
- 4D Scan의 핵심 파이프라인
- 1. Image Capture
- 2. 3D Mesh Reconstruction
- 3. Sequential Tracking
- 사실적인 인물을 표현하기 위한 여정
작성자
- 윤두밈(Graphics AI Lab)
- 자연스러운 사람의 얼굴 모션을 캡처하는 일을 하고 있습니다.
이런 분이 읽으면 좋습니다!
- 3D 그래픽스에서 사실적인 인물을 표현할 때, 얼굴의 움직임에서 어색함을 느끼고 이를 해소하고자 하는 연구자
이 글로 확인할 수 있는 내용
- 3D 그래픽스에서 자연스러운 사람을 표현하기 위한 3D Scan 및 4D Scan 기술에 대해 소개합니다.
(1부에서 이어집니다.)
4D Scan의 핵심 파이프라인
4D Scan파이프라인은 여러 기술 단계로 구성됩니다. 해당 내용을 모두 다루기에는 그 범위가 넓기에 여기서는 그 중 핵심이 되는 세 가지 단계인 연속적인 프레임의 이미지를 촬영하는 ‘Image Capture’ 단계와 이미지 기반으로 3D 그래픽스에서 사용되는 Mesh로 복원하는 ‘3D Mesh Reconstruction’ 단계, 마지막으로 프레임별 Mesh를 연결해 주는 ‘Sequential Tracking’ 단계의 각 과정에 관해서 설명하도록 하겠습니다.
 그림 4. Image Capture 단계에서 촬영한 이미지(좌)와 이 이미지를 기반으로 3D Mesh Reconstruction 단계에서 생성한 3D Mesh
그림 4. Image Capture 단계에서 촬영한 이미지(좌)와 이 이미지를 기반으로 3D Mesh Reconstruction 단계에서 생성한 3D Mesh
1. Image Capture
일반적으로 3D Scan의 경우, 사람의 여러 가지 표정을 각각 찍고 3D 그래픽스에서 주로 사용되는 Mesh 형태로 3D 복원을 수행하게 됩니다. 이때, 하나의 표정에 대한 빛 반사에 따른 변화 정보를 획득하기 위해 짧은 시간 내에 여러 각도로 빛을 조사하면서 촬영합니다. 이때 촬영에 사용되는 고해상도 카메라는 조명과 동기화되어 여러 장을 연속 촬영을 하는 과정을 거치게 됩니다. 조명이 360º로 둘러싸인 Light Stage(그림2) 가 이러한 촬영 장비 중 하나입니다. 다만, 여기서 말하는 짧은 시간이란 수초 정도의 시간입니다. 배우는 촬영이 진행되는 동안 최대한 얼굴을 움직이지 않고 해당 표정으로 고정하고 있어야 하며, 움직임이 발생하면 재촬영하거나 보정을 통해 3D 복원을 진행해야 합니다.
이러한 방식으로는 고품질의 3D Scan은 달성할 수 있지만, 1초당 60번 이상 촬영을 수행해야만 하는 4D Scan에서는 적용 불가능한 방식입니다. 따라서 4D Scan 기술을 달성하기 위해서는 몇 가지 조건을 만족시켜야 하는데, 예를 들어 1밀리초 (1,000분의 1초) 미만의 오차로 촬영 동기화가 이루어지는 카메라와 단 하나의 이미지 세트에서부터 3D 복원이 가능한 기술 등이 필요합니다.
첫 번째 조건인 동기화를 만족시키기 위해서는 머신비전 카메라가 사용되곤 하는데, 필요한 카메라의 개수는 복원 기술에 따라 달라질 수 있습니다. 예를 들어 Meta에서 제공하는 Multiface 데이터셋의 경우, 160개의 컬러 카메라를 사용하여 촬영하였고 이를 바탕으로 3D 복원을 진행하였습니다. 반면, Disney에서 발표한 연구에서는 단지 14개의 컬러 카메라를 촬영에 사용하고 Meta와는 다른 방식의 기술로 3D 복원을 진행하였습니다. 이처럼 하드웨어는 기본적으로 고성능의 많은 수의 카메라를 사용하는 게 품질 향상에 이득이 되는 측면이 있지만 그 외에도 이미지를 기반으로 하는 3D 복원 기술이 무엇이냐에 따라서도 달라질 수 있습니다.
 그림 5. Meta의 4D Scan 시스템 Mugsy v2
(출처 : https://arxiv.org/pdf/2207.11243.pdf)
그림 5. Meta의 4D Scan 시스템 Mugsy v2
(출처 : https://arxiv.org/pdf/2207.11243.pdf)
 그림 6. Disney의 4D Scan 시스템
(출처 : https://studios.disneyresearch.com/app/uploads/2022/07/Facial-Hair-Tracking-for-High-Fidelity-Performance-Capture.pdf)
그림 6. Disney의 4D Scan 시스템
(출처 : https://studios.disneyresearch.com/app/uploads/2022/07/Facial-Hair-Tracking-for-High-Fidelity-Performance-Capture.pdf)
2. 3D Mesh Reconstruction
이미지로부터 3D 복원을 수행하는 방법은 기존 3D Graphics에서도 자주 사용되는 방법들이 있는데, 크게 두 가지로 구분하자면, 단 하나의 카메라를 사용하는 싱글 카메라 기반의 Structure From Motion(이하 SFM) 과 여러 카메라를 사용하는 스테레오 기반의 Multi-View Stereo(이하 MVS) 방식으로 구분할 수 있습니다.
이러한 알고리즘들은 목적이나 촬영 하드웨어에 종속적인 경우가 일반적인데요. SFM 방식은 카메라를 하나만 사용하기 때문에 정지한 물체를 다각도로 촬영하고 3D 복원하는 목적으로 주로 사용되며, 12개의 카메라를 사용하는 디즈니의 경우 한 쌍의 스테레오 이미지로부터 3D 위치를 추정하는 방식을, 이와 다르게 160개의 카메라를 사용하는 Meta는 다중 카메라 기반의 MVS 방식을 사용합니다.
기본적인 복원 방법은 공통으로 2차원의 스테레오 평면 이미지로부터 3D 공간의 위치를 추정하는 방법인 삼각 측량의 원리가 사용됩니다. 3차원 공간에서 하나의 원점을 이미지로부터 추정하기 위해서는 두 평면 이미지에 투영된 지점을 각각 찾고, 투영된 지점의 차이로부터 원래 위치를 추정하는 방식을 사용하는데요. 사진 자체에도 다양한 왜곡과 누락된 정보가 포함되어 있어 카메라 캘리브레이션 및 원점과 투영점을 잇는 Epipolar Line을 획득하는 등의 사전 작업이 있고 나서야 추정이 가능합니다.
이러한 방법 외에도 지점마다 모든 Epipolar Line을 계산하는 방법은 연산 시간이 오래 걸리기 때문에, 이를 단축하기 위해 역으로 Epipolar Geometry로부터 이미지를 변형하여 평행을 맞추는 Rectification 과정을 거쳐 추가적인 Epipolar Line 연산 없이 추정이 가능한 방법 또한 자주 사용됩니다.
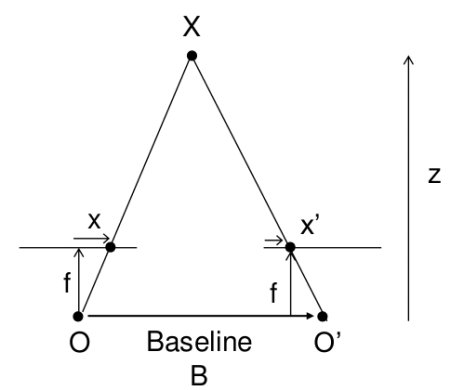 그림 7. Rectification 이후 평행 상태에서의 시차(disparity)를 계산하는 접근법
(출처 : https://docs.opencv.org/3.4/dd/d53/tutorial_py_depthmap.html)
그림 7. Rectification 이후 평행 상태에서의 시차(disparity)를 계산하는 접근법
(출처 : https://docs.opencv.org/3.4/dd/d53/tutorial_py_depthmap.html)
 그림 8. Epipoalr Line을 찾아 비교하는 접근법
(출처 : https://docs.opencv.org/3.4/da/de9/tutorial_py_epipolar_geometry.html)
그림 8. Epipoalr Line을 찾아 비교하는 접근법
(출처 : https://docs.opencv.org/3.4/da/de9/tutorial_py_epipolar_geometry.html)
촬영 이미지에는 카메라 렌즈에 의한 왜곡 외에도 노이즈, 노출, 반사광, 화이트 밸런스 등 다양한 원인으로 인해 정보가 왜곡될 수 있습니다. 따라서 이를 보완하기 위한 다양한 방법들을 추가로 사용할 수 있으며 고성능 카메라로 변경하거나 카메라의 대수를 늘리는 것도 하나의 대안으로 사용될 수 있습니다.
예를 들어 하나의 지점을 관측하기 위해 카메라를 4대를 사용하는 경우 2대만을 사용하는 경우보다 더 많은 오차를 줄일 수 있으며 많은 카메라를 사용한 Meta에서는 이러한 접근법을 통해 3D 복원을 수행하였습니다.
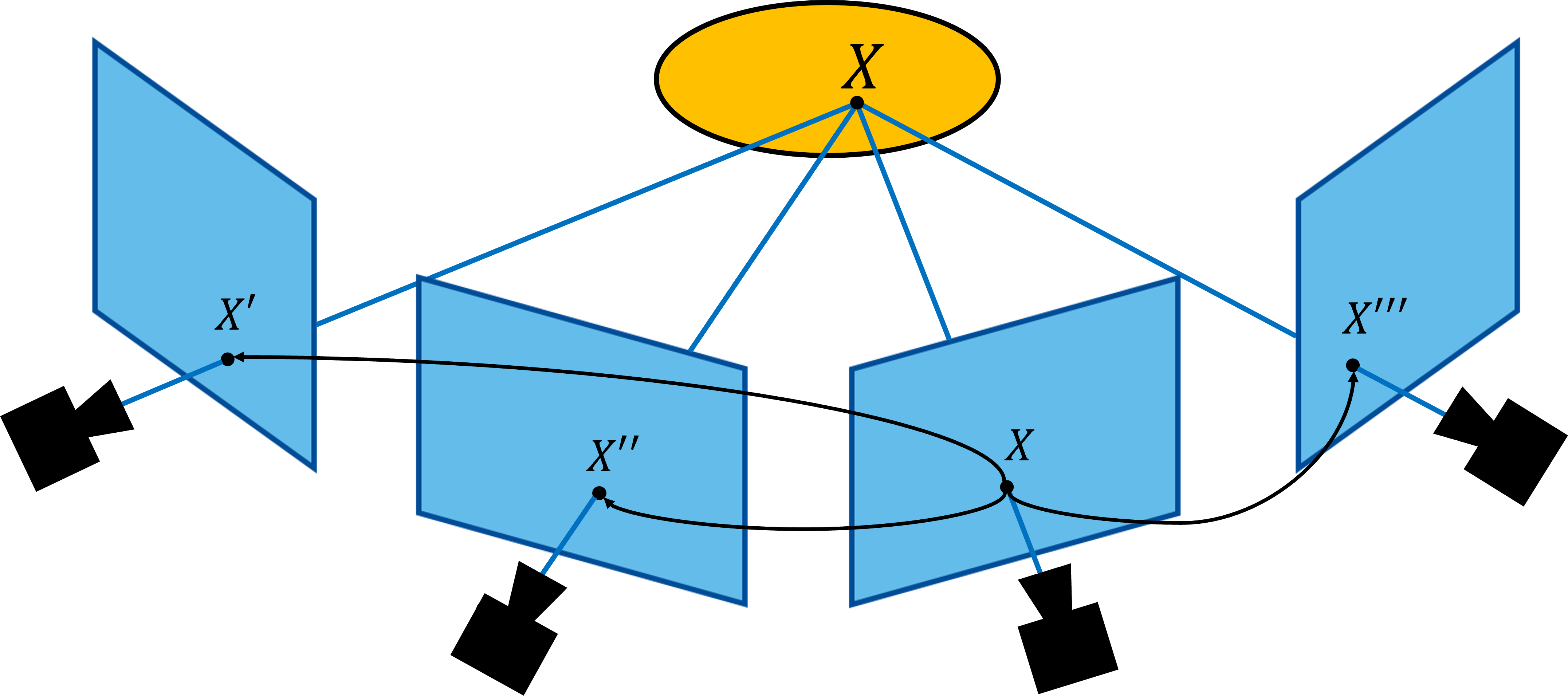 그림 9. 다수의 카메라를 활용하여 위치를 찾아내는 접근법
그림 9. 다수의 카메라를 활용하여 위치를 찾아내는 접근법
3. Sequential Tracking
앞선 단계인 3D Mesh Reconstruction단계로 생성된 3D Mesh Sequence는 시각적으로는 연속적인 Mesh로 보일 수 있으나 실제 Mesh의 구성 요소들은 프레임마다 전혀 달라 Motion을 추출하는 것이 불가능하고 Sequential Tracking을 거치고 나서야 비로소 동일한 구성 요소를 지닌 Mesh Sequence로 완성되어 모션을 추출할 수 있게 됩니다.
비디오, 곧 연속적인 이미지에서 Tracking이란 이미지 픽셀 정보를 이용하여 앞뒤 프레임 간 Motion 정보를 획득하고 이를 활용하는 것으로 달성 가능한데 여기에는 큰 어려움이 있습니다. 그것은 한두 프레임간 Motion 정보는 무시할 수 있는 수준의 작은 오차만을 포함하지만, Tracking을 수행할 프레임 양이 늘어날수록 이러한 작은 에러들이 누적되면서 오류는 걷잡을 수 없을 만큼 커지기 때문입니다. 따라서 Tracking에서는 반드시 이러한 문제를 보완할 방법을 고려해야 합니다.
보완 방법으로 생각할 수 있는 첫 번째 방법은 수작업을 통한 보정입니다. 사람은 알고리즘만큼 밀도 높은 처리는 어렵지만, 누적된 오류에 대해서는 더 정확히 잡아낼 수 있기 때문에 전문가가 직접 수정하는 방법입니다. 다만, 모든 부분은 하기에는 그 분량이 많아 일반적으로 Tracking이 어려운 부분 또는 기반이 되는 큰 움직임에 대해서만 수작업으로 조정하고 그 결과를 바탕으로 나머지 부분을 알고리즘으로 처리하여 전체적으로 낮은 에러를 갖는 고품질의 Tracking이 가능합니다. 이러한 방법의 장점은 일부 Tracking에서 문제가 발생하거나 수정이 필요하다고 판단되는 부분을 발견했을 때, 해당 부분만 수정하여 원하는 품질 또는 결과가 나올 수 있도록 재조정이 가능하다는 점입니다.
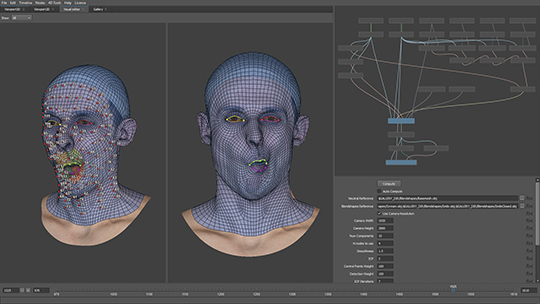 그림 10. 상용 Registration 프로그램인 R4DS Wrap4D
(출처 : https://www.russian3dscanner.com/wrap4d/)
그림 10. 상용 Registration 프로그램인 R4DS Wrap4D
(출처 : https://www.russian3dscanner.com/wrap4d/)
두 번째 방법은 오류 보정을 위한 알고리즘을 추가하는 방법입니다. 앞서 설명한 방법은 정확도가 높을 수는 있겠지만, 사람이 투입되는 만큼 처리 속도 개선과 품질에 한계가 있습니다. 품질이 곧 그 사람의 역량이기 때문에 균일한 품질을 기대하기 어려운 것이죠. 하지만 이 단점을 극복할 방법이 있습니다. 그것은 별도의 알고리즘을 통해 Tracking에서 발생할 수 있는 오차를 줄이고 가이드로 삼을 수 있는 정보를 추가하여 오차를 줄이는 방법입니다.
최근에는 딥러닝 AI 기술 발전으로, 이러한 AI를 기반으로 이미지상의 특징점을 추출하여 이를 바탕으로 Tracking 보정을 하는 방법도 사용하고 있습니다.
 그림 11. 프레임의 중간에 Anchor 지점을 추가하여 누적 오류를 보정하는 연구
(출처 : https://studios.disneyresearch.com/wp-content/uploads/2019/03/High-Quality-Passive-Facial-Performance-Capture-using-Anchor-Frames-1.pdf)
그림 11. 프레임의 중간에 Anchor 지점을 추가하여 누적 오류를 보정하는 연구
(출처 : https://studios.disneyresearch.com/wp-content/uploads/2019/03/High-Quality-Passive-Facial-Performance-Capture-using-Anchor-Frames-1.pdf)

 그림 12. 이미지 상에서 특징점을 추출하여 Tracking 정보로 활용하는 접근법
(출처 : https://arxiv.org/pdf/2207.11243.pdf)
그림 12. 이미지 상에서 특징점을 추출하여 Tracking 정보로 활용하는 접근법
(출처 : https://arxiv.org/pdf/2207.11243.pdf)
그러나 이 방법의 단점은 Tracking 결과에서 일부 잘못된 결과가 나오거나 수정이 필요할 때, 이를 변경하는 것이 거의 불가능하다는 것입니다. 이러한 Tracking과정을 거쳐 Motion 정보를 획득하면 비로소 3D Mesh Sequence와 함께 3D 공간상에서의 고밀도 Motion 정보를 얻을 수 있는 4D Scan 과정이 완료됩니다.
사실적인 인물을 표현하기 위한 여정
사실적인 사람을 가상 세계에서 표현하려면 현실에 존재하는 인물로부터 정보를 추출하는 것이 가장 좋은 방법입니다. 이 글에서는 3D Scan기술을 이용하면 형상과 질감 정보를 추출할 수 있고, 4D Scan 기술을 이용하면 미세한 얼굴 움직임까지 추출할 수 있는 4D Scan 기술에 관해 설명해드렸죠. 그러나 이 기술은 사실적인 표현을 위한 필요기술일 뿐으로 달성을 위해서는 리깅, 쉐이딩 등 보완이 필요한 기술이 더 있습니다. 따라서 NC Research는 더 사실적인 디지털 휴먼을 만들기 위해 4D Scan뿐 아니라 여러 기술 분야에서 고품질을 목표로 한 걸음씩 나아가고 있습니다. 앞으로 NC Research가 만들 실제 사람에 가까운 디지털 휴먼을 기대해 주세요. 긴 글 읽어 주셔서 고맙습니다. 이 글이 3D Scan과 4D Scan 기술로 더 자연스러운 사람을 표현하길 바라는 분들께 도움이 되었길 바랍니다. 😊
