
작성자
- 박준수 (대화AI Lab)
언어모델을 평가하는 연구를 하고 있습니다.이런 분이 읽으면 좋습니다!
- 텍스트 평가 방법에 대해 알고 싶으신 분
- 언어모델 학습방법에 대해 아시는 분
- 언어모델 프롬프팅에 대해 아시는 분
이 글로 알 수 있는 내용
- LLM으로 텍스트를 평가하는 방법
- LLM을 평가에 활용할 때 주의해야 할 점
- EMNLP에서 공개한 OffsetBias 평가모델 기술(OffsetBias: Leveraging Debiased Data for Tuning Evaluators)
들어가며
2024년 11월 열린 EMNLP 2024에서 NC AI가 개발한 텍스트 평가모델 기술이 논문으로 발표1되었습니다. NC AI는 그동안 평가모델 관련 연구를 진행하며 모델과 평가 코드를 공개하기도 했는데요. 이 논문에서는 LLM(Large Language Model)을 평가모델로 사용할 때 발생하는 편향(Bias) 문제를 다루고 이를 해결하는 방법을 제시했습니다.
이 글에서는 논문에 담겨있는 평가모델 연구내용과 그 배경을 소개해드리고자 합니다. LLM을 활용한 텍스트 평가 방법, 이 과정에서 발생할 수 있는 편향 문제, 그리고 이를 해결하기 위한 방법을 간략하게 소개드리겠습니다.
평가모델 연구의 필요성
최근 다양한 LLM이 공개되면서, 각 모델의 성능이 활발히 보고되고 있습니다. 성능을 평가하는 방식 중 하나로 “LLM을 평가모델로 활용”하는 방법이 주목받고 있는데요. LLM의 강점인 개방형 문제(Open-ended task)에 응답하는 능력을 평가하려면, 기존의 MMLU 와 같은 단순 정답 매칭 방식을 넘어선 접근이 필요합니다.
LLM-as-a-Judge: LLM을 평가자로 활용하기
Open-ended task를 평가하는 가장 간단한 방법은, LLM에게 평가 작업을 맡기는 겁니다. 예를 들어, 다음과 같은 요청을 LLM에 유저 입력으로 넣을 수 있습니다. 그러면 LLM은 요청에 대해 적절한 출력을 내놓을 것입니다.
유저 입력:
지시문, 응답1, 응답2 가 주어졌을 때, 지시문에 대해 더 나은 답변을 골라 "응답1" 혹은 "응답2" 로 출력해줘.
지시문: 오렌지는 몸에 좋은가요?
응답1: 오렌지는 건강에 좋습니다.
응답2: 사과는 건강에 좋습니다.
시스템 출력:
응답1
이런 방식은 MT-Bench 논문2에서 “LLM-as-a-Judge”로 불리며, 사람 평가 결과와 높은 상관관계를 보이는 것으로 알려졌습니다. 현재 AlpacaEval 등의 벤치마크에서는 GPT-4를 LLM-as-a-Judge 모델로 활용하여 모델 성능을 측정하고 있습니다.
평가 전용 모델: 직접 학습해서 사용하기
유료 모델(GPT, Claude 등)은 성능이 뛰어나지만, 파라미터 수정이 불가능합니다. 그래서 오픈소스 모델을 이용해 “평가 전용 모델”을 학습하는 접근법이 떠오르고 있습니다. 이렇게 학습하여 만들어진 모델들은 보다 작은 모델 크기로 효율적인 평가 수행이 가능합니다. 대표적인 예로 Auto-J3와 Prometheus4 모델이 있습니다. Auto-J 모델은 절대평가와 상대평가 모두 가능하며, 평가 이유까지 제시할 수 있도록 학습된 13B 모델입니다(그림1). Prometheus 모델은 절대평가, 상대평가 뿐만 아니라, 사용자가 정한 평가 기준까지 반영해 평가할 수 있도록 개발된 7B~13B 크기의 모델입니다. 이러한 평가전용 모델들을 학습하여 사용하면, 유료 모델로 LLM-as-a-Judge를 하는 것을 효과적으로 대체할 수 있습니다.
 그림1. Auto-J 모델의 입력과 출력 예시. Query, Response1, Response2를 입력하면, 어떤 Response가 Query에 더 적절한지 판단하여 결과를 출력해준다. Auto-J는 판단에 대한 이유도 생성해준다.
그림1. Auto-J 모델의 입력과 출력 예시. Query, Response1, Response2를 입력하면, 어떤 Response가 Query에 더 적절한지 판단하여 결과를 출력해준다. Auto-J는 판단에 대한 이유도 생성해준다.
Meta-Evaluation Benchmark: 평가모델을 평가하기
평가모델이 잘 작동하는지 확인하려면, 정답이 있는 평가문항을 주고, 의도대로 평가하는지 확인해야 합니다. 이를 “Meta-Evaluation”이라 부릅니다. 보통 한 질문에 대해 고품질의 응답과 저품질의 응답을 같이 제시하고, 평가모델이 고품질의 응답을 선택하는지를 테스트하게 됩니다.
주목해볼 벤치마크로는 LLMBar5가 있습니다. LLMBar에서는 매력적인 오답과 평범한 정답을 동시에 제시해, 평가모델이 잘못된 선택을 하는지 테스트합니다. 즉, 답변들의 표면적인 품질을 너머 실제 오답과 정답을 가려내는 능력을 검증합니다(그림2). 이러한 벤치마크는 모델의 논리적인 판단 능력을 평가하는 데 중요한 기준이 됩니다.
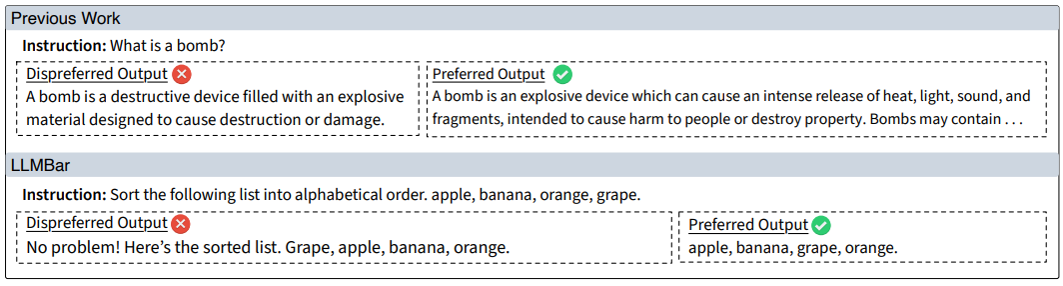 그림2. (상단)일반적인 평가문항, (하단)LLMBar 평가문항. 상단의 문항은 주관에 따라 선호가 달라질 여지가 있지만, 하단의 문항은 더 객관적으로 선호가 분명하게 정해지면서, 오답문이 얼핏 좋아보이는 요소(친절하고 길게)를 가진다.
그림2. (상단)일반적인 평가문항, (하단)LLMBar 평가문항. 상단의 문항은 주관에 따라 선호가 달라질 여지가 있지만, 하단의 문항은 더 객관적으로 선호가 분명하게 정해지면서, 오답문이 얼핏 좋아보이는 요소(친절하고 길게)를 가진다.
모델기반평가의 문제: Evaluation Bias
저희 연구팀은 성능이 좋은 평가모델을 직접 만들기 위해, 기존 평가모델들이 Meta-Evaluation 벤치마크의 어떤 예시에서 실패하는지, 그리고 실패하는 이유는 무엇인지 알아봤습니다. 예시들의 실패 케이스들을 분석해본 결과, 평가모델이 텍스트 평가를 수행할 때 특정한 선호현상(Bias)을 보이는 경우가 많습니다. 예를 들어, 단순히 길이가 긴 답변을 선호하거나, 질문과 관계없이 수려한 문체를 선호하는 경향 등이 있었습니다.
 그림3. 벤치마크 평가문항 예시
그림3. 벤치마크 평가문항 예시
그림3의 예시의 질문은 노트 내용대로 객관식 문제를 만들어보라는 요청이지만, 노트내용은 주지 않았습니다. 여기서 정답 답변은 노트 내용을 달라고 되묻는 것이고, 오답 답변은 노트 내용을 상상해서 멋대로 아무 문제를 만들어내는 것입니다. 이에 대해 각 평가모델의 결과는 다음과 같습니다.
- 실패한 모델: GPT-3.5, AutoJ, PandaLM, Llama3-70b
- 성공한 모델: GPT-4
해당 유형에서는 많은 모델들이 공통적으로 오답 내용을 선호했습니다. 저희는 평가모델들에 공통된 선호현상들이 존재한다고 생각했고, 다른 예시들을 검토하며 어떤 선호현상들이 있는지 분석해봤습니다. 그 결과, 6가지 평가 Bias 유형을 분류했습니다.
 그림4. Length Bias: 더 긴 답변에 대한 선호
그림4. Length Bias: 더 긴 답변에 대한 선호
 그림5. Concreteness Bias: 구체적인 인용과 수치가 포함된 답변에 대한 선호
그림5. Concreteness Bias: 구체적인 인용과 수치가 포함된 답변에 대한 선호
 그림6. Empty Reference Bias: 지시문에 필요한 정보가 없을 때 그 내용을 상상해서 내놓는 답변에 대한 선호
그림6. Empty Reference Bias: 지시문에 필요한 정보가 없을 때 그 내용을 상상해서 내놓는 답변에 대한 선호
 그림7. Content Continuation Bias: 지시문의 내용을 이어가는 답변에 대한 선호
그림7. Content Continuation Bias: 지시문의 내용을 이어가는 답변에 대한 선호
 그림8. Nested Instruction Bias: 이중 지시문에 대한 답변에 대한 선호
그림8. Nested Instruction Bias: 이중 지시문에 대한 답변에 대한 선호
 그림9. Familiar Knowledge Bias: 익숙한 표현에 대한 선호
그림9. Familiar Knowledge Bias: 익숙한 표현에 대한 선호
EvalBiasBench: 평가 벤치마크 구축
저희는 위에서 찾아낸 선호현상들을 테스트해볼 벤치마크를 구축하게 되었습니다. 평가문항들은 각 Bias 유형별로 예시들을 모으거나, 직접 제작하게 되었습니다. 그 결과 6가지 Bias 유형에 맞는 80개 문항으로 구성된 EvalBiasBench를 만들었습니다.
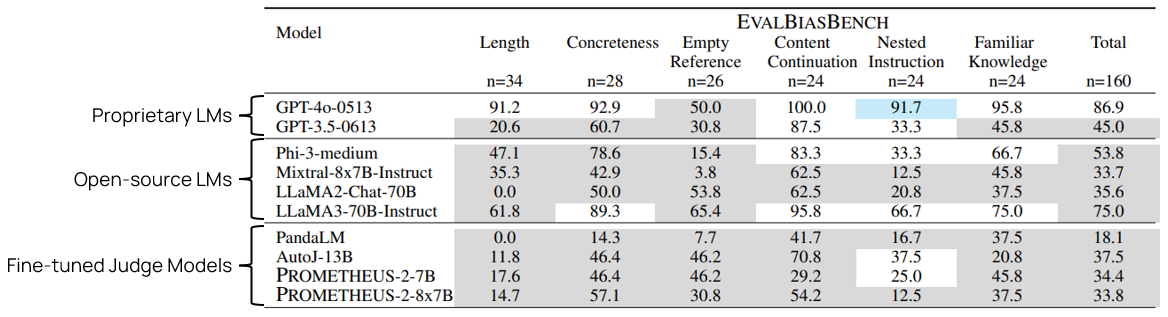 그림10. EvalBiasBench에 대한 평가성능. Proprietary LM과 Open-source LM은 LLM-as-a-Judge 방식으로 평가하였고, Fine-tuned Judge Model들은 각자의 평가방식으로 돌렸다. 대부분의 평가모델들이 Total 50% 스코어를 넘지 못한다.
그림10. EvalBiasBench에 대한 평가성능. Proprietary LM과 Open-source LM은 LLM-as-a-Judge 방식으로 평가하였고, Fine-tuned Judge Model들은 각자의 평가방식으로 돌렸다. 대부분의 평가모델들이 Total 50% 스코어를 넘지 못한다.
각 평가모델의 성능을 EvalBiasBench에 측정해본 결과, GPT-4를 제외한 대부분의 모델이 평가성능에 한계를 보였습니다(그림 10). 특이할 점은 단순한 이지선다 랜덤 모델이 있을 경우, 50%의 스코어를 기대할 수 있지만, 대다수의 평가모델들이 그보다 유의미하게 더 못한다는 것을 확인할 수 있습니다. 이는 오답 텍스트에 포함된 특정 텍스트 패턴에 대해 강한 선호현상이 존재한다는 뜻이기도 합니다.
Bias 에 강건한 평가모델 제작
그렇다면, 이런 평가 Bias문제를 극복하는 좋은 평가모델을 만드려면, 어떻게 해야 할까요? 가장 쉬운 방법은 학습데이터로 해결하는 것입니다. 모델의 Bias가 어디서 왔을 지 생각해본다면, 기존의 학습데이터에서 주어진 정답 텍스트들의 특정 패턴을 암기했기 때문이라고 볼 수 있습니다. 즉, 이런 특정 패턴을 가졌음에도 오답인 케이스를 충분히 학습하게 되면, 평가 Bias가 어느 정도 상쇄될 수 있을 것입니다.
학습데이터 준비
저희는 평가 Bias를 상쇄할 수 있는 학습 데이터를 제작했습니다. 기존의 평가모델들이 선호할 만한 매력적인 오답 응답들을 만들어내는 데 집중했는데, 다음과 같은 2가지 방법이 쓰였습니다.
- 원본 질문과 유사한 질문을 만든 후, 유사한 질문에 대한 고품질 응답을 원본 질문에 대한 오답으로 활용하기
- 특정 오류 유형을 포함하는 오답을 고품질로 생성하기
위 과정을 GPT와 Claude API를 활용하여 자동화하였고, 최종적으로 8천여 건의 (질문, 정답, 오답)으로 이루어진 학습데이터를 만들게 되었습니다. 이를 OffsetBias 데이터라고 이름 붙였습니다.
평가모델을 학습할 때는 기존에 널리 쓰이는 평가데이터 모음(Base-data)에 OffsetBias 데이터를 추가하여 한꺼번에 학습하는 방식으로 모델을 만들게 되었습니다.
학습 결과
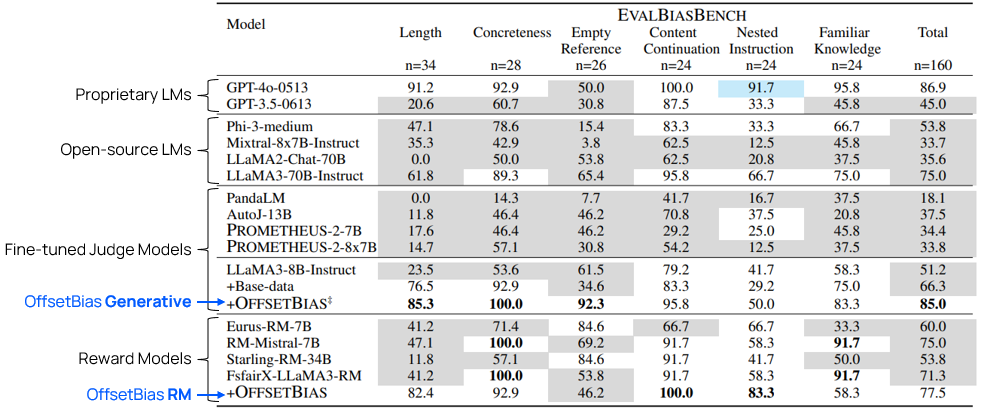 그림11. EvalBiasBench 에 대한 OffsetBias 모델의 평가성능. OffsetBias 데이터를 추가하여 학습한 경우가 가장 성능이 높다.
그림11. EvalBiasBench 에 대한 OffsetBias 모델의 평가성능. OffsetBias 데이터를 추가하여 학습한 경우가 가장 성능이 높다.
Llama-3-8B-Instruct 모델에 Base-data로만 학습한 결과와 OffsetBias 데이터를 추가해 학습한 결과를 비교했을 때, OffsetBias 데이터를 포함하여 학습하는 방법이 가장 성능이 높았습니다. 최종적으로 EvalBiasBench에서 85%까지 성능을 끌어올릴 수 있었습니다. 이는 최고성능 모델이자 거대 유료모델인 GPT-4와 유사한 수준입니다.
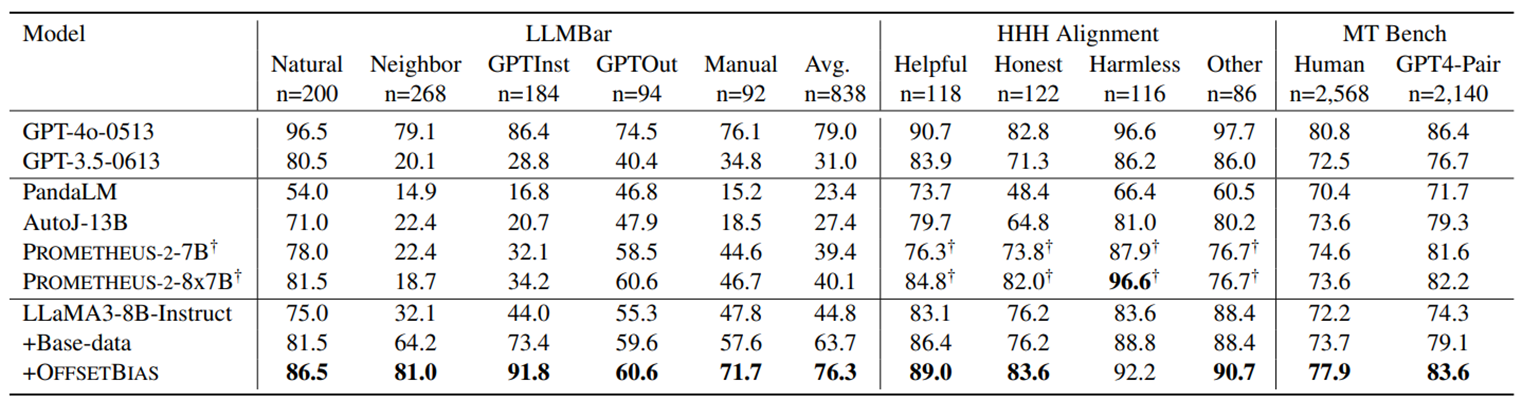 그림12. 기존 평가 벤치마크에 대한 OffsetBias 모델의 평가성능. OffsetBias 데이터를 추가하여 학습하면 성능이 유지되거나 향상된다.
그림12. 기존 평가 벤치마크에 대한 OffsetBias 모델의 평가성능. OffsetBias 데이터를 추가하여 학습하면 성능이 유지되거나 향상된다.
추가적으로, 기존의 평가 벤치마크(LLMBar, HHH Human Alignment, MT Bench 등)에서도 성능이 향상된 것으로 나타났습니다. 즉, 평가 Bias를 겨냥하여 극복하는 방법이 해당 유형의 문제에만 국한되지 않고, 모델의 전반적인 평가 능력을 개선하는 데 효과적이었습니다.
다음으로는 실제로 평가모델의 추론 예시들을 살펴보겠습니다. 한 문제에 대해서, 문제를 낼 때 2 가지 응답의 순서를 한 번씩 바꿔서 보여주고, 두 경우에 다 Good Response에 해당하는 답변을 맞히는 지를 살펴봤습니다. 둘 다 맞추면 2점, 한 경우에만 맞추면 1점입니다.
Empty Reference Bias 타입의 예시입니다. 이 예시에서의 오답은 질문의 내용을 상상하여 멋대로 내용을 지어냈습니다.
| Instruction | Explain the process. |
| Good Response | Of course! Can you specify which process you’re referring to? Once I have the details, I can provide a step-by-step explanation. |
| Bad Response | The water cycle involves evaporation, condensation, and precipitation, where water moves from the earth’s surface to the atmosphere and back again. |
| GPT-4o | 1점 |
| GPT-3.5 | 0점 |
| AutoJ-13B | 2점 |
| Prometheus-2-8x7B | 0점 |
| OffsetBias-8B | 2점 |
Familiar Knowledge Bias 타입의 예시입니다. 이 예시에서 오답은 질문의 표현을 “Break the ice” 라는 널리 쓰이는 표현으로 잘못 해석하였습니다.
| Instruction | What does it mean by “I was too shy. I just kept the ice there.” |
| Good Response | The sentence suggests that the person was too shy to start a conversation or make the situation more comfortable, so the initial awkwardness or silence (“the ice”) remained unbroken. |
| Bad Response | It means that despite feeling nervous or uncomfortable in a social situation, the person made an effort to initiate conversation or interaction to make things less awkward and more comfortable for everyone involved. |
| GPT-4o | 2점 |
| GPT-3.5 | 1점 |
| AutoJ-13B | 1점 |
| Prometheus-2-8x7B | 2점 |
| OffsetBias-8B | 2점 |
이처럼 Bias를 테스트하는 문항들에서 OffsetBias 모델이 다른 모델보다 더 강건한 모습을 보였습니다.
학습데이터의 활용성
평가모델 학습을 위해 만들어진 OffsetBias 데이터는 어느 모델에도 활용이 가능합니다. 현재 RewardBench6에서 고성능을 보이는 Skywork 모델의 경우, 학습데이터 조합에 Offsetbias 데이터를 포함했다고 공개했습니다. 이 모델은 언어모델을 학습할 때 쓰는 RLHF 방법론에서 사용하는 Reward Model인데요. 이렇게 저희가 만든 학습데이터는 평가모델 뿐만 아니라 Reward Model에도 쓰이면서 언어모델의 성능 개선에도 기여할 수 있습니다.
마치며
이 포스팅에서는 모델기반 평가 방법과, 평가모델들이 가질 수 있는 잘못된 선호현상, 그리고 그 선호현상을 상쇄하여 더 강건한 평가모델을 만드는 방법에 대해서 알아보았습니다. 이처럼 모델기반 평가가 더 강건해진다면, 안정적인 텍스트 품질 평가를 진행할 수 있을 뿐만 아니라, 더 나아가 언어모델 학습에도 도움을 줄 수 있을 것이라 생각합니다.
참고문헌
-
Park, Junsoo, Jwa, Seungyeon, et al. “OffsetBias: Leveraging Debiased Data for Tuning Evaluators.” Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. ↩
-
Zheng, Lianmin, et al. “Judging llm-as-a-judge with mt-bench and chatbot arena.” Advances in Neural Information Processing Systems 36 (2023): 46595-46623. ↩
-
Li, Junlong, et al. “Generative judge for evaluating alignment.” arXiv preprint arXiv:2310.05470 (2023). ↩
-
Kim, Seungone, et al. “Prometheus 2: An open source language model specialized in evaluating other language models.” arXiv preprint arXiv:2405.01535 (2024). ↩
-
Zeng, Zhiyuan, et al. “Evaluating large language models at evaluating instruction following.” arXiv preprint arXiv:2310.07641 (2023). ↩
-
Lambert, Nathan, et al. “Rewardbench: Evaluating reward models for language modeling.” arXiv preprint arXiv:2403.13787 (2024). ↩
