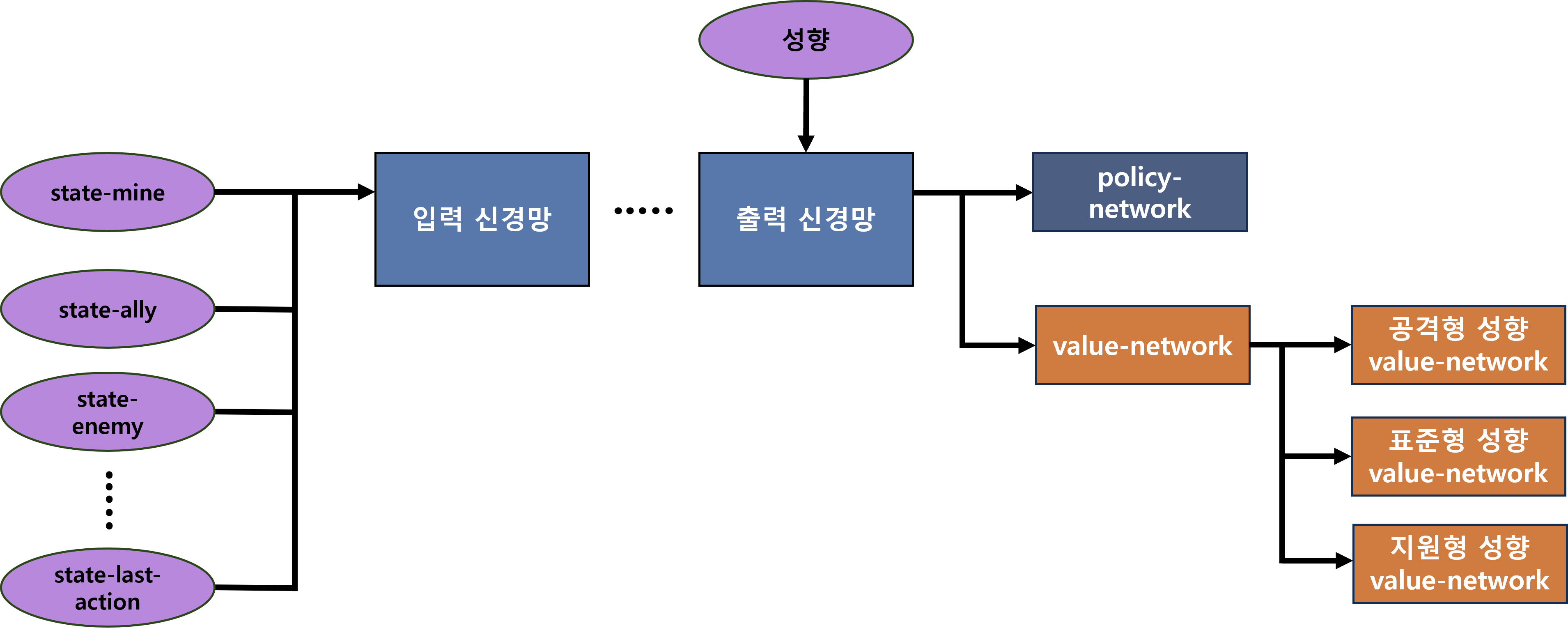
<그림8. Controllerable RL이 포함된 최종 신경망 개략도: 성향을 입력으로, 성향 별 value-network 출력을 갖음>
또한, 성향을 가중치 합 1 값을 갖는 인코딩 벡터로 변환 후, 이를 통해 가중 합 된 최종적인 GAE 값을 연산하였습니다. 이런 과정으로 각 성향에 대한 policy-network의 평가를 일반화하였습니다.
(4) Curriculum learning
우리 AI 용병 프로젝트는 리니지의 “잊혀진 섬”을 무대로 하였습니다. 이곳은 플레이어 간 PvP, 경험치 및 아이템을 획득하기 위한 PvE, 보스 몬스터 레이드, 낮과 밤에 따른 몬스터 종류 및 밀도 변화, 몬스터의 폭발적 스폰 (이하, 폭젠) 등에 의해 동적으로 다변하는 환경입니다.
<영상2. 잊혀진 섬, “폭젠” 상황: 늑대 몬스터가 동시다발적으로 스폰>
학습의 시작부터 종료까지 동일한 설정을 갖는 환경에서는 위와 같은 다양한 상황에 대처하기 어려웠습니다. 이에 우리는 “학습 커리큘럼”을 구축하는 것에 집중하였고, Learning Progress Based Curriculum Learning3 방법론을 선택하였습니다. 이 방법의 핵심 아이디어는 "이제 막 배우기 시작한 것을 더 많이 배울 수 있도록 하자"입니다.
우리는 아래와 같은 4가지 학습 시나리오를 설정하고, 여기에 기반을 둔 커리큘럼을 구성했습니다.
-
PvE Boss: NPC 없는 맵에서 보스 몬스터 레이드를 위한 시나리오
-
PvE Explosion: NPC 있는 맵에서 일정 확률로 폭젠을 발생시키고 생존을 위한 시나리오
-
PvP Only: NPC 없는 맵에서 PvP만 진행하는 시나리오
-
PvP With NPC: NPC 있는 맵에서 PvE/PvP 같이 진행하는 시나리오
커리큘럼의 핵심은 다음과 같습니다. 각 시나리오의 성공률을 바탕으로, 성공률 변화의 폭이 큰 시나리오를 우선으로 샘플링해서, 학습 대상으로 선정하였습니다. 이는 학습이 완료 단계에 있는 시나리오에 대한 샘플링은 줄이고, 아직 학습 개선의 여지가 남아있는 시나리오를 상대적으로 더 많이 샘플링하기 위함입니다.
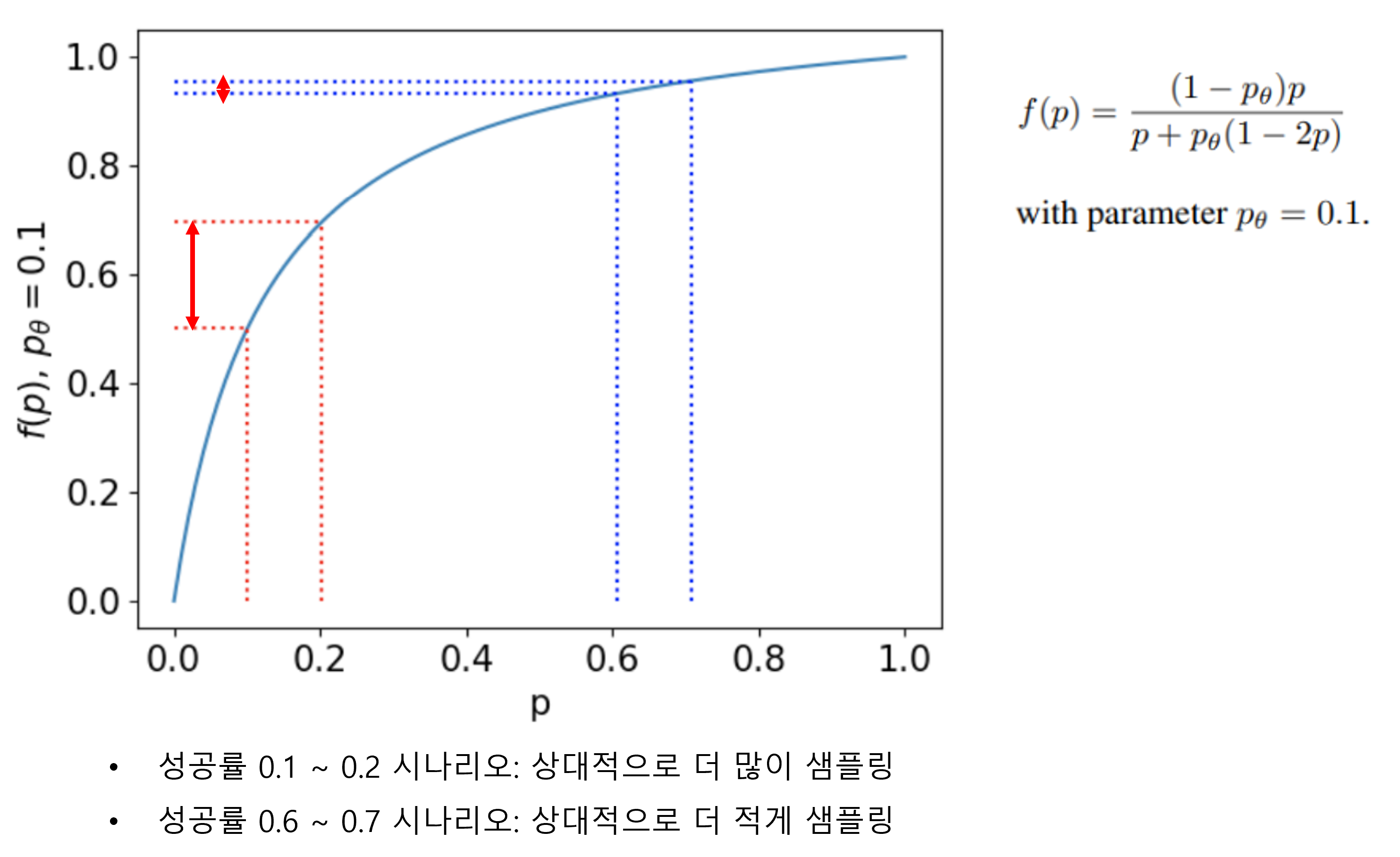
<그림9. Learning Progress Based Curriculum Learning: 성공률 기반 샘플링 척도 그래프>
(출처: https://arxiv.org/pdf/2106.14876.pdf)
마치며
지금까지 공유해 드린 우리 연구를 통해 출시한, AI 용병 프로젝트의 유저 반응을 소개합니다.

(출처: https://lineage.plaync.com/board/server/view?articleId=6540fa804d4b41052a104e24&categoryId=5ec50d7c82915c0001ace1bd)

(출처: https://lineage.plaync.com/board/free/view?articleId=654bd0a2c922af56a5d59e52)
(출처: https://www.youtube.com/watch?v=LhutCkBRLTo)
장기적으로 발전하는 AI 용병이 되었으면 좋겠다는 점과 몬스터 사냥의 재미 및 효율성을 언급해 주신 유저 피드백을 통해 좋은 서비스를 제공하고 있다는 보람을 느낄 수 있었습니다.
본 글에서는 언급하지 않았지만, 우리가 서비스한 AI 용병은 “기사”, “마법사” 클래스로 제한이 있었는데요, 한 유저분이 말씀해 주신 것처럼 기회가 닿는다면 더 다양한 클래스의 용병을 제공해 드리고 싶습니다.
지금까지 NC에서 성공적으로 라이브 서비스 출시를 완료한 “리니지 리마스터: 잊혀진 섬 AI 용병” 프로젝트에 대한 핵심적인 연구 경험을 공유해 드렸습니다. Game AI와 강화학습에 관심이 많은 분께 도움이 되었으면 좋겠습니다.
