

작성자
- 엄영식 (Audio AI Lab)
- 최승제 (Audio AI Lab)
이런 분이 읽으면 좋습니다!
- 음성 신호처리, 음성 합성에 대한 기초적인 지식을 보유하신 분
- 최신 음성 합성 기술에 대하여 아이디어를 얻고 싶으신 분
이 글로 알 수 있는 내용
- 기존 TTS 연구와 다른 MultiVerse TTS만의 차별성과 적용된 기술
- 논문: https://arxiv.org/pdf/2410.03192
들어가며
스파이크 존즈 감독의 영화 ‘Her’를 보셨나요? 주인공 테오도르는 인공지능 사만다에게 점점 더 깊이 빠져듭니다. 사만다가 단순한 프로그램이라는 것을 알면서도, 우리는 왜 그녀에게 인간적인 감정을 느끼게 될까요? 그 이유는 바로 사만다의 자연스럽고 부드러운 목소리에 있습니다. 그녀는 단순히 정보를 전달하는 것이 아니라, 마치 사람과 대화하듯 농담을 하고 감정을 표현합니다. 그렇기 때문에, 시각적인 정보 없이 오직 목소리만으로도 우리는 사만다에게 깊은 공감을 느끼게 됩니다.
최근 오픈AI가 GPT-4o를 선보이면서 영화 속 상상이 현실이 되고 있습니다. GPT-4o는 사용자와의 대화에서 지연 없이 매끄럽게 소통하며, 상황에 맞는 다양한 표현을 사용합니다. 마치 스마트폰 너머에 실제 사람이 있는 듯한 착각을 불러일으키죠.
이처럼 음성 합성 기술은 단순한 정보 전달을 넘어, 우리에게 새로운 경험을 선사합니다. 딱딱하고 기계적인 목소리에서 벗어나, 사람과의 대화처럼 자연스럽고 다채로운 표현이 가능해진 것입니다. 그렇다면, 이러한 음성 합성 기술은 어떻게 만들어지는 걸까요? 올해 개최될 EMNLP 2024를 통해 공개한 저희 연구, MultiVerse TTS를 소개하며 그 비밀을 함께 파헤쳐 보겠습니다.
음성 생성 기술의 종류는 어떠한 것이 있는가?
음성 생성 기술에서 가장 먼저 떠올리는 것은 텍스트를 음성으로 변환하는 텍스트 투 스피치(Text-To-Speech, TTS) 기술일 것입니다. 더 나아가 사용자는 단순히 텍스트를 음성으로 변환하는 것을 넘어, 자신이 원하는 특정 음색이나 스타일의 음성을 생성하고 싶어 하였습니다. 이러한 요구를 충족시키기 위해 다양한 음색의 음성을 하나의 텍스트 입력으로 생성하는 다화자 TTS (Multi-speaker TTS) 기술이 등장했습니다.
하지만 기존 TTS 모델은 학습에 사용된 화자의 음성 데이터가 충분해야만 정확한 음성을 생성할 수 있었습니다. 만약 새로운 화자의 음성을 생성하고자 한다면, 해당 화자의 많은 양의 음성 데이터가 필요했습니다. 이러한 한계를 극복하기 위해 제로샷 TTS (Zero-shot TTS) 기술이 개발되어 왔습니다. 제로샷 TTS는 짧은 음성 샘플만으로도 해당 음성에 담긴 고유한 음색 특징을 추출하여 새로운 음성을 생성하는 기술입니다. 즉, 적은 양의 데이터만으로도 다양한 화자의 음성을 생성할 수 있게 되었습니다.
한국어만 할 수 있는 사람의 목소리로 다른 언어를 구현할 수 있을까요? 이러한 궁금증에서 출발한 기술이 바로 교차 언어 TTS (Cross-lingual TTS)입니다. 기존의 다국어 TTS (Multi-lingual TTS)는 여러 언어를 유창하게 구사하는 성우의 음성 데이터를 기반으로 제작되었습니다. 즉, 같은 음색으로 다양한 언어를 구현하기 위해서는 다국어 구사 능력을 갖춘 성우가 필수였죠. 하지만 교차 언어 생성 TTS는 이러한 제약에서 벗어나, 한 가지 언어만 구사하는 화자의 음성 데이터를 학습하여 다른 언어의 음성을 생성할 수 있게 되었습니다. 이는 다국어 TTS와 동일한 효과를 제공하면서도, 필요한 음성 데이터의 양을 현저히 줄여 개발 비용을 절감할 수 있다는 장점이 있습니다.
이 외에도, 음성 생성 연구에는 다른 사람의 음성의 강세나 억양들을 원하는 사람의 음성으로 전이하는 음성 스타일 전환 (style transfer) 기술, 음의 길이(duration)과 음고(pitch) 등 음성의 특성을 원하는 만큼 수정할 수 있는 음성 편집 기술 등이 꾸준히 발전하고 있습니다.
하지만, 음성 생성 서비스를 제공하기 위해서는 다양한 모델이 필요하며, 이는 곧 비용 증가로 이어질 수 있습니다. 각 모델별로 별도의 음성 데이터를 준비하고 서버를 운영해야 하기 때문입니다. 기존 연구에서는 여러 작업을 하나의 모델로 지원하는 연구가 있었지만, 앞서 언급한 모든 기능을 수행할 수 있는 모델은 찾기 어려웠습니다.
그래서 저희는 하나의 모델로 다양한 음성 생성 작업을 수행하는 통합 프레임워크 MultiVerse TTS를 개발했습니다. MultiVerse TTS는 모든 작업에 동일한 음성 데이터를 활용하고, 단일 서버 환경에서 여러 가지의 음성 생성 서비스를 제공할 수 있습니다[표 1]. 이어지는 설명을 통해 각 기능에 대해 자세히 알아보도록 하겠습니다.
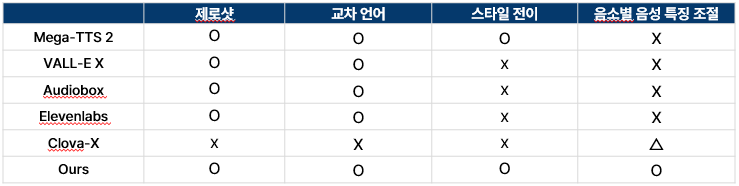
표 1. 각 프레임 워크별 사용 가능 기능 유/무
MultiVerse TTS 소개 및 기능
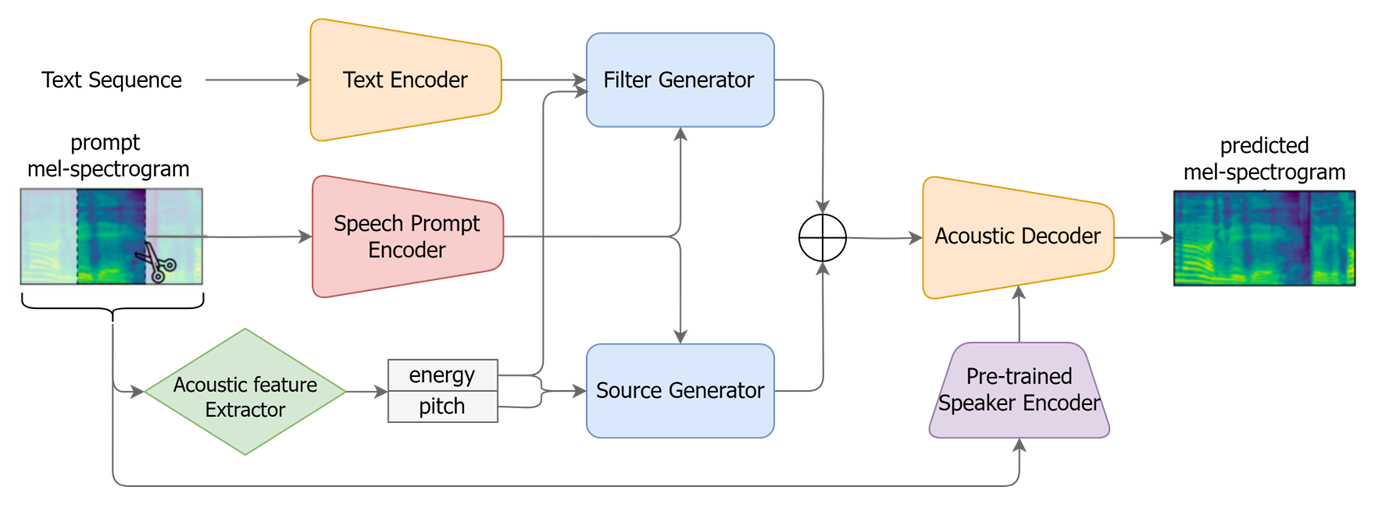
그림 1. MultiVerse TTS 구조도
MultiVerse TTS의 기본 구조 및 특징
MultiVerse-TTS [그림 1]는 인간의 음성 생성 메커니즘을 모사한 소스-필터 이론(source-filter theory) [그림 2]을 기반으로 개발되었습니다. 폐에서 나온 공기가 성대를 진동시켜 발생하는 소스(source)와, 이 음원이 구강과 비강으로 이루어진 필터(filter)를 통과하며 변형되는 과정을 분리하여 모델링하였습니다.
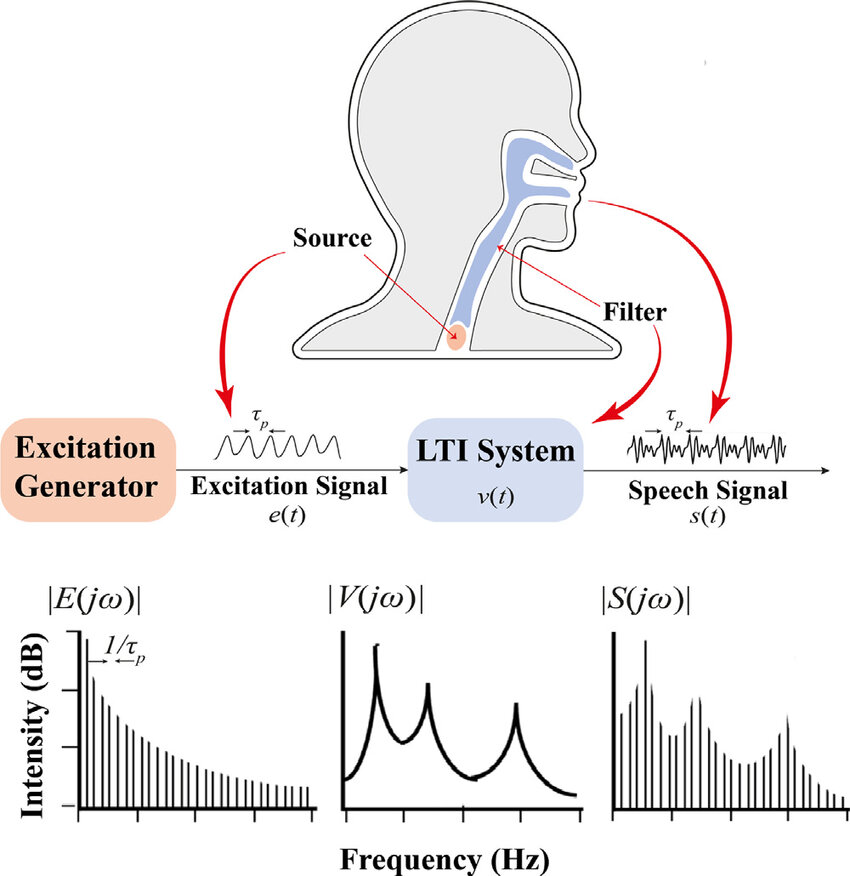
그림 2. 소스 필터 모델 구조도 1
- 소스 (Source) : 성대 진동을 통하여 생성되는 음원을 의미하고 음색, 음고 등의 정보를 담고 있음
- 필터 (Filter) : 구강, 비강 등의 공명기를 통과하여 음원이 변형되는 과정을 모델링하고 발음, 음색의 변화 등의 정보를 담고 있음
기존 TTS 모델의 인코더-디코더와 비교하여, 소스-필터 기반의 모델은 음성의 각 요소를 독립적으로 조절함으로써 음성 스타일 전이 (Style Transfer)에 용이하고 보다 자연스러운 음성을 모델링할 수 있습니다.
하지만, 음성은 음고, 음색, 발음 정보가 굉장히 얽혀있기(entangle) 때문에 소스-필터 모델링하기가 어렵습니다. 이를 해결하기 위하여, 음향 특징 추출기(acoustic feature extractor)를 통해 음성 신호에서 음량(energy)과 음고(pitch) 정보를 추출하여 소스 생성기(source generator)에 입력으로 제공합니다. 학습 시에는 지도 학습 방식으로 실제 음성에서 추출한 값을 사용하고, 생성 시에는 자기 회귀(autoregressive) 모델을 통해 음량과 음고의 시간적 변화를 예측하여 사용합니다.
Speech Prompt Encoder (SPE) 모듈은 음성 데이터 클립에서 화자 임베딩(embedding)을 추출합니다. 추출된 임베딩은 화자의 음색에 대한 국소적인(local) 정보를 담고 있습니다. Pre-trained Speaker Encoder는 음성 데이터를 고정된 차원의 벡터 공간으로 사상(mapping)하여 화자의 전역적인(global) 특징을 포착하여 decoder에 전달합니다. 이렇게 얻어진 정보들을 활용하여, 모델은 사람마다 각기 다른 음색을 더욱 자연스럽게 표현할 수 있습니다. 분리된 결과물을 [그림 3]에서 확인하실 수 있습니다.
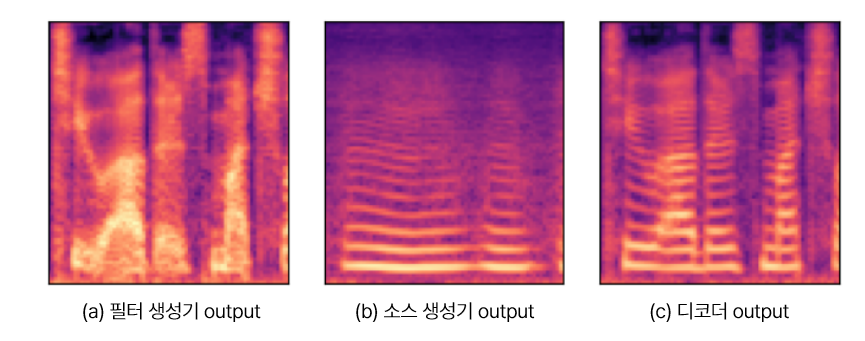
그림 3. MultiVerse TTS의 소스-필터 분리 결과
이어서 MultiVerse TTS의 핵심 기능인 제로샷 TTS (Zero-shot TTS), 교차 언어 TTS (Cross-lingual TTS), 스타일 변환 (style transfer) 기능에 대해 자세히 알아보겠습니다.
MultiVerse TTS 기능 (1) 제로샷 TTS
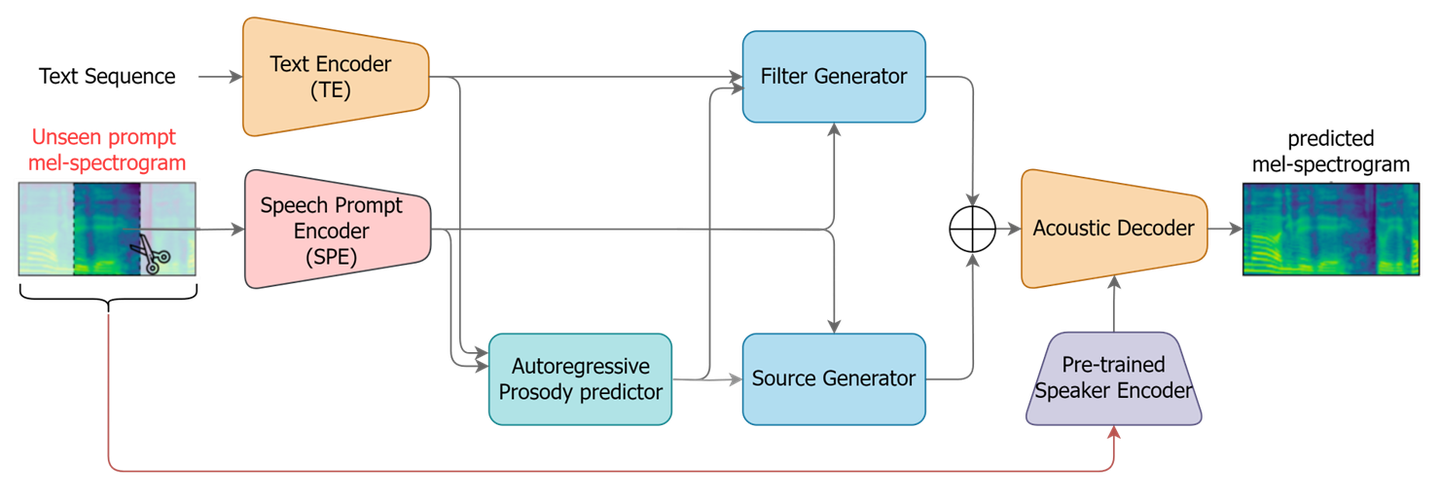
그림 4. 제로샷 시나리오 시, MultiVerse TTS
MultiVerse TTS에서 제로샷 TTS를 수행하는 과정은 다음과 같습니다.
먼저, 새로운 화자의 음성에서 랜덤하게 3초 분량의 음성 클립을 추출하고, 이를 멜-스펙트로그램(mel-spectrogram)으로 변환합니다. 이 멜-스펙트로그램은 음성 프롬프트 역할을 하며, 새로운 화자의 고유한 음색 정보를 담고 있습니다.
다음으로, 생성하고자 하는 문장을 텍스트 인코더에 입력합니다. MultiVerse TTS 학습 시에는 생성하려는 음성과 쌍을 이루는 음성 길이(duration), 음량(energy), 음고(pitch) 정보가 주어지지만, 제로샷 환경에서는 이러한 정보가 없기 때문에 운율 예측기(prosody predictor) 모듈을 사용하여 예측합니다.
MultiVerse TTS에서는 자기 회귀 방식의 운율 예측기 모듈[그림 5]을 사용합니다. 최신 TTS 연구에서는 음성을 병렬적으로 빠르게 생성하기 위하여 비자기회귀(non-autoregressive) 방식의 예측기를 사용하였습니다. 하지만 음성 길이, 음량, 음고는 시간에 따라 연속적인 값을 가지며, 이전 값과 다음 값 사이에 강한 상관관계를 보입니다. 따라서 자동회귀 모델을 사용하여 시간 순서대로 예측하면 비자기회귀 모델 보다 더욱 자연스러운 운율 정보를 얻을 수 있습니다. 실제로 다양한 실험 결과, 자기회귀 모델이 비자기회귀 모델보다 더 나은 성능을 보였습니다. 운율 예측기는 transformer 구조를 기반으로 만들어졌습니다.
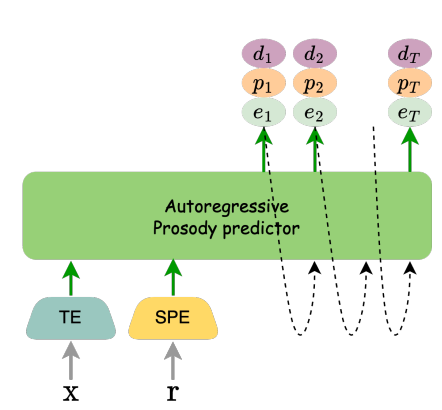
그림 5. 자동 회귀 방식의 운율 예측기
[표 2]는 제안된 MultiVerse 모델과 기존의 GANSpeech+2, YourTTS3 모델의 제로샷 TTS 성능을 다양한 평가 지표를 통해 비교한 결과입니다. 실험에서는 prompt로 사용하는 음성의 스타일 N(Neutral)와 E(Expressive)로 나누어 단조로운 음성과 표현력이 강한 음성에 대하여 테스트하였습니다. GANSpeech+는 다화자 TTS, YourTTS는 제로샷 TTS에서 많이 사용된 모델입니다. Character Error Rate (CER), Word Error Rate (WER), N-MOS를 통해 측정한 발화 정확도를 보면 대체로 GANSpeech+의 성능이 높지만 MultiVerse TTS도 성능이 유사한 것을 볼 수 있습니다.
제로샷 TTS에서는 발화 정확도 뿐만 아니라 타겟 음성의 음색과 생성된 음성의 음색이 유사한지가 가장 중요한 요소입니다. 화자 유사도를 나타내는 SECS (Speaker Embedding Cosine Similarity)와 S-MOS (Similarity Mean Opinion Score)를 비교하면 MultiVerse TTS가 GANSpeech+와 YourTTS 대비 SECS는 각각 평균 14%, 5%, S-MOS는 각각 평균 24%, 11% 성능이 높은 것을 확인할 수 있습니다. 또한 F0 PCC (F0 Pearson Correlation Coefficient), PS-MOS (Prosody Similarity MOS)를 이용하여 화자의 운율 유사도를 확인한 결과 MultiVerse TTS의 성능이 더 우수하다는 것을 확인할 수 있습니다.
이러한 결과는 MultiVerse 모델이 타겟 화자의 음성을 더욱 정확하고 자연스럽게 모방할 수 있음을 의미합니다.
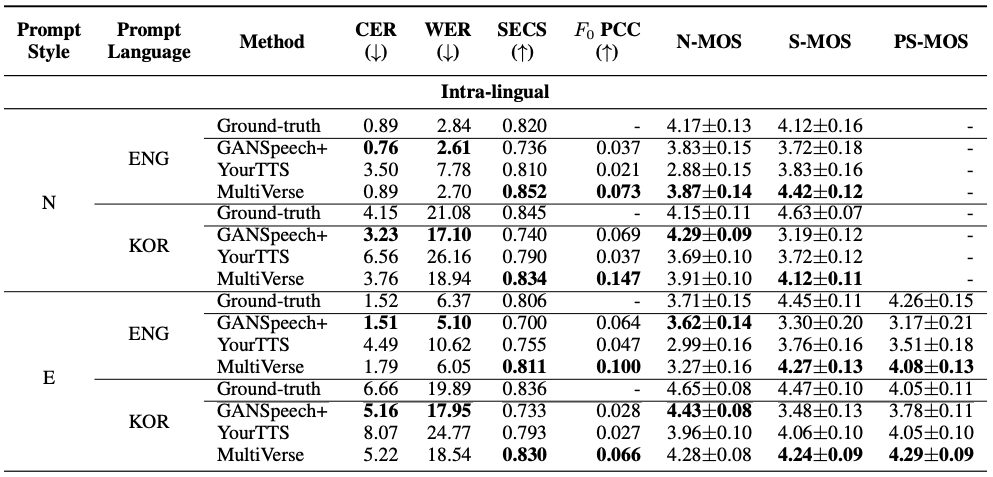
표 2. 제로샷 TTS 성능 비교표
다음은 음성 샘플입니다. 음성 샘플을 들어보면 MultiVerse TTS가 생성한 음성이 정확한 발음과 함께, prompt 음성과 음색 및 운율적으로 더욱 유사함을 알 수 있습니다.
| Prompt | GANSpeech+ | YourTTS | MultiVerse |
|---|---|---|---|
MultiVerse TTS 기능 (2) 교차 언어 TTS
다양한 언어로 자연스러운 음성을 만들기 위해서는 보통 여러 언어를 유창하게 구사하는 사람의 목소리를 확보해야 하고, 각 언어별로 충분한 양의 음성데이터를 수집해야 합니다. 하지만 현실적으로는 그림과 같이 한 가지 언어로만 녹음된 음성 데이터가 훨씬 많습니다. 기존의 다국어 TTS는 이러한 제한된 데이터로 인하여 다양한 언어의 자연스러운 음성을 만들어내기 어려웠습니다. 이러한 문제를 해결하기 위하여 등장한 기술이 바로 교차 언어 생성 모델입니다. 이 모델은 단 한 가지 언어를 구사하는 화자가 음성 데이터가 있어도 다양한 언어의 음성을 만들어 낼 수 있도록 설계가 되어있습니다.
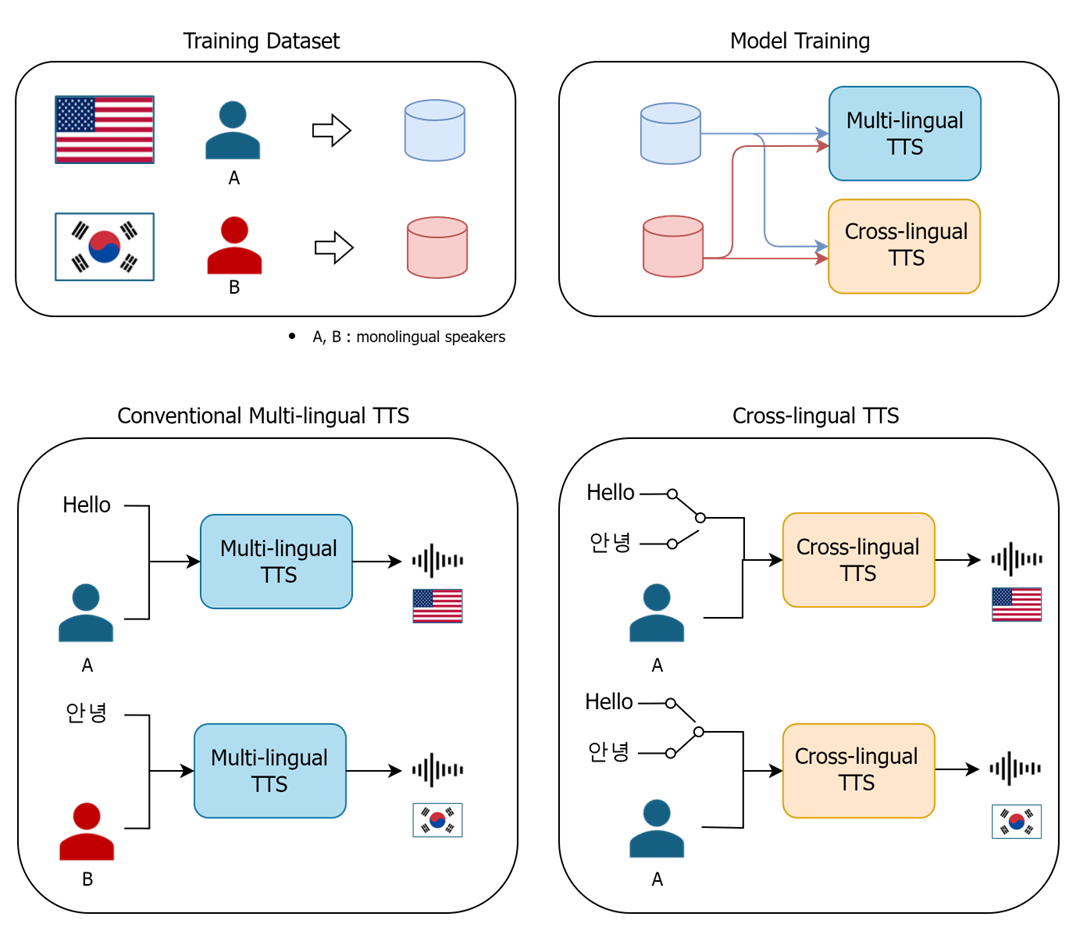
그림 6. 다국어(Multi-lingual) TTS vs 교차 언어(Cross-lingual) TTS
MultiVerse TTS는 소스-필터 이론을 활용하여 발음 정보와 운율 정보를 분리하여 학습하는 독특한 구조를 가지고 있습니다. 학습 시, 각 언어의 음성 데이터를 사용하면 모델은 발음과 관련된 정보를 담당하는 필터 생성기와 운율과 관련된 정보를 담당하는 소스 생성기로 나누어 학습합니다. 예를 들어, 한국어와 영어 음성 데이터로 학습할 경우, 각 언어의 발음 특징과 운율 패턴을 별도로 학습하게 됩니다.
음성 생성 시, 목표 언어의 텍스트를 입력하면 텍스트 인코더는 해당 언어의 문법적, 의미적 정보를 텍스트로부터 추출하여 고차원 벡터로 만듭니다. 필터 생성기는 이 벡터를 바탕으로 목표 언어의 발음 특징을 반영한 필터를 생성합니다. 마찬가지로, 소스 생성기는 입력된 텍스트 정보로부터 목표 언어의 운율 패턴을 반영한 소스를 생성합니다. 최종적으로 생성된 필터와 소스를 결합하여 자연스러운 음성을 만들어 냅니다.
단순한 인코더-디코더 구조로 교차 언어 음성합성을 하면 발음도 부정확하고 운율도 어색한 외국어를 만들어내지만, 분리 모델링을 이용하여 더욱 정확한 발음과 유창한 운율로 음성을 생성할 수 있게 된 것입니다.
제로샷 상황에서의 교차 언어 생성 결과[표 3]을 보겠습니다. GANSpeech+와 YourTTS는 인코더-디코더 구조의 모델입니다. CER, WER 지표를 통해 보면, 제안된 모델이 다른 모델과 비교하여 유사하거나 높은 발음 정확도를 보였습니다. 또한 S-MOS, F0 PCC, PS-MOS 지표를 통하여, 목표 화자의 음색을 잘 유지하면서 외국어를 구사하는 능력이 MultiVerse가 다른 모델보다 높은 것을 보여줍니다. GANSpeech+의 경우, 낮은 S-MOS 지표를 통하여 목표 화자의 음색이 생성 음성에 충분히 반영되지 않는다는 한계를 보였습니다.
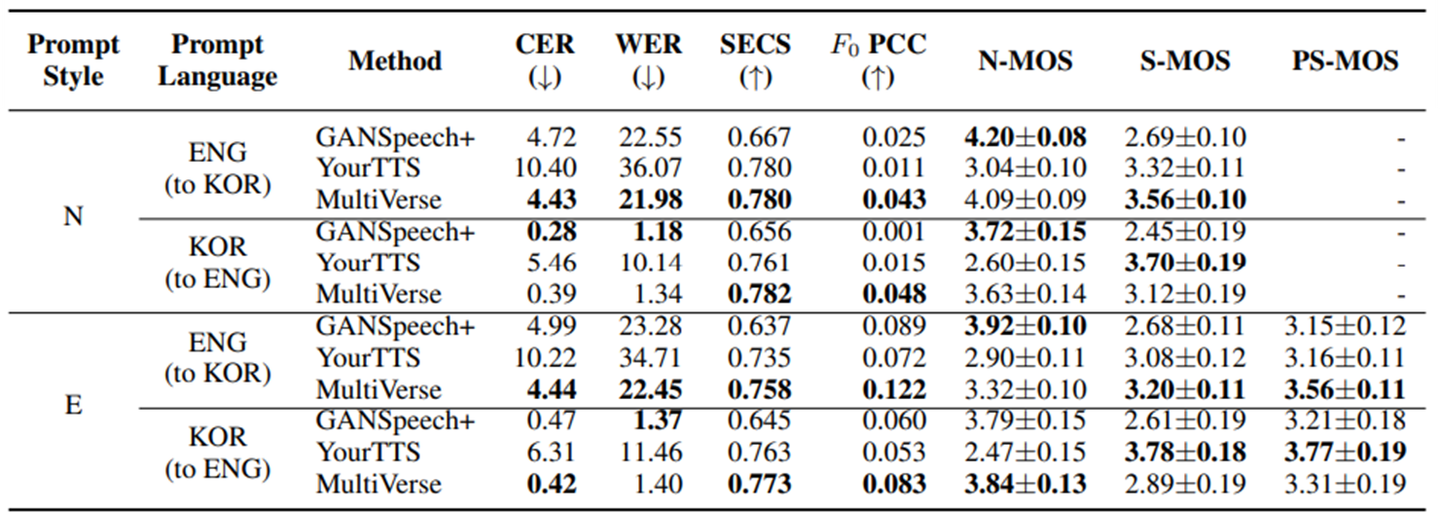
표 3. 교차 언어 TTS 성능 비교표
음성 샘플을 통하여 MultiVerse TTS의 성능을 확인하실 수 있습니다.
| Prompt | GANSpeech+ | YourTTS | MultiVerse |
|---|---|---|---|
MultiVerse TTS 기능 (3) 음성 스타일 변환
스타일 변환 TTS는 특정 화자의 고유한 음색을 유지하면서도 다른 화자의 스타일을 모방하여 새로운 음성을 생성하는 기술입니다. 이를 통해 사용자는 자신의 목소리로 다양한 스타일의 음성을 생성할 수 있습니다. 예를 들어, 자신의 목소리로 에미넴의 래퍼 스타일을 모방하거나, 스칼렛 요한슨의 매력적인 스타일을 재현할 수 있습니다.
MultiVerse TTS에서는 이러한 스타일 변환을 위해 음색과 스타일을 각각 담당하는 두 개의 음성을 prompt로 사용합니다. 예를 들어, A 화자의 음색을 유지하면서 B 화자의 스타일로 말하고 싶을 때, A 화자의 음성을 음색 prompt로, B 화자의 음성을 스타일 prompt로 사용합니다. 스타일 prompt로 입력되는 음성은 SPE 모듈을 거쳐 운율 예측기로 입력되어 스타일에 해당하는 음량(energy)과 음고(pitch)로 변환됩니다. 필터 생성기에는 음량 정보만, 소스 생성기에는 음량, 음고 정보 모두 입력으로 들어갑니다. 음색 prompt로 입력되는 음성은 SPE 모듈을 거쳐 필터, 소스 생성기에 조건으로 들어갑니다.
![]()
그림 7. 스타일 변환 시나리오 시, MultiVerse TTS
앞서 설명했듯, MultiVerse 모델은 소스-필터 모델을 기반으로 하여 발음, 운율을 분리하여 처리합니다. 필터 생성기는 입력된 텍스트 정보를 바탕으로 발음과 관련된 정보를 생성하고, 소스 생성기는 스타일 prompt를 통해 입력된 스타일 정보와 음색 prompt를 통해 입력된 음색 정보를 결합하여 운율과 음색을 생성합니다. 특히, 스타일 prompt는 운율 예측기를 통해 정규화된 피치 정보를 생성하여 상대적인 음고의 높낮이만 모델링 되며, 소스 생성기는 이 정보를 바탕으로 음색을 입혀 최종적인 음성을 생성합니다. 이러한 구조를 통해 음성의 발음, 음색, 운율을 독립적으로 조절할 수 있으므로, 다양한 화자의 음색과 스타일을 자유롭게 조합하여 새로운 음성을 생성하는 데 유리합니다.
[표 4]는 제안한 MultiVerse 모델과 비교 모델인 Daft-Exprt4 와의 스타일 변환 시나리오에서의 성능 비교를 나타낸 표입니다. 스타일 prompt 음성과 동일한 text 내용을 생성하는 same-text task와 그렇지 않은 different-text task로 실험을 진행했습니다. 스타일 변환 시나리오에서는 생성된 합성음이 발화가 정확한지, 화자 prompt와 음색적으로 유사한지, 그리고 스타일 prompt와 운율적으로 유사한지가 중요한 평가 기준입니다. 따라서 앞선 제로샷 TTS 실험과 동일한 CER, WER, SECS, N-MOS 비교와 함께 운율 유사성 비교를 위한 F0 DTW (F0 Dynamic Time Wrapping)과 Dur. RMSE (Duration Root Mean Square Estimation)을 비교했습니다. 결과적으로 비교 모델인 Daft-Exprt보다 모든 task에서 발화 정확도, 화자 유사도, 운율 유사도 측면에서 우세함을 알 수 있습니다. 특히 음소 길이와 발화 정확도 측면에서 크게 우세하며 이에 따라 청취적으로 더욱 자연스러운 합성음을 생성할 수 있었습니다. 이는 앞서 설명했듯이 소스-필터 모델링으로 인해 발화 내용과 음색 및 스타일을 분리하는 데 유리한 MultiVerse의 특성을 잘 보여줍니다.
![]()
표 4. 스타일 변환 성능 비교표
음성 샘플을 통하여 MultiVerse TTS의 성능을 확인하실 수 있습니다.
| Timbre Prompt | Style Prompt | Daft-exprt | MultiVerse |
|---|---|---|---|
제한된 리소스 내에서의 MultiVerse TTS 활용성
일반적으로 제로샷 TTS 모델을 학습하기 위해서는 많은 분량의 데이터가 필요합니다. 그 이유는 음성은 발음, 음색, 운율 정보가 강하게 얽혀 복잡한 분포를 가지고 있기 때문에, 많은 양의 데이터를 활용하여 일반화된 잠재 표현을 학습해야 하기 때문입니다. MultiVerse TTS는 이러한 문제를 해결하기 위하여 [그림 1]과같이 두 개의 화자 임베딩과 음량, 음고 정보를 모듈에 적절히 주입하는 방식을 택했으며, 특히 decoder에서는 sample-adaptive kernel selection을 이용하여 화자 정보 조건으로 효율적이면서도 다양한 분포를 학습할 수 있도록 설계하였습니다[그림 7].
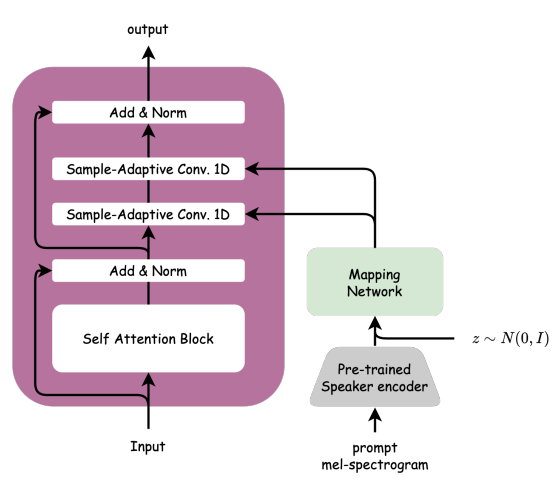
그림 7. MultiVerse TTS에서의 sample-adaptive kernel selection
최근 소개되는 많은 제로샷 TTS 모델들, Mega-TTS5, NaturalSpeech26, Voicebox7 는 각각 대략 20,000시간, 44,000시간, 60,000시간의 데이터를 사용했습니다. 하지만 제안한 MultiVerse TTS는 약 1,000시간 (~1k hour)에 해당하는 데이터만으로 훈련되었음에도 불구하고, 다른 large-scale 모델들과 비교했을 때 발음 정확도, 음색 유사도, 운율 유사도 측면에서 comparable한 성능을 보이는 것을 확인할 수 있습니다.[표 5]
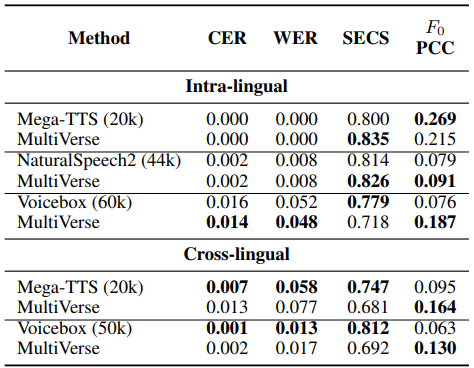
표 5. Data-driven 모델과의 성능 비교
마치며
이 글에서는, MultiVerse TTS 모델을 소개하였습니다. MultiVerse TTS는 하나의 프레임워크를 이용하여 제한된 데이터 환경에서도 다양한 음색과 스타일의 고품질 음성을 생성하였고, 다국어 지원이 가능함을 보였습니다. 각 캐릭터마다 개성 있는 음성이 필요한 MMORPG 등의 게임에 MultiVerse TTS가 활용된다면, 게임 개발 기간 단축과 비용 절감에 크게 기여함으로써, 게임 개발의 유연성을 높이고 사운드 센터의 아티스트들이 더욱 창의적인 작업을 수행할 수 있도록 도와줄 수 있을 것으로 기대하고 있습니다.
오디오 AI Lab은 MultiVerse TTS와 같은 기술 연구를 통하여 게임 산업 전반에 걸쳐 사운드 제작 파이프라인을 혁신하고, 콘텐츠의 질적 수준을 향상하는데 기여하고자 합니다. 앞으로도 지속적인 연구를 통해 더욱 정교하고 자연스러운 음성 생성 기술을 개발하고, 이를 다양한 게임 장르에 적용하여 게이머들에게 더욱 몰입감 넘치는 경험을 제공하고자 노력할 것입니다.
참고 문헌
-
Almaghrabi, Shaykhah A., Scott R. Clark, and Mathias Baumert. “Bio-acoustic features of depression: A review.” Biomedical Signal Processing and Control 85 (2023): 105020. ↩
-
Yang, Jinhyeok, et al. “GANSpeech: Adversarial training for high-fidelity multi-speaker speech synthesis.” arXiv preprint arXiv:2106.15153 (2021). ↩
-
Casanova, Edresson, et al. “Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone.” International Conference on Machine Learning. PMLR, 2022. ↩
-
Zaïdi, Julian, et al. “Daft-Exprt: Cross-speaker prosody transfer on any text for expressive speech synthesis.” arXiv preprint arXiv:2108.02271 (2021). ↩
-
Jiang, Ziyue, et al. “Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias.” arXiv preprint arXiv:2306.03509 (2023). ↩
-
Shen, Kai, et al. “Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers.” arXiv preprint arXiv:2304.09116 (2023). ↩
-
Le, Matthew, et al. “Voicebox: Text-guided multilingual universal speech generation at scale.” Advances in neural information processing systems 36 (2024). ↩
