
작성자
- 이호엽 (VARCO 서비스실)
이런 분이 읽으면 좋습니다!
- 게임과 인공지능을 모두 좋아하는 분
- 생성형 AI가 아닌 AI도 게임에 기여할 수 있다고 생각하는 분
이 글로 알 수 있는 내용
- 추천 모델이 게임 플레이에 기여하는 방법
들어가기
2016년, 인공지능 분야에서 가장 큰 화제는 이세돌과 딥마인드(Deepmind)가 만든 인공지능 바둑 프로그램 “알파고(AlphaGo)”의 대결이었습니다. 당시에 저도 이세돌과 알파고 중 누가 이길 것인가에 대해서 주변 지인들과 내기했던 기억이 있습니다. 저는 ‘알파고가 이긴다’에 한 표를 걸었지만, 제 주변을 비롯한 많은 언론에서는 아직 바둑은 수많은 경우의 수를 고려해야 하므로 해당 시점에는 사람이 우세할 것이라는 예상이 대다수였습니다. 하지만, 실제 결과는 이세돌과 알파고는 1:4로 알파고가 압도적으로 우세했습니다. 예상하지 못한 결과 때문이었는지, 이세돌과 알파고 대결의 결과는 우리에게 더 큰 충격으로 다가왔습니다. 이세돌과 알파고 대결 이후, 많은 언론에서는 인공지능이 사람의 일자리를 대체하여 사람의 입지가 좁아질 것이라는 내용의 기사가 많이 쏟아졌습니다. 하지만 지금까지도 인공지능이 사람의 일자리를 대체한 분야는 매우 제한적인 것으로 보아 사람이 할 일이 아직 많이 남아있는 것 같습니다. 🙂
최근에는 알파고와 같이 사람과의 대결에 초점을 맞춘 인공지능 대신, 사람의 의사결정을 돕는 연구도 많이 진행되고 있는 것 같습니다. 사람을 대체하는 인공지능이 아닌, 사람과 함께하는 인공지능을 연구하고 있는 것이죠. 이번 글에서는, 사람이 게임을 할 때 도움을 주는 인공지능과 관련된 연구를 소개해 드리려고 합니다.
인공지능이 게임 플레이에 도움이 될 수 있다고?
어렸을 때의 기억을 되살려 봅시다. 저는 어렸을 적 포켓몬스터 골드를 플레이하다가 막히면 공략법을 찾아보곤 했습니다. 동네 친구들 사이에서 구전되는 공략법도 있었지만, 대부분은 인터넷을 찾아보며 어려운 단계를 공략해 나갔습니다. 하지만, 흔히 떠올릴 수 있는 공략법은 포켓몬스터 골드와 같이 정해진 스토리를 따라가는 RPG(Role-Playing Game) 환경에는 적합하지만, 스타크래프트와 같이 실시간으로 상황이 변화하는 RTS(Real-Time Strategy) 환경일 때는 그다지 효과를 발휘하지 못했습니다. 예나 지금이나 똑같지만, 대부분의 RTS나 MOBA(Multiplayer Online Battle Arena) 게임에서는 일명 뇌지컬뿐만 아니라 피지컬도 중요하기 때문이죠. 이런 이유 때문인지, RTS와 MOBA 게임에서는 뇌지컬을 도와주는 프로그램 대신 피지컬을 도와주는 불법 프로그램들이 만들어졌습니다. 일반적으로 널리 알려진 일명 ‘핵’ 프로그램이 바로 위에서 언급한 피지컬을 도와주는 프로그램입니다.
불법적인 핵 프로그램 대신, 플레이어의 실시간 의사결정(일명 뇌지컬)을 도와주는 인공지능 프로그램도 있을까요? 네, 있습니다. 바로 이 글에서 다룰 주제입니다. 이제부터 소개해드릴 내용은 칠레의 Parra 교수 연구팀이 MOBA 게임으로 대상으로 시리즈로 진행한 연구들입니다. 혹시 MOBA 게임에 대해서 생소하신 분들을 위해서 차근차근 알아봅시다.
MOBA 게임 소개
MOBA(Multiplayer Online Battle Arena) 게임은 영문 본말에서 알 수 있듯이, 한 전장에서 다수의 플레이어가 각기 다른 캐릭터를 플레이하며 상대 팀과 대전하는 장르의 게임입니다. 해당 장르의 대표적인 게임으로는 Riot Games 사의 리그 오브 레전드가 있습니다. 해당 게임에서는 각각 다섯 명으로 구성된 빨강팀과 파랑팀 중에서 상대 팀의 넥서스를 먼저 파괴하는 팀이 승리하게 됩니다.
MOBA 게임에서 플레이어들은 게임 안의 재화 보상 체계를 통해 재화를 획득할 수 있으며, 플레이어는 획득한 재화를 기반으로 아이템을 구매하여 캐릭터의 능력치를 향상시켜 상대방과의 격차를 이용해 (일명 스노우볼을 굴림으로써) 승리에 다가가게 됩니다. 게임 내에서 각 플레이어는 200여 개가 넘는 아이템 중 최대 6개의 아이템을 선택하여 구매할 수 있습니다. 몇몇 아이템은 합쳐져서 새로운 아이템이 되기도 하며, 더 이상 합쳐질 수 없는 최종 아이템은 90여 개가 있습니다.
이런 상황에서 플레이어는 나의 캐릭터뿐만 아니라 상대방의 캐릭터를 고려하여 상황에 맞는 아이템을 구매하여 승리에 기여해야 합니다. 바로 이 지점에 앞으로 소개해 드릴 세 개의 연구의 포인트가 있습니다. MOBA 게임에 익숙하지 않은 플레이어는 어떤 아이템이 현재 상황에 적합한지 구매 의사결정을 하기 어렵습니다. Parra 교수 연구팀에서도 이런 초보 플레이어의 어려움을 해소하기 위해 아래와 같은 연구를 진행하였습니다.
Item Recommendation in MOBA Games
가장 먼저 소개해 드릴 연구는 2019년 RecSys라는 유명한 학회에 발표된 논문입니다. 해당 연구는 MOBA 게임에 아이템 추천을 소개한 초기 연구로써, 비교적 단순한 추천을 진행하였습니다. 그림 1은 해당 논문에서 진행한 방법론의 대략적인 구조를 보여주고 있습니다. 그림의 가장 왼쪽에서 빨강팀과 파랑팀에 속한 플레이어들이 어떤 캐릭터(=챔피언)를 선택했는지 알 수 있습니다. 가운데에는 어떤 대상 캐릭터에 대해서 추천을 진행할지, 그리고 가장 오른쪽에는 추천 아이템 목록이 표시되어 있습니다. 즉, 이 논문에서는 대상 캐릭터와 상대 팀의 캐릭터 정보를 기반으로 승리를 위해서는 어떤 아이템을 선택해서 플레이해야 하는지 플레이어에게 추천하면 좋을지에 대한 모델 개발을 진행했습니다.
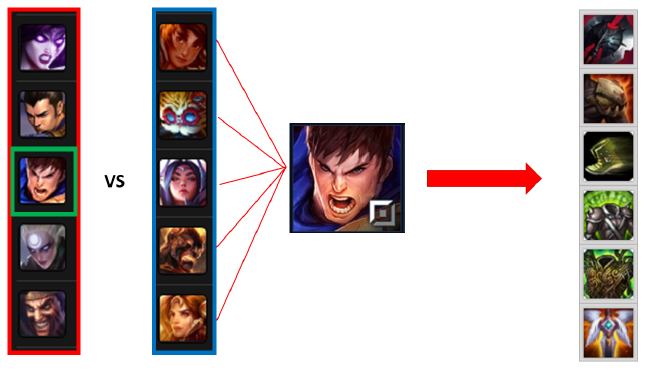
그림 1. MOBA 게임에서 한 캐릭터가 선택되었을 때의 아이템 추천 (출처: 참고 자료 1)
아무래도 MOBA 게임에서 대상 캐릭터의 아이템 추천과 관련된 초기 논문인 만큼, AI/ML 분야의 고전적인 방법인 연관 규칙(Association Rule)을 통한 추천과 의사 결정 나무(Decision Tree), 로지스틱 회귀분석(Logistic Regression), 인공신경망(Artificial Neural Network) 모델에 대한 결과를 보여주었습니다. 모델을 구성할 때는 대상 캐릭터와 상대 팀의 다섯 명의 캐릭터 정보를 기반으로 90여 개의 최종 아이템 중 여섯 개를 예측하도록 했습니다. 총 여섯 개의 아이템을 예측하기 때문에, 인공신경망 모델의 경우에는 가장 마지막 레이어에서 소프트맥스(Softmax) 함수 대신 시그모이드(Sigmoid) 함수를 사용하였으며, 손실함수(Loss function)로는 이진 크로스 엔트로피(Binary Cross-entropy) 함수를 사용했습니다. 결과는 여러분들이 직접 논문을 찾아보시면 좋을 것 같습니다. 아마 여러분들의 예상과 크게 다르지 않을 거예요.😀
TTIR 모델
다음으로 소개해 드릴 연구는 2020년 RecSys에 소개된 TTIR(Transformer for Team-aware Item Recommendation)이라는 모델입니다. 이번 연구에서는 이전 연구보다 더 발전된 모습을 보여주고 있습니다. 인공신경망 모델과 같은 인공지능 모델은 일반적으로 블랙박스 모델(black-box model)이라고 알려져 있습니다. 즉, 게임에서의 추천 모델도 일반적으로 왜 추천이 이루어졌는지 알기 어렵죠. 하지만, 플레이어는 실시간으로 어떤 아이템을 추천받거나, 전략을 추천받았을 때 직관적으로 이해되지 않으면 추천 기능을 사용하지 않게 될 것입니다. 이 논문이 바로 이런 점을 극복하기 위해서 제안되었다고 생각하시면 됩니다.
그림 2는 TTIR 모델의 구조를 보여주고 있습니다. 가장 먼저 눈에 띄는 것은 이전 모델과 달리 같은 팀에 속한 캐릭터도 입력받고 있다는 점입니다. 또한, 캐릭터의 역할 정보와 팀 정보도 함께 포함하여 아이템을 추천하기로 한 점도 눈에 띕니다. 이전 모델보다 MOBA 게임 속 상황에 대해서 더 많이 고려하고 모델을 만들었다는 것이 느껴지는 대목입니다. 이외에도, 각 캐릭터 정보를 트랜스포머(Transformer) 인코더로 임베딩하며, 대상 팀(그림에서는 오른쪽 파랑팀)의 모든 캐릭터의 아이템을 추천한다는 점도 기존과 다른 점입니다. 논문에서는 트랜스포머 인코더를 사용하여 캐릭터의 임베딩을 계산함으로써, 위에서 언급한 추천 결과를 직관적으로 이해하기 어렵다는 기존 모델의 단점을 극복할 수 있다고 소개하고 있습니다. 트랜스포머는 번역을 위해 처음 제안된 방법인데, 번역할 때 어텐션(Attention)을 기반으로 어느 부분을 중점적으로 보고 번역을 진행했는지 알 수 있도록 구조가 설계되어 있습니다(2). 이런 점을 TTIR 모델에서도 활용하여, 캐릭터의 임베딩을 계산할 때 어떤 캐릭터에 근거하여 임베딩이 계산되었는지 어텐션을 통해 직관적으로 알 수 있도록 했습니다. 이런 트랜스포머 인코더의 특성을 통해서 저자들은 플레이어가 추천받은 아이템에 대한 이유를 쉽게 유추할 수 있다고 합니다.
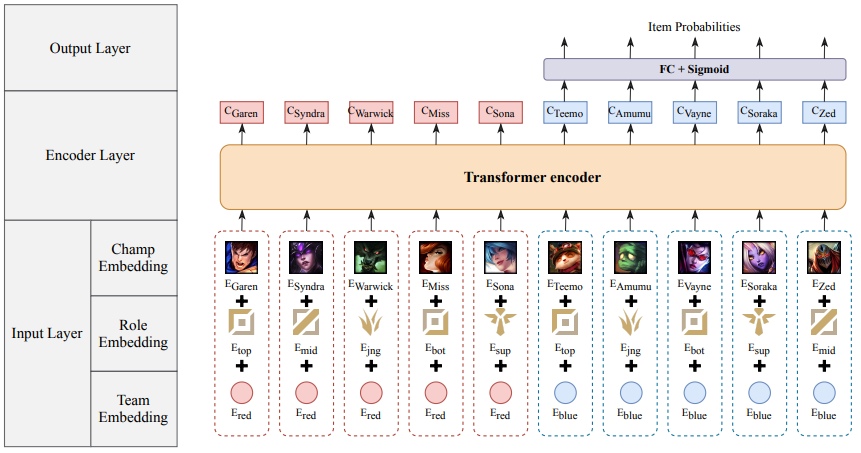
그림 2. TTIR 모델 구조도 (출처: 참고 자료 3)
아래 그림은 모델을 통해서 파랑팀에 속한 캐릭터들의 아이템을 예측한 결과입니다. 그림의 가장 오른쪽을 보면 TTIR 모델이 다섯 명의 캐릭터에 대해서 위에서 언급한 특성을 고려하여 여섯 개의 아이템을 추천하고 있습니다. 시즌 7을 플레이하셨던 독자분은 해당 아이템이 맞게 추천되었는지 기억을 더듬어보시면 좋을 것 같습니다. 🙂 추가로, 왼쪽에 히트맵 형태로 표시된 어텐션도 확인해 보시면 좋을 것 같습니다. 색이 진할수록 중요도가 높고, 색이 연할수록 중요도가 낮은 것을 의미합니다. 이를 통해서 알 수 있는 것은, TTIR 모델은 같은 팀의 캐릭터보다 상대 팀의 캐릭터를 더 중요하게 고려하고 아이템을 선택하도록 한다는 점입니다. 실제 게임을 플레이 할 때도, 캐릭터 자체보다는 상대 캐릭터가 누구인지 고려하고 플레이하는 걸 감안해볼 때, TTIR 모델이 꽤 괜찮은 모델이라고 생각합니다.
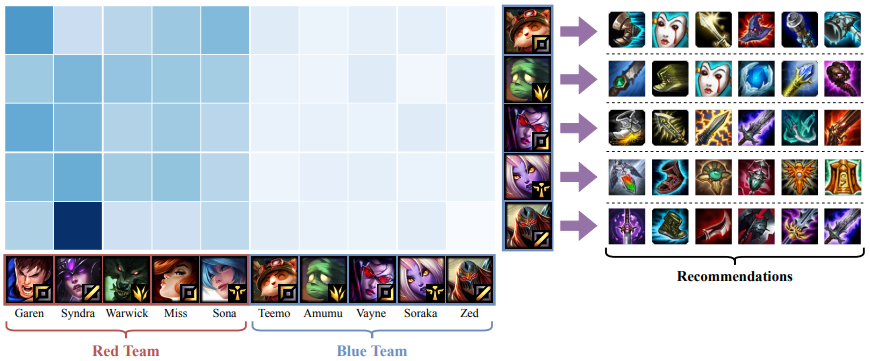
그림 3. TTIR 모델 추천 결과 및 어텐션 (출처: 참고 자료 3)
HT4Rec 모델
마지막으로는 2022년 UMAP이라는 학회에서 소개된 논문을 소개해 드리겠습니다. 이 논문을 끝으로 Parra 교수 연구팀에서는 관련 논문이 나오고 있지 않습니다. 이후 관련 논문이 나올 수도 있으니 궁금하신 분들은 구글 스칼라를 팔로우하셔도 좋을 것 같습니다.
이 논문에서 소개하고 있는 HT4Rec(Hierarchical Transformers for Sequential Recommendation)이라는 방법이 이전 논문에서 소개된 방법들과 가장 다른 점은, 같은 팀뿐만 아니라 상대 팀이 소지하고 있는 아이템을 고려하여 대상 캐릭터가 다음에 구매하면 좋을 아이템을 추천한다는 점입니다. 그림 4를 보시죠. 해당 그림에서 좌측에는 상대 팀의 캐릭터들과 소지한 아이템을 나타내고 있습니다. 중간에는 같은 팀의 캐릭터와 소지한 아이템을 보여주고 있습니다. 그림의 우측에는 대상 캐릭터가 다음에 구매하면 좋을 아이템을 나타내고 있습니다. 즉, 기존에 게임이 시작할 때 모든 아이템을 추천해 주는 것과 달리, HT4Rec 모델은 상대 팀이 결정한 아이템을 바탕으로 시시각각 대응할 수 있는 모델인 것입니다. 저도 MOBA 게임을 플레이할 때 상대방이 어떤 아이템을 선택했는지에 따라서 아이템을 선택하곤 했는데, 이 논문에서 제안하고 있는 모델이 실제 플레이어의 특성을 반영하고 있는 것입니다.
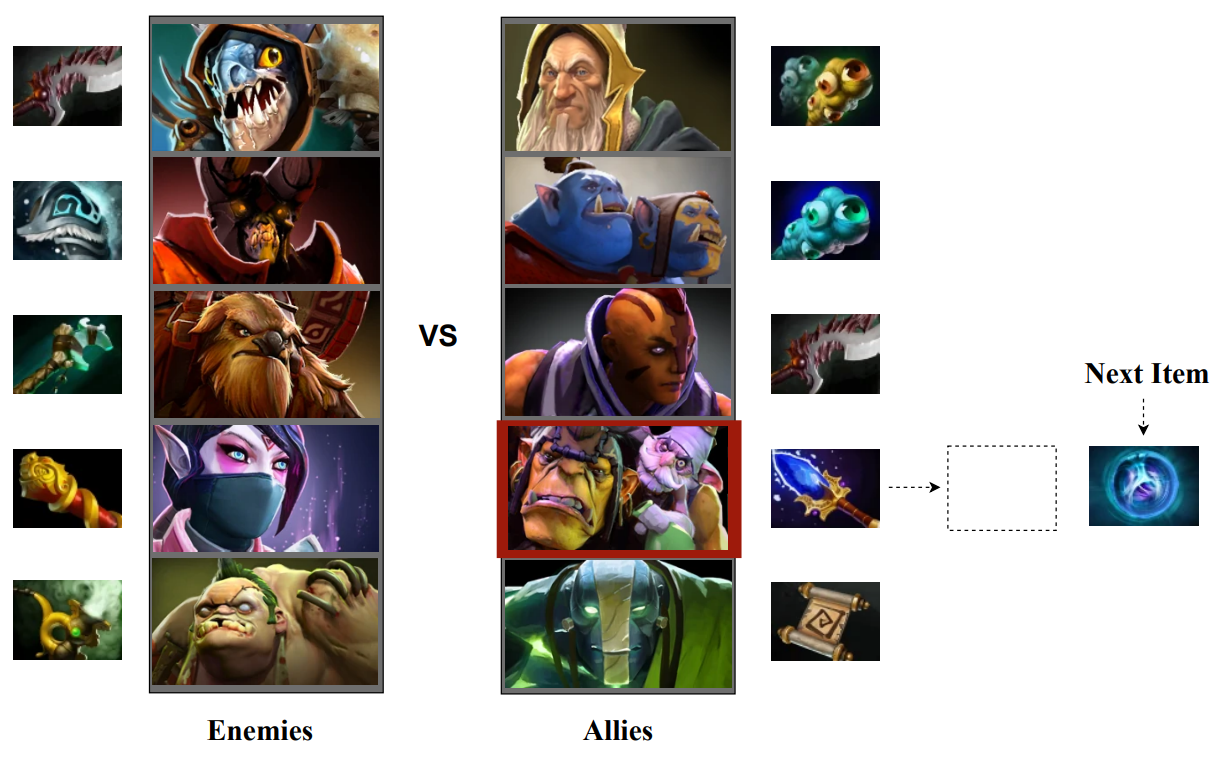
그림 4. HT4Rec 모델의 입력과 출력 (출처: 참고 자료 4)
논문에서는 플레이어의 이런 특성을 반영하기 위해서 그림 5와 같은 모델을 제안했습니다. 이 모델은 노란색과 파란색 박스로 표시된 하단과, 주황색과 초록색, 그리고 보라색으로 구성된 상단을 나누어서 살펴보겠습니다. 먼저, 하단에서 노란색 박스로 표시된 부분에서 (좌측) 상대 팀의 캐릭터($u$)와 각각의 아이템 정보($v$), (중간) 같은 팀의 캐릭터($u$)와 각각의 아이템 정보($v$), 그리고 (우측) 대상 캐릭터($u$)와 아이템 정보($v$)를 입력으로 받는다는 것을 알 수 있으며, 파란색 박스로 표시된 부분에서 트랜스포머 인코더를 통해 해당 정보를 입력한다는 것을 알 수 있습니다. 여기까지는 TTIR과 조금은 다르지만 유사한 모습입니다.
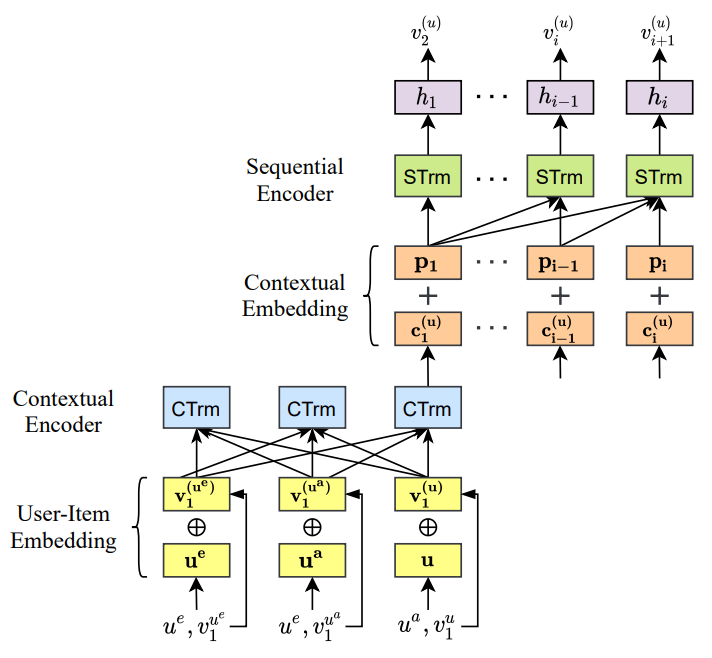
그림 5. HT4Rec 모델 (출처: 참고 자료 4)
이제는 이전과는 많이 달라진 상단을 살펴봅시다. 상단에서는 대상 캐릭터의 임베딩만을 입력받아서 어떤 아이템을 순서대로 구매해야 하는지 추천하는 모델을 구성했습니다. 화살표의 방향을 보시면 아시겠지만, 하단에서 양방향으로 뻗은 화살표와 달리, 상단에서는 왼쪽에서 오른쪽으로만 화살표가 그어져 있는 점이 눈에 띕니다. 논문 저자들은 이후에 구매한 아이템이 이전에 구매한 아이템의 의사 결정에 영향을 끼치지 않도록 위와 같이 구성한 것 같습니다. 또한 상단에서는 포지션 임베딩($p$)을 추가하여 캐릭터의 아이템 구매 순서를 추천하도록 했습니다. 상단과 하단을 종합해서 생각해 보면, HT4Rec은 상대 팀, 같은 팀, 그리고 대상 캐릭터와 각각의 아이템 정보를 입력받아, 대상 캐릭터의 임베딩을 계산한 뒤, 해당 정보를 바탕으로 구매 아이템을 순서대로 추천해 줍니다. 처음 모델을 돌이켜 생각해 볼 때, 더 많은 정보를 모델의 입력으로 넣고 플레이어들의 성향을 더 많이 고려함으로써, 아이템 추천이 기존보다 훨씬 더 많이 고도화되었네요. 특히, 논문에서는 HT4Rec이 추천 성능 관점에서 이전보다 매우 많이 향상된 것을 보여주고 있는데, 관심 있으신 분들은 얼마큼 향상되었는지 기대하시면서 논문을 찾아보셔도 좋을 것 같습니다.
마무리하며
이 글에서 설명해 드린 다양한 아이템 추천 알고리즘이 실제로 게임을 플레이할 때 적용되면 플레이어가 해야 하는 매 순간의 의사 결정을 많이 줄여주어 도움이 될 것 같다는 생각이 듭니다. 소개해 드린 논문에서 실시간성에 대한 얘기가 별도로 없는 것으로 보아 아직은 더 발전의 여지가 있어 보입니다. 그래도 머지않은 미래에는 피지컬을 도와주는 핵 대신, 뇌지컬을 도와주는 AI가 게임 속에 탑재되지 않을까 기분 좋은 상상을 해봅니다.
이런 관점에서 몇 년 전 레고 코리아 대표인 마이클은 한국에서 레고의 경쟁자는 한국의 교육 시스템이라고 인터뷰한 것이 생각납니다. 아이들이 교육에 시간을 쏟기 때문에 놀이에 쓸 시간이 없다는 점 때문이겠죠. 이런 이유로, 마이클은 장난감 시장 내에서의 치열한 경쟁이 아닌, 장난감 시장이 교육 시스템이라는 다른 시장과 경쟁하여 성장하는 것이 레고코리아가가 성장할 수 있는 방법이라고 생각했던 것 같습니다. 저는 이 블로그를 준비하면서 엔씨소프트도 비슷한 것 같다고 생각했습니다. 게임사의 경쟁자는 다른 게임사가 아닌 유튜브와 넷플릭스 같은 동영상 플랫폼을 경쟁자로 생각할 수 있지 않을까요? 사람들이 동영상 플랫폼에서 소비하는 시간이 많아짐에 따라 게임 플레이 시간이 줄어든 것은 아닐지 조심스럽게 추측해봅니다.
플레이어들이 게임으로 돌아오도록 하기 위해서 이 글에서 소개해 드린 것과 같이 게임 플레이를 도와주는 인공지능을 만드는 것도 한 방법이 될 것입니다. 저는 요즘 게임이 점점 더 고도화되면서 플레이어들이 재미를 느끼기 위한 진입 장벽이 다소 높아졌다고 생각합니다. 이렇게 높아진 재미의 진입 장벽을 인공지능이 낮춰줄 수 있다면, 플레이어들이 더 쉽게 재미를 느끼지 않을까요? 물론, 인공지능을 개발할 때 “게임은 결국 본인이 플레이하는 것”임에 입각해야겠지요. 플레이어가 게임 공략에 대한 고민과 탐색의 시간을 줄여줄 수 있도록, 플레이어와 함께하는 인공지능에 대한 탐구를 지속하겠습니다. 🙂
참고 자료
-
Araujo, V., Rios, F., & Parra, D. (2019). Data mining for item recommendation in MOBA games. In Proceedings of the 13th ACM Conference on Recommender Systems. ↩
-
https://jalammar.github.io/illustrated-transformer/ ↩
-
Villa, A., Araujo, V., Cattan, F., & Parra, D. (2020). Interpretable contextual team-aware item recommendation: application in multiplayer online battle arena games. In Proceedings of the 14th ACM Conference on Recommender Systems. ↩ ↩2
-
Araujo, V., Salinas, H., Labarca, A., Villa, A., & Parra, D. (2022) Hierarchical Transformers for Group-Aware Sequential Recommendation: Application in MOBA Games. In Adjunct Proceedings of the 30th ACM Conference on User Modeling, Adaptation and Personalization. ↩ ↩2
