
작성자
- 정지년(Intelligent Agent Lab)
- 사람의 의사 결정을 대신해 주는 Agent를 통해 가치를 만들어 내는 가치 창출자 입니다.
이런 분이 읽으면 좋습니다!
- 게임에 PVP AI 컨텐츠를 어떻게 만들었지 궁금하신 분
- 강화학습을 상용 게임에 적용하기 위한 핵심 노하우를 알고 싶은 분
이 글로 확인할 수 있는 내용
- 게임에 PVP AI를 만들 때 경험하게 되는 기술적 이슈와 해결 방안
- Multi-agent Reinforcement Learning의 게임 적용 사례
NC Research 블로그에 올릴 글을 요청받았을 때, 어떤 이야기를 해 드리면 좋을지 골똘히 고민했습니다. 이론적인 이야기는 다른 곳에서 접하실 수 있을 테니, 여기에는 우리가 Game에서 AI를 만들어 온 경험담을 들려 드리는 게 좋겠다는 생각이 들었습니다. 저희와 비슷한 길을 걷고자 하시는 분들에게 지금부터 적어가는 이야기가 도움이 되었으면 합니다. 😊
Ep1. Blade & Soul 비무 AI 연구개발 이야기
→ 1:1 PVP 로 사람과 놀아주는 AI 만들기
“어떻게 하면 AI로 게임을 더 재미있게 만들 수 있을까?”
엔씨에서 AI를 연구하면서 우리의 머릿속에 늘 맴돌던 질문이었습니다. 거기에 우리가 내린 대답은 “사람과 재미있게 놀아 주는 AI를 만들자!”였습니다. 이런 맥락에서 우리가 처음으로 타깃으로 잡은 “놀아주는 AI”는 바로 Blade & Soul의 PvP 콘텐츠인 비무에서 함께 놀아주는 비무 AI(그림 1)였습니다. Blade & Soul은 탄탄한 스토리와 고품질 그래픽을 자랑하는 엔씨의 무협 액션 MMORPG입니다. 여기서 즐길 수 있는 비무 컨텐츠는 다양한 개성을 가진 캐릭터들이 원형 경기장에서 1:1 PvP를 즐기는 것인데요. 정교한 이동 조작과 상성 관계를 가지는 스킬을 적절히 구사하여 상대방의 HP를 0으로 만드는 쪽이 승리합니다. 대전 격투 액션게임 같은 긴장감 넘치는 재미가 돋보이는 컨텐츠이지요.

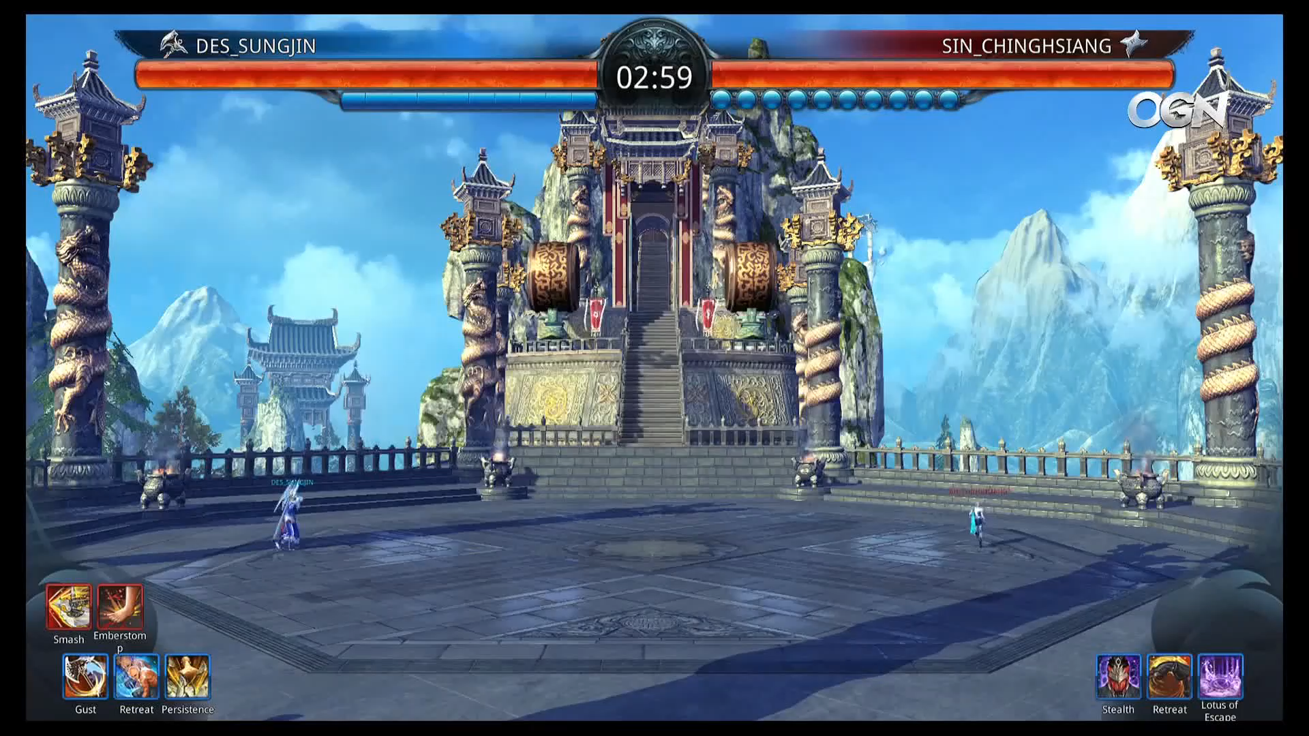 그림 1. Blade & Soul의 비무
그림 1. Blade & Soul의 비무
하지만 컨텐츠의 재미와는 별개로, 플레이어들은 사람과 비무를 하는 데 부담감을 안고 있었습니다. 비매너 플레이어를 만나서 불쾌한 경험을 하게 된다거나, 랭크의 등락으로 인한 승패 결과가 큰 부담이었죠. 그래서 우리는 사람과 비무를 할 때 느끼는 부담감은 덜어내면서도, 비무 본연의 재미는 놓치지 않는 AI를 만들기로 했습니다.
“사람과 우열을 가리기 힘든 비무 실력을 갖춘 AI를 만들어서
사람과 싸운다는 부담감 없이도
사람과 비무를 하는 것 같은 짜릿한 재미를 주자!”
우리는 다부진 포부와 함께 비무 AI 연구개발 여정을 시작했습니다.
험난한 여정의 시작
놀아주는 AI를 만들겠다는 우리의 포부는 시행착오로 가득한 험난한 여정에 직면하였습니다. AI가 사람과의 비무를 그럴싸하게 펼치기 위해서는 나와 상대의 위치, 상태, 그리고 상대의 전략에 따라 최적의 행동을 결정하고 실행해야 합니다. 비무 중 경험하게 되는 상황이나 상태가 다양하고 그에 따른 이동 및 스킬 선택지도 많아 한판의 비무에서 찾아야 할 Action space의 복잡도는 \(10^{1800}\) 으로 어림짐작 되었습니다. 바둑의 Action 복잡도가 \(10^{170}\) 수준임을 감안할 때 “탐색” 기반의 방법으로 비무 의사 결정을 하는 것은 부적절하다고 판단되었습니다. 따라서 우리에게는 다른 방식의 좀 더 효율적인 접근 방법을 취할 필요가 있었습니다. 가장 먼저 시도한 방법은 플레이어들의 플레이 로그를 이용하여 지도학습으로 비무 AI를 만드는 것이었습니다. 사람처럼 플레이하려면 “사람의 플레이”로부터 배우면 된다는 직관적인 접근 방법이었습니다. 쌓아 둔 플레이어들의 비무 로그에 대한 지도학습을 통해 플레이어들의 플레이 패턴을 비슷하게 흉내를 낼 수 있었고, 스크립트 기반 AI에 대해 82%의 승률을 보이는 비무 AI를 만들 수 있었습니다. 그러나, 이 정도 AI는 저와 같은 하급 플레이어 상대는 압도하였지만, 좀 할 줄 아는 플레이어에겐 어림도 없는 수준이었습니다. 특히 다양한 플레이어의 데이터를 학습에 사용하다 보니, 그저 그런 평균적인 수준의 비무에 그칠 뿐이었고, 빈틈도 여전히 많았습니다. 우리는 뭔가 다른 방법이 필요하다는 것을 깨닫게 되었습니다.
당시 우리는 “지도학습”과 더불어 “강화학습”을 통해 비무 AI를 만드는 시도를 하고 있었습니다. 당시는 DQN이 Pong, Breakout 등과 같은 게임에서 놀라운 성능을 보여, 비무 AI에 대한 학습도 이와 같은 연구를 참고하여 진행하고 있었습니다. 그러나 생각만큼 비무는 학습이 잘되지 않았고, 수많은 시행착오 끝에 막 등장한 따끈따끈한 연구 논문이었던 Prioritized DDQN을 통해 규칙 AI를 99%의 승률로 이길 수 있도록 만들 수 있었습니다.
‘이제 사람을 이길 수 있을까?’ 기대감을 품고 휴먼 테스트를 진행하였지만, 결과는 큰 실망으로 다가왔습니다. AI는 치명적인 허점을 가지고 있었고, 사람은 이를 이용하여 쉽게 승리할 수 있었습니다. 심지어 앞에서 “지도 학습”으로 만든 AI보다 못 싸운다는 피드백도 받았습니다. 학습된 AI는 그저 규칙 AI만을 이기는 법을 배웠을 뿐이고, 규칙 AI와 다른 방식으로 싸우는 사람에게는 전혀 대응하지 못하였던 것이었습니다.
마감 한 달을 남겨두고 찾아낸 개선방법
그래서 우리는 이 문제를 해결하기 위해 Self-play Learning을 통해 규칙이 아닌 수많은 과거의 자신을 이기는 법을 배울 수 있도록 학습 커리큘럼을 개선하였습니다. 그러나 Prioritized DDQN은 두 명 이상의 과거의 자기 자신은 이기는 법을 학습시키지 못하였고, 연구는 다시 난관에 빠지고 말았습니다. Blade & Soul 비무는 다양한 상성을 가진 전략으로 싸울 수 있었기에 비무를 하는 AI 입장에서는 매우 불안정한 확률(non-stationary)적 특성을 가진 환경이었습니다. Deterministic한 알고리즘인 DQN 계열의 강화학습 알고리즘은 이런 환경에 적합하지 않았던 것이었고, 저희에게는 이런 환경에서 안정적으로 학습될 수 있는 알고리즘이 필요했습니다. 이런 환경에는 stochastic policy를 채용하고 있는 A2C, A3C와 같은 Actor Critic 계열의 알고리즘이 적합하였지만, 이것으로는 충분하지 않았습니다. 왜냐하면 우리가 비무 AI를 만들고 있는 Blade & Soul은 강화학습 연구에 흔히 사용되는 Atari 게임 환경과 같이 마음대로 게임 시스템을 멈출 수 있는 환경이 아니었고, 이로 인해 게임에서 데이터(trajectory) 수집에 사용된 Behavior policy와 병렬적으로 실행 중인 학습 프로세스에서 업데이트 중인 target policy간에 “시간차(policy lag)”가 발생하여 policy가 올바르게 최적화되지 못하고 있던 것이었습니다.
그러나, 뜻이 있는 곳에 길이 있다고 했던가요. 프로젝트를 세상에 공개하기로 정해진 기간을 1달여 남겨 두고 절박하게 답을 찾아 헤매고 있던 우리에게 극적으로 Publish 된지 얼마 안 된 ACER라는 강화 학습 방법이 발견되었습니다. 이 논문에서는 앞에서 설명한 policy lag을 보상하기 위해 importance sampling을 Actor Critic에 적용하는 방법을 제안하고 있었고, 이 학습 방법을 통해 멈출 수 없는 환경인 Blade & Soul에서 불안정적인 확률적 환경의 원인인 다양한 과거의 자기 자신을 이길 수 있는 비무 AI가 학습되도록 만들 수 있었습니다. 우리의 문제 해결 과정은 아무도 가보지 않은 길을 갔기에 거칠 수밖에 없었던 시행착오로 가득했지만, 우리는 이 경험을 통해 논문 속의 기술로 놀아 주는 AI란 “현실의 가치”를 창출할 수 있다는 자신감을 얻게 되었습니다.
AI가 프로게이머를 이길 수 있을까?
다양한 자기 자신을 이기는 법을 학습한 우리의 비무 AI는 사내 고수쯤은 아주 쉽게 이기는 모습을 보여 주었습니다. 이에 고무된 우리는 아예 “프로게이머”와 싸워도 이길 수 있지 않을까 기대하게 되었고, 기대를 저버리지 않고 이어진 사내 테스트에서 초청된 프로게이머도 압도하는 모습을 보여 주었습니다. 자신감을 안고 우리는 “World Championship”에 Blind match라는 공개 이벤트에 우리 비무 AI를 내보내게 되었습니다.
 그림2. Blade & Soul World Championship Blind match 에 출전한 비무 AI
(DES_KnightJ와 프로게이머 Parkinson 선수와의 비무 장면)
그림2. Blade & Soul World Championship Blind match 에 출전한 비무 AI
(DES_KnightJ와 프로게이머 Parkinson 선수와의 비무 장면)
세상은 넓고 고수는 많다고 하였던가요. World Championship에 출전한 고수들의 실력은 예상 이상이었습니다. 압도적일 것이라는 예상과 달리 결과는 3승 4패로 비등한 수준의 결과를 보여주었습니다. 너무 일방적으로 이길 것을 걱정하며 “놀아주는 AI”의 취지를 더욱 살리고자 가장 강력했던 “공격형” 외에 “밸런스형”, “수비형”의 세 가지 비무 AI를 내보냈던 우리는 다시 한번 사람의 능력에 감탄하며 더 연구 개발에 매진해야겠다고 다짐하였습니다
Next Step : 팀플레이 AI 연구개발의 꿈
이제 1대 1 PVP를 통해 사람과 놀아주는 AI를 만든 우리는 이제 다음 단계를 바라보고 있었습니다. 바로 MMORPG에서 사람과 놀아 주는 AI, 즉 팀플레이를 통해 사람과 놀아주는 AI였습니다.
(Blade & Soul의 비무 AI 개발에 관한 더 자세한 이야기가 궁금하신 분들은 https://arxiv.org/abs/1904.03821, https://www.gdcvault.com/play/1025904/Reinforcement-Learning-in-Action-Creating 에서 더 많은 정보를 얻으실 수 있습니다. )
Ep2. 리니지 리마스터 거울전쟁 연구개발 이야기
→ 팀플레이로 사람과 놀아주는 AI 만들기
팀플레이를 하는 AI를 만들고자 하는 우리에게 좋은 기회가 찾아왔습니다. 리니지 리마스터에 플레이어 세력과 AI 세력이 기란 감옥 2층의 통제를 놓고 벌이는 싸움을 주제로 한 “거울전쟁”이란 이름의 AI 컨텐츠를 만들 기회가 생긴 것이었습니다.
팀플레이 하는 AI를 강화학습으로 만들기 위해 해결해야 했던 문제들
MMORPG는 팀플레이를 실현하기에 안성맞춤인 환경이었고, 이는 저희에게 아주 좋은 기회였습니다. Blade & Soul 비무 AI를 만들면서 터득한 노하우를 거울전쟁에 확장 적용하기 위해 우리는 해결해야 할 문제를 분석하고 실용적 해법을 찾고자 하였습니다. 거울 전쟁을 위해 팀플레이를 하는 AI를 강화학습으로 만들기 위해서는 다음과 같은 1 대 1 PVP에는 없었던 몇 가지 문제들을 해결해야 했습니다.
- 여러 명의 아군 캐릭터를 동시에 컨트롤해야 한다.
- 이동, 스킬 사용 외에 타게팅 의사 결정이 필요하다.
- MMORPG의 특성상 함께 등장하는 아군과 적군 수가 가변적이다.
- 자신에게는 손해이더라도 팀 전체 입장에서 이로운 플레이를 할 줄 알아야 한다.
 그림3. Single Agent RL 문제와 Multi-agent RL 문제의 차이: Multi-agent RL의 경우 환경이 다른 Agent에 의해 변화하므로 다른 Agent들의 Policy에 따라 최적 Policy가 달라진다.
그림3. Single Agent RL 문제와 Multi-agent RL 문제의 차이: Multi-agent RL의 경우 환경이 다른 Agent에 의해 변화하므로 다른 Agent들의 Policy에 따라 최적 Policy가 달라진다.
MARL 방법론 선택
이와 같이 여러 명의 Agent를 Control하는 강화학습 문제를 Muti-agent Reinforcement Learning(MARL) 문제(그림 3 참조)라고 하며 지금도 활발하게 연구되고 있는 분야입니다. 저희는 다양한 MARL 방법 중에 우리에게 맞는 방법을 적용하고 개선하고자 했습니다. 그러나 당시 QMIX와 같이 학술적으로 관심을 끌고있는 MARL 방법들은 “고정된 개수”의 Agent를 가정하고 있었기 전투에 등장하는 캐릭터의 수가 정해져 있지 않은 우리에게 적합한 방법은 아니었습니다. 그래서 저희는 QMIX와 같이 하나의 Policy가 여러 캐릭터의 Action을 동시에 결정하는 방식이 아닌, 여러 캐릭터가 Policy를 공유하고 각 캐릭터를 순회하여 Action을 결정하는 방식을 취했습니다. 더불어 각 Agent에 입력으로 주어지는 State를 Ego-centric하게 표현(주변 환경을 의사 결정 주체를 중심으로 정규화하여 표현)되도록 하였습니다. 이러한 방식은 컨트롤해야 하는 캐릭터 수가 바뀌는 경우에도 문제없이 작동할 뿐 아니라, Policy를 공유하므로 학습에 필요한 경험(Trajectory)을 확보하는 측면에서도 유리합니다.
타게팅과 팀플레이 유도
비무 AI에서는 필요 없었던 타게팅 문제는 Attention Layer를 적용해 해결하였습니다. 즉, 나의 상태를 표현한 Latent vector와 Skill Decision을 Key로 하여 타게팅 대상이 되는 Agent의 State embedding에 대해 정합도를 계산하고 정합도에 따라 확률적으로 그 스킬의 대상이 되는 적군(또는 아군)을 선택하도록 하였습니다.
팀플레이를 유도하기 위해 Agent 자신이 적을 공격하고 죽일 때 받는 보상뿐 아니라 아군이 적을 성공적으로 죽이거나 공격에 성공했을 때도 보상을 일부 받도록 하여 팀워크를 학습할 수 있도록 하였습니다.
“이동”학습시키기
추가적으로 “이동”의 효과적인 학습을 위해 우리는 Macro move를 정의하여 이를 학습하도록 하였습니다. 이상적으로는 8방향의 기본적인 이동만으로 다양한 전략적인 이동을 학습하는 것이 바람직합니다. 그러나 상용 게임 컨텐츠의 개발 일정상 학습에 긴 시간을 할애할 수 없기에 학습 복잡도가 높은 이동의 경우 8방향의 조합을 통해 유의미한 이동 전략을 학습하는 방식은 적용하기 어렵습니다. 저희는 “타겟으로 다가가기”, “도망가기”, “전략적 후퇴” 등 action의 의미와 효과가 명확한 macro move를 정의하고 이를 policy의 action으로 선택할 수 있도록 하여 상황에 따라 적절한 macro move를 학습할 수 있도록 하였습니다. 덕분에 우리는 다양한 레벨, 클래스, 개체수, 스펙 등의 조합이 존재하는 다대다 PVP 환경에서 사람과 비등하게 싸울 수 있는 AI를 2주 안에 학습될 수 있도록 만들 수 있었습니다.
이렇게 만들어진 팀플레이 PVP AI는 리니지 리마스터에서 “거울 전쟁(그림 4)”, “전설대현역(그림 5)”, “무한대전:이계침공(그림6)”이라는 컨텐츠로 출시되어 AI와의 다대다 PVP의 즐거움을 경험할 수 있도록 해 드렸습니다.
 (좌→우 순으로 그림4, 그림5, 그림6)
그림4. 거울 전쟁: AI 혈맹 세력이 기란 감옥 2층 통제를 시도하며 플레이어들과 치열한 싸움을 벌인다.
그림5. 전설대현역: 각 서버 최강 혈맹과 AI 혈맹의 3판 2승의 콜로세움 대전
그림6. 무한대전:이계침공: 인던의 최종 보스 대신 갑작스럽게 AI 혈맹이 등장하여 플레이어들을 습격한다.
(좌→우 순으로 그림4, 그림5, 그림6)
그림4. 거울 전쟁: AI 혈맹 세력이 기란 감옥 2층 통제를 시도하며 플레이어들과 치열한 싸움을 벌인다.
그림5. 전설대현역: 각 서버 최강 혈맹과 AI 혈맹의 3판 2승의 콜로세움 대전
그림6. 무한대전:이계침공: 인던의 최종 보스 대신 갑작스럽게 AI 혈맹이 등장하여 플레이어들을 습격한다.
Next Step: 이제 적이 아닌 “동료”로서 AI로
그리고, 이제 우리는 처음에 우리가 가졌던 목표, “놀아 주는 AI”의 색다른 즐거움을 느끼실 수 있도록 나의 적으로서 싸우는 AI가 아닌, “내 편이 되어 함께 싸워 주는 AI”를 목표로 연구를 진행하고 있습니다. 곧 세상에 나올 예정이니 많은 기대와 관심 부탁드립니다.
(거울 전쟁, 전설대현역 AI 개발과 관련된 더 자세한 이야기는 여기에서 확인해 주세요: https://www.gdcvault.com/play/1027645/AI-Summit-Multi-Agent-Reinforcement )
References
-
DQN: https://www.nature.com/articles/nature14236
-
Prioritized DDQN: https://arxiv.org/abs/1710.02298
-
ACER: https://arxiv.org/abs/1611.01224
-
QMIX: https://arxiv.org/abs/1803.11485
-
Attention Layer: https://arxiv.org/abs/1706.03762
