
- 들어가며
- 기계 번역이라는 사막에서 바늘을 찾기
- MTQA (Machine Translation Quality Assessment)
- 기계 번역 평가도 인공지능이 한다고요?
- 마치며
- 참고 자료
작성자
- 손동철 (AI번역서비스실)
사용자들의 채팅을 분석하고, 노이즈에 강건한 번역 시스템을 연구하고 있습니다.이런 분이 읽으면 좋습니다!
- 인공지능은 조금 알지만, 기계 번역에 대해서는 잘 알지 못하는 분
- 인공지능을 실제 서비스로 제공할 때, 이슈 대응을 위해 어떤 연구가 이뤄지는지 알고 싶은 분
이 글로 알 수 있는 내용
- 기계 번역 품질 평가의 어려움
- 기계 번역 품질을 자동으로 평가하는 방법
들어가며
안녕하세요, 여러분의 AI는 안녕하신가요? 2022년 ChatGPT가 세상에 공개되면서 우리 일상에 많은 변화를 가져왔습니다. 그중에서도 인공지능에 대한 인식이 눈에 띄게 변화한 것 같습니다. 과거에는 인공지능이 먼 미래의 이야기이거나 영화 터미네이터의 스카이넷처럼 막연한 공포의 대상이었다면, 이제는 유용한 도구이자 때로는 엉뚱한 모습을 보이기도 하는 친근한 존재가 되었습니다. 그림 1 예시처럼, 인공지능의 부정확한 답변도 하나의 유희로 즐기곤 하니까요.
 그림 1. 농구 선수 전태풍에 대해 엉뚱한 설명을 내놓은 ChatGPT (출처: 유튜브 채널 ‘피식대학’)
그림 1. 농구 선수 전태풍에 대해 엉뚱한 설명을 내놓은 ChatGPT (출처: 유튜브 채널 ‘피식대학’)
이처럼 인공지능은 날로 발전하고 있지만, 여전히 실수하기도 합니다. 그런데도 과거보다 더 많은 인공지능 서비스가 출시되었고, 이를 통해 도움을 받는 사람들이 늘었습니다. 완벽하지 않다는 것을 알면서도 큰 관심을 받는다는 게 신기하지 않나요? 어쩌면 인공지능의 실수가 그렇게 큰 문제가 아니었을 수도 있다는 생각이 듭니다. 사람 역시 실수할 때가 있으니까요. 중요한 것은 그 실수가 반복되지 않도록 노력하는 것이며, 이는 인공지능을 활용할 때도 마찬가지 아닐까요?
맞습니다. 특히 제가 속한 엔씨와 같이 인공지능 서비스를 제공하는 곳이라면, 실수를 관리하는 노력이 매우 중요합니다. 그래서 이번 글에서는 인공지능의 실수를 관리하기 위해 저희가 진행 중인 연구를 소개하고, 그 경험을 공유하려 합니다. 이어지는 글에서는 엔씨가 제공하는 대표적인 인공지능 서비스, 채팅 기계 번역을 간략히 설명하고 번역 모델의 실수를 관리하기 위한 연구로 MTQA (Machine Translation Quality Assessment)를 소개하겠습니다.
기계 번역이라는 사막에서 바늘을 찾기
기계번역
최근 몇 년간 인공지능 분야에는 몇 가지 큰 이벤트가 있었습니다. 2016년 알파고와 이세돌 9단의 대국, 그리고 2022년 ChatGPT 공개. 이러한 이벤트는 대중들에게 인공지능이 더 이상 먼 미래가 아님을 각인시킨 계기가 되었습니다. 그런데 저희가 그보다 더 오래전부터 인공지능을 사용해 왔다고 하면 믿기시나요? 잘 생각해 보세요. 해외여행을 갈 때, 휴대폰에 번역기 앱 하나쯤 설치해 본 경험이 있으실 테니까요.
이 번역기에 사용된 인공지능 기술은 바로 기계 번역(MT, Machine Translation)입니다. 기계 번역은 자연어 처리(NLP) 분야에서 오랜 역사를 지닌 연구로, 축적된 기술력을 바탕으로 다양한 서비스로 제공되어 온 대표적인 인공지능 기술입니다. 여러분이 잘 아는 Google 번역도 약 20년 전에 처음 공개되어 대중들에게 기계 번역 기술을 선보였습니다. 그만큼 우리 일상 깊숙이 자리 잡아, 이제는 기계 번역이 없는 삶을 상상하기 어렵습니다. 해외여행이나 해외직구, 외국인 친구와의 펜팔처럼 과거에는 외국어를 알아야만 할 수 있었던 일들을 누구나 할 수 있게 되었으니까요.
NCMT, 엔씨의 기계 번역 서비스
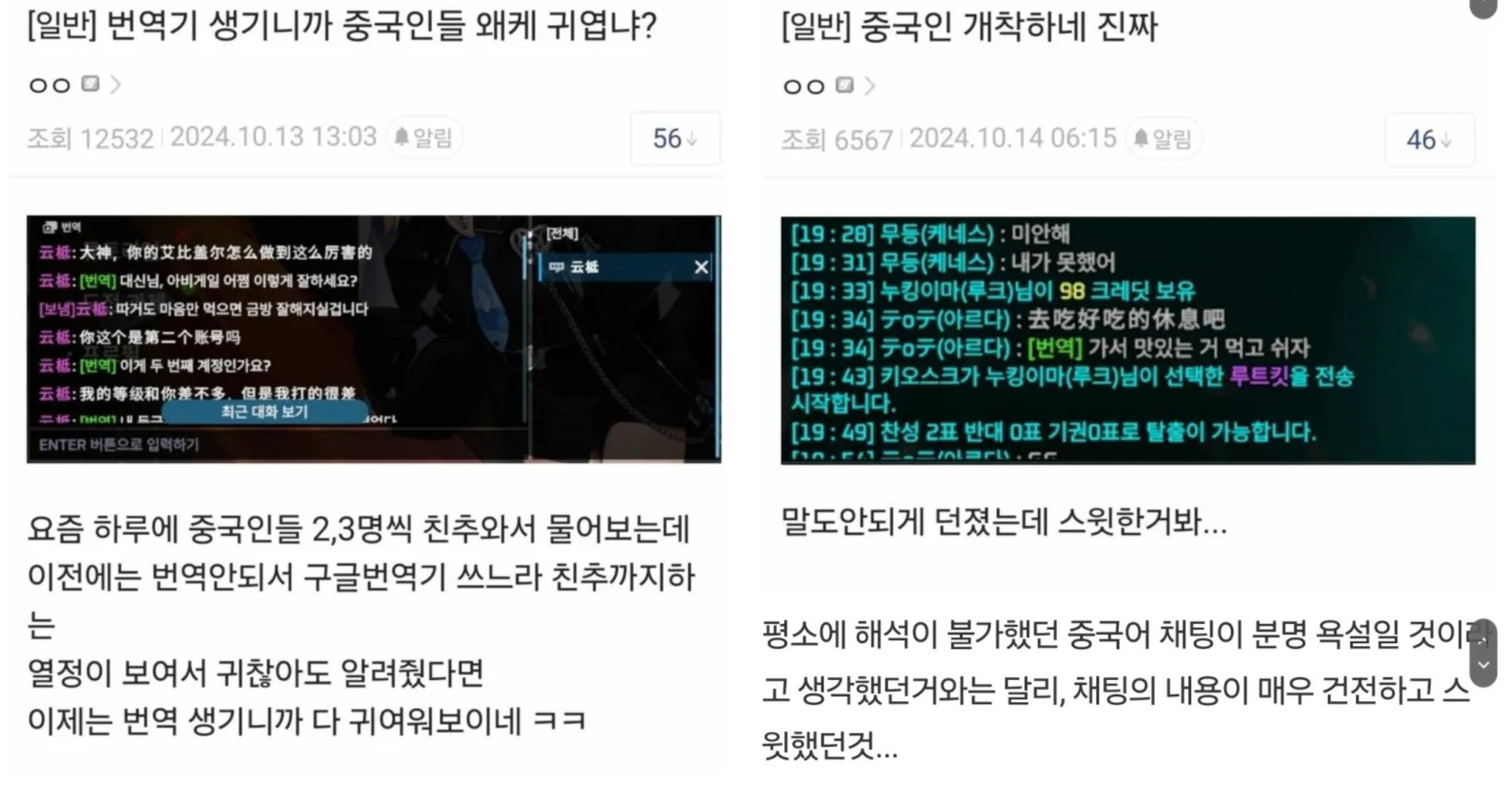
그림 2. (타사 사례) 게임 번역에 대해 긍정적인 유저 반응 (출처: 디시인사이드, 디시인사이드)
그림 2 예시처럼, 과거에는 할 수 없었던 일을 가능하게 만든다는 점에서 기계 번역은 마치 마법과도 같습니다. 사용자에게 큰 만족감을 안겨주는 연구이며, 지금도 더 많은 분야로의 도전이 계속되고 있습니다. 제가 속한 엔씨의 사례를 소개해 드리면, 엔씨는 글로벌 게임 유저 간 소통을 돕기 위해 기계 번역 기술을 활용하고 있습니다. 2021년, 게임 업계 최초로 4개 국어 실시간 채팅 번역 엔진을 공개1했고, 현재는 게임 채팅에서 Google 번역보다 높은 품질의 번역을 제공하고 있습니다.
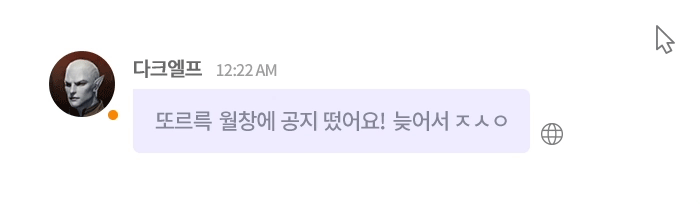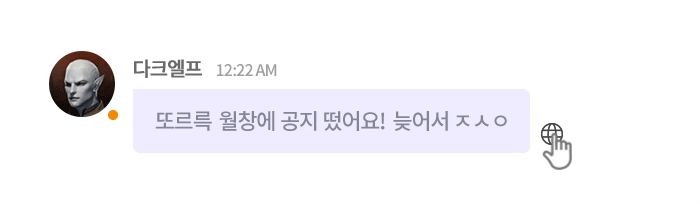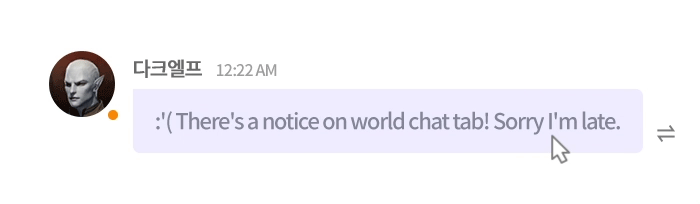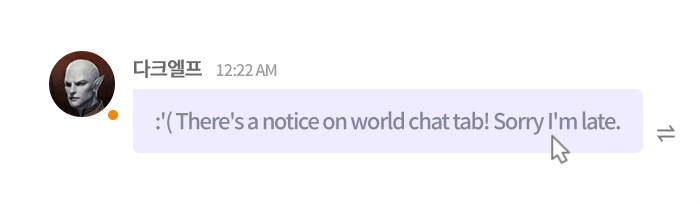
그림 3. 언어의 장벽을 허물허 모든 게이머를 연결하는 실시간 AI 번역 엔진, NCMT1
당연한 말이지만, 기계 번역 연구를 게임 도메인으로 확장하는 일은 결코 쉽지 않았습니다. 기존 연구와 비교할 때, 데이터의 특성도 다르고 고려해야 할 제약도 많았습니다. 기존의 연구가 뉴스 기사와 문서처럼 정제된 텍스트를 다뤘다면, 게임 채팅은 신조어와 은어, 비속어, 게임 특화된 용어, 심각하고 다양한 오탈자, 이모티콘, 이모지, 쉼 없이 올라오는 스팸 광고 메시지가 뒤섞인 환경이었습니다. 덕분에 인공지능 연구에 ‘야생’이 있다면, 바로 이곳이라 생각될 정도였네요. 😂
이처럼 노이즈가 많은 채팅 데이터를 정확한 의미로 실시간 번역하고, 합리적인 비용으로 서비스를 제공하기까지 많은 노력이 필요했습니다. 이는 게임 회사였기에 가능했던 연구였고, 많은 어려움에도 불구하고 연구 성과를 게임 유저 누구나 이용할 수 있는 형태로 서비스했다는 점에서 고무적인 성과로 생각됩니다.
그리고 저희의 연구는 지금도 계속되고 있습니다. 게임 채팅은 어떤 텍스트가 입력될지 예측할 수 없는 환경이므로, 노이즈에 더 강건한 번역 모델을 연구하는 한편, 실수에 대한 리스크를 관리하기 위한 연구도 함께 수행하고 있습니다. 앞서 소개해 드린 MTQA는 이러한 위험을 관리하기 위한 방안으로, 제가 속한 번역서비스실에서 주요하게 다루는 연구 주제 중 하나입니다.
기계 번역 품질을 효율적으로 검토하는 방법
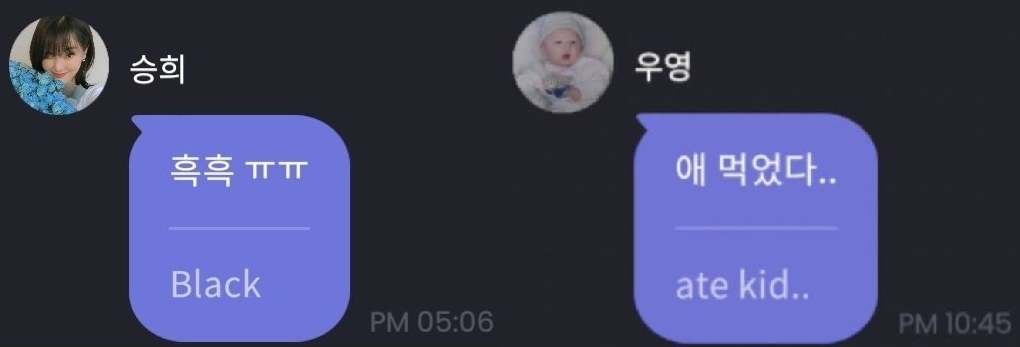
그림 4. (타사 사례) 채팅과 구어체에 강건하지 못하면 오역이 야기될 수 있다 (출처: 아티스트 소통 플랫폼 Dear U bubble)
번역기를 사용한 경험을 떠올려 보면, 번역기가 항상 찰떡같이 번역해 주지는 않았습니다. 위 사진 속 예시처럼 가끔은 실수를 범하기도 하니까요. 물론 사용자들도 인공지능이 완벽하지 않다는 것을 알기에 이를 가벼운 헤프닝으로 여길 수도 있습니다. 하지만 개발자나 서비스를 제공하는 입장에서는 이 문제를 간과할 수 없습니다. 같은 실수가 반복된다면 단순한 오류가 아닌, 서비스 신뢰성을 저해하는 심각한 문제로 이어질 수 있으니까요.
따라서 인공지능 서비스에서는 반드시 오류에 대한 대비책이 필요합니다. 이를 위해 엔씨의 게임 번역 서비스에서는 번역 품질의 안정성을 검증하는 분들이 존재합니다. 하지만 아무리 노력을 기울여도 이 대비책이 완벽할 수는 없습니다. 하루 수백만에서 수천만 건씩 쌓이는 채팅 번역 결과에서 오류를 찾아내는 일은 쉬운 일이 아닙니다. 사람이 처리할 수 있는 업무량에는 한계가 있기 때문이죠. 수많은 번역 결과 속에서 오류를 찾아내는 일은 마치 사막에서 바늘을 찾는 것과 같습니다.
이처럼 번역 품질 검토를 전적으로 사람에게만 맡긴다면, 정해진 시간 내에 정확한 검증을 마치는 것이 사실상 불가능합니다. 그렇다면 이러한 문제를 해결하기 위해 또 다른 인공지능 기술을 활용할 수는 없을까요? 이러한 문제를 해결하고자 엔씨의 기계 번역 서비스는 MTQA 연구에 주목하고 있습니다.
MTQA (Machine Translation Quality Assessment)

그림 5. 같은 대상에 대한 평가도 사람마다 달라질 수 있다 (출처: 무한도전 <짝꿍특집>)
MTQA(Machine Translation Quality Assessment)는 번역된 문장의 품질을 자동으로 평가하는 연구로, 번역 품질을 평가하는 작업이 사람이 하기에는 어렵고 또 시간이 많이 드는 작업이라는 점에서, 이를 인공지능을 통해 더 효율적으로 수행하려는 목적으로 시작되었습니다.
그렇다면, 번역 품질 평가가 왜 어렵다고 말하는 걸까요? 이는 번역에는 명확한 정답이 없기 때문입니다. 사람마다 같은 문장이라도 다르게 번역할 수 있듯이, 번역 평가 결과 역시 평가자에 따라 달라질 수 있습니다. 이런 특징은 특히 엔씨의 채팅 번역 서비스처럼 대량의 채팅 번역 결과를 검토해야 하는 환경에서 큰 문제가 됩니다. 왜냐하면, 대량의 채팅 번역 결과를 신속하게 검토하려면 많은 인력이 필요하지만, 인력이 많아질수록 검토 기준의 일관성을 유지하기 어려워지는 문제가 발생하기 때문입니다.
MTQA는 이러한 문제를 해결하기 위한 강력한 대안입니다. 하나의 인공지능 모델로 평가를 수행하기 때문에, 일관성 있는 평가를 할 수 있을 뿐만 아니라, 사람보다 훨씬 빠른 속도로 작업을 수행할 수 있습니다. 이를 통해 사람이 직접 검증해야 하는 작업량을 크게 줄이고, 인력과 시간을 절약하며, 기계 번역 서비스 운영의 효율성을 높일 수 있습니다.
또한 MTQA는 낮은 품질의 번역을 신속히 감지하여, 사용자에게 노출되지 않도록 자동화된 조치를 취할 수 있습니다. 이와 함께, 번역 모델 간의 성능을 비교하거나 모델 개발 과정에서 품질 개선을 위한 피드백을 제공하는 평가 도구로도 활용할 수 있습니다.
이와 같은 이유로 엔씨에서도 MTQA의 잠재력에 주목하고 관련 연구를 지속하고 있습니다. 실제로 회사 내부적으로는 번역 오류 모니터링 과정에 MTQA 연구를 적용해, 서비스 운영의 효율을 점차 높여가고 있습니다. 그 경험을 공유해 드리고자, 이어지는 글에서는 번역 품질을 평가하는 대표적인 방법론들을 간단히 소개하고, 각 방법론에 대한 생각을 이야기해 보겠습니다.
기계 번역 평가도 인공지능이 한다고요?
Reference-based VS Reference-free
| 평가 방식 | 설명 | 장점 | 단점 |
|---|---|---|---|
| reference-based | 정답 번역(reference)와 비교하여 번역 품질을 평가 | 품질 평가 과정이 직관적이고, 평가 결과에 대한 신뢰도가 높은 편 | 정답 번역 준비에 많은 비용과 시간이 필요한 편. 정답 번역으로 인한 편향된 평가의 위험 |
| reference-free | 정답 번역(reference) 없이 모델이 자체적으로 번역 품질을 추정 | 정답 번역을 준비하지 않으므로, 품질 추정에 비용과 시간이 적게 드는 편 | 품질 평가의 신뢰도는 온전히 모델 성능에 의존 |
번역이 잘 되었는지 확인하는 가장 좋은 방법 중 하나는 번역된 문장의 품질 점수를 계산하는 것입니다. 크게 두 가지 평가 방법이 있습니다. 첫 번째는 reference-based 방법이고, 두 번째는 reference-free 방법입니다. 여기서 reference는 사람이 미리 만들어 둔 정답 번역을 의미합니다. 따라서 reference-based 방법은 모델이 생성한 번역 결과와 정답 번역(reference) 사이의 유사도를 비교하여 평가하는 방식입니다. 이 과정에서 주로 n-gram 출현 빈도2나 단어 임베딩3 같은 기법이 활용됩니다.
정답 번역을 활용한 품질 평가
reference-based 평가 방법의 대표적인 예는 BLUE(BiLingual Evaluation Understudy)2 입니다. BLEU는 번역된 문장과 정답(reference) 간의 n-gram 일치도를 계산하여 유사도(Precision)를 구하는 방법입니다. 수식을 이용해 번역 품질을 간편하게 평가할 수 있고, 평가 결과를 수식으로 설명할 수 있다는 점이 큰 장점입니다. 하지만 몇 가지 한계로 인해 평가 결과를 전적으로 신뢰하기 어려운 경우도 있습니다.
첫 번째 한계는 reference에 대한 의존성입니다. 평가자에 따라 평가 결과가 달라질 수 있듯이, reference에 따라 평가 결과도 달라질 수 있습니다. 이는 reference가 사람에 의해 만들어지기 때문입니다. 이로 인해, 실제로는 옳은 번역임에도 불구하고 reference와 다르다는 이유로 낮은 점수를 받을 위험이 있습니다.

그림 6. 엔씨 게임 채팅 예시, 게임 채팅은 그 의미가 모호한 경우가 굉장히 많다
그림 6은 대표적인 예시입니다. 실제 엔씨 게임인 리니지W의 채팅 내용을 각색한 것으로, 주어진 문장에서 ‘요새’는 두 가지 의미로 해석될 수 있습니다. 따라서 두 가지 모두 옳은 번역 결과일 수 있지만, 만약 하나의 reference만 준비했다면 어떻게 될까요? 아마 다른 한쪽의 번역 결과는 낮은 점수를 받을 가능성이 큽니다. 게임 채팅에서는 이처럼 의미를 정확하게 파악하기 어려운 채팅이 많이 입력되므로, 편향된 품질 평가가 수행될 위험 역시 큽니다.
두 번째 한계는 reference 준비에 드는 비용과 시간입니다. 고품질의 reference를 준비하려면 두 언어에 능통한 전문가를 고용해야 하므로, 충분한 양의 reference를 만드는 데 많은 비용과 시간이 소요됩니다. 만약 엔씨처럼 게임 채팅 번역에 대한 reference를 준비하려면 신조어나 엔씨 게임 용어에 대한 전문 지식도 필요합니다. 그런데 사실 가장 큰 문제는 사용자가 어떤 채팅을 입력할지 미리 알 수 없다는 점입니다. reference를 미리 준비할 수 없으므로, reference를 활용하여 품질을 평가하는 방식은 실세계에서 활용하기 어렵습니다.
정답 없이도 품질을 계산할 수 있을까?
그래서 최근에는 reference-free 평가 방법이 주목받고 있습니다. reference-free 방법은 샘플마다 reference를 준비하지 않고도 번역 품질을 산출할 수 있어 효율적이며 실제 활용하기에도 적합한 방법입니다. 이 방법의 대표적인 연구로는 COMET-QE4가 있습니다. COMET-QE는 기존의 COMET5 모델의 후속 연구로, reference 없이 번역 품질을 평가할 수 있도록 설계된 모델입니다. 이 모델은 강력한 다국어 이해 능력을 가진 PLM(Pre-trained Language Model)을 인코더로 활용하며, 기존의 평가지표(e.g., BLEU, chrF)보다 사람의 평가와 더욱 유사한 결과를 제공하는 게 특징입니다.
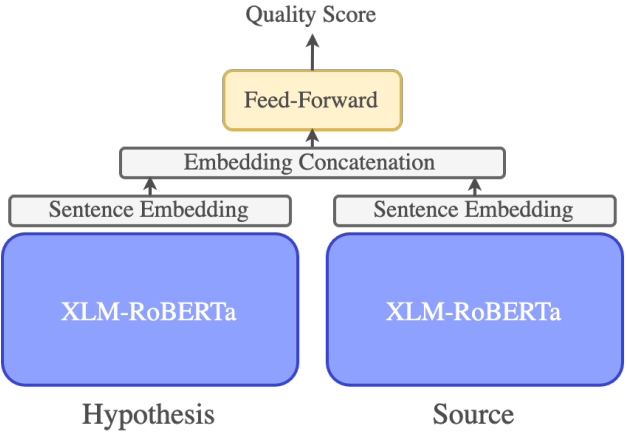
그림 7. COMET-QE 모델 구조4
과거에는 다국어 이해 능력이 부족해 reference에 의존한 평가를 수행했지만, XLM-Roberta6와 같이 강력한 다국어 이해 모델의 등장으로 원문(source)과 번역 결과 간의 의미적 유사도를 직접 비교할 수 있게 되었습니다. 그리고 이처럼 모델의 지식을 바탕으로 번역 품질을 0~100점 사이로 추정하는 방법을 DA(Direct Assessment)라고 부릅니다.

그림 8. 정준하씨처럼, 인공지능 모델도 나름의 사고를 거쳐 품질 점수를 추정한다 (출처: 무한도전 <짝꿍특집>)
reference를 준비하지 않아도 된다는 점에서 기존의 reference 기반 평가보다 효율적이고 실용적인 대안이지만, 아쉽게도 이 방법 역시도 몇 가지 한계점을 가지고 있습니다. 첫 번째 한계는 신뢰하기 어려운 품질 점수입니다. BLEU와 같은 방법은 점수 산출 과정을 수식으로 설명할 수 있지만, COMET-QE는 점수 산출 과정이 직관적이지 않습니다. 특정 점수가 도출된 이유를 명확히 알 수 없기 때문에, 평가 결과를 신뢰하는 데 한계가 있습니다.
신뢰할 수 있느냐는 문제 이전에, 해석의 어려움 자체가 번역 서비스를 운영하는 입장에서 문제가 될 수 있습니다. 예를 들어, 한국어 → 아랍어로 번역된 문장에 대해 MTQA 모델이 낮은 점수를 주었다면, 번역된 아랍어 문장에서 무엇이 잘못되었는지 즉시 파악하기 어려울 수 있습니다. 정확한 원인을 파악하려면 결국 두 언어에 능통한 전문가의 도움이 필요하므로, 문제를 해결하는 데 시간이 많이 소요될 수 있습니다. 즉, 해석의 어려움은 MTQA 모델이 추정한 품질 점수를 바탕으로 적절한 피드백을 받기 어렵다는 것을 의미합니다.
두 번째 한계는 여전히 사람의 개입을 필요로 한다는 점입니다. reference 기반 방식에 비해 사람의 개입이 줄어들긴 했지만, 여전히 충분한 양의 학습 데이터가 필수적입니다. 이 데이터를 준비하는 작업은 사람이 수행해야 하므로, 완전한 자동화를 이루기는 어렵습니다. 그렇다면, 사람의 개입을 최소화하면서도 신뢰할 수 있는 품질 평가를 제공하는 방법은 없을까요?
MQM (Multidimensional Quality Metrics)
MTQA 모델이 왜 그런 점수를 주었는지 설명할 수 있다면, 평가 결과의 신뢰성도 훨씬 높일 수 있지 않을까요? 이를 위한 방법이 바로 MQM (Multidimensional Quality Metrics)입니다. DA가 품질 점수만을 추정하는 방법이었다면, MQM은 품질 점수뿐만 아니라, 특정 문자열 범위(span)에서 발생한 오류의 종류와 심각도를 함께 탐지하는 평가 방법입니다. 이러한 평가 방법은 엔씨와 같이 기계 번역 서비스의 품질을 모니터링하는 곳에서 특히 유용할 것처럼 보입니다.
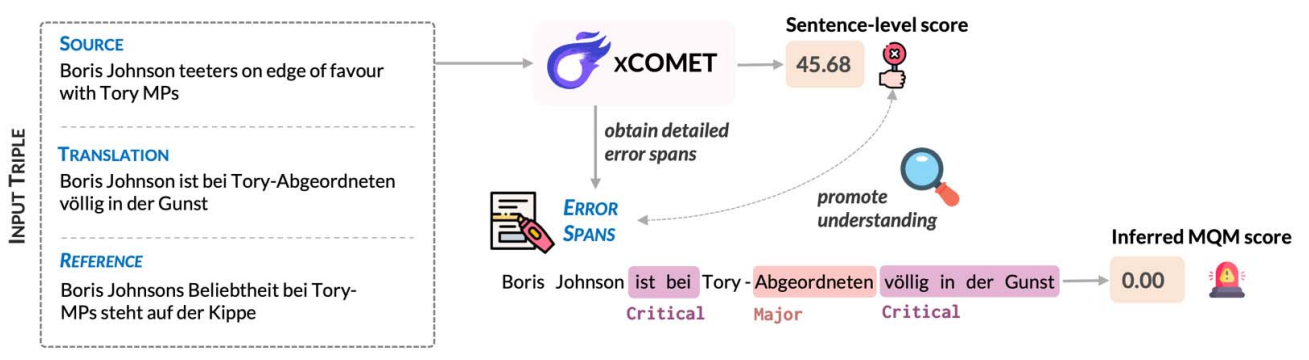
그림 9. xCOMET의 추론 예시7
물론, 품질 점수만을 추정하던 MTQA 모델이 하루아침에 오류도 예측하는 능력을 갖출 수는 없습니다. 모델 구조를 수정하고, 새로운 MQM 학습 데이터 구축한 뒤에야 비로소 품질 점수와 오류를 동시에 탐지할 수 있는 MTQA 모델을 개발할 수 있습니다. 따라서 MQM 방법은 유망한 대안이지만, 또 한편으로 실제 서비스에 적용하기에는 아직 진입 장벽이 있는 평가 방법이기도 합니다. 공개되어있는 MQM 모델은 노이즈가 많은 채팅 데이터에 대한 지식뿐만 아니라, 엔씨 게임에 대한 지식도 부족하기 때문입니다. 저희 엔씨만의 MQM 모델이 필요한 이유가 바로 여기에 있습니다.
그림 9는 MQM의 대표적인 연구인 xCOMET7의 추론 예시입니다. xCOMET은 reference가 있을 때와 없을 때모두 품질 평가를 지원하는 모델로, 그림 9는 reference가 있을 때의 추론을 보입니다. 하지만 reference가 없더라도 비슷하게 평가를 수행할 수 있기 때문에, 학습이 잘 된 MQM 모델은 유망한 품질 평가 도구로 활용될 수 있습니다.
거대 언어 모델(LLM)을 활용한 품질 평가
만약 인공지능이 훨씬 더 똑똑해져서, 별도의 추가 학습 없이도 번역 품질을 평가할 수 있다면, 비로소 사람의 개입이 최소화된 품질 평가를 할 수 있지 않을까요? 맞습니다. 그래서 최근 MTQA 연구에서는 LLM(Large Language Model)을 활용한 번역 품질 평가가 주목받고 있습니다. 이 방법은 별도의 reference나 학습 데이터를 구축할 필요 없이, 단순히 LLM에 프롬프트를 입력하는 것만으로 품질 평가를 수행할 수 있기 때문입니다. 이러한 장점 덕분에 번역 품질 평가 과정에서 사람의 개입이 최소화되었습니다.
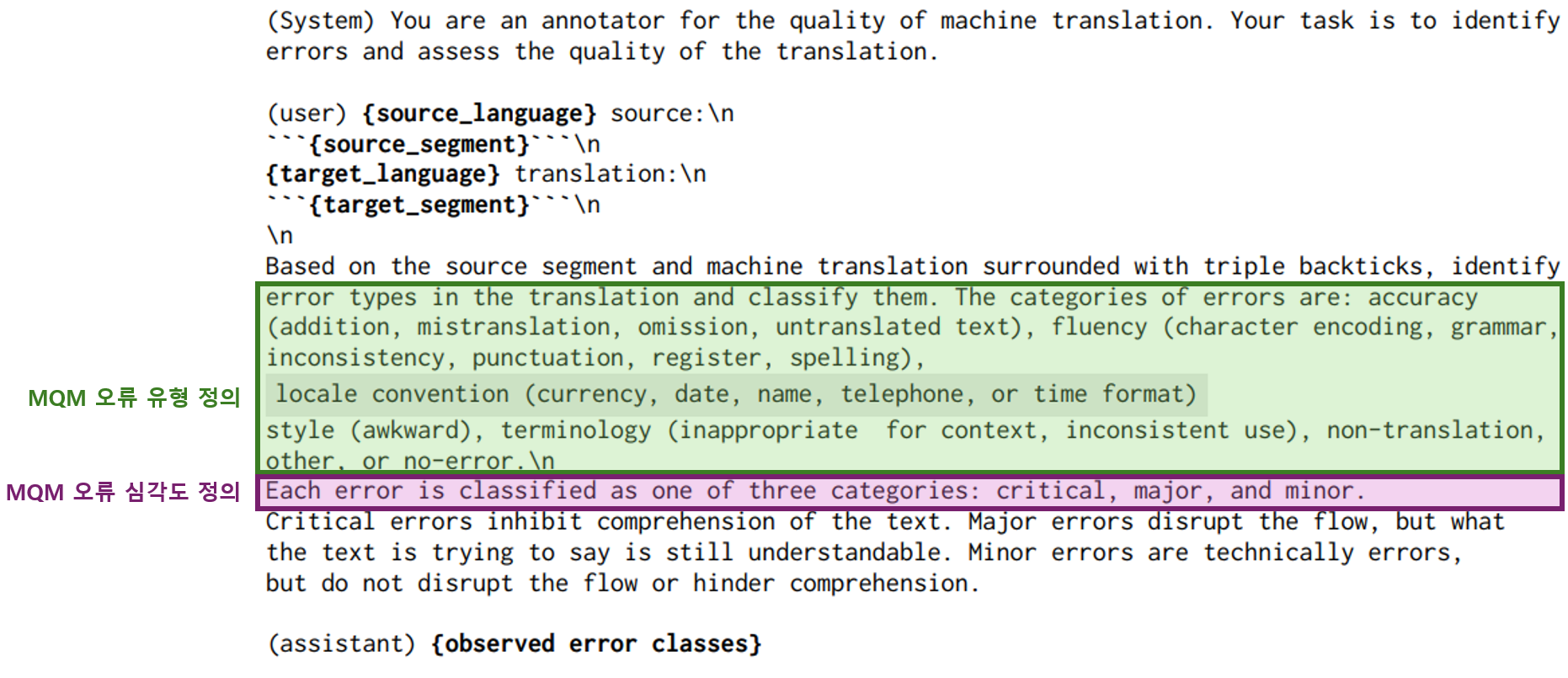
그림 10. GEMBA-MQM 프롬프트 입력 예시8
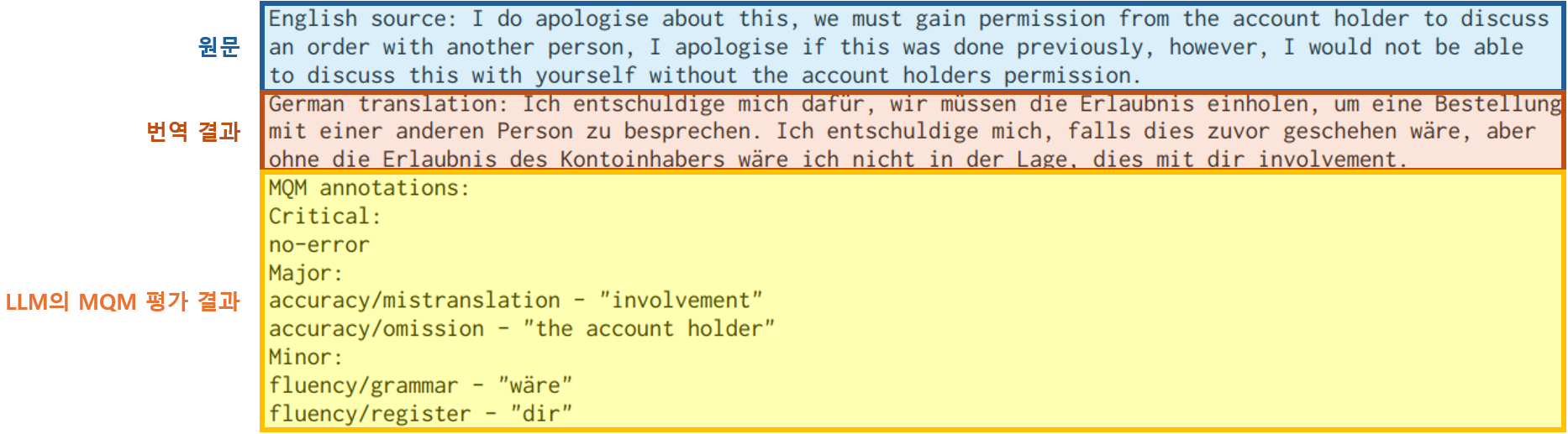
그림 11. GEMBA-MQM 프롬프트를 입력받은 GPT-4의 생성 결과8
LLM을 품질 평가에 활용하는 대표적인 연구 중 하나는 GEMBA-MQM8입니다. 이 연구에서는 OpenAI의 GPT-4에 프롬프트를 입력하여 번역 품질을 평가하며, LLM에 어떤 방식으로 프롬프트를 입력해야 효과적으로 품질 평가를 수행할 수 있는지를 중점적으로 탐구합니다. 그림 10과 그림 11은 프롬프트만으로 품질 평가를 수행하는 GEMBA-MQM의 예시입니다.
LLM을 활용한 방법은 간편하게 품질을 평가할 수 있다는 장점 외에도, 달라지는 평가 기준에 쉽게 대응할 수 있다는 강점이 있습니다. 예를 들어, MTQA를 활용하는 환경과 목적에 따라 정의하는 오류 유형이 달라질 수 있습니다. xCOMET과 같은 방법론은 이러한 변화에 대응하기 위해 학습 데이터를 재구성하고 모델을 다시 학습해야 합니다. 반면, LLM 기반 품질 평가에서는 프롬프트에 변화된 내용을 추가 설명하는 것만으로도 효과적으로 대응할 수 있습니다.
학습 데이터라는 제약까지 벗어던졌으니, LLM을 활용한 품질 평가 방법이 가장 좋은 걸까요? 저는 아직 확답할 수 없다고 생각합니다. 여기에는 몇 가지 이유가 있는데, 사실 가장 큰 이유는 현실적인 문제입니다. 엔씨에서는 게임 콘텐츠 번역 결과를 GPT-4로 품질 평가한 사례가 있습니다. 최적의 프롬프트를 찾기 위해 여러 실험을 진행했고, 그 결과 일부 성과도 얻었지만, 동시에 몇 가지 어려움도 맞닥뜨렸습니다. 왜냐하면, 만능처럼 보이는 LLM도 ‘평가’라는 작업에서는 종종 제어하기 어려운 경우가 많기 때문입니다. 여기에는 여러 가지 이유가 있겠지만 MTQA 선행 연구에서도 지적이 되는 점이기도 합니다.
그런데 사실 가장 큰 문제는 ‘비용’입니다. LLM을 활용하는 방법은 주로 ChatGPT나 Claude와 같은 외부 LLM API를 사용하는 형태입니다. 이는 하루에도 수백만, 수천만 건씩 채팅 번역 결과가 쌓이는 엔씨와 같은 환경에서 활용하기에는 쉽지 않은 방법입니다. 따라서 LLM 기반 평가를 도입할 때는 비용 문제를 포함해 다양한 현실적인 제약을 함께 고려해야 합니다.
마치며
지금까지 MTQA가 무엇인지 소개하고, 각 방법에 대한 생각을 공유해 보았습니다. 흥미로운 점은 최신의 방법이 반드시 최고의 방법은 아니라는 사실입니다. 이는 MTQA가 연구적 차원은 물론, 실제 서비스 관점에서도 유용한 연구로, 도입하려는 환경과 목적에 따라 적절한 방법이 달라질 수 있기 때문이었습니다.
그만큼 MTQA는 다양한 가능성 및 잠재력을 가진 연구 분야로 주목받고 있습니다. 예를 들어, MTQA를 연구를 거대 기계 번역 모델의 RLHF(Reinforcement Learning from Human Feedback) 학습 과정의 Reward 모델로 활용하려는 시도9가 있었고, 조금 더 실제 문제 해결에 초점을 맞춘 경량화된 MTQA 모델을 제안10하거나, 채팅 번역에서 발생하는 오류를 분석하고 해결하려는 연구11도 활발히 진행되고 있습니다.
저희 AI번역서비스실은 사용자에게 조금 더 고품질의 번역을 제공하는 것을 목표로 끊임없이 노력하고 있습니다. MTQA는 그러한 노력의 일환이며, 번역 서비스의 안정성을 보장하고 운영 효율성을 크게 향상시킬 수 있을 것으로 기대하고 있습니다. 이러한 저희의 노력이 언어의 장벽을 허물고 더 많은 사람들이 자유롭게 소통할 수 있도록 기여하길 바랍니다.
참고 자료
-
NC Research. 2021. 언어의 장벽을 넘어 세상 모든 게이머를 연결하는 실시간 AI 번역 엔진, NCMT ↩ ↩2
-
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318. ↩ ↩2
-
Muhammad ElNokrashy and Tom Kocmi. 2023. eBLEU: Unexpectedly Good Machine Translation Evaluation Using Simple Word Embeddings. In Proceedings of the Eighth Conference on Machine Translation, pages 746-750. ↩
-
Ricardo Rei, Ana C Farinha, Chrysoula Zerva, Daan van Stigt, Craig Stewart, Pedro Ramos, Taisiya Glushkova, André F. T. Martins, and Alon Lavie. 2021. Are References Really Needed? Unbabel-IST 2021 Submission for the Metrics Shared Task. In Proceedings of the Sixth Conference on Machine Translation, pages 1030-1040. ↩ ↩2
-
Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. COMET: A Neural Framework for MT Evaluation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2685-2702. ↩
-
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzman, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116. ↩
-
Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and André F. T. Martins. 2024. xcomet: Transparent Machine Translation Evaluation through Fine-grained Error Detection. Transactions of the Association for Computational Linguistics, 12:979-995. ↩ ↩2
-
Tom Kocmi and Christian Federmann. 2023. GEMBA-MQM: Detecting Translation Quality Error Spans with GPT-4. In Proceedings of the Eighth Conference on Machine Translation, pages 768-775. ↩ ↩2 ↩3
-
Zhiwei He, Xing Wang, Wenxiang Jiao, Zhuosheng Zhang, Rui Wang, Shuming Shi, and Zhaopeng Tu. 2024. Improving Machine Translation with Human Feedback: An Exploration of Quality Estimation as a Reward Model. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8164–8180 ↩
-
Daniil Larionov, Mikhail Seleznyov, Vasiliy Viskov, Alexander Panchenko, and Steffen Eger. 2024. xCOMET-lite: Bridging the Gap Between Efficiency and Quality in Learned MT Evaluation Metrics. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21934-21949. ↩
-
Sweta Agrawal, Amin Farajian, Patrick Fernandes, Ricardo Rei, and André F. T. Martins. 2024. Assessing the Role of Context in Chat Translation Evaluation: Is Context Helpful and Under What Conditions?. Transactions of the Association for Computational Linguistics, 12:1250–1267 ↩
