
작성자
- 김영준 (멀티모달 AI Lab)
멀티모달모델과 멀티모달검색을 연구/개발하고 있습니다.이런 분이 읽으면 좋습니다!
- HuggingFace에 공개된 VARCO-VISION-14B 모델이 궁금하신 분
이 글로 알 수 있는 내용
- 모델 평가 결과
- 모델 추론 예시
들어가며
안녕하세요. 멀티모달생성팀 리더를 맡고 있는 김영준입니다. AI 분야에서 멀티모달의 중요성이 커짐에 따라 국내에서도 멀티모달 연구의 출발점으로 VLM(Vision-Language Model) 개발이 점차 활성화되고 있습니다. 기존의 LLM(Large-Language-Model)은 텍스트를 입력으로 받아 텍스트를 생성하는 모델이었다면, VLM은 텍스트와 이미지를 입력으로 받아 텍스트를 생성하는 모델을 말합니다. 그러나 대부분의 오픈소스 VLM은 영어와 중국어에 특화되어 있고, 한국어를 지원하지 않는 경우가 많습니다. 이에 우리 팀은 한국어 이해 및 생성 능력이 뛰어난 VARCO-VISION을 개발하고 누구나 사용 가능하도록 오픈소스로 공개하였습니다. 아래 그림은 VARCO-VISION의 다양한 활용사례를 한눈에 보여주고 있습니다. 이번 글에서는 VARCO-VISION의 테크니컬 리포트 1를 요약하여 소개하고자 합니다. 자세한 내용이 궁금하신 분들은 테크니컬 리포트를 참고해주시면 감사하겠습니다.
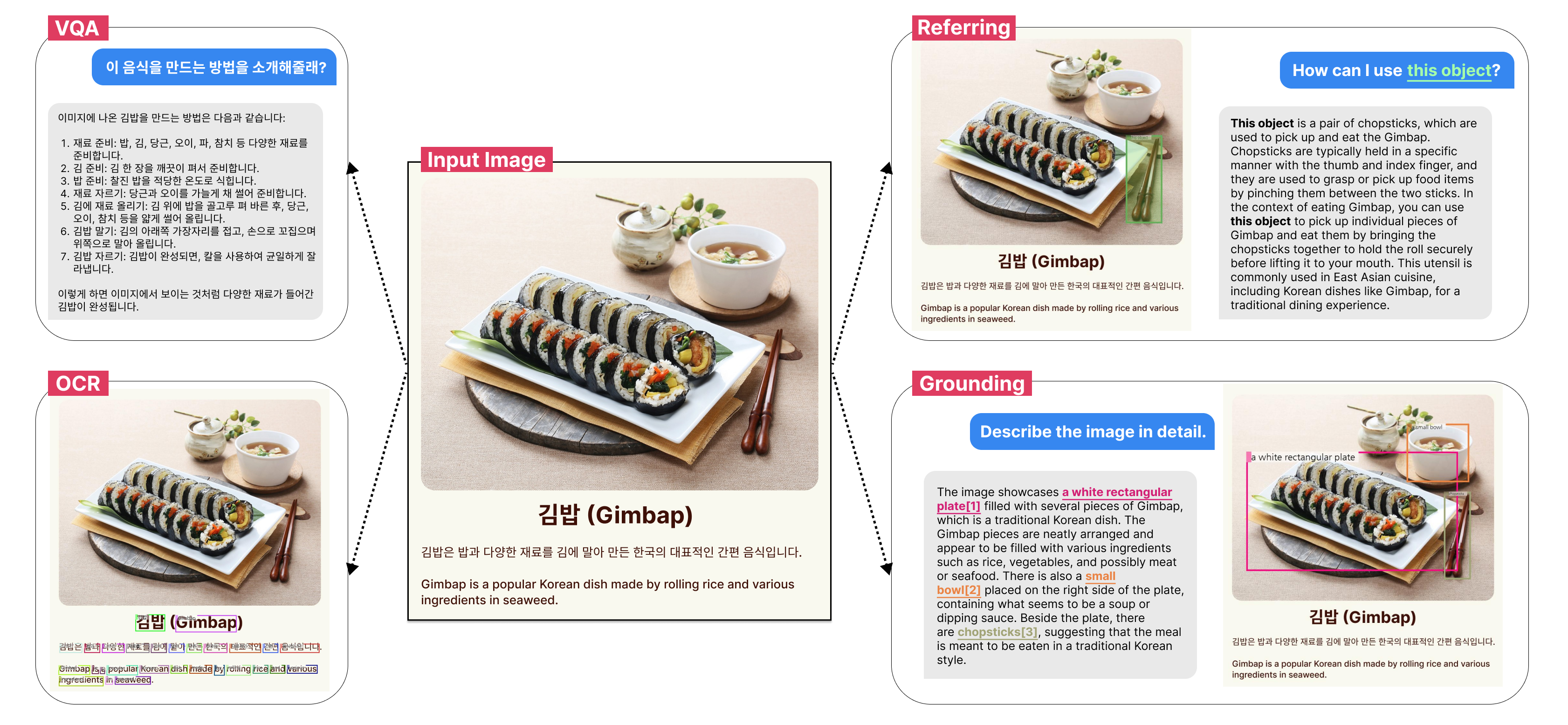
그림 1. VARCO-VISION의 다양한 활용 사례
우리 팀의 2024년 하반기 미션 중 하나는 “VLM 오픈소스 공개” 였습니다. 처음 이 미션을 받았을 때는 흥미로운 도전이라고 생각했습니다. 하지만 시간이 갈수록 경쟁이 가속화되었습니다. 새롭게 등장하는 오픈소스 모델들이 늘어났고 벤치마크 SOTA(State-of-the-Art) 점수도 나날이 높아져 갔습니다. 이러한 어려운 상황에서 팀원들과 함께 중간 평가 결과를 철저히 분석하고, 다음 단계로 나아갈 방향을 신중하게 논의하며 전략적으로 모델을 발전시켜나갔습니다. 그 결과 동일 규모의 모델 대비 뛰어난 성능을 가진 한국어 VLM 모델을 완성해 공개할 수 있었습니다. 또한 국내 멀티모달 연구에 기여하고자 한국어 기반 VLM 평가 데이터셋 5종도 함께 배포하였습니다. 아래 표에 연구 성과를 정리하였습니다. 우리 팀의 연구 결과물이 국내 VLM 생태계 발전에 의미 있는 기여가 되길 바랍니다.

표 1. VARCO-VISION 관련 내용 요약
모델 학습
VARCO-VISION의 모델 구조는 세 가지 컴포넌트로 구성되어 있습니다. 컴포넌트는 이미지 인코더(Image encoder), MLP(Multi-Layer Perceptron) 프로젝션 레이어, 사전 학습 된 언어모델(Large Language Model, LLM) 입니다. 먼저 사전 학습 된 언어모델은 QWEN-2.5 14B 2, 이미지 인코더는 SigLIP 3을 활용했습니다. 전체 모델 구조와 이미지 처리 방식은 LLaVA-OneVision 4의 방법론을 참고했습니다. 토크나이저(Tokenizer)에는 특정 기능을 트리거(Trigger)하는 스페셜 토큰을 추가했습니다. 이를 통해 사용자는 VARCO-VISION 단일 모델만으로도 OCR, 그라운딩(Grounding), 레퍼링(Referring)과 같은 비전 태스크를 수행할 수 있습니다. 특히 사용자가 원하는 시점에 해당 기능들을 켜고 끌 수 있어 유연하게 제어할 수 있는 컨트롤러블(Controllable) 환경을 제공합니다. VARCO-VISION의 훈련 파이프라인은 시각적 정보와 언어적 정보를 점진적으로 통합하고 이해할 수 있도록 4단계로 설계되었습니다. 특히 2단계부터 4단계까지는 텍스트 전용 데이터를 포함하여 사전 학습된 모델의 언어적 능력을 최대한 유지하도록 했습니다. 아래는 각 학습 단계별 주요 특징입니다.
- Stage 1. Feature Alignment Pre-training
- 학습 설정: 랜덤으로 초기화된 MLP(Multi-Layer Perceptron)프로젝션 레이어만 학습하고, 나머지 이미지 인코더와 사전 학습 된 언어모델의 가중치는 고정(Weight Freeze) 합니다.
- 데이터셋 구성:
- 캡션(Caption)
- etc.
- 결과: 이미지 인코더와 LLM이 잘 연결될 수 있게 됩니다.
- Stage 2. Basic Supervised Fine-tuning
- 학습 설정: 모든 컴포넌트를 학습(Full Fine-tuning)합니다.
- 데이터셋 구성:
- 캡션(Caption)
- 지시(Instruction)
- 문자 인식 및 검출(OCR)
- 그라운딩/레퍼링(Grounding/Referring)
- 문서/표/차트/수학
- 텍스트 전용 데이터셋
- etc.
- 결과: 모델은 기본적인 시각-언어 처리 능력을 획득합니다.
- Stage 3. Advanced Supervised Fine-tuning
- 학습 설정: 이전 단계와 동일하게 모든 컴포넌트를 학습(Full Fine-tuning)합니다.
- 데이터셋 구성:
- 데이터셋 구성 이전 학습 단계와 유사합니다.
- 이미지 해상도를 높입니다.
- 텍스트 난이도를 높인 데이터셋을 사용합니다.
- 결과: 모델의 추론 능력과 명령 수행 능력(Instruction Following)이 강화되며, 고해상도 이미지의 세밀한 분석이 가능해집니다.
- Stage 4. Preference Optimization(DPO)
- 학습 설정: 사전 학습 된 언어모델만 학습 가능하도록 설정합니다.
- 데이터셋 구성:
- 응답 정렬(Response Alignment)
- 생성 품질 향상(Generation Capability)
- 기능별 컨트롤러빌리티(Functional Controllability)
- etc.
- 결과: 모델의 생성 능력이 강화되고 사용자의 선호도에 맞는 답변을 제공하도록 학습합니다.
모델 평가
VARCO-VISION의 정량 평가는 다음 네 가지 카테고리로 나누어 진행되었습니다. 그럼 평가 결과를 하나씩 살펴보도록 하겠습니다.
- 한국어 벤치마크 기반 VLM 능력 평가
- 영어 벤치마크 기반 VLM 능력 평가
- 한국어/영어 언어 능력 평가
- 문자 인식 및 검출 평가(OCR)
한국어 벤치마크 기반 VLM 능력 평가
VLM(Vision-Language Model)의 한국어 기반 이미지 이해 및 텍스트 생성 능력을 정량적으로 평가할 수 있는 벤치마크가 부족한 상황은 국내 멀티모달 모델 연구의 제약 요인이 되어 왔습니다. 이러한 한계를 극복하고자 VLM을 한국어로 평가할 수 있는 벤치마크 5종(K-MMBench, K-SEED, K-MMSTAR, K-DTCBench, K-LLaVA-W)을 공개하기로 하였습니다. 다음은 각 벤치마크에 대한 설명입니다.
- K-MMBench : K-MMBench는 영어로 구성된 MMBench를 한국어로 번역하고 확장한 벤치마크입니다. 이 벤치마크는 아이덴티티 추론, 이미지 감정 분석, 속성 인식 등 20가지 카테고리로 이루어져 있어, 모델의 다양한 이미지 이해 능력을 종합적으로 평가할 수 있습니다.
- K-SEED : K-MMBench와 유사하게 이미지 이해 능력을 종합적으로 평가할 수 있는 벤치마크 입니다. 영어 SEED-Bench 데이터 중 20%를 추출하여 한국어로 번역하였습니다.
- K-MMStar : K-MMStar는 이미지를 깊이있게 이해해야 답을 할 수 있는 1,500개의 질문으로 구성된 벤치마크입니다. MMBench와 SEED 보다 난이도가 높고, 이미지 종류가 다양하여 모델의 추론 능력을 평가할때 유용합니다.
- K-DTCBench : K-DTCBench는 한국어로 작성된 문서, 표, 차트의 이해 능력을 평가하기 위해 직접 구축한 벤치마크입니다.
- K-LLaVA-W : K-LLaVA-W는 주어진 이미지와 텍스트를 기반으로 자연스럽고 일관된 한국어 생성이 가능한지 GPT API를 사용하여 평가합니다. 이는 모델이 단순히 이미지를 이해하는 것을 넘어 창의적이고 유창한 생성 능력을 가지고 있는지를 판단하는 중요한 지표입니다.
이러한 벤치마크를 통해 VARCO-VISION을 평가한 결과, 최신 오픈소스 중소형 모델들 중에서 한국어 기반 이미지 이해 및 텍스트 생성 능력이 가장 우수한 것으로 나타났습니다. 아래 표에서 확인할 수 있듯이, VARCO-VISION은 K-MMBench, K-SEED, K-MMStar에서 가장 높은 점수를 기록하였습니다. 특히 K-DTCBench에서 84.58점을 기록하여, 한국어로 작성된 문서, 표, 차트의 이해 능력이 다른 모델들에 비해 크게 앞섰습니다. 또한 K-LLaVA-W에서도 84.74점으로 최고 성능을 보이며, 모델의 생성 능력도 우수함을 입증하였습니다. 비록 VARCO-VISION이 상업적 모델이나 72B 규모의 대형 오픈소스 모델과 비교하면 다소 낮지만 모델의 크기와 효율성을 고려하면 준수한 성능이라고 할 수 있습니다. 이번에 공개하는 5종의 벤치마크가 한국어 기반 VLM의 발전에 기여하고, 연구/개발자들에게 유용한 데이터셋으로 활용되기를 기대합니다.
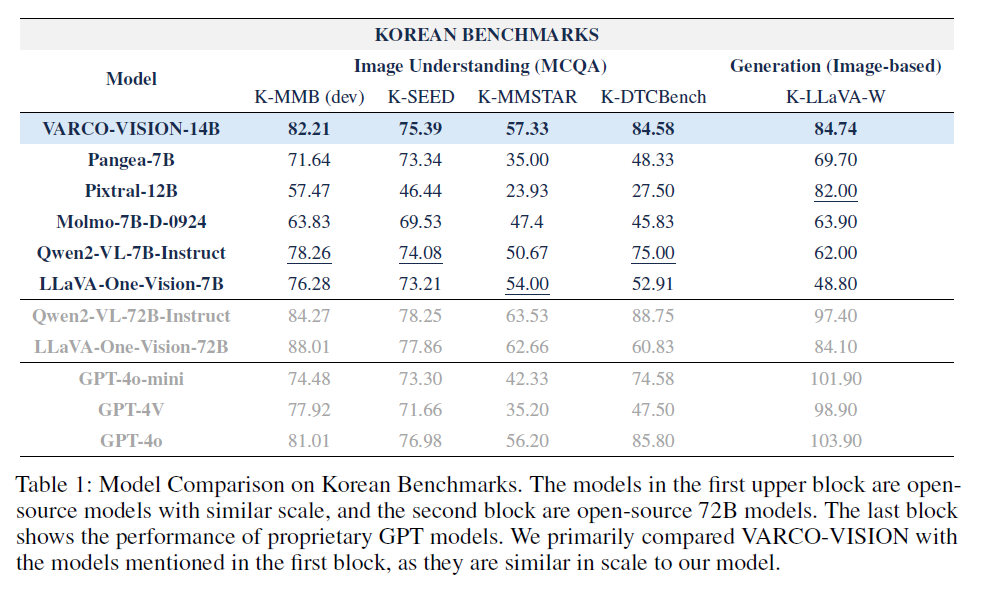
표 2. 한국어 기반 VLM 벤치마크 평가결과
영어 벤치마크 기반 VLM 능력 평가
VARCO-VISION은 영어 평가에서도 뛰어난 성능을 보여주었습니다. 비슷한 크기의 최신 오픈소스 모델들과 비교했을 때, 이미지 이해 능력을 평가하는 MMB, SEED, MMStar 벤치마크에서 가장 높은 점수를 기록하였습니다. 이 외에도 대학교 수준의 지식이 필요한 이미지를 이해할 수 있는지 평가하는 MMMU와 문자 인식 성능을 평가할 수 있는 OCRBench에서도 경쟁력 있는 모습을 보였습니다. 이를 통해 VARCO-VISION이 한국어뿐만 아니라 영어도 잘 이해한다는 것을 알 수 있습니다.
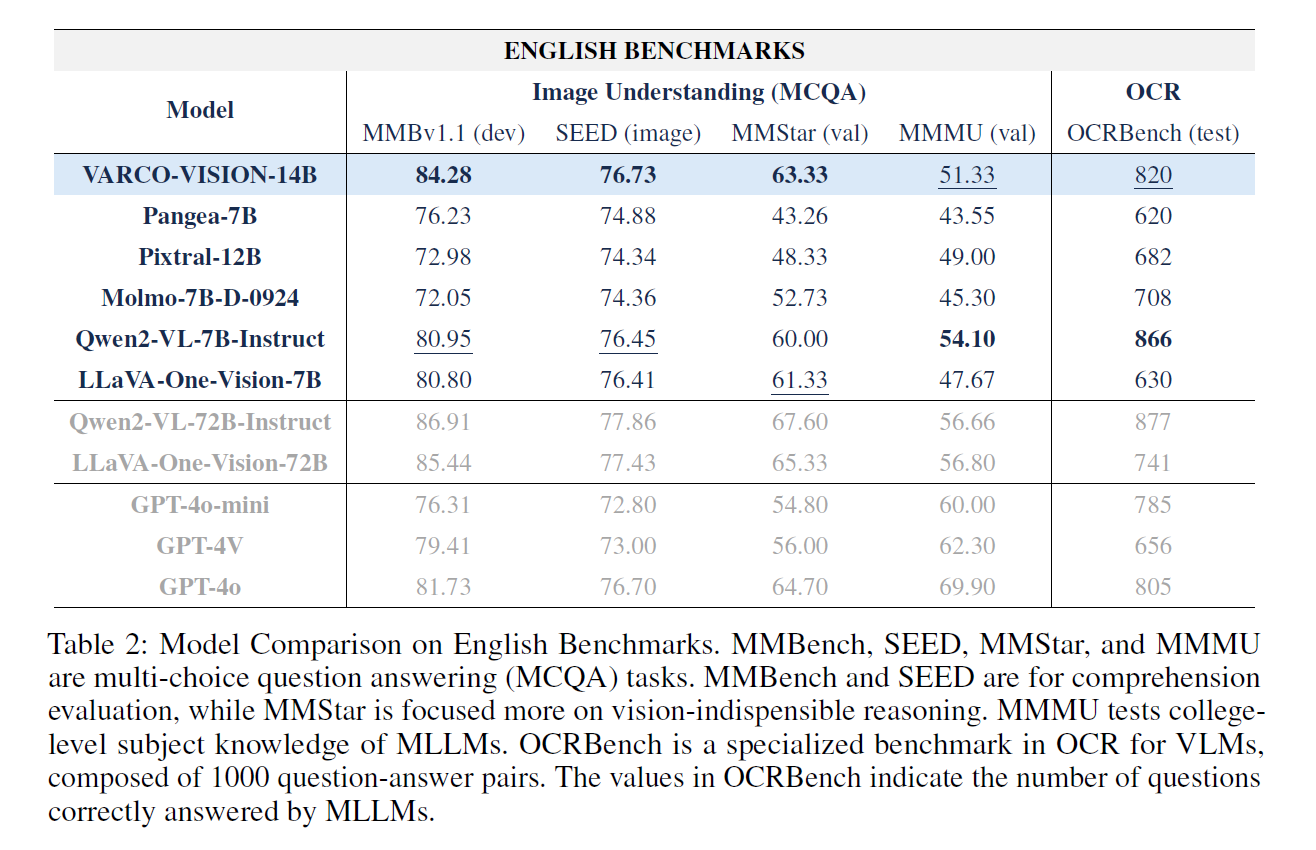
표 3. 영어 기반 VLM 벤치마크 평가결과
한국어/영어 언어 능력 평가(Language Benchmark)
끝으로 LLM을 평가할 때 사용하는 벤치마크들을 활용하여 VLM을 평가하였습니다. 대부분의 오픈소스 VLM은 LLM에 비해 언어 능력 점수가 다소 낮은 편입니다. 그러나 VARCO-VISION은 VLM임에도 불구하고 높은 점수를 기록하였습니다.
- 한국어 언어 능력 평가
- LogicKor: 8.69점
- KoMT-Bench: 8.39점
- 영어 언어 능력 평가
- MT-Bench: 8.80점
특히, 72B 규모의 대형 VLM과 비교했을 때도 VARCO-VISION의 언어 능력 점수가 더 높게 나타났습니다. 또한 이 점수는 최신 오픈소스 LLM에 근접한 수준이기도 합니다. 따라서 애플리케이션에서 LLM과 VLM 두 개의 모델을 운용하지 않아도, VARCO-VISION 단일 모델만으로 이미지-텍스트 작업과 텍스트 전용 작업을 모두 처리할 수 있을 것으로 기대됩니다.
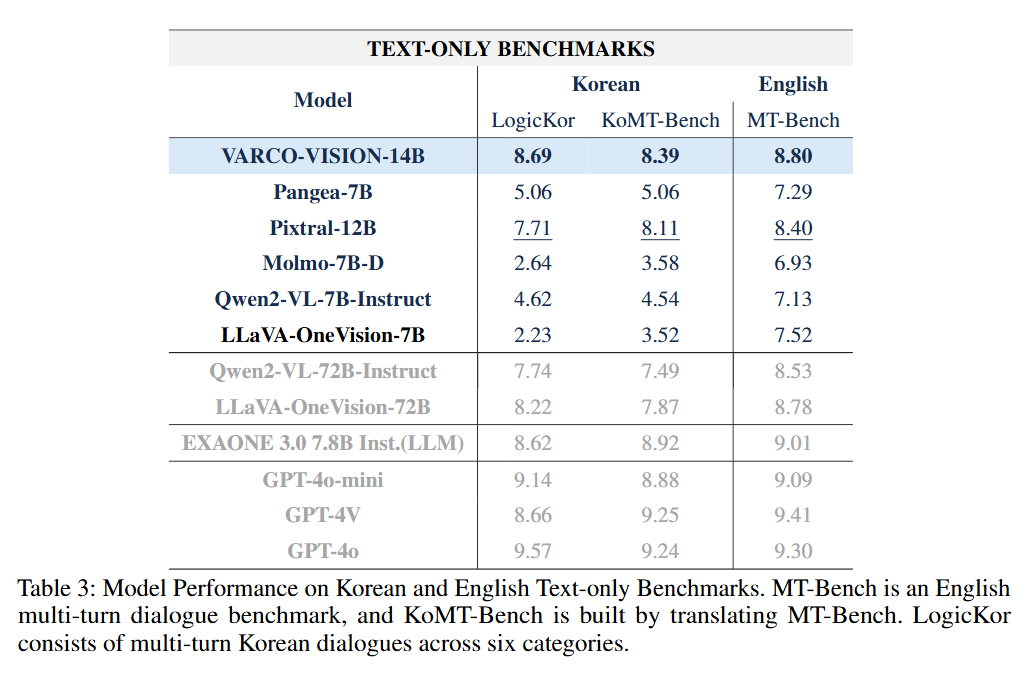
표 4. 한국어/영어 Language Benchmark
문자 인식 및 검출 평가(OCR)
VARCO-VISION은 문자 인식뿐만 아니라 이미지에서 특정 글자의 위치를 바운딩 박스로 검출하는 기능도 제공합니다. 이러한 기능 덕분에 OCR 전용 모델들과 성능 비교가 가능합니다. 아래 표는 VLM이 아닌 OCR 전용 모델들과의 평가 결과를 비교한 것 입니다. 아래 표에서 EasyOCR, Pororo, PaddleOCR은 오픈소스 모델이고, CLOVA OCR은 상업적 모델입니다. 비교 대상 모델들이 OCR만 수행할 수 있는 특화 모델이라는 점을 고려할 때, VARCO-VISION이 범용 모델임에도 불구하고 경쟁력 있는 성능을 달성했다고 평가할 수 있습니다.
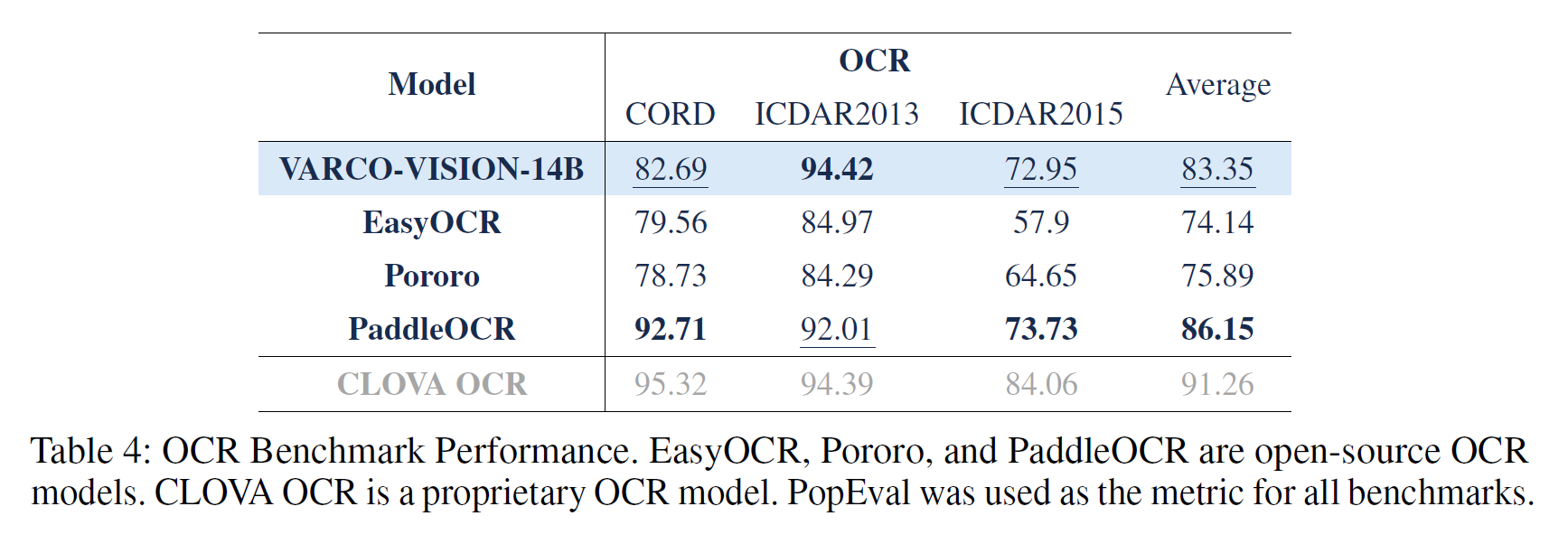
표 5. 문자 인식 및 검출 평가(OCR)
추론 예시
지금부터는 VARCO-VISION의 추론 결과를 보여드리겠습니다. 아래 예시에서는 메뉴판 이미지가 주어졌습니다. 사용자는 치즈버거 한 개와 탄산음료 한 개를 주문하고, 총 금액 계산을 요청했습니다. 모델은 각 메뉴의 가격을 정확하게 인식하여 합산한 뒤, 올바른 총액을 계산해냈습니다. 이를 통해 VARCO-VISION이 실생활에서 유용하게 활용될 수 있음을 알 수 있습니다.

그림 2. Information Extraction and Calculation 추론 예시
이번에는 문제의 난이도를 올려보겠습니다. 이미지에서 색칠된 부분의 넓이를 계산하는 문제입니다. 모델은 이를 해결하기 위해 부채꼴과 삼각형의 면적 공식을 활용했습니다. 구체적으로 전체 부채꼴의 넓이에서 삼각형의 넓이를 빼는 방식으로 정답을 도출했습니다. 이러한 문제 해결 과정을 통해 기본적인 수학적 추론 능력을 갖추고 있음을 확인할 수 있습니다.

그림 3. Mathematical Reasoning 추론 예시
이번에는 영어로 질문을 입력해보겠습니다. 제공된 이미지는 모바일 화면에 표시된 수면 그래프이며 모델에게 수면의 질을 평가하고 조언을 요청하고 있습니다. 결과적으로 모델은 그래프를 정확히 해석하고 수면에 대한 전문적인 지식을 바탕으로 적절한 조언을 제공했습니다. 특히 주목할 만한 점은 한글이 아닌 영어로 작성된 질문도 자연스럽게 이해하고 답변을 생성했다는 점입니다.
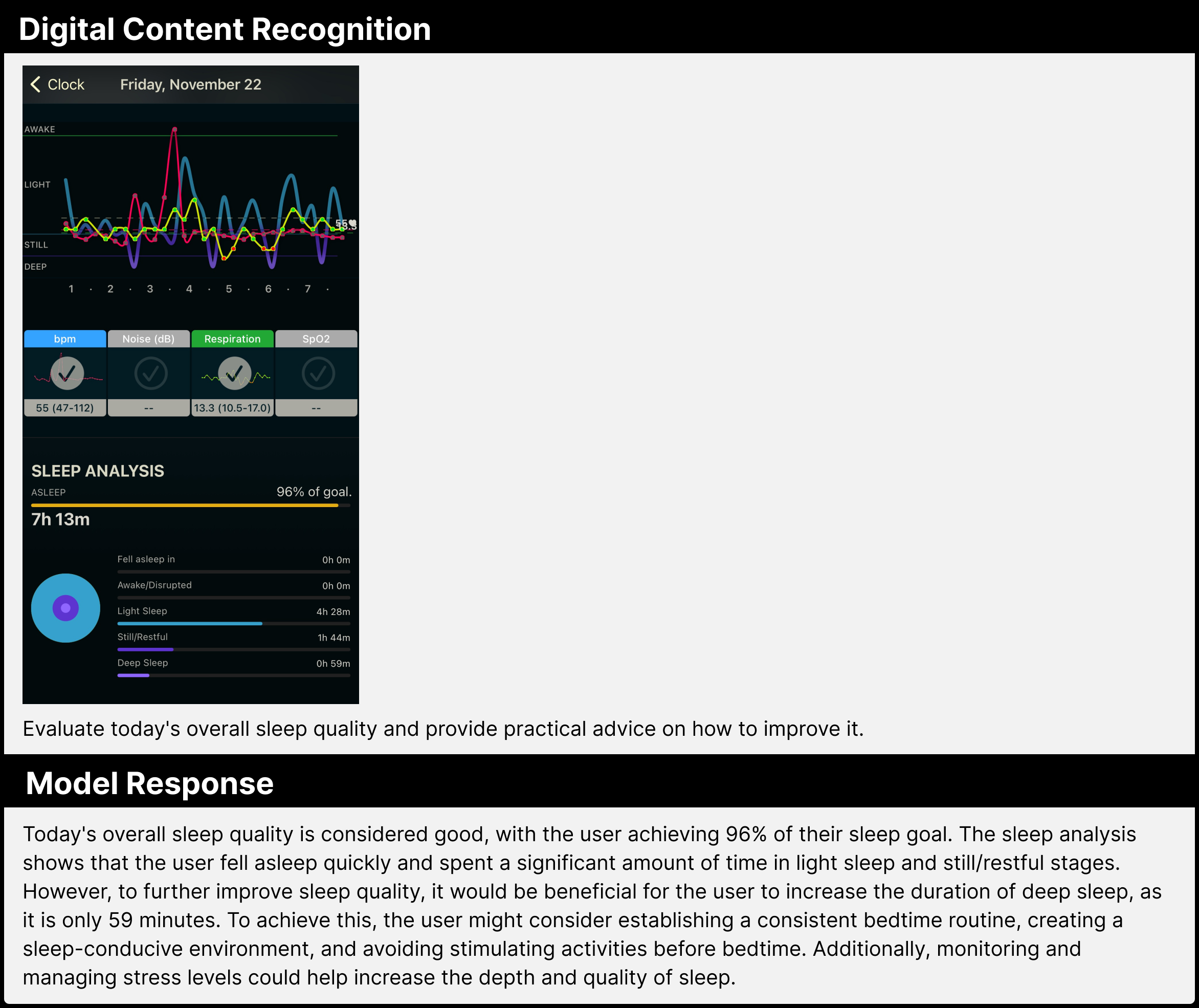
그림 4. Digital Content Recognition 추론 예시
VARCO-VISION의 OCR 기능을 살펴보겠습니다. 많은 오픈소스 VLM은 문자 인식만 가능하고, 글자의 위치 정보를 나타내는 바운딩 박스 좌표를 제공하지 않습니다. 일부 모델이 바운딩 박스를 제공하지만, 이미지 이해 능력이 부족한 경우가 많습니다. 그러나 VARCO-VISION은 단일 모델로 문자 인식과 검출을 모두 수행하며, 이미지 이해 능력도 뛰어납니다. 아래 예시에서 한글, 영어, 숫자를 모두 읽고 해당 글자의 위치까지 추론하고 있는 것을 확인할 수 있습니다.

그림 5. OCR 추론 예시
VARCO-VISION은 자연어 질의에 대한 텍스트 답변과 함께 객체별 위치 정보를 추출할 수 있습니다. 이 그라운딩(Grounding) 기능을 활용하면 객체 탐지 모델이 필요한 애플리케이션에서 VARCO-VISION 단일 모델만으로 효율적인 운용이 가능합니다.

그림 6. 그라운딩(Grounding) 추론 예시
이미지의 특정 영역을 지정하여 질의 하는 것도 가능합니다. 아래 예시와 같이 프롬프트에 특정 영역의 좌표를 입력하면 모델은 그 부분에 대한 정확한 답변을 제공합니다. 이 레퍼링(Referring) 기능은 다양한 애플리케이션에서 활용 가치가 높을 것으로 기대됩니다.

그림 7. 레퍼링(Referring) 추론 예시
마치며
글을 마치며 우리 팀의 향후 계획을 소개하고자 합니다. 단기적으로는 VARCO-VISION을 더욱 강화하는 데 집중할 예정입니다. 현재 다중 이미지(Multi-Image)와 한국 문화를 깊이 있게 이해할 수 있는 현지화된 모델을 개발하고 있습니다. 개발이 상당 부분 진행되어 가까운 시일 내에 선보일 수 있을 것으로 기대됩니다. 장기적으로는 모달리티를 확장하여 비디오와 오디오까지 처리할 수 있도록 할 계획입니다. 또한 에이전트 시대를 맞이하여 멀티모달검색(MMIR) 연구도 진행하고 있습니다. 이를 통해 멀티모달 관련 서비스에서 더욱 실용적인 솔루션을 제공하여 국내 멀티모달 기술 발전에 기여하고자 합니다.
마지막으로 VARCO-VISION을 함께 만들어나간 김대영님, 박선영님, 주정호님 외 개발에 도움을 주신 모든 분들께 진심으로 감사의 인사를 전합니다. 훌륭한 동료들과 아이디어를 공유하며 밀도 높은 시간을 보낼 수 있어 매일 아침이 설레었습니다. 앞으로도 끊임없는 도전을 통해 더 나은 기술을 만들어 나가겠습니다. 긴글을 끝까지 읽어주셔서 감사합니다.
참고 문헌
-
J. Ju et al., “VARCO-VISION: Expanding Frontiers in Korean Vision-Language Models,” arXiv preprint arXiv:2411.19103, 2024. ↩
-
P. Wang et al., “Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution,” arXiv preprint arXiv:2409.12191, 2024. ↩
-
X. Zhai et al., “Sigmoid Loss for Language Image Pre-Training,” ICCV 2023. ↩
-
B. Li et al., “LLaVA-OneVision: Easy Visual Task Transfer,” arXiv preprint arXiv:2408.03326, 2024. ↩
