
- TL;DR
- 도입
- 하나만 만들지 왜 고민을 사서 하는가: 선택지가 많아지는 이유
- 군계일학 찾기: 언어모델 줄 세우기 (벤치마킹)
- 우리가 제안하는 솔루션: VARCO Arena
- 마치며
- References
작성자
- 손선일 (텍스트AI Lab)
- LLM 튜닝과 평가 관련 업무를 맡고 있습니다.
이런 분이 읽으면 좋습니다!
- (LLM 이전 시대 NLG 라는 단어가 사용되던 그 때) 생성문 평가 방법론에 대해 관심가져본 적 있는 분
- LLM 순위는 어떻게 매기는지 알고 싶은 분
- LLM Fine-tuning 후 모델 선정 / prompt engineering / decoding parameter 선정 등, LLM을 활용하기 위해 한 번이라도 학습 이후의 선별과정을 겪어보신 분
이 글로 알 수 있는 내용
- 사람들은 LLM 들의 순위를 어떤 식으로 정하고 있는지
- VARCO Arena: 토너먼트를 통해서 기준 생성문 없이 모델들을 줄 세우는 방법
TL;DR
언어 모델을 개발하다 보면 미세한 차이를 지닌 여러 모델을 비교해야 하는 상황이 자주 발생합니다. 이런 비교 과정은 시간과 노력이 많이 들며, 때로는 새로운 테스트 시나리오를 추가해야 할 때도 있습니다.
이러한 문제를 해결하기 위해 저희는 VARCO Arena라는 reference-free 벤치마킹 프레임워크를 개발했습니다. 이 도구는 모범답안 없이도 언어 모델들의 성능을 평가하고 순위를 매길 수 있어, 비교 과정을 크게 간소화합니다.
도입

안녕하세요, 손선일입니다. 남의 것 소개 안하고 저희가 만든(!) 오리지널 컨텐츠로 다시 만나뵙게 되어 반갑습니다. 언제 볼지 모른다고 생각했는데 그새 1년이 지났네요 :0 저번에는 LLM 바람이 어디서부터 불어왔는지, 그리고 이것들을 가볍게(?) 사용하게 하는 PEFT에 대해 리뷰하는 2편의 포스트를 투고했었습니다.
- Large Language Model을 밀어서 잠금해제: Parameter-Efficient Fine-Tuning 1
- Large Language Model을 밀어서 잠금해제: Parameter-Efficient Fine-Tuning 2
오늘은 “내가 갓 구운 LLM이 얼마나 잘하는지” 등수 매겨주는 벤치마킹 시스템, VARCO Arena [바르코 아레나] 를 개발하여 여러분께 소개드릴겁니다. VARCO Arena는 LLM 이상형 월드컵(들)을 통해서 “최애의 LLM”을 뽑아주며 1등이 아닌 다른 순위들 (e.g. 2, 3, 4, 5등…) 도 결과로 제공합니다. 최애만 뽑는 게 아니라 어떤 다른 참가자들의 순위도 함께 제공한다는 점 기억해주세요. 자 그럼 시작해봅시다.
하나만 만들지 왜 고민을 사서 하는가: 선택지가 많아지는 이유
이해를 돕기 위해서 그려봤습니다. 맨 아래가 항상 원본 보다 낫다는 보장이 없겠죠? ^ㅡ^
선택지가 없으면 고민할 것도 없습니다. 하나의 LLM만 잘 만들어서 그걸 쓰면 될텐데 왜 고민을 할까요? 안타깝게도, LLM을 개선하는 많은 방법들은 모든 것들을 순차적으로 적용할 수 있는 것도 아니고, 모든 것들이 상호 보완적이지도 않습니다. 그러니까 곧 하나의 잘 만든 LLM을 위해서 수 많은 선택이 필연적으로 뒤따릅니다. 예를 들어, 어떤 사용처에 맞추어 LLM을 개발하기로 했다고 생각해봅시다. 먼저 우리는 사전학습만 된 모델부터 시작할지, 지시문 학습 (instruction tuning) 된 모델로부터 시작할지부터 고민해야합니다. 그리고 그것을 미세조정 할지 말지, 데이터는 어떤 걸 쓸지, 학습은 어떻게 할지, 얼마나 할지 그리고 만약에 이걸 다 거친 후에는 어떻게 프롬프팅 할지, 추론시 파라미터는 뭘 줄지… 끝도 없는 선택의 향연입니다. 이런 선택지를 개략적으로 표로 그려보면 아래와 같습니다.
| 단계 | 선택지 |
|---|---|
| 모델 선정 | • 사전학습된 된 모델로부터 시작하기 • Instruction Tuning 된 모델로부터 시작하기 |
| 데이터 선정 및 구성 | • 수행하려는 작업의 데이터 (e.g. 계약 번역) 만 쓸지 • 연관성 있는 데이터도 추가해서 쓸지 (e.g. 일반 번역) • 합성된 데이터를 포함할지, 얼마나 포함할지 |
| 학습 과정 | • Post-training을 할지 • 어떤 loss를 쓸지 • 하이퍼파라미터 선정 (e.g. lr, scheduling, loss coefficient, training steps…) |
| 프롬프팅 | • 어떻게 물어봐야 더 잘에 드는 답이 나오는지 • 여러 단계를 거쳐서 최종 출력을 낼지 |
| 디코딩 | • 디코딩 전략 선택 • 정량적 샘플링 파라미터 (온도, 길이 페널티, min_p, top_p 등) |
위의 단계별로 2가지씩만 선택지가 생긴다고 해도 총 32개에 달하는 선택지가 나오게 됩니다. 최대한 줄여도 가짓수가 둘 셋 이하로는 잘 안 떨어졌던 것 같네요.
문제는 이렇게 만든 선택지들의 차이를 측정하는 것도 대부분의 경우에는 그렇게 명료하지 않다는 것입니다. 최후의 3개, 4개는 장단도 있고 대동소이할 겁니다. 이처럼 최애 LLM을 고르는 건 생각보다 만만한 일은 아닙니다😥.
군계일학 찾기: 언어모델 줄 세우기 (벤치마킹)
비슷하게 느껴지는 언어 모델들을 비교하고 최고의 모델을 선별하는 통상적인 방법엔 어떤 것이 있을까요? 가장 기본적인 방법 중 하나는 모든 모델에게 동일한 ‘시험’을 치르게 하는 것입니다. 이를 위해 사용되는 것이 바로 ‘벤치마크 데이터셋’입니다.
벤치마크 데이터셋은 일종의 표준화된 시험지로, 보통 평가용 지시문과 그에 따른 모범답안을 포함합니다. 이를 통해 얻은 벤치마크 점수는 모델의 성능을 나타내는 ‘시험 점수’와 같은 역할을 합니다.
채점 방식은 어떨까요? 가장 명확하고 객관적인 채점이 가능한 문제들이 주로 사용됩니다. 예를 들어, MMLU1 나 BigBenchHard2 와 같은 벤치마크는 다지선다형 문제를 통해 기초부터 대학 수준까지의 지식을 평가합니다. 또한, GSM8K3 나 SVAMP4 같은 벤치마크는 수학적 능력을 명확하게 측정할 수 있는 문제들로 구성되어 있습니다.

다지선다로는 무엇이든 물어볼 수 있습니다.
이 예시는 그 장점을 남용한 것 같긴 합니다만…
다지선다형 벤치마크는 객관적인 평가에 유용하지만, 언어 모델의 자연스러운 표현 능력을 평가하는 데는 한계가 있습니다. 이러한 한계를 보완하기 위해 서술형 벤치마크들이 개발되었습니다.
서술형 벤치마크의 주요 예시로는 AlpacaEval5, MTBench6, 그리고 Chatbot Arena7 에서 균형 있게 선별된 문제로 구성된 Arena-Hard-Auto8 가 있습니다. 이러한 벤치마크들은 논술형 문제와 그에 따른 모범답안을 제공합니다.
평가 방식은 모델이 생성한 답변을 모범답안과 비교하여 얼마나 선호되는지를 기준으로 점수를 매깁니다. 이는 마치 논술 시험에서 채점관이 모범답안을 참고하여 학생의 답안을 평가하는 것과 유사합니다. 이러한 접근 방식은 언어 모델의 지식 표현 능력, 논리적 사고력, 그리고 자연스러운 언어 사용 능력을 종합적으로 평가할 수 있게 해줍니다.
| 지시문 | 모범답안 | 모델 1 답변의 적절성 | 모델 2 답변의 적절성 |
|---|---|---|---|
| [요약할 기사] | [요약문] | ✅ [적당한 요약문] | ❌ [틀린 요약문] |
| 민사와 형사의 차이? | [법 관련 지식] | ✅ [올바른 답변] | ✅ [역시 올바른 답변] |
| 너의 이름은? | 저는 VARCO LLM 입니다. | ✅ 저는 AI라서 이름이 없긴 합니다 | ❌ 기미노 나마에와? |
| …(나머지 97 개) | … | 80/100 | 50/100 |
여기서 잠깐 LLM의 답변을 모범답안과 비교하는 과정을 짚고 넘어가겠습니다. 많은 수의 지시문에 대해 LLM 답변의 품질을 모범답안과 비교하게 되니 자동화가 필요한데요, 보통은 LLM-as-a-judge라고 불리는 방식을 사용합니다. LLM에게 비교하고자 하는 답변들을 주고 선호를 물어보게 되는데요, OpenAI 모델을 사용한 경우가 많습니다. 사람에게 시키듯이 블라인드 테스트를 시키면 되는데요. 아래 예시와 같습니다.
LLM-as-a-judge 예시, 유저가 LLM Judge를 요청하는 prompt
지시문에 비추어 보았을 때, 어떤 LLM 에이전트의 답변이 더 지시문에 적합한 답인가요? A,B로 답해주세요.
[지시문] 기침이 나는데 어떻게 해야할까?
답변A: 기침을 무조건 참으세요 기침은 기관지에 좋지 않습니다.
답변B: 먼저 의사의 진단을 받아보는 것을 추천드리지만, 당장 그럴 수 없다면 목을 따뜻하게 하고 물을 자주 마셔주는 것은 도움이 될 수 있습니다.
더 나은 것:
LLM judge가 생성한 부분
B
여태 서술한 방식 시험지 방식과 다르게 게임에서 레이팅을 매기는 방법을 채택하는 경우도 있습니다. 적절한 LLM쌍을 골라서 같은 걸 시켰을 때 어떤 게 더 나은 답변을 내는지를 일일이 표기하고 전적이 쌓임에 따라서 이를 바탕으로 상대적인 실력을 산출하여 순위를 매기는 것이죠. 대표적으로 Chatbot Arena가 이 방식을 채택합니다. Chatbot Arena의 경우는 고정된 데이터셋도 없고 따라서 모범답안도 미리 준비해둘 수가 없죠. 모든 LLM이 같은 범위의 지시문 위에서 테스트 되지는 않습니다. 그러나 이를 보강할 정도로 충분히 많은 지시문으로 테스트하게 됩니다.
다뤘던 벤치마크들은 아래 표에 특징에 따라서 정리해보았습니다.
| 벤치마크 이름 | 평가하는 항목 | 평가 방법 | 지시문 전달 | 모범 답안 | 평가자 |
|---|---|---|---|---|---|
| MMLU, BigBenchHard | • 지식 | 다지선다 정답 체점 | 고정 | 필요함 | Exact Match |
| GSM8K, SVAMP | • 산수 | 숫자가 맞는지 확인 | 고정 | 필요함 | Exact Match 혹은 검산 |
| MTBench | • 지식 • 문장력 |
(모범답안과) 쌍 비교 | 고정 | 필요한 것 필요하지 않은 것들이 섞여있음 | OpenAI (gpt-4-0613) |
| AlpacaEval, Arena-Hard-Auto | • 지식 • 문장력 |
(모범답안과) 쌍 비교 | 고정 | 필요함 | OpenAI (gpt-4-1106-preview) |
| Chatbot Arena | • 지식 • 문장력 |
(답변끼리) 직접 쌍 비교 | 자유 (사람이 씀) | 필요하지 않음 | 사람* (자동이 아님) |
모범답안에 기대는 것은 항상 적절한가?
제가 여기서 주장하려는 것은 “아니다” 입니다. 모범답안에 기대는 것은 항상 적절한 것은 아닙니다. 특히 위에서 표에서 문장력 을 평가한다고 써놓은 경우들이 그렇습니다.
자유롭게 답안을 서술할 수 있는 문제에 대해서 모범답안을 참고할 수 있도록 제시하는 것은 분명히 큰 장점이 있습니다. 모범답안이 LLM 답안 평가의 기준선이 된다는 점입니다. 기준을 구체적으로 제안하기 힘들 때 가장 좋은 방법 중 하나입니다. 하지만 이것이 언제나 장점으로 작용하진 않습니다.9
대체로 지시문이 요구하는 답변의 범위가 열려있을 수록 모범답안의 역할은 제한적으로 변합니다. 모범답안은 그저 가능한 답변 중 하나에 불과하니까요. 세 줄짜리 웃긴 얘기를 써보라는 지시에 어떤 모범답안이 모든 가능한 답변들을 대표할 수 있을까요? 객관식 문제의 정답은 우리의 점수를 결정하지만 논술형 문제집의 답안지는 참고용에 불과한 이유가 여기에 있습니다.
모범답안의 한계점은 LLM이라는 단어가 등장하기 전부터… 구체적으로는 “자연어생성 (Natural Language Generation, NLG)” 이라는 단어로 관련 연구들을 통칭하던 시대부터 알려진 문제입니다. 그래서 텍스트 품질 평가를 수행하는 방법에 있어서 reference를 이용하는 방법과 reference에 기대지 않는 reference-free 방법은 quality estimation이라는 이름으로 따로 분류되어 불리기도 했습니다. 메트릭 연구 관점에서는 reference-free metric이라고 직접적으로 분류되었고요.
모범답안의 치명적인 매력: 효율
LLM이 다재다능해진 지금, 튜링 테스트처럼 무엇이든 물어보는 상황에서 과연 모범답안에 기대는 것이 적절한지 의문을 제기할 수 있습니다. 이는 당연한 질문이지만, 모범답안을 사용하는 데에는 숨겨진 매력이 있습니다. 바로 효율성입니다.
비교 작업 자체를 횟수당 비용으로 환산해 보겠습니다. 실제로 LLM으로 평가를 자동화하면 회당 비용으로 계산하게 됩니다. 테스트할 벤치마크 데이터셋의 지시문이 500개라고 가정해 봅시다.
여기 LLM A와 B를 비교하는 두 가지 방법이 있습니다:
- Reference-free: A와 B의 답변 각 500개를 서로 비교해 누가 더 많이 이겼는지 확인
- Reference-based: 500개의 모범답안과 비교해 모범답안보다 우월한 답변의 개수 비교
비교할 대상이 A, B 단 둘인 경우에는 비교 횟수가 같아 비용 차이가 없습니다. 그러나 실제로는 한 번의 업데이트에 여러 개의 LLM 후보를 고려합니다. 현실적으로 3-4개 정도를 후보로 놓는게 덜 고통스럽습니다.
LLM 답변 품질 비교가 단순한 수의 대소 비교는 아니지만, 그렇다고 가정해도 n개 모델을 정렬하려면 지시문별로 O(n log₂ n)의 비교가 필요합니다. 반면 모범답안을 활용하면 항상 지시문별 n번의 비교만 필요합니다.
사람이 비교하든 OpenAI 모델을 사용하든, 비용 측면에서 모범답안 사용은 큰 이점이 됩니다. 또한 자세한 순위까지 얻을 수 있어, 이는 모범답안에 기대게 되는 충분한 이유가 됩니다.
우리가 제안하는 솔루션: VARCO Arena
LLM 순위를 매기는 데 모범답안 외에 다른 효율적인 방법은 없을까요? VARCO Arena가 바로 이 문제를 해결합니다. 경쟁 스포츠에서 힌트를 얻어, 모범답안 없이도 같은 횟수의 비교로 순위를 매길 수 있게 설계했습니다.
VARCO Arena는 Single-Elimination 토너먼트와 Elo 레이팅 시스템을 결합한 형태로 작동합니다. 이 개념들은 경쟁 스포츠에서 차용했기 때문에, 다음 설명에서는 ‘참가자’, ‘매치’, ‘승자’ 등의 용어가 자주 등장합니다. 이해를 돕기 위해 다음과 같이 해석할 수 있습니다:
참가자 = 후보 LLM
매치/경기 = 두 후보 LLM이 하나의 지시문에 대해 답변한 것을 Judge LLM이 비교하는 상황
심판 = LLM 답변의 우열을 가리는 Judge LLM
승자 = 더 나은 답변으로 판정된 후보 LLM
이제 VARCO Arena의 작동 방식을 토너먼트부터 순서대로 설명하겠습니다.
1등을 뽑는 방법: Tournament
많은 경쟁 스포츠는 토너먼트 방식으로 승자를 결정합니다. 가장 유명한 single-elimination 방식에서는 1회 패배 시 탈락하고, 승자는 다음 라운드로 진출합니다. 최후의 승자가 1등이 됩니다.
토너먼트의 매력적인 점은 우승자를 가리기까지의 경기 횟수가 항상 (참가자 수) - 1이라는 것입니다. 따라서 1등만 정하려면 매우 효율적인 방법입니다.
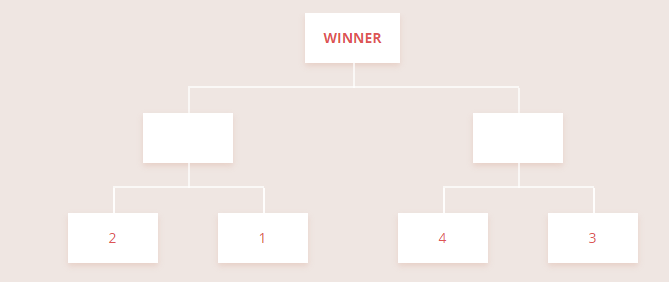
일반적으로 많이 접하는 single-elimination tournament. 이기는 사람만 다음 경기할 기회가 주어진다.
하지만 세부적인 순위를 알아보는 데는 적합하지 않습니다. 토너먼트는 1등을 뽑기 위해 설계되어 2등부터는 신뢰성이 떨어집니다. 예를 들어:
- 2등이 1등과 결승전 이전에 만났다면, 결승전에는 3등과 1등이 대결했을 수 있습니다.
- 4강에 진출한 팀들은 3, 4위 결정전을 하지 않으면 동등한 4강으로 간주됩니다.
8팀이 참가하는 토너먼트 컵의 순위는 다음과 같이 나타납니다:
- 우승
- 준우승 3-4. 4강 (동률) 5-8. 8강 (동률)
이처럼 토너먼트는 정확한 순위 정하기가 어렵다는 한계점이 있습니다. 그렇다면 피파 랭킹 같은 것들은 어떻게 산출되는 걸까요? 그건 4강이 아니라 3위 처럼 구체적이었던 것 같은데 말이죠.
전적을 통해서 점수표를 만드는 방법: Elo Rating
상세 순위는 주로 역대 전적을 바탕으로 산출됩니다. 하지만 모든 경우의 수로 경기를 하는 것도 아니고, 그렇게 한다 해도 정확한 순위 정렬이 어렵습니다. 이런 상황에서 유용하게 쓰이는 것이 Elo rating system10 입니다.
Elo rating은 이변이 일어날 수 있는 경쟁 스포츠에서 참가자들의 랭킹을 매기기 위해 개발되었습니다. 체스 선수들의 실력을 점수화하기 위해 Elo 교수가 제안한 이 방법은 현재 Chatbot Arena에서 LLM 등수를 매기는 데 핵심적인 역할을 하고 있으며, 여러 수정본이 FIFA 랭킹, 하키 랭킹 등에 활용되고 있습니다.
간단히 말해, Elo 점수는 두 참가자의 상대 승률로 환원할 수 있는 실력 점수입니다. 점수 차를 로지스틱 함수에 넣으면 두 참가자 사이의 상대 승률이 나옵니다. 식은 다음과 같습니다:
\(P(A\) wins \(B) = 1 / ( 1 + 10^{(R_B - R_A)/400} )\)
*\(R_A\) = A의 Elo rating, \(R_B\) = B의 Elo rating
실력 점수인 rating (\(R_*\)) 을 계산하기 위해서는 역대 두 팀의 전적을 참고해 상대 승률 (\(P(A\) wins \(B)\))을 정한 다음, 두 팀의 점수 차 (\(R_B-R_A\)) 를 가늠합니다. 여러 매치업의 상대 승률을 최대한 비슷하게 맞출 수 있는 각 팀의 점수가 실력 점수가 되며, 이에 따라 순위를 매깁니다.
따라서 만나본 적이 없거나 기록이 충분하지 않은 경기에 대해 예상 승률이 나온다면, 보통 Elo rating system이나 유사한 실력-점수화 시스템을 사용하고 있는 것입니다. 경쟁전 게임에서 적절한 매치업을 위해 Match-Making-Rate (소위 말하는 MMR) 을 활용하고 이를 실력 지표로 삼는 것도 같은 맥락입니다.
VARCO Arena ← Tournament + Elo rating
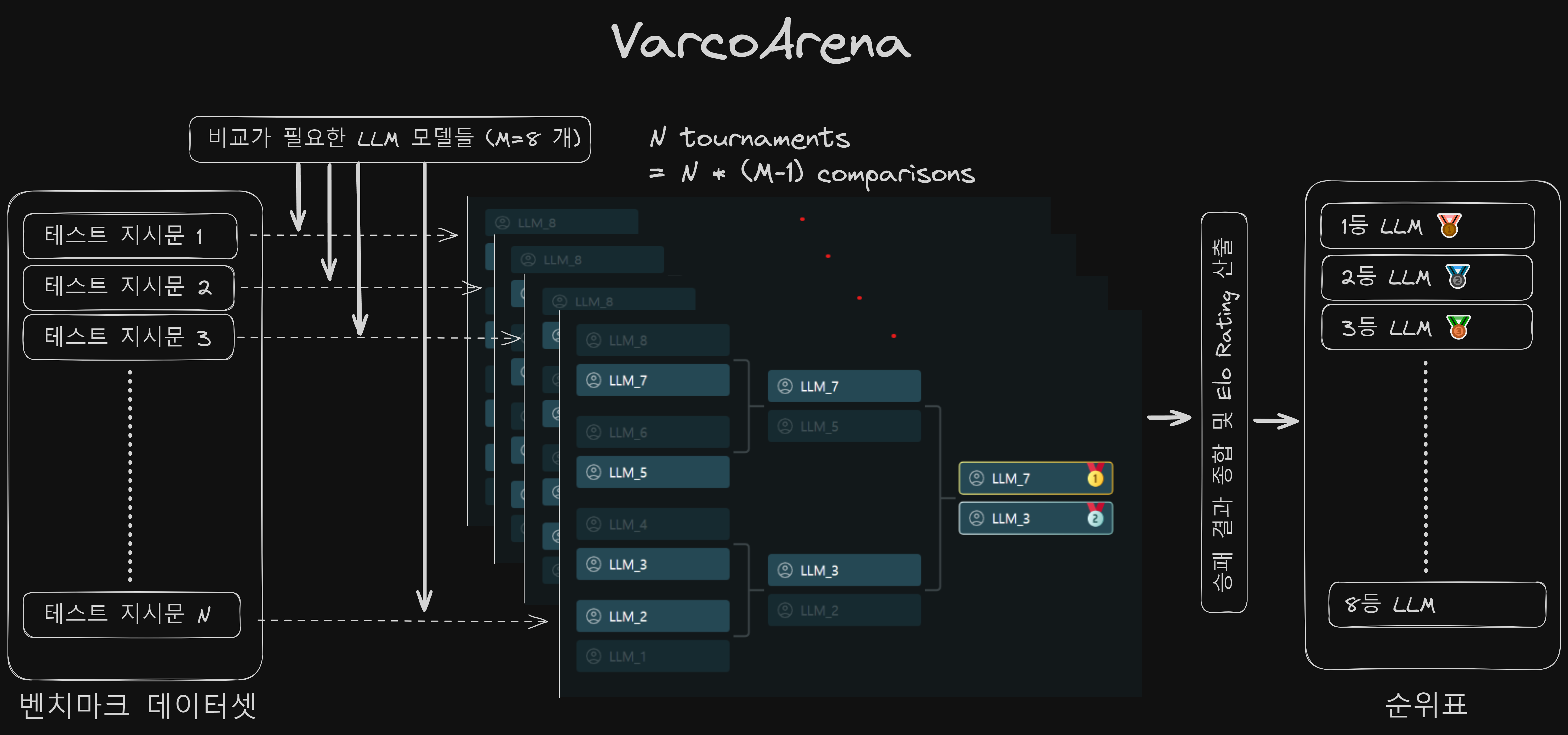
VARCO Arena 동작 흐름도
토너먼트의 장점인 많은 대결 횟수와 Elo의 장점인 세밀한 순위를 동시에 얻을 수 있을까요? 제목에서 언급했듯이, 토너먼트와 Elo 시스템의 장점을 결합하면 가능합니다.
Elo 시스템은 가능한 모든 대결에 대한 상대 승률이 정확할수록 더 신뢰할 수 있는 순위를 제공합니다. 따라서 다양한 매치업에 대해 충분한 수의 대결이 이루어진다면 더욱 유용할 것입니다.
저희는 LLM 벤치마크 데이터셋의 크기가 보통 100개 단위로 시작한다는 점에 주목했습니다. 100개의 지시문에 대해 각 참가 LLM 모델들의 출력 품질을 토너먼트 방식으로 평가한다고 생각해보세요. 이는 100개의 과거 월드컵 결과를 종합하여 FIFA 랭킹을 산출하는 것과 유사합니다.
작동 방식을 의사 코드로 표현하면 다음과 같습니다:
- 테스트 지시문 데이터셋, LLM 모델들, 그리고 각 모델의 출력을 준비합니다.
- MATCH 함수를 정의합니다:
- 두 모델과 프롬프트를 입력받습니다.
- 더 나은 출력을 생성한 모델을 반환합니다.
- TOURNAMENT 함수를 정의합니다:
- 플레이어(모델 목록)과 프롬프트를 입력받습니다.
- 플레이어가 2명이면 MATCH 함수로 승자를 결정합니다.
- 2명 이상이면 목록을 좌우 브라켓으로 나누어 재귀적으로 토너먼트를 진행합니다.
- TOURNAMENT2LEADERBOARD 함수를 정의합니다:
- 모든 테스트 프롬프트와 모델을 입력받습니다.
- 각 프롬프트에 대해:
- a. 모델 목록을 섞습니다.
- b. TOURNAMENT 함수로 토너먼트를 실행합니다. * 모든 결과를 기록합니다.
- TOURNAMENT2LEADERBOARD 함수를 실행합니다.
- 5 에서 기록한 결과를 바탕으로 Elo 레이팅을 계산합니다.
- Elo 레이팅에 따라 LLM 모델들의 순위를 매깁니다.
100개의 토너먼트가 모두 같은 대진 구조를 가진다면, 지시문이 바뀌어 매치 결과가 달라질 수 있다 하더라도 불공정한 대진 문제가 반복될 수 있습니다. 이를 방지하기 위해 우리는 매 토너먼트마다 대진을 랜덤하게 구성합니다 (4.2.a).
랜덤 대진 방식 (4.2.a) 은 두 가지 장점이 있습니다:
- 가능한 모든 매치업을 최대한 탐색할 수 있습니다.
- 정확한 상대 승률을 산출하기 위해 균형 있게 매치를 배정할 수 있습니다.
실력이 뛰어난 LLM들은 여러 라운드를 진출하게 되므로 자연스럽게 더 많은 매치에 참여하게 됩니다. 이는 상위권 LLM들 간의 미세한 차이를 더 정확하게 구분하는 데 도움이 됩니다. 반면, 하위권 LLM들의 경우에도 매 토너먼트마다 최소 1회는 매치에 참여하게 됩니다. 이는 LLM 벤치마킹 관점에서 모든 LLM을 빠짐없이 테스트할 수 있게 해주는 장점이 있습니다.
실제 결과
아래는 Chatbot Arena의 상위 20개 모델들을 Arena-Hard-Auto 벤치마크 데이터로 평가하고 순위를 매겼을 때, 그 결과가 Chatbot Arena의 순위와 얼마나 일치하는지를 Spearman 상관 계수로 나타냈습니다. 이 계수가 1에 가까울수록 순위 예측이 정확히 되었다는 뜻입니다.
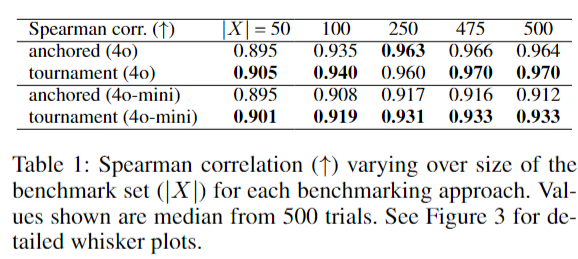
500번의 랜덤 대진, 500번의 벤치마크 랜덤 샘플로부터 측정한 순위 예측값 - Chatbot Arena 순위의 Spearman correlation 중간값
벤치마크 데이터셋 사이즈 (표의 \(\lvert X \rvert\)) 나 어떤 심판(Judge LLM, gpt-4o 또는 gpt-4o-mini)에 상관없이, VARCO Arena가 순위를 더 정확히 매깁니다. 표에서 ‘anchored’는 모범답안을 사용한 기존 접근 방식을, ‘tournament’는 VARCO Arena가 채택한 방식을 나타냅니다. 더욱 주목할 만한 점은, VARCO Arena (tournament) 의 경우 모범답안을 사용하지 않으면서도 더 나은 결과를 얻었다는 것입니다. 또한, 비용 측면에서도 항상 데이터셋 개수만큼의 절감 효과를 보였습니다:
모범답안 활용 시: 데이터셋 크기 * 모델 수
토너먼트 활용 시: 데이터셋 크기 * (모델 수 - 1)
저희는 VARCO Arena의 성능향상이 오히려 모범답안을 사용하지 않은데에서 (reference-free) 기인한다고 추정하고 있습니다. 두 모델의 출력 우열을 가리는데에 중간 다리가 하나 주는 거니까요. VARCO Arena에서 채택한 토너먼트 방식이 어째서 신뢰할 만한 순위를 도출하는지에 대한 자세한 내용은 논문에서 확인하실 수 있습니다. 아래에 둘의 차이를 표로 정리해 두었습니다.
| 벤치마크 방식 | 단일 매치 (LLM judge로 자동화) |
M개 모델 중세우는데 필요한 총 매치 수 (N=벤치마크 데이터셋 사이즈) |
|
|---|---|---|---|
| VARCO Arena | 토너먼트 + Elo | LLM 출력상 직접 비교 | (M-1) * N |
| 기존 방식 | 모범답안과 비교승률 | LLM 출력과 모범답안 비교 | M*N |
더 자세한 내용
이 외에도 논문에서는 사용한 심판 (위 실험의 경우에는 OpenAI gpt-4o[-mini]를 judge로 사용) 의 정확도, 순위 매길 후보 LLM의 갯수등의 요인에 따라 VARCO Arena 여전히 일관된 성능향상이 있는지 자세히 다루었습니다. 완성해둔 LLM리더보드 순위에 새 모델을 끼워넣는 때에는 어떻게 하면 좋을지 등에 대해서도 상세히 다루었습니다.
마치며
저희는 VARCO Arena를 모델 학습 완료 후나 프롬프트 엔지니어링 이후의 성능 평가 및 순위 매김에 활용하고 있습니다. 이 방법은 최종 배포 전 모든 결과물을 직접 검토해야 하는 필요성을 줄여주어, 작업 효율을 크게 향상시켰습니다. 내부적으로는 몇 차례의 파일럿 테스트를 통해 VARCO Arena의 순위 결과가 사람들이 매긴 점수와 상당히 유사함을 확인했습니다.
500회의 반복 실험 결과, VARCO Arena의 초기 대진에 따른 결과 변동성은 모범답안을 활용한 방식과 큰 차이가 없었습니다. 다만, 벤치마크 산출 과정에 무작위성 요소로 대진표가 추가된 점에 대해 일부 사용자들은 우려를 표할 수 있을 것 같습니다.
VARCO Arena를 활용해보실 수 있도록 웹 데모와 CLI로 구동 가능한 소스코드를 공개할 예정입니다 (논문과 함께요). 많은 관심 부탁드릴게요. :saluting_face: 이상으로 VARCO Arena에 대한 소개를 마치겠습니다. 앞으로도 좋은 기회에 다시 만나뵈었으면 좋겠네요. 감사합니다.
References
-
Hendrycks, Dan, et al. “Measuring Massive Multitask Language Understanding.” International Conference on Learning Representations.
paper link / benchmark link ↩ -
Suzgun, Mirac, et al. “Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them.” Findings of the Association for Computational Linguistics: ACL 2023. 2023.
paper link / benchmark link ↩ -
Cobbe, Karl, et al. “Training verifiers to solve math word problems.” arXiv preprint arXiv:2110.14168 (2021).
paper link / benchmark link ↩ -
Patel, Arkil, et al. “Are NLP Models Really Able to Solve Simple Math Word Problems?” Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021.
paper link / benchmark link ↩ -
Dubois, Yann, et al. “Alpacafarm: A simulation framework for methods that learn from human feedback.” Advances in Neural Information Processing Systems 36 (2024).
paper link / benchmark link ↩ -
Zheng, Lianmin, et al. “Judging llm-as-a-judge with mt-bench and chatbot arena.” Advances in Neural Information Processing Systems 36 (2024).
paper link ↩ -
Chiang, Wei-Lin, et al. “Chatbot arena: An open platform for evaluating llms by human preference.” arXiv preprint arXiv:2403.04132 (2024).
paper link / arena link ↩ -
Li, Tianle, et al. “From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline.” arXiv preprint arXiv:2406.11939 (2024).
paper link / blog link ↩ -
Sheng, Shuqian et al. “Is Reference Necessary in the Evaluation of NLG Systems? When and Where?.” Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
paper link ↩ -
Elo, Arpad E., and Sam Sloan. “The rating of chessplayers: Past and present.” (No Title) (1978). ↩
