

작성자
- 이현수 (Graphics AI Lab)
- 박경민 (Graphics AI Lab)
이런 분이 읽으면 좋습니다!
- 3D 생성 기술의 현 수준에 대해 알고 싶으신 분
- 사진 한 장으로 게임 어셋용 3차원 모델이 어떻게 만들어질 수 있는지 궁금하신 분
이 글로 알 수 있는 내용
- LRM의 동작 원리와 특징
- LRM의 한계와 발전 방향
들어가며
안녕하세요! 지난 NC Research 블로그 NeRF로 실감나는 3D 모델 만들기, NeRF를 게임 제작에서 이용할 수 있을까?를 통해 NeRF1가 무엇인지, 어떻게 게임과 결합될 수 있는지 소개해 드렸습니다. 이번 글에는 NeRF를 응용한 LRM(Large Reconstruction Model)2이란 기술을 소개해 드리고자 합니다.
LRM은 단 한 장의 이미지로 불과 5초 만에 3D 모델을 만들어내는 기술입니다. 기존 NeRF로는 고작 3D 모델 하나를 만들기 위해 백 장이 넘는 이미지로 수 시간이나 계산을 했어야 했는데요, LRM은 어떻게 3D 생성에 필요한 이미지 수와 계산 시간을 크게 줄일 수 있었는지 지금부터 하나씩 살펴보도록 하겠습니다.
 |
 |
 |
|
|
|
|
표 1. 입력 이미지와 LRM이 만들어낸 3D 모델2
왜 LRM일까?
NeRF의 문제점
NeRF를 직접 학습하는 방식은 준비과정이 번거롭고 오래 걸려… 그리고 반복 작업으로 비효율적
NeRF는 물체나 장면을 전문 모델러나 비싼 스캔 장비의 도움 없이도 여러 위치에서 촬영한 이미지들로 고품질 3D 모델을 만들 수 있는 기술입니다. 하지만 3D 모델 하나를 만들기 위해 (1) 물체의 이미지를 백 장 넘게 촬영해서 준비해야 하고, (2) 하루 종일 NeRF를 학습 시켜서, (3) 우리가 눈으로 볼 수 있도록 렌더링 하는데 수십 초가 걸리며, (4) 새로운 3D 모델을 만들려면 (1)~(3)을 다시 해야 한다는 문제가 있습니다.
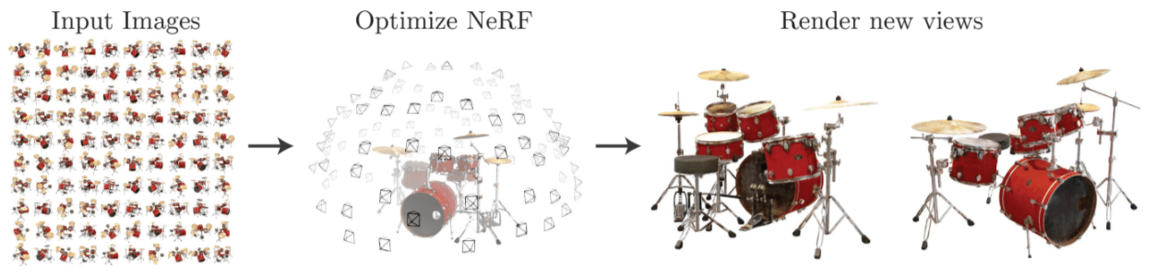
그림1. NeRF1
(더 자세히 알고 싶으시다면 이전 글 NeRF로 실감나는 3D 모델 만들기를 참조해 주세요)
LLM 말고 LRM
LLM은 많은 텍스트를 학습해 문맥을 이해하고 새로운 텍스트를 생성하는 것이 가능
LRM은 많은 3D/비디오를 학습해 물체의 구조를 이해하고 새로운 3D 모델을 생성하는 것이 가능
Gothic Chair by Dirtrock on Sketchfab
3D로 만든 의자 (출처: Sketchfab)
여기 의자를 준비했습니다. 마우스로 돌려보지 않아도 우리는 의자의 뒷면이 어떻게 생겼는지 예상할 수 있습니다. 왜냐면 우리는 “앉는 부분과 등을 기댈 수 있는 등받이로 구성되어 있으며, 네 개의 다리가 달린 의자라는 물건”을 일상에서 자주 본 적이 있기 때문입니다.
그럼 많은 LLM(Large Language Model)이 많은 텍스트를 학습하여 문맥을 이해하고 다양한 문장을 생성하는 것처럼 어떤 모델에 많은 3D 데이터를 학습시키면 물체의 구조를 이해하고 다양한 3D 모델을 생성하는 것도 가능하지 않을까요? 이런 아이디어에서 출발해 LLM처럼 확장성이 높은 Transformer 기반 구조를 아주 많은 3D/비디오 데이터를 학습시킨 LRM(Large Reconstruction Model)이 탄생했습니다.
빠르고 편리한 LRM
LRM은 한 장의 이미지로 5초 만에 3D 데이터를 생성 가능, 게임 개발 환경에 적용하기 좋아…
LRM은 단 한 장의 이미지만으로 5초 만에 3D 데이터를 생성할 수 있습니다. 이는 사전에 많은 데이터를 학습하여 구축한 사전 지식을 활용해 이미지에서 물체의 형상을 즉시 추론할 수 있고, 또한 효율적인 Triplane-NeRF 구조3를 사용해 렌더링에 필요한 시간을 단축했기 때문입니다.
이러한 특징으로 LRM은 그때그때 떠오르는 아이디어를 스케치하고, 바로바로 테스트를 해야 하는 일이 잦은 게임 개발 프로세스에서 매우 유용하게 사용될 수 있습니다.
LRM의 동작 방식과 특징
LRM은 어떻게 이미지로 3D 데이터를 만들까?
Transformer 기반 Encoder-Decoder가 입력 이미지를 Triplane Feature Map으로 변환
Triplane-NeRF 방식으로 3D 데이터를 표현
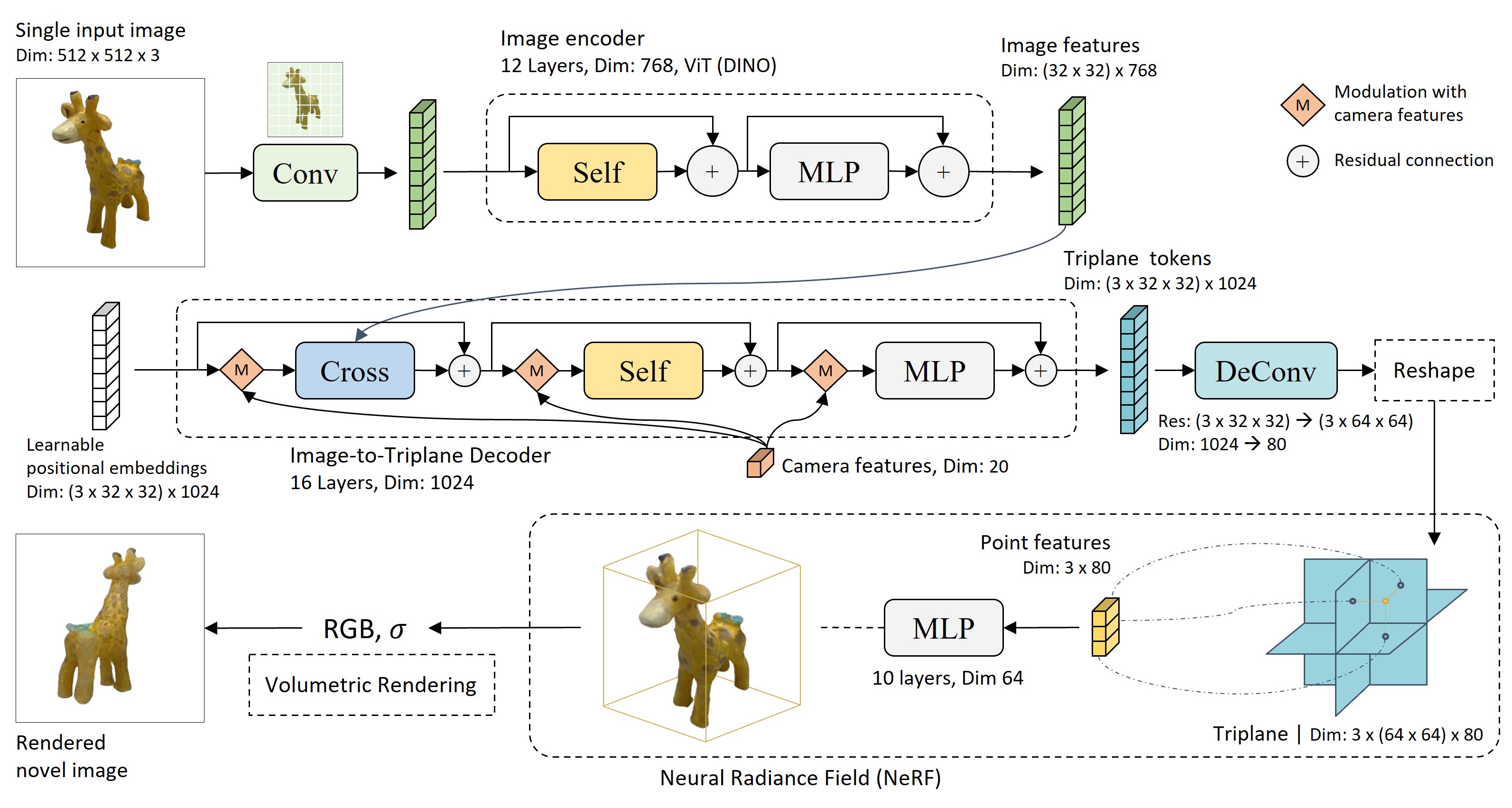
그림 2. LRM 구조2
LRM이 이미지에서 3D 모델을 만드는데 두 단계를 거칩니다.
(1) 이미지를 Triplane Feature Map으로 변환하기: Image Encoder가 이미지에서 사물의 정보를 추출하면 Image-to-Triplane Decoder가 그 정보를 3D 형태와 색상 정보를 담은 Triplane token으로 변환합니다. 마지막으로 일련의 과정을 거쳐 Triplane token은 삼중 평면 구조의 Triplane Feature Map으로 재구성됩니다.
(2) Triplane-NeRF를 이용한 볼륨 렌더링: Triplane-NeRF는 NeRF의 일종으로 Triplane Feature Map에 담긴 정보를 이용해 볼륨 렌더링을 수행합니다. 볼륨 렌더링은 3차원 공간의 각 점 (a, b, c)에서 색과 밀도를 계산하는 방식으로 이루어집니다. 이때 색과 밀도를 계산하기 위한 정보는 Triplane Feature Map의 세 평면 XY, YZ, XZ에서 점 (a, b, c)에 대응하는 지점의 정보들을 모아 합치는 것으로 만들 수 있습니다. 추가로, DMTet4과 같은 기술을 이용해 Triplane-NeRF에서 Mesh를 만들 수도 있습니다.
DINO: 사물의 형태와 질감을 이해하는 능력이 뛰어난 Image Encoder
이미지 속 사물의 형태와 질감 정보를 추출하는 능력이 뛰어난 DINO가 LRM이 3D 데이터를 만드는 데 도움을 줘
DINO5는 사전에 많은 이미지를 학습하여 이미지에 대한 풍부한 사전 지식을 갖춘 Vision Transformer 모델입니다. 특히 이미지 속 사물의 형태와 질감 정보를 추출하는 능력이 탁월해 다양한 컴퓨터 비전 분야에서 활용되고 있습니다.
LRM 또한 DINO를 Image Encoder로 사용합니다. DINO가 어떤 이미지에서라도 3D 정보를 추론하는데 필요한 양질의 정보를 잘 추출해 주기에 LRM이 다양한 이미지로부터 3D 모델을 생성할 수 있게 되었습니다.
초대량의 데이터로 학습하여 물체의 형상을 이해한 LRM
Objaverse와 MVImgNet 데이터로 로 Image-to-Triplane Decoder와 Triplane NeRF의 MLP를 학습
2D와 3D의 관계성을 이해, NeRF 재학습이 필요 없이 이미지 한 장으로 3D 정보를 추론하는 능력을 갖춰…
LRM은 약 70만 개가 넘는 3D 모델과(Objaverse 데이터 셋) 20만 개가 넘는 비디오를 학습했습니다. 총 100만 개가 넘는 데이터를 이용해 사물의 이미지와 입체 형상 간 상관관계를 학습한 덕분에 이미지 한 장에서 3D 정보를 추론할 수 있는 능력을 갖추게 되었습니다. 그 결과 LRM은 NeRF처럼 학습용 이미지를 여러 장 준비하거나 NeRF를 재학습 시킬 필요 없이 빠르게 3D 모델을 만들어낼 수 있게 되었습니다.
 |
 |
그림3. LRM 학습에 사용한 데이터셋 (좌)Objaverse Dataset6, (우)MVImgNet7
Triplane-NeRF: 메모리 효율과 렌더링 속도 두 가지 토끼를 잡은 3D 표현 방식
NeRF는 렌더링 속도가 느려, Voxel은 메모리 사용량이 많아…
Triplane-NeRF는 둘의 장점만 모은 하이브리드방식, 적은 메모리만 사용해 빠르게 렌더링이 가능
LRM은 Triplane-NeRF 방식으로 3D 데이터를 표현, 덕분에 3D 모델 생성 시간을 더욱 단축할 수 있어
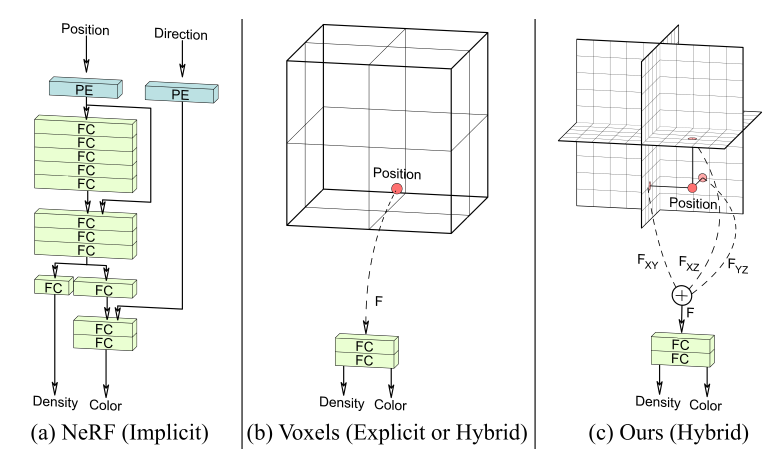
그림 4. (a) NeRF, (b) Voxel, (c) Triplain-NeRF3
NeRF는 작은 네트워크 모델 안에 3D를 표현하는데 필요한 정보를 모두 담고 있습니다. 그래서 사용하는 메모리가 많진 않지만 렌더링에 필요한 정보를 얻기 위해 매번 많은 연산을 수행해야 하기에 3D 정보를 시각화하는데 많은 시간이 걸립니다. 이와 반대로 Voxel은 3차원 그리드에 렌더링에 필요한 정보를 미리 저장해두는 방식으로, 빠르게 렌더링이 가능하지만 많은 메모리를 사용하게 됩니다.
Triplane-NeRF는 NeRF와 Voxel의 장점을 합친 방식입니다. 렌더링에 필요한 정보를 셋으로 나눠 2차원 그리드 3개에 나눠 저장하였다 필요하면 다시 꺼내 합치는 방식으로 Voxel처럼 많은 메모리를 사용하지 않고도 NeRF보다 빠르게 렌더링을 수행합니다.
LRM은 3D 정보를 표현하기 위해 Triplane-NeRF를 채용하였습니다. Triplane-NeRF의 빠른 속도 덕에 이미지 입력에서 3D 모델 렌더링까지 걸리는 시간을 더욱 단축시킬 수 있었습니다.
LRM의 한계와 개선 연구
이미지 한 장 만으론 정보가 부족해
이미지 한 장에서 얻을 수 있는 정보가 부족, 뒷면이 흐릿하고 형태가 왜곡된 데이터가 만들어져…
→ 사물을 여러 각도에서 바라본 이미지들을 생성하는 Multi-view Diffusion을 도입해 개선
이미지 한 장으로만 3D 모델을 만들어내는 건 역시 한계가 있었습니다. 이미지에선 보이지 않는 측면, 후면에 대한 추론 능력이 다소 부족해 3D 모델의 측면이나 후면이 흐릿한 문제가 있습니다. 그리고 우리가 한쪽 눈을 감으면 물체의 거리감을 잘 느끼지 못하듯 LRM 또한 이미지 한 장 만으론 원근법에 의한 물체 왜곡을 인지하지 못해 뒤틀린 형상의 3D 모델을 만드는 실수를 하기도 합니다.
이를 극복하기 위해 LRM에 Multi-view Diffusion을 도입하는 방법이 연구되었습니다. Muti-view Diffusion이란 텍스트 혹은 한 장의 이미지로부터 여러 각도에서 물체를 바라본 이미지를 생성하는 기술입니다. 이를 이용해 LRM이 물체의 정면, 측면, 후면을 동시에 참조하도록 하여 디테일 정보 손실이나 형태 왜곡이 일어나는 것을 막을 수 있습니다.

그림 5. 이미지 한 장으로 여러 각도에서 본 이미지를 만드는 Multi-view Diffusion 모델8
| 입력 이미지 | LRM 결과 | InstantMesh 결과 |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
표 2. 이미지 한 장만 사용하는 LRM과 Multi-view Diffusion을 사용하는 InstantMesh9
디테일을 살리기엔 메모리가 모자라
고품질 3D 데이터를 생성하려면 더 큰 Triplane이 필요, 하지만 메모리 용량은 충분하지 않은데…
→ 효율적인 공간 표현으로 메모리 사용량을 줄인 GeoLRM, 아낀 만큼 더 많은 이미지를 사용해 고품질 3D 데이터 생성
LRM이 더 고품질의 3D 모델을 만들게 하려면 더 큰 Triplane Feature Map을 사용하면 됩니다. 하지만 Triplane Feature Map의 크기를 무작정 늘리다 보면 금방 메모리가 부족하게 됩니다. 이 문제로 LRM이 만들 수 있는 3D 모델의 품질엔 한계가 있습니다.
GeoLRM10은 3차원 공간에서 물체가 차지하지 않는 빈 공간이 꽤 많다는 사실에 착안해 고안한 더 효율적 3D 정보 저장 방식을 사용합니다. 그리고 절약한 메모리를 더 많은 입력 이미지를 처리하는데 활용해 디테일이 살아있는 3D 모델을 생성할 수 있었습니다.
영상1. GeoLRM이 만든 고품질 3D 모델10
마치며
이상으로 이미지 한 장으로 5초 만에 3D 모델을 만들어내는 LRM의 동작 방식과 특징, 한계에 대해 살펴봤습니다.
LRM은 그 잠재력을 알아본 연구자들에 의해 계속 발전이 이루어져 많은 파생 기술이 개발되고 있는데요, NC Research에서도 관심 있게 지켜보며 3D 생성 기술을 연구하고 있습니다. 앞으로 LRM과 LRM에 뿌리를 둔 기술들이 어떻게 더 발전할지, 저희 NC Research의 연구가 어떤 발전을 만들어낼지 기대해 주시기 바랍니다.
긴 글 읽어주셔서 감사합니다.
Reference
-
Mildenhall, Ben, et al. Nerf: Representing scenes as neural radiance fields for view synthesis ↩ ↩2
-
Hong, Yicong, et al. Lrm: Large reconstruction model for single image to 3d ↩ ↩2 ↩3
-
Chan, Eric R., et al. Efficient geometry-aware 3d generative adversarial networks ↩ ↩2
-
Shen, Tianchang, et al. Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis ↩
-
Caron, Mathilde, et al. Emerging properties in self-supervised vision transformers ↩
-
Deitke, Matt, et al. Objaverse-xl: A universe of 10m+ 3d objects ↩
-
Yu, Xianggang, et al. Mvimgnet: A large-scale dataset of multi-view images ↩
-
Shi, Ruoxi, et al. Zero123++: a single image to consistent multi-view diffusion base model ↩
-
Xu, Jiale, et al. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models ↩
-
Zhang, Chubin, et al. Geolrm: Geometry-aware large reconstruction model for high-quality 3d gaussian generation ↩ ↩2
