
작성자
- 정민경 (AI데이터실)
AI데이터의 설계, 생성, 정제, 평가 전반에 걸친 업무를 맡고 있습니다.이런 분이 읽으면 좋습니다!
- LLM의 평가 방법을 알고 싶은 분
- 한국어 LLM 평가 방법에 대해 고민하고 계신 분
이 글로 알 수 있는 내용
- LLM을 평가하는 방법
- 벤치마크에 대한 개괄
- 한국어 벤치마크 설계 시 고려해야 할 점
들어가기
최근 인공지능 연구와 비즈니스 분야에서 초거대 언어 모델(LLM, Large Language Model)의 발전 속도가 가속화되며, 각종 리더보드에서 ‘세계 1위’, ‘성능 1위’와 같은 타이틀을 차지하기 위한 경쟁이 치열해지고 있습니다. 특히 자연어 처리(NLP)와 대화형 AI 기술은 이러한 경쟁 속에서 빠르게 발전하고 있으며, 사용자의 기대에 부응하기 위한 새로운 기술 표준이 형성되고 있습니다. 매달 새로운 LLM들이 기록을 갱신하며 등장하는 가운데 NCSOFT의 ‘Llama-VARCO LLM’이 지난 9월 Logickor 벤치마크에서 1위를 차지하며 한국어 LLM에 대한 기술적 가능성을 입증하기도 했습니다.
LLM 평가에서 벤치마크는 마치 교육을 통해 인간이 시험으로 검증받듯이, 모델이 다양한 언어적 작업에서 얼마나 효과적으로 기능하는 지를 확인하는 프레임워크입니다. 언어는 인간의 사고와 경험을 표현하고, 지식을 전달하며, 문화를 공유하는 중요한 매체로, LLM은 이러한 언어적 능력을 기계적으로 재현하는 수준을 평가받습니다. 벤치마크는 이 과정에서 모델의 강점을 명확히 하고, 부족한 부분에 대한 피드백을 제공하여 성능 향상을 촉진하는 중요한 역할을 합니다.
이에 따라, 이번 블로그 글에서는 우리가 평가해야 할 LLM의 핵심 역량과 이를 효과적으로 측정할 수 있는 벤치마크에 대해 소개하려고 합니다. 특히 몇 가지 주요 벤치마크 유형에 대해 깊이 있게 살펴보고, 한국어 LLM 평가를 위한 영어 기반 한국어 번역 벤치마크와 한국어의 언어적 특성과 문화적 맥락을 반영한 한국어 기반 벤치마크도 함께 다뤄보고자 합니다.
언어모델 평가
언어 모델의 평가 방법은 아래의 그림 1과 같이, 언어 모델의 발전과 함께 단순한 규칙 기반 평가에서 점차 다차원적 평가 방식으로 진화해왔습니다. 초기 언어 모델들은 단순한 규칙이나 사전 정의된 패턴을 기반으로 작동했기 때문에, 1960~1970년대에는 평가 방식 또한 주로 이러한 규칙의 정확성을 확인하는 데 초점이 맞춰져 있었습니다. 그러나 2000년대 초반, 인터넷이 활성화되고 사용할 수 있는 데이터 양이 급증하면서 통계적 언어 모델이 등장했고, 이에 따라 BLEU(Bilingual Evaluation Understudy), ROUGE(Recall-Oriented Understudy for Gisting Evaluation)와 같은 텍스트 일치도 기반 평가 방법이 개발되었습니다. 더 나아가 2010년대에는 GLUE(General Language Understanding Evaluation)와 SuperGLUE(Super General Language Understanding Evaluation) 같은 종합 평가 방법이 도입되어 모델의 전반적인 언어 이해 능력을 평가하는 표준으로 자리 잡았고, 최근에는 GPT-3, BERT 등의 LLM이 등장하면서 평가 방식에도 큰 변화가 필요해졌습니다.
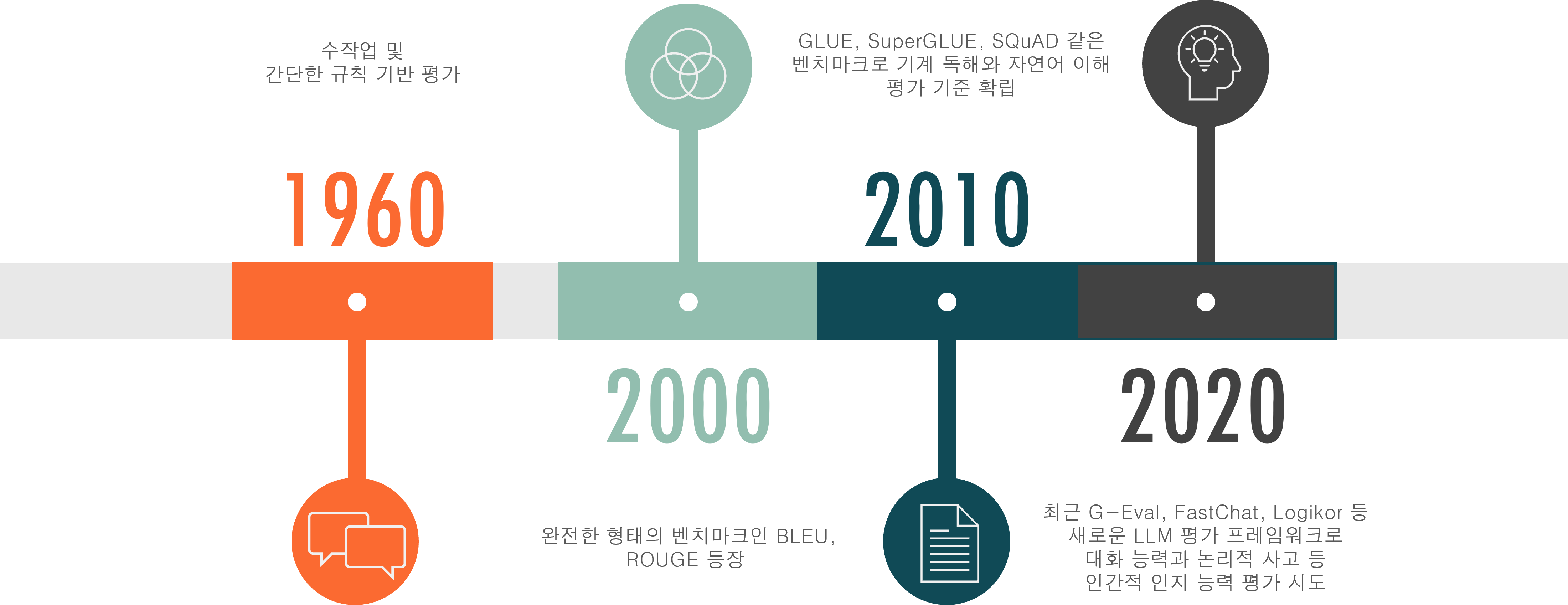
그림 1. 언어 모델 평가의 변천사
현재의 LLM은 다양한 도메인의 지식과 복잡한 언어적 맥락을 이해하고 반응하는 능력을 요구받습니다. 이에 따라 평가 또한 모델이 지식과 추론 능력을 얼마나 잘 발휘하는지, 사용자와의 상호작용에서 신뢰할 수 있는 답변을 제공하는지, 윤리적이고 안전한 결과를 생성하는지를 측정하는 다차원적 접근으로 발전했습니다.
이러한 맥락에서, Zheng(2023)은 최근 발전하는 LLM에 대해 우리가 평가해야 할 핵심 역량(Core Competency)을 네 가지로 요약했습니다. 연구에 따르면, LLM은 추론 능력(Reasoning), 지식(Knowledge), 신뢰성(Reliability), 안전성(Safety)을 적절히 갖추고 있어야 하며, 이를 기준으로 평가해야 한다고 제안합니다. 이 네 가지 역량은 LLM이 실질적인 문제 해결과 신뢰할 수 있는 정보를 제공하는 데 필수적인 요소로 작용하며, 각 역량에 대한 평가를 통해 모델의 성능을 객관적으로 파악할 수 있습니다.
| 평가 항목 | 정의 | 평가 방법 |
|---|---|---|
| 추론 능력 | · 복잡한 문제를 해결하기 위한 논리적 사고와 결론 도출 능력 평가 · 모델이 정보를 처리하고 논리적으로 답을 도출하는 능력 측정 |
· 수학 문제 해결, 인과관계 추론, 유추적 사고 등을 통한 추론 능력 확인 |
| 지식 | · 모델이 일반 상식과 전문 지식을 얼마나 잘 이해하고 활용하는지 평가 · 다양한 주제에 대한 지식 응용 능력 측정 |
· 사실 기반 질문에 정확한 답변을 요구하여 지식의 깊이와 폭 평가 |
| 신뢰성 | · 모델이 일관된 품질의 응답을 생성할 수 있는 능력 평가 · 동일한 질문에 대해 일관된 답변을 제공하는지를 확인하여 응답의 신뢰성 평가 |
· 동일한 질문을 여러 번 제시하고, 일관된 답변을 제공하는지 확인 |
| 안정성 | · 모델이 유해하거나 편향된 내용을 생성하지 않도록 방지하는 능력을 평가 · 사회적, 윤리적으로 책임 있는 콘텐츠 제공 능력을 중점적으로 평가 |
· 민감한 주제에 대한 반응을 테스트하여 유해한 정보 생성 여부 평가 |
표 1. Zheng(2023), Though the lens of core competency: survey on evaluation of large language models 내용 정리
그러나 이러한 핵심 역량은 개념적으로 매우 중요한 평가 요소이지만, 각 요소는 본질적으로 주관적이고 추상적이기 때문에 이를 명확하고 일관된 기준에 따라 평가하기란 여간 어려운 문제가 아닙니다. 예를 들어, 추론 능력의 경우 논리적인 답 뿐만 아니라 문제 해결 과정의 깊이와 정교함을 가지고 있는지 평가해야 하지만, 이를 객관적으로 정량적으로 측정하기에는 많은 어려움이 뒤따릅니다. 이러한 평가 상의 한계를 보완하고자 다양한 벤치마크가 개발되었으며, 각각의 벤치마크는 각 요소를 보다 더 체계적이고 신뢰성 있게 평가하기 위한 기틀에 해당합니다.
벤치마크
벤치마크(benchmark)는 다양한 언어 모델을 위의 표 1과 같은 핵심 역량에 따라 평가할 수 있도록 설정된 작업이나 데이터셋으로, 모델의 성능을 비교하고 기술의 발전을 확인하는 데 중요한 역할을 합니다. 이러한 벤치마크는 연구기관, 기업, 학계에서 활발히 개발되며, 자연어 처리(NLP) 연구 대회나 컨퍼런스 또는 Hugging Face와 같은 오픈 소스 플랫폼을 통해 공개되어 쉽게 접근할 수 있습니다. 이를 이용해 우리는 각 모델의 강점과 약점을 면밀히 분석하고, 특정 과제나 응용 분야에 적합한 모델을 선정할 수 있습니다. 또한, 모델 성능 개선을 위한 연구 방향을 제시하고, 차세대 모델 개발에 필요한 데이터와 기술적 요구 사항을 구체화하는 데 활용되기도 합니다.
2023년에 발표된 Lianmin Zheng의 연구에 따르면, LLM 벤치마크는 크게 기초 지식 평가, 작업 지시 수행 평가, 대화형 상호작용 평가의 세 가지 유형으로 구분됩니다. 이들은 각각 모델의 특정 능력을 심층적으로 평가하기 위한 기준으로, 벤치마크 유형에 따라 평가의 초점이 달라집니다. 기초 지식 평가는 모델이 보유한 일반 지식과 특정 분야의 이해도를 평가하며, 작업 지시 수행 평가는 사용자 지시의 정확한 수행 능력을, 대화형 상호작용 평가는 문맥 이해와 자연스러운 대화 지속 능력을 측정합니다.
| 벤치마크 유형 | 목적 | 평가 항목 | 평가 방법 | 대표 벤치마크 예시 |
|---|---|---|---|---|
| 기초 지식 평가 (Core-knowledge benchmarks) |
모델이 일반 지식이나 특정 분야의 지식을 얼마나 잘 이해하는지 평가 | 추론 능력, 지식 | 역사, 과학, 수학 등 다양한 분야의 질문에 대해 정확한 답변을 요구하며, 다중 선택 문제 활용 | MMLU, HellaSwag, ARC, WinoGrande, HumanEval, GSM8k, AGIEval |
| 작업 지시 수행 평가 (Instruction-following benchmarks) |
모델이 사용자의 지시나 명령을 얼마나 정확하게 수행하는지 평가 | 추론 능력, 신뢰성 | 개방형 질문 및 다양한 과제에 대해 지시에 맞는 응답을 요구 | Flan, SNI |
| 대화형 상호작용 평가 (Conversational benchmarks) |
모델이 사용자와의 대화에서 문맥을 이해하고 자연스러운 대화를 이어나가는 능력을 평가 | 신뢰성, 안정성 | 다중 턴 대화를 통해 질문의 의도 이해와 문맥 기반 응답 능력 측정 | CoQA, MMDialog, OpenAssistant, FastChat, G-Eval |
표 2. Zheng(2023), Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena 내용 정리
위와 관련해, 기초 지식 평가에 해당하는 MMLU, GSM8K, 작업 지시 수행 평가에 해당하는 Flan, SNI, 그리고 대화형 상호 작용로서 FastChat, G-Eval 벤치마크를 간략히 소개하고, 각각의 구성, 특징, 중요성, 예시에 대해 면밀히 살펴보고자 합니다.
기초 지식 평가(Core-knowledge benchmarks)
기초 지식 평가는 언어 모델이 기본적인 일반 지식과 특정 분야의 지식을 얼마나 잘 이해하고 있는지를 평가하는 데 중점을 둔 벤치마크 유형입니다. 모델이 학습한 지식의 범위와 깊이를 측정하며, 특히 역사, 과학, 수학과 같은 다양한 분야에서 객관적이고 정확한 답변을 할 수 있는지 확인하는 것을 목적으로 합니다. 특히 이 벤치마크는 주로 다중 선택 문제 형식을 활용하여 모델의 정확한 추론 능력과 지식 응답의 신뢰성을 평가하는데 주안점을 두고 있습니다. 이 벤치마크의 대표적인 예시로는 MMLU(Massive Multitask Language Understanding)와 GSM8K(Grade School Math 8K)가 있습니다.
MMLU (Massive Multitask Language Understanding)
MMLU는 다양한 학문 분야에 걸쳐 LLM을 평가하는 종합 벤치마크 데이터 셋이자, 가장 일반적으로 사용되는 벤치마크 중 하나입니다. 과학, 역사, 수학, 문학 등 다양한 분야에서 총 57개의 과제로 구성되어 있으며, 이 데이터셋은 모델이 특정 분야에 국한되지 않고 폭넓은 지식과 추론 능력을 발휘할 수 있는 지 객관식으로 평가합니다. 특히 제로샷, 퓨샷에 대한 종합적 지능을 측정하는 데 주로 사용되기도 합니다.
-
구성 : MMLU는 교육 수준에 따라 고등학교, 학부, 대학원 등 다양한 난이도의 객관식 질문을 포함하여, 모델이 각 단계에서 요구되는 지식을 충분히 갖추고 있는지 평가할 수 있습니다.
-
특징 : 이 벤치마크는 모델이 단순한 문장 생성이나 질문 응답 이상의 능력을 발휘할 수 있는지, 즉 다양한 주제에서 주어진 선택지 중 가장 적절한 답을 선택하는 능력을 중점적으로 테스트합니다. 이를 통해 모델의 지식 수준뿐 아니라, 선택지 간의 차이를 구별하여 정확한 답을 도출하는 추론 능력을 평가할 수 있습니다.
-
중요성 : MMLU는 다분야 학문 능력 및 상식 테스트를 통해 모델이 실질적인 사고와 지식을 바탕으로 문제를 해결할 수 있는지 평가하는 중요한 기준으로 활용됩니다.
-
예시
{
"question": "What is the embryological origin of the hyoid bone?",
"choices": ["The first pharyngeal arch", "The first and second pharyngeal arches", "The second pharyngeal arch", "The second and third pharyngeal arches"],
"answer": "D"
}
출처: https://huggingface.co/datasets/cais/mmlu
GSM8k (Grade School Math 8K)
GSM8k는 LLM의 수학적 추론과 문제 해결 능력을 평가하는 벤치마크 데이터셋으로, 초등학교 수준의 수학 문제 8,000개로 구성되어 있습니다. 이 데이터셋은 모델이 단순히 계산을 수행하는 것이 아닌, 논리적인 사고를 통해 수학적 문제를 해결하는 능력을 측정합니다. GSM8k는 메인 타입과 소크라테스 타입의 문제를 포함하고 있어, 문제를 풀어나가는 단계별 과정을 테스트할 수 있습니다.
-
구성 : GSM8k는 기본적인 산술 연산부터 고난도의 수학적 추론 문제까지를 포함하고 있으며, 모델은 문제에서 주어진 정보를 분석하고 논리적으로 접근하여 답을 도출하는 능력을 보여야 합니다.
-
특징 : 이 벤치마크는 수학 문제를 언어 형태로 제시하기 때문에, 모델은 수학적 이해 뿐 아니라 언어 처리 또한 수행해야합니다. 또한 문제를 단계별로 풀어가는 능력도 테스트하여 모델이 계산 과정에서 발생할 수 있는 오류를 최소화할 수 있는지를 평가합니다.
-
중요성 : 수리적 추론 능력은 자연어 처리에서 가장 어려운 영역 중 하나로, GSM8k에서의 성능은 모델이 논리적 사고와 수학적 추론 능력을 얼마나 잘 발휘할 수 있는지 판단하는 중요한 지표가 됩니다. 이에 따라 LLM이 복잡한 수학적 문제를 정확히 해결할 수 있는 지를 평가하는 데 자주 사용됩니다.
-
예시
{
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72"
}
출처: https://huggingface.co/datasets/openai/gsm8k
이러한 기초 지식 평가는 모델의 기본 성능과 지식의 정밀성을 평가하는 기준이 되며, MMLU와 GSM8K 외에도 HellaSwag, ARC, WinoGrande, HumanEval, AGIEval과 같은 다양한 벤치마크들이 이 유형에 포함됩니다. 그러나 이러한 기초 지식 평가 벤치마크 유형은 모델이 단순히 정답을 암기하거나 특정 지식을 기반으로 답변을 제공할 수 있는지를 확인하는 데 그쳐, 실제 상황에서 사용자와의 상호작용 능력이나 지시 수행 능력을 평가하기에는 한계가 있습니다. 이를 보완하기 위해 작업 지시 수행 평가와 같은 더 실질적이고 응용적인 평가 방식이 도입되기도 하였습니다.
작업 지시 수행 평가 (Instruction-following benchmarks)
작업 지시 수행 평가는 언어 모델이 사용자의 지시나 명령을 얼마나 정확하게 이해하고 수행하는지를 평가하는 데 중점을 둔 벤치마크 유형입니다. 이 벤치마크는 모델이 특정 지시를 따라 명확하고 일관된 결과를 생성할 수 있는지 측정하여, 모델의 유연성과 지시 수행 능력을 평가합니다. 특히, 다양한 작업 지시를 포함해 모델이 다양한 상황에서 지시를 얼마나 효과적으로 이해하고 반응하는지 확인하는 것을 목적으로 합니다.
Flan (Fine-tuned Language Net)
Flan은 다양한 자연어 처리 작업에 대한 지시를 포함하는 데이터셋으로, 모델이 주어진 지시를 얼마나 정확하게 수행하는지를 평가합니다. 이를 통해 모델의 지시 수행 능력과 일반화 성능을 측정할 수 있습니다. Flan은 텍스트 요약, 번역, 질문 응답 등 여러 작업 유형을 포함하여, 모델이 다양한 지시를 이해하고 수행하는 능력을 평가합니다.
-
구성 : Flan은 텍스트 요약, 번역, 질문 응답 등 여러 NLP 작업의 지시로 구성되어, 모델이 각 작업에 대해 명확한 지시를 얼마나 정확히 이해하고 수행할 수 있는지 평가합니다. 각 작업 유형은 모델이 주어진 지시의 의도를 파악하고, 그에 따라 응답을 생성하는 능력을 중점적으로 테스트할 수 있도록 설계되었습니다.
-
특징 : Flan의 주요 특징은 모델이 단순한 텍스트 생성에 그치지 않고, 다양한 지시를 정확하게 이행하는 능력을 평가한다는 점입니다. 모델이 지시를 해석하고 정확하게 수행할 수 있는 유연성과 일관성, 신뢰성을 측정함으로써, 다양한 작업 유형에 대한 대응 능력을 평가할 수 있습니다. 이를 통해 모델의 지시 수행 능력을 더욱 강화할 수 있는 지표를 제공합니다.
-
중요성 : Flan은 사용자의 지시 수행 평가에 중요한 역할을 합니다. 이를 통해 사용자가 특정 작업을 명확히 지시했을 때 모델이 얼마나 정확하게 이행할 수 있는지를 평가하고, 실제 사용자 환경에서 신뢰성 높은 언어 모델 개발을 도모할 수 있습니다. Flan 벤치마크는 모델의 성능이 다양한 사용자 요구를 충족할 수 있는지 확인하는 데 있어 중요한 평가 기준이 됩니다.
-
예시
{
"task": "task1540_parsed_pdfs_summarization",
"sample": [
{
"id": "task1540-80a1b85f028c4f63bf89dadadb6e52a8",
"input": "Data can be acquired, shared, and processed by an increasingly larger number of entities, in particular people. The distributed nature of this phenomenon has contributed to the development of many crowdsourcing projects. This scenario is prevalent in most forms of expert/non-expert group opinion and rating tasks (including many forms of internet or on-line user behavior), where a key element is the aggregation of observations-opinions from multiple sources.",
"output": "Evaluating Crowdsourcing Participants in the Absence of Ground-Truth"
}
]
}
SNI (Super-NaturalInstructions)
SNI는 1,616개의 다양한 NLP 작업과 전문가가 작성한 지시로 구성된 대규모 벤치마크로, 모델이 새로운 작업에 대한 지시를 얼마나 잘 수행하고 일반화할 수 있는지를 평가하는 데 중점을 둡니다. 이 벤치마크는 76개의 서로 다른 작업 유형을 포함하며, 이를 통해 모델의 지시 수행 능력과 작업에 대한 적응력을 폭넓게 측정할 수 있습니다.
-
구성 : SNI는 1,600개 이상의 NLP 작업을 다루는 대규모 데이터셋으로, 번역, 감정 분석, 요약 등 다양한 작업을 포함합니다. 전문가가 작성한 다양한 지시가 포함되어 있어, 모델이 새로운 작업에 대한 지시를 얼마나 잘 수행하는지를 폭넓게 평가할 수 있습니다.
-
특징 : 이 데이터셋은 작업의 복잡도와 난이도가 서로 다른 76개의 작업 유형으로 구성되어 모델이 명령어를 이해하고 수행하는 능력을 측정할 수 있도록 설계되었습니다. 특히 모델의 새로운 지시 해석 능력과 일반화 성능에 중점을 두어 테스트합니다.
-
중요성 : SNI는 모델이 특정 지시를 정확하게 수행할 수 있는지, 새로운 작업 지시에 대해 얼마나 적응력 있게 반응할 수 있는지를 평가하는 데 중요한 기준이 됩니다. 이를 통해 다양한 사용 사례에 대응할 수 있는 모델을 평가할 수 있으며, LLM의 활용 범위를 확대하는 데 중요한 벤치마크로 자리 잡고 있습니다.
-
예시
{
"Categories": [
"Sentiment Analysis"
],
"Positive Examples": [
{
"input": "Person1: The taxi drivers are on strike again . \n Person2: What for ? \n Person1: They want the government to reduce the price of the gasoline . \n Person1: It is really a hot potato . ",
"output": "anger, disgust, anger, anger",
"explanation": "The conversation between the two people contains the emotions anger and disgust about the taxi drivers going on strike."
}
],
"Negative Examples": [
{
"input": "Person1: Are you busy tomorrow morning ? \nPerson2: I"m free . What"s up ? \n Person1: Someone has to pick up the boss at the airport . \n Person1: Oh , I just remembered I"ve got a report to write . ",
"output": "disgust, surprise, happiness, sadness",
"explanation": "This conversation does not have any happiness present, therefore the classification and the sequence of emotions is wrong."
}
],
"Instances": [
{
"id": "task1532-26c822a5dfa248bba6b38b1d37f8d574",
"input": " Person1: I cannot understand why she always helps and supports her brother . \n Person2: Why do you say so ? \n Person1: Because he is often in trouble . \n Person2: She has promised her mother that she would be with him through thick and thin . \n Person1: Oh , I see . ",
"output": [
"No emotion,No emotion,No emotion,No emotion,No emotion"
]
}
]
}
작업 지시 수행 평가 벤치마크인 Flan과 SNI는 모델이 사용자 지시를 얼마나 정확하게 수행하는지를 평가하는 데 유용한 기준을 제공합니다. 하지만 이러한 벤치마크에도 한계가 존재합니다.
Flan과 SNI는 각기 개별적인 작업 지시에 대한 모델의 반응성을 측정하지만, 실제 사용자와의 상호작용에서 요구되는 복잡한 맥락을 온전히 반영하지 못하는 점이 있습니다. 예를 들어, 사용자의 지시가 연속적인 대화 흐름 속에서 주어질 때, 모델이 대화의 흐름을 자연스럽게 이어가고 문맥에 맞는 응답을 제공하는 능력까지 평가하기에는 한계가 존재합니다.
또한, 단순한 지시 수행 평가로는 대화의 연속성, 의도 파악, 맥락에 대한 이해와 같은 사용자들이 기대하는 자연스러운 상호작용 품질을 충분히 측정하기 어렵습니다. Flan과 SNI는 모델의 지시 수행 능력에 대한 중요한 벤치마크로 자리 잡고 있지만, 실제 사용자의 기대를 충족시키기 위한 상호작용 평가에서는 보완적인 접근이 필요합니다.
대화형 상호작용 평가 (Conversational benchmarks)
대화형 상호작용 평가는 언어 모델이 사용자와의 연속적인 대화에서 문맥을 이해하고 자연스럽게 상호작용할 수 있는지를 평가하는 데 중점을 둔 벤치마크 유형입니다. 이 평가는 모델이 단순히 주어진 지시를 수행하는 것을 넘어서, 복잡한 대화 흐름에서 사용자의 의도를 정확히 파악하고 적절한 응답을 생성하는 능력을 측정합니다. 작업 지시 수행 평가가 단일 지시나 명령에 대한 모델의 수행 능력에 초점을 맞추었다면, 대화형 상호작용 평가는 다중 턴 대화를 통해 모델의 의도 이해, 대화의 연속성, 신뢰성 있는 응답 생성 등을 중점적으로 평가합니다. 이를 통해 모델이 실제 사용자와의 대화에서 얼마나 자연스럽고 유용한 상호작용을 제공할 수 있는지를 확인할 수 있습니다. 이러한 대화형 상호작용 평가 유형에 해당하는 벤치마크 데이터셋으로는 G-Eval과 FastChat을 찾아볼 수 있습니다.
G-Eval
G-Eval은 LLM이 생성하는 텍스트의 일관성, 유창성, 사실성을 평가하는 벤치마크로써 모델이 자연스럽고 정확한 텍스트를 생성할 수 있는 능력을 측정합니다. G-Eval은 주로 정형화된 답변이 없는 창의적 작업이나 요약, 대화 생성 등의 텍스트 품질을 평가하는 데 초점을 맞추고 있습니다. 이 벤치마크는 GPT-4와 같은 고성능 언어 모델을 활용하여 사람이 평가하는 방식과 유사하게 응답 품질에 점수를 매깁니다. 이 벤치마크는 여러 장점을 가지고 있지만, GPT-4를 이용해 평가하는 만큼, GPT가 생성한 결과에 대해서는 비교적 더 좋은 평가를 주는 단점을 가지고 있기도 합니다.
-
구성 : G-Eval은 요약, 창의적 텍스트 생성, 사실적 정보 전달 등 다양한 텍스트 작업을 포함하고 있으며, 모델이 표현력과 일관성 있게 정보를 전달할 수 있는지 평가합니다.
-
특징 : G-Eval은 단순히 정답을 맞추는 형태가 아닌, 창의적이거나 열린 형태의 질문에 대해 일관되고 정확한 답변을 생성할 수 있는 지 중점적으로 평가합니다. 이 과정에서 문장의 연결성, 내용의 사실 여부, 정보 전달의 명확성 등을 평가하여, 모델의 텍스트 생성 능력을 종합적으로 분석합니다.
-
중요성 : G-Eval은 특히 요약과 같은 창의적 작업에서 모델이 유창하고 일관되게 응답할 수 있는 지 판단하는 데 중요한 기준이 됩니다. 이는 LLM이 사용자의 기대에 부합하는 자연스러운 텍스트를 생성할 수 있는지 평가하는 데 필수적입니다.
-
예시
You will be given evaluation instruction, input and AI-generated response.
Your task is to rate the response on given metric.
Please make sure you read and understand these instructions carefully. Please keep this document open while reviewing, and refer to it as needed.
Evaluation Criteria:
- Fluency (1-5): The quality of the language used in the translation. A high-quality response should be grammatically correct, idiomatic, and free from spelling and punctuation errors.
- Coherence (1-5): A high score indicates that the response maintains consistent context. A low score is given if the response shifts context or language inappropriately from instruction(e.g. instruction"s language is Korean, but response is English).
- Accuracy (1-5) - The correctness of the answer. The answer should be factually correct and directly answer the question asked
- Completeness (1-5) - The extent to which the response covers all aspects of the question. The response should not just address one part of the question, but should provide a comprehensive response.
- Overall Quality (1-5) - The overall effectiveness and excellence of the response, integrating considerations of all above criteria.
Evaluation Steps:
1. Read the instruction and input carefully and understand what it is asking.
2. Read the AI-generated response and Evaluation Criteria.
3. Assign a score for each criterion on a scale of 1 to 5, where 1 is the lowest and 5 is the highest.
Instruction:
{instruction}
Input:
{input}
Response:
{response}
Evaluation Form (scores ONLY):
- Fluency (1-5):
- Coherence (1-5):
- Accuracy (1-5):
- Completeness (1-5):
- Overall Quality (1-5):
출처: https://huggingface.co/nlpai-lab
FastChat
FastChat은 대화형 AI 시스템의 실시간 상호작용 능력을 평가하는 벤치마크로, 모델이 문맥을 이해하고 자연스럽게 대화를 이어나갈 수 있는지를 중점적으로 평가합니다. 주로 상용 AI 시스템에서 응답 품질과 대화 흐름 유지 능력을 테스트하며, 다양한 대화 시나리오에서 모델의 맥락 인식과 일관된 답변 생성을 평가합니다. 특히 공개 플랫폼인 ‘Chatbot Arena’에서 모델을 비교 평가하며, 사용자 피드백을 반영해 FastChat 기반의 성능 평가를 더욱 현실적이고 정교하게 수행할 수 있습니다.
-
구성 : FastChat은 다양한 대화 상황을 포함하며, 모델이 사용자와 실시간으로 상호작용할 때 직면할 수 있는 여러 시나리오를 기반으로 설계되어 있습니다. 이 벤치마크는 대화 중 발생하는 다양한 질문과 상황 변화에 대해 모델이 어떻게 반응하는지를 평가합니다.
-
특징 : 이 벤치마크는 단순한 질문 응답 이상의 대화형 능력을 평가하기 위해 설계되었습니다. 다중 턴 대화에서 모델이 문맥을 이해하고 적절하게 반응할 수 있는지, 사용자가 언급한 내용을 기억하며 대화 흐름을 유지할 수 있는지를 중점적으로 테스트합니다. 이러한 특성은 모델이 자연스럽고 일관성 있는 대화를 유지하는 데 필요한 주요 요소입니다.
-
중요성 : FastChat은 대화형 AI 시스템에서 모델이 문맥을 인식하고 일관된 답변을 생성할 수 있는지를 판단하는 데 필수적입니다. 실시간 사용자 상호작용 중 발생할 수 있는 여러 상황에 대한 모델의 대응 능력을 평가하여, 상업적 응용 및 연구에 있어 사용자 경험을 개선하고 실용성을 높이는 중요한 평가 기준을 제공합니다. 특히, Chatbot Arena를 통한 사용자 피드백 기반의 평가 방식은 이러한 평가의 현실성을 더욱 높여줍니다.
-
예시
[
{
"id": "identity_0",
"conversations": [
{
"from": "human",
"value": "Who are you?"
},
{
"from": "gpt",
"value": "I am Vicuna, a language model trained by researchers from Large Model Systems Organization (LMSYS)."
},
{
"from": "human",
"value": "Have a nice day!"
},
{
"from": "gpt",
"value": "You too!"
}
]
}
]
출처: https://github.com/lm-sys/FastChat/blob/main/data/dummy_conversation.json
여기까지 벤치마크의 세 가지 유형인 기초 지식 평가, 작업 지시 수행 평가, 대화형 상호작용 평가에 대해 알아보았습니다. 이 세 가지 벤치마크는 모두 언어 모델의 추론 능력, 지식, 신뢰성, 안정성을 평가하는 것을 목표로 하지만, 각각의 데이터 구조와 평가 방식에서 차이점을 보입니다.
기초 지식 평가는 질문과 단일 정답 쌍으로 구성된 간단한 구조를 통해 모델이 사실적 정보를 얼마나 정확하게 인식하는지를 평가합니다. 작업 지시 수행 평가는 지시-응답 쌍을 기반으로 모델이 특정 지시에 대해 얼마나 정확하고 반응성 있게 수행하는지를 측정합니다. 마지막으로, 대화형 상호작용 평가는 다중 턴 대화 트리 구조를 사용하여, 모델이 연속적인 대화 맥락에서 일관된 응답을 생성할 수 있는 능력을 평가합니다.
겉보기에는 비슷해 보일 수 있지만, 각 벤치마크는 그 고유한 구조와 방식으로 서로 다른 측면에서 모델의 성능을 면밀히 평가하도록 설계되어 있습니다. 이러한 차이점은 아래 표에서 자세히 확인할 수 있습니다.
| 유형** | 기초 지식 평가 (Core-knowledge)** | 작업 지시 수행 평가 (Instruction-following)** | 대화형 상호작용 평가 (Conversational)** |
|---|---|---|---|
| 구성 요소 | question: 특정 주제나 도메인 관련 answer: 단일 정답 (명확한 기준 존재) |
instruction: 사용자가 원하는 작업 요구 response: 지시 수행 결과 (주관적 평가 가능) |
utterance: 대화 시작 및 흐름 전개 response: 문맥 유지와 적절성 평가 |
| 예시 | question: 지구에서 가장 큰 바다는 무엇인가요? answer: 태평양입니다. |
instruction: 이 텍스트를 3문장으로 요약해 주세요. response: 이 사건은 큰 영향을 미쳤으며... [요약된 내용] |
utterance: 안녕하세요, 오늘 날씨 어때요? response: 안녕하세요! 오늘은 맑고 화창한 날씨입니다. |
표 3. 벤치마크 유형의 데이터 구성 요소 및 예시 비교
한국어 벤치마크 데이터셋
앞서 살펴본 여러 벤치마크를 비롯한 대부분의 벤치마크는 영어를 기반으로 개발되고 배포됩니다. 그렇다면 영어 기반의 벤치마크 데이터셋을 단순히 번역하여 한국어 LLM에 적용해도 될까요? 이번 장에서는 한국어 LLM의 성능을 평가하기 위한 벤치마크를 살펴보고, 영어 기반의 벤치마크 데이터셋을 단순히 번역해 사용하면 안되는 이유에 대해서도 살펴보고자 합니다.
한국어 LLM 의 성능을 체계적으로 평가하기 위한 벤치마크 데이터셋은 주로 두 가지 유형으로 나눌 수 있습니다. 먼저, 영어로 개발된 데이터셋을 한국어로 번역하고 최적화한 데이터셋과, 두 번째로는 한국어 고유의 언어적 특성을 반영해 처음부터 한국어로 구축된 데이터셋입니다.
영어 기반 한국어 번역 및 최적화 벤치마크 데이터셋
영어 기반 벤치마크 데이터셋을 한국어로 번역하고 최적화한 벤치마크는 한국어 LLM 성능 평가의 신뢰성을 높이기 위해 필수적입니다. 한국어에 특화된 고품질 벤치마크 데이터셋이 부족한 상황에서, 영어로 구축된 벤치마크가 국제적으로 통용되는 평가 기준을 제공하기 때문에 이를 기반으로 한국어 평가 데이터셋을 구축하는 접근법이 필요하게 되었습니다. 이러한 벤치마크 데이터셋을 이용하면 한국어 LLM의 성능을 국제적인 수준에서 객관적으로 비교하고 평가할 수 있으며, 이는 한국어 모델이 타 언어 모델과의 경쟁에서 얼마나 효과적으로 기능할 수 있는지에 대한 신뢰성 있는 지표를 제공합니다.
대표적인 데이터셋으로는 KorNLI, Open Korean Instructions가 있습니다. KorNLI는 영어의 SNLI, MNLI, XNLI와 같은 자연어 추론(NLI) 데이터셋을 한국어로 번역하여, 문장 간 논리적 관계를 분석하고 모델이 두 문장의 포함(entailment), 모순(contradiction), 중립(neutral) 관계를 잘 구분할 수 있는지 평가할 수 있습니다. Open Korean Instructions는 한국어로 번역된 다양한 지시 데이터셋을 한 곳에 모은 공개 자료입니다. “Open Korean Instructions”는 KoAlpaca, ShareGPT 번역 데이터 등 다양한 지시 기반 데이터셋을 한데 모은 한국어 공개 자료로, AI 모델이 사용자 지시를 얼마나 잘 수행하는지 평가하는 데 활용됩니다. 작업 지시 수행 평가에 중점을 두고 있지만, 일부 데이터셋을 통해 대화형 상호작용 평가도 가능하여 모델의 지시 이해도와 응답 정확도뿐 아니라 대화 능력까지 종합적으로 테스트할 수 있는 환경을 제공합니다.
이러한 한국어 번역 및 최적화 데이터셋은 한국어 LLM의 전반적인 성능을 평가하는 중요한 기준을 제시하며, 한국어 모델이 실제 환경에서 얼마나 효과적으로 작동하고 다양한 과제를 유연하게 수행할 수 있는지를 심층적으로 평가할 수 있도록 합니다. 그러나 영어 기반 데이터를 한국어로 번역하고 최적화하는 과정에서, 언어적 차이로 인한 문제가 발생하기도 합니다.
| 데이터셋 | KorNLI | Open Korean Instructions |
|---|---|---|
| 원본 데이터셋 | SNLI, MultiNLI | KoAlpaca, ShareGPT |
| 벤치마크 유형 | 기초 지식 평가 | 작업 지시 수행 평가, 대화형 상호작용 평가 |
| 평가 항목 | 문장 간 논리 관계 추론 (참, 거짓, 중립) | 지시 이해도, 수행 정확성 |
| 활용 분야 | 자연어 추론, 논리적 관계 분석 | 한국어 NLP, 대화형 시스템 |
| 평가 방식 | 번역된 SNLI, MNLI, XNLI를 통해 논리적 관계 추론 | 지시 수행 응답 평가 |
| 한계 | 한국어 번역 과정에서 의미의 뉘앙스 차이 발생 가능 | 영어 데이터를 번역하여 자연스러움이 부족할 수 있음 |
| 예시 |
전제 (Premise): 선생님이 학생에게 밖에서 기다리라고 말했다. 가설 (Hypothesis): 그 남자가 그에게 밖에서 기다리라고 했다. 레이블 (Label): Neutral |
|
표 4. KorNLI, Open Korean Instruction
KorNLI, Open Korean Instructions와 같은 한국어 벤치마크는 영어 데이터셋을 한국어로 번역하여 구축되었으나, 번역 과정에서 발생하는 언어적 뉘앙스와 문법적 구조 차이로 인해 평가의 정확성이 떨어질 수 있습니다. 예를 들어 영어에서 성별을 나타내는 “sir”이 한국어로는 중립적인 “선생님”으로 번역되면서 자연어 추론 결과에 차이를 불러오거나, 한국어의 형태소 결합 방식으로 인해 단순한 어절 매칭이 어려워 정확한 평가에 한계가 생기기도 합니다. 따라서 한국어 벤치마크는 한국어의 고유한 특성을 반영한 평가 기준이 필요하며, 이를 통해 한국어 LLM의 성능을 정확히 평가하고 글로벌 평가 기준에 부합하도록 하는 것이 중요합니다.
한국어 기반 벤치마크 데이터셋
앞서 살펴본 여러 문제점에 따라 한국어 기반 벤치마크 데이터셋이 개발되기도 했습니다. 이러한 데이터셋은 단순히 영어 벤치마크를 번역하는 것 이상의 깊이 있는 분석을 가능하게 하며, 한국어 LLM이 실제 한국어 사용자에게 적합한 응답을 제공하는지 평가하는 데 중요한 역할을 합니다. 특히 한국어 사용자들이 필요로 하는 맥락에 맞는 정확하고 자연스러운 응답을 평가할 수 있어, 실제 사용자 입장에서 더욱 유용한 평가 기준이 됩니다. 대표적인 데이터셋으로는 KorNAT, NSMC, FunctionChat-Bench이 있습니다.
KorNAT는 한국어 대형 언어 모델(LLM)의 사회적 가치 및 상식을 평가하기 위해 개발된 벤치마크입니다. 이 데이터셋은 6,174명의 한국인을 대상으로 한 대규모 설문조사를 통해 구축되었으며, 사회적 가치와 상식에 대한 이해도를 측정하는 데 목적을 두고 있습니다. KorNAT는 총 4,000개의 사회적 가치 질문과 6,000개의 상식 질문으로 구성되어 있으며, 이를 통해 모델이 한국 사회의 가치관과 일반 지식을 얼마나 잘 이해하고 있는지를 평가할 수 있습니다. 특히 이 데이터는 한국인의 사회적 가치와 상식에 대한 대규모 설문조사를 기반으로 다중 선택 질문을 제공하며, 한국어 LLM의 문화적 정렬 평가에 중점을 두고 있습니다.
NSMC(Naver Sentiment Movie Corpus)는 네이버 영화 리뷰를 기반으로 한 감정 분석 데이터셋으로, 영화 리뷰에 나타난 감정을 긍정 및 부정으로 분류하여 한국어 감정 분석 모델의 성능을 평가하는 데 널리 사용됩니다. 이 데이터셋은 총 200,000개의 영화 리뷰로 구성되어 있으며, 각 리뷰에는 긍정 또는 부정의 감정 레이블이 부여되어 있습니다. NSMC는 한국어 텍스트 분류 및 감정 분석 연구에 중요한 자원으로 자리 잡고 있으며, 대규모의 레이블링된 영화 리뷰 데이터로 구성된 이진 감정 분류용 데이터셋으로 모델 학습과 평가에 활용됩니다.
FunctionChat-Bench는 카카오에서 개발한 한국어 대화형 상호작용 벤치마크로, AI 언어 모델의 함수 호출 정확성과 문맥 인지, 정보 누락 여부 등을 평가합니다. 이 벤치마크는 모델이 “날씨 알려줘” 같은 요청에 정확한 API를 호출하고, 다중 턴 대화에서 일관성 있게 문맥을 유지하며, 필요한 정보를 빠뜨리지 않고 응답할 수 있는지를 중점적으로 테스트합니다. FunctionChat-Bench는 한국어 기반 AI 모델의 성능을 평가하는 중요한 도구로, 한국어 챗봇의 상호작용 품질을 높이고 한국어 언어 모델의 유연성과 정확성을 검증하는 데 도움을 줍니다.
| 데이터셋 | KorNAT | NSMC (Naver Sentiment Movie Corpus) | FunctionChat-Bench |
|---|---|---|---|
| 벤치마크 유형 | 기초 지식 평가 (Core-knowledge benchmarks) | 작업 지시 수행 평가 (Instruction-following benchmarks) | 대화형 상호작용 평가 (Conversational benchmark) |
| 평가 항목 | 상식, 사회적 가치 | 긍정/부정 감정 | 함수 호출의 정확성, 정보 누락 인지, 대화 맥락 유지 |
| 활용 분야 | 상식 및 사회적 가치 기반 모델 개발 | 감정 분석, 텍스트 분류 | 한국어 기반 AI 대화 시스템, 챗봇 기능 테스트, 함수 호출 기반 AI 시스템 평가 |
| 평가 방식 | 한국인의 상식과 사회적 가치에 기반한 질문 응답 | 영화 리뷰의 감정을 긍정/부정으로 레이블링 | 다중 턴 대화를 통해 모델이 각 대화 맥락에서 적절하게 함수 호출을 수행하고 대화 흐름을 유지하는지 평가 |
| 한계 | 특정 시점의 사회적 가치관 반영, 시간이 지남에 따라 변화 가능 | 영화 리뷰 도메인에 특화되어 다른 도메인에는 일반화 어려움 | 주로 함수 호출을 중심으로 하여 다른 대화형 맥락에서의 일관성 평가가 부족할 수 있음 |
| 예시 |
질문: “낮말은 새가 듣고 밤말은 쥐가 듣는다"라는 속담의 뜻을 기술하시오 보기:
|
문장: 굳 ㅋ 레이블: 긍정 (1) 문장: 볼 거 없을때 봐도 재미 없는 영화! 레이블: 부정 (0) |
사용자: 제리 출국날이 언제였지? AI 응답:
AI 응답:
AI 응답: 문자 전송 기능은 없습니다. |
표 5. KorNAT, NSMC, FunctionChat-Bench
이러한 한국어 기반 벤치마크 데이터셋은 한국어 LLM이 사용자와의 소통에서 신뢰성과 적합성을 높이는 데 중요한 역할을 합니다. 특히, 한국어 사용자에게 자연스럽고 친숙한 결과를 생성할 수 있다는 장점이 있습니다. 다만, 특정 도메인에 국한된 데이터셋, 사회적 가치의 변화, 국제적 비교 기준 적용의 어려움 등으로 인해 지속적인 데이터셋 개발과 정기적인 업데이트가 필요합니다.
마무리하며
지금까지 LLM 모델의 성능을 객관적으로 비교하고 실제 활용 가능성을 판단하는 기준으로 벤치마크가 어떻게 사용되는지, 그리고 주요 평가 요소와 벤치마크 유형에 대해 살펴보았습니다. 특히 추론 능력, 지식, 신뢰성, 안정성과 같은 중요한 요소들이 모델 평가에 사용되며, 이들 요소를 효과적으로 평가하기 위해 기초 지식 평가, 작업 지시 수행 평가, 대화형 상호작용 평가라는 세 가지 벤치마크 유형이 활용되고 있습니다.
영어 기반의 벤치마크는 한국어 LLM에 그대로 적용하기에는 한계가 있습니다. 단순 번역만으로는 의미의 일관성을 유지하기 어렵고, 문화적 차이나 언어적 특수성이 반영되지 않아 한국어 사용자에게 최적화된 성능을 평가하기에는 부족함이 있기 때문입니다. 따라서 한국어 LLM을 정확히 평가하려면 한국어의 언어적 특성과 사용자 경험을 반영한 최적화 작업이 필수적이며, 이를 통해 다양한 상황에서 실질적으로 활용될 수 있는 기반을 마련할 수 있습니다.
최근 애플의 연구에 따르면, 문제의 수치나 단어가 약간만 변경되어도 LLM의 성능이 크게 저하되는 현상이 관찰되었다고 합니다. 이는 LLM이 실제 추론보다는 학습된 패턴에 의존해 답변을 생성하는 경향이 있음을 시사합니다. 빠르게 발전하고 있는 LLM 이지만, 여전히 논리적 추론과 사고 능력 면에서는 한계를 있다는 의미이기도 합니다.
향후 LLM이 더욱 정교한 논리적 사고와 의미 이해 능력을 갖추기 위해서는, 평가 방식과 벤치마크 데이터셋도 함께 발전해야 할 것입니다. 이를 통해 LLM이 다양한 언어와 문화 속에서 실제 사용자들에게 신뢰성 있고 유용한 도구로 자리 잡을 수 있도록, 지속적인 연구와 개선이 이어져야 할 것입니다.
참고자료
- Zhuang, Z., Chen, Q., Ma, L., Li, M., Han, Y., Qian, Y., Bai, H.,
Zhang, W., & Liu, T. (2023). Through the lens of core competency: Survey on
evaluation of large language models. arXiv.
https://arxiv.org/abs/2308.07902 - Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y.,
Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., & Stoica, I.
(2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. arXiv.
https://arxiv.org/abs/2306.05685 - Kim, S., Lee, J., & Lee, C. (2023). KorNAT: LLM alignment benchmark
for Korean social values and common knowledge. arXiv.
https://arxiv.org/abs/2309.12345 - Park, H., Kim, D., & Choi, Y. (2023). BEEP! Korean corpus of online
news comments for toxic speech detection. arXiv.
https://arxiv.org/abs/2307.12345 -
Mirzadeh, I., Alizadeh, K., Shahrokhi, H., Tuzel, O., & Bengio, S. (2024). GSM-Symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv.
https://arxiv.org/abs/2410.05229 - https://huggingface.co/datasets/jiyounglee0523/KorNAT
- https://huggingface.co/datasets/cais/mmlu
- https://huggingface.co/datasets/openai/gsm8k
- https://huggingface.co/nlpai-lab
- https://github.com/allenai
- https://github.com/google-research/FLAN/tree/main/flan
- https://github.com/e9t/nsmc
- https://github.com/kocohub/korean-hate-speech
- https://github.com/lm-sys/FastChat
- https://www.enkefalos.com/newsletters-and-articles/evaluating-large-language-models/
