


작성자
- 김원규, 이상학, 이종현 (챗봇서비스실)
여러 임베딩 및 검색 기술 연구를 하고 있습니다.이런 분이 읽으면 좋습니다!
- MMIR (Multimodal Information Retrieval, 멀티모달 정보 검색)의 트렌드를 알고 싶으신 분
이 글로 알 수 있는 내용
- MMIR에 대한 태스크 설명, 관련 데이터
- MMIR의 최신 기술들
시작하며
정보 검색은 수 많은 문서들이 들어있는 데이터베이스에서 유저 질의에 가장 적합한 문서를 선택해주는 역할을 하며, Retrieval Augmented Generation, Open-Domain Question Answering 등 LLM (Large Language Model)과 함께 어우러져 많은 분야의 태스크들을 수행하기 위해 필요한 핵심 기술입니다.
기존의 정보 검색 방식은 주로 텍스트 기반으로 다양한 연구와 발전이 이루어졌습니다. 그러나 최근 사용자들의 요구가 점점 더 다양해짐에 따라, 텍스트 뿐만 아니라 이미지, 음성, 비디오 등 다양한 형태의 모달리티를 결합하여 질의하고자 하는 경향이 뚜렷해지고 있습니다. 예를 들어, “주어진 이미지의 연설자를 아시아인으로 바꾼 새로운 이미지를 검색해 줘.”와 같은 텍스트 명령어와 함께 아시아인 연설자가 포함된 이미지를 질의하여 사용자가 원하는 방식으로 수정된 이미지를 검색하는 등, 보다 정교하고 복합적인 정보 검색 기능에 대한 기대가 커지고 있습니다.
또한, 생성 분야에서는 다양한 모달리티의 입출력이 가능한 MLLM (Multimodal Large Language Model)이 빠른 속도로 연구되고 있으며, GPT-4o 1는 높은 수준의 결과를 보여주고 있습니다. 이러한 흐름에 발맞추어, 여러 모달리티를 다루는 MMIR (MultiModal Information Retrieval) 연구의 필요성이 더욱 강조되고 있습니다.
이 글에서는 챗봇서비스실에서 연구하고 있는 MMIR의 기술 트렌드에 대해 소개 드리려고 합니다. MLLM과 마찬가지로 MMIR은 텍스트, 이미지, 음성, 비디오 등의 다양한 모달리티 입출력이 가능하지만 텍스트와 이미지 간의 검색에 집중한 기술들을 공유 드리겠습니다.
MMIR Task Description
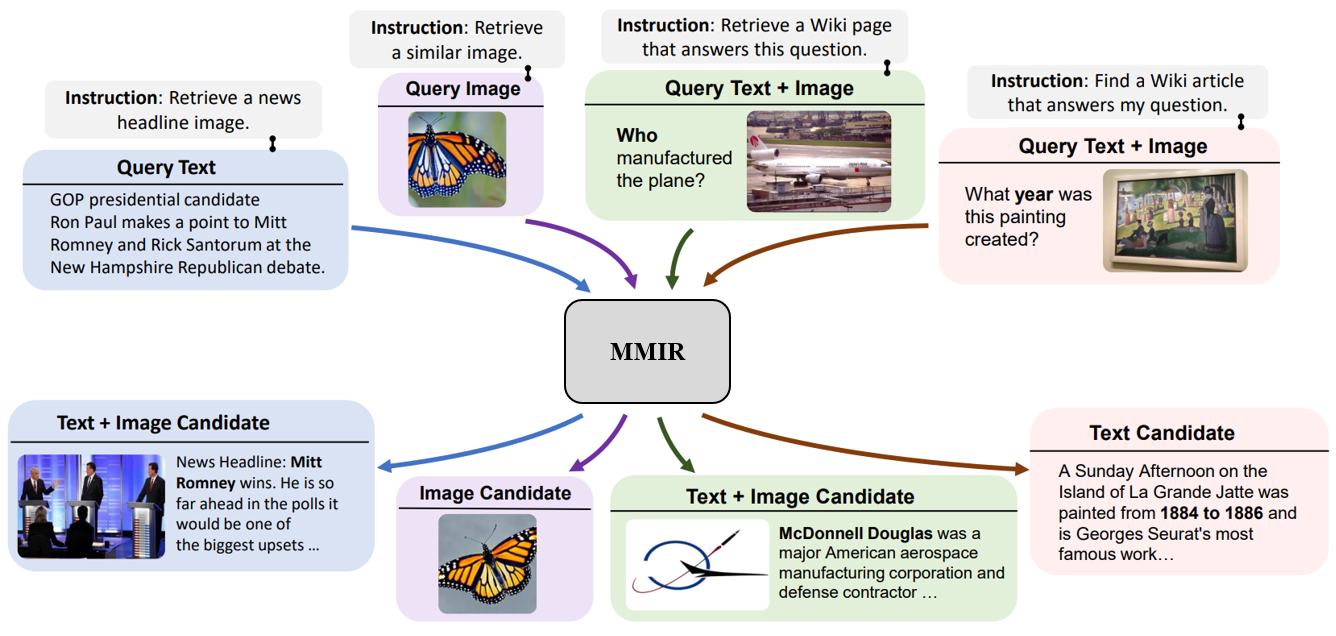 그림 1. MMIR 태스크. 질의와 후보 문서에는 텍스트, 이미지, 그리고 텍스트와 이미지가 혼합된 형태로 들어갈 수 있다. 태스크 구별을 위해 질의 부분에 Instruction을 넣어주는 것은 필수적으로 적용되고 있다.
그림 1. MMIR 태스크. 질의와 후보 문서에는 텍스트, 이미지, 그리고 텍스트와 이미지가 혼합된 형태로 들어갈 수 있다. 태스크 구별을 위해 질의 부분에 Instruction을 넣어주는 것은 필수적으로 적용되고 있다.
기존 텍스트 기반 정보 검색은 텍스트로 구성된 질의에 적합한 텍스트 후보 문서를 후보 문서 풀에서 찾는 걸 목표로 합니다. 하지만 MMIR에서는 질의와 후보 문서에 텍스트 대신 이미지를 넣거나 이미지와 텍스트를 혼합하여 사용할 수도 있습니다. 따라서 “텍스트 질의 → 텍스트 후보 문서”와 더불어 “텍스트 질의 → 이미지 후보 문서”, “이미지 질의 → 텍스트 후보 문서”, “이미지와 텍스트가 혼합된 질의 → 이미지/텍스트 후보 문서” 등 수행해야 할 태스크들이 증가하게 됩니다.
그림 1은 MMIR에서 발생할 수 있는 태스크들을 보여줍니다 2. 그림 1의 가장 오른쪽 예시에서 어떤 한 그림 이미지가 “What year was this painting created?”라는 질문 텍스트와 함께 MMIR에 질의 돼 해당 그림이 1884년부터 1886년 사이에 만들어졌다는 정보를 담은 텍스트 후보 문서를 검색하는 걸 볼 수 있습니다. 추가적으로 “Find a Wiki article that answers my question.“이라는 Instruction을 질의 앞에 붙여 함께 넣어주는데요. 검색 모델이 다양한 태스크들을 올바르게 구별하며 수행하기 위해 질의 부분에 각 태스크에 상응하는 Instruction을 함께 넣어주는 것은 통상적입니다. 하지만 이러한 데이터셋과 벤치마크를 구성하는 것은 쉽지 않은 작업입니다. 다음 섹션에서는 MMIR의 여러 태스크 수행을 위해 구축된 M-BEIR 2라는 데이터셋 및 벤치마크에 대해 설명합니다.
MMIR Dataset & Benchmark - M-BEIR
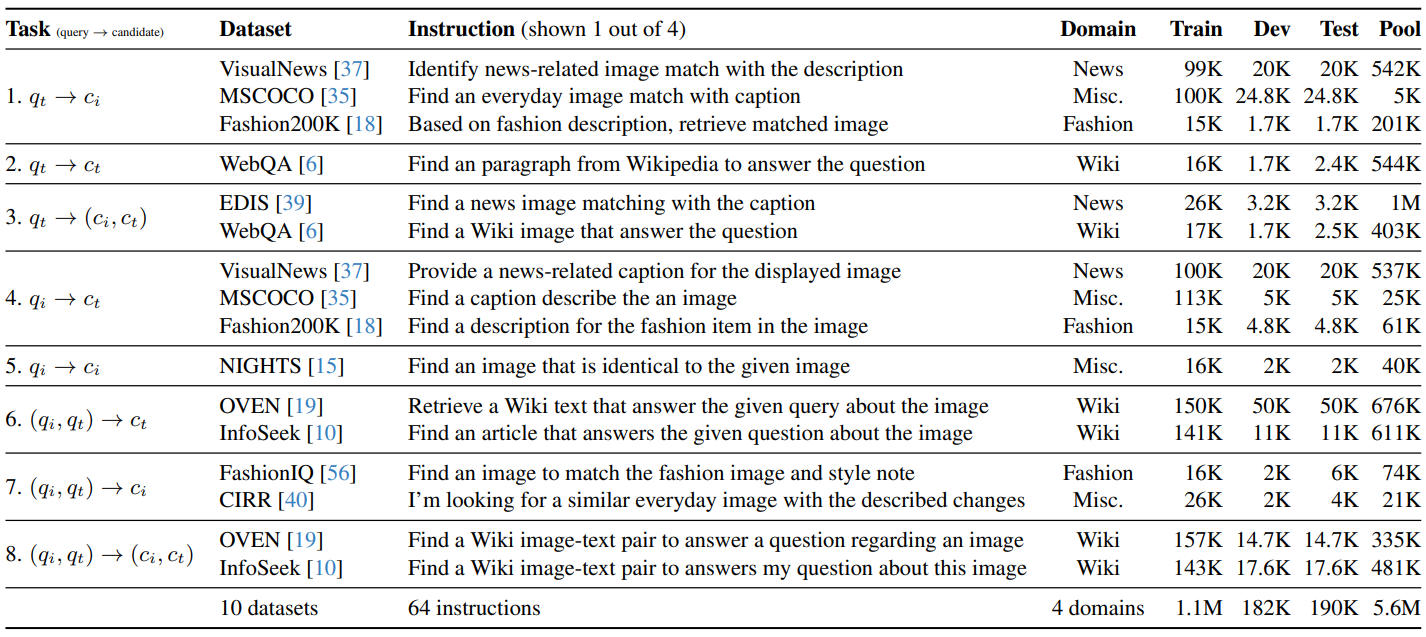 표 1. M-BEIR 개요. M-BEIR는 8가지의 다양한 태스크들을 수행하기 위한 10개의 데이터셋을 포함한다. 태스크 열에서 표기되는 \(q, c\)는 각각 질의와 후보 문서를 의미하며 \(t, i\)는 각각 텍스트와 이미지를 나타낸다. 데이터셋의 도메인은 다양하며 이미 구축된 데이터셋들을 큐레이션한 것이기 때문에 크기도 적절하다. 또한 태스크 구별 능력을 위해 각 태스크 마다 Insturction이 존재한다.
표 1. M-BEIR 개요. M-BEIR는 8가지의 다양한 태스크들을 수행하기 위한 10개의 데이터셋을 포함한다. 태스크 열에서 표기되는 \(q, c\)는 각각 질의와 후보 문서를 의미하며 \(t, i\)는 각각 텍스트와 이미지를 나타낸다. 데이터셋의 도메인은 다양하며 이미 구축된 데이터셋들을 큐레이션한 것이기 때문에 크기도 적절하다. 또한 태스크 구별 능력을 위해 각 태스크 마다 Insturction이 존재한다.
M-BEIR는 ECCV 2024에서 소개 되었으며 표 1은 M-BEIR의 개요를 보여줍니다. M-BEIR는 8가지의 태스크들을 커버하는 10개의 데이터셋을 포함하고 있습니다. 가장 왼쪽에 있는 태스크 열에서 \(q, c\)는 각각 질의와 후보 문서를 의미하고 \(t, i\)는 각각 텍스트와 이미지를 나타냅니다. 기존에 널리 쓰이던 텍스트 기반 검색 벤치마크 BEIR 3 처럼 다양한 도메인에 존재하는 데이터셋들을 큐레이션하여 M-BEIR가 구축되었습니다. 또한 앞서 언급한 것처럼 태스크들을 구별하기 위해 태스크 마다 Instruction을 다르게 작성한 것을 볼 수 있습니다.
그림 2는 M-BEIR에 존재하는 샘플들의 예시를 보여줍니다. 우측 중간의 샘플을 보면 갈색 곱슬 털의 강아지 이미지를 밥그릇과 함께 있는 하얀색 곱슬 털의 강아지로 변경을 요청하는 질의에 있어 적절한 이미지의 후보 문서가 연결되어 있는 것을 확인할 수 있고 다른 샘플들도 역시 올바른 것을 볼 수 있습니다. 이처럼 다양한 태스크와 여러 가지 도메인, 그리고 Instruction이 포함된 M-BEIR를 통해 보다 품질이 뛰어난 검색 모델들을 만들 수 있게 됩니다.
 그림 2. M-BEIR 샘플. 후보 문서가 질의에 적합한 것을 확인할 수 있으며 M-BEIR의 견고함을 보여준다.
그림 2. M-BEIR 샘플. 후보 문서가 질의에 적합한 것을 확인할 수 있으며 M-BEIR의 견고함을 보여준다.
MMIR Methods
본 섹션에서는 MMIR을 위한 최신 기술들의 대표적인 유형들을 설명합니다. 기존 텍스트 기반 검색 모델들과 동일하게 MMIR 모델들도 질의어와 후보 문서를 독립적으로 인코딩하는 Bi-Encoder 방식을 따르고 있습니다. 하지만 유형 별로 다른 인코딩 벡터를 취하게 되는데, 대표적으로 Dense, Sparse, MLLM 기반 모델들이 있습니다. 이어지는 섹션들에서는 Dense 모델인 UniIR 2, VISTA 4와 Sparse 모델인 STAIR 5, MLLM 기반 모델인 E5-V 6에 대해서 설명합니다. 그리고 마지막으로 Case Study에서 M-BEIR 샘플들에 대해 모델들의 결과를 비교합니다.
UniIR
처음으로 소개드릴 방법은 ECCV 2024에서 발표된 UniIR 2입니다. UniIR에서 “Uni-“는 Universal을 나타내며 다양한 검색 태스크들을 하나의 모델이 수행하는 구조를 설계하는 것이 목표였습니다. 따라서 M-BEIR 같은 데이터에 쉽게 적용될 수 있었으며 MMIR에서 기반이 되는 연구로 자리 잡고 있습니다.
그렇다면 UniIR은 어떤 방식으로 검색을 진행하게 될까요? 검색 모델은 대개 질의와 후보 문서를 각각 하나의 벡터로 나타낸 다음 두 벡터들 사이의 유사도를 계산하여 검색을 진행합니다. UniIR도 이 큰 틀을 벗어나지 않습니다. 그림 3은 UniIR의 검색 방식을 나타내며 구조는 간단합니다. 그림 3의 왼쪽 부분은 질의를 벡터로 표현하는 방법인데, 이미지 인코더는 이미지를 입력 받아 하나의 벡터로 표현하고 텍스트 인코더는 텍스트를 입력 받아 하나의 벡터로 표현한 뒤 Weighted Sum을 통해 두 벡터를 하나로 합치게 됩니다. 만약 질의에 하나의 모달리티만 있다면 합치는 작업은 생략됩니다. 그림 3의 오른쪽 부분에서 후보 문서에 대한 벡터 표현도 똑같은 과정을 거치게 됩니다. 이후 질의와 후보 문서 벡터들 간의 Dot Product를 이용하여 유사도를 계산해 해당 후보 문서가 질의에 얼마나 관련 있는지 알 수 있게 됩니다. 텍스트와 이미지 인코더는 CLIP 7 또는 BLIP 8을 사용할 수 있습니다. 두 모델은 사전 학습된 멀티모달 인코더로 NLP에서의 BERT 9와 비슷한 역할을 수행합니다.
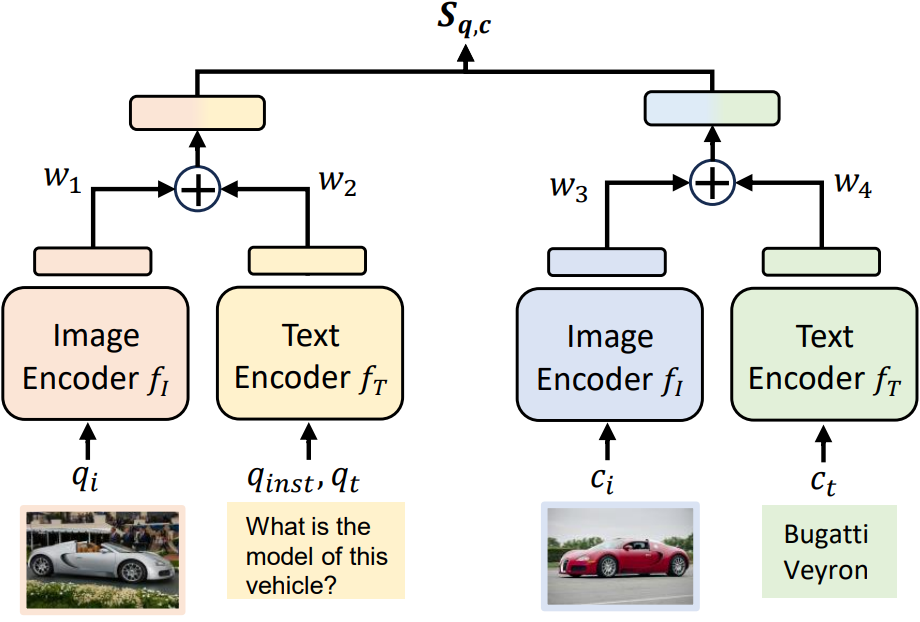 그림 3. UniIR의 검색 방식. 왼쪽은 질의 인코딩, 오른쪽은 후보 문서 인코딩 과정이다. 이미지와 텍스트의 벡터 결합 방법은 Weighted Sum을 사용하며 유사도 계산은 Dot Product를 통해 진행된다.
그림 3. UniIR의 검색 방식. 왼쪽은 질의 인코딩, 오른쪽은 후보 문서 인코딩 과정이다. 이미지와 텍스트의 벡터 결합 방법은 Weighted Sum을 사용하며 유사도 계산은 Dot Product를 통해 진행된다.
UniIR의 학습은 여느 검색 모델에서 사용하는 Contrastive Loss 10를 통해 진행됩니다 (수식 1). 해당 기법을 통해 질의의 벡터가 Positive의 후보 문서 벡터와는 거리가 가깝도록, 그리고 Negative의 후보 문서 벡터와는 거리가 멀어지도록 모델에게 가르칠 수 있습니다. Negative 후보 문서를 따로 구축하기 어렵기 때문에 미니배치 안의 다른 Positive 후보 문서들을 Negative로 여기는 In-Batch Negative 방법을 사용합니다. 이런 학습을 통해 실제 추론 환경에서 관련 있는 후보 문서에 더욱 높은 유사도를 부여할 수 있게 됩니다.
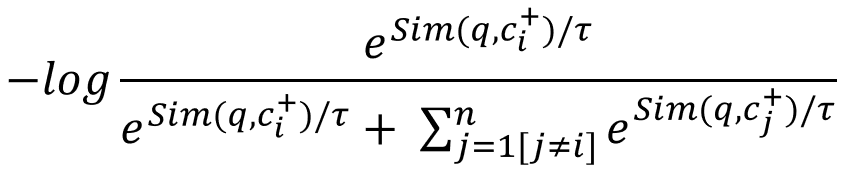 수식 1. In-Batch Negative 기반 Contrastive Loss. 해당 기법을 통해 모델은 Positive 후보 문서와는 가깝고 Negative 후보 문서와는 멀어지는 벡터 표현 능력을 배우게 된다. \(n, i, j\)는 각각 배치 사이즈, 미니 배치 안에서 현재 샘플의 인덱스, 다른 샘플들의 인덱스를 나타낸다. +는 해당 후보 문서가 Positive임을 나타내고 \(Sim(·), τ\)는 각각 유사도 함수와 Temperature를 의미한다.
수식 1. In-Batch Negative 기반 Contrastive Loss. 해당 기법을 통해 모델은 Positive 후보 문서와는 가깝고 Negative 후보 문서와는 멀어지는 벡터 표현 능력을 배우게 된다. \(n, i, j\)는 각각 배치 사이즈, 미니 배치 안에서 현재 샘플의 인덱스, 다른 샘플들의 인덱스를 나타낸다. +는 해당 후보 문서가 Positive임을 나타내고 \(Sim(·), τ\)는 각각 유사도 함수와 Temperature를 의미한다.
VISTA
ACL 2024에서 발표된 VISTA 4는 UniIR 처럼 다양한 검색 태스크들을 처리하는 범용적 모델로써 수행하도록 만들어졌습니다. 검색 과정이 UniIR과 대부분 비슷하여 M-BEIR에 쉽게 적용할 수 있지만 모델 구조적인 부분에서 차이를 두어 보다 나은 벡터 표현을 얻고자 했습니다. 그림 4는 VISTA의 모델 구조로 두 가지의 장점을 가지고 있습니다.
- In-Depth Fusion
- 텍스트 인코더 능력 보존
In-Depth Fusion. UniIR 같은 경우 간단한 Weighted Sum을 통해 이미지 벡터와 텍스트 벡터를 결합하지만 VISTA는 이미지 인코더의 각 포지션에서 나온 여러 벡터들을 텍스트 인코더에 전달하게 됩니다. 그 후 해당 벡터들은 텍스트 인코더 내부에서 텍스트 임베딩들과의 더 깊은 상호작용을 할 수 있고 결과적으로 더욱 유의미한 최종 질의 또는 후보 문서 벡터를 추출할 수 있습니다. 이러한 구조는 많은 MLLM들에서 비슷하게 사용되고 있는데 그만큼 입증된 구조라고 생각할 수 있습니다.
텍스트 인코더 능력 보존. 저자들은 CLIP 기반 멀티모달 검색 모델의 경우 이미지에 비해 텍스트 벡터 표현 능력이 떨어지는 것을 발견 했습니다. 이에 따라 저자들은 CLIP의 텍스트 인코더 대신에 기존 텍스트 기반 검색 모델의 인코더를 가져와 적용하면 해결될 것이라고 생각했습니다. 결과적으로 해당 방법은 성능 향상에 기여를 했으며 그림 4를 보시면 텍스트 인코더 능력을 지속적으로 보존하기 위해 학습 시 해당 파라미터들을 얼리는 것을 확인할 수 있습니다.
VISTA는 UniIR 처럼 수식 1을 활용하여 In-Batch Negative 기반으로 학습을 진행합니다. BERT 9 계열의 텍스트 인코더를 사용하기 때문에 [CLS] 토큰에서 나온 벡터를 최종 표현으로 사용하게 됩니다.
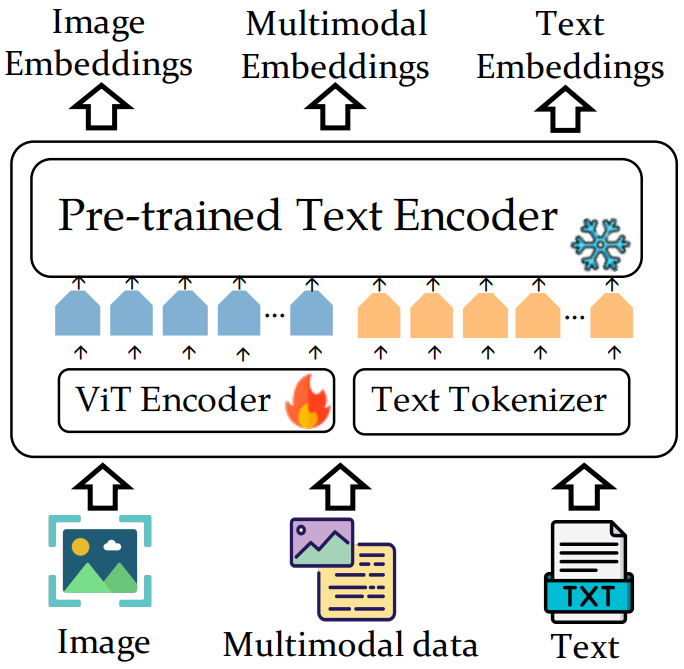 그림 4. VISTA 모델 구조. 이미지 인코더에서 나온 벡터들이 텍스트 인코더로 전달되어 내부에서 텍스트 임베딩들과 보다 깊은 상호작용을 할 수 있다. 텍스트 인코더 능력 보존을 위해 해당 파라미터를 얼리게 된다.
그림 4. VISTA 모델 구조. 이미지 인코더에서 나온 벡터들이 텍스트 인코더로 전달되어 내부에서 텍스트 임베딩들과 보다 깊은 상호작용을 할 수 있다. 텍스트 인코더 능력 보존을 위해 해당 파라미터를 얼리게 된다.
STAIR
위에서 설명한 UniIR, VISTA는 질의와 후보 문서를 Dense 벡터로 표현합니다. Dense 벡터는 차원이 낮아 사람이 해석할 수 없고, 입력 텍스트의 Lexical 정보를 잘 반영하지 못하는 모습을 보입니다. 이를 해결하기 위해서 질의와 후보 문서를 Vocabulary 크기의 큰 차원을 가진 Sparse 벡터로 만드는 Learned Sparse Retrieval 방법론들이 등장했습니다.
EMNLP 2023에서 발표된 STAIR 5는 Learned Sparse Retrieval 방법론 중 하나이며, 지난 검색 패러다임의 변천사 글에서 설명드린 SPLADE 모델의 멀티모달 버전이라고 볼 수 있습니다. 표 2 처럼, STAIR는 질의나 후보 문서를 Sparse 벡터로 만들게 되는데, 각 차원이 토큰 하나하나에 해당하게 되어 사람이 해석하기 쉽고, Lexical 정보를 잘 반영하게 됩니다. 높은 점수를 가진 “candles“, “girl“, “child“ 등은 해당 이미지를 나타내기에 적절한 토큰인 것을 확인할 수 있습니다.
| 이미지 | Spare 벡터 |
 |
candles:1.6386 girl:1.5023 .:1.4988 child:1.4075 food:1.3474 woman:1.2649 candle:1.2561 eating:1.2169 sweet:1.1732 birthday:1.1044 |
표 2. STAIR 모델로 이미지를 인코딩한 결과. Sparse 벡터의 각 차원에 해당하는 토큰을 점수를 기준으로 내림차순 했다. 사람이 해석하기에, Lexical 정보를 반영하기에, 쉽고 적합하다.
그림 5처럼, STAIR는 Sparse 벡터와 관련된 부분 외에 UniIR과 모델 구조 상 큰 차이는 없습니다. 텍스트 인코더로 BERT를, 이미지 인코더로 CLIP을 사용합니다. 특이한 점은 Token Prediction Head를 사용한다는 것입니다. 그림 5의 왼쪽에 나타나있듯, Token Prediction Head는 BERT LM Head (그림의 Dense Layer + GeLU + LayerNorm + Projection Layer)와 Log Saturation (그림의 ReLU Max_Pooling)으로 구성됩니다. 이 Token Prediction Head를 통해 질의나 후보 문서를 Vocabulary의 각 토큰 정보를 담은 Sparse 벡터로 만들게 되며, 텍스트 인코더와 이미지 인코더 모두에 적용됩니다.
STAIR는 원래 \(q_t → c_i, q_i → c_t\) 만을 위해 만들어진 모델이라서, 다양한 모달리티가 공존하는 M-BEIR 환경에 사용하기 위해 UniIR 처럼 별도의 이미지와 텍스트 벡터의 결합을 해주어야 합니다. 이에 맞추어 질의 또는 후보 문서 자체가 멀티모달인 경우, 이미지와 텍스트 Sparse 벡터들 간의 Element-wise Max Fusion 기반 결합을 통해 질의 또는 후보 문서의 최종 벡터를 계산하도록 했습니다. 이렇게 함으로써 STAIR도 이미지와 텍스트가 혼합된 형태의 질의와 후보 문서를 처리할 수 있게 됩니다.
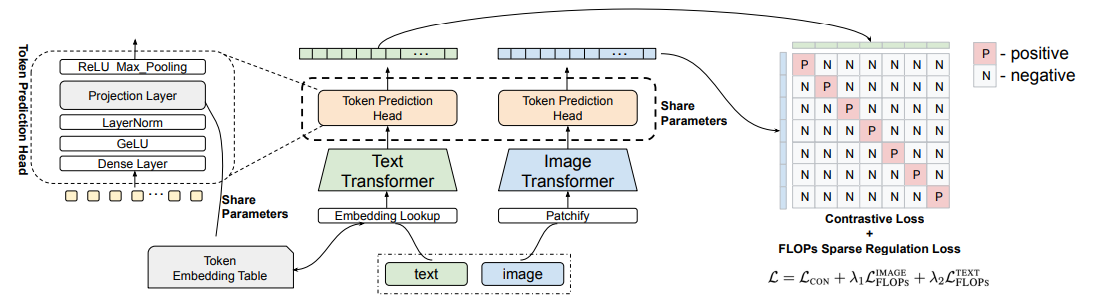 그림 5. STAIR 모델 구조. 그림 왼쪽과 같이 구성된 Token Prediction Head를 통해 질의, 후보 문서의 이미지와 텍스트를 각 토큰에 대한 점수를 담은 Vocabulary 크기의 Sparse 벡터로 인코딩한다. 그림 오른쪽과 같이 Contrastive loss와 Sparse Regularization Loss (FLOPs)를 통해 학습하고, Sparse 벡터 간 유사도를 계산해 검색한다.
그림 5. STAIR 모델 구조. 그림 왼쪽과 같이 구성된 Token Prediction Head를 통해 질의, 후보 문서의 이미지와 텍스트를 각 토큰에 대한 점수를 담은 Vocabulary 크기의 Sparse 벡터로 인코딩한다. 그림 오른쪽과 같이 Contrastive loss와 Sparse Regularization Loss (FLOPs)를 통해 학습하고, Sparse 벡터 간 유사도를 계산해 검색한다.
그림 5의 오른쪽과 같이, STAIR의 학습은 UniIR과 마찬가지로 Contrastive Loss로 학습합니다. 대신, 결과 벡터를 Sparse하게 유지하기 위해서 Sparse Regularization Loss (FLOPs)도 함께 적용합니다.
텍스트 인코더는 BERT로 되어 있어서 BERT LM Head와 함께 사용해도 문제가 없지만, 이미지 인코더의 CLIP은 Sparse 벡터의 각 차원이 어떤 단어에 해당하는지 모르기 때문에 별도의 학습 과정이 필요합니다. 이를 위해서 STAIR는 특이한 학습 방식을 가지고 있습니다. 다음의 세 가지 스테이지를 통해 이미지 인코더, 텍스트 인코더, 모델 전체 순서로 학습을 진행합니다.
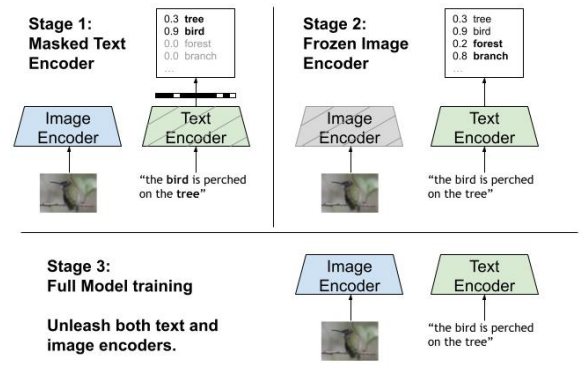 그림 6. STAIR 모델의 학습을 위한 세 가지 스테이지. 스테이지 1에서는 텍스트 인코더의 Sparse 벡터를 마스킹하고 이미지 인코더 위주로 학습한다. 스테이지 2에서는 이미지 인코더를 얼리고 텍스트 인코더만 학습한다. 스테이지 3에서는 어떠한 파라미터도 얼리지 않고 이미지와 텍스트 인코더를 동시에 학습한다.
내용일 잘못됨
그림 6. STAIR 모델의 학습을 위한 세 가지 스테이지. 스테이지 1에서는 텍스트 인코더의 Sparse 벡터를 마스킹하고 이미지 인코더 위주로 학습한다. 스테이지 2에서는 이미지 인코더를 얼리고 텍스트 인코더만 학습한다. 스테이지 3에서는 어떠한 파라미터도 얼리지 않고 이미지와 텍스트 인코더를 동시에 학습한다.
내용일 잘못됨
스테이지 1: 처음에 이미지 인코더는 이미지를 적절한 Sparse 벡터로 표현할 줄 모르는 상태입니다. 따라서 이미지 인코더가 이미지를 나타내기 위한 적절한 토큰들이 무엇인지 알도록 학습시키게 됩니다. 그림 6의 왼쪽 위처럼, 텍스트 인코딩에서 텍스트에 실제로 있는 토큰들만 보이도록 마스킹 합니다. 수식 1과 같이 이미지 벡터와 마스킹된 텍스트 벡터 사이의 Contrastive Learning을 진행합니다.
스테이지 2: 학습된 이미지 인코더를 통해 텍스트 인코더가 텍스트를 기존보다 더욱 적절한 Sparse 벡터로 표현하도록 가르치는 스테이지 입니다. 그림 6의 오른쪽 위처럼, 이미지 인코더의 파라미터를 얼리고, 수식 1의 Contrastive Learning을 해서 텍스트 인코더만 학습합니다.
스테이지 3: 앞의 두 스테이지를 통해 적절한 Sparse 벡터 표현을 할 수 있게 된 뒤 마지막으로 모델이 텍스트와 이미지 간의 검색에 적응하는 스테이지를 진행합니다. 마스킹이나 파라미터를 얼리는 것 없이 역시 수식 1을 이용해 모델 전체를 Contrastive Learning 합니다.
논문의 실험 결과를 보면, 세 가지 스테이지는 모두 텍스트와 이미지 간의 검색 성능을 올립니다. 한 스테이지라도 빠질 경우 성능 하락이 발생하기에, 각 스테이지가 필수적이고 잘 구성된 학습 방식이라고 볼 수 있습니다.
E5-V
앞서 소개한 기술들은 멀티모달 질의와 후보 문서를 이해하기 위해, 텍스트 인코더와 이미지 인코더가 분리된 형태의 구조를 (e.g. CLIP, BLIP) 사용했습니다. 그러나 이들은 텍스트와 이미지 각각을 위해 별도의 인코더를 사용해야 하기 때문에 이미지와 텍스트가 혼합된 입력을 효과적으로 표현하는데 어려움을 겪고 있습니다 6. 게다가, CLIP은 LLM에 비해 짧고 적은 수의 텍스트로 학습 되었기 때문에 복잡한 텍스트를 이해하는 능력이 부족하며 긴 텍스트를 처리하는데 한계가 있습니다.
네 번째로 소개할 E5-V6는 앞서 소개한 모델들과 다르게 사전 학습된 MLLM을 인코더로 사용합니다. MLLM은 이미지 인코더와, 텍스트 인코더인 LLM이 하나로 결합된 구조를 가지고 있기 때문에, 이미지와 텍스트가 혼합된 입력을 효과적으로 표현할 수 있을 것이라 기대할 수 있습니다. 또한, LLM은 CLIP과 같은 모델보다 길고 많은 수의 텍스트로 학습되었기 때문에 복잡하고 긴 텍스트를 보다 잘 이해할 수 있습니다.
그러나, MLLM은 입력을 임베딩 벡터로 표현하기 위해 Contrastive 방식이 아닌 Generative 방식으로 학습하기 때문에 다음과 같이 프롬프트 기반 방법으로 멀티모달 입력을 임베딩 벡터로 표현하는 방법을 제안합니다.
Unifying Multimodal Embeddings
그림 7의 왼쪽과 같이 기존 MLLM을 이용해 얻어낸 벡터들을 시각화 해 보면, 서로 다른 모달리티 벡터들 간에 간극이 발생하는 것을 알 수 있습니다. 이를 모달리티 간극(Modality gap)이라고 합니다. 이러한 모달리티 간극을 제거하기 위해 아래와 같은 프롬프트 기반의 표현 방법을 사용합니다.
- 텍스트 벡터 표현 프롬프트 예시: <text>\nSummary of the above sentence in one word:
- 이미지 벡터 표현 프롬프트 예시: <image>\nSummary above image in one word:
- *이미지와 텍스트가 혼합된 벡터 표현 프롬프트 예시: <image>\n
\nDescribe the above image and text in one word:*
그림 7의 오른쪽과 같이 위와 같은 프롬프트를 통해 MLLM이 멀티모달 입력을 한 단어로 표현하도록 명시적으로 지시하면 텍스트와 이미지 사이의 모달리티 간극을 제거할 수 있다고 합니다.
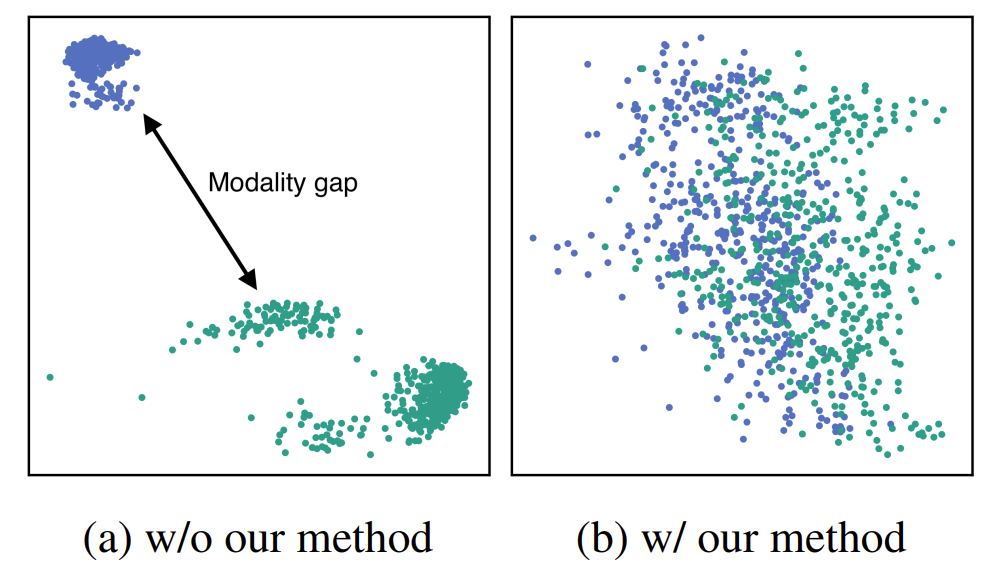 그림 7. 프롬프트 사용 유무에 따른 MLLM의 이미지 벡터와 텍스트 벡터의 분포 비교. 프롬프트 기반 방법을 이용하였을 때 모달리티 간극이 제거되었음을 알 수 있다.
그림 7. 프롬프트 사용 유무에 따른 MLLM의 이미지 벡터와 텍스트 벡터의 분포 비교. 프롬프트 기반 방법을 이용하였을 때 모달리티 간극이 제거되었음을 알 수 있다.
Single Modality Training
LLM이나 MLLM을 이용해 벡터를 만들기 위해 대개 마지막 토큰 자리로부터 얻게 됩니다. 왜냐하면 LLM이나 MLLM은 Generative 방식을 통해 다음 단어를 예측하도록 학습하기 때문입니다. 따라서 해당 벡터들은 문맥 내 단어 간 관계나 확률 분포를 나타내는 데 최적화되어 있지만 검색은 주어진 두 벡터의 의미적 유사도를 비교하는 것이 목표입니다. 그러므로 MLLM으로부터 얻어낸 벡터가 멀티모달 입력의 의미를 함축하도록 만드는 학습이 필요합니다.
앞서 프롬프트를 통해 모달리티 간극이 제거되었기 때문에 멀티모달이 아닌 텍스트 페어로만 학습해도 벡터 표현 능력이 전이 되어 모델이 멀티모달 벡터 표현 능력을 갖출 수 있다고 합니다 (그림 8). 또한, 이 경우에 학습 과정에서 이미지 데이터가 필요하지 않으므로 상당한 인적 및 물적 이점이 있다고 볼 수 있습니다.
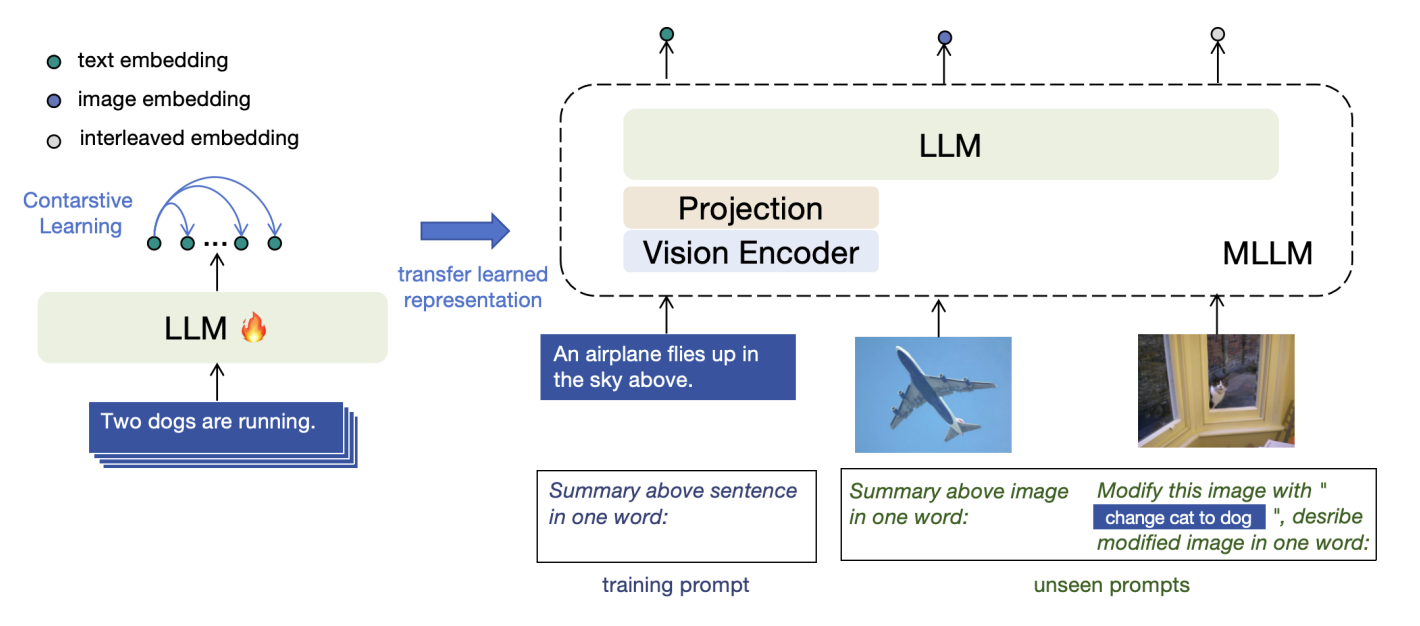 그림 8. E5-V의 단일 모달리티 학습 및 추론 과정. 학습은 Contrastive Leaning 방식으로 LLM에 대해서만 진행한다. 모델 추론 시에는 이미지 인코더와 Projection Layer를 결합하여 진행한다.
그림 8. E5-V의 단일 모달리티 학습 및 추론 과정. 학습은 Contrastive Leaning 방식으로 LLM에 대해서만 진행한다. 모델 추론 시에는 이미지 인코더와 Projection Layer를 결합하여 진행한다.
따라서 학습을 위해 오직 NLI 데이터셋 11만을 사용합니다. NLI 데이터 셋은 텍스트 만으로 구성되어 있기 때문에 그림 8의 왼쪽과 같이 MLLM에서 이미지 인코더와 Pojection Layer를 제거하고 수식 1을 활용해 LLM만 Contrastive learning 방식으로 학습합니다. 다만 11의 NLI 데이터셋에는 Hard Negative가 이미 구축되어 있기 때문에 이를 추가적으로 사용합니다. E5-V의 백본 MLLM으로 LLaVA-NeXT-8B12을 사용합니다.
M-BEIR 와 같은 Universal 환경에서 멀티모달 검색을 수행한다면 어떻게 해야 할까요? 6에서 제안한 프롬프트에는 표 1에 표기된 태스크들에 대한 Instruction이 포함되어 있지 않기 때문에 Instruction을 포함하도록 프롬프트를 수정해야 합니다. 저희는 M-BEIR의 Instruction과 E5-V의 프롬프트를 결합하여 아래 예시와 같은 새로운 프롬프트를 제작하여 E5-V 모델 학습 및 평가에 사용하였습니다.
- \(q_t → c_i\) 프롬프트 예시: <text>\nSummary the above caption in one word to help find a matching image:
- \(q_i → c_t\) 프롬프트 예시: <image>\nDescribe the above image in one word to help find a matching caption:
- \((q_i, q_t) → c_i\) 프롬프트 예시: <image>\n<text>\nDescribe the above image and query in one word to help find matching Wikipedia passages that provide answer:
Case Study
이번 섹션에서는 여러 예시들을 통해 각 모델의 결과를 분석합니다. 표 3은 모델들의 검색 결과를 보여줍니다.
첫 번째 예시에서 “작은 자전거를 타며 흙 길을 지나가는 빨간 모자를 쓴 남자”의 이미지를 질의하고 있습니다. UniIR, VISTA, E5-V는 Top-1으로 정답을 선택했지만 STAIR가 검색한 이미지를 확인하면 자전거를 오토바이로 대체하고 있으며 흙 길과 빨간 모자는 확인되지 않습니다. STAIR는 어느 정도 비슷하지만 세부적인 맥락을 담지 못한 이미지를 고르고 있는데 이러한 경향은 Learned Sparse Retrieval 중 하나인 텍스트 검색 모델 SPLADE 13에서도 확인이 되었으며 Sparse 벡터의 일관적인 단점을 보여주고 있습니다.
추가적으로 UniIR, VISTA, E5-V의 결과에서 이미지가 아닌 질의와 완전히 같은 텍스트를 검색하기도 합니다. “Instruction 사용”, “프롬프트를 통한 모달리티 간극 완화” 등을 적용 했음에도 아직 완전히 태스크를 구별하지 못하고 있으며 모달리티 간극 해소를 위한 방법들이 더 필요해 보입니다.
세 번째 예시의 경우, 어떤 한 드레스가 있는 이미지에서 해당 드레스를 “얇은 끈을 갖고 다른 패턴을 포함하며 가을 느낌의 좀 더 긴 드레스“로 바꾼 새로운 이미지를 검색하길 원합니다. 이전과 비슷하게 UniIR, VISTA, STAIR는 Top-1으로 질의와 완전히 같은 이미지를 검색합니다. 해당 질의를 모델들이 소화하지 못하고 있으며 검색을 할 때 질의와 완전히 똑같을 경우 선택을 하지 않는 능력이 필요해 보입니다. Top-2나 Top-3에도 다른 패턴을 가진 가을 느낌의 드레스 이미지보다는 비슷한 패턴을 가진 어두운 느낌의 드레스 이미지가 있는 것을 보아 해당 모델들의 능력이 아직 부족하다는 것을 알 수 있습니다. 또한 해당 오답 이미지의 사람이 질의 이미지에 있는 사람과 똑같은 것을 확인할 수 있는데, 이 역시 질의와 유사한 후보 문서가 있으면 점수를 높게 주려는 것으로 예상됩니다. 반면 E5-V가 검색한 결과들은 끈을 갖고 다른 패턴을 포함하며 가을 느낌도 가지고 있습니다. E5-V가 MLLM을 인코더로 사용함으로써 이미지와 텍스트가 혼합된 질의에 대해 더 능숙하다는 것을 증명하고 있습니다.
네 번째 예시의 경우, 어떤 한 곤충이 있는 이미지에서 해당 곤충의 종류를 물어보고 있습니다. 정답은 “Andricus quercuscalifornicus“라는 곤충인데, 유일하게 E5-V만 Top-1과 Top-2에서 정답을 포함하고 있습니다. 이 역시 세 번째 예시처럼 E5-V가 MLLM을 통해 이미지와 텍스트가 혼합된 질의에 대해 강력한 모습을 보여주는 걸 알 수 있습니다. 추가적으로, 큰 규모의 사전 학습을 겪은 MLLM의 수 많은 지식들이 “Andricus quercuscalifornicus“라는 곤충을 이해하는데 도움이 됐을 거라 예상됩니다.
| 태스크 | 데이터셋 | 질의 | 정답 | UniIR Top 3 | VISTA Top 3 | STAIR Top 3 | E5-V Top 3 |
| $$q_t → c_i$$ | MSCOCO | A man with a red helmet on a small moped on a dirt road. |  |
|
|
 |
|
| A man with a red helmet on a small moped on a dirt road. | A man with a red helmet on a small moped on a dirt road. |  |
 |
||||
 |
 |
 |
A man with a red helmet on a small moped on a dirt road. | ||||
| $$q_i → c_t$$ | MSCOCO | |
A young girl inhales with the intent of blowing out a candle. A young girl is preparing to blow out her candle. A kid is to blow out the single candle in a bowl of birthday goodness. Girl blowing out the candle on an ice-cream. A little girl is getting ready to blow out a candle on a small dessert. |
A kid is to blow out the single candle in a bowl of birthday goodness. | A young girl inhales with the intent of blowing out a candle. | Girl blowing out the candle on an ice-cream. | Girl blowing out the candle on an ice-cream. |
| Girl blowing out the candle on an ice-cream. | Girl blowing out the candle on an ice-cream. | A young girl is preparing to blow out her candle. | A young girl is preparing to blow out her candle. | ||||
| A young girl inhales with the intent of blowing out a candle. | A young girl inhales with the intent of blowing out a candle. | A little girl is getting ready to blow out a candle on a small dessert. | A little girl is getting ready to blow out a candle on a small dessert. | ||||
| $$(q_i, q_t) → c_i$$ | FashionIQ | Has thin straps and different pattern and more autumn colored and longer. |
 |
|
|
|
 |
 |
 |
|
 |
||||
|
 |
 |
 |
||||
| $$(q_i, q_t) → c_t$$ | Infoseek | What is the closest parent taxonomy of this insect? |
Andricus quercuscalifornicus. Andricus quercuscalifornicus (occasionally "Andricus californicus"), or the California gall wasp, is a small wasp species that induces oak … Andricus quercuscalifornicus. galls immediately, where they can seem to balloon almost overnight onto the tree. This is the point where most of the parasitoids enter the gall, … |
Andricus kingi. Andricus kingi, the red cone gall wasp, is a species of gall wasp in the family Cynipidae.This species induces galls on various white oak species, such as the valley oak "Quercus lobata". | Ropica hoana. Ropica hoana is a species of beetle in the family Cerambycidae. It was described by Pic in 1932. | Cerioporus squamosus. up to 50 (cm) across. It plays an important role in woodland ecosystems by decomposing wood, usually elm, silver maple, or box elder but is occasionally a parasite on living trees. … | Andricus quercuscalifornicus. galls immediately, where they can seem to balloon almost overnight onto the tree. This is the point where most of the parasitoids enter the gall, … |
| Malacosoma californicum. will feed on many other types of tree foliage. Adult moths do not eat and live for 1–4 days.## Thermoregulation.Western tent caterpillars are ectothermic, … | Ropica elongata. Ropica elongata is a species of beetle in the family Cerambycidae. It was described by Breuning in 1939. It is known from Australia. | Gymnopilus junonius. Gymnopilus junonius is a species of mushroom in the family Cortinariaceae. Commonly known as the spectacular rustgill, this large orange mushroom is typically found … | Andricus quercuscalifornicus. Andricus quercuscalifornicus (occasionally "Andricus californicus"), or the California gall wasp, is a small wasp species that induces oak … | ||||
| Umbellularia. fresh sprouts.The species is a host of "Phytophthora ramorum", the pathogen that causes the disease sudden oak death. It is important in this sense because it is one of two tree species ... | Ropica coomani. Ropica coomani is a species of beetle in the family Cerambycidae. It was described by Pic in 1926. | List of lichens of Maryland. [Physciaceae]Syn.: "Physcia pusilloides" Zahlbr.Skorepa "et al." (1977) – Frederick Co., on trees.Skorepa "et al." (1979) – on bark.E.C. Uebel Herbarium … | Amphibolips confluenta. Amphibolips confluenta, known generally as the spongy oak apple gall wasp, is a species of gall wasp in the family Cynipidae. |
표 3. 모델 별 검색 결과. (각주 참고 MSCOCO14, FashionIQ15, Infoseek16)
마치며
MMIR의 태스크 정의부터 데이터셋과 벤치마크, 그리고 관련 최신 기술들까지 소개 드렸습니다. 특히 멀티모달 환경으로부터 발생하는 여러 모달리티 조합의 다양한 태스크를 어떤 식으로 모델들이 수행하고 있는 지에 대해 집중하며 설명했습니다. 이러한 멀티모달 환경의 범용적 모델들은 다양하고 복잡한 사용자의 검색 요구를 처리할 수 있고, 하나의 검색 모델이 여러 태스크를 동시에 커버하기 때문에 검색 비용과 벡터 데이터베이스 저장 비용에서 효율적이라는 장점을 가지고 있습니다.
본 블로그에서 대표적인 유형인 Dense, Sparse, MLLM 기반 인코딩 방식을 통해 MMIR에서 사용할 수 있는 다양한 모델들로 Case Study를 수행하였습니다. 해당 스터디를 통해 모델들이 질의를 만족스럽게 처리하는 부분도 있었지만 아직 부족한 결과도 보여주는 것을 확인했습니다. 특히, 인코딩 벡터에서 다양한 모달리티를 이해하고 구별하는 모달리티 간극 문제를 해소하는 것이 중요한 요소임을 알 수 있었습니다.
이러한 부분을 고려해 미래에는 다양한 모달리티에 견고하게 동작하는 MMIR 기술들을 개발하려고 합니다. 더 많은 데이터셋 및 벤치마크를 구축하고 있고 Hard Negative Sampling 등 정보 검색에서 효과를 보여왔던 기술들의 적용을 고려하고 있습니다. 추가적으로 여러 언어를 이해하는 능력을 갖추며 멀티모달 입력에 대응하는 검색 기술도 함께 연구하고 있으며 텍스트, 이미지를 넘어 오디오, 비디오의 모달리티가 확장된 검색도 계획하고 있습니다.
GPT-4o 1와 같은 멀티모달 Agent들이 빠르게 발전되고 있는 상황입니다. 이에 맞춰 Multimodal RAG, QA 등의 태스크들도 주목을 받고 있으며 MMIR 또한 중요한 기술로 자리 잡고 있습니다. 따라서 저희는 앞에서 언급한 대로 여러 측면을 고려하면서 다양한 분야에 기여 할 수 있는 견고하고 범용적인 MMIR을 지속적으로 연구해 갈 계획입니다.
참고 문헌 및 자료
-
UniIR : Training and Benchmarking Universal Multimodal Information Retrievers, ECCV 2024 ↩ ↩2 ↩3 ↩4
-
BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models, NeurIPS 2021 ↩
-
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval, ACL 2024 ↩ ↩2
-
STAIR: Learning Sparse Text and Image Representation in Grounded Tokens, EMNLP 2023 ↩ ↩2
-
E5-V: Universal Embeddings with Multimodal Large Language Models, arXiv preprint arXiv:2407.12580 ↩ ↩2 ↩3 ↩4
-
Learning Transferable Visual Models From Natural Language Supervision, ICML 2021 ↩
-
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation, ICML 2022 ↩
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019 ↩ ↩2
-
A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020 ↩
-
Simcse: Simple contrastive learning of sentence embeddings, EMNLP 2021 ↩ ↩2
-
Llava-next: Stronger llms supercharge multimodal capabilities in the wild ↩
-
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking, SIGIR 2021 ↩
-
Microsoft coco: Common objects in context, ECCV 2014 ↩
-
Fashion IQ: A new dataset towards retrieving images by natural language feedback, CVPR 2021 ↩
-
Can pre-trained vision and language models answer visual information-seeking questions?, EMNLP 2023 ↩
