
- Intro
작성자
- 이한울 (시장이해AI팀)
- AI를 이용해 시장의 거시구조와 미시구조를 이해하고 활용하는 방법들을 연구하고 있습니다.
이런 분이 읽으면 좋습니다!
- 금융 분야의 자연어 처리 기술에 관심이 있는 분
- ESG분야의 AI 활용에 관심이 있는 분
Intro
우리는 어떤 형태로 매일 금융 정보와 접하고 있을까요? 몇년 전부터 주식 거래가 큰 인기를 끌게 되면서 숫자와 그래프로 가득 찬 화면 속에서 많은 정보를 얻으시는 분들도 많지만, 우리는 대부분 글을 통해 금융과 관련된 정보를 얻습니다. 글을 통해 정보를 얻고 나면, 우리는 새롭게 얻은 정보에 대해 고민하고 새로운 의사결정을 내립니다. 만약 방금 읽은 신문 기사를 통해 “게임 분야가 앞으로 유망하게 떠오를 것 같다!”라는 생각이 들면 게임 관련 주식을 사는 행위로 이어지는 것처럼 말이죠. 우리가 정보를 얻고, 무언가를 거래하는 이 모든 행위들은 하나로 합쳐져 시장을 만들고 이는 분석 가능한 구조를 이룹니다.
NCSOFT의 시장 이해 AI팀은 인공지능을 통해 금융 시장의 구조와 역동성을 이해하고, 이를 사람이 이용하기 쉽게 만드는 기술을 연구하고 있습니다. 크게는 거시적인 관점에서 금융 시장을 움직이는 요인들을 다양한 자산들의 가격과 텍스트로부터 추출하고, 그 결과를 바탕으로 투자자가 자산 배분을 잘 할 수 있게 도와주는 기술을 연구하고, 작게는 증권 거래소에서 매매가 일어나는 패턴을 분석하여, 투자자가 매수, 매도하고자 하는 물량과 일정만 정해주면 알아서 대신 매매 해주는 주문 집행 기술을 연구하고 있습니다. 이를 위해 정량 데이터에 대한 분석과 모델링은 물론이고, 텍스트 데이터를 처리하기 위한 자연어 처리 기술까지도 폭넓게 적용하고 있습니다.
오늘은 그 중에서도 우리에게 가장 친숙한 형태인 ‘글’(Text)과 이를 이해하고 처리하는 기술인 자연어 처리(Natural Language Processing)을 적용한 연구에서의 성과를 공유하고자 합니다. 참고로, 오늘 공유해드릴 이야기는 저와 다른 팀원분들의 무모한 도전에서 비롯된 이야기입니다. 기술 이야기에 얹힌 저희의 도전기도 함께 재밌게 읽어주시면 좋겠습니다.
팀장님, 저희 대회 나가겠습니다!
시장이해AI 팀은 위에서 언급했듯 다양한 기술 영역을 다루고 있기 때문에, 내부적인 세미나를 통해서 서로의 전문 지식을 공유하고 새로운 기술 영역을 학습합니다. 2023년 상반기에는 자연어 처리 기술을 중심적으로 학습해나갔고, 기존에도 금융 자연어처리 연구를 해오던 저는 함께 학습한 내용을 바탕으로 어려운 금융 문제에 도전해보자는 제안을 하였습니다.
 팀장님 : “…일도 바쁜데 괜찮으시겠어요?”
이한울 : “네! 업무에 지장 가지 않도록 해보겠습니다”
팀장님 : “…일도 바쁜데 괜찮으시겠어요?”
이한울 : “네! 업무에 지장 가지 않도록 해보겠습니다”
저의 무모한 도전에는 저와 비슷한 시기에 입사하신 성범님, 소현님 그리고 저희 모두의 버디님이신 종현님까지 가세하게 되었고 저희는 NCSoft Market Understanding AI (엔씨소프트 시장이해AI팀)을 줄여 NCMU라는 이름으로 출전하게 되었습니다.
특히 이 도전에 앞서, “단순히 금융 NLP 대회를 나가자!”라는 마음이 아닌 실제 금융에 있어서 중요한 문제에 도전해보자는 이야기를 하였고 이에 가장 적합했던, ESG 이슈 분류라는 문제를 제안한 FinNLP workshop의 ML-ESG SharedTask에 출전하게 되었습니다. (해당 대회에 대한 설명은 후술하겠습니다!)
그리고 저희는 여러 기업과 연구소들을 크게 앞지르고 English subtask 1위, French subtask 2위라는 값진 성적을 기록했습니다! 지금부터 그 여정과, 여러가지 제약 속 저희가 사용한 기술들에 대해 설명드리겠습니다.
금융에서 ESG의 중요성
“대회에 나가겠다!” 라는 마음도 물론 큰 부분이었지만 위에서도 언급하였듯 금융에 있어서 중요한 문제를 AI를 통해 해결하자는 마음도 저희의 마음 속 큰 부분을 차지하고 있었습니다. 금융에서의 중요한 문제는 언제나 그렇듯 산더미처럼 많지만, 저희의 시선을 사로잡은 주제는 바로 ESG였습니다.
ESG는 Environmental(환경), Social(사회), Governance(지배구조)를 의미하는 것으로서, 기업이 지속가능한 경영을 달성하기 위한 핵심 요소들입니다. 이들은 기업의 손익계산서와 재무상태표에서는 드러나지 않지만 기업의 중, 장기적 기업가치에도 영향을 미치며 기업 뿐만 아니라 우리 사회의 지속 가능성에도 중요한 영향을 미칩니다.
특히 ESG는 단순히 윤리적, 도덕적인 것을 넘어 2,000개 이상의 실증적 연구가 기업의 ESG 활동이 높은 기업 성과와 긍정적 연관성이 있다는 것을 보여주고 있어 투자 관점에서도 중요한 의제가 되었습니다. 또한 2025년부터 우리나라 자산총액 2조원 이상의 유가증권시장 상장사에 대해 기업의 ESG 활동이 담긴 ‘지속가능경영보고서’를 공시하도록 의무를 부여하여, 기업 활동의 공시 및 보고 측면에서도 중요성이 날로 가중되고 있습니다.
기업의 ESG 활동에 대한 평가는 주로 등급으로 매겨지지만, 대부분의 활동은 숫자나 기호로 표시하기 어려운 형태이며 글의 형태로 지속가능경영보고서나 뉴스 기사를 통해 전달됩니다. 따라서 기업의 ESG 활동을 추적하기 위해서는 이런 글 형태의 데이터를 추적하여야 하는데, 지속가능경영보고서는 보통 수십 페이지에서 수백 페이지에 달하고 있고 기업 활동에 관련된 뉴스는 매일 엄청난 양이 쏟아지고 있기 때문에 일일이 확인하는 것은 정말 어렵습니다.
그렇기에 이들을 추적하고, 분류하고, 분석하는 데에 있어서는 인공지능이 그 유용성을 보여줄 수 있는 것이죠!
저희가 만난 ML-ESG SharedTask는 이런 저희의 생각과 거의 부합하는 문제 의식을 지니고 있었습니다.
Multi-Lingual ESG Issue Identification (ML-ESG) Shared Task
SharedTask는 자연어 처리 및 머신 러닝 분야에서 학술적인 연구와 혁신을 장려하기 위한 일종의 대회로, 참가자들은 주어진 작업(Task)에 대한 새로운 모델과 알고리즘을 개발하여 성능을 경쟁합니다. 일반적으로 성능 경쟁 결과가 담긴 리더보드(순위표) 발표 이후, 연구자들은 자신의 접근 방법을 논문으로 공유하고 학회 등에서 발표함으로써 연구자 간 지식을 공유하고 함께 발전시킵니다. 저희 팀이 참여했던 ML-ESG SharedTask는 FinNLP Workshop에서 주최하는 대회로, 뉴스 데이터 속에서 ESG 이슈를 분류해내는 문제였습니다. FinNLP Workshop은 금융 자연어처리 분야에서는 권위있는 워크숍으로서, 작년도 ‘KB-서울대’ 공동연구 논문이 한국최초로 해당 워크숍에 게재되어 많은 관심을 받기도 했습니다.
기존에 AI 기반의 금융 의사결정은 대부분 재무적인 요소, 즉 투자 성과와 같은 것들에만 집중되어 있었습니다. 이번 FinNLP 워크숍은 이런 현실적인 상황을 지적하며, ESG 요소가 AI 기반의 금융 의사결정 프로세스에 통합되는 방법을 함께 학자들과 고민할 수 있도록 본 SharedTask를 개최하였습니다. 저희 NCMU팀 역시 이 문제 의식에 공감하였기에 문제 해결에 적극적인 태도로 임하게 되었습니다.
영어, 프랑스어, 중국어로 된 대회 문제가 출제되었습니다. 참가자들은 언어 별로 대회에 지원할 수 있었고, 저희 팀은 영어와 프랑스어가 가능했기(가능은 했기…) 때문에 영어 subtask와 프랑스어 subtask에 참여하게 되었습니다.
ESG 이슈는 MSCI ESG rating guidelines에 따라 환경(Environmental), 사회(Social), 기업 지배구조(Corporate Governance)라는 대분류 안에 10~13개의 소분류로 이루어져, 총 35개의 분류를 이루고 있었습니다.
(자세한 분류는 다음 페이지를 참고해주세요!)
데이터에서 영어 뉴스는 ESGToday, 프랑스어 뉴스는 RSEDATANEWS, Novethic 로부터 수집되었으며 Fortia라는 기업의 Data&Language Analyst Team에서 해당 뉴스 데이터들에 레이블링을 진행하였습니다. 저희는 이렇게 여러가지 언어로 된 뉴스 데이터들을 언어모델에게 보여주고, 그 언어모델이 뉴스를 35개의 ESG Issue 중 하나로 잘 분류하면 되는 문제를 풀게 되었습니다. 말로 들었을 때는 그다지 난이도가 높은 문제는 아닌 것 같았지만, 해당 대회에 참여하고 문제를 맞이했을 때 저희는 세 가지의 어려운 점과 두 가지의 제약 사항을 마주하였습니다.
이 문제가 왜 어려울까 (1) 데이터가 적음
| English | French | Chinese | |
|---|---|---|---|
| Train | 1,199 | 1,200 | 900 |
| Dev | - | - | 100 |
| Test | 300 | 300 | 238 |
| Total | 1,499 | 1,500 | 1,238 |
SharedTask에서는 일반적으로 학습을 위한 Train 데이터셋 과 검증을 위한 Dev 데이터셋을 제공하지만, 저희가 참여한 English Subtask와 French Subtask에서는 Dev 데이터셋은 제공되지 않았습니다.
(Train 데이터셋은 학습을 위한 데이터셋이며, Dev 데이터셋은 학습 결과를 검증하고자 Test 데이터셋 공개 이전에 활용되는 데이터셋입니다)
게다가 데이터도 약 1,200개 정도만 제공되었는데, 저희가 분류해야 할 라벨이 35개라는 것을 떠올리면 단순 계산으로 한 라벨당 약 30개 정도의 데이터가 존재한다고 볼 수 있습니다.
그리고 이는 한 라벨을 정확히 분류해내기에 일반적으로 충분하지 않습니다.
특히 저희가 마주하는 데이터가 뉴스 데이터입니다. ESG 뉴스는 기본적으로 기업 혹은 기업인이 특정한 활동을 했을 때 직접 보도자료를 발표하거나 기자 분들의 취재를 통해 작성됩니다. 따라서 기업이 활동하는 ESG 활동이 다양하고 복잡할 수록, 약 30여 개 수준의 데이터 만으로는 언어모델이 이를 학습하였더라도 특정 분류를 잘 파악해내기 어려워집니다.
이 문제가 왜 어려울까 (2) 데이터가 불균형
데이터가 적은 것 만이 문제가 아니었습니다. 기본적으로 저희가 마주한 데이터의 라벨은 극심한 불균형을 이루고 있었습니다.
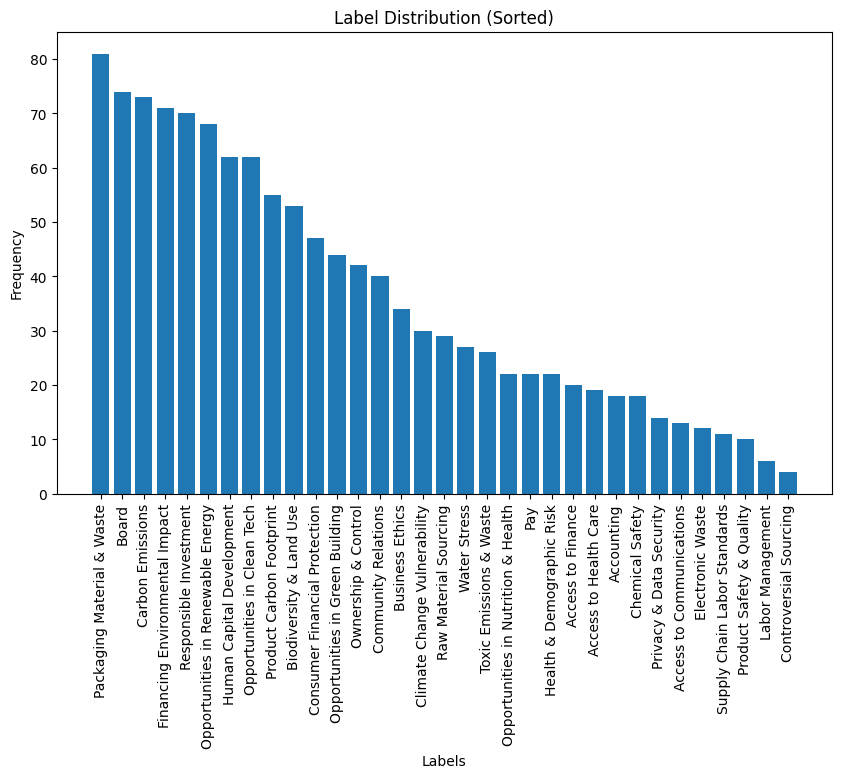
심지어 특정 라벨은 Train 데이터 셋에 아예 존재하지도 않았습니다. 이런 라벨의 불균형은 기업이 선호하거나 자주 수행하는 특정 ESG 활동이 있을 경우에 자연적으로 발생할 수 밖에 없는 현상입니다. 그러나 이런 자연스러운 현상으로 인해 언어모델은 이를 분류하는 법을 배우는 것이 어렵습니다. 언어모델은 분류 성능을 최고로 끌어올리는 것을 목표로 (오차를 줄이는 것을 목표로) 학습을 진행하는데, 만약 데이터에 불균형이 심해서 한 라벨이 과도하게 자주 등장한다면 언어모델은 데이터를 면밀히 보고 분류하는 것이 아닌 자주 등장하는 라벨을 더 자주 뱉어내는 식으로 학습할 수 있기 때문입니다. 물론 데이터 불균형이 무조건 학습 실패로 이어지진 않지만, 일반적으로는 불균형을 어느 정도 해소한 뒤에 학습시키는 것이 모델의 성능을 더 좋게 만들어 줍니다.
이 문제가 왜 어려울까 (3) 결정 경계(Decision Boundary)가 복잡하다
저희가 다뤘던 데이터 속 뉴스 기사를 하나 번역해서 가져와 보았습니다. 여러분은 다음의 분류 중, 해당 뉴스가 어떤 분류에 해당한다고 생각하시나요?
“G7 정상들은 탄소 배출 집약적 산업이 기후에 미치는 영향을 해결해야 한다고 강조하면서 몇 가지 특정 부문을 겨냥한 이니셔티브와 조치를 강조했습니다. 에너지 산업과 관련하여 정상들은 에너지 효율을 높이고, 재생에너지 및 기타 무공해 에너지 보급을 가속화하며, 낭비적인 소비를 줄이는 데 노력을 집중하는 한편, 향후 몇 년 동안 국내 전력 시스템을 대대적으로 탈탄소화할 것을 약속했습니다. 또한 성명은 야심찬 기후 중립 경로에 따라 제한된 예외를 제외하고 국제 탄소 집약적 화석 연료 에너지에 대한 새로운 정부 직접 지원을 가능한 한 빨리 단계적으로 폐지할 것이라고 밝혔습니다.”
MSCI ESG rating guideline에서 해당 뉴스와 관련이 있을 만한 라벨은 3개 정도가 있는데요
- Carbon Emissions (탄소 배출)
- Opportunities in Renewable Energy (재생 에너지에 대한 기회)
- Product Carbon Footprint (제품에서 발생하는 탄소 발자국)
이들은 저희가 사용하는 35개 ESG Issue 라벨에 포함되는 것들입니다. 과연 어느 분류가 해당 기사에 대한 분류로 적절할까요?
대부분의 사회 현상은 하나의 이름표로 그 현상을 온전하게 설명하기 어렵습니다. 특히 그 현상에 대해서 잘 모르면 어떤 이름표가 맞을 지 더 알기 어렵습니다. 저희가 받은 데이터셋은 전문가분들의 검수 하에 특별한 이름표들이 붙어 있긴 하지만, 피상적인 수준에서 그 차이를 인지하는 것은 어렵습니다. 저희에게 어려운 것은 언어모델에게도 대부분 어렵습니다. 이런 상황에서는 더 좋은 자연어 이해(NLU) 능력과 더 많은 배경 지식이 있는 언어모델이 그렇지 않은 언어모델보다 나은 성능을 보여줄 확률이 높습니다.
우리가 지닌 제약 사항 (1) 컴퓨팅 자원이 부족하다
처음 저희가 대회에 나갈 때 팀장님과 약속했던 사항이 있습니다.
“업무에 지장을 줘서는 안되며, 업무 시간에 해서는 안되며, 회사의 리소스를 사용해서는 안된다”
일반적으로 인공지능 분야의 개인 연구자가 마주하는 가장 큰 제약은 바로 컴퓨팅 자원의 한계입니다. 인공지능 학습을 위해 사용하는 고성능의 GPU는 가격이 비싸고, 구입 자체도 어려우며, 사용하기 위한 환경을 구성하는 것도 어렵습니다. 또한 모든 걸 다 갖췄다고 해도 이를 운용하는 것 자체에도 비용이 듭니다. 현대의 인공지능들은 막대한 컴퓨팅 자원을 요구하기 때문에 개인 연구자는 최신 인공지능을 연구하기 위해서는 엄청난 현금 지출을 감당하여야 합니다. 회사라는 따뜻한 컴퓨팅 울타리(…) 밖으로 벗어난 저희 팀은 십시일반을 통해 인공지능 학습을 위한 서버를 대여하고 활용하게 되었습니다.

인공지능 학습용 컨테이너를 대여해주는 회사는 몇 개 있었고, 저희는 저희의 예산 제약에 따라, 시간당 약 2달러 정도 지불하는 컨테이너를 하나 대여하게 되었습니다. 시간 당 비용이 계산되기 때문에, 80GB짜리 VRAM을 지닌 A100 GPU 한 장을 단 한 순간도 쉬지 않게 활용하였습니다.
우리가 지닌 제약 사항 (2) 인적 자원이 부족하다
대회 기간은 약 한 달 정도 진행되며 그 기간 동안 다양한 기업과 연구실들은 수 많은 실험을 통해 가장 높은 성능의 머신러닝 모델을 만듭니다. 저희도 가능한 한 많은 접근을 실험하고, 더 많은 방법을 고안해보고자 하였으나 다들 회사에서 진행하는 연구와 개발 업무가 있는 만큼 시간이 매우 부족했습니다. 실제로 ML-ESG SharedTask 참여 팀들의 논문을 살펴보면, 효과적인 문제 해결을 위해 언어모델 아키텍쳐 레벨부터 다양한 시도를 하던 팀들이 많았습니다. 하지만 저희는 시간, 금전, 노동 효율적인 방법을 활용했어야 했고, 결국 언어모델의 구조가 아닌 데이터의 한계를 해결하는 방법을 모색하고자 했습니다. 부족하고, 불균형하고, 어려운 데이터를 많고, 균형 잡히고, 충분히 학습 가능하게 만드는 것을 목표로 저희는 여러가지 접근을 하게 됐습니다.
극복을 위한 고난의 행군
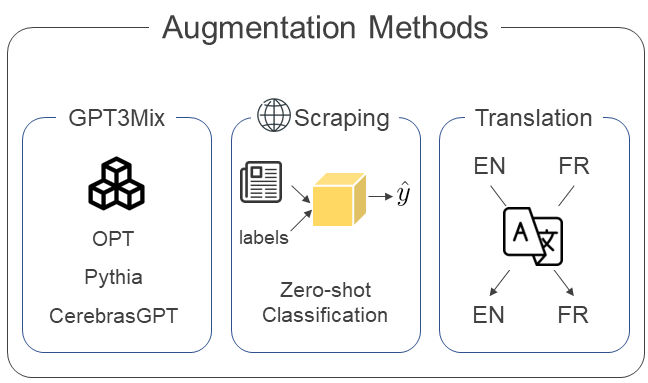
저희가 취한 전략을 종합하자면 "더 큰 언어모델이 지닌 지식을 바탕으로, 데이터가 가진 근본적 문제를 해결하여 작고 강력한 분류 모델을 만들자!"였습니다.
일반적으로 인공지능은, 특히 언어 모델은 크기가 클수록 더 높은 성능을 지니고 있고, 더 복잡한 문제를 잘 해결하며, 다양한 문제를 해결할 수 있는 능력을 갖고 있습니다. 다만 인공지능의 크기가 커질수록 저희가 하고자 하는 특정 문제를 위해 미세 조정(fine tuning)하는 데에 있어서 더 많은 자원이 투입되어야 합니다. 저희가 가진 자원은 일반적으로 거대 언어 모델이라 불리는(파라미터 사이즈 10B 이상의) 인공지능을 미세 조정하는 데에 있어서는 부족하였으나, 이를 추론(Inference)에 사용하는 수준은 가능했습니다. 그래서 저희의 전략은 거대 언어 모델의 추론을 이용해서, 작은 사이즈의 언어모델을 더 잘 학습하는 것에 초점을 맞추게 되었습니다.
그러기 위해 가장 적극적으로 활용한 세가지 전략은 다음과 같습니다.
- Translation → 영어 기사를 프랑스어로, 프랑스어 기사를 영어로 번역해서 각각의 언어를 구사하는 언어모델에게 학습용 데이터를 더해주자
- Data augmentation via Zero-shot Classification → 웹에서 가져온 여러가지 ESG 뉴스기사들을, 더 큰 언어모델들의 합의를 통해 라벨링 하여 학습용 데이터에 더해주자
- GPT3Mix Augmentation → 더 큰 언어모델에게 우리가 해결해야할 문제를 알려줘서, 데이터를 직접 만들어 달라고 해서 학습용 데이터에 더해주자
그리고 이 2,3번 전략을 수행하기 위해, 13B 정도 되는 사이즈의 거대 언어 모델 세 친구가 함께하였습니다.
Pythia, CerebrasGPT, OPT
해당 대회 시작 시기 즈음부터 Alpaca, Vicuna부터 시작된, 효과적으로 사전 학습 및 미세 조정된 오픈소스 언어모델이 출시되었으나, 당시 새로운 미세조정된 오픈소스 언어모델들에 대한 저희 팀의 활용 경험은 아직 부족했습니다. 따라서 이미 활용해 보았던 세 개의 거대 언어 모델을 선정하여 활용하게 됐습니다. Translation의 경우, 단순히 번역을 위한 api를 이용해서 만들었기 때문에 2, 3번 전략에 초점을 두어 설명 드리겠습니다.
Data Augmentation via Zero-shot Classification
멋있게 적어두었지만, 사실 특별한 기술은 아닙니다. 대부분 크기가 큰 언어모델은 작은 모델들보다 더 많은 지식과 능력을 가지고 있습니다. 특히 크기가 큰 언어모델이 작은 언어모델보다 잘하는 것 중 하나가 Zero-shot Classification입니다.
일반적으로 과거 딥러닝 기반의 작은 인공지능들은 학습 시 보았던 데이터들에 대해서만 그 분류를 예측할 수 있었는데요,
시간이 지나고 인공지능이 더 많은 데이터를 학습함에 따라 자신이 학습했던 지식을 전이하여 처음보는 데이터의 분류를 예측할 수 있게 되었습니다.
이 말은 즉, 어느정도 크기가 있고 학습을 많이 한 인공지능은 저희가 풀어야 할 이 문제에 대해서도 추가적인 학습 없이 분류가 가능하다는 것이죠! (물론 정확도가 직접 데이터를 학습한 경우보다 대부분 떨어집니다)
저희는 이를 이용해서 데이터를 증강(augmentation)하기로 하였습니다.
저희는 데이터셋이 부족한 상태에서, 각 이슈가 다루고 있는 폭넓은 주제들을 포착하기 위해 저희는 Pythia, CerebrasGPT, OPT에게 라벨에 대한 정보를 주고 Zero-shot classification을 수행했습니다.
그러나 Zero-shot classification은 정확도가 높지 않고, 세 모델은 작은 모델은 아니지만 저희가 마주하는 마법같은 능력을 지닌 언어모델들에 비해 작은 크기이기 때문에 라벨에 대한 신뢰도가 그다지 높지 않았습니다.
따라서 다음의 세 조건을 모두 만족하는 데이터만을 필터링하여 학습 데이터에 추가하게 되었습니다.
1번 조건이 가장 중요하게 활용되었고, 2번 및 3번 조건은 그 후 데이터를 전처리를 할 때 활용한 조건입니다.
- 세 개의 모델이 모두 동일한 라벨을 골랐을 것
- 각 ESG 이슈의 핵심 키워드가 포함되어 있을 것 (이는 저희가 사전에 이슈 별로 몇 개의 키워드들을 만들어 둔 것을 활용했습니다)
- 라벨 별 데이터들로 Document Embedding을 기반의 군집을 형성 하였을 때, 군집 중심으로부터 거리가 멀 때 (가장 먼 20%의 데이터 제거)
이런 조건에 따라 데이터가 수집되었고, Crawled(da)라는 이름으로 학습을 위한 준비가 완료되었습니다.
GPT3Mix Augmentation
GPT3Mix는 생성형 언어모델이 지닌 지식과 능력을 이용하여, 주어진 문제에 맞는 데이터를 증강해내는 기법입니다. (자세한 사항은 다음 논문을 참고해주세요!)

위의 그림처럼 GPT3Mix는 언어모델에게 문제에 대한 설명 (Task Specification) 및 예시 (Examples)를 보여주고 이에 따라 데이터를 생성해내는 방법론입니다. 저희는 해당 방법론에 따라 저희의 문제에 대한 설명을 기술하고, 저희가 가진 라벨들에 대한 설명을 붙인 뒤 학습 데이터셋을 이용한 (없는 라벨에 대해서는 제로샷 분류한 데이터로부터) 예시를 보여주었습니다.
헌데 35개나 되는 라벨과 이에 대한 예시를 모두 붙이게 된다면 일단 길이가 과도하게 길어지고(+이로 인해 메모리 사용량이 과도해지고) 생성 자체도 어려워지는 문제가 있었습니다. 그래서 저희는 라벨간 유사도를 바탕으로, 약 2~5개의 라벨에 대한 군집을 형성하고 그 군집 내에서 GPT3Mix를 통해 데이터를 증강하였습니다.
저희는 Pythia, CerebrasGPT, OPT 세가지 모델을 이용하였고, 이후 간단한 검수 작업을 통해 (그러나 저희의 눈은 고생이 많았습니다) 데이터셋을 제작했습니다.
각각의 데이터셋은 사용한 거대언어모델에 따라
GPTMix-Pythia(pyt)
GPTMix-CerebrasGPT(cpt)
GPTMix-OPT(opt)
라는 이름을 부여했습니다. (GPT3Mix에서 3이 빠진건 무시해주세요)
그렇게 만들어진 우리의 데이터셋
그렇게 저희의 데이터셋이 완성되었습니다. 처음 증강했던 데이터들은 여러 검수 작업을 거치며 그 양이 줄어들었고, Zero-shot classification을 통해 증강하려던 데이터는 영어에 대해서는 잘 데이터셋이 만들어졌으나 프랑스어에 대해서는 데이터 수집부터 Zero-shot classifcation, 그리고 검수까지 모든 과정이 험난했기에(프랑스어를 잘 몰라서요..) 결국 만드는 것을 실패했습니다. 또한 GPTMix 데이터셋들을 전부 모아서 만든 대량의 데이터셋인 GPTMix-Mixed Models(mix) 데이터셋도 준비하였습니다.

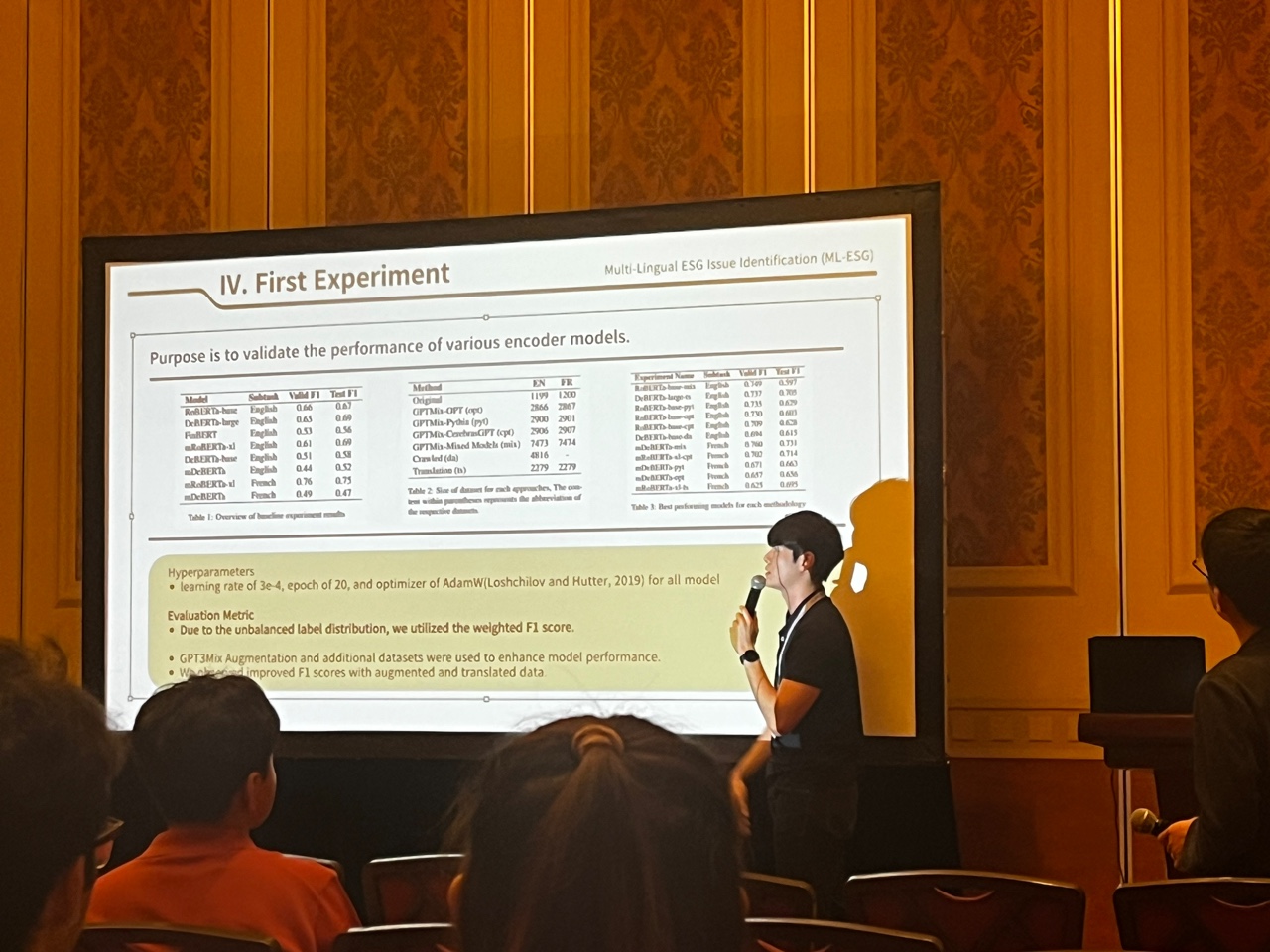
학습의 여정, 그리고 결말
여러가지 데이터 증강 기법을 통해 데이터에서 오는 제약 사항을 어느 정도 해결하고 난 뒤, 저희가 할 수 있는 일은 쉼없이 새로운 언어모델들에 데이터를 학습시키는 일 뿐이었습니다. 저희는 분류기로서 성능이 좋고 학습이 비교적 효율적인 Transformer Encoder 구조의 사전학습된 언어모델들을 조사했습니다. BERT, RoBERTa, DeBERTa, FinBERT, mDeBERTa, mRoBERTa 모델들이 선정되었고 각 모델들의 base 모델부터 large 모델까지 전부 준비가 되었습니다. 그리고 각 사전 학습된 언어모델들은 저희가 회사에 있는 동안, 저희가 밥을 먹는 동안, 그리고 저희가 잠을 잘 때에도 계속 학습되었습니다.
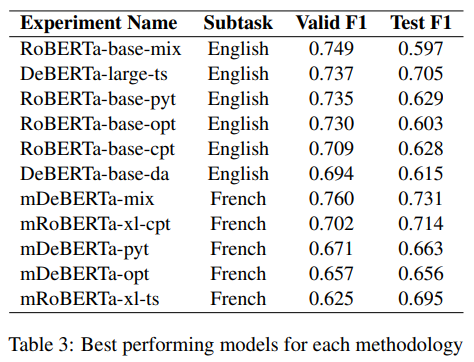
어떤 모델은 아예 학습이 제대로 이루어지지 않기도 했고, 어떤 모델(금융 코퍼스로 학습되었던 FinB..읍읍) 은 기대에 비해 훨씬 떨어지는 성능을 보여주기도 했습니다. 그러나 저희가 실험을 계속해서 진행하며, 저희가 제시한 방법론이 실제로 어느정도 성능 향상을 이끌어내고 있다는 점을 확인하였습니다. 저희 팀은 해당 블로그에 제시된 방법에 더해, validation set sampling에 변화를 주고 하이퍼파라미터 튜닝, 앙상블 기법도 추가하여 성능을 조금씩 개선해나갔습니다.
그리고,
English subtask 1위, French subtask 2위
Trading Central Labs, Fidelity Investments, 등 오랜 기간 FinNLP SharedTask에서 높은 성적을 거둬 온 타 기업 및 학교들을 제치고 높은 성적을 기록했습니다. English subtask에서는 높은 성적으로 1위를 기록했고, French Subtask에서는 아주 미묘한 차이로 아쉽게 2등을 차지했습니다.
해당 성적과 참여내용을 바탕으로, IJCAI에서 열리는 FinNLP Workshop에 저희의 문제 해결과정이 담긴 논문을 제출하였고 마카오에서 열린 해당 워크숍에서 이를 발표할 기회를 얻었습니다.
(논문 작성 기간은 겨우 10일 정도 줬습니다…흑흑..너무해)

이후 NCMU팀 모두 함께 마카오에서 열린 IJCAI 컨퍼런스에 참여해서(대회를 개인적으로 참여했기에 저희 사비로 갔습니다..) 다양한 연구자들과 교류했으며
저희 팀이 이 문제를 해결한 방법들 워크숍 자리에서 역시 다양한 금융 인공지능 연구자들에게 공유할 수 있었습니다!
그 이후
이번 대회에서 얻은 값진 경험은 단순히 대회 안에서만 끝나지 않았습니다. 이 세상에 데이터는 많지만, 저희가 해결해야 할 일이 아주 좁고 전문적인 영역일 수록 이를 위한 데이터는 부족해집니다. 저희 팀은 연구 과정에서도 수 많은 Low-Resource 문제를 맞닥뜨리게 되었고, 그 과정마다 본 SharedTask에서 얻게 된 노하우와 경험들은 좋은 기반이 되었습니다. 그리고 그 노하우들은 현재 세상에 공개되기 위한 서비스와 프로덕트를 위해서 열심히 사용되고 있습니다.
이후에도 저희 시장이해AI팀의 여러가지 도전기와, 저희가 활용하고 발전시킨 기술들에 대해서도 자주 소개 드리겠습니다.
금융AI 분야에서 NCSOFT의 시장이해AI팀의 행보를 기대해주세요!
