

- MMORPG의 또 다른 재미, 캐릭터 커스터마이징과 AI 기술
- 캐릭터의 모습을 만드는 신경망, 뉴럴 렌더러(Neural Renderer)
- TL 캐릭터의 뉴럴 렌더러 구성요소: 생성자(Generator)와 판별자(discriminator)
- TL 캐릭터 뉴럴렌더러 학습을 위한 데이터셋 준비(wt. TL 개발 조직)
- 사진과 캐릭터가 얼마나 닮았는지 측정하는 3가지 방법과 한계점
- 게임엔진에서 직접 사용할 수 있는 유사도 바탕 모델 설계
- AI가 커스터마이징 장인이 되는 그날까지
작성자
- 김연우, 강인구 (Vision AI Lab)
- 딥러닝을 통해 현실의 사람을 가상 공간 속의 환경에 녹아들게 만드는 기술과 초현실적인 가상 공간 기술을 중점적으로 연구하고 있는 김연우, 강인구입니다.
이런 분이 읽으면 좋습니다!
- 생성 AI에 관심이 많으신 분
- TL 사진 반영 기능의 원리가 궁금하신 분
이 글로 확인할 수 있는 내용
- 딥러닝으로 게임엔진을 모방하는 방법
- 사진과 캐릭터의 닮은 정도를 측정하는 방법
영상 1. TL 캐릭터 커스터마이징 장면
안녕하세요! 엔씨 AI Center의 Vision AI Lab의 김연우, 강인구입니다. 이번 글에서는 THRONE AND LIBERTY(이하TL)에서 만나보실 수 있는 Vision AI Lab의 AI 커스터마이징 기능에 대해 소개하려고 합니다.
TL에서는 플레이어가 사진을 입력하여 쉽게 닮은 캐릭터를 얻을 수 있으며 원하는 외모, 의상, 헤어스타일 등을 선택하거나 조합하여 캐릭터를 개성 있게 꾸밀 수 있습니다. 위 영상 1은 TL에서 캐릭터 커스터마이징을 하는 장면입니다. 데이터 수집 단계에서 다양한 캐릭터의 모습을 촬영하고, 이를 똑같이 흉내 내는 AI를 학습합니다. 그리고 이 AI에 사진을 입력하였을 때 기본 외형에서부터 점점 닮게 만들어 나가는 과정을 담았습니다. 해당 결과는 2D이미지 도메인에서 생성AI의 결과입니다. 그러나 실제로 게임 적용할 수 있는 TL캐릭터 생성을 위해서는 단순히 이미지 생성 AI를 적용할 수는 없었습니다. 이는 게임 시스템 내에서 허용되는 제약 조건을 준수해야 했기 때문입니다. 따라서 게임에 적용할 수 있는 사진과 닮은 3D캐릭터 생성은 표현력 제약이 없는 이미지 생성 AI보다 더 어려운 난이도의 프로젝트였습니다.
그럼 이제 입력한 얼굴 사진을 TL 게임 스타일로 변환하는 걸 넘어서, 실제 게임엔진에 AI 커스터마이징 기능을 적용하기까지 과정을 기술 중심으로 소개하겠습니다. 😊
 그림 1. 생성한 얼굴을 카툰풍으로 변환
(출처: https://www.fotor.com/)
그림 1. 생성한 얼굴을 카툰풍으로 변환
(출처: https://www.fotor.com/)
MMORPG의 또 다른 재미, 캐릭터 커스터마이징과 AI 기술
얼굴을 보정해 주는 카메라 앱이나 애니메이션으로 얼굴을 변화시켜주는 기능을 써보신 적 있나요? 최근에는 누구나 마음만 먹으면 생성 AI 도구를 사용하여 재미있는 작업을 할 수 있게 되었습니다. 인물 사진만 넣으면 성별, 나이, 헤어스타일 등은 원하는 대로 마음껏 조절할 수 있죠. 사진과 똑 닮은 디지털 아바타도 만들 수 있습니다.
이런 기술 발전은 게임에도 새로운 재미의 가능성을 제시하고 있습니다. 특히 MMORPG 게임의 또다른 재미요소 중 하나가 캐릭터 커스터마이징인데요. 플레이어는 자기 상상력을 발휘하여 독특한 캐릭터를 만드는 즐거움을 느낍니다. 이제 플레이어는 생성 AI 도구를 사용하여 원하는 사진을 좋아하는 게임 스타일로 변환할 수 있게 되었으며 이를 바탕으로 더욱더 창의적인 커스터마이징을 할 수 있게 되었습니다. 하지만 사진을 게임 스타일로 바꾸었더라도 게임이 표현할 수 있는 캐릭터로 만드는 것은 쉽지 않습니다.
우리는 특정 사진을 바탕으로 커스터마이징 할 때, 커스터마이징 파라미터를 수정하고 눈으로 확인하는 과정을 반복해서 캐릭터를 만듭니다. 사람의 언어를 컴퓨터가 이해할 수 없듯이, 눈으로 비교하는 과정을 AI가 대신하기 위해서는 AI가 이해할 수 있도록 캐릭터의 모습을 신경망으로 만들어 낼 수 있어야 합니다. 캐릭터의 모습을 만드는 신경망을 뉴럴 렌더러라고 부르며 이 기술을 먼저 소개합니다.
 그림 2. 다양한 게임의 캐릭터 커스터마이징
그림 2. 다양한 게임의 캐릭터 커스터마이징
캐릭터의 모습을 만드는 신경망, 뉴럴 렌더러(Neural Renderer)
뉴럴 렌더러는 딥러닝 기술을 사용하여 2D 이미지나 3D 공간을 생성하는 기술입니다. 게임에서 사용되는 렌더링 방식은 빛의 궤적과 물체의 울퉁불퉁함 등 어려운 물리적인 계산을 하여 결과물을 얻습니다. 뉴럴 렌더러는 단순한 연산의 반복으로 물리적인 계산과 같은 결과가 나올 수 있도록 모방하는 신경망이라서 시간과 비용을 절약할 수 있는 장점이 있습니다. 결정적으로 신경망 연산은 다항식의 곱 연산으로 이뤄져 있기 때문에 신경망의 입력과 그 결과물을 미분할 수 있어서 기술적으로 확장성이 크다는 장점이 있습니다. 미분이 가능하다는 것은 출력을 변경하였을 때 입력이 얼마나 변하는지를 알 수 있다고 해석할 수 있습니다. 그렇다면 TL 캐릭터의 모습을 모방하는 뉴럴 렌더러는 어떻게 만들 수 있을까요?
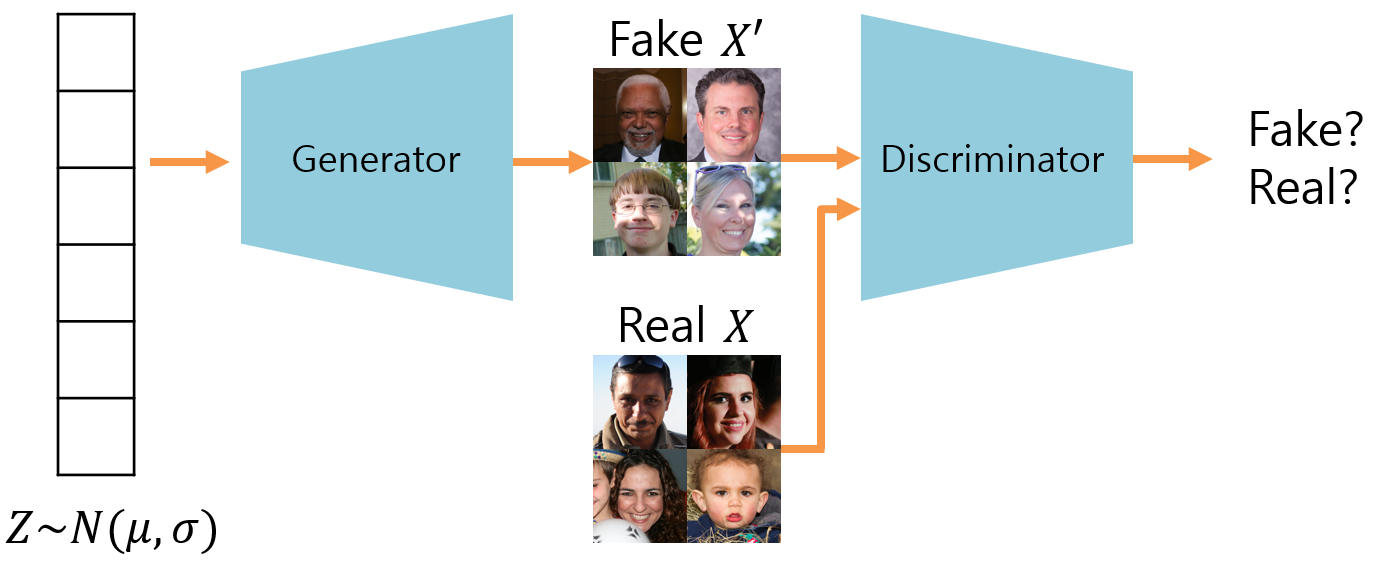 그림 3. GAN Model
(출처: https://learnopencv.com/introduction-to-generative-adversarial-networks/)
그림 3. GAN Model
(출처: https://learnopencv.com/introduction-to-generative-adversarial-networks/)
TL 캐릭터의 뉴럴 렌더러 구성요소: 생성자(Generator)와 판별자(discriminator)
TL 캐릭터의 뉴럴 렌더러는 GAN(Generative Adversarial Network)이라는 신경망 알고리즘을 기반으로 만들어졌습니다. 이 알고리즘은 크게 생성자(generator)와 판별자(discriminator)라는 2개의 주요 구성 요소로 이루어져 있습니다. 먼저, 생성자는 무작위 입력을 받아 이미지를 만드는 역할을 합니다. 생성자는 학습을 진행하면서 실제 이미지와 유사한 이미지를 생성하려 합니다. 반면에 판별자는 생성자가 생성한 이미지와 실제 이미지를 구분하는 방법을 배웁니다. 이때 생성자는 판별자가 구분하는 방법을 보고 그 방법을 쓸 수 없도록 자기 능력을 보완합니다. 이 과정을 반복하며 생성자와 판별자는 서로 경쟁하면서 학습하게 됩니다. 그 결과, 생성자는 판별자가 구분하지 못하도록 점점 실제 이미지와 유사한 이미지를 생성하는 능력을 갖추게 됩니다.
앞서 설명한 생성자에 입력되는 무작위 입력은 다항식의 연산에 해당하는 신경망의 입력이라는 점에서 하나의 벡터로 해석할 수 있습니다. 벡터가 갖고 있는 각 차원의 숫자 값이 변함에 따라 신경망 출력도 변화한다는 점에서 벡터 각각의 수치는 출력 이미지를 표현하기 위한 정보를 담고 표현할 수 있는 일종의 잠재 공간(latent space)으로 볼 수 있습니다. 만약 벡터 각각의 수치가 어떤 것을 표현하는지 명확히 알고 있다면 직접적으로 지도하여 신경망을 학습할 수도 있습니다. 생성자에 입력되는 무작위 벡터 대신, 커스터마이징에 실제로 사용되는 눈꼬리 높낮이, 입술 두께와 같은 값을 입력으로 사용하여 캐릭터의 모습을 생성하도록 생성자를 학습시킬 수도 있습니다. 이렇게 생성자가 특정한 조건을 받아들이는 GAN을 Conditional-GAN이라고도 합니다.
TL 캐릭터 뉴럴렌더러 학습을 위한 데이터셋 준비(wt. TL 개발 조직)
AI를 학습시키기 위해서는 막대한 양의 데이터가 필요하다는 사실을 들어 보셨을 것입니다. 뉴럴 렌더러를 학습시키기 위해서도 마찬가지로 충분한 양의 데이터셋이 필요합니다. TL 캐릭터 뉴럴 렌더러를 학습하기 위한 데이터셋 제작은 TL 개발 조직과 협업을 통해 이루어졌습니다. 무작위 TL 파라미터를 입력으로 받아 이에 해당하는 (무작위) 캐릭터 얼굴을 생성하고, 스크린샷으로 저장할 수 있는 개발 도구를 제작해 주셨고, 이 개발 도구를 사용하여 총 10만여 장의 무작위 TL 캐릭터 이미지와 해당 얼굴을 만들기 위한 커스터마이징 파라미터값을 쌍으로 갖는 학습 데이터셋을 만들었습니다. 이 데이터셋을 GAN 알고리즘에 입력하여 뉴럴 렌더러를 효과적으로 만들 수 있었습니다.
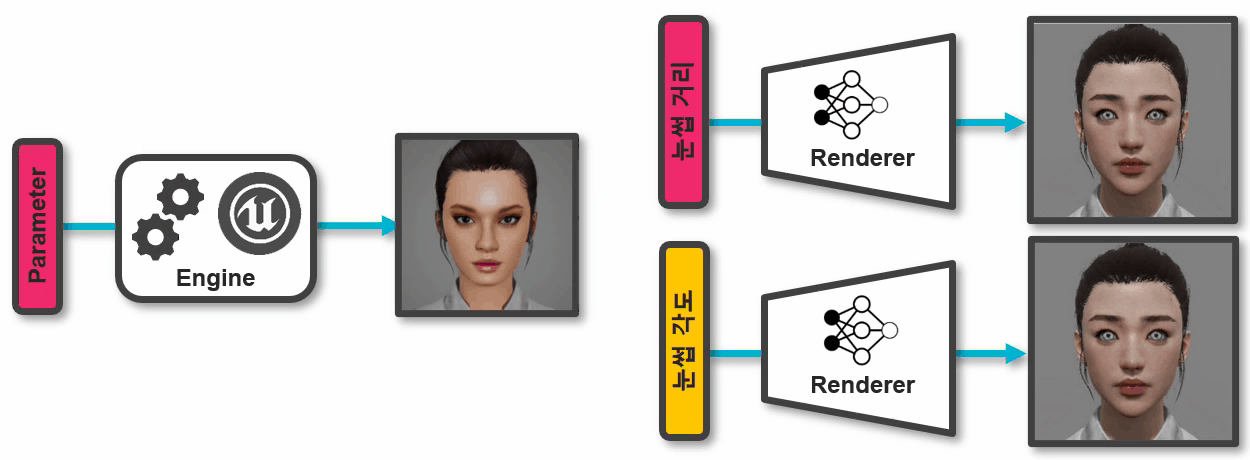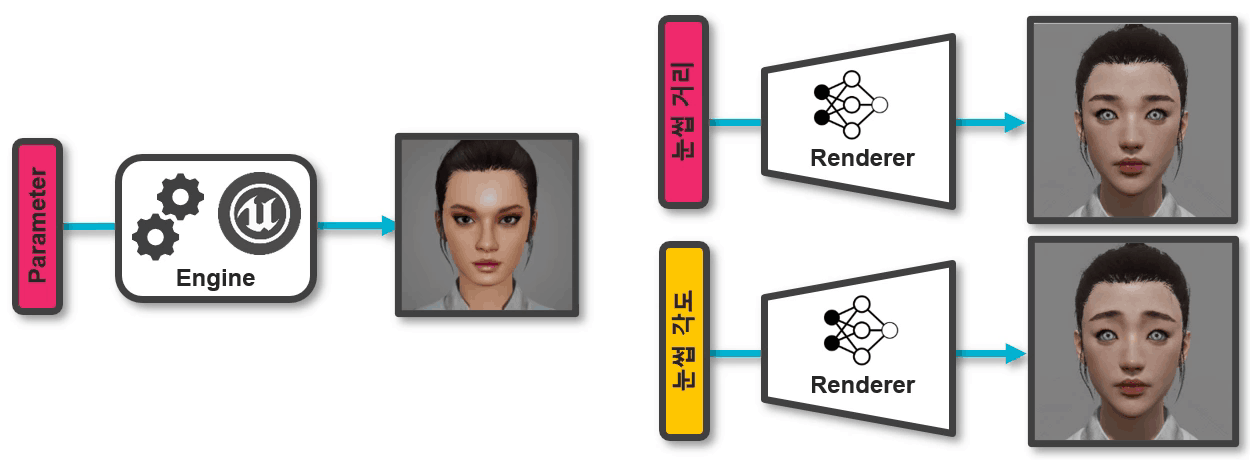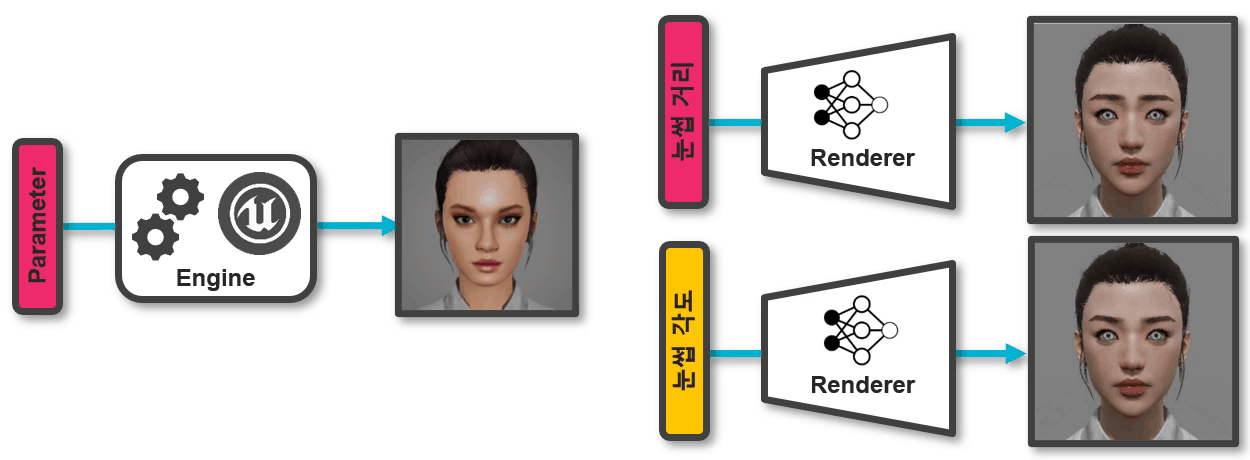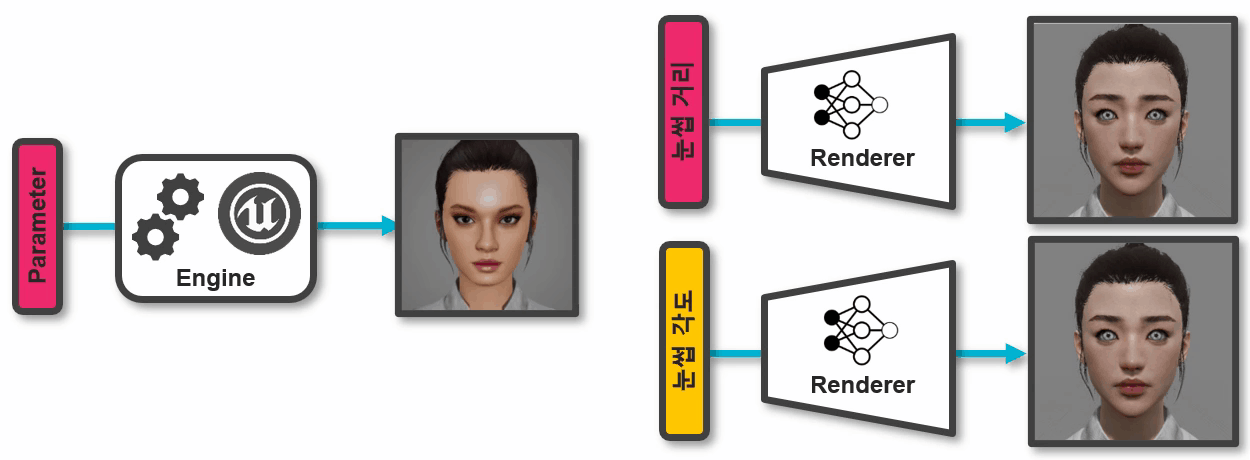 그림 4. 게임 엔진과 뉴럴 렌더러
그림 4. 게임 엔진과 뉴럴 렌더러
사진과 캐릭터가 얼마나 닮았는지 측정하는 3가지 방법과 한계점
TL 캐릭터를 모방하는 뉴럴 렌더러를 완성하였지만, 아직 뉴럴 렌더러에는 사진과 캐릭터를 비교할 수 있는 ‘눈’이 없습니다. AI는 수학을 바탕으로 하고 있어 수학적인 수식을 눈으로 사용하고 있습니다. 캐릭터와 사진이 닮았는지를 수학적으로 표현할 수 있어야 AI가 눈을 갖고 판단을 할 수 있게 됩니다. 그러면 두 얼굴이 얼마나 닮았는지 수치화하는 방법은 무엇이 있을까요? 첫 번째로는 우리가 사람을 구분할 때와 같이 얼굴형, 눈코입의 위치, 눈썹 모양과 각도 등 이목구비를 구성하는 얼굴의 요소가 얼마나 비슷한지를 평가하는 방식이 있습니다. 이를 위해 얼굴의 각각의 영역을 구분할 수 있는 Facial Parser Network(Face Part Segmentation)과 같은 기술이 사용됩니다. Facial Parser Network는 얼굴 사진을 입력받아 눈, 코, 입 등의 영역을 구분한 결과물을 출력하는 신경망입니다. 이를 통해 사진의 얼굴 영역과 뉴럴 렌더러의 얼굴 영역이 얼마나 다른지를 손실함수로 정의하여 이목구비에 대한 이미지 유사성을 비교할 수 있습니다. 두 번째 방법으로는 신경망 내부의 특징 공간에서 얼굴 검증을 통해 두 얼굴이 동일한 사람인지를 판단하는 Face Verifier Network를 활용하는 것입니다. 이 신경망은 얼굴 사진을 입력받아 신경망만이 파악할 수 있는 여러가지 얼굴 속의 특징을 담고 있는 벡터 값을 출력합니다. 얼굴 사진에 대한 출력과 뉴럴 렌더러에 대한 출력으로 얻은 두 벡터 값을 기반으로 두 이미지 간의 유사도를 측정하기 위해 cosine distance를 계산하는 알고리즘을 사용하는 등 여러 가지 지표를 적용할 수 있습니다. 또 얼굴에서 신경망을 통해 특징점(Landmark)들을 찾아서 비교하는 방법도 사용할 수 있습니다. 이러한 방식들은 얼굴 특징을 고려하여 두 얼굴의 유사도를 정량화하는 것이며, Apple의 Face ID처럼 얼굴 인증을 하거나 닮은 사람을 찾는 소프트웨어와 같이 다양한 분야에서 많이 사용되고 있습니다.
앞서 알아본 두 얼굴의 유사도 측정 방식들은 도메인이 같은 상황에서는 충분히 좋은 성능을 보이지만, 실제 사진과 3D 게임이라는 서로 다른 도메인의 얼굴에 적용하면 쉽게 동작하지 않습니다. 이러한 문제점을 해결하기 위해서 이미지 도메인 간 변환 기술을 전처리로 사용할 수 있습니다. 몇 년 전 풍경 사진을 고흐의 별이 빛나는 밤 스타일로 바꿔주는 앱이 유행했던 적이 있는데, 이런 기술을 Style Transfer 또는 Image Translation이라고 합니다. 이 기술은 각 도메인이 표현할 수 있는 범위 안으로 상호 변환해 주는 기술로 실제 사진을 3D 게임 안에서 표현할 수 있는 가장 닮은 형태로 변환시켜 그 차이를 줄이는 데 사용할 수 있습니다. 현실에는 존재하지만, 게임 프리셋에는 없는 수염의 형태, 머리 모양, 안경, 눈 크기, 코 모양 등 다양한 도메인 차이를 줄여 유사도를 측정하는 방법에 사용할 수 있습니다.
 그림 5. TL 이미지 변환 예시
그림 5. TL 이미지 변환 예시
게임엔진에서 직접 사용할 수 있는 유사도 바탕 모델 설계
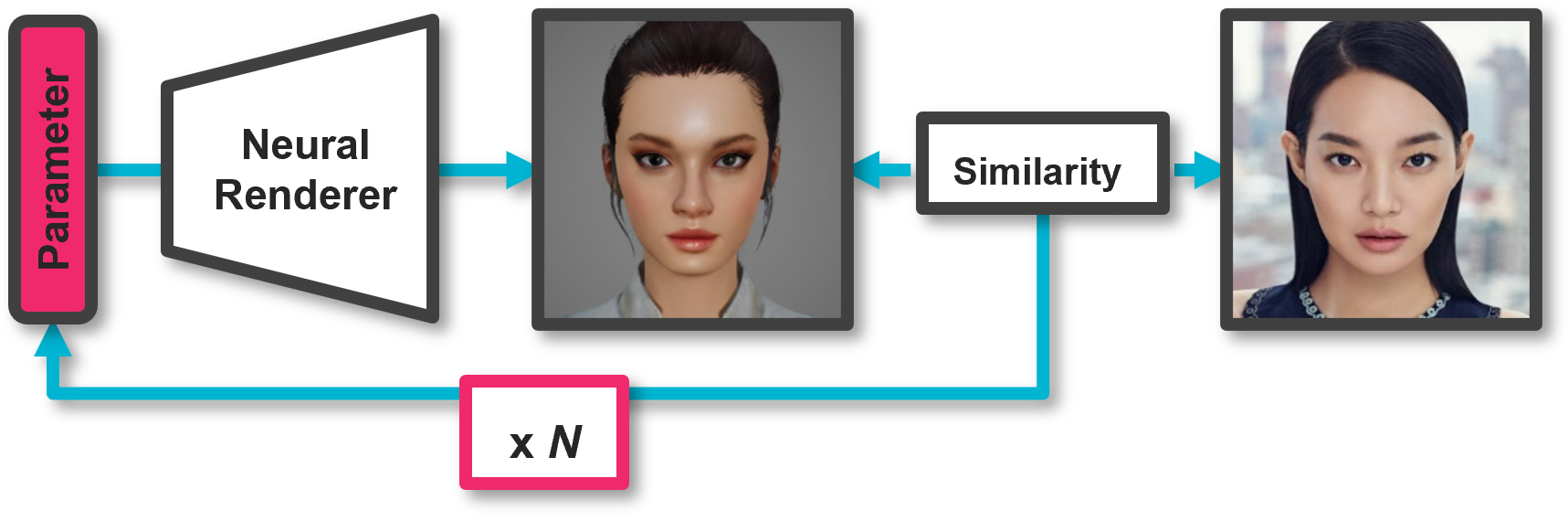 그림 6. 최적화 파이프라인
그림 6. 최적화 파이프라인
실제 사진과 유사한 TL 게임 캐릭터를 생성하기 위해 이러한 다양한 기술들을 효과적으로 활용할 수 있습니다. 단순한 예시로 Image Translation을 통해 입력된 실사 사진을 TL 캐릭터 특징을 가진 이미지로 변환하여 도메인 차이를 줄이고 변환 결과물과 캐릭터 모습을 모방하는 뉴럴 렌더러의 결과물이 유사도가 높아지도록 Facial Parser와 Face Verifier 등 다양한 신경망을 통해 뉴럴 렌더러의 입력 파라미터를 최적화하는 방법을 들 수 있습니다. 뉴럴 렌더러는 게임의 외형 파라미터를 입력받도록 학습하였기에 게임 엔진에서도 직접적으로 사용할 수 있습니다.
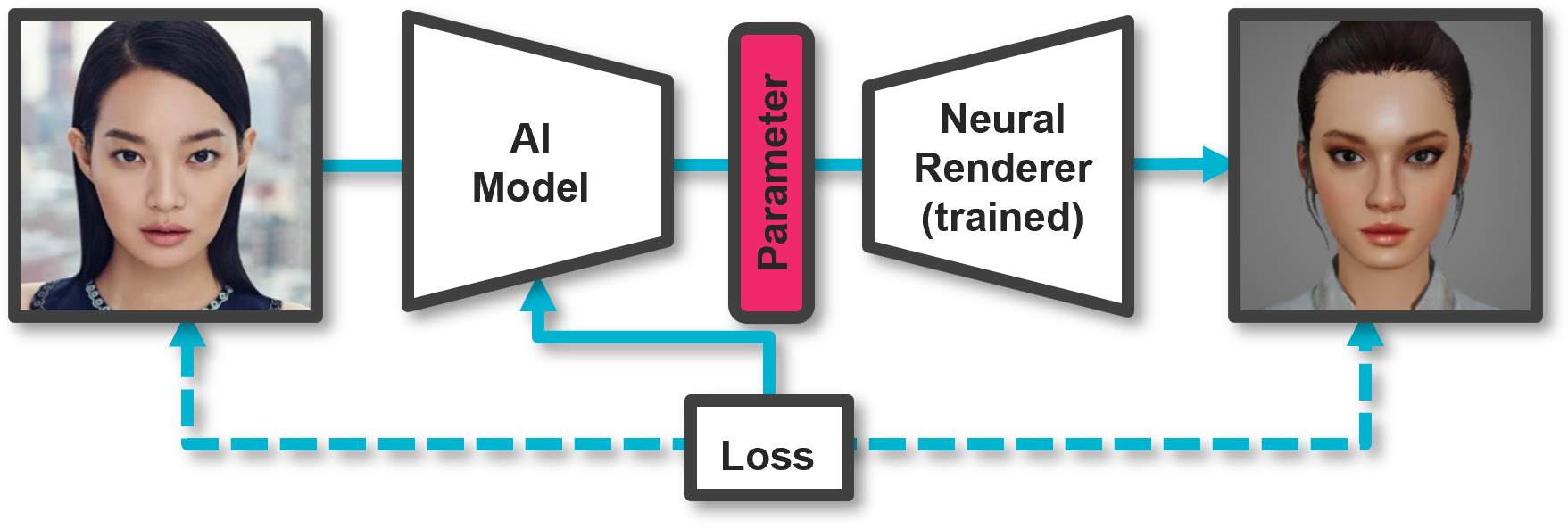 그림 7. 하나로 합친 모델 구조
그림 7. 하나로 합친 모델 구조
또 최적화 과정에 사용한 신경망들을 하나의 구조로 합쳐 실제 사진에 해당하는 파라미터가 무엇인지 단번에 추정할 수 있는 신경망을 설계할 수도 있습니다.
뉴럴 렌더러의 입력을 최적화하는 방식은 입력 사진과 유사한 TL 캐릭터의 외형 파라미터를 찾는 데에 매우 효과적입니다. 하지만 계산 비용이 많이 들고 반복적 추론이 필요하여 여러 단계를 거치면서 시간이 오래 걸리기 때문에 실제 서비스에는 적합하지 않습니다. 그렇기에 단일 패스의 출력 계산을 통해 빠른 속도와 낮은 비용의 장점이 있는 Feed-forward 방식을 적용하거나 하나로 합쳐진 단일 모델에서 파라미터를 출력하는 앞부분의 신경망만 사용하여 결과물을 얻는 방식이 필요합니다. 실제 사용자가 결과물을 받았을 때도 어색하지 않고 빠른 속도도 챙기기 위해서 내부적으로 많은 실험을 거쳤으며 최대 3초 이내에 사용자가 결과물을 받을 수 있도록 게임에 적용할 수 있었습니다.
AI가 커스터마이징 장인이 되는 그날까지
현재 개발된 기술은 게임 엔진에서 제한된 얼굴 표현 범위로 인하여 사진과 꼭 닮은 캐릭터를 생성하기는 어렵습니다. 하지만 인물 사진에서 3D 얼굴 모델링과 텍스처를 복원하는 기술을 활용한다면 커스터마이징 파라미터 조절을 통한 캐릭터 생성 방식이 가지는 표현력의 제약을 해결할 수 있습니다. 향후에는 최근 화제가 되는 텍스트 기반 이미지 생성 기술을 활용하여 사진이 아니라 얼굴을 묘사하는 글만으로도 원하는 캐릭터를 만들 수 있으리라 생각합니다.
또한, 게임에서 가상의 인물을 만드는 것은 게임을 즐기는 사용자뿐만 아니라, 게임을 만드는 개발자들에게도 필요한 과정입니다. 인물 사진으로부터 캐릭터를 생성하는 기술은 게임의 주요 등장인물의 외형을 기획하거나, 다양한 가상의 인물 사진을 생성하여 대량의 NPC 얼굴을 빠르게 제작하는 용도로도 활용될 수 있을 것으로 기대하고 있습니다. 현재 엔씨 Vision AI Lab에서는 이 글에서 소개한 기술 이외에도 다양한 생성 AI 기술을 바탕으로 게임에서 손쉽게 원하는 캐릭터를 만들 수 있도록 열심히 연구하고 있습니다. 기회가 되면 또 다른 프로젝트 소개로 찾아 뵙겠습니다. 😊
영상 2. 게임 클라이언트 동작 영상
